引言
在當今數據驅動的環境中,組織需要高效的方法來提取、處理和分析網絡內容。傳統的網絡抓取面臨著諸多挑戰:反機器人保護、復雜的JavaScript渲染以及持續的維護需求。此外,理解非結構化的網絡數據則需要復雜的處理能力。
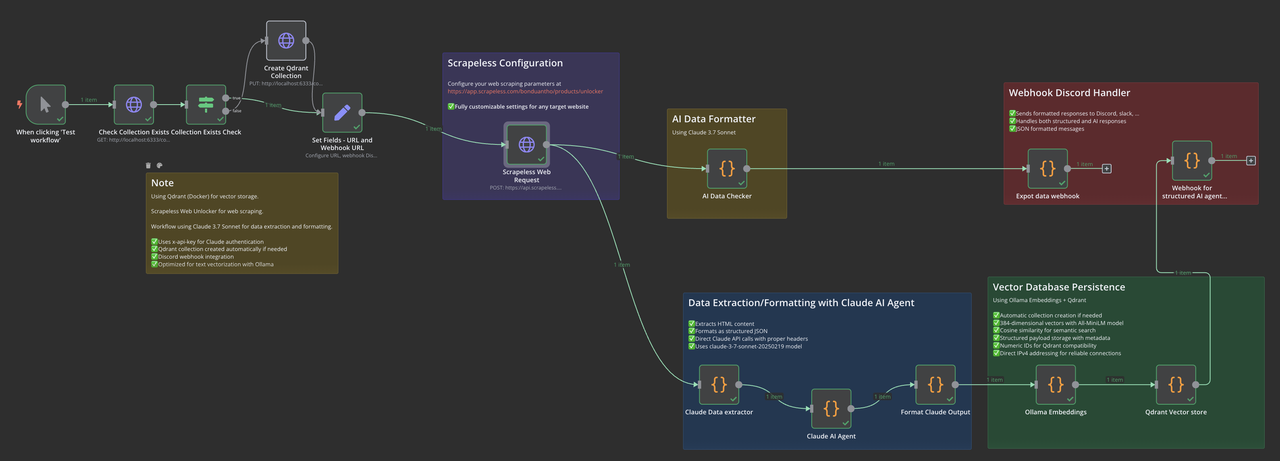
本指南演示了如何使用 n8n 工作流自動化、Scrapeless 網絡抓取、Claude AI 進行智能提取,以及 Qdrant 向量數據庫進行語義存儲,構建完整的網絡數據管道。無論您是構建知識庫、進行市場研究,還是開發 AI 助手,此工作流都提供了強大的基礎。
您將構建的內容
我們的 n8n 工作流結合了幾種尖端技術:
- Scrapeless 網絡解鎖器:先進的網絡抓取與 JavaScript 渲染
- Claude 3.7 詩集:人工智能驅動的數據提取和結構化
- Ollama 嵌入:本地向量嵌入生成
- Qdrant 向量數據庫:語義存儲和檢索
- 通知系統:通過網絡鉤子實現實時監控
這個端到端的管道將凌亂的網絡數據轉化為結構化、向量化的信息,準備進行語義搜索和 AI 應用。
安裝與設置
安裝 n8n
n8n 需要 Node.js v18、v20 或 v22。如果您遇到版本兼容性問題:
Copy
# 檢查您的 Node.js 版本
node -v# 如果您有一個較新不受支持的版本(例如 v23+),請安裝 nvm
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.5/install.sh | bash
# 或者對于 Windows,使用 NVM for Windows 安裝程序# 安裝兼容的 Node.js 版本
nvm install 20# 使用已安裝的版本
nvm use 20# 全局安裝 n8n
