7GB顯存如何部署bf16精度的DeepSeek-R1 70B大模型?-CSDN博客
服務容錯治理框架resilience4j&sentinel基礎應用---微服務的限流/熔斷/降級解決方案-CSDN博客
conda管理python環境-CSDN博客
快速搭建對象存儲服務 - Minio,并解決臨時地址暴露ip、短鏈接請求改變瀏覽器地址等問題-CSDN博客
大模型LLMs的MCP入門-CSDN博客
使用LangGraph構建多代理Agent、RAG-CSDN博客
大模型LLMs框架Langchain之鏈詳解_langchain.llms.base.llm詳解-CSDN博客
大模型LLMs基于Langchain+FAISS+Ollama/Deepseek/Qwen/OpenAI的RAG檢索方法以及優化_faiss ollamaembeddings-CSDN博客
大模型LLM基于PEFT的LoRA微調詳細步驟---第二篇:環境及其詳細流程篇-CSDN博客
大模型LLM基于PEFT的LoRA微調詳細步驟---第一篇:模型下載篇_vocab.json merges.txt資源文件下載-CSDN博客?使用docker-compose安裝Redis的主從+哨兵模式_使用docker部署redis 一主一從一哨兵模式 csdn-CSDN博客
docker-compose安裝canal并利用rabbitmq同步多個mysql數據_docker-compose canal-CSDN博客
目錄
技術體系
PythonAI ---- 本文主要是本地Ollama加載模型
流式輸出核心代碼
?完整的代碼
JavaAI
引入依賴
返回Flux流 --- 測試
解決中文亂碼問題
結合Python流接口
初始化WebClient
接收String流
接收JSON流
日志&錯誤處理
移除多余的前綴
保存歷史記錄
完整代碼
SpringBoot啟動---瀏覽器請求
Test/Main啟動
Vue前端
創建項目
HBuilderX創建
使用命令創建
?修改HelloWorld.vue
請求測試
寫在前文:之所以設計這一套流程,是因為 Python在前沿的科技前沿的生態要比Java好,而Java在企業級應用層開發比較活躍;
畢竟許多企業的后端服務、應用程序均采用Java開發,涵蓋權限管理、后臺應用、緩存機制、中間件集成及數據庫交互等方面。但是現在的AI技術生態發展得很快,而Python在科研(數據科學/機器學習領域)語言,在這方面有天然的優勢;所以為了接入大模型LLMs,選擇用Python接入大模型LLMs,然后通過FastAPI發布HTTP接口,讓Java層負責與前端Vue.js應用及Python流接口進行交互,這樣的話,前端直接訪問Java應用,企業應用只需要保持現有生態即可,當前的權限、后臺應用、緩存、中間件等流程都不用再Python端再次開發,省去了很多工作;
整個流程如下: python負責和模型交互---Java作為中間層負責和前端Vue以及Python流接口交互-----Vue負責展示;
技術體系
PythonAI端:
- LLM模型:本地ChatOllama+Qwen VLLm+Qwen、本地通過HF的Transformer加載- Embedding向量:OllamaEmbedding + nomic-embed-text:latest- 向量庫FAISS:使用本地版本的Faiss庫- 檢索優化:混合(二階段)檢索:similarity_score_threshold相似性打分(向量檢索)+BM25(關鍵字)檢索構成的混合檢索 結合 FlashRank重排序優化檢索繼續優化,多階段檢索:多查詢檢索(LLM擴展)、混合檢索(向量檢索+BM25關鍵字檢索)、重排序優化、LLM壓縮;---之所以不使用多查詢LLM擴展和LLM壓縮,是因為性能問題---在使用LLM壓縮時,最好結合微調效果會好很多,不然可能會排除掉一些問題和答案關聯性不強但實際上是一一對應的問題答案;使用單獨使用混合檢索的時候滿足絕大多數情況;- 重排序:離線的FlashRankRerank+默認ms-marco-MultiBERT-L-12模型
- 流輸出:使用StreamingResponse包裝結合yield關鍵字;
- 性能優化:調用astream的異步執行方法/如果要使用stream同步方法,那么使用iterate_in_threadpool轉異步/也可以使用async+with來管理異步執行
JavaAI端:
- 核心:Springboot
- 請求流接口:WebClient
- 返回流結果:Flux前端:vue3+vite構建項目核心接口主要包含下面的功能:
Python的流輸出:Python通過yield定義一個生成器函數(可以不間斷的返回數據),然后通過“StreamingResponse”包裝后流式返回;
---注意:return是一次性返回;
Java請求流接口:在Java端我們使用WebClient請求Python的流接口;
Java流輸出:將結果轉為Flux類型的數據返回到前端頁面;
---?此時這兩個接口,都是可以直接通過瀏覽器訪問接口查看效果
--- 如果使用Postman,必須返回標準的SSE格式的數據,不然是看不到效果的;
SSE數據格式:每個數據塊以"data: "開頭,結尾加兩個換行符
PythonAI ---- 本文主要是本地Ollama加載模型
下一篇更新:云服務通過VLLm部署模型,然后本地使用OpenAI加載云端的VLLm模型;以及“使用HuggingFace的原生Transformer加載LLM”
流式輸出核心代碼
主要是通過yield定義一個生成器函數,再通過StreamingResponse包裝返回,注意設置media_type="text/event-stream;charset=utf-8"
def llm_astream(self, faiss_query):from fastapi.concurrency import iterate_in_threadpoolsync_generator = self.chain.astream(faiss_query)# 如果 chain.stream 是同步生成器,使用 iterate_in_threadpool 轉換為異步async for chunk in iterate_in_threadpool(sync_generator):# yield chunk.content# 標準的SEE數據格式;如果不修改為下面這個,那么在使用Java的WebClient請求時,返回的是空白/報錯。# # 包裝成SSE格式,每個數據塊以"data: "開頭,結尾加兩個換行符# yield f"data: {chunk.content}\n\n" # 使用String字符串返回import json# 統一返回Json格式,并且禁止Unicode編碼---不然返回的就是Unicode編碼后的代碼yield f"data: {json.dumps({'content': chunk.content}, ensure_ascii=False)}\n\n" # # 如果 chain.stream 本身是異步生成器,直接使用:# async for chunk in self.chain.stream(faiss_query):# yield chunk.content@app.get("/stream")
