MySQL事務機制與日志系統詳解
一、MySQL事務機制
1. 事務特性(ACID)
| 特性 | 實現機制 |
|---|---|
| 原子性(Atomicity) | undo log回滾,(事務作為一個整體被執行,包含在其中的對數據庫的操作要么全部被執行,要么都不執行)。 |
| 一致性(Consistency) | 約束檢查+雙寫緩沖(事務應確保數據庫的狀態從一個一致狀態轉變為另一個一致狀態。一致狀態的含義是數據庫中的數據應滿足完整性約束。) |
| 隔離性(Isolation) | MVCC+鎖機制(多個事務并發執行時,一個事務的執行不應影響其他事務的執行。) |
| 持久性(Durability) | redo log持久化(一個事務一旦提交,他對數據庫的修改應該永久保存在數據庫中) |
2. 事務隔離級別
首先需要了解
臟讀:讀到了其他事務還沒有提交的數據。
不可重復讀:對某數據進行讀取過程中,有其他事務對數據進行了修改(UPDATE、DELETE),導致第二次讀取的結果不同。
幻讀:事務在做范圍查詢過程中,有另外一個事務對范圍內新增了記錄(INSERT),導致范圍查詢的結果條數不一致。
?
| 級別 | 臟讀 | 不可重復讀 | 幻讀 | 實現方式 |
|---|---|---|---|---|
| 讀未提交 | 可能 | 可能 | 可能 | 無鎖 |
| 讀已提交 | 不可能 | 可能 | 可能 | MVCC快照讀 |
| 可重復讀 | 不可能 | 不可能 | 可能(InnoDB實際避免) | 一致性視圖 |
| 串行化 | 不可能 | 不可能 | 不可能 | 讀寫鎖 |
1.查看當前會話隔離級別
select @@tx_isolation;
在MySQL 8.0中:SELECT @@transaction_isolation;
2.查看系統當前隔離級別
select @@global.tx_isolation;
3.設置當前會話隔離級別
set session transaction isolatin level repeatable read;
4.設置系統當前隔離級別
set global transaction isolation level repeatable read;
5.命令行,開始事務時
set autocommit=off 或者 start transaction
一次InnnoDB的update操作,涉及到BufferPool、BinLog、UndoLog、RedoLog以及物理磁盤,完整的一次操作過程基本如下:
1、在Buffer Pool中讀取數據:當InnoDB需要更新一條記錄時,首先會在Buffer Pool中查找該記錄是否在內存中。如果沒有在內存中,則從磁盤讀取該頁到Buffer Pool中。
2、記錄UndoLog:在修改操作前,InnoDB會在Undo Log中記錄修改前的數據。Undo Log是用來保證事務原子性和一致性的一種機制,用于在發生事務回滾等情況時,將修改操作回滾到修改前的狀態,以達到事務的原子性和一致性。UndoLog的寫入最開始寫到內存中的,然后由1個后臺線程定時刷新到磁盤中的。
3、在Buffer Pool中更新:當執行update語句時,InnoDB會先更新已經讀取到Buffer Pool中的數據,而不是直接寫入磁盤。同時,InnoDB會將修改后的數據頁狀態設置為“臟頁”(Dirty Page)狀態,表示該頁已經被修改但尚未寫入磁盤。
4、記錄RedoLog Buffer:InnoDB在Buffer Pool中記錄修改操作的同時,InnoDB 會先將修改操作寫入到 redo log buffer 中。
5、提交事務:在執行完所有修改操作后,事務被提交。在提交事務時,InnoDB會將Redo Log寫入磁盤,以保證事務持久性。
6、寫入磁盤:在提交過程后,InnoDB會將Buffer Pool中的臟頁寫入磁盤,以保證數據的持久性。但是這個寫入過程并不是立即執行的,是有一個后臺線程異步執行的,所以可能會延遲寫入,總之就是MYSQL會選擇合適的時機把數據寫入磁盤做持久化。
7、記錄Binlog:在提交過程中,InnoDB會將事務提交的信息記錄到Binlog中。Binlog是MySQL用來實現主從復制的一種機制,用于將主庫上的事務同步到從庫上。在Binlog中記錄的信息包括:事務開始的時間、數據庫名、表名、事務ID、SQL語句等。
?
?