npm install n8n -g# 運行 n8n
n8n您的 n8n 實例現在應該可以在?http://localhost:5678?訪問。
設置 Claude API
- 訪問 Anthropic 控制臺并創建一個帳戶
- 導航到 API 密鑰部分
- 點擊“創建密鑰”,并設置適當的權限
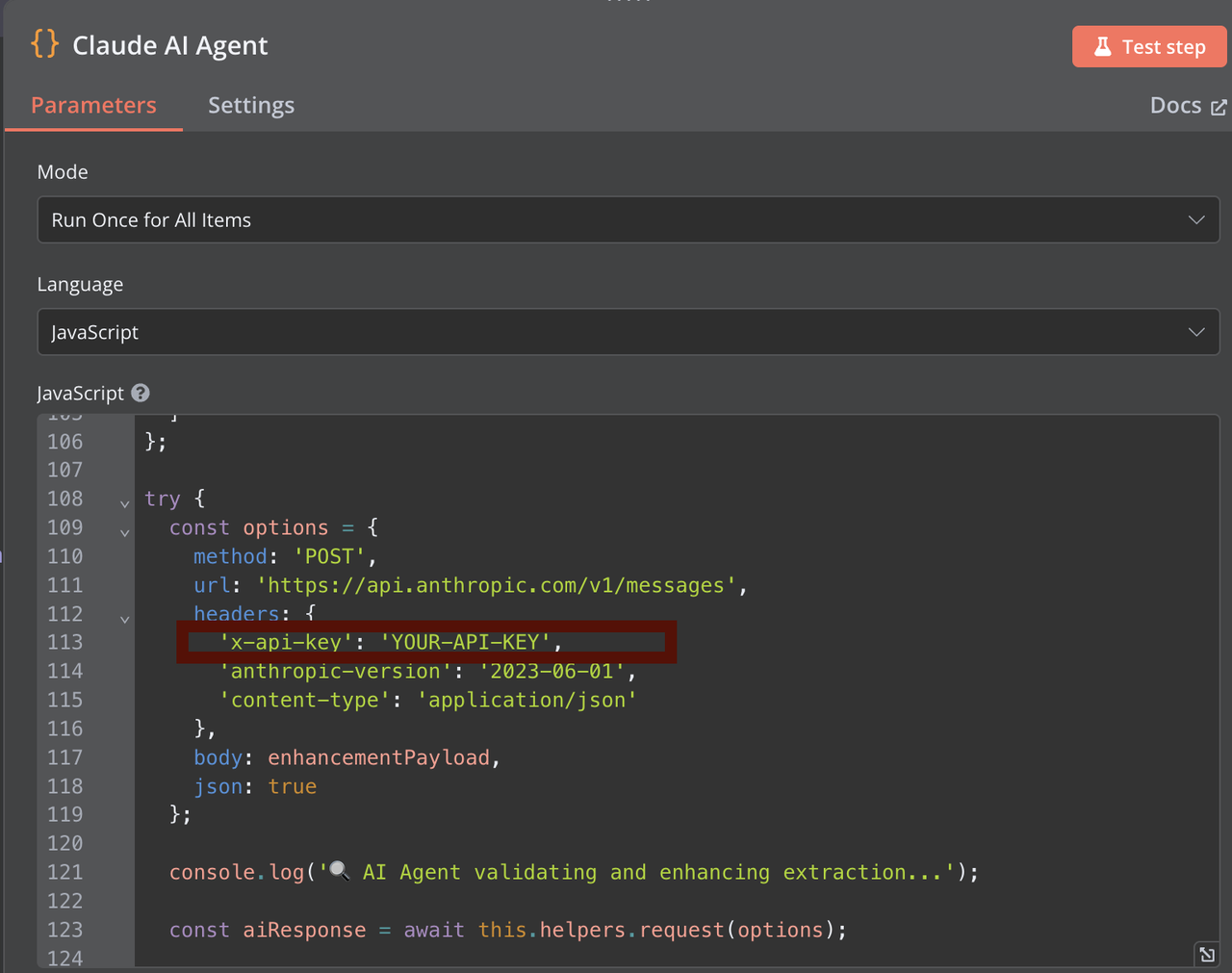
- 復制您的 API 密鑰以用于 n8n 工作流(在 AI 數據檢查器、Claude 數據提取器和 Claude AI 代理中)
設置 Scrapeless
- 訪問?Scrapeless?并創建一個帳戶
- 導航到儀表板中的通用抓取 API 部分?Effortless Web Scraping Toolkit - Scrapeless
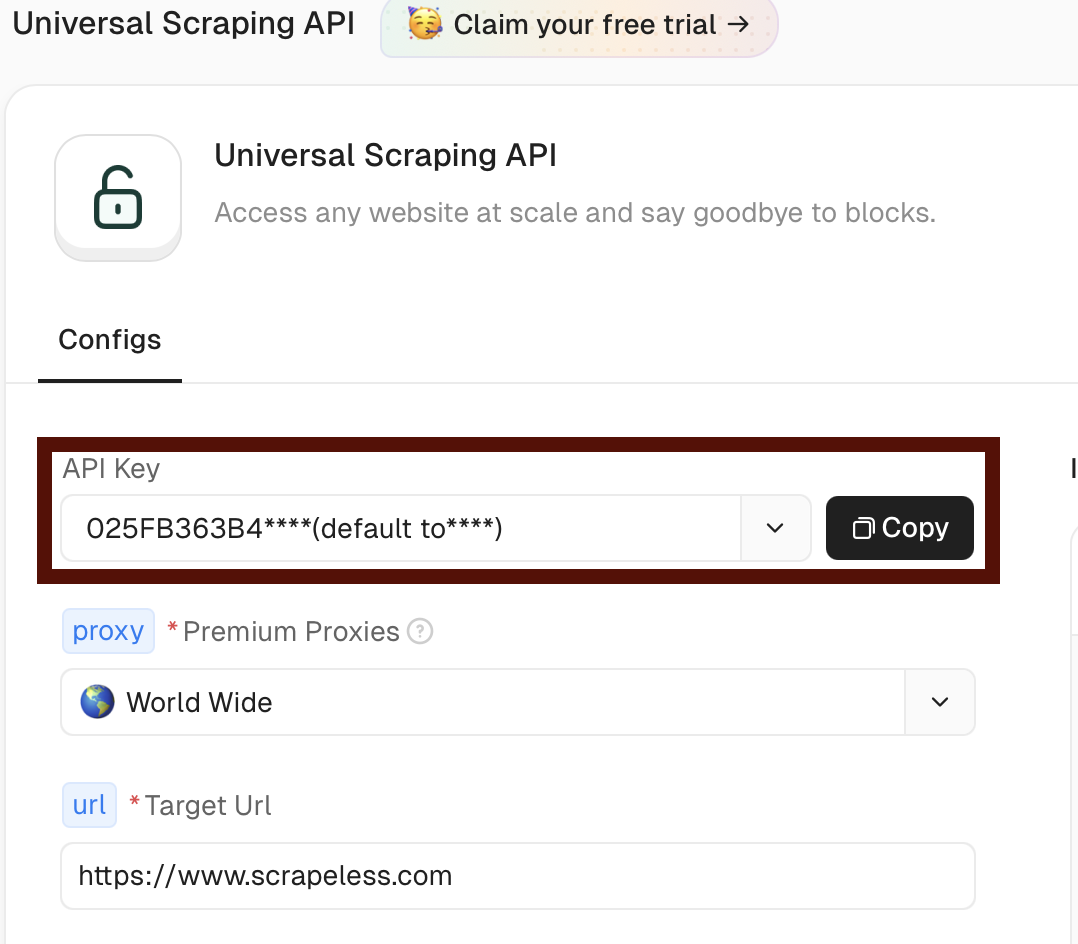
- 復制您的令牌以用于 n8n 工作流
您可以使用此 curl 命令自定義您的 Scrapeless 網絡抓取請求,并將其直接導入到 n8n 的 HTTP 請求節點中:
Copy
curl -X POST "https://api.scrapeless.com/api/v1/unlocker/request" \-H "Content-Type: application/json" \-H "x-api-token: scrapeless_api_key" \-d '{"actor": "unlocker.webunlocker","proxy": {"country": "ANY"},"input": {"url": "https://www.scrapeless.com","method": "GET","redirect": true,"js_render": true,"js_instructions": [{"wait":100}],"block": {"resources": ["image","font","script"],"urls": ["https://example.com"]}}}'