async def llm_stream(query: str):from starlette.responses import StreamingResponsereturn StreamingResponse( # 使用StreamingResponse包裝,流返回retriever.llm_astream(query),media_type="text/event-stream;charset=utf-8" # text/plain、text/event-stream;強制響應頭charset=utf-8)?注意:此種方法可以使用瀏覽器看到效果;但是用Postman---如果不是標準的SSE格式數據就看不到效果;
注意:我們返回數據時一定要返回SSE格式的數據,不然Java端要報錯“java.lang.NullPointerException: The mapper [xxxxxxx$$Lambda$880/0x0000000801118d08] returned a null value”;
SSE標準格式,返回JSON格式版本:yield f"data: {json.dumps({'content': chunk.content})}\n\n"
????????Java端使用“ServerSentEvent”事件接收;
SSE標準格式,返回字符串格式版本:yield f"data: {chunk.content}\n\n"
????????Java端使用“String”事件接收;
?完整的代碼
下面關于檢索優化、構建鏈、llm交互、rag知識入庫、向量庫、Ollama加載云端API等...技術知識見我之前發的幾篇文章;---- 安裝了依賴以后,可以直接運行下面代碼;
請求地址:http://localhost:8000/astream?query=xxxxx
---還可以訪問stream接口看看使用異步協程、同步返回的不同效果;
"""檢索agent"""
import asynciofrom langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
from langserve import add_routesdef log_retrieved_docs(ctx):# print(f"[{ctx['msgid']}] [{ctx['query']}] Retrieved documents:[{ctx['content']['content']}]")print(f"Retrieved documents:[{ctx}]")return ctx # 確保返回原數據繼續鏈式傳遞class RetrieverLoad:def __init__(self):print("加載向量庫...")from langchain_ollama import OllamaEmbeddingsself.faiss_persist_directory = 'faiss路徑'self.embedding = OllamaEmbeddings(model='nomic-embed-text:latest')self.faiss_index_name = 'faiss_index名稱'self.faiss_vector_store = self.load_embed_store()self.llm = ChatOllama(model="qwen2.5:3b")self.prompt = ChatPromptTemplate.from_template(retriver_template)self.retriever = self.retriever()self.chain = self.llm_chain()def load_embed_store(self):return FAISS.load_local(self.faiss_persist_directory,embeddings=self.embedding,index_name=self.faiss_index_name, # 需與保存時一致allow_dangerous_deserialization=True)def retriever(self, score_threshold: float = 0.5, k: int = 5):sst_retriever = self.faiss_vector_store.as_retriever(search_type='similarity_score_threshold',search_kwargs={"score_threshold": score_threshold, "k": k})# 初始化BM25檢索# (使用公共方法獲取文檔)documents = list(self.faiss_vector_store.docstore._dict.values())from langchain_community.retrievers import BM25Retrieverbm25_retriever = BM25Retriever.from_documents(documents,k=20, # 返回數量k1=1.5, # 默認1.2,增大使高頻詞貢獻更高b=0.8 # 默認0.75,減小以降低文檔長度影響)# 混合檢索:BM25+embedding的from langchain.retrievers import EnsembleRetrieverensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, sst_retriever],weights=[0.3, 0.7])# 混合檢索后 重排序# 構建壓縮管道:重排序 + 內容提取from flashrank import Rankerfrom langchain_community.document_compressors import FlashrankRerankflashrank_rerank = FlashrankRerank(client=Ranker(cache_dir='D://A4Project//LLM//flash_rankRerank//'),top_n=8)# 三階段檢索:粗檢索、重排序、內容壓縮from langchain.retrievers import ContextualCompressionRetrieverbase_retriever = ContextualCompressionRetriever(# step1. 粗檢索---30% BM25+70% Embedding向量檢索base_retriever=ensemble_retriever,# step2. 