文章目錄
- 1 SQL優化
- 1.1插入數據優化
- 1.2主鍵優化
- 頁分裂
- 頁合并
- 主鍵設計原則
- 1.3order by設計優化
- 1.4group by設計優化
- 小理解
- 1.5limit設計優化
- 順序IO和隨機IO小疑惑
- 1.6count設計優化
- 1.7update優化
- 關于隱式事務事務的DML操作
- 鎖
- 全局鎖
- 表級鎖
- 表鎖
- 元數據鎖
- 意向鎖
- 行級鎖
- 鎖的釋放條件
1 SQL優化
講一些SQL語句的性能優化
1.1插入數據優化
- 普通插入:
1.采用批量插入(一次插入的數據不建議超過1000條)
INSERT INTO tb_test VALUES(1, 'Tom'), (2, 'Cat'), (3, 'Jerry');
2.手動提交事務
默認情況下,mysql執行單個insert語句會開啟事務,insert執行完結束
這樣單個insert語句事務就加入我們聲明的事務,將所有事務變成一個事務,節省事務開啟結束時間
START TRANSACTION;
INSERT INTO tb test VALUES(1, 'Tom'), (2, 'Cat'), (3, 'Jerry');
INSERT INTO tb test VALUES(4, 'Tom'), (5, 'Cat'), (6, 'lerry');
INSERT INTO tb test VALUES(7, 'Tom'), (8, 'Cat'), (9, 'lerry');
COMMIT;

