RL?: Better Test-Time Scaling by Unifying LLM Reasoners With Verifiers
在人工智能領域,大語言模型(LLM)的推理能力提升一直是研究熱點。今天要解讀的論文提出了一種全新的強化學習框架RL?,通過融合推理與驗證能力,為大模型的測試效率和泛化性能帶來了突破性進展。這一成果不僅解決了傳統強化學習方法的關鍵缺陷,更展現了統一化訓練在提升模型綜合能力上的巨大潛力。
論文標題
Putting the Value Back in RL: Better Test-Time Scaling by Unifying LLM Reasoners With Verifiers
來源
arXiv:2505.04842 [cs.LG] + https://arxiv.org/abs/2505.04842
PS: 整理了LLM、量化投資、機器學習方向的學習資料,關注同名公眾號 「 亞里隨筆」 即刻免費解鎖
研究背景
在大語言模型(LLM)推理能力的強化學習(RL)優化中,主流方法(如 GRPO、VinePPO)為降低訓練成本,普遍舍棄傳統價值函數,轉而依賴經驗估計回報。這一 “去價值化” 策略雖提升了訓練階段的計算效率和內存利用率,卻導致測試階段喪失關鍵的內置驗證能力—— 傳統價值函數本可作為 “結果驗證器” 評估推理鏈正確性,支撐并行采樣(如 Best-of-N 投票)等計算擴展策略。這一策略雖然提升了訓練效率,卻導致模型在測試階段缺乏內置的驗證機制,難以利用并行采樣等計算擴展策略優化推理結果。
研究問題
1. 測試階段計算效率低下:缺少價值函數或驗證器,無法通過并行采樣(如Best-of-N投票)有效提升推理準確性。
2. 獨立驗證器的高成本:部署單獨的驗證模型會增加數據標注、計算資源和內存占用的負擔。
