CCAFusion:用于紅外與可見光圖像融合的跨模態坐標注意力網絡
CCAFusion: Cross-Modal Coordinate Attention Network for Infrared and Visible Image Fusion
摘要
紅外與可見光圖像融合旨在生成一幅包含全面信息的圖像,該圖像既能保留豐富的紋理特征,又能保留熱信息。然而,在現有的圖像融合方法中,融合后的圖像要么會損失熱目標的顯著性與紋理的豐富性,要么會引入偽影等無用信息的干擾。為緩解這些問題,本文提出一種用于紅外與可見光圖像融合的高效跨模態坐標注意力網絡,命名為CCAFusion。為充分融合互補特征,本文設計了基于坐標注意力的跨模態圖像融合策略,該策略包含特征感知融合模塊與特征增強融合模塊。此外,本文采用基于多尺度跳躍連接的網絡來獲取紅外圖像與可見光圖像中的多尺度特征,以便在融合過程中充分利用多層次信息。為減小融合圖像與輸入圖像之間的差異,本文構建了包含基礎損失與輔助損失的多約束損失函數,用于調整灰度分布,確保融合圖像中結構與強度和諧共存,進而避免偽影等無用信息的干擾。在廣泛使用的數據集上進行的大量實驗表明,無論是在定性評價還是定量測量方面,所提CCAFusion網絡的性能均優于當前主流的圖像融合方法。此外,將該網絡應用于顯著目標檢測的結果表明,CCAFusion在高級視覺任務中具有應用潛力,能夠有效提升檢測性能。
關鍵詞:紅外與可見光圖像融合;注意力機制;跨模態融合策略;坐標注意力;多約束損失函數
1 引言
紅外與可見光圖像融合旨在生成一幅包含全面信息的圖像。該技術能夠保留可見光圖像中豐富的紋理特征以及紅外圖像中的熱信息[1]-[3],從而提升在光照變化、目標遮擋、背景雜亂等復雜場景下的關鍵信息獲取能力。圖像融合作為一項重要的預處理技術,可助力眾多應用準確識別復雜場景中的潛在目標與現象。尤其在視頻監控[4]、語義分割[5]、目標檢測[6]-[7]等多模態高級視覺任務中,圖像融合技術展現出廣泛的應用價值。
早期的圖像融合研究主要采用多尺度變換法、稀疏表示法、顯著性檢測法、子空間法、混合方法等多種傳統方法對不同模態圖像進行融合[8]-[9]。這些傳統融合方法雖對紅外與可見光圖像融合任務有一定積極作用,但由于其所采用的手工設計特征表達能力有限,導致融合圖像易出現空間失真問題,如存在偽影、信息不完整等。
近年來,深度學習憑借其卓越的特征提取能力被引入圖像融合領域。現有基于深度學習的融合方法主要基于卷積神經網絡(CNN)框架[10]-[11]、生成對抗網絡(GAN)框架[12]-[14]以及自編碼器(AE)框架[15]-[16]構建。盡管基于深度學習的圖像融合方法能生成質量較好的融合結果,但仍存在一些局限性:
-
部分圖像融合方法采用簡單直接的方式將源圖像特征遷移至融合圖像中。例如,文獻[17]-[18]中預設的融合規則僅通過對特征圖取平均來獲取融合特征,這種直接的特征處理方式可能導致源圖像中提取的特征未被充分利用。
-
由于圖像融合任務缺乏理想的真值數據,難以平衡源圖像與融合圖像之間的差異,甚至可能在融合圖像中引入偽影等無用信息干擾。為此,有研究探索了基于GAN框架的圖像融合方法[19]-[20]。這類方法雖能保留大部分細節信息,但GAN網絡難以充分挖掘多模態圖像中的代表性信息。
-
基于AE的融合方法在整合源圖像有效信息時,對提取的特征缺乏合理引導便直接進行融合[21]-[23]。近年來,研究人員將注意力機制引入基于AE的融合框架中,以區分不同特征的重要性。例如,有研究提出基于卷積塊注意力模塊(CBAM)[24]的融合策略,用于表征各空間位置及各通道的重要性[25],該方法能生成較好的融合結果。但該融合方法在特征融合過程中未挖掘跨特征與長距離依賴關系,且采用大尺度池化操作捕捉局部相關性,易造成位置信息丟失。
受近期注意力機制相關研究[28]及Densefuse方法[21]的啟發,本文提出一種用于紅外與可見光圖像融合的高效跨模態坐標注意力網絡(CCAFusion),旨在解決上述圖像融合方法中存在的問題。與傳統基于深度學習的融合方法相比,CCAFusion通過引入通道與位置重要性,構建跨模態坐標注意力以引導特征融合;同時,在特征融合過程中挖掘跨特征與長距離依賴關系,避免大尺度全局池化導致的位置信息丟失。為實現互補特征的有效融合,本文在融合策略中設計了特征感知融合模塊(FAF)與特征增強融合模塊(FEF)。此外,采用基于多尺度跳躍連接的網絡結構,提取紅外圖像與可見光圖像中的多尺度特征。
具體而言,CCAFusion網絡由編碼器模塊、融合模塊及解碼器模塊構成。通過跨模態坐標注意力融合模塊,實現各層級的跨模態特征融合;將這些跨模態融合特征輸入基于跳躍連接結構的解碼器模塊,從高層信息到低層信息逐步重構出最終的融合圖像。此外,針對圖像融合任務中缺乏理想真值數據的問題,本文設計了一種新的損失項用于約束網絡訓練,即多約束損失函數。

為直觀展示CCAFusion的優勢,圖1給出了紅外與可見光圖像融合的示意圖,結果表明該網絡能有效保留熱目標與紋理特征,且無偽影產生。
綜上,本文的主要貢獻如下:
-
提出一種新型紅外與可見光圖像融合跨模態坐標注意力網絡(CCAFusion),該網絡在圖像融合任務中表現出優異性能。將其擴展應用于顯著目標檢測任務,結果表明CCAFusion可提升后續高級視覺任務的檢測性能。
