構建RAG混合開發---PythonAI+JavaEE+Vue.js前端的實踐-CSDN博客
服務容錯治理框架resilience4j&sentinel基礎應用---微服務的限流/熔斷/降級解決方案-CSDN博客
conda管理python環境-CSDN博客
快速搭建對象存儲服務 - Minio,并解決臨時地址暴露ip、短鏈接請求改變瀏覽器地址等問題-CSDN博客
大模型LLMs的MCP入門-CSDN博客
使用LangGraph構建多代理Agent、RAG-CSDN博客
大模型LLMs框架Langchain之鏈詳解_langchain.llms.base.llm詳解-CSDN博客
大模型LLMs基于Langchain+FAISS+Ollama/Deepseek/Qwen/OpenAI的RAG檢索方法以及優化_faiss ollamaembeddings-CSDN博客
大模型LLM基于PEFT的LoRA微調詳細步驟---第二篇:環境及其詳細流程篇-CSDN博客
大模型LLM基于PEFT的LoRA微調詳細步驟---第一篇:模型下載篇_vocab.json merges.txt資源文件下載-CSDN博客?使用docker-compose安裝Redis的主從+哨兵模式_使用docker部署redis 一主一從一哨兵模式 csdn-CSDN博客
docker-compose安裝canal并利用rabbitmq同步多個mysql數據_docker-compose canal-CSDN博客
目錄
寫在前文
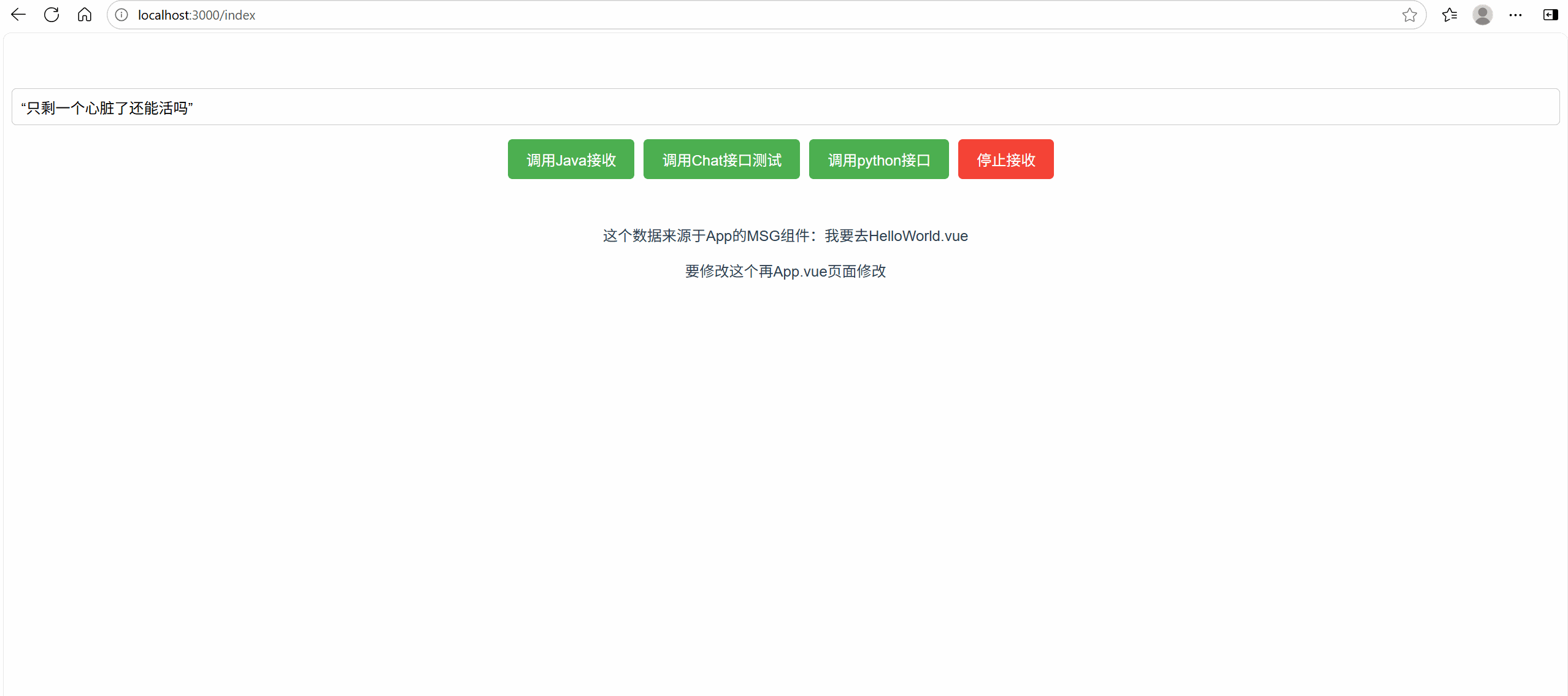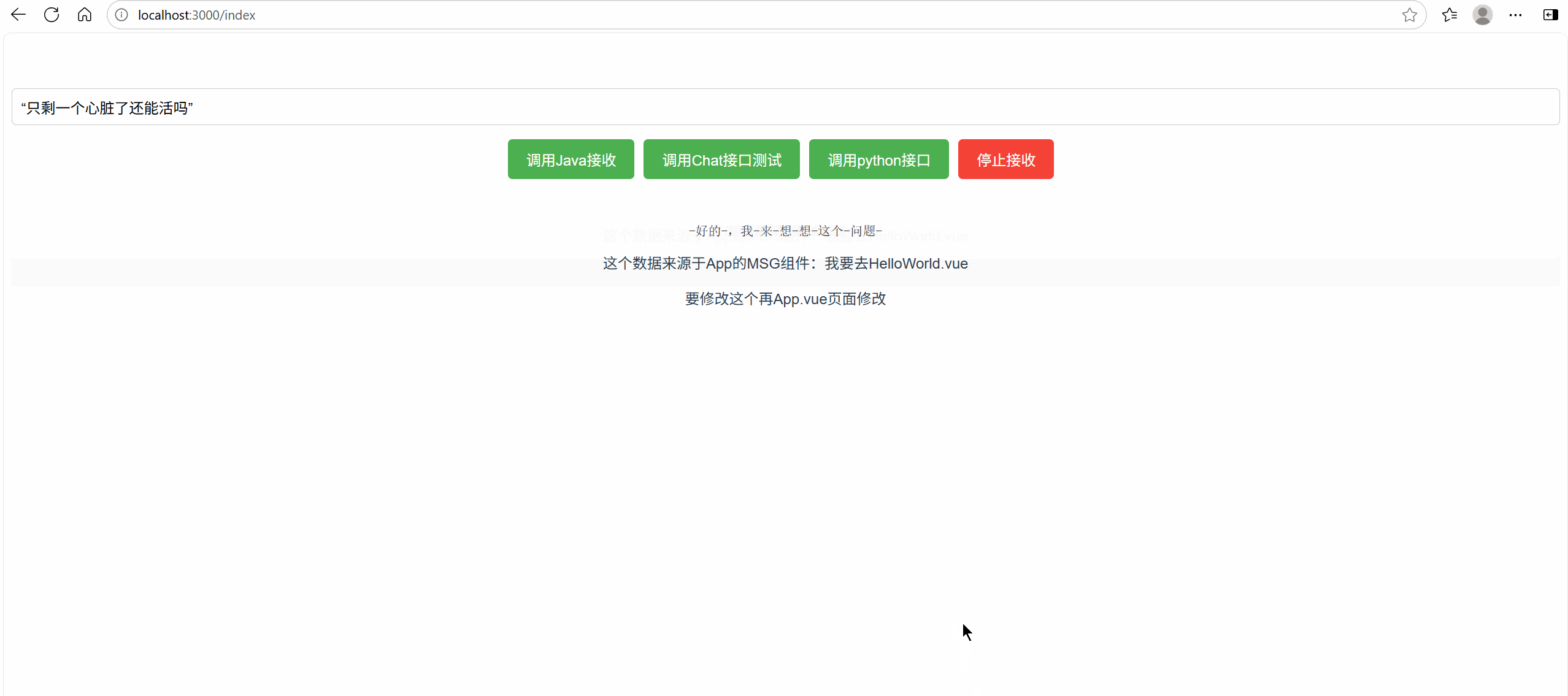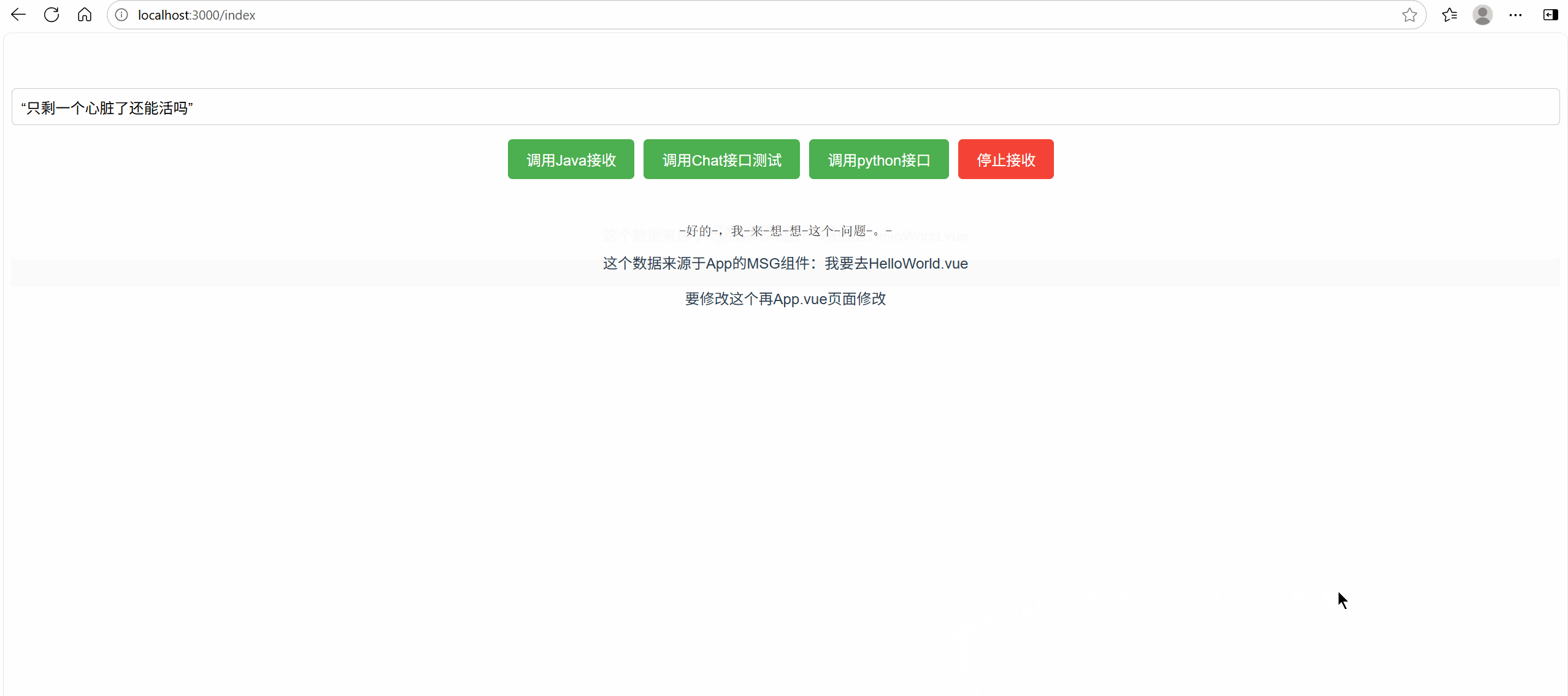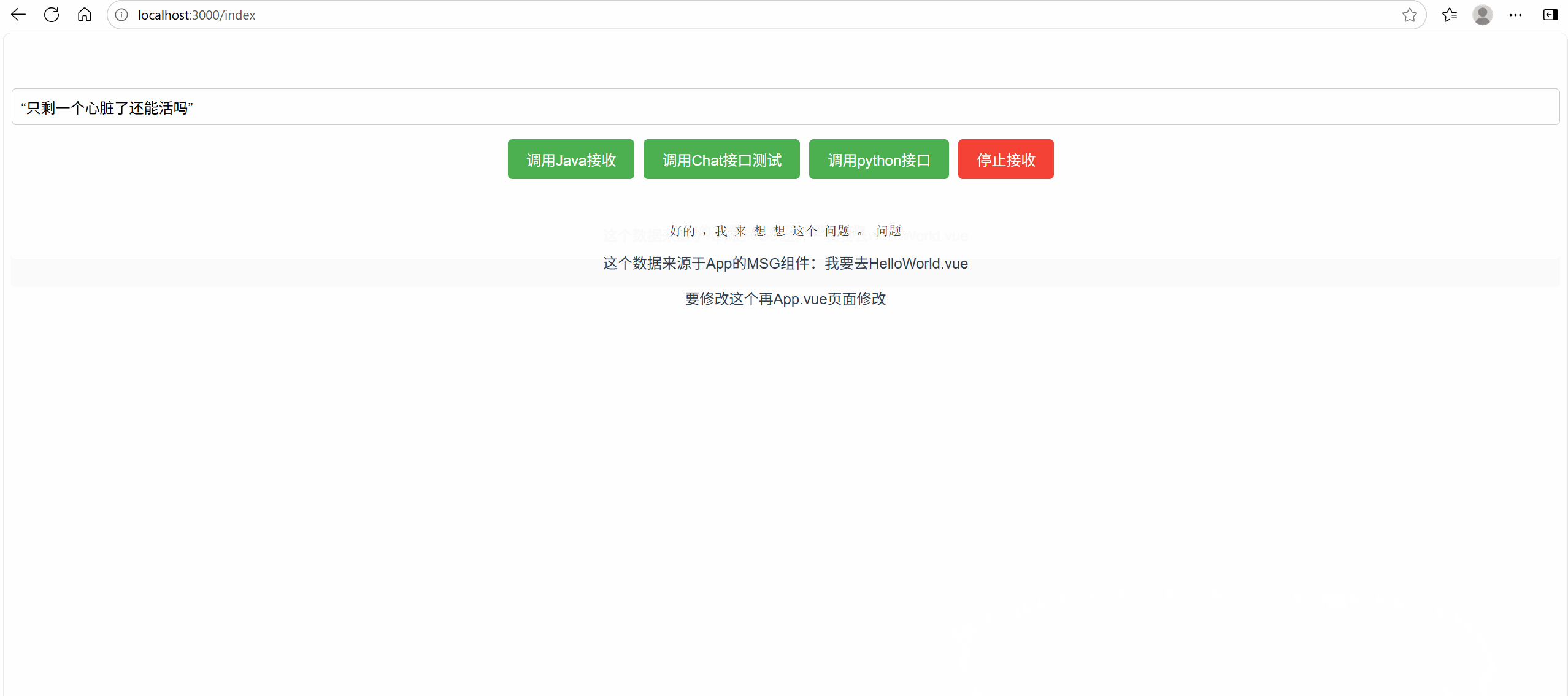
效果展示
輸出日志展示
內存使用情況
?編輯curl測試
?編輯?頁面請求流式效果
名詞解釋
顯存計算方法
技術體系
為什么選擇vLLM
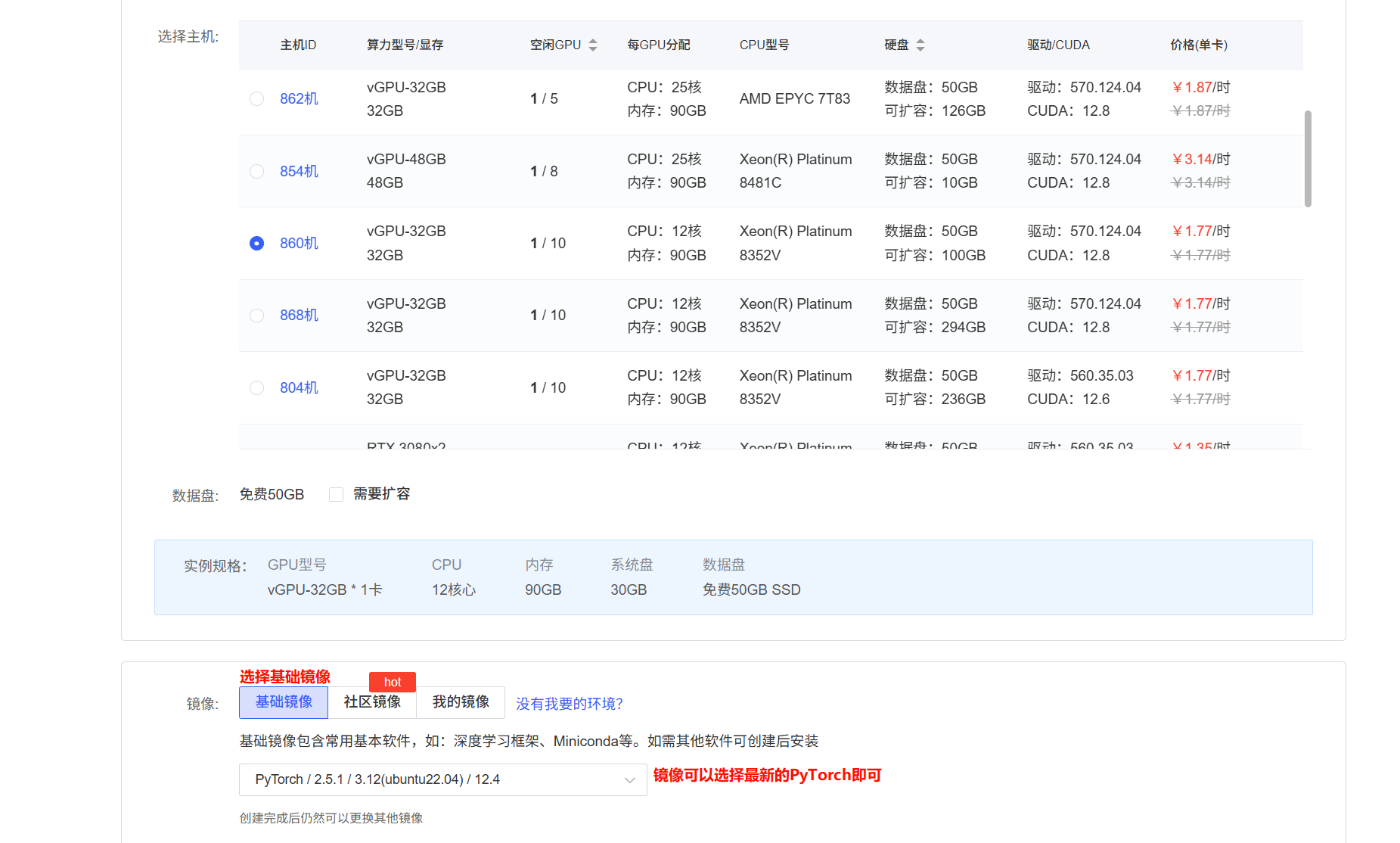
Step1:租用服務器
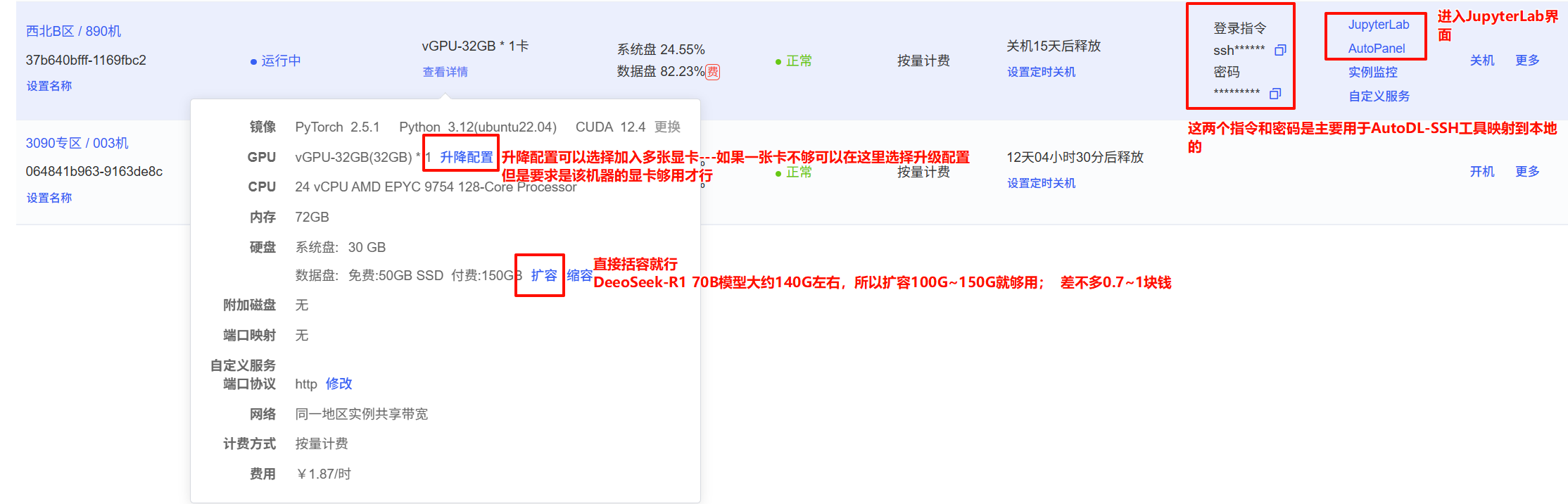
Step2、環境部署
擴容內存
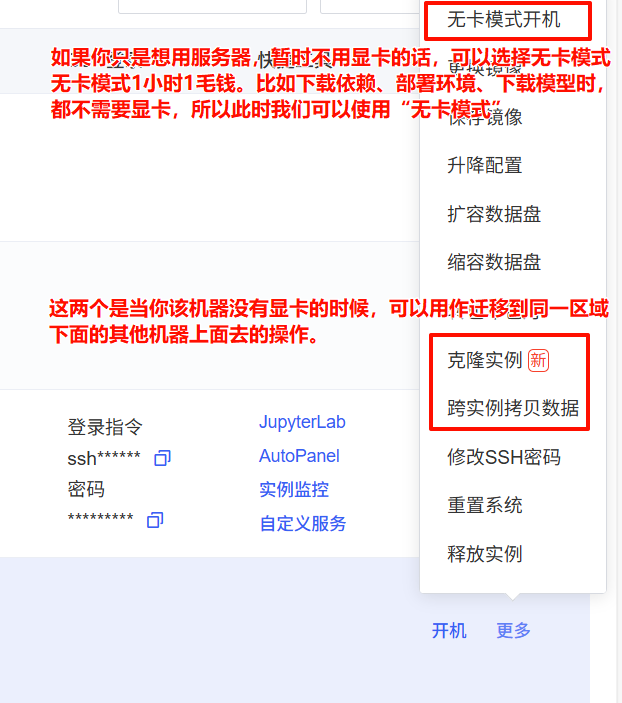
使用無卡模式啟動
更新/下載環境
Step3、下載模型
Step4、腳本參數
32GB顯存配置
7GB顯存的配置?