重排序---FlashRankbase_compressor=flashrank_rerank)# step3、內容壓縮---LLM---部分場景不推薦使用LLM內容壓縮,壓縮可能會刪除RAG里面原本Q&A對應但是答案中不包含問題,導致關聯性小的數據;而且很影響性能# from langchain.retrievers.document_compressors import LLMChainExtractor# # 重排序后 壓縮上下文# compressor_prompt = """# 鑒于以下問題和內容,提取與回答問題相關的背景*按原樣*的任何部分。如果上下文都不相關,則返回{no_output_str}。# 記住,*不要*編輯提取上下文的部分。# 問題: {{question}}# 內容: {{context}}# 提取相關部分:# """# from langchain_core.prompts import PromptTemplate# compressor_prompt_template = PromptTemplate(# input_variables=['question', 'context'],# template=compressor_prompt.format(no_output_str='NO_OUTPUT'))# compressor = LLMChainExtractor.from_llm(prompt=compressor_prompt_template, llm=self.llm)# # compressor = LLMChainExtractor.from_llm(llm=self.llm)# pipeline_retriever = ContextualCompressionRetriever(# base_retriever=base_retriever,# base_compressor=compressor# )return base_retrieverdef llm_chain(self):# 處理檢索結果的函數(將文檔列表轉換為字符串)from langchain_core.runnables import RunnableLambda# process_docs = RunnableLambda(lambda docs: "\n".join([doc.page_content for doc in docs]))from langchain_core.runnables import RunnablePassthroughprompt = """請根據以下內容回答問題,內容中如果沒有的那就回答“請咨詢人工...”,內容中如果有其他不相干的內容,直接刪除即可。內容:{content}問題:{query}回答:"""prompt_template = ChatPromptTemplate.from_template(prompt)from operator import itemgetterchain = (# RunnableLambda(log_retrieved_docs) | # 直接打印傳遞進來的參數{# 這個content和query會繼續往下傳遞,直到prompt --->{content}、{query}"content": RunnableLambda(lambda x: x["query"]) # 必須,不然要報錯“TypeError: Expected a Runnable, callable or dict.Instead got an unsupported type: <class 'str'”| self.retriever # 檢索# | RunnableLambda(log_retrieved_docs) # 打印出檢索到的文檔,檢索后未處理# 先檢索再處理文檔| RunnableLambda(lambda docs: "\n".join([doc.page_content for doc in docs])),# | process_docs # 先檢索再處理文檔 --- 和上面方法二選一# | RunnableLambda(log_retrieved_docs), # 打印出檢索后的文檔 --- 這里傳遞的僅僅是檢索到的內容且預處理后的內容"query": itemgetter("query"), # 直接傳遞用戶原始問題"msgid": RunnableLambda(lambda x: x["msgid"]), # 顯示傳遞msgid --- 和itemgetter同樣的效果}| RunnableLambda(log_retrieved_docs) # 傳遞的是前面整個content、query、msgid的值到日志中| prompt_template # 組合成完整 prompt| self.llm # 傳給大模型生成回答# | RunnableLambda(log_retrieved_docs) # 傳遞的是LLM生成的內容 --- 但是在這一步以后,系統會同步返回---不推薦在這里打印日志)return chainasync def llm_invoke(self, query):return self.chain.invoke(query)async def retriever_stream(self, query):return self.retriever.stream(query)async def llm_astream(self, query: str, msgid: str):# 直接使用astream 異步執行chunks = []result = ""async for chunk in self.chain.astream({"query": query, "msgid": msgid}):chunks.append(chunk.content)result += chunk.content# yield chunk.content# 標準的SEE數據格式;如果不修改為下面這個,那么在使用Java的WebClient請求時,返回的是空白/報錯。# # 包裝成SSE格式,每個數據塊以"data: "開頭,結尾加兩個換行符import json# 統一返回Json格式,并且禁止Unicode編碼---不然返回的就是Unicode編碼后的代碼yield f"data: {json.dumps({'content': chunk.content}, ensure_ascii=False)}\n\n"print(f"query:{query} msgid:{msgid} llm:{result}")# # 如果 chain.stream 本身是異步生成器,直接使用:# async for chunk in self.chain.stream(query):# yield chunk.contentasync def llm_stream(self, query):from fastapi.concurrency import iterate_in_threadpool# 如果 chain.stream 是同步生成器,使用 iterate_in_threadpool 轉換為異步async for chunk in iterate_in_threadpool(self.chain.stream(query)):# yield chunk.content# 標準的SEE數據格式;如果不修改為下面這個,那么在使用Java的WebClient請求時,返回的是空白/報錯。