-
設計一種簡潔高效的跨模態圖像融合策略,該策略包含特征感知融合模塊(FAF)與特征增強融合模塊(FEF)。其中,FAF基于單模態注意力權重實現互補特征融合;FEF利用跨模態注意力權重增強互補特征。通過對融合模塊的消融實驗驗證了該融合策略的有效性,結果表明FAF與FEF協同作用,能使融合網絡保留豐富的圖像信息。
-
構建用于圖像融合的多約束損失函數。具體而言,本文提出一種新的基礎損失,通過KL散度使融合圖像與源圖像保持相似的灰度分布,從而保留基礎信息;輔助損失則用于保留細節信息與熱輻射信息。利用該損失函數訓練的CCAFusion網絡,可合理調整灰度分布,確保融合圖像中結構與強度和諧共存,有效避免偽影干擾。通過對損失函數的消融實驗,驗證了各損失項的有效性及其不同作用。
本文后續內容安排如下:第2章綜述圖像融合方法的相關研究;第3章詳細介紹CCAFusion網絡結構;第4章在公開數據集上開展圖像融合實驗;第5章總結全文。
2 相關工作
本節首先綜述經典圖像融合算法,隨后介紹近年來基于深度學習的圖像融合方法相關研究。
2.1 經典圖像融合方法
經典圖像融合方法可分為六類:多尺度變換法、稀疏表示法、顯著性檢測法、子空間法、混合方法及其他方法[8]-[9]。其中,應用最廣泛的是多尺度變換法與稀疏表示法。
作為經典圖像融合方法的代表性分支,多尺度變換法旨在將源圖像分解為不同尺度,隨后通過逆變換將不同尺度下的特征融合[29]。傳統多尺度變換方法包括拉普拉斯金字塔變換(LAP)[30]、非下采樣輪廓波變換(NSCT)[31]及離散小波變換(DWT)[32]。Madheswari與Venkateswaran[33]提出一種基于離散小波變換的圖像融合框架,結合粒子群優化技術實現紅外熱圖像與可見光圖像的融合,其性能優于大多數多分辨率融合技術。
經典圖像融合方法的另一典型分支是稀疏表示法。基于稀疏表示的融合方法核心是利用過完備字典對源圖像進行表示,再依據融合規則對過完備字典中的稀疏表示系數進行整合,最終得到融合圖像[34]。為在字典構建過程中獲取充分的特征表示,Wang等人[35]提出一種結合形態學、隨機坐標編碼與同步正交匹配追蹤的圖像融合方法。考慮到稀疏表示的滑動窗口技術易引入偽影,研究人員提出卷積稀疏表示法[36],用于學習對應整幅源圖像的系數;Liu等人[37]采用該卷積稀疏表示法,有效改善了圖像融合任務中細節保留效果不佳的問題。
2.2 基于深度學習的圖像融合方法
近年來,基于深度學習的方法[38]-[40]憑借出色的特征提取能力,在圖像融合領域取得顯著進展。根據圖像融合任務中所采用網絡架構的特點,基于深度學習的融合方法可分為基于卷積神經網絡(CNN)的融合框架、基于生成對抗網絡(GAN)的融合框架以及基于自編碼器(AE)的融合框架[41]。
2.2.1 基于CNN的融合方法
此類方法利用卷積算子提取顯著特征并生成權重圖。Liu等人[11]首次將CNN應用于圖像融合任務,但該方法依賴二值圖,僅適用于多聚焦圖像融合。為實現紅外與可見光圖像融合,Li等人[42]將源圖像分解為基礎部分與細節部分,針對細節部分,基于深度學習網絡提取的特征生成權重。隨后,Zhang與Ma[43]構建了一種用于融合任務的壓縮-分解模型,該模型采用自適應決策塊優化目標函數,并通過調整權重改變不同輸入圖像的信息占比。
2.2.2 基于GAN的融合方法
這類方法充分利用概率分布估計能力生成融合圖像,其核心是生成器與判別器之間的博弈過程。Ma等人[20]創新性地將GAN框架引入圖像融合任務,通過判別器驅動生成器生成融合圖像。然而,單一判別器易導致模式崩潰,即融合圖像過度偏向可見光圖像或紅外圖像中的某一種;此外,文獻[20]中的FusionGAN依賴對抗學習進行特征學習,穩定性較差,導致融合結果缺乏紋理細節。為平衡紅外圖像與可見光圖像的信息,Ma等人[44]提出雙判別器條件生成對抗網絡;為更好地融合源圖像的紋理信息,Yang等人[45]構建了基于紋理條件生成對抗網絡的圖像融合網絡。
2.2.3 基于AE的融合方法
此類方法采用自編碼器架構實現特征提取與特征重構。Li與Wu[21]提出一種基于編碼器-解碼器結構的紅外與可見光圖像融合方法,命名為Densefuse。但該方法在融合層采用直接相加策略整合顯著特征,限制了融合性能。為解決這一問題,Xu等人[46]提出一種基于自編碼器的圖像融合框架,結合逐像素分類的顯著性融合規則,突破了深度學習在融合規則應用中的瓶頸。
近年來,注意力機制被引入圖像融合任務。Li等人[25]提出基于卷積塊注意力模塊(CBAM)的融合策略,該策略考慮了各空間位置與各通道的重要性;類似地,Wang等人[16]也在融合層構建了空間注意力與通道注意力模型。與文獻[25]中的Nestfuse方法不同,文獻[16]將L1范數、均值運算與注意力模型結合,為顯著特征生成權重圖。
基于深度學習的融合方法雖展現出具有競爭力的融合性能,但仍存在部分待解決的缺陷:
-
圖像融合不僅能整合關鍵信息,還可助力高級視覺任務。然而,以往的融合方法[22]、[45]、[47]-[49]僅關注融合圖像的視覺質量與統計指標,忽視了圖像融合在高級視覺任務中的應用。與之不同,本文方法不僅在圖像融合任務中表現優異,還能提升后續高級視覺任務的檢測性能——這一點已通過在顯著目標檢測中的擴展應用得到驗證。