Step5、啟動
Step6、日志分析
正常日志
enforce-eager對性能的影響
?編輯?異常日志處理
CUDA out of memory.
KV緩存不夠(No available memory for the cache blocks)
?內存占用
寫在前文
以下在AutoDL算力云平臺的顯卡RTX3080 20G * 2 和?vGPU-32GB * 1測試通過;
---- 沒有用真正的7GB顯卡,用的是顯存32GB的服務器,但是通過“nvidia-smi- l 2”顯示顯存只用了7GB;
---- 想測試3090ti和4090的,沒找到合適的服務器...。
本文核心在于:在保持數值穩定性的前提下通過降低精度bfloat16將模型顯存需求降低50%,再執行INT4對稱量化,將模型體積壓縮至原始尺寸的25%(140G→35G),降低資源分配(通過犧牲一定的生成性能、推理速度、并發數、上下文token長度、生成token長度、每批次處理的序列長度等)將模型所需顯存極致壓縮,然后啟用vLLM PageAttention顯存管理引擎,實現顯存碎片率降低80%+,關閉CUDA Graph模式,解除計算圖固化約束,提升顯存復用靈活性。最后結合GPU-CPU交換空間,設置虛擬內存功能,大幅度降低對顯存的需求,以達到單機單卡7GB即可啟動DeepSeek-R1 70B 的大模型。
效果展示
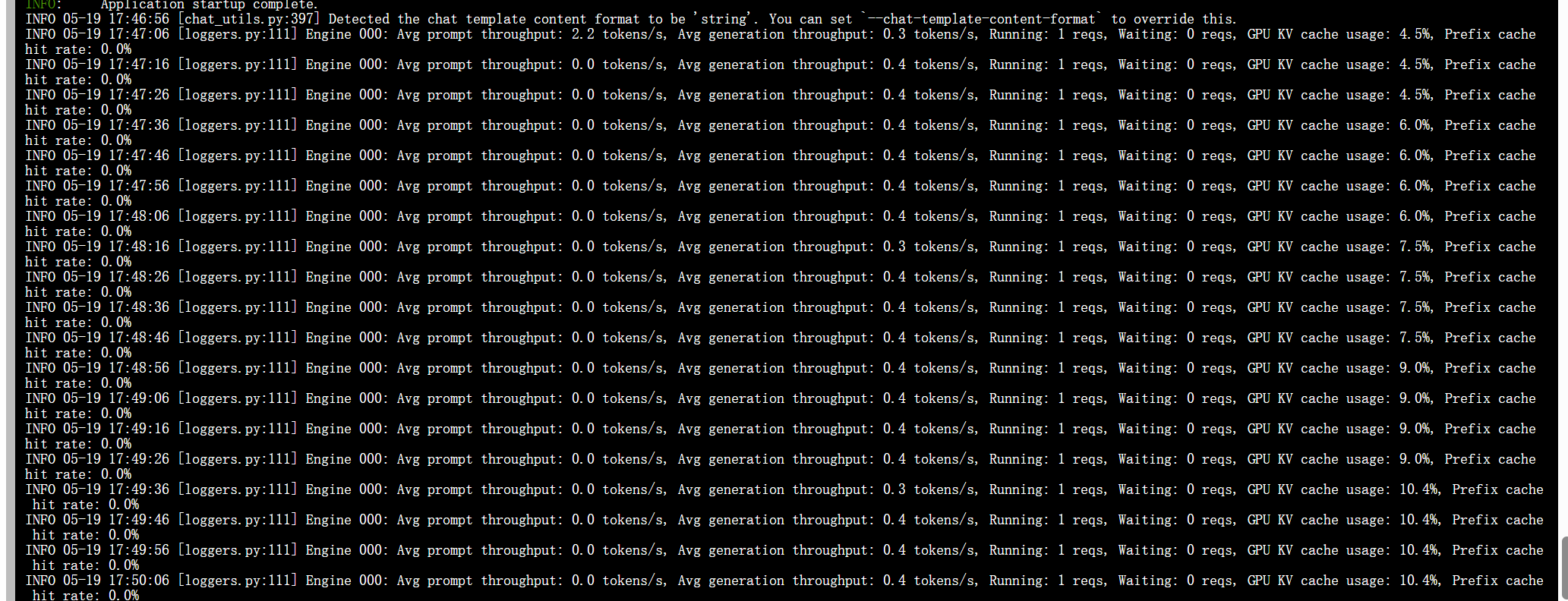
輸出日志展示
輸出token:0.4token/s,貌似有點慢~~~[😂,不過可以理解,畢竟只花了7GB顯存]
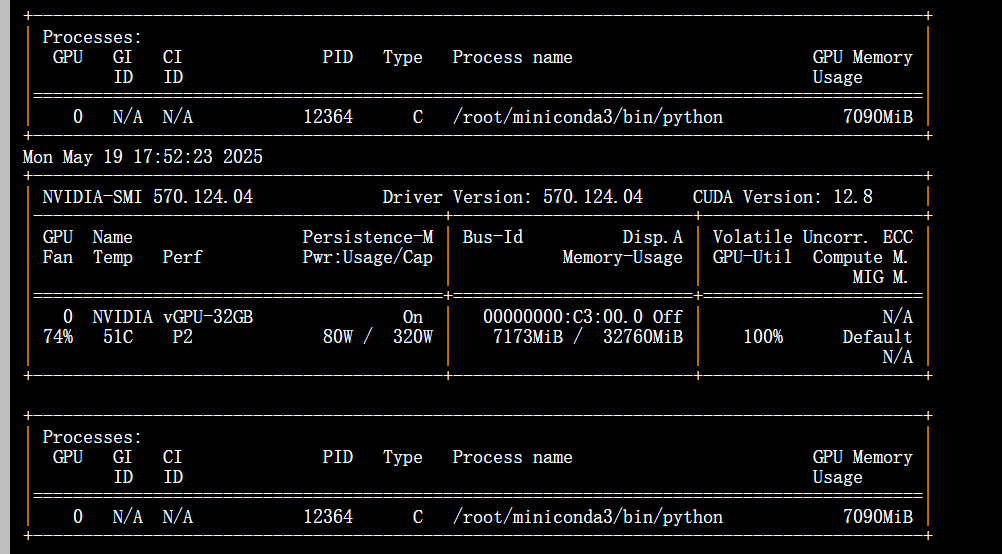
內存使用情況
curl測試
 ?頁面請求流式效果
?頁面請求流式效果
PS:真的好慢....自己玩玩就行了。理論是一樣的。
名詞解釋
DeepSeek-R1 70B FP16:
B:指billion,10億;70B即70*10=700億參數;
FP16,大模型精度是16精度,除了FP16以外還有雙精度(FP64)、單精度(FP32、TF32)、半精度(FP16、BF16)、8位精度(FP8)、4精度(FP4、NF4);量化精度(INT8、INT4)
- 32bit就是1位符號位+8位指數位+23位尾數位,可以表達6-7個有效的小數位;
- 而16bit可用bfloat16/float16,bfloat16,1位符號位+8位指數位+7位尾數位以犧牲位數位為代價指數位與32bit保持一致,避免在訓練時梯度溢出/下降(梯度爆炸);
- float16呢,就是1位符號位+5位指數位+10位尾數位,占用的內存都是32bit的一半;
- 而8bit、4bit就是將高精度的32bit通過一定算法(比如縮放因子、零點近似原數值等)映射到8bit/4bit上面;
- 而Q4量化,是Lora中對4bit量化中的一種方法;
顯存計算方法
1字節=8位,也就是說,
32bit精度的1參數代表4字節byte;16bit精度的1參數代表2byte;8bit精度的1參數代表1byte;4bit精度的1參數代表0.5byte;顯存1GB≈10億字節;
不采用任何優化的情況下,DeepSeek-R1所需要的顯存:
????????要部署完整的DeepSeek-R1 70B FP16精度或者4bit量化的話,FP16參數體積70*10*2byte=1400億字節=140GB,即顯存表面最低需140GB顯存,加上推理過程損耗(實際情況需要增加20~30%用于計算中間激活值 比如KV緩存等)以及不同模型版本FP16精度的不同,實際所需顯存一般需要在參數上面增加20~30%,實際顯存占用168~210G;
????????Q8參數體積70GB,顯存占用84~105GB;
????????Q4參數體積35GB,顯存占用42~42.5GB;
????????如果要用于微調/訓練,那么需要額外存儲優化器狀態、梯度、參數等信息,顯存可能超過3~4倍也就是400~600GB以上。????????