使用 Docker 安裝 Qdrant
Copy
# 拉取 Qdrant 鏡像
docker pull qdrant/qdrant# 以數據持久化運行 Qdrant 容器
docker run -d \--name qdrant-server \-p 6333:6333 \-p 6334:6334 \-v $(pwd)/qdrant_storage:/qdrant/storage \qdrant/qdrant驗證 Qdrant 是否正在運行:
Copy
curl http://localhost:6333/healthz安裝 Ollama
macOS:
Copy
brew install ollamaLinux:
Copy
curl -fsSL https://ollama.com/install.sh | shWindows:從 Ollama 的網站下載并安裝。
啟動 Ollama 服務器:
Copy
ollama serve安裝所需的嵌入模型:
Copy
ollama pull all-minilm驗證模型安裝:
Copy
ollama list設置 n8n 工作流
工作流概述
我們的工作流由以下關鍵組件組成:
- 手動/計劃觸發:啟動工作流
- 集合檢查:驗證 Qdrant 集合是否存在
- URL 配置:設置目標 URL 和參數
- Scrapeless 網絡請求:提取 HTML 內容
- Claude 數據提取:處理和結構化數據
- Ollama 嵌入:生成向量嵌入
- Qdrant 存儲:保存向量和元數據
- 通知:通過網絡鉤子發送狀態更新
