作者:來自 Elastic?Tomás Murúa

了解 RAG、grounding,以及如何通過將 LLM 連接到你的文檔來減少幻覺。
更多閱讀:Elasticsearch:在 Elastic 中玩轉 DeepSeek R1 來實現 RAG 應用
想獲得 Elastic 認證嗎?查看下一期 Elasticsearch Engineer 培訓的時間!
Elasticsearch 擁有大量新功能,幫助你為你的使用場景構建最佳搜索方案。深入學習我們的示例 notebook,了解更多信息,開始免費的 cloud 試用,或者現在就在你的本地機器上嘗試 Elastic 吧。
大型語言模型(LLM)能夠生成連貫的回答,但當你需要真實且更新的信息時,它們可能會產生幻覺(編造數據)并給出不可靠的答案。為防止這種情況,我們使用 grounding 來為模型提供專門的、針對特定使用場景的、相關的上下文信息,超越 LLM 的訓練內容。
Grounding 是將特定數據源連接到模型的過程,用于將其 “接地” 到真實內容,而不是僅依賴模型訓練時學到的模式,從而提供更可靠和更準確的答案。
Grounding 有助于減少模型幻覺,根據你的數據源生成響應,并通過提供引用讓你能夠審查回答內容。
檢索增強生成( Retrieval Augmented Generation?- RAG )是一種 grounding 技術,它使用搜索算法從外部來源檢索相關信息,然后將這些信息作為上下文提供給 LLM,最后模型結合增強后的上下文和其原始訓練數據生成答案。