3. 泛化能力受限:傳統方法在跨難度(Easy-to-Hard)或跨領域(Out-of-Domain)任務中表現不足,難以應對復雜推理需求。
主要貢獻
1. 統一化訓練框架RL?
首次提出在單一LLM中同時訓練推理器(Reasoner)和生成式驗證器(Generative Verifier),利用強化學習過程中產生的(問題-解-獎勵)數據,通過聯合優化RL目標與驗證目標(如預測“是否正確”的下一個標記),實現“一次訓練,雙重能力”。與傳統方法相比,無需額外模型或數據開銷,驗證能力提升的同時推理性能保持穩定。
2. 測試階段計算效率的革命性提升
- 并行采樣效率:在MATH500數據集上,使用加權投票策略時,RL?相比基線方法(如GRPO)的計算效率提升8-32倍,準確率提高超20%。
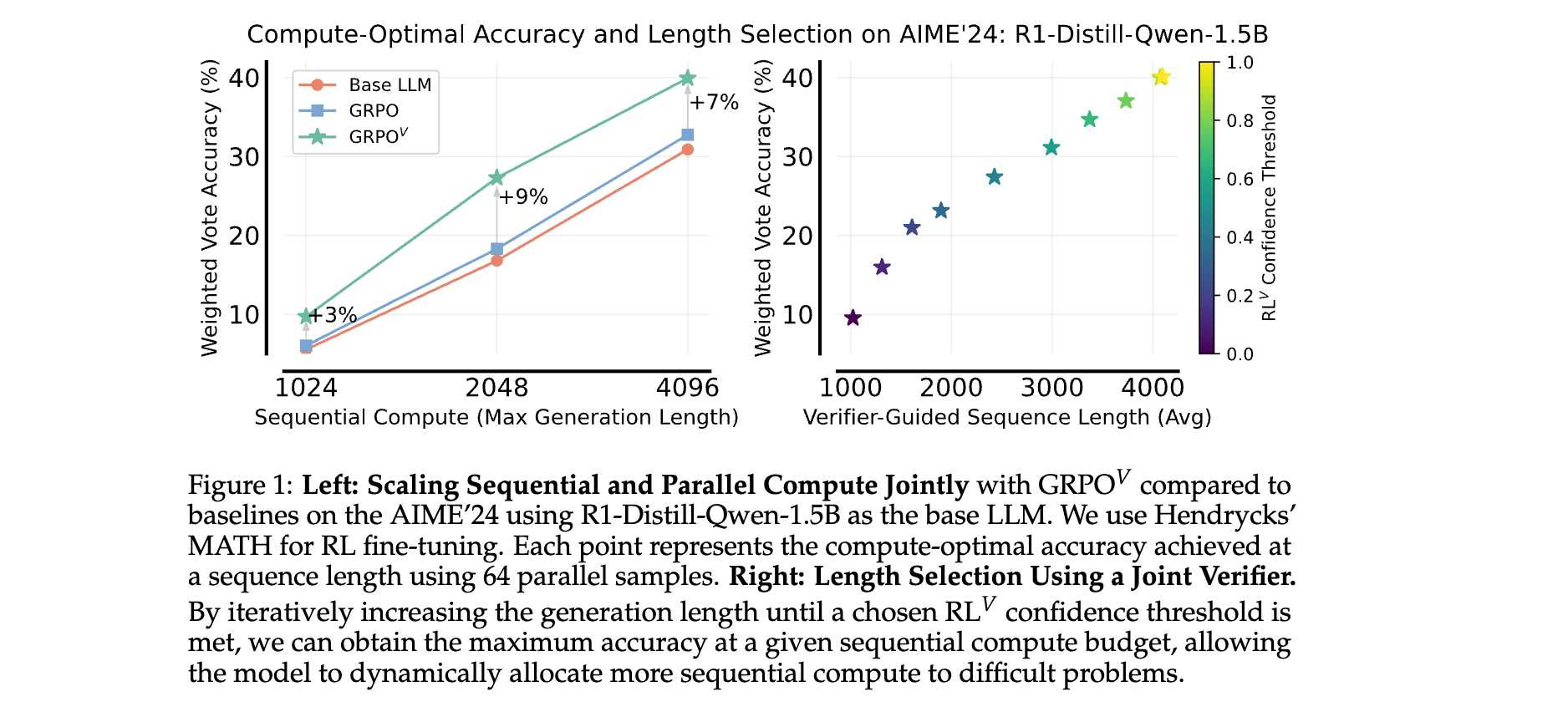
- 動態序列長度優化:通過設定驗證置信度閾值,模型可自動為難題分配更長的推理序列,在AIME’24數據集上實現計算預算內的準確率最大化。
3. 跨場景泛化能力突破
- 難度泛化:在MATH2(更復雜數學問題)上,RL?的成功率比基線方法高10%以上。
- 領域泛化:在GPQA物理問題(跨領域任務)中,準確率提升超10%,證明其驗證機制具有通用性。
4. 長推理模型的互補性增強
與長思維鏈模型(如R1-Distill-Qwen-1.5B)結合時,RL?在并行+序列計算聯合擴展場景下,性能比基線方法高1.2-1.6倍,驗證了其與現有技術的兼容性。
方法論精要
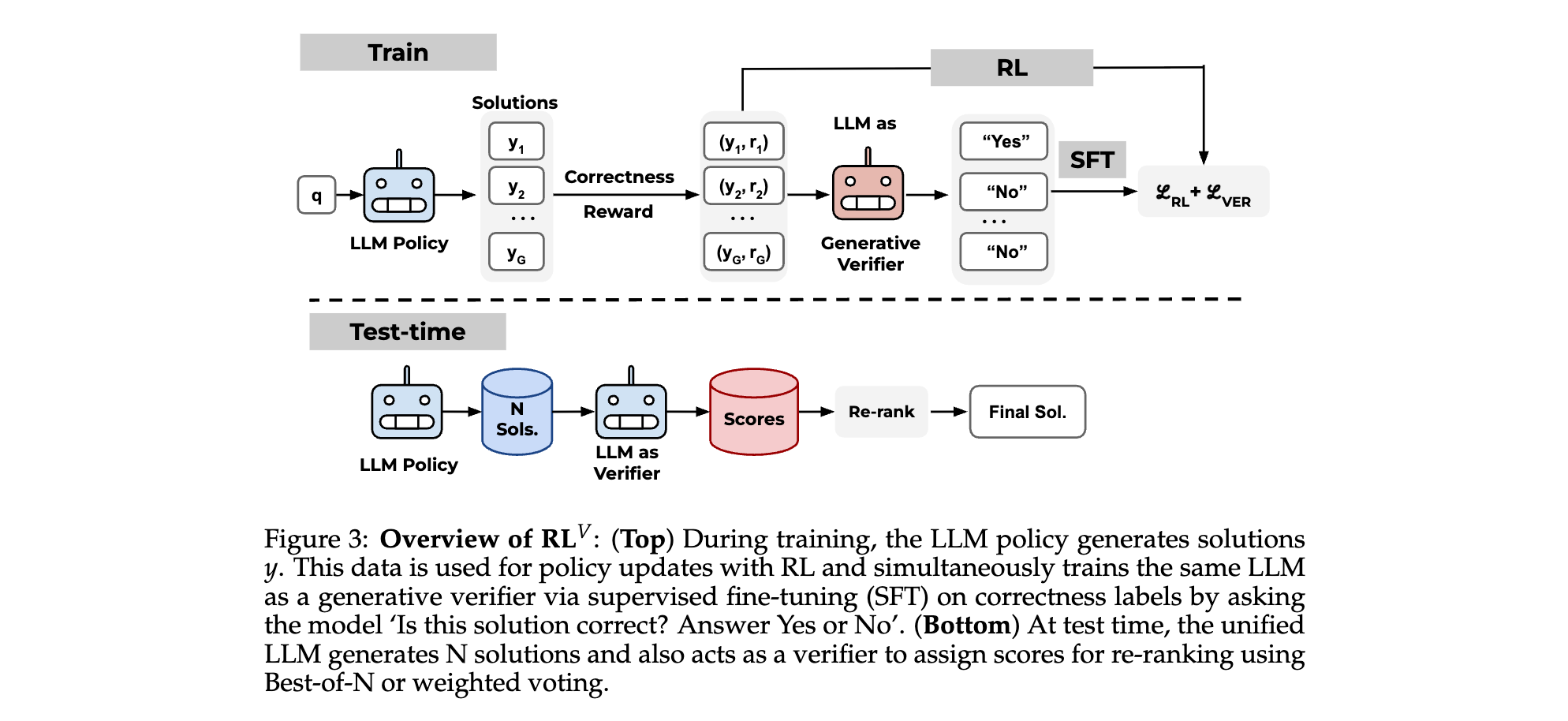
1. 核心框架:RL?的統一訓練機制
- 訓練階段:
