目錄
1、文件系統
1.1、磁盤
1.2、文件系統
1.3、文件的增刪查改
2、軟硬鏈接
2.1、軟鏈接
2.2、硬鏈接
3、物理內存與文件
4、動靜態庫
4.1、靜態庫
4.1.1、靜態庫的制作
4.1.2、靜態庫的使用
4.2、動態庫
4.2.1、動態庫的制作
4.2.2、動態庫的使用
4.3、動靜態庫一起使用
4.4、ncurses庫
5、動態庫的加載
6、進程地址空間
6.1、未被加載的程序的地址
6.2、程序加載后的地址
6.3、動態庫的地址
1、文件系統
如果一個文件沒有被打開,是放在磁盤中進行存儲的。磁盤上存儲文件=存儲文件的內容+文件的屬性。Linux中的文件在磁盤中存儲是將屬性和內容分開存儲的。
注意:磁盤又叫機械硬盤,和固態硬盤是不同的。像這種筆記本基本上目前都是用的固態硬盤。但是今天談論的不是固態硬盤,而是磁盤,因為目前大多服務器還是使用的磁盤,而不是固態硬盤。
1.1、磁盤
為什么要了解磁盤呢?上一篇文章中,主要講了被打開的文件,而這一講中主要講未被打開的文件,未被打開的文件放在磁盤上進行存儲,因此有必要了解一下磁盤。磁盤是計算機中唯一的機械設備。
磁盤的樣貌:

內部結構為:

?一個盤片是有兩面,每一面都有一個磁頭。磁頭和磁盤面是不接觸的。主軸里面有馬達,可以使磁盤高速旋轉,在磁盤進行高速旋轉時,磁頭臂也會來回擺動。信息就被存儲在盤片中。磁盤不工作時,磁頭會停靠在磁頭停泊區。

?這些磁頭是連在一起的,也就是說這些磁頭會同時擺動。
我們可以對上面的磁盤建立如下的模型,結構如下圖:
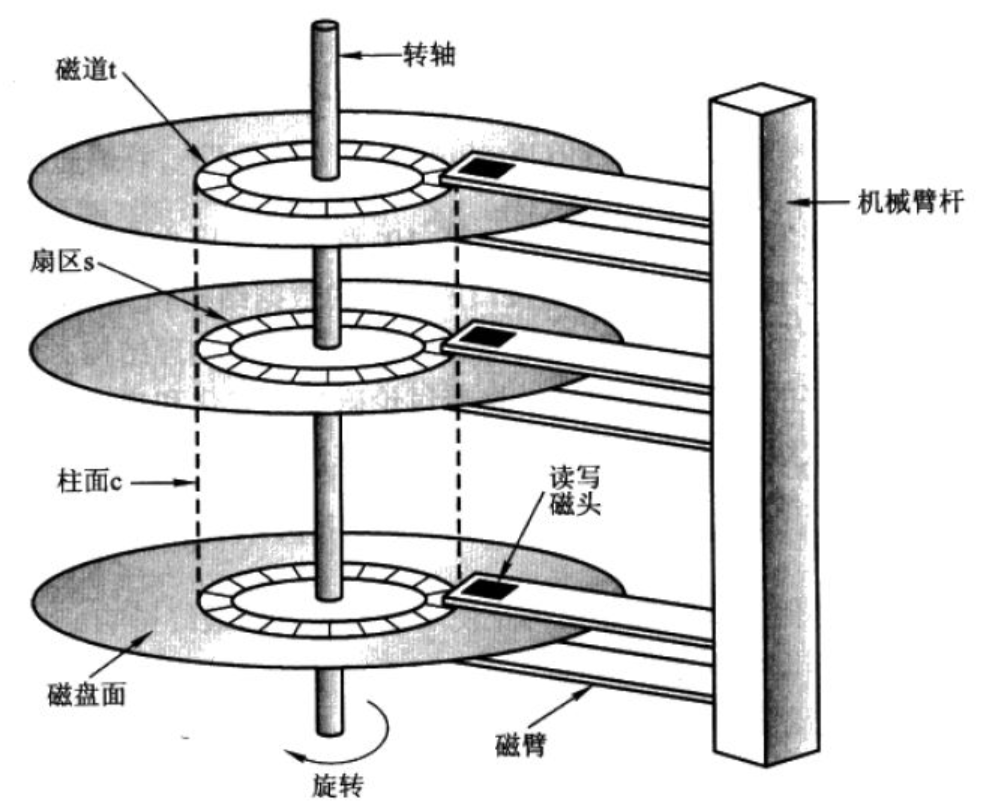
磁頭來回擺動本質上就是在定位磁道,磁盤進行旋轉本質上就是在定位扇區。
磁盤讀寫的最基本的單位是扇區,一般一個扇區的大小為512字節或者4kb。數據在磁盤上并不是隨便進行擺放的,比如相關的數據會盡可能的放在一起。
我們可以把磁盤看成由很多扇區構成的存儲介質,要把數據存儲到磁盤,第一個要解決的問題就是定位一個磁頭(這將決定訪問哪一個盤面的哪一面),然后再確定在哪一個磁道,最后再確定在哪一個扇區。
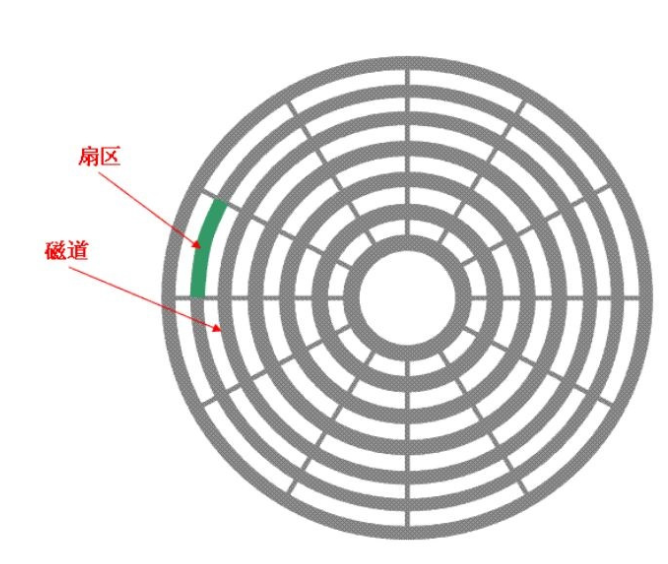
我們可以把磁盤展開,例如:
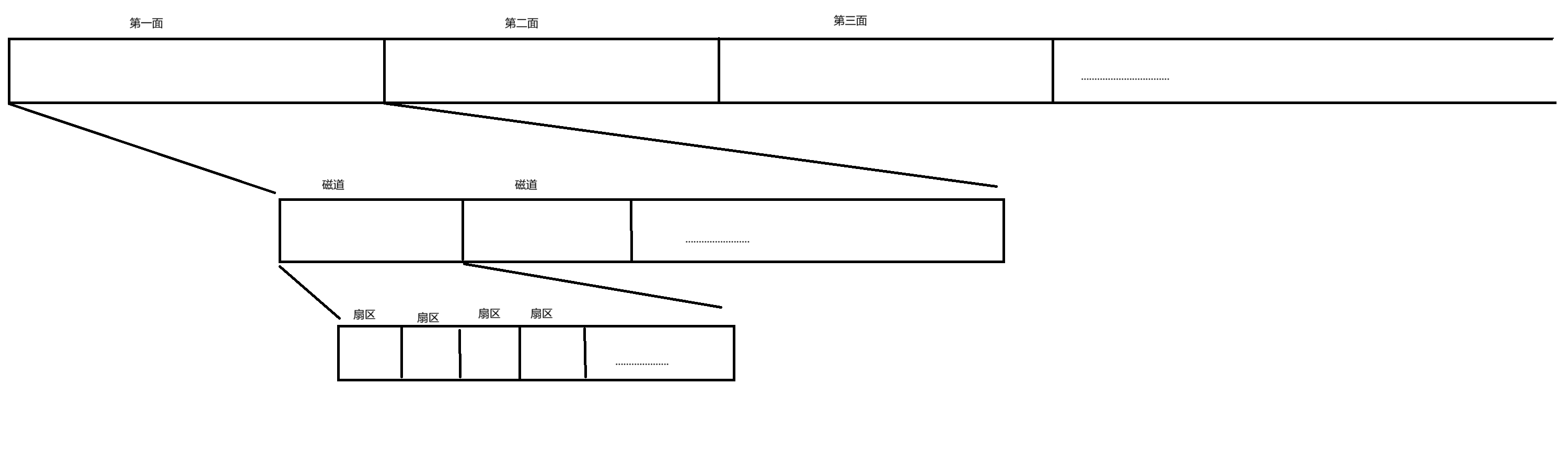
其中每一面是磁盤盤片的一面,每一面又有很多磁道組成,每個基本磁道的基本單元為一個扇區。因此我們可以把磁盤抽象成一個線性結構,每個基本單元的大小為一個扇區。如下圖:

不僅僅只有CPU有寄存器的概念,像是磁盤也是有類似于寄存器的概念的,比如:控制寄存器(控制讀和寫),數據寄存器(數據),狀態寄存器(IO結果的狀態),地址寄存器(存放地址信息)。
1.2、文件系統
為了管理磁盤,就需要有文件系統,我們在此了解的是Linux中的ext2文件系統。
上面我們已經把磁盤抽象為一個線性結構了,對于這樣一個線性結構,為了管理起來,對磁盤進行分區(之所以要進行分區是因為文件系統能管理的容量是有限的,不是無限的),只要把每個分區管理好,就可以管理好整個磁盤。
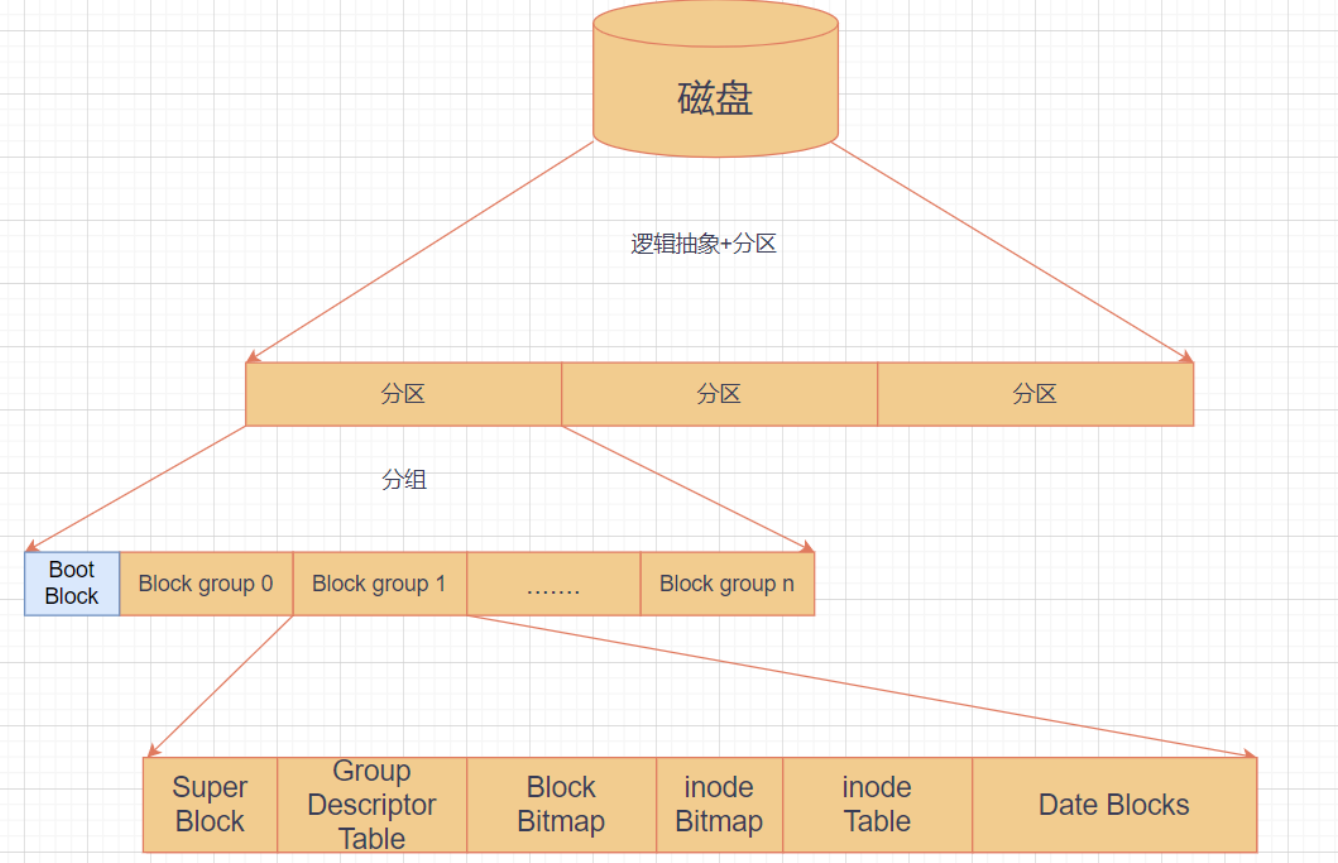
Linux下每個分區上的文件系統是相互獨立的, 也就是說每個分區都有自己的文件系統,每個分區的文件系統可以不同,當然也可以相同。所以一個分區就代表了一個文件系統。
邏輯塊(block):block是在分區中進行文件系統的格式化時所指定的"最小存儲單位",這個最小存儲單位以扇區的大小為基礎,大小為扇區的 2? 倍。一般邏輯塊的大小都是4KB,即由連續的 8 個扇區構成的一個塊,這樣就大大提高了文件的讀取效率。邏輯塊也并不是越大越好。因為一個邏輯塊最多僅能容納一個文件(這里指 Linux 的 ext2 文件系統)。所以邏輯塊很大可能會導致空間的浪費。所以最好的方式是根據實際的使用場景來設置邏輯塊的大小。簡單來說就是扇區是物理上的一個單位概念,文件系統的單位是block,這是一個邏輯上的概念。簡單來講就是文件系統對磁盤的訪問和操作的基本單位是block(一般也就是4kb),多訪問的數據可以理解為這就是預加載,預加載的目的是為了提高效率。
inode:Linux 操作系統中的文件內容和文件屬性是分開存儲的,權限與屬性放置到 inode中,一個文件有一個inode,inode有唯一的編號。
Boot block(引導塊):是一個重要的組成部分,用于存儲與啟動操作系統相關的信息。這個區域出問題,整個文件系統就掛掉了。
Block Group n:ext2文件系統會根據分區的大小劃分為數個Block Group。而每個Block Group都有著相同的結構組成。
Super Block(超級塊):超級塊會記錄整個文件系統的整體信息,記錄的信息主要有:bolck 和 inode的總量, 未使用的block和inode的數量,一個block和inode的大小,最近一次掛載的時間,最近一次寫入數據的時間,最近一次檢驗磁盤的時間等其他文件系統的相關信息等等。Super Block的信息被破壞,可以說整個文件系統結構就被破壞了。其實上除了第一個 block group 內會含有 super block 之外,后續的 block group 一般都包含了 super block,即做為第一個 block group 內 super block 的備份。所以,如果第一個超級塊損壞了,則可以從后面的超級塊復制過來,super?block?的大小為 1024 Bytes。
Group Descriptor Table(組描述符):描述塊組屬性信息,描述每個 group 的開始與結束位置的 block 號碼,以及說明每個塊(super block、bitmap、inode bitmap、data block) 分別介于哪一個 block 號碼之間。組描述符信息和超級塊信息一樣,后面的block group一般也都包含Group Descriptor Table也是用來作為備份。
Block Bitmap(數據塊位圖):其中每個bit表示一個data blocks中的單元是否空閑可用。
inode Bitmap(索引節點位圖):其中每個bit表示一個inode Table中的單元是否空閑可用。
inode Table(索引節點表):中存放著一個個 inode,inode 的內容記錄文件的屬性以及該文件實際數據放置在哪些 block 內。每個 inode 大小均固定為 128 Bytes,每一個文件都有一個唯一的inode,Linux中文件的屬性不包括文件的名稱,在Linux中標識文件使用inode編號,可以使用下面的命令查看文件的inode編號,例如:其中開頭的第一個代表的就是inode編號。