3.主鍵順序插入
主鍵順序插入性能優于主鍵亂序插入(涉及到樹的查找和優化)。-主鍵優化,看完主鍵結構即可理解
- 大批量插入:
load命令插入
-- 客戶端連接服務端時,加上參數 -–local-infilemysql –-local-infile -u root -p-- 設置全局參數local_infile為1,開啟從本地加載文件導入數據的開關set global local_infile = 1;
-- 執行load指令將準備好的數據,加載到表結構中
load data local infile '/root/sql1.log' into table tb_user fields
terminated by ',' lines terminated by '\n' ;
視頻操作
1.2主鍵優化
數據組織方式:在innodb存儲引擎中,表數據都是根據主鍵順序存放的,這種存儲方式的表稱為索引組織表。
非葉子節點的索引和葉子節點的數據都存放在page里,一個extent(區)-1MB中可以存放64個page(頁)-16KB
InnoDB的內存組織結構
頁分裂
除了新增頁,新申請的空間,正常頁至少包含兩條數據
正常你按主鍵順序插入
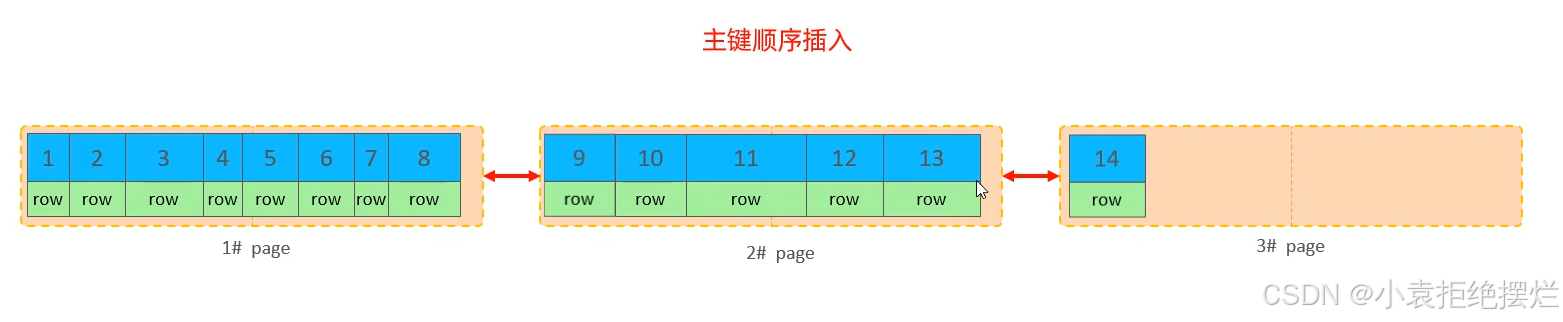
不按主鍵順序插入的話會出現頁分裂
比如現在要插入50
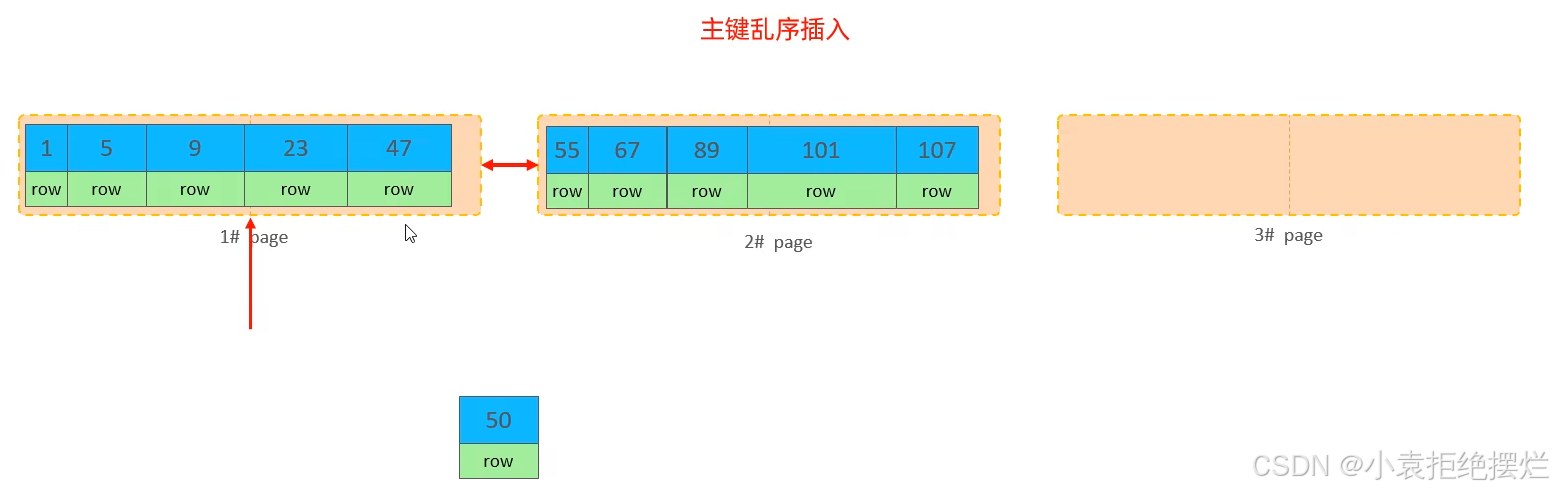
但是1頁滿了,所以要申請新一頁來存儲,將50放入,需要將1頁的后50%元素(即23和47)移入3頁和50湊成一頁,這個就叫頁分裂
為什么要數據重新分配?-將原頁后50%和新增數據合并(問AI)