RAG 的工作流程圖如下:
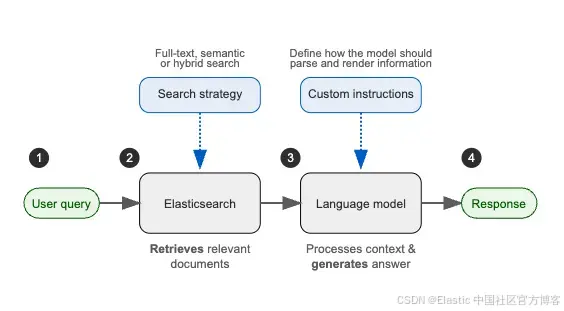
RAG 讓你可以通過更新或擴展模型可訪問的外部數據源來輕松擴展系統。同時,它也是一種相較于微調 LLMs 更具性價比的替代方案,因為你只需添加數據,無需大量定制。
而且由于 RAG 可以訪問并使用最新信息,它非常適合那些對最新信息要求較高的使用場景。
幻覺示例
在這個例子中,我們將使用 DeepSeek 并提問:“Who is the author who won the Chilean National Literature Prize in 1932?” 這是一個有陷阱的問題,因為這個獎項是在 1942 年才設立的。讓我們看看模型是如何回答的:

如你所見,由于 AI 沒有完整的信息,它產生了幻覺并給出了一個編造的答案。盡管作者和作品是真實存在的,但回答中的其他部分是錯誤的。
現在,我們來看看當我們使用 RAG 進行 grounding 后,模型的表現如何。為此,我們將上傳關于智利國家文學獎的 Wikipedia 頁面:

現在,讓我們再次提出同樣的問題并檢查答案:

如你所見,使用 RAG 后我們得到了正確的答案。它指出 1932 年沒有頒發該獎項,并請求用戶進一步澄清問題。