-
部分融合策略在整合源圖像有效信息時,依賴直接的手工設計規則,缺乏合理引導(例如文獻[21]、[22]中的加法運算)。相比之下,本文基于注意力機制設計了一種新型跨模態圖像融合策略,能在注意力機制的引導下整合源圖像的有效信息。盡管文獻[45]、[49]中基于注意力機制的方法可引導模型更多關注重要內容,但在特征融合過程中忽略了長距離依賴關系。與這些方法不同,本文方法采用坐標注意力設計特征感知融合模塊與特征增強融合模塊,可同時捕捉通道與位置重要性及長距離依賴關系。
-
同一場景下的圖像往往具有相似的灰度分布,這種分布特性可反映圖像融合中的基礎信息,但現有方法[48]、[49]忽視了這一點。與之相反,本文基于“同一場景圖像灰度分布相似”這一事實,設計了一種新的損失函數,通過KL散度使融合圖像與源圖像保持相似的灰度分布,從而保留基礎信息。
3 所提方法
本節首先闡述所提方法的設計動機,隨后介紹CCAFusion網絡的整體架構,并詳細說明跨模態坐標注意力融合策略;接著,詳細介紹所設計的多約束損失函數;最后,闡述用于RGB-紅外圖像融合的CCAFusion具體框架。
3.1 設計動機
紅外與可見光圖像融合旨在生成一幅包含全面信息的圖像,該圖像需保留可見光圖像中豐富的紋理特征以及紅外圖像中的熱信息。然而,紅外圖像與可見光圖像由不同成像機制的傳感器生成,導致源圖像之間存在域差異。這種域差異對紅外與可見光圖像融合任務構成了巨大挑戰,因為難以平衡源圖像間關鍵特征的差異。當源圖像的結構與強度無法和諧共存時,融合圖像的高對比度邊緣區域往往會出現偽影。此外,由于現有紅外與可見光圖像融合方法在融合過程中存在特征表示能力有限、關鍵信息丟失等問題,其融合結果也易受不良偽影影響,進而不可避免地降低最終性能。
鑒于上述局限性,本文提出一種新型紅外與可見光圖像融合網絡,旨在實現充分的特征保留、強大的特征表示能力以及關鍵特征的和諧共存,從而避免向融合圖像中引入不良偽影。
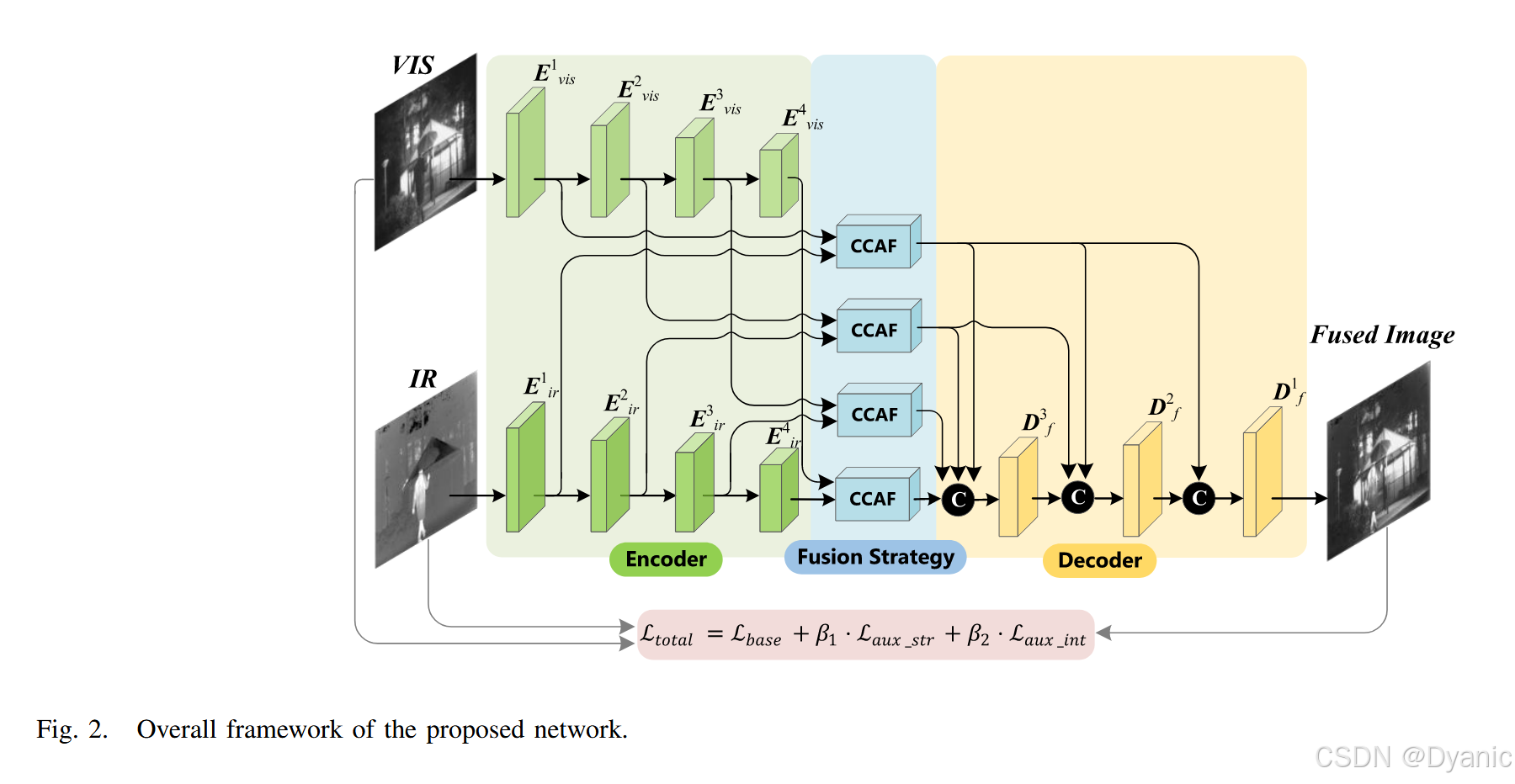
3.2 網絡概述
所提網絡采用雙分支結構,包含4個編碼器模塊(記為EjiE_j^iEji?,其中i∈{1,2,3,4}i \in \{1,2,3,4\}i∈{1,2,3,4},j∈{ir,vis}j \in \{ir,vis\}j∈{ir,vis},iririr代表紅外分支,visvisvis代表可見光分支)、4個融合模塊以及3個解碼器模塊(記為DfiD_f^iDfi?,其中i∈{1,2,3}i \in \{1,2,3\}i∈{1,2,3})。圖2展示了該網絡的整體框架。
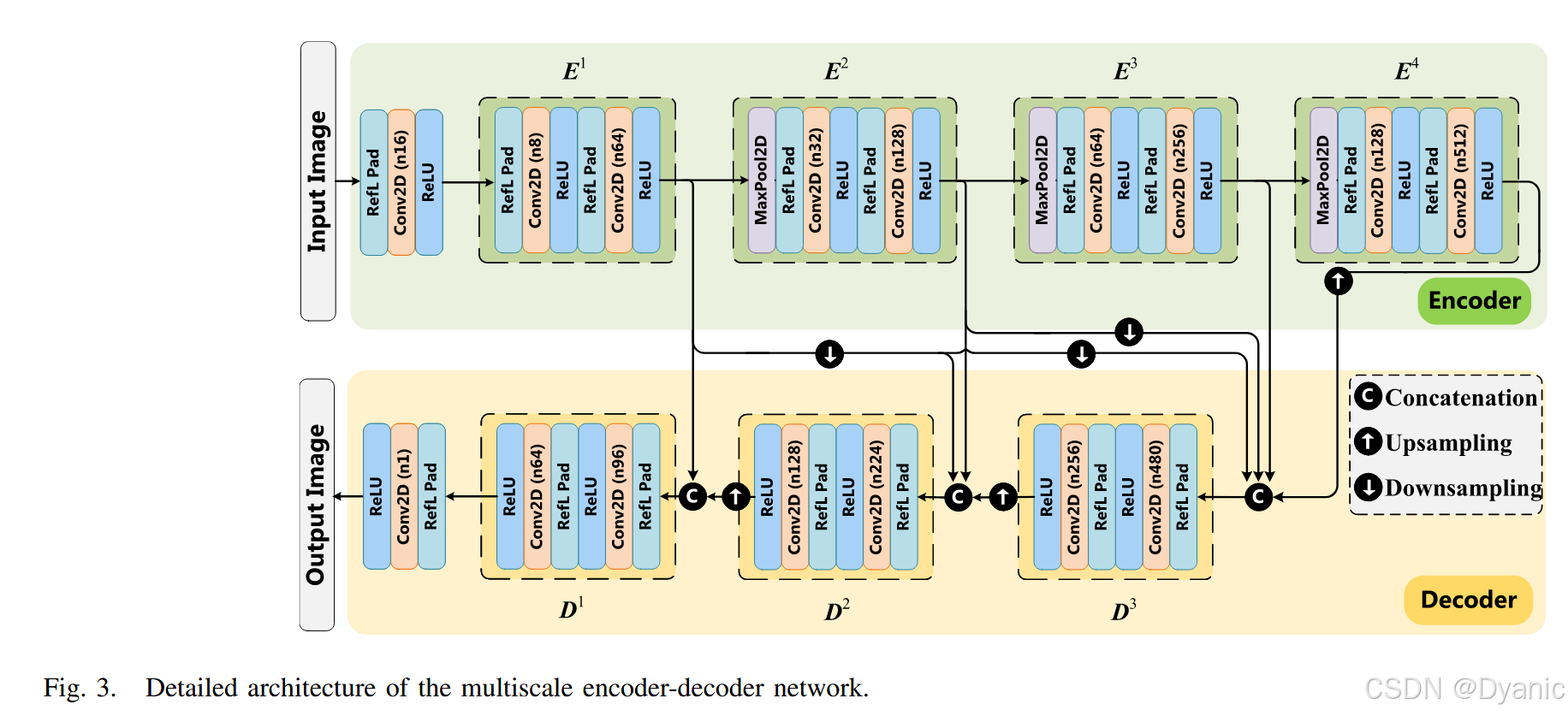
具體而言,首先將紅外圖像與可見光圖像分別輸入雙分支特征提取網絡。每個分支的主干網絡為基于多尺度跳躍連接結構的編解碼器網絡[50],其結構如圖3所示。編碼器模塊的作用是提取各層級的深層特征;隨后,將編碼器模塊的輸出傳入跨模態坐標注意力融合模塊(CCAF),實現各層級的跨模態特征融合;接著,將這些跨模態融合特征輸入基于跳躍連接結構的解碼器模塊,從高層信息到低層信息逐步重構出最終的融合圖像。
下文將詳細介紹編解碼器網絡的結構。該編解碼器網絡的設計靈感來源于Densefuse[21],但與Densefuse通過基于密集連接的網絡獲取重構圖像不同,本文采用基于多尺度跳躍連接的編解碼器網絡[50],以充分利用紅外圖像與可見光圖像中的多尺度特征,其結構如圖3所示。
每個分支的編碼器由4個模塊構成,每個模塊包含2個填充層(Padding層)、2個卷積層(Convolution層)和2個ReLU激活層。其中,第一個卷積層的卷積核大小為3×33 \times 33×3,第二個卷積層的卷積核大小為1×11 \times 11×1。通過多尺度跳躍連接結構與拼接操作(Concatenation)對提取到的不同尺度特征進行整合,再將整合結果分別輸入3個解碼器模塊。與編碼器部分類似,每個解碼器模塊也包含2個填充層、2個卷積層和2個ReLU激活層。各卷積層的通道數如圖3所示,最終通過將通道數減少至1,生成輸出圖像。
3.3 融合策略
可見光圖像包含豐富的紋理特征,紅外圖像則呈現熱輻射特征。在背景雜亂、目標遮擋、光照變化等復雜環境下,這兩類特征具有互補性。考慮到不同空間信息與通道的作用存在差異,在融合這些互補特征時需重點關注有效信息。因此,本文在融合策略中引入一種新型注意力機制,用于區分特征的重要性。
注意力機制已在多個領域得到廣泛研究與應用,能夠引導模型更多關注重要內容[51]-[52]。其中,擠壓-激勵(SE)注意力[53]是最知名且應用最廣泛的方法之一,但SE模塊僅考慮通道間信息,忽略了位置信息的重要性。卷積塊注意力模塊(CBAM)同時考慮通道信息與位置信息,文獻[25]將其應用于圖像融合任務,然而該注意力機制存在長距離依賴關系捕捉不足的問題。
本文的融合策略基于坐標注意力[28]設計,可同時捕捉通道與位置重要性及長距離依賴關系。圖4展示了跨模態融合策略的具體結構,該策略包含兩個核心部分:特征感知融合模塊(FAF)與特征增強融合模塊(FEF)。