然后他們頁之間進行一下排序,1-3-2這樣
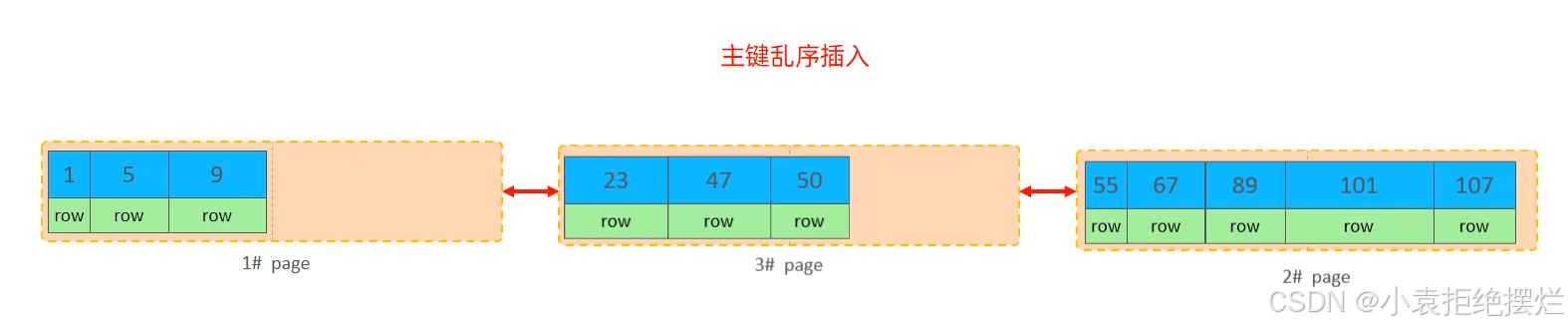
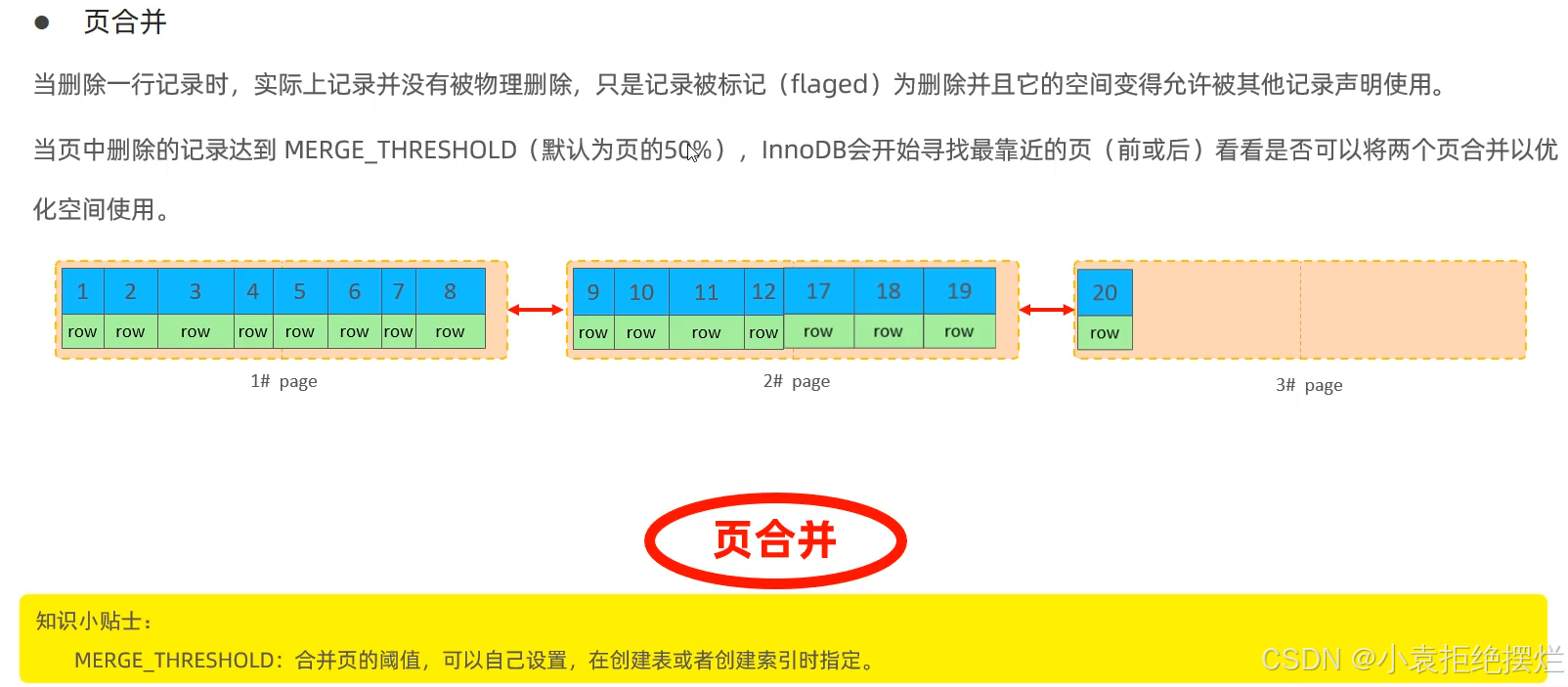
頁合并
如果一個數據源恰刪數據刪除后只剩50%不到數據(占頁空間大小一半不到),會發出合并請求,找兩邊的頁,如果恰好兩側的頁也有不足50%的頁,這兩個頁的數據就會合并
主鍵設計原則
-
①滿足業務需求的情況下,盡量降低主鍵長度。
-
②插入數據時,盡量選擇順序插入,選擇使用auto_increment自增主鍵。
-
③盡量不要使用uuid做主鍵或者其他自然主鍵,如身份證號。(但是由于分布式的影響現在基本都是用雪花算法這種)
-
④業務操作時,盡量避免對主鍵的修改。
1.3order by設計優化
MySQL的排序,有兩種方式:
Using filesort:通過表的索引或全表掃描,讀取滿足條件的數據行,然后在排序緩沖區sort buffer中完成排序操作,所有不是通過索引直接返回排序結果的排序都叫 FileSort 排序。
Using index:通過有序索引順序掃描直接返回有序數據,這種情況即為 using index,不需要額外排序,操作效率高。
對于以上的兩種排序方式,Using index的性能高,我們在優化排序操作時,盡量要優化為 Using index。
create index idx_user_age_phone_aa on tb_user(age [asc/desc],phone [asc/desc]);
explain select id,age,phone from tb_user order by age, phone