所以,如果我們在未優化的情況下,要部署一個DeepSeek-R1 70B模型的話,最低顯存都需要160G以上;但是我們可以通過4bit量化、PagedAttention、KV緩存、前綴緩存、虛擬/臨時內存等優化方法優化,后可以在32GB的內存上運行。
技術體系
云服務器AutoDL + 大模型DeepSeek-R1 70B + 推理框架vLLM + 量化框架bitsandbytes
為什么選擇vLLM
- vLLM專用于服務器-vLLM只有Linux版本,高吞吐量服務(性能較高、運行速度快)--很適合;
- 擁有量化功能:AWQ(一種量化方法)、FP8、INT4(采用bitsandbytes)
- 兼容OpenAI相關API --- 可以部署為服務器,像請求ChatGPT的API一樣請求,也可以流輸出;
- 支持緩存:前綴緩存、KV緩存
使用?PagedAttention?有效管理注意力鍵和值內存
可以一鍵配置張量并行/流水線并行計算,在單卡單節點壓力大的情況下,可以迅速切換多卡甚至多節點
.......
Step1:租用服務器
本文采用AutoDL算力云平臺;

Step2、環境部署
# 因為本文采用的模型是Deepseek-R1 70B模型,140G大小,所以需要擴容;
擴容內存
使用無卡模式啟動
更新/下載環境
1、查看python/pip版本
python --version
pip --version

2、更新pip
python -m pip install --upgrade pip
3、安裝依賴
pip install?modelscope vllm torch transformers[torch] bitsandbytes?
# 本文主要采用vllm推理框架和bitsandbytes量化方法;
#?modelscope是用來下載模型的。
下載完成,可以通過“vllm --version”查看vllm版本
4、下載SSH本地代理
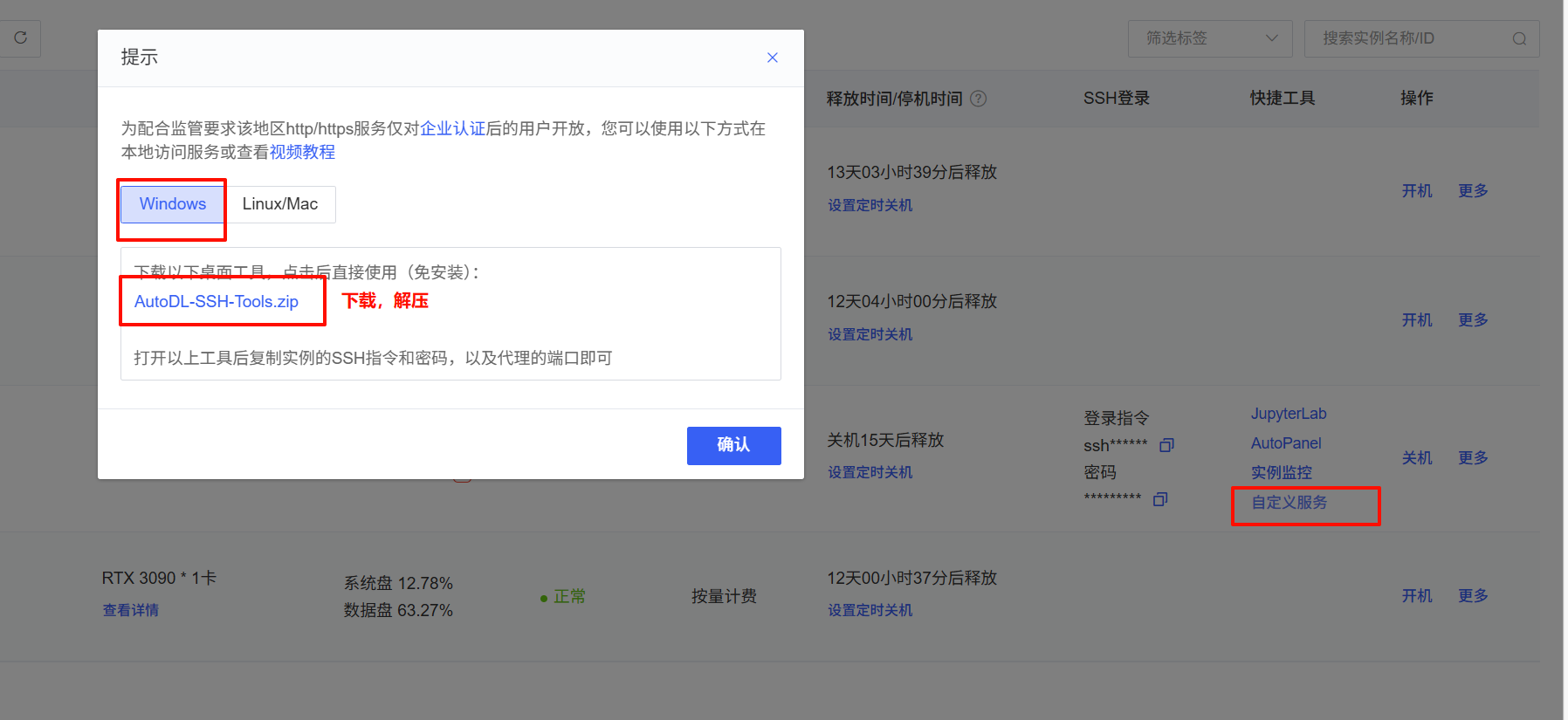
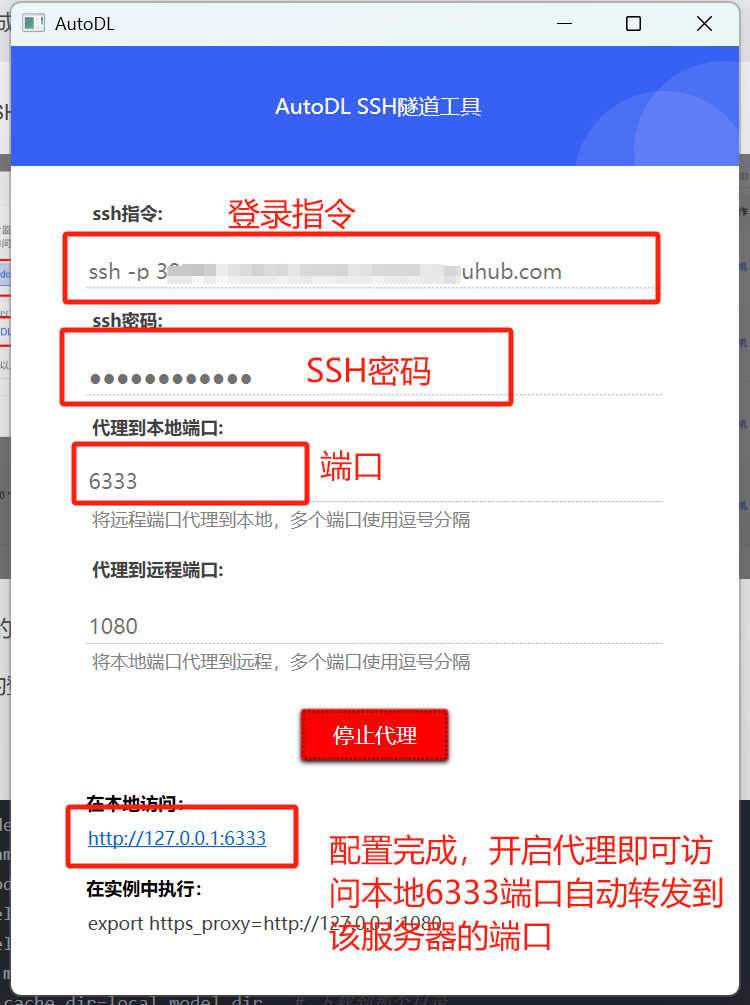
?啟動其中的AutoDL.exe;
Step3、下載模型
from modelscope import snapshot_download
model_names = ["deepseek-ai/DeepSeek-R1-Distill-Llama-70B"]
local_model_dir = r'/root/autodl-tmp/llms' # 自己指定要下載的目錄
for model_name in model_names:model_dir = snapshot_download(model_name, # 要下載的模型名稱cache_dir=local_model_dir, # 下載到那個目錄revision='master',ignore_file_pattern='.pth', # 配置過濾,不下載“.pth”的原始文件。只下載“.safetensors”的模型文件)print(f"{model_name} is downloaded to {model_dir}")剩下時間就是等待...