本文采用FAF實現互補特征(包括可見光圖像的紋理特征與紅外圖像的熱輻射特征)的融合。首先,將可見光分支生成的第iii層特征EvisiE^i_{vis}Evisi?與紅外分支生成的第iii層特征EiriE^i_{ir}Eiri?輸入跨模態坐標注意力融合模塊(CCAF);隨后,通過坐標注意力模塊(CAM)獲取權重矩陣wvisiw^i_{vis}wvisi?與wiriw^i_{ir}wiri?,分別反映可見光特征與紅外特征的重要性。
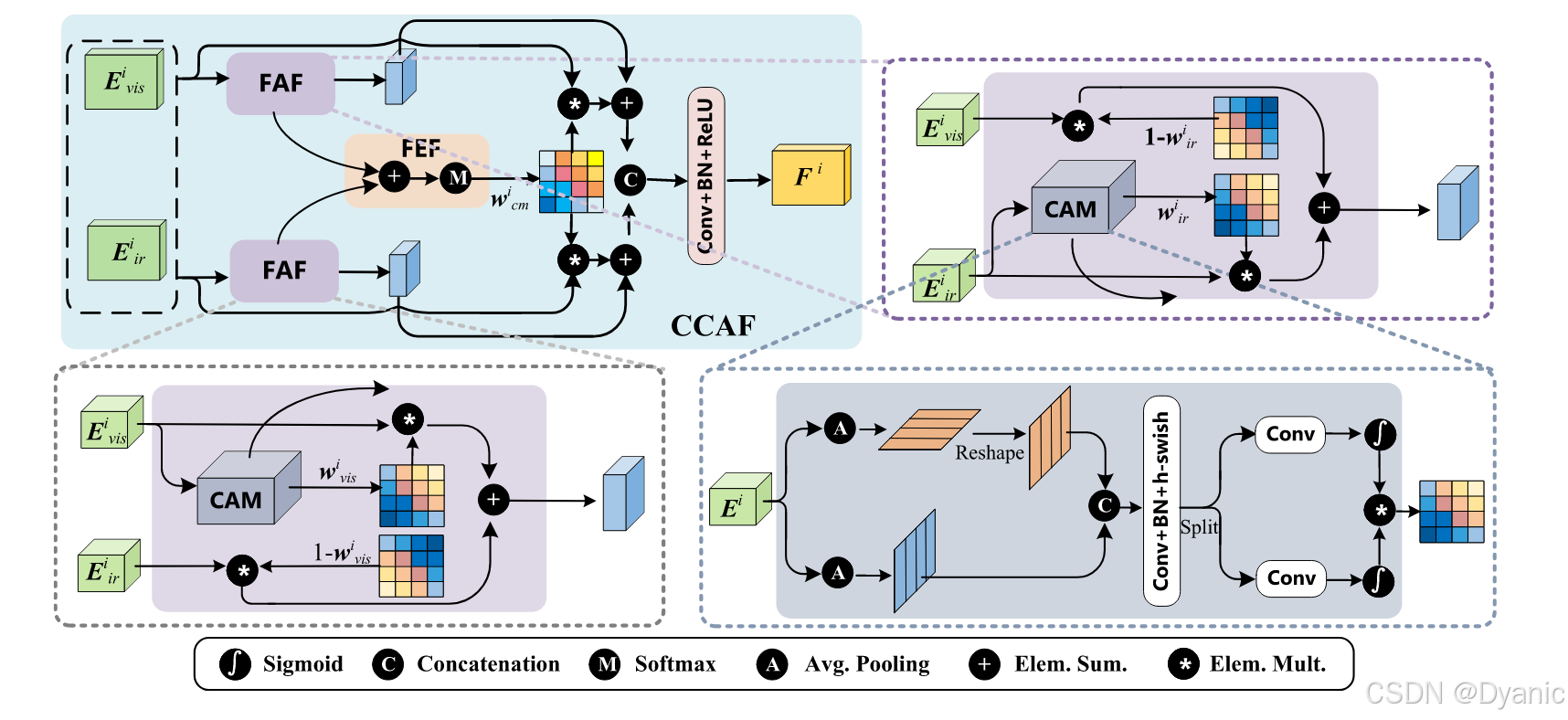
CAM的具體結構如圖4右下角所示。給定尺寸為C×H×WC \times H \times WC×H×W的第iii層輸入特征EiE_iEi?,分別采用尺寸為(H,1)(H,1)(H,1)和(1,W)(1,W)(1,W)的池化核,沿水平坐標與垂直坐標對不同通道的信息進行編碼。其中,高度為hhh處第ccc個通道的編碼過程定義如下:
yi_ch(h)=1W∑0≤l<WEi_c(h,l)(1)y^h_{i\_c}(h) = \frac{1}{W}\sum_{0 \leq l < W} E^{i\_c}(h,l) \tag{1}yi_ch?(h)=W1?0≤l<W∑?Ei_c(h,l)(1)
類似地,寬度為www處第ccc個通道的編碼過程定義如下:
yi_cw(w)=1H∑0≤k<HEi_c(k,w)(2)y^w_{i\_c}(w) = \frac{1}{H}\sum_{0 \leq k < H} E^{i\_c}(k,w) \tag{2}yi_cw?(w)=H1?0≤k<H∑?Ei_c(k,w)(2)
上述兩個過程生成沿兩個空間方向的方向感知特征圖,使注意力模塊能沿一個空間方向捕捉長距離依賴關系,同時沿另一個空間方向保留精確的位置信息,從而幫助網絡準確定位感興趣目標的位置。CAM的直觀效果將在4.6.3節詳細說明。
為生成經重塑的yi_ch(h)y^h_{i\_c}(h)yi_ch?(h)與yi_cw(w)y^w_{i\_c}(w)yi_cw?(w)的聚合特征圖,先對兩者進行拼接,再通過1×11 \times 11×1卷積操作將通道數減少至C/rC/rC/r(其中rrr為通道縮減系數,參考文獻[28]設為32),具體公式如下:
f=δ(F1([yi_ch(h),yi_cw(w)]))(3)f = \delta\left(F_1\left([y^h_{i\_c}(h), y^w_{i\_c}(w)]\right)\right) \tag{3}f=δ(F1?([yi_ch?(h),yi_cw?(w)]))(3)
式中,[?,?][\cdot,\cdot][?,?]表示拼接操作,F1F_1F1?代表1×11 \times 11×1卷積變換函數,δ\deltaδ為h-swish激活函數[54]。隨后,將輸出特征圖f∈RC/r×(H+W)f \in \mathbb{R}^{C/r \times (H+W)}f∈RC/r×(H+W)分解為兩個獨立張量fh∈RC/r×Hf^h \in \mathbb{R}^{C/r \times H}fh∈RC/r×H與fw∈RC/r×Wf^w \in \mathbb{R}^{C/r \times W}fw∈RC/r×W;通過兩個1×11 \times 11×1卷積變換函數F1hF^h_1F1h?與F1wF_1^wF1w?將通道數恢復至CCC,權重矩陣wiw_iwi?為F1hF^h_1F1h?與F1wF_1^wF1w?的乘積輸出,公式如下:
wi=σ(F1h(fh))×σ(F1w(fw))(4)w^i = \sigma\left(F_1^h(f^h)\right) \times \sigma\left(F_1^w(f^w)\right) \tag{4}wi=σ(F1h?(fh))×σ(F1w?(fw))(4)
式中,σ\sigmaσ為sigmoid函數。將EvisiE^i_{vis}Evisi?與EiriE^i_{ir}Eiri?輸入CAM,可分別得到權重矩陣wvisiw^i_{vis}wvisi?與wiriw^i_{ir}wiri?。將這兩個權重矩陣與輸入特征相乘,突出融合任務中的重要特征并抑制無關特征,具體過程如下:
Firi=Eiri?wiri+Evisi?(1?wiri)(5)F^i_{ir} = E^i_{ir} * w^i_{ir} + E^i_{vis} * (1 - w^i_{ir}) \tag{5}Firi?=Eiri??wiri?+Evisi??(1?wiri?)(5)
Fvisi=Evisi?wvisi+Eiri?(1?wvisi)(6)F^i_{vis} = E^i_{vis} * w^i_{vis} + E^i_{ir} * (1 - w^i_{vis}) \tag{6}Fvisi?=Evisi??wvisi?+Eiri??(1?wvisi?)(6)
其中,FiriF^i_{ir}Firi?與FvisiF^i_{vis}Fvisi?為FAF的輸出結果。
此外,紅外圖像中也會體現部分紋理特征,可見光圖像中同樣存在部分熱輻射特征,因此需通過FEF增強這些互補特征。首先對權重矩陣wvisiw^i_{vis}wvisi?與wiriw^i_{ir}wiri?進行聚合,再將聚合結果輸入softmax函數,得到跨模態權重矩陣wcmiw^i_{cm}wcmi?,公式如下:
wcmi=softmax(wvisi+wiri)(7)w^i_{cm} = softmax(w^i_{vis} + w^i_{ir}) \tag{7}wcmi?=softmax(wvisi?+wiri?)(7)
基于跨模態權重矩陣wcmiw^i_{cm}wcmi?,將FAF輸出結果與FEF增強結果相加,得到增強特征FIRiF^i_{IR}FIRi?與FVISiF^i_{VIS}FVISi?,具體如下:
FIRi=Firi+Eiri?wcmi(8)F^i_{IR} = F^i_{ir} + E^i_{ir} * w^i_{cm} \tag{8}FIRi?=Firi?+Eiri??wcmi?(8)
FVISi=Fvisi+Evisi?wcmi(9)F^i_{VIS} = F^i_{vis} + E^i_{vis} * w^i_{cm} \tag{9}FVISi?=Fvisi?+Evisi??wcmi?(9)
最后,將可見光分支與紅外分支生成的增強特征進行拼接,并輸入卷積層,得到跨模態融合特征FiF^iFi,公式如下:
Fi=Conv([FVISi,FIRi])(10)F^i = Conv([F^i_{VIS}, F^i_{IR}]) \tag{10}Fi=Conv([FVISi?,FIRi?])(10)
3.4 損失函數
針對圖像融合任務中缺乏理想真值數據的問題,本文從多維度設計網絡訓練的損失函數,以在紅外與可見光圖像融合中保留更多有效信息。
一方面,考慮到同一場景下圖像的灰度分布具有相似性,本文結合灰度分布與KL散度損失設計基礎損失Lbase\mathcal{L}_{base}Lbase?,公式如下:
Lbase=12(KL(S(pf)∥S(qir))2+KL(S(pf)∥S(qvis))2)(11)\mathcal{L}_{base} = \sqrt{\frac{1}{2}\left( \text{KL}(S(p_f) \parallel S(q_{ir}))^2 + \text{KL}(S(p_f) \parallel S(q_{vis}))^2 \right)} \tag{11}Lbase?=21?(KL(S(pf?)∥S(qir?))2+KL(S(pf?)∥S(qvis?))2)?(11)
式中,qirq_{ir}qir?與qvisq_{vis}qvis?分別表示紅外圖像與可見光圖像的灰度分布,pfp_fpf?表示融合圖像的灰度分布,S(?)S(\cdot)S(?)為softmax函數,用于對元素進行重縮放。通過KL散度約束融合圖像與源圖像的灰度分布相似性,從而保留源圖像中的基礎信息。
另一方面,考慮到融合圖像需充分保留細節信息與熱輻射信息:融合圖像的細節可表示為紅外與可見光圖像紋理的最大聚合,以保留豐富的細節信息;逐元素最大值選擇可使融合圖像獲得最優強度分布,從而突出熱輻射信息。基于此,本文構建輔助結構損失Laux?str\mathcal{L}_{aux-str}Laux?str?與輔助強度損失Laux?int\mathcal{L}_{aux-int}Laux?int?,公式分別如下:
Laux?str=∥∣?If∣?max?(∣?Iir∣,∣?Ivis∣)∥1(12)\mathcal{L}_{aux-str} = \left\| \left| \nabla I_f \right| - \max\left( \left| \nabla I_{ir} \right|, \left| \nabla I_{vis} \right| \right) \right\|_1 \tag{12}Laux?str?=∥∣?If?∣?max(∣?Iir?∣,∣?Ivis?∣)∥1?(12)
Laux?int=∥If?max?(Iir,Ivis)∥1(13)\mathcal{L}_{aux-int} = \left\| I_f - \max\left( I_{ir}, I_{vis} \right) \right\|_1 \tag{13}Laux?int?=∥If??max(Iir?,Ivis?)∥1?(13)
式中,IfI_fIf?、IirI_{ir}Iir?與IvisI_{vis}Ivis?分別表示融合圖像、紅外圖像與可見光圖像,?\nabla?為梯度算子。
最終,CCAFusion的損失函數由基礎損失與輔助損失兩部分構成,其中輔助損失進一步包含輔助結構損失與輔助強度損失。多約束總損失函數Ltotal\mathcal{L}_{total}Ltotal?定義如下:
Ltotal=Lbase+β1?Laux?str+β2?Laux?int(14)\mathcal{L}_{total} = \mathcal{L}_{base} + \beta_1 \cdot \mathcal{L}_{aux-str} + \beta_2 \cdot \mathcal{L}_{aux-int} \tag{14}Ltotal?=Lbase?+β1??Laux?str?+β2??Laux?int?(14)
式中,β1\beta_1β1?與β2\beta_2β2?為權重系數,用于平衡各損失項的貢獻。β1\beta_1β1?與β2\beta_2β2?的具體取值調整將在4.2.1節說明。
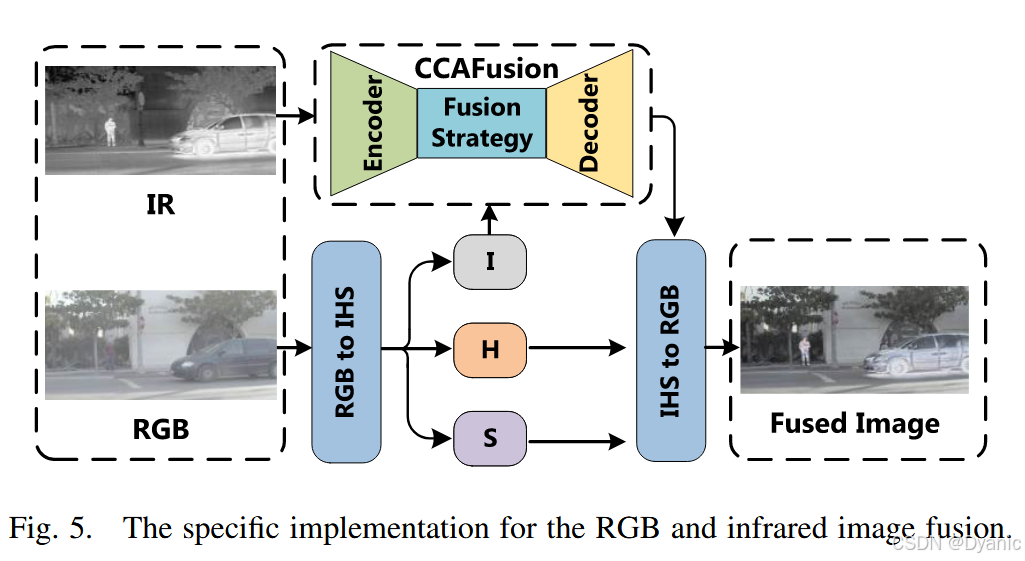
3.5 RGB-紅外圖像融合