現在我們建立聯合索引默認升序
如果order by age desc,phone desc;會多顯示一個Backward index scan;-反向掃描索引
也是用了索引,性能方面沒什么影響

- 1.兩個都升序或者兩個都降序,走聯合索引
- 2.要遵循最左前綴原則,單phone排序,但是沒有單phone索引,有age,phone聯合索引就不行
- 3.如果要求按先phone后age進行排序,但是生成的索引是先age后phone,那么還是出現using filesort;創建索引前后字段結構要和排序前后字段結構要相同(和索引底層結構有關)
- 4.如果要求按先按age升序排列,后按phone降序排列,此時生成的索引是先age后phone,那么還是出現using filesort,因為創建索引的時候默認collation為A,即為asc,按升序排列的。
聯合索引,它不是單獨的按誰排列的,它是根據兩個字段一起排列的合并結果,數據列是phone和age的共同排序結果,所以這個用不了反向掃描
一個升序一個降序,需要重新創建索引。
創建如下索引即可解決
create index index_age_pho_ad on tb_user(age asc,phone desc);
- 5.最好使用覆蓋索引,如果表數據量太少都可能不回表查詢,直接全表掃了
- 6.如果不可避免地出現filesort,可以適當增大排序緩沖區大小sort_buffer_size(默認256k)
1.4group by設計優化
group by也要遵循最左前綴使用原則
沒有創建索引時候
explain select profession,count(*) from tb_user group by profession;
using temporary-使用臨時表,效率不高

創建索引后
create index idx_user_pro_age_sta on tb_user(profession,status);explain select profession,count(*) from tb_user group by profession;
這樣就會用到索引

explain select age,count(*) from tb_user group by age;
這樣的話,既會使用到索引也會使用到臨時表
具體內部怎么執行?
為什么用索引:因為全表掃描和查索引差不多,索引不用回表查age就在索引結構中,索引這里只起到提供數據的作用
具體執行過程


如果兩個字段都用(有最左且連續)
explain select profession,age,count(*) from tb_user group by profession,age;
正常using index

思考下面這條sql的執行計劃是怎么樣的
explain select age,count(*) from tb_user where profession='軟件工程' group by age;正常使用index,為什么和之前的單用age分組不一樣呢?
因為滿足最左前綴使用法則,where 篩選中用了profession
小理解
看完上面那個思考
我認為group by order by
其實和where后面字段一樣,只要用的話,都會用索引
order by和group by列順序和聯合索引順序一致的時候,才是最高性能的時候
1.5limit設計優化
無論你是根據索引還是根據全表查(Using filesort)都要獲取前20000條數據
而且limit實際一般會和我們的order by聯合使用
這樣一般就用的是索引,因為最后是一張鏈表嘛,需要一個一個遍歷元素
注:Using filesort雖然說是照物理結構讀取,但是底層物理結構不是數組,其實還是通過B+樹葉子節點的鏈表查詢,這里的葉子節點其實是頁(Page),獲取到頁內后,逐行讀取頁內數據(計數器累加行數,再到下一個頁累加,直到達到 offset=20000),然后讀取后10個再輸出

我們可以通過連表查詢的方式
我們可以通過覆蓋索引+子查詢
SELECT * FROM your_table ORDER BY id LIMIT 50000, 10;
先查詢對應的主鍵id,再根據主鍵聯表查
SELECT * FROM your_table
INNER JOIN (SELECT id FROM your_table ORDER BY id LIMIT 50000, 10
) AS tmp where your_table.id=tmp.id;
有的同志可能又疑問了,這不還是根據鏈表查詢嗎?
還是要查前50000條數據啊,為什么下面的就比上面的效率高呢
- 1.僅讀取索引字段(如 id):索引存儲在獨立的 B+樹中,體積更小,
通常可完全載入內存。
盡管這個是主鍵索引,下面是data,但是我們只讀取索引字段id即可,不訪問data,而select *則需要訪問葉子節點的數據字段data - 2.是這條sql完全不需要回表查詢,因為id是主鍵
- 3.順序訪問:如果順序插入(無修改),主鍵索引的葉子節點物理地址就會連續,掃描時是 連續 I/O(高效)。
所以子查詢會很快,子查詢查出來后聯表根據id條件查,那也很快