在 Playground 中使用 RAG
通過使用 Elasticsearch,你可以輕松擴展,唯一的限制是集群容量。你可以使用不同的數據源和連接器(connectors)來獲取所需數據。此外,你完全擁有你的數據,因為它保留在你的基礎設施中,不會上傳到第三方服務;如果你運行本地 LLM,你的數據甚至不會離開你的網絡。最后,你可以通過設計查詢和基于訪問控制( RBAC )的過濾方式來控制搜索過程。
我們將使用 Playground,這是我們的低代碼平臺,它可以讓你快速簡單地使用 Elasticsearch 內容創建 RAG 應用。
以下是一個逐步指南,教你如何將 PDF 或其他文檔上傳到 Playground。你也可以在這里查看更多信息,并在這里試用 Playground。
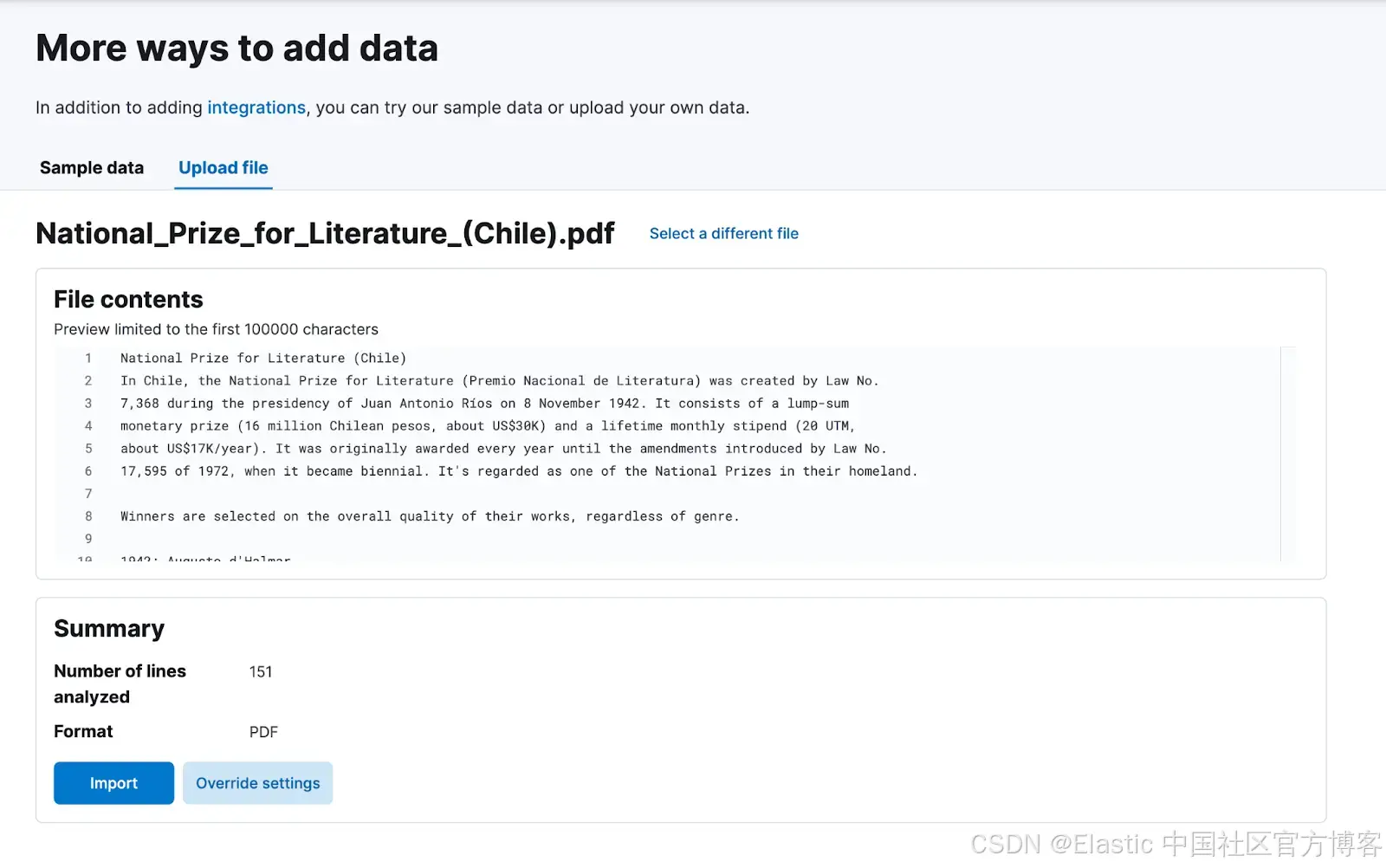
上傳 PDF
我們將把與 DeepSeek 提供的相同 PDF 文件索引到 Kibana 中。如果你按照上面文章中的步驟操作并創建了 semantic_text 字段,你將創建一個帶有相應嵌入的向量數據庫,準備好供使用。
提問
提問以下問題:
“Who is the author who won the Chilean National Literature Prize in 1932?”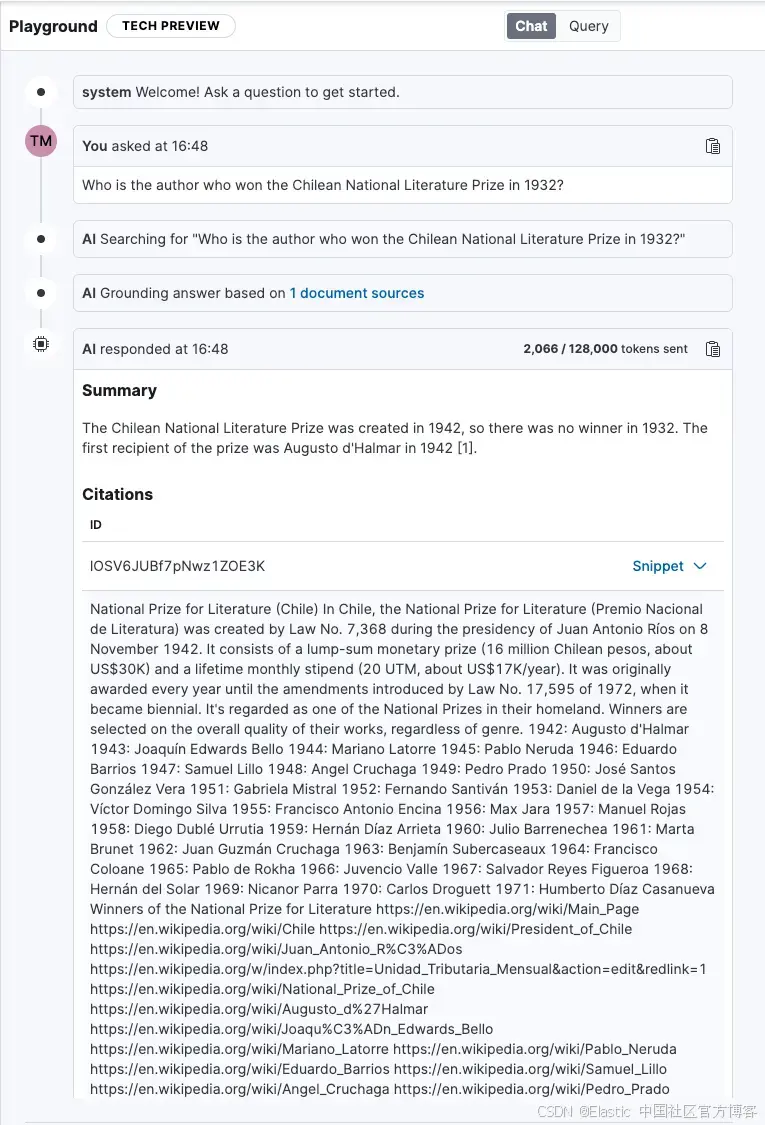