LLM同時作為策略網絡(生成推理鏈)和驗證器(預測解的正確性)。利用RL生成的解及其正確性標簽(由獎勵函數提供),通過監督微調(SFT)訓練驗證器,目標為最大化預測“是/否”標簽的似然性。
統一目標函數:
J Unified ( θ ) = J RL ( θ ; x ) + λ J Verify ( θ ; x ) \mathcal{J}_{\text{Unified}}(\theta) = \mathcal{J}_{\text{RL}}(\theta; x) + \lambda \mathcal{J}_{\text{Verify}}(\theta; x) JUnified?(θ)=JRL?(θ;x)+λJVerify?(θ;x)
其中, J RL \mathcal{J}_{\text{RL}} JRL?為強化學習目標, J Verify \mathcal{J}_{\text{Verify}} JVerify?為驗證目標, λ \lambda λ平衡兩者權重。
- 測試階段:
LLM生成N個候選解,同時作為驗證器為每個解評分(“是”的概率),通過加權投票或Best-of-N策略選擇最終答案。例如,加權投票將同一答案的驗證分數累加,選擇最高分答案,顯著優于無驗證的多數投票基線。
2. 關鍵參數設計原理
- 驗證目標的形式:
將驗證視為“下一個標記預測”任務,輸入為(問題x,解y,提示“該解是否正確?回答是或否”),輸出為“是/否”標記,避免引入額外分類頭或回歸層,降低結構復雜度。 - 超參數平衡:
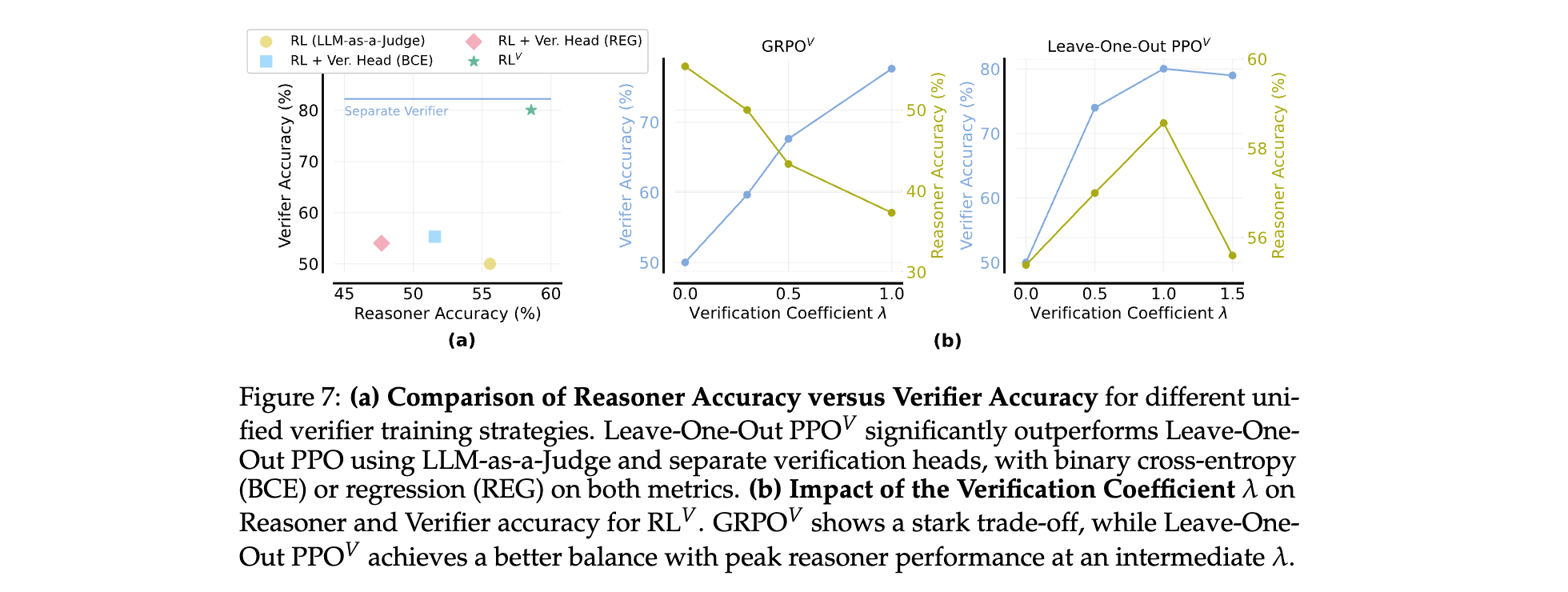
λ \lambda λ的取值影響推理與驗證能力的權衡。實驗表明,Leave-one-out PPO?在 λ = 1 \lambda=1 λ=1時達到最佳平衡,推理準確率(Pass@1)與驗證準確率(對正誤解的區分能力)均保持高位,而GRPO?因優化特性導致兩者存在顯著取舍。