# # 包裝成SSE格式,每個數據塊以"data: "開頭,結尾加兩個換行符import json# 統一返回Json格式,并且禁止Unicode編碼---不然返回的就是Unicode編碼后的代碼yield f"data: {json.dumps({'content': chunk.content}, ensure_ascii=False)}\n\n"# # 如果 chain.stream 本身是異步生成器,直接使用:# async for chunk in self.chain.stream(query):# yield chunk.contentfrom fastapi import FastAPIapp = FastAPI(title='ruozhiba', version='1.0.0', description='ruozhiba檢索')
# 添加 CORS --- 跨域 中間件
from fastapi.middleware.cors import CORSMiddleware
app.add_middleware(CORSMiddleware,allow_origins=["*"], # 允許所有來源,生產環境建議指定具體域名allow_credentials=True, # 允許攜帶憑證(如cookies)allow_methods=["*"], # 允許所有HTTP方法(可選:["GET", "POST"]等)allow_headers=["*"], # 允許所有HTTP頭
)
# 同步返回
@app.get("/invoke")
async def llm_invoke(query: str):results = await retriever.llm_invoke(query)return {"results": results.content}@app.get("/retriever")
async def retriever_stream(query: str):return await retriever.retriever_stream(query)# 流式輸出——異步執行
@app.get("/astream")
async def astream(query: str, msgid: str):from starlette.responses import StreamingResponseprint(f"請求開始:query:{query} msgid:{msgid}")return StreamingResponse(retriever.llm_astream(query, msgid),media_type="text/event-stream;charset=utf-8" # text/plain、text/event-stream;強制響應頭charset=utf-8)# 流式輸出——同步執行
@app.get("/stream")
async def llm_stream(query: str):from starlette.responses import StreamingResponsereturn StreamingResponse(retriever.llm_stream(query),media_type="text/event-stream;charset=utf-8" # text/plain、text/event-stream;強制響應頭charset=utf-8)
if __name__ == '__main__':# asyncio.run(main())import uvicornretriever = RetrieverLoad()uvicorn.run(app, host='localhost', port=8000)JavaAI
引入依賴
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.1.1</version><relativePath/> <!-- lookup parent from repository --></parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId></dependency></dependencies>返回Flux流 --- 測試
---瀏覽器訪問就可以看到流效果...但是中文的話,會是亂碼;
@GetMapping(value = "/chat", produces = MediaType.TEXT_EVENT_STREAM_VALUE)public Flux<String> chat() {
// Thread.sleep()會阻塞線程,改用Flux.interval實現非阻塞延遲:return Flux.interval(Duration.ofMillis(100)) // 每100ms生成一個數字.map(i -> "消息:" + i) // 轉換為消息字符串.take(10); // 限制總數量為10000條
// return Flux.create(emitter -> {
// // 模擬數據流
// for (int i = 0; i < 10000; i++) {
// emitter.next("Message " + i);
// try {
// Thread.sleep(100); // 模擬延遲
// } catch (InterruptedException e) {
// emitter.error(e);
// }
// }
// emitter.complete();
// });}解決中文亂碼問題
如果不使用Filter,那么在返回前端頁面的時候會是中文亂碼;
@Component
@Order(Ordered.HIGHEST_PRECEDENCE)
public class FluxPreProcessorFilter implements Filter {@Overridepublic void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)throws IOException, ServletException {response.setCharacterEncoding("UTF-8");chain.doFilter(request, response);}
}結合Python流接口
初始化WebClient