步驟 1:配置工作流觸發器和集合檢查
首先添加一個手動觸發節點,然后添加一個 HTTP 請求節點以檢查您的 Qdrant 集合是否存在。您可以在此初始步驟中自定義集合名稱 - 如果集合不存在,工作流將自動創建它。
重要說明:?如果您想使用與默認“hacker-news”不同的集合名稱,請確保在所有引用 Qdrant 的節點中一致地更改它。
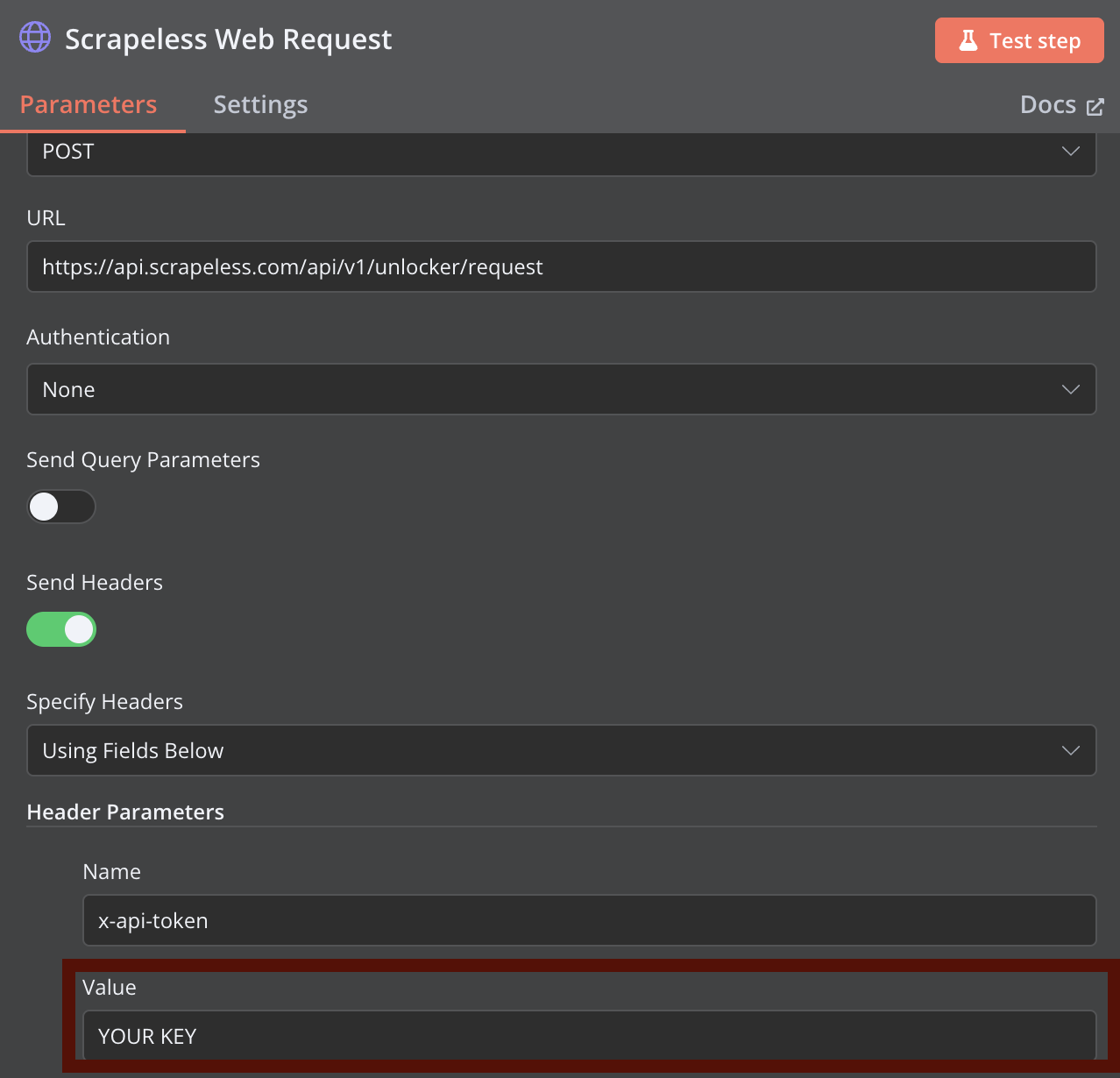
步驟 2:配置 Scrapeless 網絡請求
添加一個 HTTP 請求節點用于 Scrapeless 網絡抓取。使用之前提供的 curl 命令配置節點,將 YOUR_API_TOKEN 替換為您實際的 Scrapeless API 令牌。
您可以在 Scrapeless Web Unlocker 中配置更高級的抓取參數。
步驟 3:Claude 數據提取
添加一個節點處理 HTML 內容,使用 Claude。您需要提供您的 Claude API 密鑰以進行身份驗證。Claude 提取器分析 HTML 內容并以 JSON 格式返回結構化數據。
步驟 4:格式化 Claude 輸出
此節點獲取 Claude 的響應,并通過提取相關信息并適當地格式化來為向量化做準備。
步驟 5:生成 Ollama 嵌入
此節點將結構化文本發送到 Ollama 以生成嵌入。確保您的 Ollama 服務器正在運行,并且已安裝 all-minilm 模型。
步驟 6:Qdrant 向量存儲
此節點將生成的嵌入存儲在您的 Qdrant 集合中,連同相關的元數據。
步驟 7:通知系統
最后一個節點通過您配置的網絡鉤子發送工作流執行狀態的通知。
常見問題排查
n8n Node.js 版本問題
如果您看到如下錯誤:
Copy
您的 Node.js 版本 X 當前不受 n8n 支持。