3. 創新性技術組合
- 數據復用:
直接利用RL訓練中產生的解數據(無需額外標注),通過“生成-驗證”閉環實現數據高效利用,避免獨立驗證器所需的大規模標注成本。 - 輕量級驗證:
驗證過程與推理共享同一模型參數,無額外內存占用,推理時僅需一次前向傳播即可同時獲得解和驗證分數,相比獨立驗證器節省約50%計算資源。
- 實驗驗證:數據集與基線選擇
- 數據集:
- 數學推理:MATH(訓練)、MATH500、MATH2(難度泛化)、AIME’24(長序列推理)。
- 跨領域:GPQA Physics(物理問題,測試領域泛化)。
- 基線方法:
主流“無價值函數”RL方法,如GRPO、Leave-one-out PPO、VinePPO,對比時使用LLM-as-a-Judge(即直接提示基模型作為驗證器)或獨立驗證器作為基線驗證方案。
實驗洞察
1. 性能優勢:準確率與效率雙提升
- 并行采樣效果:
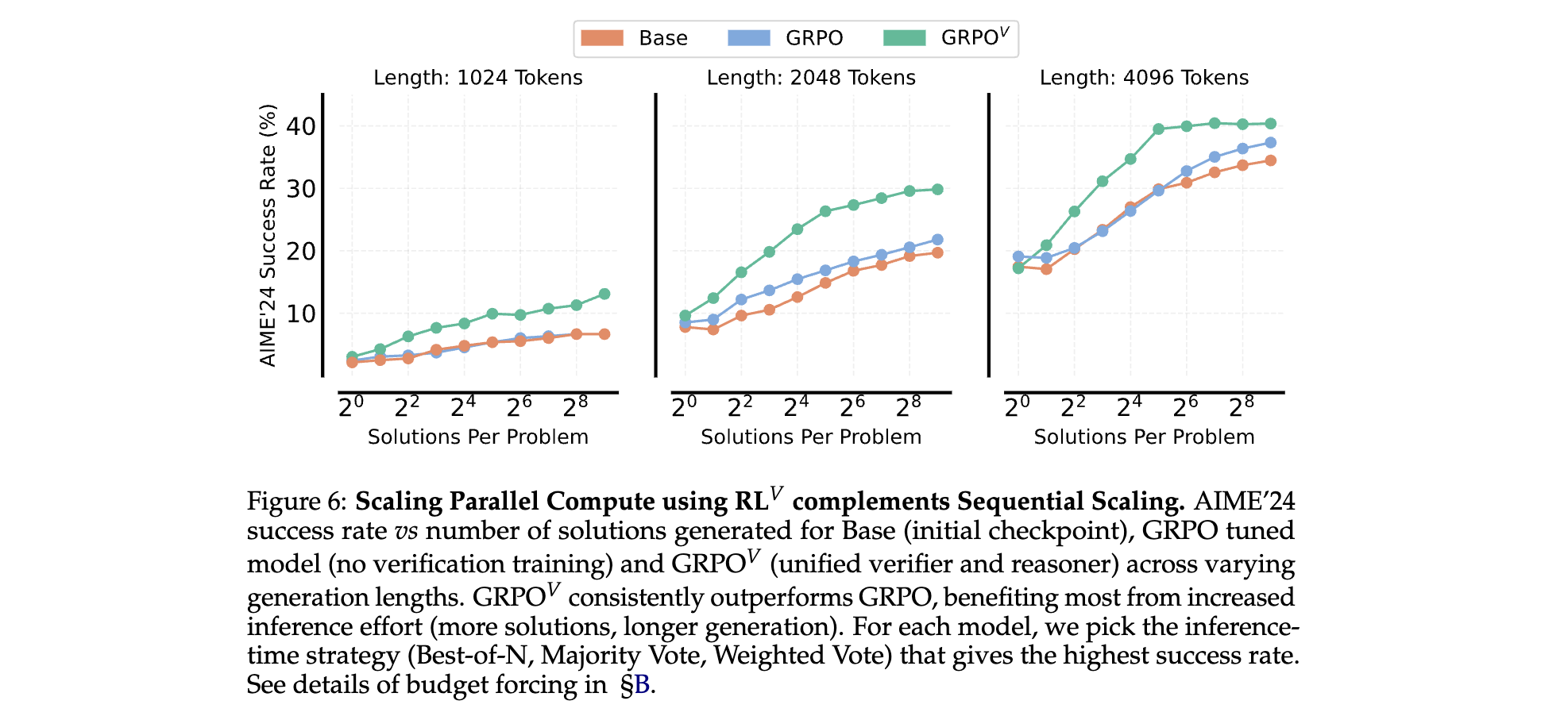
在MATH500上,當使用64個并行樣本時,RL?(GRPO?)的加權投票準確率達79.0%,遠超基線GRPO的55.6%,且計算效率提升32倍(即達到相同準確率所需計算量僅為基線的1/32)。 - 長序列推理:
在AIME’24數據集上,RL?(GRPO?)結合4096 token序列長度時,成功率比基線GRPO高15%,顯示其在處理復雜推理時的優勢。
2. 效率突破:計算資源的智能分配
- 動態序列長度優化:
通過設定驗證置信度閾值(如加權投票分數≥0.6),模型可自動為難題延長推理序列。例如,在AIME’24中,平均序列長度從1024 token增加到4096 token時,準確率從30%提升至40%,證明其按需分配計算資源的能力。 - 模型規模擴展性:
當模型從1.5B擴展至7B時,RL?的驗證準確率在MATH500上從76%提升至82%,加權投票準確率提升約5%,表明其性能隨模型規模增長而持續優化。
3. 消融研究:核心模塊的必要性驗證
- 統一訓練 vs. 獨立驗證器:
對比使用獨立驗證器(基于相同RL數據訓練)和RL?的統一驗證器,兩者驗證準確率接近(約80% vs. 78%),但RL?無需額外模型參數,內存占用減少50%以上。 - 驗證目標的形式:
對比二進制交叉熵(BCE)分類頭、回歸頭和生成式驗證(下一個標記預測),生成式驗證在推理準確率(Pass@1)和驗證準確率上均最優,表明利用LLM生成能力的有效性。
總結與展望
RL?通過將推理與驗證統一到單一LLM中,巧妙解決了傳統強化學習方法在測試階段的效率瓶頸,同時以近乎零成本增強了模型的泛化能力。其核心價值在于數據與計算資源的高效復用,為未來大模型的輕量化部署和復雜推理任務提供了新方向。
值得關注的是,論文提出的動態計算分配機制(如基于置信度的序列長度調整)為長上下文模型(如32K token模型)的優化提供了思路——通過驗證器實時評估推理進度,可避免無效的長序列生成,進一步提升計算效率。
未來研究方向可能包括:
- 擴展驗證器以生成思維鏈解釋(而非簡單“是/否”判斷),增強可解釋性;
- 探索RL?在代碼生成、科學推理等更廣泛領域的應用;
- 與更先進的并行采樣策略(如蒙特卡洛樹搜索)結合,進一步提升復雜任務的推理能力。








:頻域中的拉普拉斯算子)



![題解:P12207 [藍橋杯 2023 國 Python B] 劃分](http://pic.xiahunao.cn/題解:P12207 [藍橋杯 2023 國 Python B] 劃分)