private final WebClient webClient;public ChatMsgController(WebClient.Builder webClientBuilder) {this.webClient = webClientBuilder.clientConnector(new ReactorClientHttpConnector(HttpClient.create().responseTimeout(Duration.ofSeconds(30)) // 第一次請求可以設置長點.compress(false) // 關閉壓縮(如果開啟可能緩沖)))// .codecs(configurer -> configurer.defaultCodecs().maxInMemorySize(256 * 1024 * 1024))// .defaultHeader(HttpHeaders.AUTHORIZATION, "Bearer " + openAi)// 網上說:必須設置為JSON格式;初始設置MediaType.TEXT_EVENT_STREAM_VALUE會導致請求失敗,必須使用APPLICATION_JSON_VALUE// 實際測試,與這無關
// .defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE).baseUrl("http://localhost:8000") // python項目地址.build();}接收String流
public Flux<Object> stream(String query) {return webClient.get().uri("/stream?query={query}", query).accept(MediaType.TEXT_EVENT_STREAM).retrieve().bodyToFlux(String.class).doOnError(e->System.err.println("發生錯誤: " + e.getMessage()));}接收JSON流
public Flux<String> stream(String query) {return webClient.get().uri("/stream?query={query}", query).accept(MediaType.TEXT_EVENT_STREAM).retrieve().bodyToFlux(ServerSentEvent.class)// 解析為標準的SSE事件.mapNotNull(ServerSentEvent::data) // 提取標準的SEE數據格式的 數據部分.doOnError(e->System.err.println("發生錯誤: " + e.getMessage())).map(Object::toString); // 返回是否需要根據情況來定 --- 如果不需要,返回“Flux<Object>”即可}日志&錯誤處理
public Flux<String> stream(@PathVariable("query") String query) {String msgid = UUID.randomUUID().toString().replace("-", "");log.info("請求開始。msgid:{},query:{}", msgid, query);return webClient.get().uri("/stream?query={query}", query).accept(MediaType.TEXT_EVENT_STREAM).retrieve()// 請求失敗返回錯誤。// 狀態碼 --- 當未請求成功時的異常.onStatus(HttpStatusCode::isError, response -> {log.error("錯誤狀態碼。msgid:{},query:{},errorCode:{}", msgid, query, response.statusCode());return response.bodyToMono(String.class).flatMap(body -> Mono.error(new RuntimeException("HTTP錯誤: " + body)));}).bodyToFlux(String.class).log() // 打印日志.doOnNext(data -> System.out.println("接收到數據塊:" + data)) // 打印接收到的數據.doOnError(e -> log.error("發生錯誤。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 請求成功后,返回來的異常}移除多余的前綴
@GetMapping(value = "/astream/{query}", produces = MediaType.TEXT_EVENT_STREAM_VALUE)public Flux<String> astream(@PathVariable("query") String query) {String msgid = UUID.randomUUID().toString().replace("-", "");log.info("請求開始。msgid:{},query:{}", msgid, query);return webClient.get().uri("/astream?query={query}&msgid={msgid}", query, msgid).accept(MediaType.TEXT_EVENT_STREAM).retrieve().onStatus(HttpStatusCode::isError, response -> {log.error("錯誤狀態碼。msgid:{},query:{},errorCode:{}", msgid, query, response.statusCode());return response.bodyToMono(String.class).flatMap(body -> Mono.error(new RuntimeException("HTTP錯誤: " + body)));}).bodyToFlux(String.class) // 轉為String// 移除多余的Python返回的前綴; --- 因為我們返回給前端的也是SSE數據格式,所以返回的數據也是默認會有data:.map(x -> x.substring(0, x.length() - 2).replace("{\"content\": \"", "")) .doOnError(e -> log.error("發生錯誤。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 請求成功后,返回來的異常.map(Object::toString);}保存歷史記錄