請使用 Node.js v18.17.0(推薦)、v20 或 v22! 通過安裝 nvm 并使用兼容的 Node.js 版本來修復,如設置部分所述。
Scrapeless API 連接問題
- 驗證您的 API 令牌是否正確
- 檢查您是否超出了 API 速率限制
- 確保 URL 格式正確
Ollama 嵌入錯誤
常見錯誤:connect ECONNREFUSED ::1:11434
修復:
- 確保 Ollama 正在運行:ollama serve
- 驗證模型是否已安裝:ollama pull all-minilm
- 使用直接 IP(127.0.0.1)而不是 localhost
- 檢查是否有其他進程在使用端口 11434
高級用法場景
批處理多個 URL
要在一次工作流執行中處理多個 URL:
- 使用批次拆分節點并行處理 URL
- 為每個批次配置適當的錯誤處理
- 使用合并節點合并結果
定期數據更新
通過定期更新保持您的向量數據庫最新:
- 用計劃節點替換手動觸發
- 配置更新頻率(每日、每周等)
- 使用如果節點僅處理新或更改的內容
自定義提取模板
為不同內容類型調整 Claude 的提取:
- 為新聞文章、產品頁面、文檔等創建特定提示
- 使用開關節點選擇合適的提示
- 將提取模板存儲為環境變量
結論
此 n8n 工作流創建了一個強大的數據管道,結合了 Scrapeless 網絡抓取、Claude AI 提取、向量嵌入和 Qdrant 存儲的優勢。通過自動化這些復雜的過程,您可以專注于使用提取的數據,而不是獲取它的技術挑戰。
n8n 的模塊化特性使您能夠擴展此工作流,增加更多處理步驟、與其他系統的集成或自定義邏輯,以滿足您的特定需求。無論您是構建 AI 知識庫、進行競爭分析,還是監控網絡內容,這個工作流都提供了堅實的基礎。



