順序IO和隨機IO小疑惑
這樣說吧,順序IO和隨機IO是不由我們自己決定的
我們要做的就是,最好順序插入數據,減少頁分裂現象
頁分裂會123頁換成132頁,原來123邏輯物理地址相同,現在132邏輯物理就不同,物理地址不同,就需要移動磁頭1-2-3本來順序移動磁頭,現在1-3-2要從1-3移動一次3-2又要移動一次-這就變成隨機IO了,效率就會低。
順序I/O的優勢體現在:
- 磁盤尋道時間減少:磁頭不需要頻繁移動
- 預讀機制有效:數據庫可以提前讀取后續數據塊
- 緩存命中率提高:連續的數據塊更容易被保留在內存中
1.6count設計優化
問題: InnoDB引擎執行count(*)的時候,需要把數據一行一行地從引擎中讀出來,然后累積計數
注: MyISAM引擎把一個表地總行數存在了磁盤上,沒有where條件地時候,就會直接返回這個數,效率很高。
優化思路: 自己計數,在Redis中保存一個數來記錄
count的幾種用法:
count()會一行一行數據進行判斷,如果count函數的參數不是NULL,累計值就加1,否則不加
用法:
count(*) ——總記錄數,不取值直接累加
count(主鍵) ——取主鍵值,直接按行累加,但不用判斷null
count(字段) ——加NOT NULL取字段值按行累加(不是累加字段值,是累加一個字段算一行的總行數,但是會取出字段值),沒加NOT NUL約束情況時,如果NULL不加
count(1) ——InnoDB引擎遍歷整張表,但不取值。服務層對于返回的每一行,放一個數字“1”,直接按行進行累加。
優化: count(*) ~ count(1) > count(主鍵id) > count(字段)
理論count(*)最快
1.7update優化
update主要就是避免表鎖,將表鎖降級為行鎖
沒有索引就會鎖住整張表
優化: 根據索引字段進行更新,并且索引字段不能失效,否則行鎖就會升級為表鎖,影響并發性能
關于隱式事務事務的DML操作
默認autocommit=1
每個 DML 語句都會隱式開啟一個事務,并在執行后立即自動提交。
INSERT INTO users (name) VALUES ('Alice'); -- 隱式開啟事務 → 執行 → 自動提交
UPDATE users SET name='Bob' WHERE id=1; -- 隱式開啟事務 → 執行 → 自動提交
下面的DDL和隱式事務,這種情況不多,涉及元數據鎖
這里展示DML和DDL在一個事務