public Flux<String> astream(@PathVariable("query") String query) {String msgid = UUID.randomUUID().toString().replace("-", "");log.info("請求開始。msgid:{},query:{}", msgid, query);Flux<String> dataFlux = webClient.get().uri("/astream?query={query}&msgid={msgid}", query, msgid).accept(MediaType.TEXT_EVENT_STREAM).retrieve()// 通過cache()共享數據流,單獨訂閱以保存數據,避免重復請求,確保保存操作僅觸發一次。// 必須開啟,不然在后續執行"dataFlux.collectList()/ dataFlux.reduce"會再次發起請求// 不開啟cache的話---相當于前端請求一次,后端發起了三次請求.cache().doOnError(e -> log.error("發生錯誤。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 請求成功后,返回來的異常.map(Object::toString);// 單獨訂閱以收集并保存數據 --- 下面是測試方法,二選一// 使用.collectList() 收集成一個完整的 List<String>,打印出來的list是一個chunk,["你好", ",世界", "!"]// 自己拼裝ListdataFlux.collectList() //.flatMap(list -> {String join = String.join("", list);log.info("觸發collectList保存。msgid:{},query:{},llm:{}", msgid, query, join);return Mono.just(join);}).subscribeOn(Schedulers.boundedElastic()).subscribe(null,error -> log.error("collectList保存失敗。msgid:{},query:{}", msgid, query, error),() -> log.info("collectList數據已保存。msgid:{},query:{}", msgid, query));// 使用reduce,合并ChunkdataFlux.reduce((a, b) -> a + b).flatMap(list -> {log.info("觸發reduce保存。msgid:{},query:{},llm:{}", msgid, query, list);return Mono.just(list);}).subscribeOn(Schedulers.boundedElastic()).subscribe(null,error -> log.error("reduce保存失敗。msgid:{},query:{}", msgid, query, error),() -> log.info("reduce數據已保存。msgid:{},query:{}", msgid, query));return dataFlux;}完整代碼
SpringBoot啟動---瀏覽器請求
@RestController
@RequestMapping("/ai")
@CrossOrigin("*")
@Slf4j
public class ChatMsgController {private final WebClient webClient;public ChatMsgController(WebClient.Builder webClientBuilder) {this.webClient = webClientBuilder.clientConnector(new ReactorClientHttpConnector(HttpClient.create().responseTimeout(Duration.ofSeconds(60)).compress(false) // 關閉壓縮(如果開啟可能緩沖)))
// .codecs(configurer -> configurer.defaultCodecs().maxInMemorySize(256 * 1024 * 1024))// .defaultHeader(HttpHeaders.AUTHORIZATION, "Bearer " + openAi)// ?? 必須設置為JSON格式;初始設置MediaType.TEXT_EVENT_STREAM_VALUE會導致請求失敗,必須使用APPLICATION_JSON_VALUE
// .defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE).baseUrl("http://localhost:8000").build();}@GetMapping(value = "/astream/{query}", produces = MediaType.TEXT_EVENT_STREAM_VALUE)public Flux<String> astream(@PathVariable("query") String query) {String msgid = UUID.randomUUID().toString().replace("-", "");log.info("請求開始。msgid:{},query:{}", msgid, query);Flux<String> dataFlux = webClient.get().uri("/astream?query={query}&msgid={msgid}", query, msgid).accept(MediaType.TEXT_EVENT_STREAM).retrieve()// 請求失敗返回錯誤。// 狀態碼 --- 當未請求成功時的異常.onStatus(HttpStatusCode::isError, response -> {log.error("錯誤狀態碼。msgid:{},query:{},errorCode:{}", msgid, query, response.statusCode());return response.bodyToMono(String.class).flatMap(body -> Mono.error(new RuntimeException("HTTP錯誤: " + body)));}).bodyToFlux(String.class) // 轉為String
// .bodyToFlux(ServerSentEvent.class) // 解析為標準的SSE事件
// .mapNotNull(ServerSentEvent::data) // 提取標準的SEE數據格式的 數據部分.map(x -> x.substring(0, x.length() - 2).replace("{\"content\": \"", ""))