注:每個inode中的屬性包括:inode編號、文件類型、權限、引用計數、擁有者、所屬組等等。 另外inode的是以分區進行設置的,不能跨分區,也就是說每一個分區內用一套inode,分區與分區的inode是有重復的。
Date Blocks(數據區):存放文件內容的地方。
注意:每一個分區被使用之前,都必須提前將部分文件系統的屬性信息設置進對應的分區中,這個動作被稱為格式化,這個格式化是對前四個塊來講的,即超級塊、組描述符、數據塊位圖、索引節點位圖。比如:格式化后,一個分區的可以使用的inode的總數是確定的。
注意:目錄也是一個文件,也有自己的inode,目錄也是由屬性+內容組成的,目錄的內容存放的是該目錄下,文件的文件名和對應文件的inode編號的映射關系。
1.3、文件的增刪查改
1、新建一個文件
分配 inode:為新文件分配一個 inode,記錄文件的屬性數據。
分配數據塊:為文件分配數據塊,存儲文件內容。
更新目錄內容:在包含該文件的目錄中創建相應的目錄項,記錄文件名與 inode之間的映射關系。
2、刪除一個文件
查找文件:通過目錄中的映射關系找到對應的 inode。
釋放數據塊:釋放與 inode 關聯的數據塊,標記這些塊為可用。
釋放 inode:將 inode 標記為可用。
更新目錄內容:從目錄中刪除對應的映射關系。
3、查詢一個文件
查找 inode:在目錄中查找文件名與inode的映射關系,找到對應的 inode。
讀取數據塊:根據 inode 獲取指向數據塊的指針,讀取文件的內容。
4、修改一個文件
查找 inode:通過文件名和inode的映射關系,找到相應的 inode。
寫入數據塊:修改文件的內容,更新相應的數據塊。
更新屬性信息:更新 inode 內部的時間戳信息等。
2、軟硬鏈接
2.1、軟鏈接
軟鏈接和Windows中的快捷方式很像,我們可以使用如下命令建立軟鏈接:
ln -s file.txt soft-link其中,ln表示建立鏈接,-s選項表示建立軟鏈接,上面所表達的意思是給file.txt文件建立soft-link軟鏈接。?
軟鏈接是一個獨立的文件,有獨立的inode編號,也有獨立的數據塊,該文件中的數據塊中保存的是指向文件的路徑。例如:我們可以使用ls -li命令查看

很顯然,兩個文件的inode編號是不同的,因此是兩個不同的文件。?
如果我們把軟鏈接指向的文件給刪除了,就會出現:

刪除軟鏈接可以使用rm 來進行刪除,但是給目錄上的軟鏈接使用rm是沒法刪除的,例如:
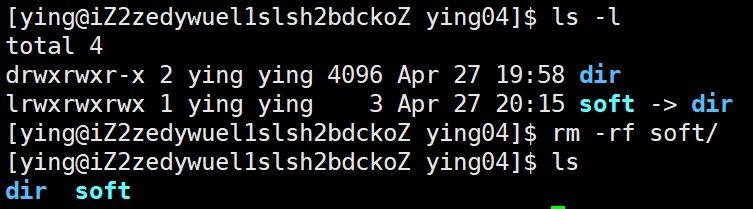
可以使用下面的命令進行刪除軟鏈接,無論是給文件上軟鏈接還是給目錄上軟鏈接都可以被刪除,例如:
unlink soft-link軟鏈接的應用:我們可以給目錄或者是文件添加軟鏈接。軟鏈接的應用就是類似于Windows的快捷方式。
2.2、硬鏈接
所謂的建立硬鏈接,本質就是在特定的目錄的數據塊中新增文件名和指向文件的inode編號的映射關系,相當于給文件起了一個別名。我們可以使用如下命令建立硬鏈接:
ln test.txt hard-link上面的所表達的意思是給test.txt文件建立hard-link硬鏈接。?
硬鏈接不是一個獨立的文件,因為不具有獨立的inode編號,例如:

通過觀察便可以發現這兩個文件的inode編號是一樣的,因此是同一個文件, 只是名字不同而已。另外,我們發現鏈接數從1變成了2,說明這里的數字本質表示的是一個文件的硬鏈接數的個數。
注:任意一個文件,無論是目錄還是文件,都有inode編號。每一個inode內部都有一個叫做引用計數的計數器,用來表明有多少個文件指向同一個inode。只有計數器為零時,才會正真的刪除文件,否則僅僅只是計數器減一。
硬鏈接的應用:硬鏈接最典型的應用就是目錄,比如我們創建一個目錄,我們就可以看到他的鏈接數為2。

之所以鏈接數為2是因為在dir目錄下有一個名字為.的隱藏文件?,該文件就是dir目錄的硬鏈接。
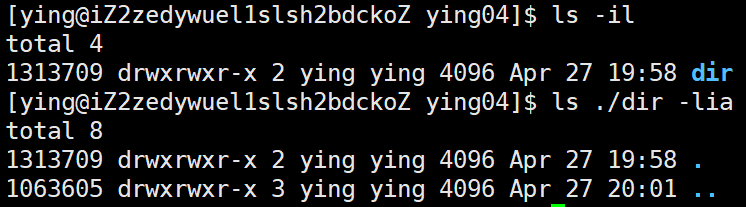
從圖中可以看出dir與dir目錄下的.隱藏文件的inode是一樣的。其中dir目錄下的..隱藏文件也是一樣的,只不過它是指向上級目錄的。又因為ying04目錄下又有一個.隱藏文件,因此鏈接數是3。