前文所述融合過程針對灰度可見光圖像與紅外圖像。對于RGB-紅外圖像融合,可先將RGB圖像轉換至IHS顏色空間(其中III為強度通道,HHH為色調通道,SSS為飽和度通道)。由于主要空間信息集中在III通道,可采用CCAFusion將紅外圖像與RGB圖像生成的III通道進行融合;隨后,將融合后的III通道與原RGB圖像的HHH、SSS通道結合,再轉換回RGB顏色空間,即可得到最終的RGB-紅外融合圖像。RGB-紅外圖像融合的對應架構如圖5所示。
4 實驗與分析
本節首先說明實驗設置,包括數據集、評價指標、對比方法及實現細節;隨后通過消融實驗驗證CCAFusion中各組件的有效性,并將所提網絡與當前主流圖像融合方法進行對比;此外,通過泛化實驗驗證CCAFusion的泛化能力;最后,將其擴展應用于顯著目標檢測任務,以證明CCAFusion對高級視覺任務的促進作用。
4.1 實驗設置
4.1.1 數據集與評價指標
所提網絡在VTUAV數據集[55]上進行訓練,該數據集是目前最新的公開可見-熱成像多模態數據集,包含兩個城市的15個場景(涵蓋橋梁、海洋、道路、公園、街道等),且包含霧天、大風天、陰天等不同天氣條件下的數據。從VTUAV數據集中隨機選取10000對圖像作為訓練樣本,所有訓練圖像均轉換為灰度圖并調整尺寸至256×256。
在兩個公開數據集上測試所提網絡的融合性能:
- TNO數據集[56]:包含21對灰度可見光-紅外圖像,該數據集通過多波段相機系統預先配準,涵蓋不同軍事與監控場景的多光譜圖像(包括增強可見光、近紅外、長波紅外/熱成像圖像)。
- RoadScene數據集[27]:包含61對RGB-紅外配準圖像,基于FLIR視頻[57]構建,場景豐富(涵蓋道路、車輛、行人等)。
為全面評估融合質量,從定性評價與定量指標兩方面對融合圖像進行評估:
- 定性評價:基于人類視覺感知,但主觀視覺感知易受人為因素影響。
- 定量指標:采用4種廣泛使用的指標,具體如下:
- 互信息(MI)[58]:衡量從輸入圖像傳遞到融合圖像的信息量,值越大表示融合圖像包含的信息越豐富。
- 視覺信息保真度(VIF)[59]:評估融合結果的信息保真度,值越大與人類視覺感知的一致性越好。
- 空間頻率(SF)[60]:衡量紋理結構的豐富程度,值越大表示融合結果的紋理越豐富。
- 熵(EN)[61]:評估融合結果中保留的信息量,值越大表示融合結果包含的信息越多。
4.1.2 對比方法與實現細節
為驗證CCAFusion的融合性能,將其與當前主流圖像融合方法對比,包括傳統方法與基于深度學習的方法:
- 傳統方法:MDLatLRR[62]。
- 基于深度學習的方法:DenseFuse[21]、SDNet[43]、PIAFusion[26]、U2Fusion[27]。
所有對比方法均采用默認參數設置,實驗環境與實現細節如下:
- MDLatLRR:在MATLAB R2020b環境下運行,硬件為AMD R7-4800H 2.9GHz CPU。
- DenseFuse、SDNet、PIAFusion、U2Fusion:基于TensorFlow框架,硬件為1塊Nvidia 2080Ti GPU。
- 所提網絡(CCAFusion):基于PyTorch框架,硬件為1塊Nvidia 2080Ti GPU;優化器采用Adam,學習率設為0.0001,批大小(batch size)設為8,訓練輪次(epoch)設為10,訓練總時長約9小時。
4.2 消融實驗
4.2.1 超參數影響
CCAFusion中的超參數包括多約束損失函數中的β1β?β1?與β2β?β2?:β1β?β1?用于平衡基礎損失與輔助結構損失,β2β?β2?用于平衡基礎損失與輔助強度損失。設計初衷為:通過基礎損失保留源圖像中的主要信息,輔助結構損失與輔助強度損失為次要損失,用于進一步確保融合圖像中的紋理特征與熱輻射信息。
為分析超參數敏感性,將β1β?β1?與β2β?β2?的取值范圍設為0~1,實驗步驟如下:
- 固定β2β?β2?,測試不同β1β?β1?對網絡訓練的影響。
- 固定β1β?β1?,測試不同β2β?β2?對網絡訓練的影響。
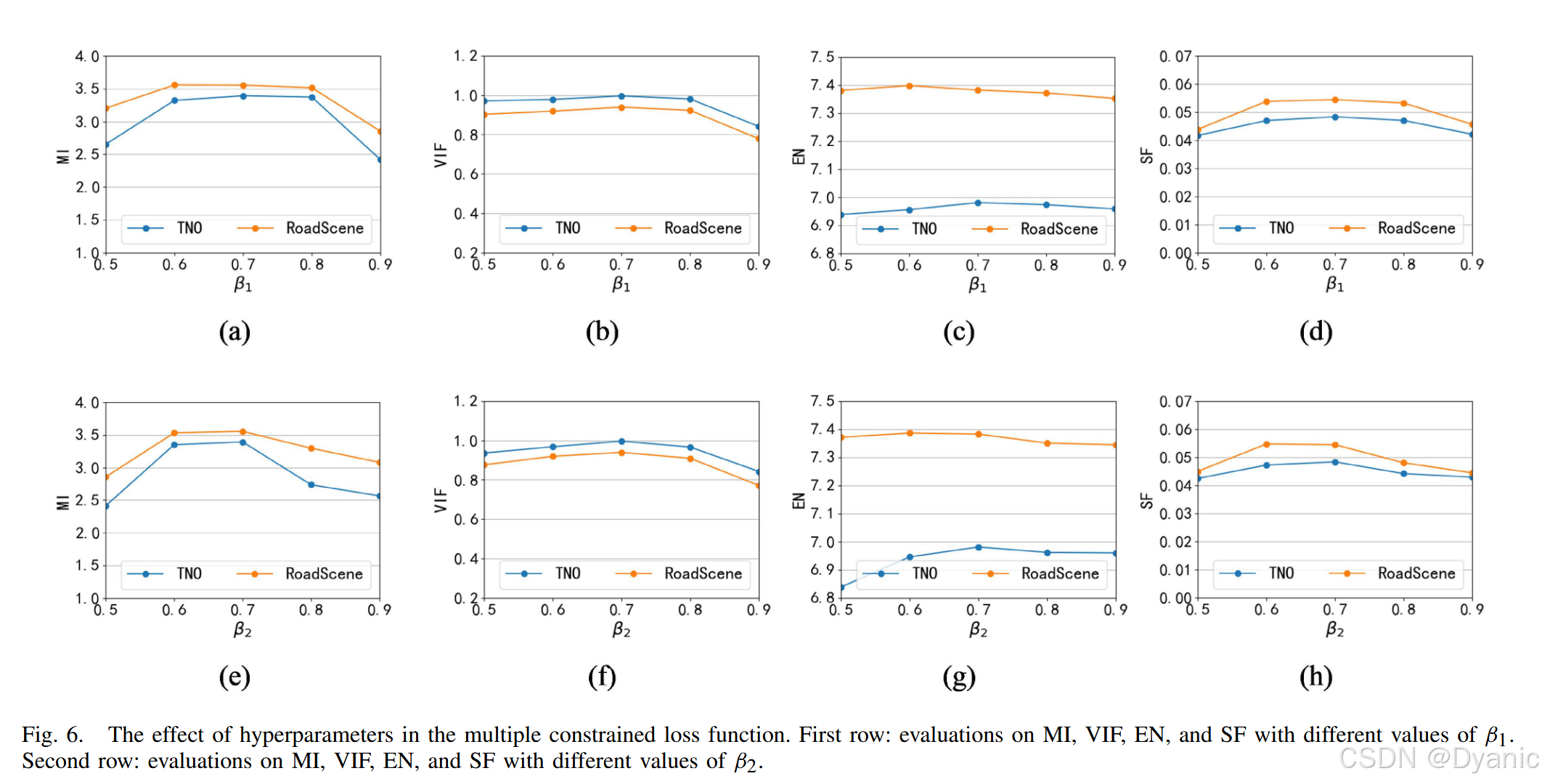
大量實驗表明,當β1=0.7β?=0.7β1?=0.7且β2=0.7β?=0.7β2?=0.7時,網絡在4項評價指標上均取得最佳性能,結果如圖6所示。
4.2.2 損失函數影響
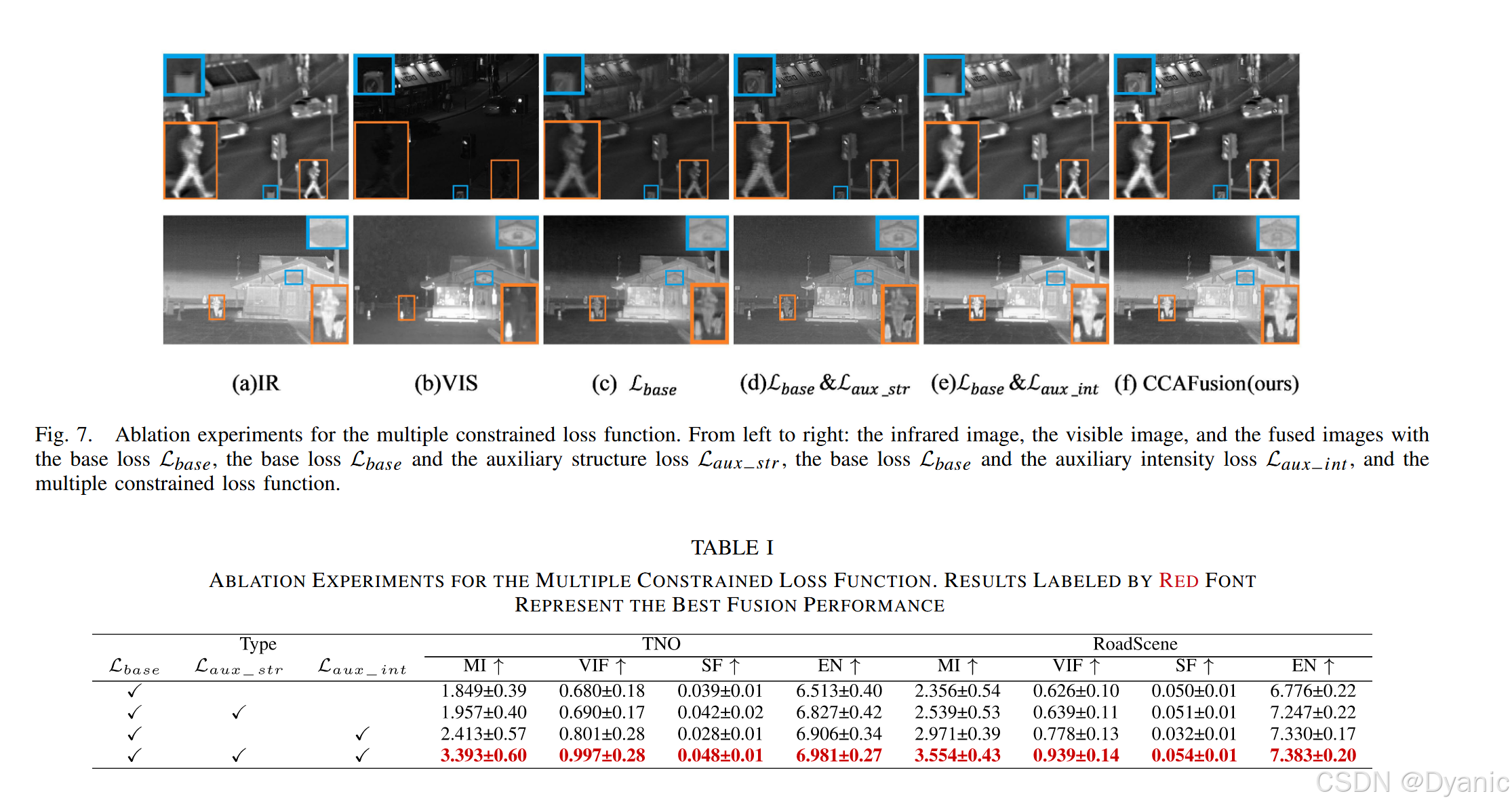
為驗證多約束損失函數的有效性,對損失函數的3個組成部分(基礎損失Lbase、輔助結構損失Laux-str、輔助強度損失Laux-int)進行消融實驗。圖7與表1展示了不同損失函數對應的融合結果,分析如下:
- 僅使用基礎損失Lbase時:網絡僅能保證融合圖像的主要灰度分布,但會丟失部分熱信息與紋理特征(如圖7?所示)。
- 使用基礎損失Lbase+輔助結構損失Laux-str時:雖能將源圖像的細節傳遞至融合結果,但熱目標顯著性不足(如圖7(d)所示)。
- 使用基礎損失Lbase+輔助強度損失Laux-int時:熱信息突出,但細節特征丟失(如圖7(e)所示)。
- 使用多約束損失函數時:融合結果同時保留熱信息與紋理特征(如圖7(f)所示),且在各項定量指標上均取得最高平均值(如表1所示),證明所設計損失函數的有效性。