// .log() // 打印日志 --- 這個日志是一個chunk一個chunk打印的.cache()// 通過cache()共享數據流,單獨訂閱以保存數據,避免重復請求,確保保存操作僅觸發一次。必須開啟,不然在后續執行"dataFlux.collectList()/ dataFlux.reduce"會再次發起請求---相當于前端請求一次,后端發起了三次請求
// .doOnNext(data -> System.out.println("接收到數據塊:" + data)) // 打印接收到的數據.doOnError(e -> log.error("發生錯誤。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 請求成功后,返回來的異常.map(Object::toString);// 單獨訂閱以收集并保存數據// 使用.collectList() 收集成一個完整的 List<String>,打印出來的list是一個chunk,["你好", ",世界", "!"]// 自己拼裝ListdataFlux.collectList() //.flatMap(list -> {String join = String.join("", list);log.info("觸發collectList保存。msgid:{},query:{},llm:{}", msgid, query, join);return Mono.just(join);}).subscribeOn(Schedulers.boundedElastic()).subscribe(null,error -> log.error("collectList保存失敗。msgid:{},query:{}", msgid, query, error),() -> log.info("collectList數據已保存。msgid:{},query:{}", msgid, query));// 使用reduce,合并ChunkdataFlux.reduce((a, b) -> a + b).flatMap(list -> {log.info("觸發reduce保存。msgid:{},query:{},llm:{}", msgid, query, list);return Mono.just(list);}).subscribeOn(Schedulers.boundedElastic()).subscribe(null,error -> log.error("reduce保存失敗。msgid:{},query:{}", msgid, query, error),() -> log.info("reduce數據已保存。msgid:{},query:{}", msgid, query));return dataFlux;}
}Test/Main啟動
public class StreamApiClient {public void streamData(String query) {
// WebClient client = WebClient.create("http://localhost:8000");WebClient client = WebClient.builder().clientConnector(new ReactorClientHttpConnector(HttpClient.create().responseTimeout(Duration.ofSeconds(10))
// .compress(false) // 關閉壓縮(如果開啟可能緩沖)))
// .defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE).baseUrl("http://localhost:8000").build();Flux<String> stream = client.get().uri("/stream?query={query}", query).accept(MediaType.TEXT_EVENT_STREAM).retrieve().onStatus(HttpStatusCode::isError, response -> { // 請求失敗返回錯誤System.out.println("錯誤狀態碼: " + response.statusCode());return response.bodyToMono(String.class).flatMap(body -> Mono.error(new RuntimeException("HTTP錯誤: " + body)));}).bodyToFlux(String.class)
// .log()
// .doOnNext(data -> System.out.println("接收到數據塊:" + data)).doOnError(e -> System.err.println("發生錯誤: " + e.getMessage()));stream.subscribe(chunk -> System.out.println("Received chunk: " + chunk),error -> System.err.println("Error: " + error),() -> System.out.println("Stream completed"));}public static void main(String[] args) throws InterruptedException {StreamApiClient streamApiClient = new StreamApiClient();streamApiClient.streamData("五塊能娶幾個老婆");Thread.sleep(40000); // 可以適當提升時間,不然可能程序還沒得到返回就結束了,看不到效果}
}Vue前端
前端使用vue3+vite構建
創建項目
HBuilderX創建

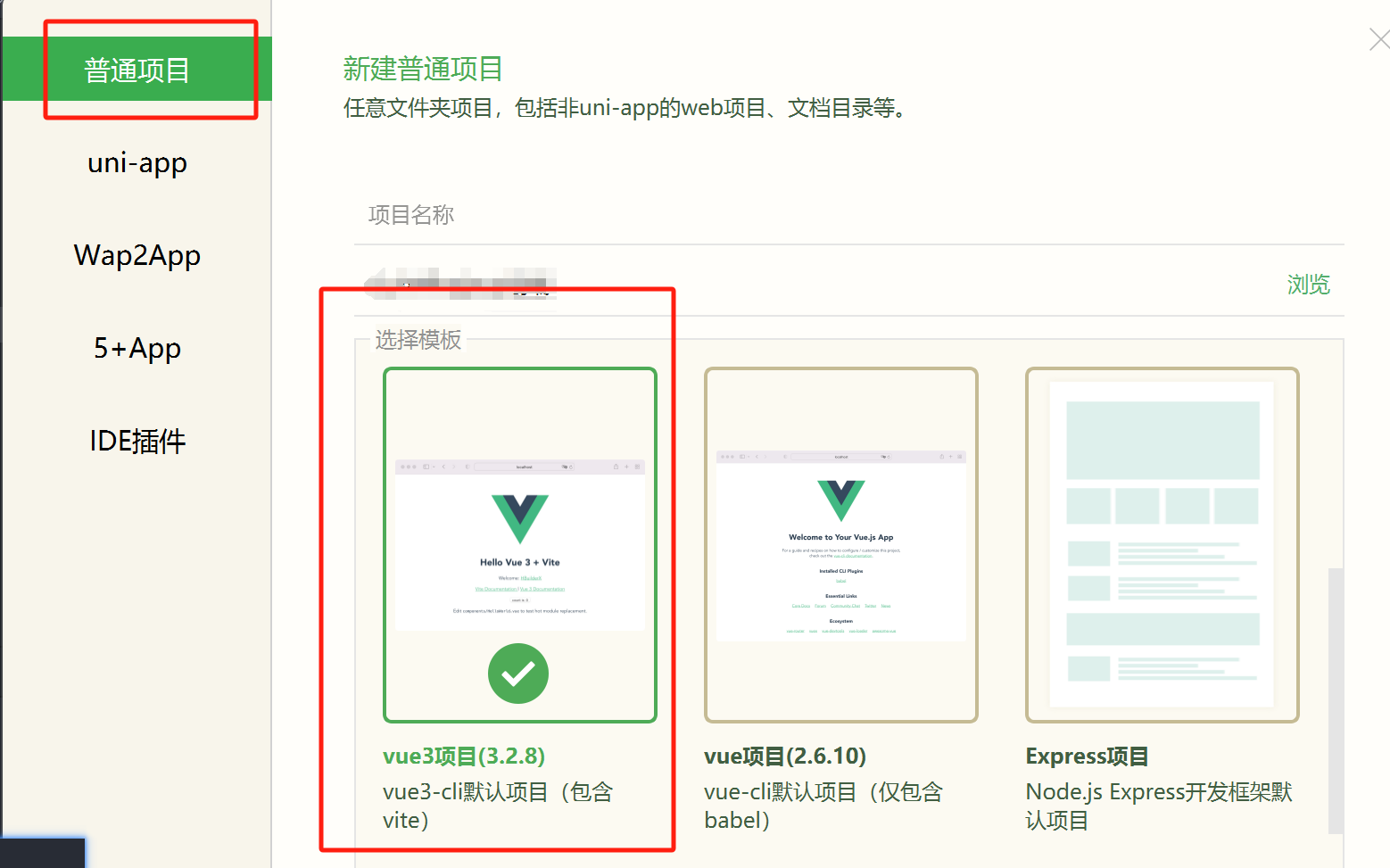
使用命令創建
npm create vite@latest my-vue-app -- --template vue # 創建項目
cd my-vue-app # 進入到項目中
npm install # 安裝依賴
npm run dev # 運行dev環境項目<!-- 其中: -->
<!-- index.html 主要是標簽---包含標簽頁itme樣式; -->
<!-- src/App.vue ---主頁訪問,系統 import HelloWorld from './components/HelloWorld.vue'導入了HelloWorld.vue? -->
<!-- src/components/HelloWorld.vue ---剛開始是廣告頁,可以修改內容 -->
<!-- 所以啟動成功后,訪問"http://localhost:3000/index"會直接進入HelloWorld.vue; -->