Step4、腳本參數
本文采用的是vllm的config結合.yaml的形式,將啟動參數保存在了一個文件中;
新建文件config.yaml,內容如下:
修改參數:dtype(模型數據類型)、quantization(量化類型)、cpu-offload-gb(虛擬內存,也可以把它看成臨時內存)、gpu-memory-utilization(預分配內存)、enforce-eager(是否使用混合模式);
其中核心通過定義“cpu-offload-gb”的大小,即主要作用于推理過程中 KV緩存和臨時張量的CPU交換空間。
當顯存使用超過 gpu-memory-utilization 閾值時,按 cpu-offload-gb 定義的最大值遷移KV緩存數據到CPU。
比如,我們cpu-offload-gb設置為10G,模型總顯存需要20G,其中KV緩存有10G,那么此時我們只需要一個10G顯存服務就可以啟動這個需要20G顯存的模型;
理論上講,我們要啟動DeepSeek-R1 70B模型的話,我們適當調整max-num-batched-tokens、max-model-len、swap-space、max-seq-len-to-capture、block-size結合cpu-offload-gb我們可以在顯存僅7GB的顯卡上運行---(我在vGPU32G,通過測試,實際顯存最低可以達到7173MB,也就是7G作左右顯存)
基礎參數:model、served-model-name、host、port、api-key,其余參數配置按需配置即可。
32GB顯存配置
# config.yaml
model: "/root/autodl-tmp/llms/deepseek-ai/DeepSeek-R1-Distill-Llama-70B"
served-model-name: "DeepSeek-R1" # API中要使用的名稱,如果不指定那么在通過API調用的時候必須是和“model”保持一致
host: "0.0.0.0" # host 0.0.0.0 \ # 服務器監聽的主機地址,0.0.0.0表示接受所有網絡接口的連接。
port: 6333
api-key: "ltingzx" # API密鑰,用于請求驗證,確保服務安全。
# 未開時/開啟bfloat16/half,29500M;開啟bitsandbytes--->850M;
# vLLM占用的內存由gpu-memory-utilization決定,所以無論如何我們設置dtype或者quantization時,系統都是“顯存*gpu-memory-utilization”的大小X
# 此時如果我們的max-model-len參數>X,會導致報錯;
dtype: "bfloat16"
quantization: "bitsandbytes" # 量化:加載時bitsandbytes、fp8;預訓練并且使用autoawq---要使用awq必須是awq預訓練完成的量化模型
gpu-memory-utilization: 0.9 # 降低顯存利用率閾值,默認0.9 --- 如果設置0.9,假如我們服務器32G*0.9=28.8G這個就是vLLM預分配的內存大小,無論模型多小,都會預分配;此時如果使用“nvidia-smi -l 2”查看,其中的“Memory-Usage”就是顯示的預分配大小;
cpu-offload-gb: 20 # 虛擬內存大小.每個 GPU 要卸載到 CPU 的空間 (GiB)。默認值為 0,表示不卸載
swap-space: 4 # 每個 GPU 的 CPU 交換空間大小.默認值4
max-num-seqs: 256 # 提高并發處理數(默認: 256).每次迭代的最大序列數pipeline-parallel-size: 1 #-pp:管道并行階段數,默認1 --- 即部署在多節點/服務器分布式推理時需要
tensor-parallel-size: 1 #-tp:張量并行副本數,默認1 --- 單節點/服務器上面有多張卡時需要,可以通過“nvidia-smi -L”查看
max-num-batched-tokens: 8192 # 單批次最大token數
max-model-len: 8192 # 模型上下文長度 --- 默認是4096,此時如果我們將gpu-memory-utilization設置太小,預分配小于參數的話比如4G(使用Qwen-7B測試時,將gpu-memory-utilization設置為0.2會報錯),那么會報錯
enable-prefix-caching: true # 啟用前綴緩存
block-size: 32 # KV緩存塊大小 (默認: 16---必須大余16).32減少內存碎片
max-seq-len-to-capture: 8192 # 匹配max-model-len(原4096 → 1024) 圖覆蓋的最大序列長度 默認8192
#kv-cache-dtype: fp8 # kv緩存的數據類型auto, fp8(CUDA 11.8+), fp8_e5m2(CUDA 11.8+), fp8_e4m3(AMD GPU)。默認采用和模型保持一致的類型。可能報錯“ERROR xxx [engine.py:448] AttributeError: 'Tensor' object has no attribute 'bnb_quant_state'”
#calculate-kv-scales: # 當 kv-cache-dtype 為 fp8 時,啟用 k_scale 和 v_scale 的動態計算。如果 calculate-kv-scales 為 false,則將從模型檢查點加載比例(如果可用)。否則,比例將默認為 1.0。enforce-eager: false # 默認False使用eager模式和CUDA圖的混合模式來執行操作,必須關閉以啟用PagedAttention。CUDA圖是PyTorch中用于優化性能的一種技術。 禁用CUDA圖(即設置 enforce_eager 為True)可能會影響性能,但可以減少內存需求
#max-parallel-loading-workers: #多批次順序加載模型時,并行加載工作器的最大數量。用于避免在使用張量并行和大型模型時出現 RAM OOM。
disable-custom-all-reduce: true # 禁用多GPU自定義通信,自定義AllReduce(減少多GPU顯存開銷)默認#uvicorn-log-level: "info"
#disable-log-stats: true # 禁用統計日志記錄。
disable-log-requests: true # 禁用請求日志記錄
trust-remote-code: true # 允許加載遠程代碼(來自Hugging Face等),對于某些特定模型可能需要。7GB顯存的配置?
# config.yaml
model: "xxxxxdeepseek-ai/DeepSeek-R1-Distill-Llama-70B"
served-model-name: "DeepSeek-R1" # API中要使用的名稱,如果不指定那么在通過API調用的時候必須是和“model”保持一致
host: "0.0.0.0" # host 0.0.0.0 \ # 服務器監聽的主機地址,0.0.0.0表示接受所有網絡接口的連接。
port: 6333
api-key: "xxxxx" # API密鑰,用于請求驗證,確保服務安全。
# 未開時/開啟bfloat16/half,29500M;開啟bitsandbytes--->850M;
# vLLM占用的內存由gpu-memory-utilization決定,所以無論如何我們設置dtype或者quantization時,系統都是“顯存*gpu-memory-utilization”的大小X
# 此時如果我們的max-model-len參數>X,會導致報錯;
dtype: "bfloat16"
quantization: "bitsandbytes" # 量化:加載時bitsandbytes、fp8;預訓練并且使用autoawq---要使用awq必須是awq預訓練完成的量化模型
gpu-memory-utilization: 0.25 # 降低顯存利用率閾值,默認0.9 --- 如果設置0.9,假如我們服務器32G*0.9=28.8G這個就是vLLM預分配的內存大小,無論模型多小,都會預分配;此時如果使用“nvidia-smi -l 2”查看,其中的“Memory-Usage”就是顯示的預分配大小;
cpu-offload-gb: 60 # 虛擬內存大小.每個 GPU 要卸載到 CPU 的空間 (GiB)。默認值為 0,表示不卸載
swap-space: 20 # 每個 GPU 的 CPU 交換空間大小.默認值4
max-num-seqs: 8 # 提高并發處理數(默認: 256).每次迭代的最大序列數pipeline-parallel-size: 1 #-pp:管道并行階段數,默認1 --- 即部署在多節點/服務器分布式推理時需要
tensor-parallel-size: 1 #-tp:張量并行副本數,默認1 --- 單節點/服務器上面有多張卡時需要,可以通過“nvidia-smi -L”查看
max-num-batched-tokens: 512 # 單批次最大token數
max-model-len: 512 # 模型上下文長度 --- 默認是4096,此時如果我們將gpu-memory-utilization設置太小,預分配小于參數的話比如4G(使用Qwen-7B測試時,將gpu-memory-utilization設置為0.2會報錯),那么會報錯
enable-prefix-caching: true # 啟用前綴緩存
block-size: 16 # KV緩存塊大小 (默認: 16---必須大余16).32減少內存碎片
max-seq-len-to-capture: 512 # 匹配max-model-len(原4096 → 1024) 圖覆蓋的最大序列長度 默認8192
#kv-cache-dtype: fp8 # kv緩存的數據類型auto, fp8(CUDA 11.8+), fp8_e5m2(CUDA 11.8+), fp8_e4m3(AMD GPU)。默認采用和模型保持一致的類型。可能報錯“ERROR xxx [engine.py:448] AttributeError: 'Tensor' object has no attribute 'bnb_quant_state'”
#calculate-kv-scales: # 當 kv-cache-dtype 為 fp8 時,啟用 k_scale 和 v_scale 的動態計算。如果 calculate-kv-scales 為 false,則將從模型檢查點加載比例(如果可用)。否則,比例將默認為 1.0。enforce-eager: true # 默認False使用eager模式和CUDA圖的混合模式來執行操作,必須關閉以啟用PagedAttention。CUDA圖是PyTorch中用于優化性能的一種技術。 禁用CUDA圖(即設置 enforce_eager 為True)可能會影響性能,但可以減少內存需求
#max-parallel-loading-workers: #多批次順序加載模型時,并行加載工作器的最大數量。用于避免在使用張量并行和大型模型時出現 RAM OOM。
disable-custom-all-reduce: true # 禁用多GPU自定義通信,自定義AllReduce(減少多GPU顯存開銷)默認#uvicorn-log-level: "info"
#disable-log-stats: true # 禁用統計日志記錄。
disable-log-requests: true # 禁用請求日志記錄
trust-remote-code: true # 允許加載遠程代碼(來自Hugging Face等),對于某些特定模型可能需要。參數詳解
基本配置
- --host HOST: 指定服務器主機名。
- --port PORT: 指定服務器端口號。
- --uvicorn-log-level {debug,info,warning,error,critical,trace}: 設置 Uvicorn 的日志級別。
- --allow-credentials: 允許跨域請求時攜帶憑證。
- --allowed-origins ALLOWED_ORIGINS: 允許跨域請求的來源。
- --allowed-methods ALLOWED_METHODS: 允許跨域請求的方法。
- --allowed-headers ALLOWED_HEADERS: 允許跨域請求的頭部。
- --api-key API_KEY: 如果提供,該服務器將要求在請求頭中提供此密鑰。
模型配置
- --served-model-name SERVED_MODEL_NAME: API 使用的模型名稱。如果未指定,則默認為 Hugging Face 模型名稱。
- --model MODEL: 使用的 Hugging Face 模型名稱或路徑。
- --tokenizer TOKENIZER: 使用的 Hugging Face 分詞器名稱或路徑。
- --revision REVISION: 使用的特定模型版本(分支名、標簽名或提交 ID)。若未指定,將使用默認版本。
- --code-revision CODE_REVISION: 使用 Hugging Face Hub 上的特定模型代碼版本。
- --tokenizer-revision TOKENIZER_REVISION: 使用的特定分詞器版本(分支名、標簽名或提交 ID)。
- --tokenizer-mode {auto,slow}: 分詞器模式。"auto" 使用快速分詞器(如有),"slow" 始終使用慢速分詞器。
- --trust-remote-code: 信任 Hugging Face 遠程代碼。
模型加載和量化
- --download-dir DOWNLOAD_DIR: 下載和加載權重的目錄,默認為 Hugging Face 默認緩存目錄。
- --load-format {auto,pt,safetensors,npcache,dummy}: 模型權重的加載格式。 "auto" 嘗試使用 safetensors 格式加載權重,如果不可用則回退到 pytorch bin 格式。
- --dtype {auto,half,float16,bfloat16,float,float32}: 模型權重和激活的數據類型。"auto" 對于 FP32 和 FP16 模型使用 FP16 精度,對于 BF16 模型使用 BF16 精度。
- --kv-cache-dtype {auto,fp8_e5m2}: 鍵值緩存存儲的數據類型。 "auto" 使用模型數據類型。注意,FP8 僅在 CUDA 版本高于 11.8 時支持。
- --max-model-len MAX_MODEL_LEN: 模型上下文長度。如果未指定,將自動從模型中推導。
性能優化
- --pipeline-parallel-size PIPELINE_PARALLEL_SIZE, -pp PIPELINE_PARALLEL_SIZE: 管道并行階段的數量。
- --tensor-parallel-size TENSOR_PARALLEL_SIZE, -tp TENSOR_PARALLEL_SIZE: 張量并行副本的數量。
- --max-parallel-loading-workers MAX_PARALLEL_LOADING_WORKERS: 使用多個批次順序加載模型,以避免使用張量并行和大模型時的內存不足。
- --gpu-memory-utilization GPU_MEMORY_UTILIZATION: 模型執行器使用的 GPU 內存百分比,范圍為 0 到 1。若未指定,將使用默認值 0.9。
- --swap-space SWAP_SPACE: 每個 GPU 的 CPU 交換空間大小(以 GiB 為單位)。
- --block-size {8,16,32,128}: 令牌塊大小。
- --max-num-batched-tokens MAX_NUM_BATCHED_TOKENS: 每次迭代的最大批處理令牌數。
- --max-num-seqs MAX_NUM_SEQS: 每次迭代的最大序列數。
- --max-logprobs MAX_LOGPROBS: 返回的最大日志概率數量。
SSL 配置
- --ssl-keyfile SSL_KEYFILE: SSL 密鑰文件的路徑。
- --ssl-certfile SSL_CERTFILE: SSL 證書文件的路徑。
- --ssl-ca-certs SSL_CA_CERTS: CA 證書文件。
- --ssl-cert-reqs SSL_CERT_REQS: 是否需要客戶端證書(參見標準庫的 SSL 模塊)。
其他配置