如果不是一個事務DDL會等帶DML的事務提交后再進行操作,如下圖

鎖
innodb引擎中鎖的分類
- 全局鎖:鎖定數據庫中所有的表
- 表級鎖:每次操作鎖住整張表
- 行級鎖:每次操作鎖住對應的行數據
全局鎖
全局鎖就是對整個數據庫實例加鎖,加鎖后整個實例就處于只讀狀態,后續的DML的寫語句,DDL語句,已經更新操作的事務提交語句都將被阻塞。
其典型的使用場景是做全庫的邏輯備份,對所有的表進行鎖定,從而獲取一致性視圖,保證數據的完整性。
備份Mysql數據庫:
1.可以在navicat直接轉存sql文件
2.可以使用Mysql自帶的 mysqldump 工具來備份數據庫。該工具可以生成 SQL 腳本文件,包含數據庫中所有表和數據的語句
mysqldump -u [username] -p [database_name] > [backup_file].sql
# [username] 是 MySQL ?戶名
#[database_name] 是需要備份的數據庫名稱,[backup_file].sql 是備份的?件名。
恢復Mysql數據庫:
1.一般都是直接把sql文件拖入navicat
2.如果要恢復數據庫,前提要有備份的文件。可以運行以下命令:
mysql -u [username] -p [database_name] < [backup_file].sql
# [username] 是 MySQL ?戶名
# [database_name] 是需要恢復的數據庫名稱,[backup_file].sql 是備份的文件名。
為什么備份庫需要給庫上全局鎖?
因為可能幾個表之間有關聯,導致數據的邏輯不匹配
比如:備份庫存表之后,扣減庫存,又生成訂單,再備份訂單,這樣造成了庫存表沒有去減1,但是多了個訂單對不上庫存了
使用mysqldump的時候不會自動使用全局鎖,而是使用表鎖,通過 LOCK TABLES 對每個表依次加讀鎖(READ LOCK)備份期間該表只讀(其他會話寫入會阻塞)
所以我們要自己實現全局鎖
語法
1). 加全局鎖
flush tables with read lock ;
2). 數據備份
mysqldump -uroot –p1234 itcast > itcast.sql
3). 釋放鎖
unlock tables ;
特點
數據庫中加全局鎖,是一個比較重的操作,存在以下問題:
- 如果在主庫上備份,那么在備份期間都不能執行更新,業務基本上就得停擺。
- 如果在從庫上備份,那么在備份期間從庫不能執行主庫同步過來的二進制日志(binlog),會導致主從延遲。
在InnoDB引擎中,我們可以在備份時加上參數 --single-transaction 參數來完成不加鎖的一致性數據備份。
mysqldump --single-transaction -uroot –p123456 itcast > itcast.sql
表級鎖
介紹
表級鎖,每次操作鎖住整張表。鎖定粒度大,發生鎖沖突的概率最高,并發度最低。應用在MyISAM、InnoDB、BDB等存儲引擎中。
對于表級鎖,主要分為以下三類:
- 表鎖
- 元數據鎖(meta data lock,MDL)
- 意向鎖
表鎖
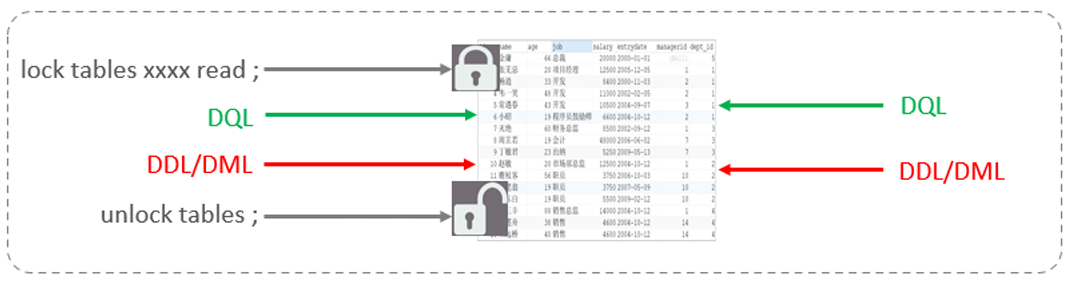
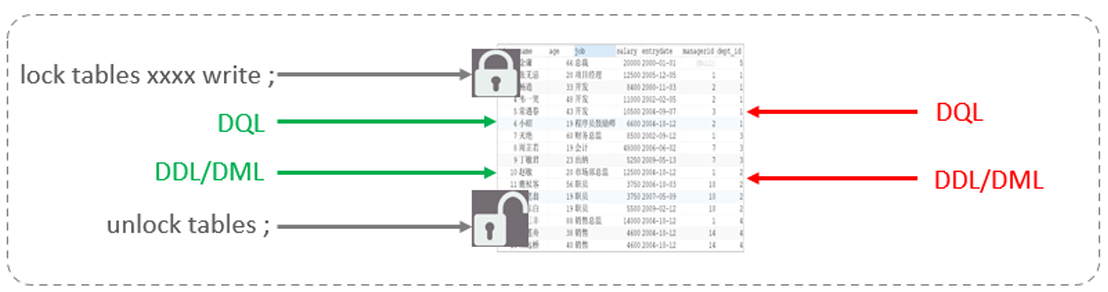
對于表鎖,分為兩類
1.表共享讀鎖(read lock)
- 所有客戶端都只能讀數據,不能寫數據
2.表獨占寫鎖(write lock)
- 只有上鎖的客戶端可以讀寫數據,其他都不能讀寫數據。
讀鎖
寫鎖:
語法
加鎖:lock tables 表名... read / write。
釋放鎖:unlock tables / 客戶端斷開連接釋放鎖。
說實話其實表鎖不常用(個人感覺)
元數據鎖
meta data lock , 元數據鎖,簡寫MDL。
MDL加鎖過程是系統自動控制,無需顯式使用,在訪問一張表的時候會自動加上。
這里的元數據,可以簡單理解為就是一張表的表結構, 也就是說,某一張表涉及到未提交的事務時,是不能夠修改這張表的表結構的。
在MySQL5.5中引入了MDL,當對一張表進行增刪改查的時候,加MDL讀鎖(共享)除EXCLUSIVE的其他元數據鎖;當對表結構進行變更操作的時候,加MDL寫鎖(排他)EXCLUSIVE。
MDL讀鎖:防止DDL語句,即修改表結構
MDL寫鎖:防止DML和DQL即增刪改查
當事務執行提交后,就會釋放MDL讀鎖。
注:所有除EXCLUSIVE元數據鎖,其目的都是防止表結構被修改,不管是SHARED_READ或者其他的都是這樣,圖片第一列是表鎖,上表鎖也會上一個元數據鎖,表鎖是防止寫/讀(上一小節),而元數據鎖是防止DDL語句修改表結構,達到協同作用