注意:可以給目錄添加軟鏈接,但是不可以給目錄建立硬鏈接,因為給目錄建立硬鏈接會破壞目錄樹的結構,會導致出現環路問題,比如查找一個文件,因為有環,所以會導致死循環。系統對目錄中的.和..兩個隱藏文件做了特殊的處理,使得在進行一些操作時,會忽略這兩個文件,比如查找文件時,忽略這兩個隱藏文件進行查找。

總的來說就是用戶是不被允許給目錄建立硬鏈接的。?
3、物理內存與文件
操作系統對內存的管理是相當復雜的,這里僅僅只是補充一些對內存管理的認識。
1、內存的本質是對數據的臨時存取,我們可以把內存看作為一個很大的緩沖區。物理內存也是劃分為一塊一塊的,與磁盤進行交互時的單位是4kb。
2、操作系統要管理物理內存也是要先描述、再組織的。描述使用struct page結構體,該結構體中描述了每個4kb物理內存的屬性。組織采用數組的方式,以4GB物理內存為例,struct page mem_array[1048576],因此對物理內存的管理就變成了對數組的管理,又因為數組是有下標的,因此就有了頁號的概念,每個4kb大小的單位都對應一個頁號。要訪問一個物理內存,我們只需要先找到這個4kb所對應的page,就能在系統中找到對應的物理內存的頁。所有申請物理內存的動作都是在訪問內存數組。
3、Linux中,我們每一個進程,打開的每一個文件,都要有自己的inode屬性和自己的文件頁緩沖區(內核級緩沖區)。?系統啟動時,會把磁盤的一些常用的內容給加載到內存,這個就是預加載。
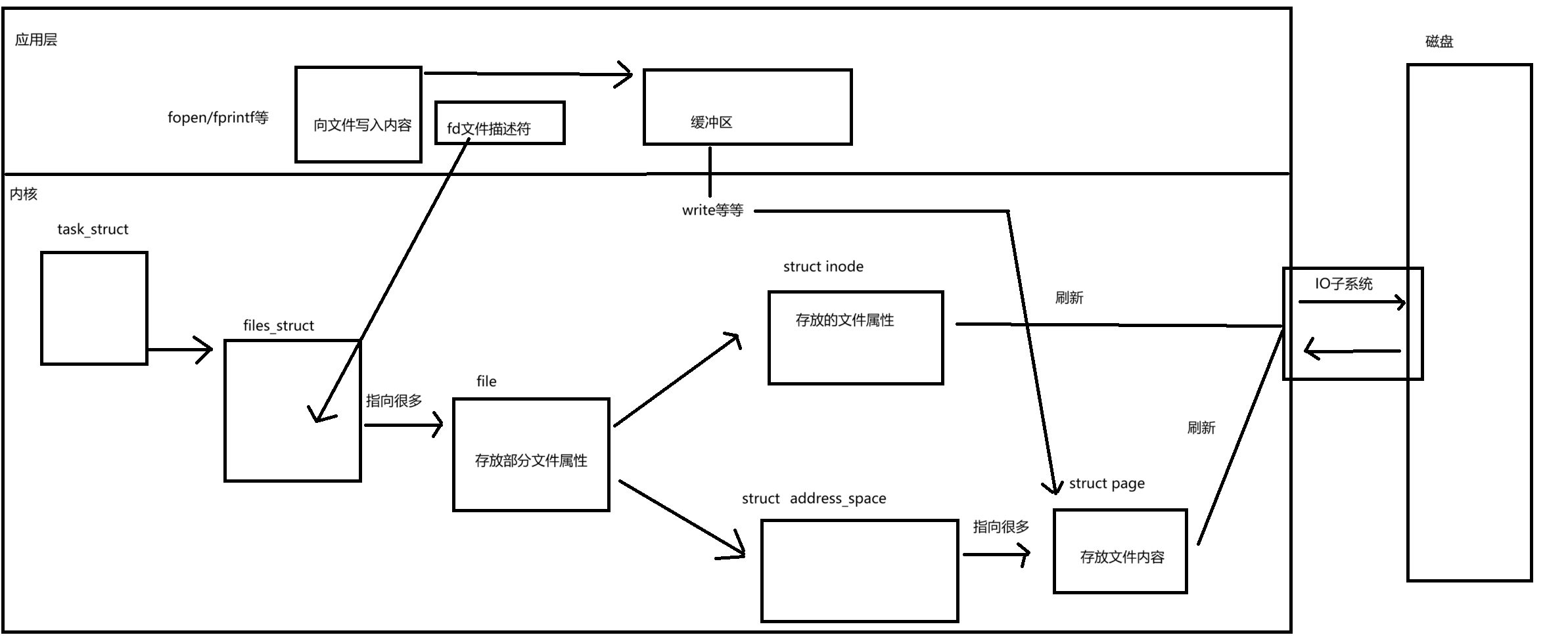
?其中struct inode和struct page就是內核級緩沖區。從圖中就可以看出,文件內容要寫到磁盤至少要經過三次拷貝,向緩沖區進行一次拷貝,向內核級緩沖區再拷貝一次,最后向磁盤再拷貝一次。
4、動靜態庫
動靜態庫之前我們簡單了解過,下面我們將嘗試著自己去制作動靜態庫。
4.1、靜態庫
靜態庫(.a):程序在編譯鏈接的時候把庫的代碼鏈接到可執行文件中。程序運行的時候將不再需要靜態庫。靜態庫的命名規則:libxxx.a
4.1.1、靜態庫的制作
把我們自己提供的方法給別人用,有兩種方式,一種是把源代碼直接給他;另一種方法就是把我們的源代碼打包成庫,然后把庫和對應的頭文件給他(頭文件是一定要給的,因為頭文件就像一份說明書,如果沒有這個說明書,使用者是不知道如何使用庫的)。
例如:我們有這樣一個程序
mymath.h:
#pragma once #include<stdio.h>extern int myerrno;int add(int x,int y);
int sub(int x,int y);
int mul(int x,int y);
int div(int x,int y);mymath.c:
int myerrno=0;int add(int x,int y)
{return x+y;
}
int aub(int x,int y)
{return x-y;
}
int mul(int x,int y)
{return x*y;
}
int div(int x,int y)
{if(y==0){myerrno=1;return -1;}return x/y;
}
制作靜態庫庫其實就是將源文件編譯成目標文件,然后再打包成庫。
例如:我們先將mymath.c文件編譯成目標文件mymath.o
gcc -c mymath.c -o mymath.o然后再進行打包,形成libmymath.a:
ar -rc libmymath.a mymath.o現在就生成了靜態庫libmymath.a了。
我們可以使用如下命令查看靜態庫中的內容,例如:
ar -tv libmymath.a
結果為:
![]()
然后我們可以將生成的靜態庫與頭文件放在一起,給別人使用,例如:
mkdir -p mylib/include
mkdir -p mylib/lib
cp mymath.h mylib/include
cp libmymath.a mylib/lib
?現在我們就有了lib目錄,里面存放著頭文件和對應的庫。下面我們使用一下自己制作的庫。
4.1.2、靜態庫的使用
例如:我們現在寫了一個代碼,要調用我們上面制作的庫里面的函數
#include"mymath.h"int main()
{printf("div:%d,errno:%d\n",div(10,0),myerrno);return 0;
}
然后我們嘗試使用gcc直接編譯該文件,就會出現:
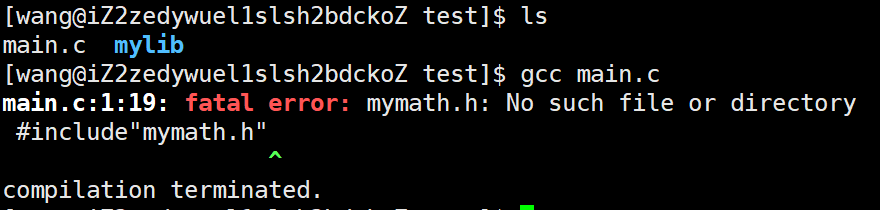
原因是gcc在找頭文件時會去默認路徑/usr/include/或者在當前目錄下去找(前提是使用""包含頭文件)頭文件,而我們自己編寫的頭文件既不在當前目錄也不在/usr/include/中,因此出錯。
?我們可以在使用gcc時加上-I選項,該選項后面跟頭文件的搜索路徑。除了使用這種加-I(大寫的i)選項的方式外,還可以直接在源程序main.c中使用include直接包含頭文件路徑(相對或者絕對路徑都可以)。我們使用加選項的方式,例如:

很顯然,這是一個鏈接的錯誤,出現這個錯誤是因為找不到我們寫的靜態庫,因為gcc默認去系統路徑/lib64/下或者當前路徑下去找庫,所以報錯了。
我們可以在使用gcc的時候加上-L選項,指明庫文件所在的路徑。例如:
 運行后我們發現又有問題了,原因是我們沒有指定庫名,gcc是認識C語言中標準庫的名稱的,但不認識我們自己寫的庫的名稱,所以出現了報錯。
運行后我們發現又有問題了,原因是我們沒有指定庫名,gcc是認識C語言中標準庫的名稱的,但不認識我們自己寫的庫的名稱,所以出現了報錯。
我們在使用gcc時,可以加上-l選項,指明庫的名稱。例如:
 注意:庫的真實名稱是去掉前面的lib和后綴所剩下的部分,例如:libmystdio.a,這個庫的真實名稱是mystdio。有人可能有疑惑的是,為什么庫需要指定庫的名稱,而頭文件不需要指定頭文件的名稱呢?原因是在,main.c程序中我們已經包含了頭文件的名稱。
注意:庫的真實名稱是去掉前面的lib和后綴所剩下的部分,例如:libmystdio.a,這個庫的真實名稱是mystdio。有人可能有疑惑的是,為什么庫需要指定庫的名稱,而頭文件不需要指定頭文件的名稱呢?原因是在,main.c程序中我們已經包含了頭文件的名稱。
到這里,我們已經明白了如何使用我們自己制作的靜態庫。如果想要不帶這么多的選項,可以將我們寫的庫和頭文件分別放在/lib64/路徑下以及/usr/include/路徑下,這樣我們僅需帶-l選項指定庫名即可。
除了上面說的方法,我們也可以給頭文件所在的路徑和庫文件分別在/lib64/和/usr/include中建立軟鏈接,例如:給頭文件所在的路徑在/usr/include中建立軟鏈接:

給庫文件建立軟鏈接:

?此時我們要想直接gcc main.c -l mymath是不行的,我們需要更改一下頭文件,例如:
#include"myinc/mymath.h"int main()
{printf("1+1:%d,errno:%d\n",add(1,1),myerrno);return 0;
}
此時我們可以直接使用gcc main.c -l mymath來直接編譯了。例如:

但是我們發現程序的結果有問題,想象中的errno是1才對,之所以會有這個結果是因為C語言中函數參數的處理順序是從右向左的,所以會導致這樣一個結果,我們可以進行如下修改,例如:
#include"myinc/mymath.h"int main()
{int n=div(10,0);printf("div:%d,errno:%d\n",n,myerrno);return 0;
}
?然后再進行編譯后運行結果為:

這樣就完成了。?
注:第三方庫的使用,必定會用到-l選項來指定庫名。如果僅提供了靜態庫,則gcc只能對該庫進行靜態鏈接,簡單來說就是,在不加-static選項時,有動態庫就連動態庫,沒動態庫就連靜態庫;如果加上-static,則只連靜態庫。
4.2、動態庫
動態庫(.so):程序在運行的時候才去鏈接動態庫的代碼,多個程序共享使用庫的代碼。動態庫的命名規則:libxxx.so
4.2.1、動態庫的制作
動態庫和靜態庫的制作是有相似之處的,也是要編譯成目標文件的。在靜態庫中,我們只將一個文件制作成庫,這次我們試著將多個文件制作成庫,例如:我們有如下文件
myprint.c
#include"myprint.h"void Print()
{printf("hello linux\n");printf("hello linux\n");printf("hello linux\n");printf("hello linux\n");
}
myprint.h
#pragma once #include<stdio.h>void Print();mylog.c
#include"mylog.h"void Log(const char* info)
{printf("warning:%s\n",info);
}
mylog.h
#pragma once #include<stdio.h>void Log(const char*);首先,要把mylog.c和myprint.c文件編譯成目標文件,和靜態庫的區別是要多加一個-fPIC選項,例如:
gcc -fPIC -c mylog.c
gcc -fPIC -c myprint.c?生成mylog.o和myprint.o文件,然后再使用gcc加上-shared選項進行下面的操作:
gcc -shared -o libmymethod.so mylog.o myprint.o最后就生成了libmymethod.so動態庫。?
我們同樣將動態庫以及對應的頭文件分別放入mylib/lib/和mylib/include目錄下,結果為:
4.2.2、動態庫的使用
main.c
#include"mylog.h"
#include"myprint.h"
int main()
{Print();Log("hello log function\n");return 0;
}
動態庫的使用和靜態庫類似,例如:
 然后我們去運行該程序,便會看到:
然后我們去運行該程序,便會看到:

使用ldd命令,便會看到:

上面顯示libmymethod.so動態庫是找不到的,要解決這個問題,我們可以把動態庫拷貝到/lib64/的目錄下,或者在/lib64/目錄中建立動態庫的軟鏈接,例如:
sudo ln -s /home/wang/dy-static/test/mylib/lib/libmymethod.so /lib64/libmymethod.so然后使用ldd可以看到:

?我們發現此時已經找到了動態庫,然后我們便可以運行程序了。例如:
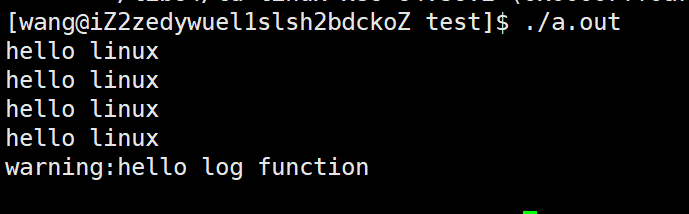
或者我們使用一個環境變量來解決這個問題,這個環境變量就是LD_LIBRARY_PATH,一般來說系統中是沒有這個環境變量的,因為我之前配置過vim所以才有了這個環境變量,這個環境變量是專門給用戶提供搜索用戶自定義的庫的路徑的,例如:

?我們只要把庫路徑添加到該環境變量中即可,例如:

?這樣就導入成功了。此時使用ldd就可以看到:
 顯然,已經找到了動態庫。當然,這種方式不是長久有效的,一旦關掉Xshell然后重新登陸后我們配置的環境變量信息也就沒了,如果想要配置長久有效,就要把我們配置的信息填寫到系統啟動時的一些文件中。
顯然,已經找到了動態庫。當然,這種方式不是長久有效的,一旦關掉Xshell然后重新登陸后我們配置的環境變量信息也就沒了,如果想要配置長久有效,就要把我們配置的信息填寫到系統啟動時的一些文件中。
或者我們也可以在/etc/ld.so.conf.d/下建立一個以.conf為后綴的文件,庫路徑填寫到這個文件中,然后使用ldconfig命令把配置文件重新加載一下,也可以解決這個問題,這種方式是長久有效的,例如:

然后我們使用ldd查看我們的可執行文件便會發現:

此時動態庫就找到了。 如果想要刪除這個配置,僅需把test.conf文件刪除掉或者清空,然后重新執行一下ldconfig即可。
有人可能會感到疑惑的是,我們明明已經指定了路徑和庫名,為啥還會要再指明呢?原因是之前的指明是告訴的編譯器,而這里指明是告訴加載器。之所以我們之前寫的C語言程序的運行不用指明的原因是系統在加載時,會默認去某些路徑下去進行搜索對應的動態庫。
注意:實際情況中,我們使用的庫都是別人成熟的庫,都采用直接安裝到系統的方式。通俗的講就是把庫和對應的頭文件分別放到系統的默認路徑下。下面我們通過ncurses庫來實踐一下。
4.3、動靜態庫一起使用
例如:我們的main.c文件
#include"mymath.h"#include"mylog.h"#include"myprint.h"int main()
{int n=div(10,0);printf("div:%d,errno:%d\n",n,myerrno);Print();Log("hello log function\n");return 0;
}
?使用下面的方式編譯此文件并運行:

?注:a.out這個可執行程序的運行并不依賴與靜態庫,只要該可執行程序形成,哪怕我們把靜態庫刪掉也不會影響該可執行程序的運行。但是如果我們把動態庫刪掉,則a.out這個可執行程序就不能運行了。
4.4、ncurses庫
ncurses庫是一個基于終端的圖形界面的庫,我們可以試著用一下這個庫。
其實我們對ncurses本身并不陌生,因為vim的制作就使用了ncurses庫。下載:
sudo yum install ncurses-devel.x86_64
安裝完成之后,我們可以查看一下系統中是否成功安裝庫,例如:
現在我們就可以使用該庫進行開發了。
?例如:test.c
#include <string.h>
#include <ncurses.h>int main()
{initscr(); // 初始化屏幕raw(); // 禁用行緩沖noecho(); // 禁用回顯curs_set(0); // 隱藏光標char *c = "Hello, World!";mvprintw(LINES/2, (COLS-strlen(c))/2, c); // 在屏幕中央打印字符串refresh(); // 刷新屏幕getch(); // 等待用戶輸入endwin(); // 結束ncurses模式return 0;
}
?編譯該程序,例如:
gcc test.c -o test -l ncurses注意:在編譯時要使用-l選項來指定庫名?。
程序運行結果為:在屏幕中間顯示“Hello, World!”(居中),隱藏光標,不回顯鍵盤輸入,然后等待用戶按鍵后退出。
關于ncurses庫的其他使用,自行了解。
5、動態庫的加載
動態庫在程序執行時是需要被加載的,而靜態庫不會被加載,動態庫在被加載之后,會被所有用到它的進程所共享。
當第一個進程運行時需要某個動態庫的時候,動態庫被加載到物理內存,然后通過頁表,被映射進虛擬地址空間的共享區里面,然后從程序從當前的正在執行的位置(也就是代碼區中)跳轉到共享區里面執行庫的程序,執行完成之后,再返回代碼區繼續執行接下來的代碼。
當第二個進程也需要使用該庫時,先判斷這個庫是否被加載了,如果被加載到了物理內存,則直接通過頁表映射進該進程的虛擬地址空間的共享區中,然后程序跳轉到共享區里面執行庫的代碼,然后再返回代碼區繼續向下執行。如下圖所示:
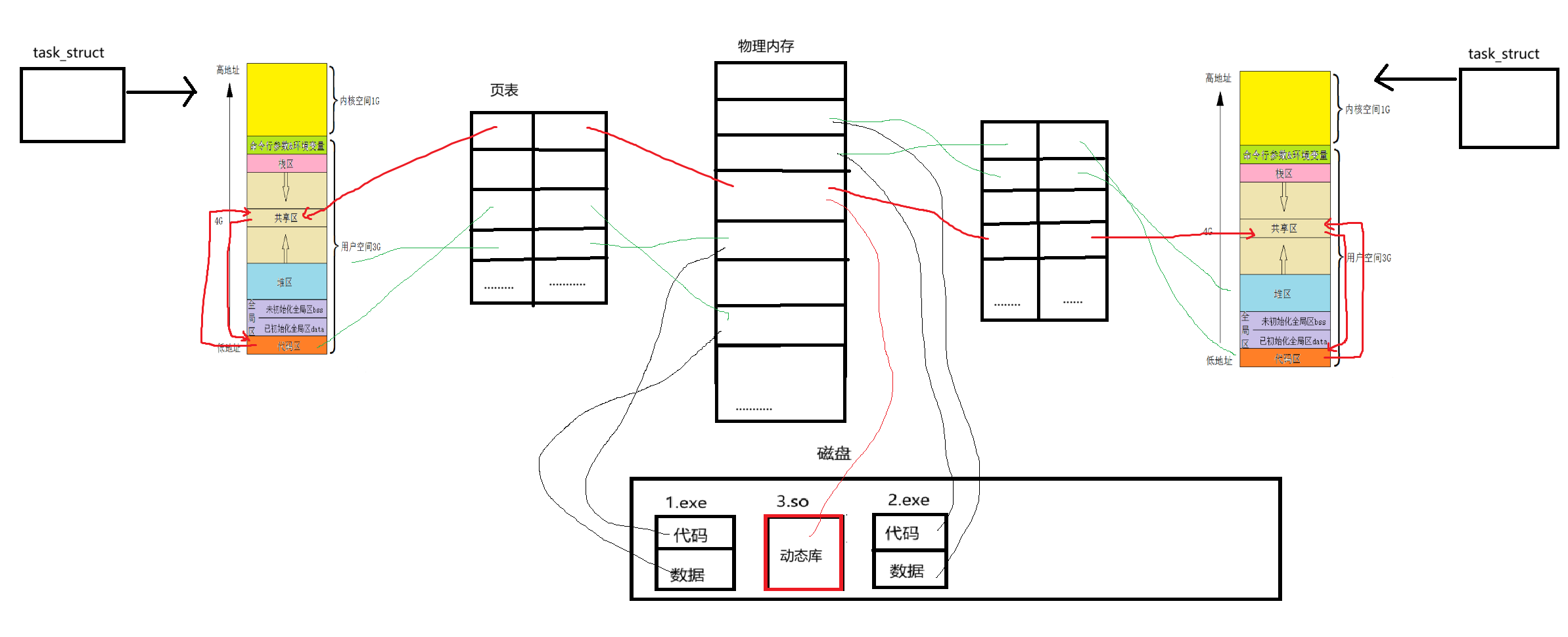
有人可能會疑惑的是,如果多個進程在使用動態庫的時候對其中的一些全局變量進行修改的話,豈不是會影響其他進程嗎?比如我們的libc.so動態庫中有一個errno全局變量,如果某個進程修改了它,那其他正在使用該動態庫的進程也會被影響嗎?事實上是不會被影響的,因為會發生寫時拷貝。因此一個動態庫,是可以被多個進程使用且進程與進程之間使用同一個動態庫是互不影響的。所以動態庫也叫做共享庫。系統在運行中,一定會存在多個動態庫,為了管理這些動態庫,采用先描述再組織的方式進行管理。
6、進程地址空間
之前我們簡單的了解過進程地址空間,這里再進行一些補充。