4.2.3 融合模塊影響
為評估融合策略中核心組件的有效性,分別移除CCAFusion的特征感知融合模塊(FAF)與特征增強融合模塊(FEF),分析其對融合性能的影響:
- 無FEF的融合網絡(記為“w/o FEF”)。
- 無FAF的融合網絡(記為“w/o FAF”)。
- 完整CCAFusion網絡。
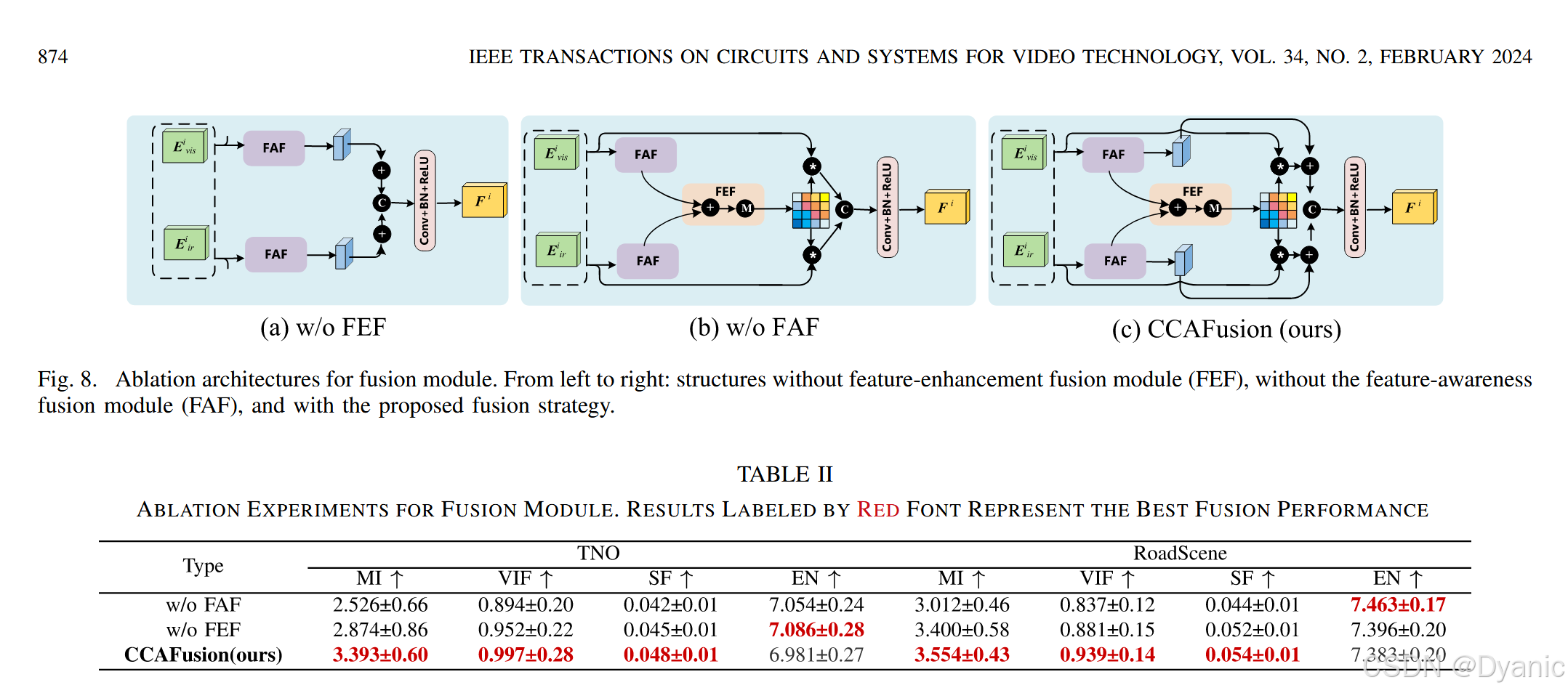
實驗結果如圖8與表2所示,分析如下:
- CCAFusion在互信息(MI)、視覺信息保真度(VIF)、空間頻率(SF)3項指標上均取得最高平均值:
- 互信息(MI)最優:表明CCAFusion能從源圖像向融合圖像傳遞更多信息。
- 視覺信息保真度(VIF)最優:表明融合結果與人類視覺感知的一致性更好。
- 空間頻率(SF)最優:表明所提方法保留細節信息的能力更優。
- 雖CCAFusion的熵(EN)與“w/o FEF”“w/o FAF”網絡差距較小,但結合4.3節與4.4節中與主流方法的對比可知,CCAFusion的融合結果仍包含豐富信息,整體性能更優。
4.2.4 注意力機制影響
為驗證坐標注意力(CAM)的有效性,將其與其他常用注意力機制(SE注意力、CBAM)進行對比:將CCAFusion中的CAM替換為SE注意力或CBAM,其他設置保持不變。不同注意力機制的圖像融合定量結果如表3所示。
結果表明,得益于CAM對關鍵通道信息、位置信息及長距離依賴關系的捕捉能力,采用CAM的CCAFusion在互信息(MI)、視覺信息保真度(VIF)、空間頻率(SF)3項指標上均取得最優值,熵(EN)與最優值差距較小,證明CAM在CCAFusion中的有效性。
4.3 對比實驗
在TNO數據集上,從定性與定量兩方面將CCAFusion與當前主流圖像融合方法進行對比,以評估其融合性能。
4.3.1 定性對比
為直觀展示不同融合方法的性能差異,從TNO數據集中選取3對圖像進行定性對比,結果如圖9~11所示。每幅圖中,圖像從左上到右下依次為:紅外圖像、可見光圖像、DenseFuse-add融合圖、DenseFuse-L1融合圖、MDLatLRR融合圖、SDNet融合圖、PIAFusion融合圖、U2Fusion融合圖、CCAFusion融合圖。為清晰展示差異,選取每幅融合圖中的局部區域(藍色框與橙色框)放大后置于角落,分析如下:
-
圖9:DenseFuse-add、MDLatLRR、SDNet、U2Fusion的融合結果雖在一定程度上保留了熱目標,但存在偽影問題。例如,MDLatLRR的融合圖中房屋邊緣、樹枝邊緣出現不良光暈或亮邊(藍色框所示),DenseFuse-add、SDNet、U2Fusion也存在類似現象;DenseFuse-L1的融合圖無偽影,但顯著目標與背景對比度不足,且與可見光圖像的天空區域不一致;PIAFusion的融合圖保留了背景信息,但丟失了部分樹枝紋理;CCAFusion的融合圖中樹枝紋理與可見光圖像最一致,且同時保留了紅外圖像中的顯著目標與可見光圖像中的細節,無偽影。
-
圖10~11:CCAFusion能有效融合源圖像的互補信息。具體而言,圖10中,除CCAFusion與PIAFusion外,其他方法的融合圖天空區域要么與可見光圖像不一致,要么存在偽影污染;而PIAFusion在復雜背景區域的熱輻射目標有所弱化。圖11中,CCAFusion與SDNet的融合圖熱輻射目標最顯著,但SDNet的融合圖背景云層與可見光圖像不一致。
綜上,CCAFusion既能有效突出紅外圖像中的顯著目標,又在保留可見光圖像的細節紋理方面具有優勢。
4.3.2 定量對比
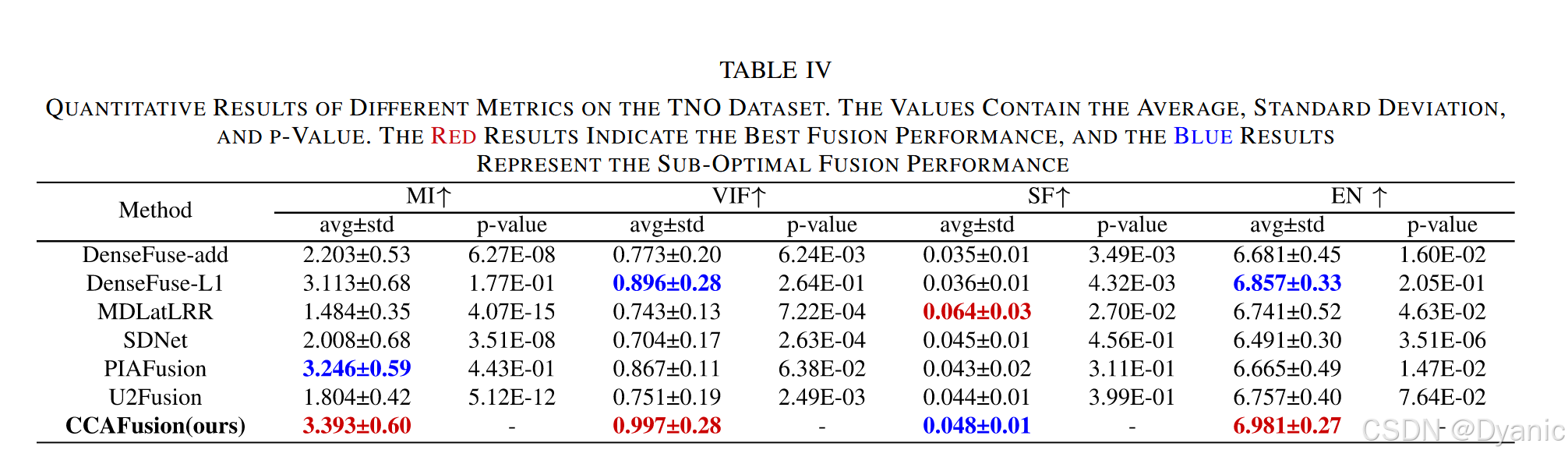
除視覺感知外,通過4種廣泛使用的定量指標進一步驗證CCAFusion的融合質量。圖12與表4展示了TNO數據集21對圖像在不同方法下的定量指標對比結果,分析如下:
- 圖12:展示了不同融合方法在各定量指標上的直方圖分布,數據越靠右偏,表明指標值越大,融合性能越好。
- 表4:列出了各指標的平均值、標準差及p值。由于指標值越大表示融合性能越好,p值基于單側右尾檢驗計算(p=Pr(T≥t|H?),其中T為所提方法的檢驗統計量,t為對比方法的檢驗統計量,H?為原假設,Pr為H?成立時T至少與t同樣極端的概率);紅色字體標注最優結果,藍色字體標注次優結果。
結果表明,在4項指標中,CCAFusion在互信息(MI)、視覺信息保真度(VIF)、熵(EN)3項指標上具有顯著優勢:
- 互信息(MI)更高:表明CCAFusion的融合圖從源圖像中獲取的信息更多。
- 視覺信息保真度(VIF)更高:表明CCAFusion的融合圖信息保真度更好,與人類視覺感知一致性更強。
- 熵(EN)更高:表明CCAFusion的融合圖包含的信息更豐富。
在空間頻率(SF)上,CCAFusion僅略低于MDLatLRR,原因是MDLatLRR產生的偽影與過度銳化導致其空間頻率(SF)偏高。
4.4 泛化實驗
為驗證CCAFusion的泛化能力,在RoadScene數據集上進行實驗。由于RoadScene數據集的可見光圖像為RGB圖像,采用3.5節所述的RGB-紅外融合策略實現融合。
4.4.1 定性對比