意向鎖
為了避免 DML 在執行時,加的行鎖與表鎖的沖突,在 InnoDB 中引入了意向鎖,使得表鎖不用檢查每行數據是否加鎖,使用意向鎖來減少表鎖的檢查。
假如沒有意向鎖,客戶端一對表的某一行加了行鎖后,客戶端二想給表加表鎖時,會從第一行數據,檢查到最后一行數據查找是否有行鎖。如果沒有,則會添加表鎖,如果存在,則不添加。這種方法效率非常低
有了意向鎖之后,客戶端一在執行 DML 操作時,會對涉及的行加行鎖,同時也會對該表加上意向鎖。
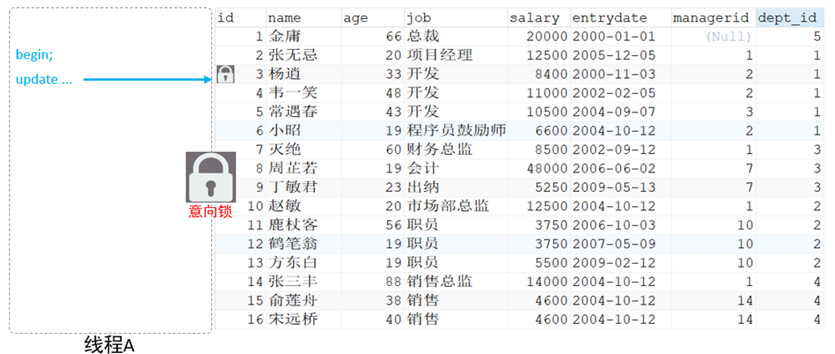
而其他客戶端,在對這張表加表鎖的時候,會根據該表上所加的意向鎖來判定是否可以成功加表鎖,而不用逐行判斷行鎖情況了。
意向鎖和表鎖兼容即可加
意向鎖和表鎖不兼容即不可加
意向鎖類型和兼容狀態
分類:
- 意向共享鎖 (IS): 由語句
select ... lock in share mode(普通 select 不加鎖) 添加 。 與表共享讀鎖 (read lock) 兼容,與表獨占寫(write lock)互斥。 - 意向排他鎖 (IX): 由insert、update、delete、select…for update添加 。與表鎖共享鎖 (read) 及排他鎖 (write) 都互斥,意向鎖之間不會互斥。
和我的理解一樣,就是有一個意向鎖,標識了整張表中行鎖的狀態,所以上表鎖的時候,只需要檢查意向鎖即可判斷能否加標鎖
select * from score where id=1 lock in share mode;
會給這行加上行鎖的共享鎖,同時為score這張表加上意向共享鎖,此時可以給表加讀鎖,但是不能加寫鎖。
意向鎖會在事務提交后解鎖
行級鎖
介紹
行級鎖,每次操作鎖住對應的行數據。鎖定粒度最小,發生鎖沖突的概率最低,并發度最高。應用在InnoDB存儲引擎中。
InnoDB的數據是基于索引組織的,行鎖是通過對索引上的索引項加鎖來實現的,而不是對記錄加的鎖。
所以update的優化,需要加索引防止表鎖
對于行級鎖,主要分為以下三類:
- 行鎖(Record Lock):鎖定單個行記錄的鎖,防止其他事務對此行進行 update 和 delete。在RC(讀未提交)、RR(讀已提交)隔離級別下都支持。