Playground 將此查詢發送到 Elasticsearch,Elasticsearch 運行語義搜索并定位與問題相關的信息片段。然后,這些片段作為上下文被包含在發送給 LLM 的提示中,以便將答案與我們提供的信息源進行 grounding。
最后,Playground 生成的答案說明 1932 年沒有頒發獎項,并提供相關片段的引用作為證據。
Playground 還提供了兩個非常有用的功能,以幫助理解 RAG 系統的底層組件:
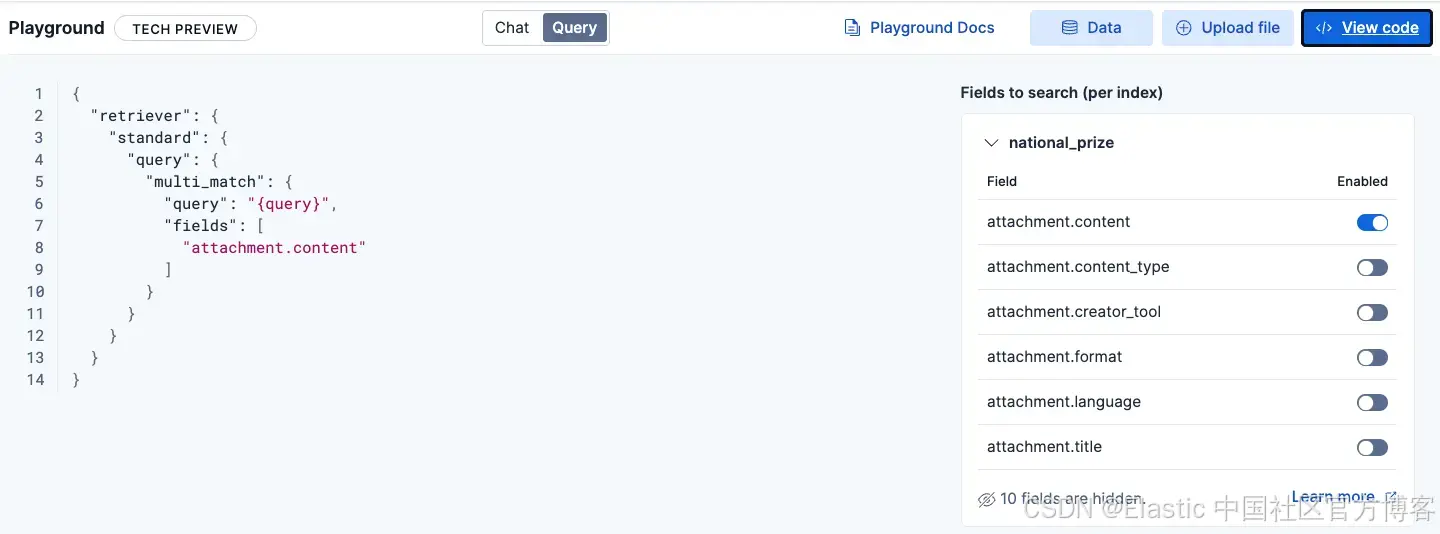
查詢
你可以查看 Elasticsearch 正在運行的查詢,以檢索相關文檔,并根據需要啟用/禁用字段。
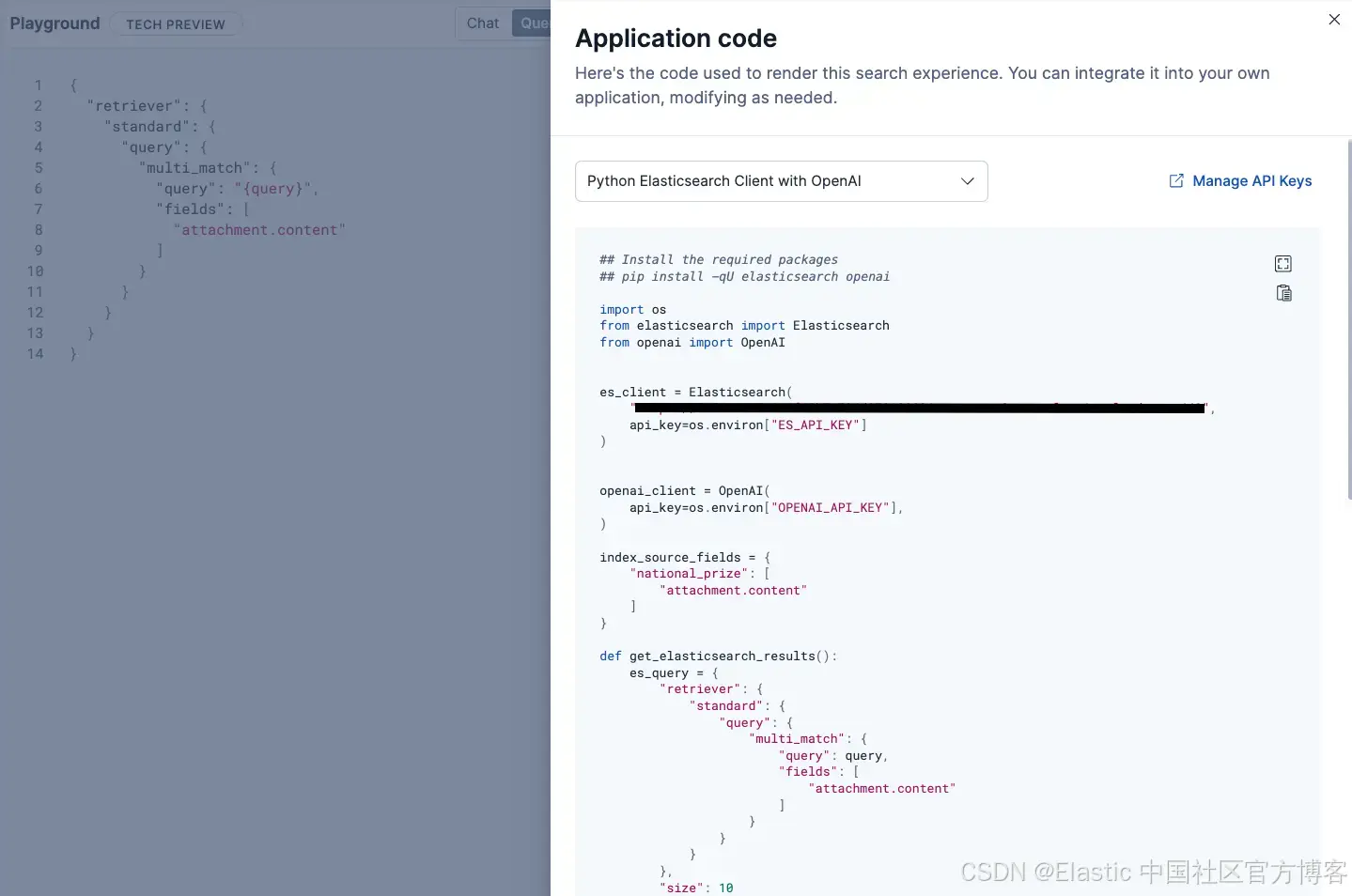
查看代碼
如果你可以部署你的 RAG 應用,Playground 為你提供支持。在 "View Code" 標簽下,你可以查看用于創建整個 RAG 工作流的底層代碼。你可以選擇兩種 Python 方案:使用 Elasticsearch 客戶端與 OpenAI,或基于 Langchain 的實現。
如果你想定制體驗并將代碼部署到其他地方,你可以使用這個代碼片段作為起點。
結論
Grounding 是一個將 LLM 連接到外部數據源的過程,使它們能夠超越訓練內容,提供更準確和可信的答案。檢索增強生成(RAG)是一種 grounding 方法,它具有可擴展性、性價比高,并確保可以訪問最新的信息。
像 Playground 這樣的工具通過啟用大規模索引、定制搜索和帶有引用的響應,簡化了 RAG 的實施,這使你能夠輕松驗證答案并確保獲得準確和可信的結果。
如果你想關于 RAG 特性的深入文章,可以從這篇開始,獲得 RAG 的更技術性定義。你還可以查看《Rag vs. fine-tuning: When RAG is the best decision》,《How to leverage document security using RAG》以及《RAG systems in production》。
原文:RAG and the value of grounding - Elasticsearch Labs


)
B題【顏色轉換】原論文講解(含完整python代碼))



![[2025]MySQL的事務機制是什么樣的?redolog,undolog、binog三種日志的區別?二階段提交是什么?ACID怎么保證的?主從復制的過程?](http://pic.xiahunao.cn/[2025]MySQL的事務機制是什么樣的?redolog,undolog、binog三種日志的區別?二階段提交是什么?ACID怎么保證的?主從復制的過程?)










)