- --root-path ROOT_PATH: 在基于路徑的路由代理后面時使用的 FastAPI 根路徑。
- --middleware MIDDLEWARE: 應用到應用程序的額外 ASGI 中間件。可以接受多個 --middleware 參數,值應為導入路徑。
- --max-log-len MAX_LOG_LEN: 日志中打印的最大提示字符或提示 ID 數量,默認無限制。
- --enable-prefix-caching: 啟用自動前綴緩存。
- --use-v2-block-manager: 使用 BlockSpaceMangerV2。
- --num-lookahead-slots NUM_LOOKAHEAD_SLOTS: 實驗性調度配置,必要時進行投機解碼。
分布式和異步配置
- --worker-use-ray: 使用 Ray 進行分布式服務,當使用超過 1 個 GPU 時將自動設置。
- --engine-use-ray: 使用 Ray 在單獨的進程中啟動 LLM 引擎。
- --ray-workers-use-nsight: 如果指定,使用 nsight 對 Ray 工作者進行分析。
- --max-cpu-loras MAX_CPU_LORAS: 存儲在 CPU 內存中的最大 LoRAs 數量。必須 >= max_num_seqs,默認為 max_num_seqs。
- --device {auto,cuda,neuron,cpu}: vLLM 執行的設備類型。
- --enable-lora: 如果為 True,啟用 LoRA 適配器處理。
圖像輸入配置
- --image-input-type {pixel_values,image_features}: 傳遞給 vLLM 的圖像輸入類型,應為 "pixel_values" 或 "image_features"。
- --image-token-id IMAGE_TOKEN_ID: 圖像令牌的輸入 ID。
- --image-input-shape IMAGE_INPUT_SHAPE: 給定輸入類型的最大圖像輸入形狀(最差內存占用),僅用于 vLLM 的 profile_run。
- --image-feature-size IMAGE_FEATURE_SIZE: 沿上下文維度的圖像特征大小。
Step5、啟動
監控內存:nvidia-smi -l 2
下面是32GB版本
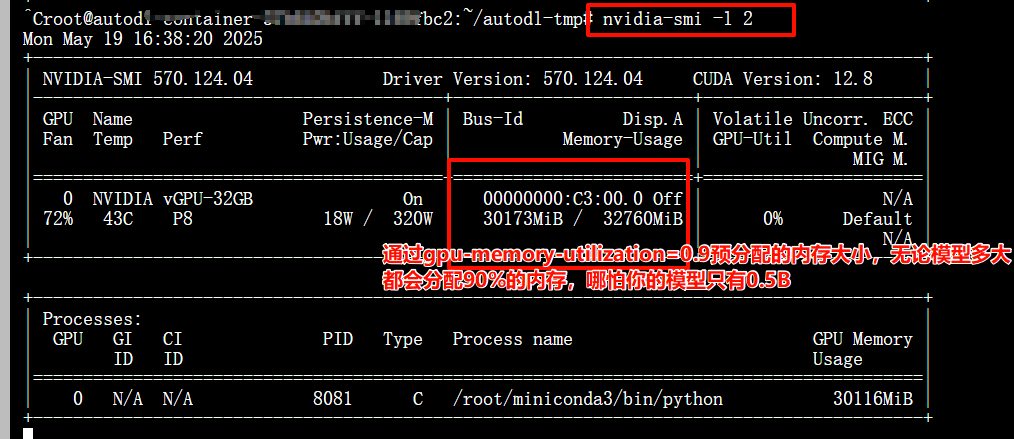
正式啟動:vllm serve --config config.yaml
啟動成功后可以直接使用:
查看啟動模型的信息:curl -X GET "http://localhost:端口/v1/models" -H "Authorization: Bearer config中設置的api-key"
完成會話:
curl -X POST "http://localhost:6333/v1/chat/completions" \-H "Authorization: Bearer ltingzx" \-H "Content-Type: application/json" \-d '{"model": "DeepSeek-R1","messages": [{"role": "system", "content": "你是一個機器人,名字叫“小花”"},{"role": "user", "content": "你叫啥?"}]}'
? ? ? 網頁版本:見我上一篇“構建RAG混合開發---PythonAI+JavaEE+Vue.js前端的實踐-CSDN博客”修改Python項目中的self.llm如下即可
self.llm = ChatOpenAI(
? ? ? ? ? ? model='DeepSeek-R1---啟動配置中的served-model-name名稱,不然要和model保持一致',
? ? ? ? ? ? api_key='xxxx',
? ? ? ? ? ? base_url='http://localhost:6333/v1---需要本地代理',
? ? ? ? )
Step6、日志分析
正常日志
INFO 05-16 23:06:03 [__init__.py:239] Automatically detected platform cuda.
INFO 05-16 23:06:07 [api_server.py:1043] vLLM API server version 0.8.5.post1
INFO 05-16 23:06:07 [api_server.py:1044] args: Namespace(subparser='serve', model_tag=None, config='', host='0.0.0.0', port=6333, uvicorn_log_level='info', disable_uvicorn_access_log=False, allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], api_key='ltingzx', lora_modules=None, prompt_adapters=None, chat_template=None, chat_template_content_format='auto', response_role='assistant', ssl_keyfile=None, ssl_certfile=None, ssl_ca_certs=None, enable_ssl_refresh=False, ssl_cert_reqs=0, root_path=None, middleware=[], return_tokens_as_token_ids=False, disable_frontend_multiprocessing=False, enable_request_id_headers=False, enable_auto_tool_choice=False, tool_call_parser=None, tool_parser_plugin='', model='/root/autodl-tmp/llms/Qwen/Qwen3-8B', task='auto', tokenizer=None, hf_config_path=None, skip_tokenizer_init=False, revision=None, code_revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=True, allowed_local_media_path=None, load_format='auto', download_dir=None, model_loader_extra_config={}, use_tqdm_on_load=True, config_format=<ConfigFormat.AUTO: 'auto'>, dtype='auto', max_model_len=4096, guided_decoding_backend='auto', reasoning_parser=None, logits_processor_pattern=None, model_impl='auto', distributed_executor_backend=None, pipeline_parallel_size=1, tensor_parallel_size=2, data_parallel_size=1, enable_expert_parallel=False, max_parallel_loading_workers=None, ray_workers_use_nsight=False, disable_custom_all_reduce=False, block_size=32, gpu_memory_utilization=0.5, swap_space=4.0, kv_cache_dtype='auto', num_gpu_blocks_override=None, enable_prefix_caching=None, prefix_caching_hash_algo='builtin', cpu_offload_gb=5.0, calculate_kv_scales=False, disable_sliding_window=False, use_v2_block_manager=True, seed=None, max_logprobs=20, disable_log_stats=False, quantization=None, rope_scaling=None, rope_theta=None, hf_token=None, hf_overrides=None, enforce_eager=True, max_seq_len_to_capture=8192, tokenizer_pool_size=0, tokenizer_pool_type='ray', tokenizer_pool_extra_config={}, limit_mm_per_prompt={}, mm_processor_kwargs=None, disable_mm_preprocessor_cache=False, enable_lora=None, enable_lora_bias=False, max_loras=1, max_lora_rank=16, lora_extra_vocab_size=256, lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=None, fully_sharded_loras=False, enable_prompt_adapter=None, max_prompt_adapters=1, max_prompt_adapter_token=0, device='auto', speculative_config=None, ignore_patterns=[], served_model_name=['Qwen3-8B'], qlora_adapter_name_or_path=None, show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, disable_async_output_proc=False, max_num_batched_tokens=4096, max_num_seqs=256, max_num_partial_prefills=1, max_long_partial_prefills=1, long_prefill_token_threshold=0, num_lookahead_slots=0, scheduler_delay_factor=0.0, preemption_mode=None, num_scheduler_steps=1, multi_step_stream_outputs=True, scheduling_policy='fcfs', enable_chunked_prefill=None, disable_chunked_mm_input=False, scheduler_cls='vllm.core.scheduler.Scheduler', override_neuron_config=None, override_pooler_config=None, compilation_config=None, kv_transfer_config=None, worker_cls='auto', worker_extension_cls='', generation_config='auto', override_generation_config=None, enable_sleep_mode=False, additional_config=None, enable_reasoning=False, disable_cascade_attn=False, disable_log_requests=True, max_log_len=None, disable_fastapi_docs=False, enable_prompt_tokens_details=False, enable_server_load_tracking=False, dispatch_function=<function ServeSubcommand.cmd at 0x7f36272bfce0>)
INFO 05-16 23:06:14 [config.py:717] This model supports multiple tasks: {'reward', 'score', 'generate', 'embed', 'classify'}. Defaulting to 'generate'.
INFO 05-16 23:06:14 [config.py:1770] Defaulting to use mp for distributed inference
INFO 05-16 23:06:14 [config.py:2003] Chunked prefill is enabled with max_num_batched_tokens=4096.
WARNING 05-16 23:06:14 [cuda.py:93] To see benefits of async output processing, enable CUDA graph. Since, enforce-eager is enabled, async output processor cannot be used
INFO 05-16 23:06:18 [__init__.py:239] Automatically detected platform cuda.
INFO 05-16 23:06:21 [core.py:58] Initializing a V1 LLM engine (v0.8.5.post1) with config: model='/root/autodl-tmp/llms/Qwen/Qwen3-8B', speculative_config=None, tokenizer='/root/autodl-tmp/llms/Qwen/Qwen3-8B', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=True, dtype=torch.bfloat16, max_seq_len=4096, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=2, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=True, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='auto', reasoning_backend=None), observability_config=ObservabilityConfig(show_hidden_metrics=False, otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=None, served_model_name=Qwen3-8B, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=True, chunked_prefill_enabled=True, use_async_output_proc=False, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"splitting_ops":[],"compile_sizes":[],"cudagraph_capture_sizes":[],"max_capture_size":0}
INFO 05-16 23:06:21 [shm_broadcast.py:266] vLLM message queue communication handle: Handle(local_reader_ranks=[0, 1], buffer_handle=(2, 10485760, 10, 'psm_49a90570'), local_subscribe_addr='ipc:///tmp/faa9cb44-6d06-4d89-9862-759b0f3d52d4', remote_subscribe_addr=None, remote_addr_ipv6=False)
INFO 05-16 23:06:25 [__init__.py:239] Automatically detected platform cuda.
