概述
一致性就是數據保持一致,在分布式系統中,可以理解為多個節點中數據的值是一致的。
強一致性:這種一致性級別是最符合用戶直覺的,它要求系統寫入什么,讀出來的也會是什么,用戶體驗好,但實現起來往往對系統的性能影響大弱一致性:這種一致性級別約束了系統在寫入成功后,不承諾立即可以讀到寫入的值,也不承諾多久之后數據能夠達到一致,但會盡可能地保證到某個時間級別(比如秒級別)后,數據能夠達到一致狀態最終一致性:最終一致性是弱一致性的一個特例,系統會保證在一定時間內,能夠達到一個數據一致的狀態。這里之所以將最終一致性單獨提出來,是因為它是弱一致性中非常推崇的一種一致性模型,也是業界在大型分布式系統的數據一致性上比較推崇的模型
緩存可以提升性能、緩解數據庫壓力,但是使用緩存也會導致數據不一致性的問題。
三種經典的緩存模式
有三種經典的緩存模式:
- Cache-Aside Pattern:旁路緩存模式
- Read-Through/Write through:讀寫穿透
- Write behind:異步緩存寫入
Cache-Aside Pattern(旁路緩存模式)
Cache-Aside Pattern,即旁路緩存模式,它的提出是為了盡可能地解決緩存與數據庫的數據不一致問題。
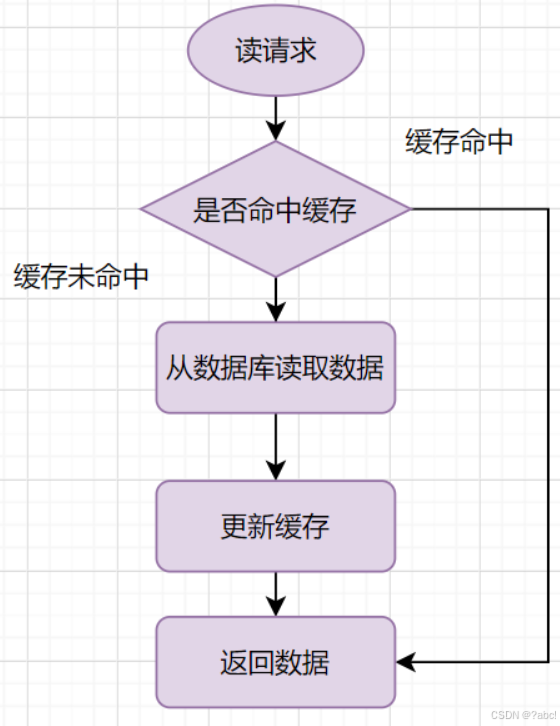
讀
讀請求流程如下:
- 讀的時候,先讀緩存,緩存命中的話,直接返回數據;
- 緩存沒有命中的話,就去讀數據庫,從數據庫取出數據,放入緩存后,同時返回響應。
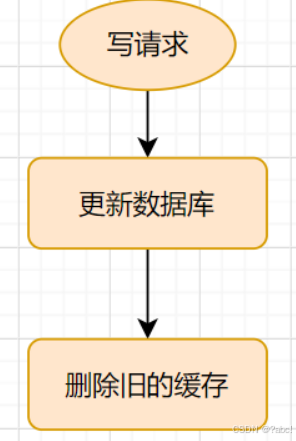
寫
寫請求流程如下:
更新的時候,先更新數據庫,然后再刪除緩存。
問題
為什么這是直接刪除緩存?
如果是更新的話,會有下述幾個缺點
- 會出現數據不一致問題,假設:
- 線程A先發起一個寫操作,第一步先更新數據庫;
- 線程B再發起一個寫操作,第二步更新了數據庫
- 由于網絡等原因,線程B先更新了緩存, 線程A更新緩存
- 這時候,
緩存保存的是A的數據(老數據),數據庫保存的是B的數據(新數據),數據不一致了,臟數據出現 - 這時候,
如果是刪除緩存取代更新緩存則不會出現這個臟數據問題
- 如果你寫入的緩存值,是經過復雜計算才得到的話。 更新緩存頻率高的話,就浪費性能
- 寫多讀少的情況下,數據很多時候還沒被讀取到,又被更新了,這也浪費了性能
但是如果是更新緩存的話,在讀多寫少的場景,價值大。
為什么先操作數據庫后操作緩存
假設有A、B兩個請求,請求A做更新操作,請求B做查詢讀取操作。
如果是先操作緩存的話,A、B兩個請求的操作流程如下:
- 線程
A發起一個寫操作,第一步del cache - 此時線程
B發起一個讀操作,cache miss - 線程
B繼續讀DB,讀出來一個老數據 - 然后
線程B把老數據設置入cache - 線程A寫入DB最新的數據
如果是先操作緩存的話便會出現:緩存保存的是老數據,數據庫保存的是新數據。
因此,Cache-Aside緩存模式,選擇了先操作數據庫而不是先操作緩存。
數據不一致情況
情況的核心是
線程1:DB寫操作和刪除緩存在事務中,刪除緩存后,事務還未提交。
線程2:緩存已經刪除,從DB讀后,寫入緩存。
由于線程1的事務未提交,線程2讀取并放入緩存的的還是舊數據,導致數據最終不一致。
但,這個case理論上會出現,不過,實際上出現的概率可能非常低,因為這個條件需要發生在讀緩存時緩存失效,而且并發著有一個寫操作。
而實際上數據庫的寫操作會比讀操作慢得多,而且還要鎖表,而讀操作必需在寫操作前進入數據庫操作,而又要晚于寫操作更新緩存,所有的這些條件都具備的概率基本并不大。
所以,要么通過2PC或是Paxos協議保證一致性,要么就是拼命的降低并發時臟數據的概率,
而Facebook使用了這個降低概率的玩法,因為2PC太慢,而Paxos太復雜。
當然,最好還是為緩存設置上過期時間。
解決方案: 刪除緩存,做2次刪除:
- 直接刪除;
- 注冊事務回調,事務結束(提交或回滾)后再次刪除。
Read-Through/Write through(讀寫穿透)
Read/Write Through模式中,服務端把緩存作為主要數據存儲。應用程序跟數據庫緩存交互,都是通過抽象緩存層完成的。
- 可以理解為,
應用認為后端就是一個單一的存儲,而存儲自己維護自己的Cache。
讀
Read-Through實際只是在Cache-Aside之上進行了一層封裝,它會讓程序代碼變得更簡潔,同時也減少數據源上的負載。
Read-Through讀流程如下
從緩存讀取數據,讀到直接返回- 如果
讀取不到的話,從數據庫加載,寫入緩存后,再返回響應。
流程如下所示
實例應用講解)




)






)






)