6.1、未被加載的程序的地址
未被加載的程序的地址,簡單來說就是,程序還沒被加載到內存,還在磁盤上。
程序編譯好后,形成的可執行程序內部已經采用虛擬地址編址了,也就是說內部是有地址的,這里面的地址是虛擬地址。例如:我們把程序反匯編,這里面的地址就是虛擬地址。我們使用下面的命令對可執行程序進行反匯編
objdump -S a.out部分結果為:
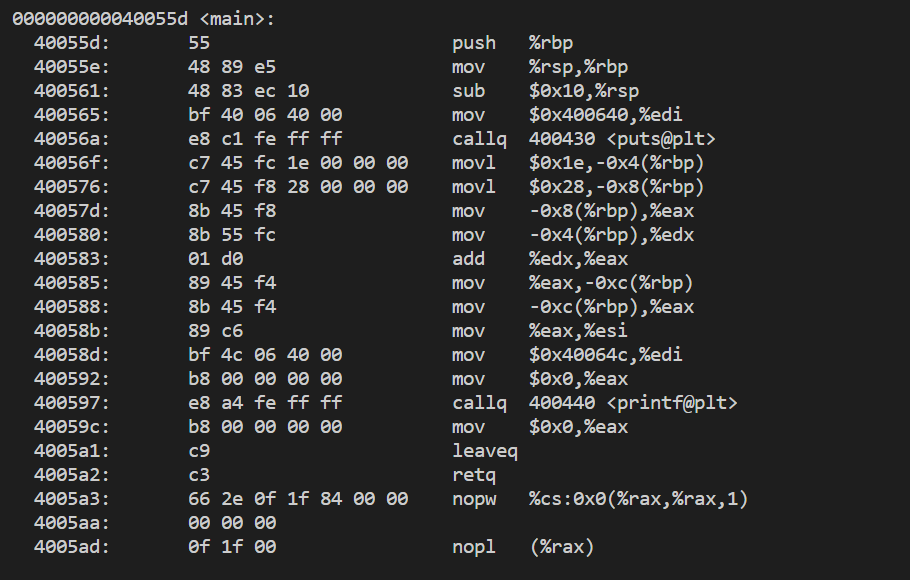
其中左邊這一列數表示后面右邊每一行指令所對應的地址。?在可執行程序中,左邊的這一列地址的是可以去掉的,而僅有右邊的指令操作。
程序編譯好后形成的可執行程序是被分成很多段的,簡單來說就是在磁盤上的可執行程序的內部的分段和虛擬地址空間的一些分區基本是一致的,例如:以4GB為例
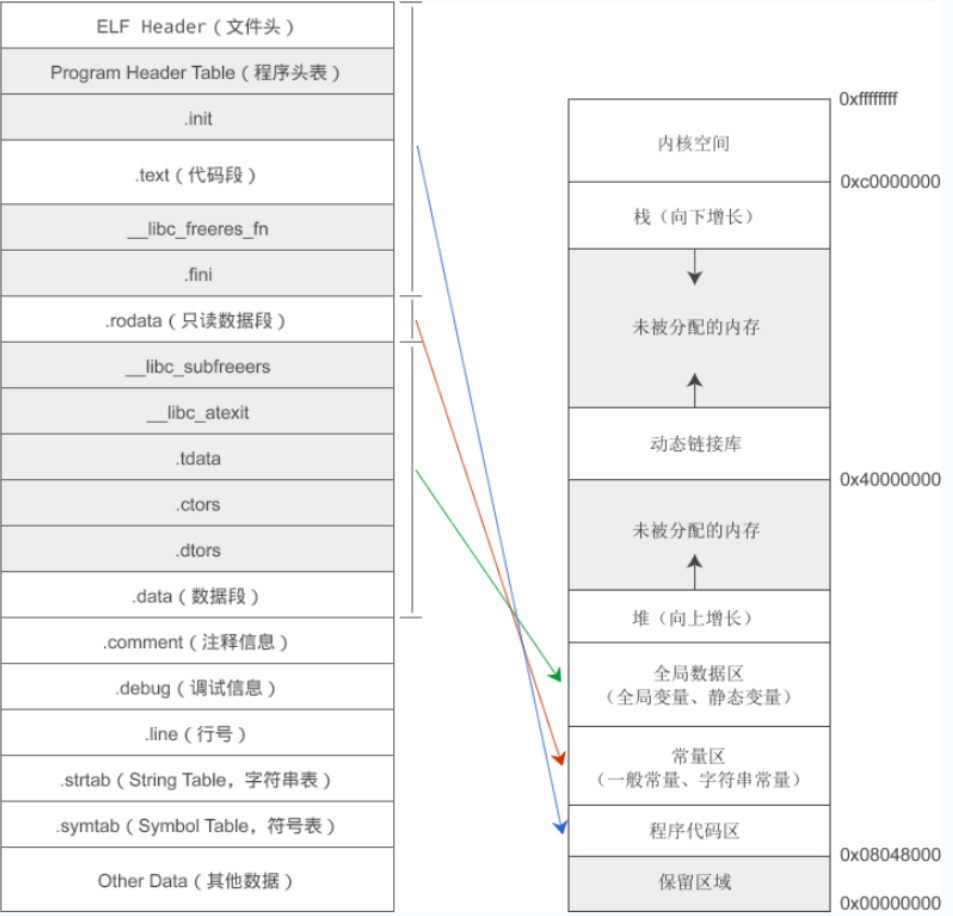
因此程序在被編譯好后就已經為運行做好準備了。?
6.2、程序加載后的地址
當可執行程序被加載到內存的時候,可執行程序中依然是虛擬地址,但是它要被加載到物理內存上,要占據物理內存的空間,自然也就有了對應的物理地址。因此每條指令也就有了自己在物理內存上的物理地址,以及在可執行程序中的虛擬地址。
可執行程序的頭部中是有該可執行程序的入口地址的,該地址不是物理地址,是虛擬地址。
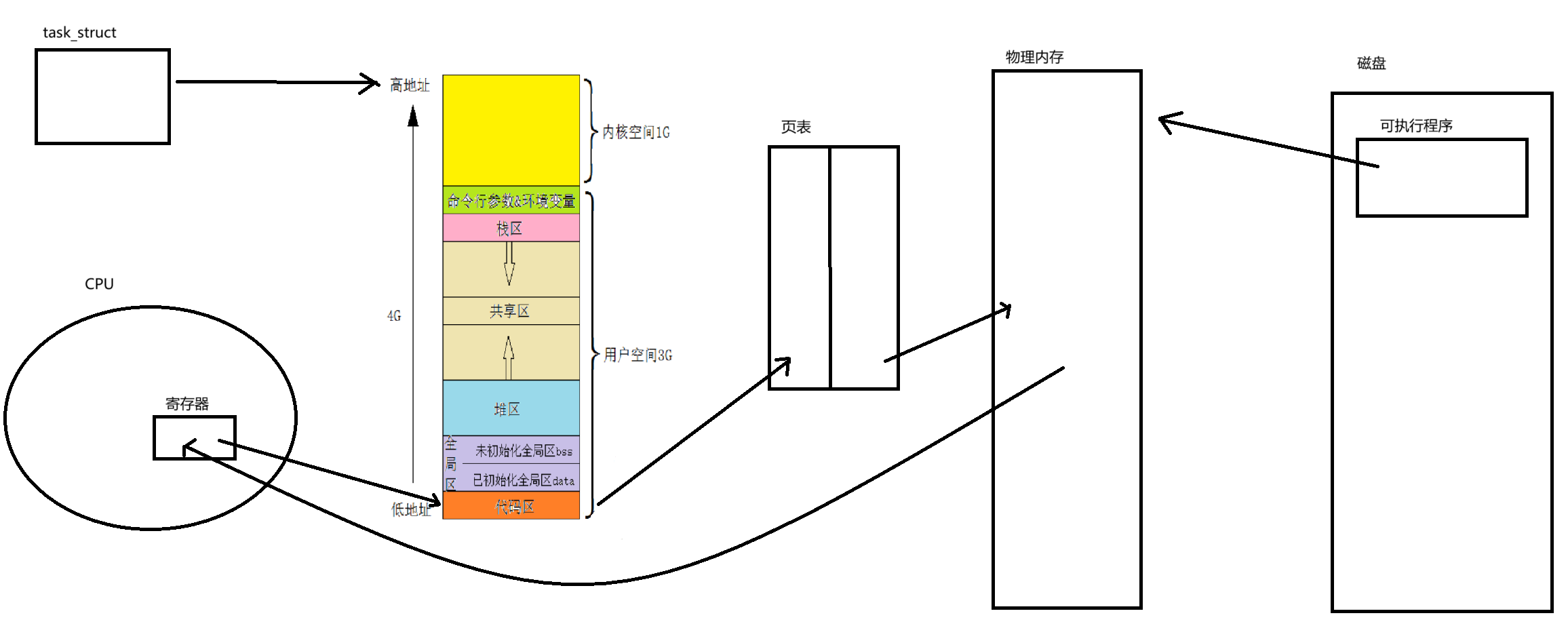
CPU中的寄存器讀到可執行程序的入口的內容(也就是讀到了入口地址),然后通過頁表的轉換找物理地址,如果此時對應的映射關系還沒有建立,則會引發缺頁中斷,然后加載程序,然后映射關系建立,然后開始執行,執行的時候CPU中的寄存器的地址會發生自增,增加的大小與指令的長度有關,然后就可以一條一條的執行。
6.3、動態庫的地址
絕對地址:指的是內存中的具體位置,從內存的起始位置算起的唯一地址。相對地址(偏移地址):指的是相對于某個基準地址或起點的偏移量。
例如,當我們的可執行程序要執行標準庫中的printf函數時,可執行程序內部已經沒有函數名這種東西了,僅有地址,但是這個地址是固定的,那就意味著共享庫被加載后,共享庫中的printf函數在共享區的地址也應該是固定的,否則的話,可執行程序就找不到printf函數。可是如果地址空間中該地址被其他東西占用了怎么辦?
共享庫是可以在共享區的任意位置加載的。這是怎么做到的呢?只要讓動態庫內部的函數不要采用絕對編址,而是采用每個函數在庫中的偏移量即可。因此只要知道共享庫在虛擬地址空間中的起始位置,然后再加上偏移量,就可以找到要找的內容在虛擬地址空間的絕對地址。
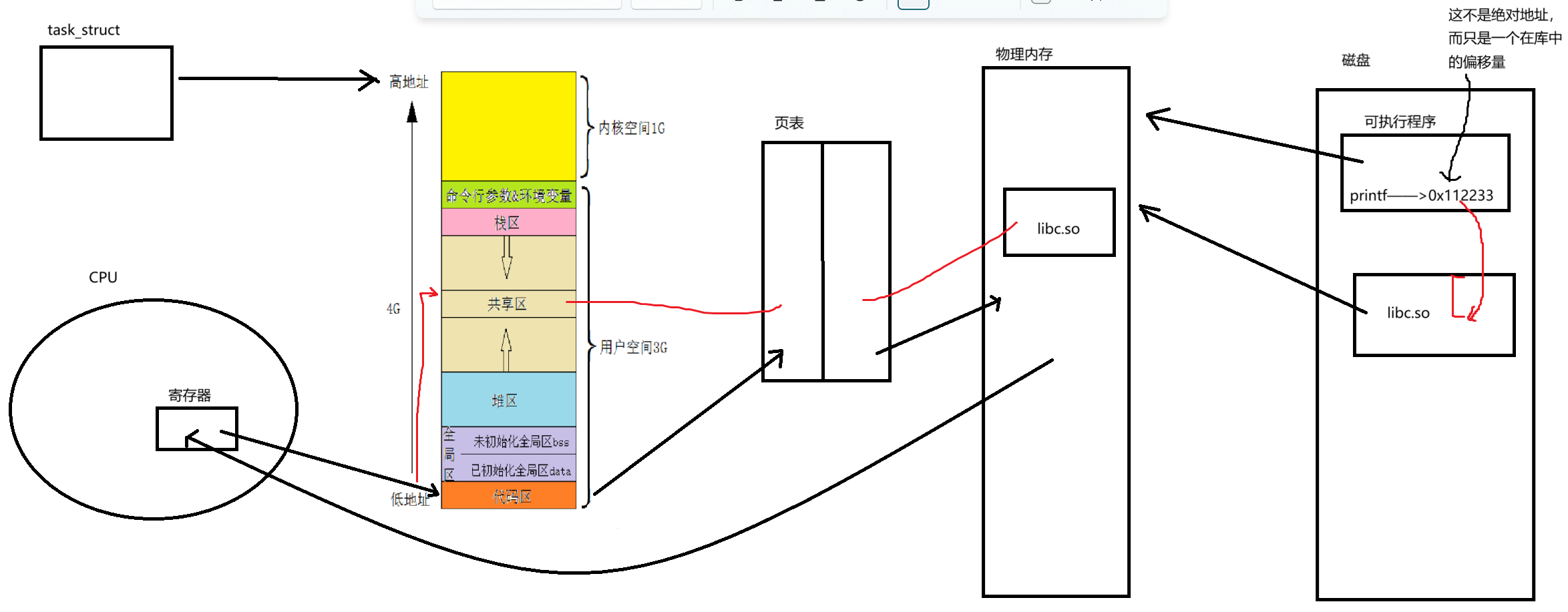
?之前在生成動態庫時,用到了一個選項,叫-fPIC,這個選項表示與地址無關。默認gcc是采用絕對編址的,使用這個選項后,就使用偏移量對庫中的函數進行編址。

:Clocking Wizard 動態配置)

操作的一個函數 flip())




)
)