INFO 05-16 23:06:25 [__init__.py:239] Automatically detected platform cuda.
WARNING 05-16 23:06:28 [utils.py:2522] Methods determine_num_available_blocks,device_config,get_cache_block_size_bytes,initialize_cache not implemented in <vllm.v1.worker.gpu_worker.Worker object at 0x7f761b89d880>
(VllmWorker rank=0 pid=2874) INFO 05-16 23:06:28 [shm_broadcast.py:266] vLLM message queue communication handle: Handle(local_reader_ranks=[0], buffer_handle=(1, 10485760, 10, 'psm_9435994d'), local_subscribe_addr='ipc:///tmp/ad5dbedf-8abd-4e6c-94c3-094c812f8cf0', remote_subscribe_addr=None, remote_addr_ipv6=False)
WARNING 05-16 23:06:29 [utils.py:2522] Methods determine_num_available_blocks,device_config,get_cache_block_size_bytes,initialize_cache not implemented in <vllm.v1.worker.gpu_worker.Worker object at 0x7f6f9e1a0770>
(VllmWorker rank=1 pid=2875) INFO 05-16 23:06:29 [shm_broadcast.py:266] vLLM message queue communication handle: Handle(local_reader_ranks=[0], buffer_handle=(1, 10485760, 10, 'psm_33628a58'), local_subscribe_addr='ipc:///tmp/bd547b68-a9d8-4798-9c36-144250db6a30', remote_subscribe_addr=None, remote_addr_ipv6=False)
(VllmWorker rank=1 pid=2875) INFO 05-16 23:06:29 [utils.py:1055] Found nccl from library libnccl.so.2
(VllmWorker rank=1 pid=2875) INFO 05-16 23:06:29 [pynccl.py:69] vLLM is using nccl==2.21.5
(VllmWorker rank=0 pid=2874) INFO 05-16 23:06:29 [utils.py:1055] Found nccl from library libnccl.so.2
(VllmWorker rank=0 pid=2874) INFO 05-16 23:06:29 [pynccl.py:69] vLLM is using nccl==2.21.5
(VllmWorker rank=0 pid=2874) INFO 05-16 23:06:29 [custom_all_reduce_utils.py:244] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1.json
(VllmWorker rank=1 pid=2875) INFO 05-16 23:06:29 [custom_all_reduce_utils.py:244] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1.json
(VllmWorker rank=0 pid=2874) WARNING 05-16 23:06:29 [custom_all_reduce.py:146] Custom allreduce is disabled because your platform lacks GPU P2P capability or P2P test failed. To silence this warning, specify disable_custom_all_reduce=True explicitly.
(VllmWorker rank=1 pid=2875) WARNING 05-16 23:06:29 [custom_all_reduce.py:146] Custom allreduce is disabled because your platform lacks GPU P2P capability or P2P test failed. To silence this warning, specify disable_custom_all_reduce=True explicitly.
(VllmWorker rank=0 pid=2874) INFO 05-16 23:06:29 [shm_broadcast.py:266] vLLM message queue communication handle: Handle(local_reader_ranks=[1], buffer_handle=(1, 4194304, 6, 'psm_42d23171'), local_subscribe_addr='ipc:///tmp/f32d862a-0a6a-4675-864d-01e99cc7dac8', remote_subscribe_addr=None, remote_addr_ipv6=False)
(VllmWorker rank=0 pid=2874) INFO 05-16 23:06:29 [parallel_state.py:1004] rank 0 in world size 2 is assigned as DP rank 0, PP rank 0, TP rank 0
(VllmWorker rank=1 pid=2875) INFO 05-16 23:06:29 [parallel_state.py:1004] rank 1 in world size 2 is assigned as DP rank 0, PP rank 0, TP rank 1
(VllmWorker rank=0 pid=2874) INFO 05-16 23:06:29 [cuda.py:221] Using Flash Attention backend on V1 engine.
(VllmWorker rank=1 pid=2875) INFO 05-16 23:06:29 [cuda.py:221] Using Flash Attention backend on V1 engine.
(VllmWorker rank=0 pid=2874) WARNING 05-16 23:06:29 [topk_topp_sampler.py:69] FlashInfer is not available. Falling back to the PyTorch-native implementation of top-p & top-k sampling. For the best performance, please install FlashInfer.
(VllmWorker rank=1 pid=2875) WARNING 05-16 23:06:29 [topk_topp_sampler.py:69] FlashInfer is not available. Falling back to the PyTorch-native implementation of top-p & top-k sampling. For the best performance, please install FlashInfer.
(VllmWorker rank=1 pid=2875) INFO 05-16 23:06:29 [gpu_model_runner.py:1329] Starting to load model /root/autodl-tmp/llms/Qwen/Qwen3-8B...
(VllmWorker rank=0 pid=2874) INFO 05-16 23:06:29 [gpu_model_runner.py:1329] Starting to load model /root/autodl-tmp/llms/Qwen/Qwen3-8B...
Loading safetensors checkpoint shards: 0% Completed | 0/5 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 20% Completed | 1/5 [00:00<00:01, 2.86it/s]
Loading safetensors checkpoint shards: 40% Completed | 2/5 [00:00<00:01, 2.18it/s]
Loading safetensors checkpoint shards: 60% Completed | 3/5 [00:01<00:00, 2.00it/s]
Loading safetensors checkpoint shards: 80% Completed | 4/5 [00:01<00:00, 2.08it/s]
Loading safetensors checkpoint shards: 100% Completed | 5/5 [00:02<00:00, 2.58it/s]
Loading safetensors checkpoint shards: 100% Completed | 5/5 [00:02<00:00, 2.37it/s]
(VllmWorker rank=0 pid=2874)
(VllmWorker rank=0 pid=2874) INFO 05-16 23:06:35 [loader.py:458] Loading weights took 2.16 seconds
(VllmWorker rank=0 pid=2874) INFO 05-16 23:06:35 [gpu_model_runner.py:1347] Model loading took 2.6077 GiB and 5.417584 seconds
(VllmWorker rank=1 pid=2875) INFO 05-16 23:06:35 [loader.py:458] Loading weights took 2.37 seconds
(VllmWorker rank=1 pid=2875) INFO 05-16 23:06:35 [gpu_model_runner.py:1347] Model loading took 2.6077 GiB and 5.831182 seconds
INFO 05-16 23:06:53 [kv_cache_utils.py:634] GPU KV cache size: 79,040 tokens
INFO 05-16 23:06:53 [kv_cache_utils.py:637] Maximum concurrency for 4,096 tokens per request: 19.30x
INFO 05-16 23:06:53 [kv_cache_utils.py:634] GPU KV cache size: 79,040 tokens
INFO 05-16 23:06:53 [kv_cache_utils.py:637] Maximum concurrency for 4,096 tokens per request: 19.30x
INFO 05-16 23:06:54 [core.py:159] init engine (profile, create kv cache, warmup model) took 19.09 seconds
INFO 05-16 23:06:54 [core_client.py:439] Core engine process 0 ready.
WARNING 05-16 23:06:54 [config.py:1239] Default sampling parameters have been overridden by the model's Hugging Face generation config recommended from the model creator. If this is not intended, please relaunch vLLM instance with `--generation-config vllm`.
INFO 05-16 23:06:54 [serving_chat.py:118] Using default chat sampling params from model: {'temperature': 0.6, 'top_k': 20, 'top_p': 0.95}
INFO 05-16 23:06:54 [serving_completion.py:61] Using default completion sampling params from model: {'temperature': 0.6, 'top_k': 20, 'top_p': 0.95}
INFO 05-16 23:06:54 [api_server.py:1090] Starting vLLM API server on http://0.0.0.0:6333
INFO 05-16 23:06:54 [launcher.py:28] Available routes are:
INFO 05-16 23:06:54 [launcher.py:36] Route: /openapi.json, Methods: GET, HEAD
INFO 05-16 23:06:54 [launcher.py:36] Route: /docs, Methods: GET, HEAD
INFO 05-16 23:06:54 [launcher.py:36] Route: /docs/oauth2-redirect, Methods: GET, HEAD
INFO 05-16 23:06:54 [launcher.py:36] Route: /redoc, Methods: GET, HEAD
.......enforce-eager對性能的影響
?enforce-eager = false

enforce-eager = true
1個并發
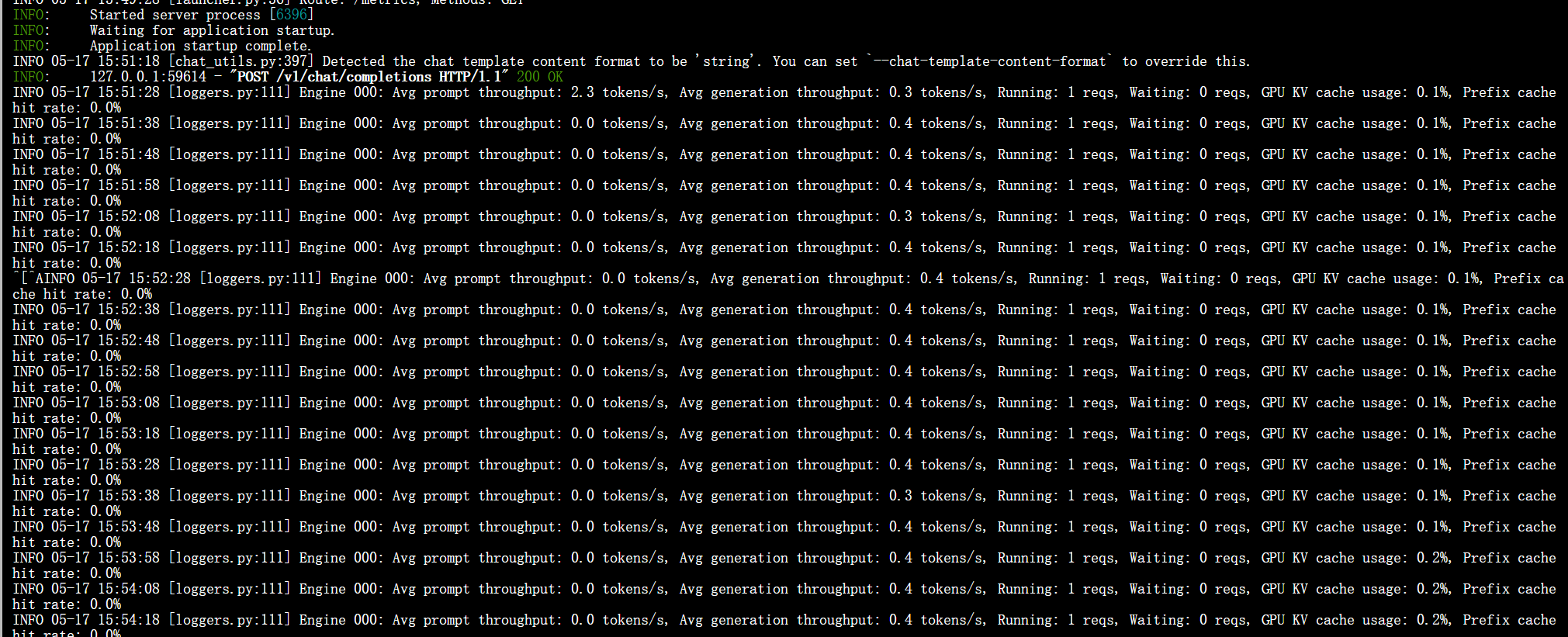
8個并發?