- 間隙鎖(Gap Lock):鎖定索引記錄間隙(不含該記錄),確保索引記錄間隙不變,防止其他事務在這個間隙進行
insert,產生幻讀。在 RR 隔離級別下支持。

- 臨鍵鎖(Next-Key Lock):行鎖和間隙鎖組合,同時鎖住數據,并鎖住數據
前面的間隙Gap。在RR隔離級別下支持

行鎖
InnoDB 實現了以下兩種類型的行鎖:
- 共享鎖(S):允許一個事務去讀一行,阻止其他事務獲得相同數據集的排它鎖。
- 排他鎖(X):允許獲取排他鎖的事務更新數據,阻止其他事務獲得相同數據集的共享鎖和排他鎖。
兩種行鎖的兼容情況如下:
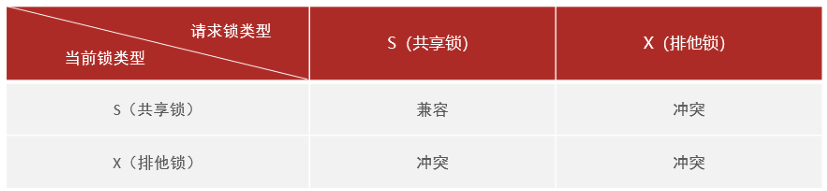
常見的SQL語句,在執行時,所加的行鎖如下:

默認情況下,InnoDB在REPEATABLE READ(可重復讀)事務隔離級別運行,InnoDB使用next-key-臨鍵鎖進行搜索和索引掃描,以防止幻讀。
- 針對唯一索引進行檢索時,對已存在的記錄進行等值匹配時,將會自動優化為行鎖。
- 對于 行鎖類型:排他鎖 來說InnoDB的行鎖是針對于索引加的鎖,不通過索引條件檢索數據,那么InnoDB將對表中的所有記錄加鎖,此時就會升級為表鎖。
間隙鎖&臨鍵鎖
默認情況下,InnoDB在 REPEATABLE READ 事務隔離級別運行,InnoDB 使用 next-key 鎖進行搜索和索引掃描,以防止幻讀。
- 針對唯一索引進行檢索時,對不存在的記錄進行等值匹配時,將會自動優化為間隙鎖。
現在只有id=1,3,8,...
begin;
update stu set age = 10 where id = 5;//此時沒有id=5的數據
這里就不會加行鎖了,而會加間隙鎖
鎖住3-8之間的間隙,該間隙鎖不會鎖3和8對應的記錄,鎖的只是間隙
此時insert into stu values(7,'ruby',18);是阻塞的,因為7在3-8中間,需要等待間隙鎖釋放
- 索引上的等值查詢(普通索引),向右遍歷時最后一個值不滿足查詢需求時,next-key lock 退化為間隙鎖。
比如說現在有age為非唯一索引,age有1,3,7,.....
begin;
select * from stu where age = 3 lock in share mode;
由于age為非唯一索引,不確定age=3的有幾個,也不確定事務未提交前,是否別的事務會插入age=3的數據
所以此時,有三個鎖
1.鎖住age=3這一行的行鎖,共享鎖S
2.鎖住1-3之間間隙的間隙鎖
3.鎖住3-7之間的間隙鎖
就是把等值數據和其旁邊間隙鎖住
- 索引上的范圍查詢(唯一索引) ,會訪問到不滿足條件的第一個值為止。
現在有age 19,25;后面就沒了
begin;
select * from stu where id>=19 lock in share mode;
此時會有三個鎖
1.先鎖19這一行的行鎖
2.19-25之間的臨鍵鎖,鎖25行和19-25之間的間隙
3.臨鍵鎖,鎖25-正無窮之間的間隙和正無窮這個值(???有疑問)
注意:間隙鎖唯一目的是防止其他事務插入間隙。間隙鎖可以共存,一個事務采用的間隙鎖不會阻止另一個事務在同一間隙上采用間隙鎖。
鎖的釋放條件
所有隱式生效的鎖,都會在事務提交后解鎖
所有顯示上的鎖,都需要自己執行解鎖語句







![[ctfshow web入門] web68](http://pic.xiahunao.cn/[ctfshow web入門] web68)




詳解)

)
簡介)


:數據一致性)
實例應用講解)