<!-- 我們現在只需要修改HelloWorld.vue即可 -->?修改HelloWorld.vue
<template><div><input v-model="query" placeholder="輸入查詢內容" class="query-input" /><button @click="startStream" class="action-button start-button">調用Java接收流</button><button @click="chatStream" class="action-button start-button">調用Chat接口測試</button><button @click="pythonStream" class="action-button start-button">調用python接口</button><button @click="closeStream" class="action-button stop-button">停止接收</button><div class="result-container"><pre class="response-data">{{ responseData }}</pre><div>這個數據來源于App的MSG組件:{{msg}}</div></div></div>
</template>
<script setup>
import { ref, onBeforeUnmount } from 'vue'// Props 定義
const props = defineProps({msg: String
})// 響應式數據
const query = ref('為什么砍頭不找死刑犯來演')
const responseData = ref('')
const eventSource = ref(null)// 方法
const pythonStream = () => {closeStream()responseData.value = ''const url = `http://localhost:8000/astream?query=${encodeURIComponent(query.value)}&msgid=123456`eventSource.value = new EventSource(url)eventSource.value.onmessage = (event) => {const data = JSON.parse(event.data)responseData.value += data.content + "\n"}eventSource.value.onerror = (error) => {console.warn("EventSource warn:", error)closeStream()}
}const chatStream = () => {closeStream()responseData.value = ''const url = `http://localhost:8080/ai/chat`eventSource.value = new EventSource(url)eventSource.value.onmessage = (event) => {responseData.value += event.data + "\n"}eventSource.value.onerror = (error) => {console.warn("EventSource warn:", error)closeStream()}
}const startStream = () => {closeStream()responseData.value = ''const url = `http://localhost:8080/ai/astream/${encodeURIComponent(query.value)}`eventSource.value = new EventSource(url)eventSource.value.onmessage = (event) => {responseData.value += event.data + "-"}eventSource.value.onerror = (error) => {console.warn("EventSource warn:", error)closeStream()}
}const closeStream = () => {if (eventSource.value) {eventSource.value.close()eventSource.value = null}
}// 生命周期鉤子
onBeforeUnmount(() => {closeStream()
})
</script><style scoped>.container {max-width: 600px;margin: 50px auto;padding: 20px;border-radius: 10px;box-shadow: 0 4px 8px rgba(0, 0, 0, .1);background-color: #fff;}.query-input {width: calc(100% - 22px);padding: 10px;margin-bottom: 15px;border: 1px solid #ccc;border-radius: 5px;font-size: 16px;}.action-button {padding: 10px 20px;margin-right: 10px;border: none;border-radius: 5px;cursor: pointer;font-size: 16px;transition: all .3s ease;}.start-button {background-color: #4CAF50;color: white;}.stop-button {background-color: #f44336;color: white;}.start-button:hover {background-color: #45a049;}.stop-button:hover {background-color: #e53935;}.result-container {margin-top: 20px;padding: 15px;background: #f9f9f9;border-radius: 5px;overflow-x: auto;}.response-data {white-space: pre-wrap;word-wrap: break-word;font-size: 14px;color: #333;}
</style>請求測試
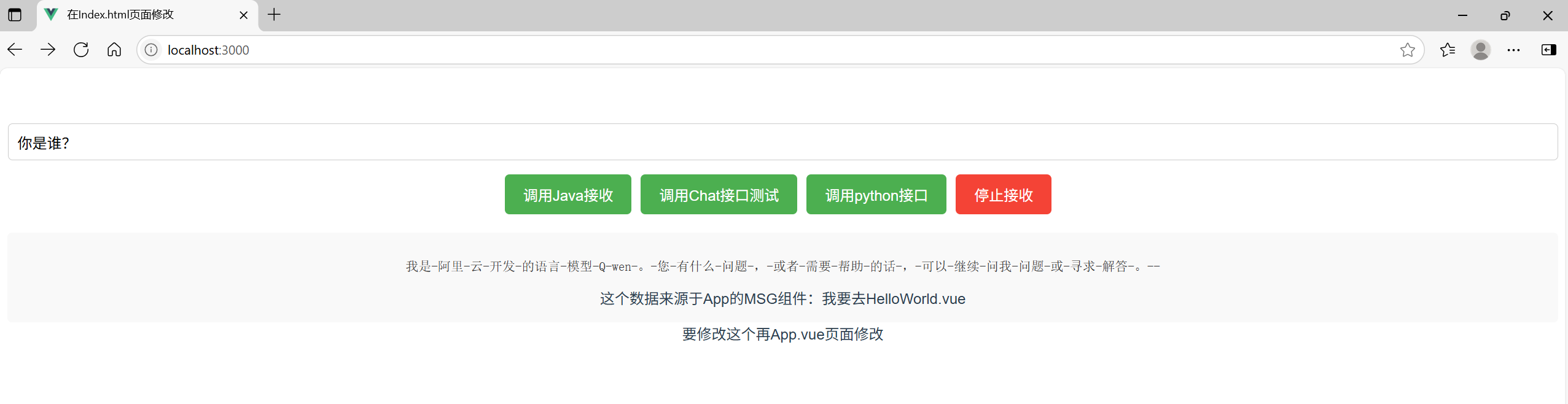
)




)





——攝像頭調用、攝像頭OCR)

)