 ?異常日志處理
?異常日志處理
(以下為了快速測試,使用的是Qwen7B模型FP16精度+4bit量化)
CUDA out of memory.
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 448.00 MiB. GPU 0 has a total capacity of 31.48 GiB of which 447.56 MiB is free. Including non-PyTorch memory, this process has 30.97 GiB memory in use. Of the allocated memory 27.98 GiB is allocated by PyTorch, with 619.88 MiB allocated in private pools (e.g., CUDA Graphs), and 808.06 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
[rank0]:[W517 15:35:52.765542648 ProcessGroupNCCL.cpp:1496] Warning: WARNING: destroy_process_group() was not called before program exit, which can leak resources. For more info, please see https://pytorch.org/docs/stable/distributed.html#shutdown (function operator())
Traceback (most recent call last):File "/root/miniconda3/bin/vllm", line 8, in <module>原因是:CUDA要分配的內存不夠;比如CUDA需要2G,但是你通過“gpu-memory-utilization”將31G顯存進行了預分配,但事實上其中可能有28G內存可能實際可能沒用到的,這部分內存可以通過預分配內存降低,將更多的內存分配給CUDA;
降低預分配:gpu-memory-utilization: 0.9 由原來得0.95--->0.9KV緩存不夠(No available memory for the cache blocks)
(VllmWorker rank=1 pid=3244) INFO 05-16 23:09:33 [gpu_model_runner.py:1347] Model loading took 1.2216 GiB and 5.555432 seconds
(VllmWorker rank=0 pid=3243) INFO 05-16 23:09:33 [gpu_model_runner.py:1347] Model loading took 1.2216 GiB and 5.552125 seconds
ERROR 05-16 23:09:36 [core.py:396] EngineCore failed to start.
ERROR 05-16 23:09:36 [core.py:396] Traceback (most recent call last):
ERROR 05-16 23:09:36 [core.py:396] File "/root/miniconda3/lib/python3.12/site-packages/vllm/v1/engine/core.py", line 387, in run_engine_core
ERROR 05-16 23:09:36 [core.py:396] engine_core = EngineCoreProc(*args, **kwargs)
ERROR 05-16 23:09:36 [core.py:396] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR 05-16 23:09:36 [core.py:396] File "/root/miniconda3/lib/python3.12/site-packages/vllm/v1/engine/core.py", line 329, in __init__
ERROR 05-16 23:09:36 [core.py:396] super().__init__(vllm_config, executor_class, log_stats,
ERROR 05-16 23:09:36 [core.py:396] File "/root/miniconda3/lib/python3.12/site-packages/vllm/v1/engine/core.py", line 71, in __init__
ERROR 05-16 23:09:36 [core.py:396] self._initialize_kv_caches(vllm_config)
ERROR 05-16 23:09:36 [core.py:396] File "/root/miniconda3/lib/python3.12/site-packages/vllm/v1/engine/core.py", line 134, in _initialize_kv_caches
ERROR 05-16 23:09:36 [core.py:396] get_kv_cache_config(vllm_config, kv_cache_spec_one_worker,
ERROR 05-16 23:09:36 [core.py:396] File "/root/miniconda3/lib/python3.12/site-packages/vllm/v1/core/kv_cache_utils.py", line 699, in get_kv_cache_config
ERROR 05-16 23:09:36 [core.py:396] check_enough_kv_cache_memory(vllm_config, kv_cache_spec, available_memory)
ERROR 05-16 23:09:36 [core.py:396] File "/root/miniconda3/lib/python3.12/site-packages/vllm/v1/core/kv_cache_utils.py", line 527, in check_enough_kv_cache_memory
ERROR 05-16 23:09:36 [core.py:396] raise ValueError("No available memory for the cache blocks. "
ERROR 05-16 23:09:36 [core.py:396] ValueError: No available memory for the cache blocks. Try increasing `gpu_memory_utilization` when initializing the engine.
ERROR 05-16 23:09:37 [multiproc_executor.py:123] Worker proc VllmWorker-0 died unexpectedly, shutting down executor.1.模型加載顯存:
- 每個GPU加載Qwen3-8B模型約占用 1.22 GiB(日志顯示 Model loading took 1.2216 GiB)。
- 若你有2個GPU(從日志的 rank=0 和 rank=1 推斷),則總模型顯存占用約為 2.44 GiB。
2.KV緩存顯存需求:
- vLLM默認的 gpu_memory_utilization 參數是 0.9(即90%的GPU顯存用于模型和KV緩存)。
- 你需要確保剩余的顯存(總顯存 × gpu_memory_utilization - 模型占用顯存)足夠分配給KV緩存。
可用顯存 = X × gpu_memory_utilization
KV緩存需求 = 可用顯存 - 模型占用顯存model需要1.2G顯存,但是我們通過“gpu_memory_utilization=0.12”分配了0.12*20=2.4,按道理來說應該夠用,但是系統依然報錯“No available memory for the cache blocks.”----KV緩存不夠
解決方法:降低KV緩存
- 降低max-num-batched-tokens(單批次最大token數);
- 降低模型上下文長度(max-model-len)
- 降低并發數(max-num-seqs)
- 關禁用cuda圖enforce-eager=true降低內存消耗
- 降低最大序列長度(max-seq-len-to-capture)
- 禁用多GPU自定義通信(disable-custom-all-reduce=true)達到減少多GPU顯存開銷
?內存占用
模型只占用了1.2G,但是nvidia-smi顯示占用了4.5G,剩下3G去哪兒了?
(VllmWorker rank=0 pid=5361)
(VllmWorker rank=0 pid=5361) INFO 05-16 23:43:35 [gpu_model_runner.py:1347] Model loading took 1.2216 GiB and 5.527624 seconds
(VllmWorker rank=1 pid=5362) INFO 05-16 23:43:35 [gpu_model_runner.py:1347] Model loading took 1.2216 GiB and 5.531894 seconds
(VllmWorker rank=1 pid=5362) INFO 05-16 23:43:50 [backends.py:420] Using cache directory: /root/.cache/vllm/torch_compile_cache/c15482133e/rank_1_0 for vLLM's torch.compile
(VllmWorker rank=1 pid=5362) INFO 05-16 23:43:50 [backends.py:430] Dynamo bytecode transform time: 15.34 s
(VllmWorker rank=0 pid=5361) INFO 05-16 23:43:50 [backends.py:420] Using cache directory: /root/.cache/vllm/torch_compile_cache/c15482133e/rank_0_0 for vLLM's torch.compile
(VllmWorker rank=0 pid=5361) INFO 05-16 23:43:50 [backends.py:430] Dynamo bytecode transform time: 15.67 s
(VllmWorker rank=1 pid=5362) INFO 05-16 23:44:02 [backends.py:118] Directly load the compiled graph(s) for shape None from the cache, took 10.311 s
(VllmWorker rank=0 pid=5361) INFO 05-16 23:44:02 [backends.py:118] Directly load the compiled graph(s) for shape None from the cache, took 10.182 s
(VllmWorker rank=1 pid=5362) INFO 05-16 23:44:05 [monitor.py:33] torch.compile takes 15.34 s in total
(VllmWorker rank=0 pid=5361) INFO 05-16 23:44:05 [monitor.py:33] torch.compile takes 15.67 s in total
INFO 05-16 23:44:06 [kv_cache_utils.py:634] GPU KV cache size: 7,216 tokens
INFO 05-16 23:44:06 [kv_cache_utils.py:637] Maximum concurrency for 1,024 tokens per request: 7.05x
INFO 05-16 23:44:06 [kv_cache_utils.py:634] GPU KV cache size: 7,216 tokens
INFO 05-16 23:44:06 [kv_cache_utils.py:637] Maximum concurrency for 1,024 tokens per request: 7.05x
(VllmWorker rank=0 pid=5361) INFO 05-16 23:44:49 [gpu_model_runner.py:1686] Graph capturing finished in 44 secs, took 1.99 GiB
(VllmWorker rank=1 pid=5362) INFO 05-16 23:44:49 [gpu_model_runner.py:1686] Graph capturing finished in 44 secs, took 1.99 GiB
INFO 05-16 23:44:50 [core.py:159] init engine (profile, create kv cache, warmup model) took 74.74 seconds
INFO 05-16 23:44:50 [core_client.py:439] Core engine process 0 ready.
WARNING 05-16 23:44:50 [config.py:1239] Default sampling parameters have been overridden by the model's Hugging Face generation config recommended from the model creator. If this is not intended, please relaunch vLLM instance with `--generation-config vllm通過:nvidia-smi -l 2 查看其中的Memory-Usage內存使用+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.78 Driver Version: 550.78 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3080 On | 00000000:98:00.0 Off | N/A |
| 0% 30C P8 26W / 320W | 4546MiB / 20480MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA GeForce RTX 3080 On | 00000000:B1:00.0 Off | N/A |
| 0% 30C P8 21W / 320W | 4546MiB / 20480MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+| 類別 | 顯存占用 | 說明 |
| 模型參數 | 1.2 GB | 量化后Qwen3-8B的實際占用(bitsandbytes生效) |
| KV緩存預分配 | 2.5 GB | block-size=16 + max-model-len=512 的預分配空間(日志顯示7216 tokens) |
| 框架運行時開銷 | 0.8 GB | PyTorch CUDA上下文 + vLLM通信緩存 + 動態批處理隊列 |
| CUDA內核編譯緩存 | 0.5 GB | torch.compile 生成的編譯緩存(/root/.cache/vllm/torch_compile_cache) |
?

















![信息學奧賽一本通 1539:簡單題 | 洛谷 P5057 [CQOI2006] 簡單題](http://pic.xiahunao.cn/信息學奧賽一本通 1539:簡單題 | 洛谷 P5057 [CQOI2006] 簡單題)