圖13~15展示了RoadScene數據集中3對圖像的融合結果,對比了不同融合算法的性能。為清晰觀察視覺差異,用橙色框與藍色框標記每幅圖像的局部區域并放大,分析如下:
DenseFuse-add、MDLatLRR、SDNet、U2Fusion的融合結果存在失真信息,具體表現為:
- 天空顏色失真(如圖13、圖15所示)。
- 路燈顏色失真(如圖14所示)。
DenseFuse-L1與PIAFusion的融合結果中,源圖像的紋理信息與顯著目標有所弱化(如圖13~15所示)。
值得注意的是,CCAFusion有效保留了源圖像中的紋理細節與顯著目標,無明顯失真。
4.4.2 定量對比
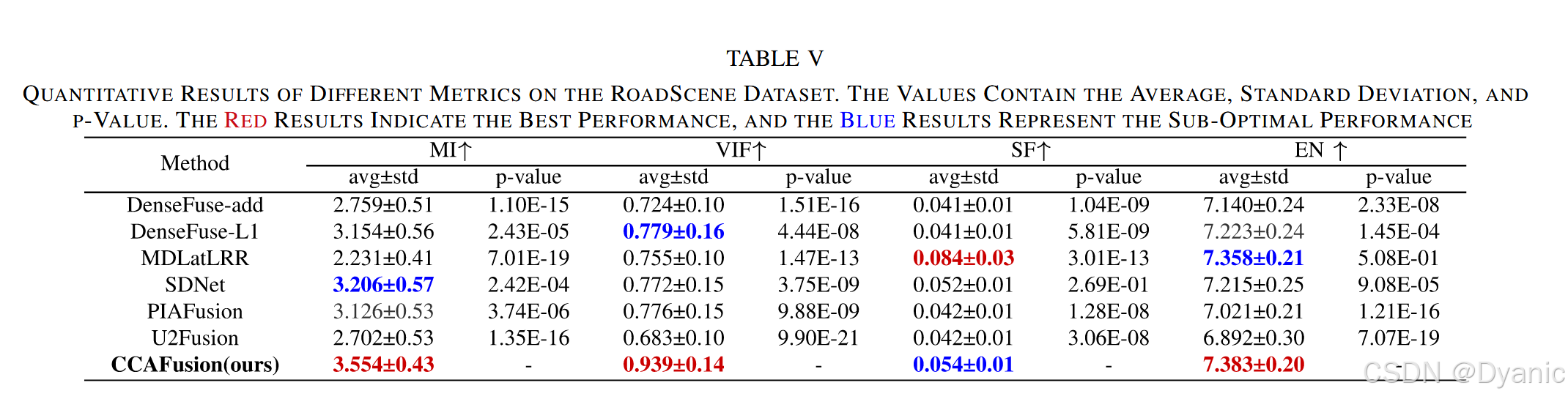
對RoadScene數據集進行定量評估,圖16與表5展示了該數據集61對圖像在不同方法下的定量指標對比結果:
- 圖16:展示了各定量指標的直方圖分布,數據越靠右偏,表明指標值越大,融合能力越強。
- 表5:列出了各指標的平均值、標準差及p值,最優結果用紅色標注。
結果表明,CCAFusion在RoadScene數據集上仍保持優異性能,進一步驗證了其良好的泛化能力。
4.5 效率對比
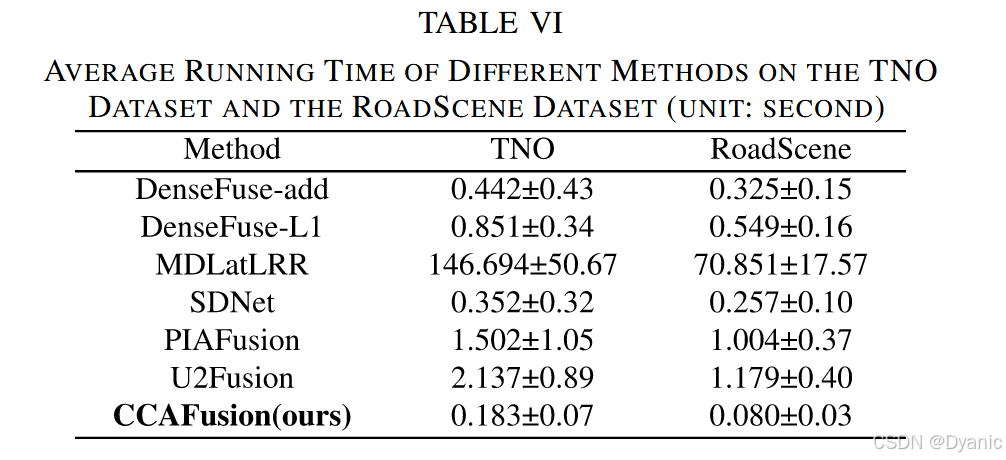
為對比所提方法與其他方法的處理速度,記錄不同方法在TNO數據集與RoadScene數據集上的平均運行時間,結果如表6所示。需注意:傳統方法(MDLatLRR)在AMD R7-4800H 2.90GHz CPU上運行,其他基于深度學習的方法均在Nvidia 2080Ti GPU上運行。
平均運行時間反映模型的處理速度,運行時間標準差反映模型的穩健性。結果表明:
- 得益于GPU加速,基于深度學習的方法顯著快于傳統方法。
- 與其他基于深度學習的方法相比,CCAFusion具有競爭力的運算效率與相當的穩健性,可作為高級視覺任務的預處理模塊高效部署。
4.6 顯著目標檢測應用
顯著目標檢測(SOD)是常見的高級視覺任務之一,旨在識別數字圖像中的顯著目標或區域。為進一步驗證所提融合方法的有效性,將源圖像與融合結果分別輸入顯著目標檢測方法[63],并在3個公開的紅外-可見光圖像對SOD數據集(VT821[64]、VT1000[65]、VT5000[66])上進行測試。
4.6.1 定性對比
圖17展示了典型示例,以說明CCAFusion在促進顯著目標檢測方面的優勢,分析如下:
- 可見光圖像:受背景限制,無法突出所有顯著目標,導致檢測結果區域不完整。
- 紅外圖像:當背景與顯著目標混淆時,檢測結果與真值(GT)差距較大。
- 融合圖像:相較于單模態圖像,對顯著目標檢測具有積極作用;其中,CCAFusion的融合圖像因具備強大的熱信息與紋理信息整合能力,檢測結果與真值最一致。
4.6.2 定量對比
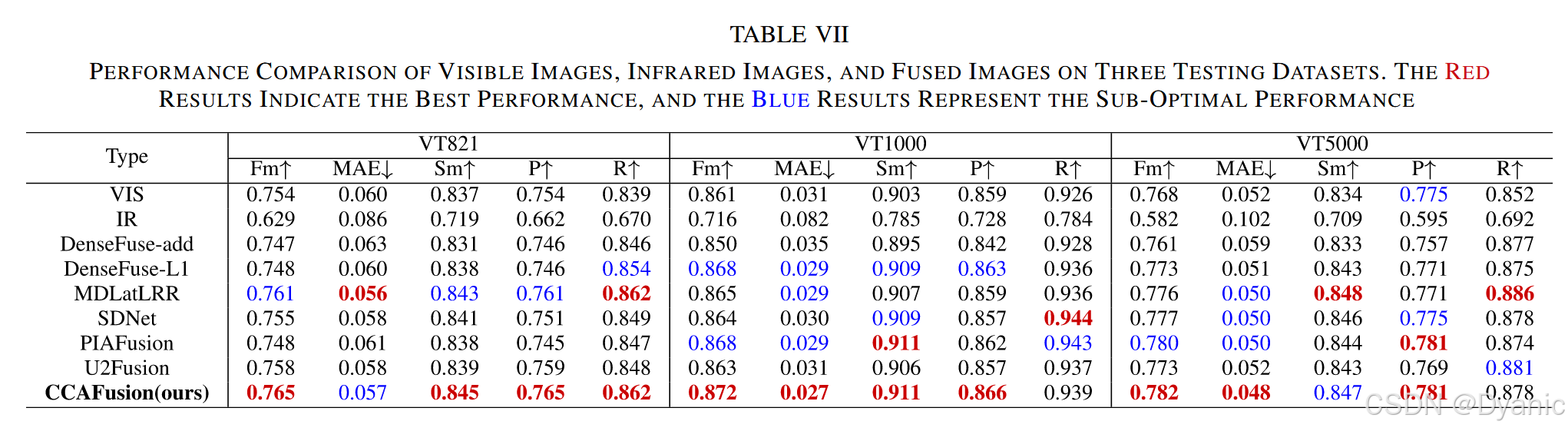
采用定量指標評估顯著目標檢測性能,結果如表7所示。所用指標定義如下:
- 精度(P)與召回率(R):分別為平均精度與平均召回率。
- F測度(Fm):精度與召回率的加權調和平均數,值越大檢測性能越好。
- S測度(Sm):評估預測圖與真值圖的空間結構相似度,值越大檢測性能越好。
- 平均絕對誤差(MAE):衡量預測圖與真值圖在像素級的平均相對誤差,值越小檢測性能越好。
表7對比了可見光圖像、紅外圖像及不同方法融合圖像的檢測性能,結果表明:
- 融合圖像的檢測性能優于單模態圖像,證明圖像融合對顯著目標檢測的積極作用。
- DenseFuse-add的融合圖像因融合層采用直接相加策略,檢測性能較差。
- CCAFusion的融合圖像在多數指標上具有明顯優勢,驗證了所提方法的有效性。
綜上,CCAFusion的融合圖像不僅在紅外-可見光圖像融合任務中表現優異,還能提升顯著目標檢測的性能。
4.6.3 注意力機制對比

為進一步對比坐標注意力(CAM)與其他注意力機制在CCAFusion中的性能,將CAM替換為常用的SE注意力與CBAM,其他設置與原CCAFusion一致。不同注意力機制的定性與定量結果分別如圖18與表8所示,分析如下:
- 定性結果(圖18):采用CAM的CCAFusion在顯著目標檢測中表現優于SE注意力與CBAM。
- 定量結果(表8):采用CAM的CCAFusion在多數指標上優于其他注意力機制。
優勢原因分析:
- SE注意力:僅考慮通道間信息,忽略位置信息的重要性。
- CBAM:雖同時考慮通道信息與位置信息,但缺乏長距離依賴關系捕捉能力。
- CAM:可同時捕捉通道與位置重要性及長距離依賴關系,因此CCAFusion采用CAM能獲得更優性能。
5 結論
本文提出一種用于紅外與可見光圖像融合的高效跨模態坐標注意力網絡(CCAFusion),具體工作如下:
- 設計跨模態坐標注意力融合策略,實現互補特征的有效融合;將該融合策略應用于不同尺度,以充分利用多層次信息。
- 定義由基礎損失與輔助損失組成的多約束損失函數,用于調整融合圖像的灰度分布,確保其結構與強度和諧共存。
大量對比實驗表明,無論是定性評價還是定量指標,CCAFusion均優于當前主流圖像融合方法;此外,在顯著目標檢測上的擴展實驗證明,CCAFusion能有效促進高級視覺任務的性能。






)


)







】)