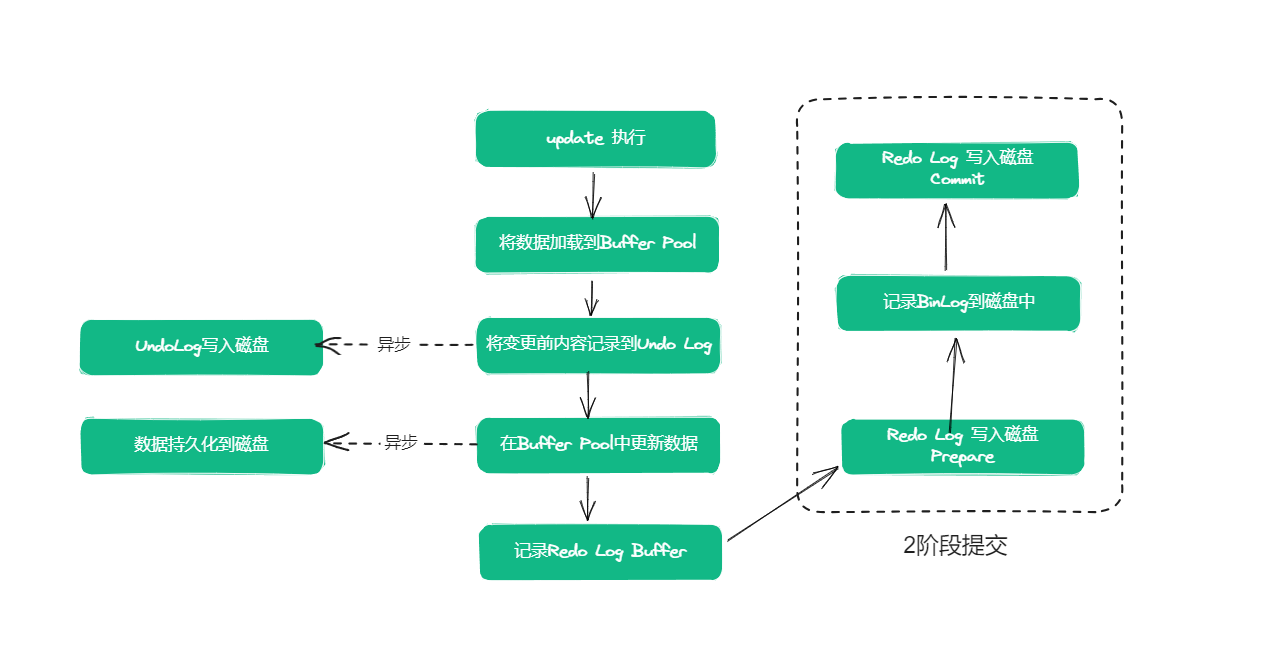
需要注意的是,在binlog和redolog的寫入過程中,其實是分成了2階段的,通過2階段提交的方式來保證一致性的。
一次insert操作呢:
1、寫入undolog,先將事務修改前的數據記錄到Undo Log中。
2、寫入redolog,處于prepare階段 (表示事務已修改但未提交)。
3、寫入binlog,將binlog 內存日志數據寫入文件緩沖區并刷新到磁盤中。
4、寫入redolog,處于commit階段。
二、三大日志系統對比
在MySQL中,redo log和undo log只適用于InnoDB存儲引擎,因為要支持事務。而不適用于MyISAM等其他存儲引擎。而binlog則適用于所有存儲引擎。
1. redo log(重做日志)
Redo Log是MySQL用于實現崩潰恢復和數據持久性的一種機制
作用:
-
確保事務持久性
-
實現WAL(Write-Ahead Logging)機制
-
崩潰恢復時重放已提交事務
特點:
-
物理日志(記錄頁的修改)
-
循環寫入(固定大小文件組)
-
InnoDB引擎特有
配置參數:
innodb_log_file_size = 512M # 單個日志文件大小 innodb_log_files_in_group = 2 # 日志文件數量
2. undo log(回滾日志)
Undo Log則用于在事務回滾或系統崩潰時撤銷(回滾)事務所做的修改。Undo Log還支持MVCC(多版本并發控制)機制,用于在并發事務執行時提供一定的隔離性。
作用:
-
事務回滾時恢復數據
-
實現MVCC多版本控制
-
提供一致性讀視圖
特點:
-
邏輯日志(記錄反向SQL)
-
存儲在系統表空間或獨立undo表空間
-
隨事務結束逐漸清理
存儲結構:
-- 查看undo表空間 SHOW VARIABLES LIKE 'innodb_undo%';
3. binlog(歸檔日志)
用來數據備份、崩潰恢復、主從復制。主要用來對數據庫進行數據備份、崩潰恢復和數據復制等操作
特點:
-
Server層實現(所有引擎通用)
-
邏輯日志(SQL語句或行事件)
-
追加寫入(可配置大小)
三種格式:
| 格式 | 寫入時機 | 性能 | 安全性 |
|---|---|---|---|
| STATEMENT | 事務提交(SQL 語句的原文) | 高 | 低(導致主從同步的數據不一致) |
| ROW | 事務提交(每個數據更改的具體行的細節) | 低(記錄更多的內容) | 高(記錄行變化) |
| MIXED | 自動選擇 | 中 | 中 |
在RR下,row和statement都可以生效,但是在RC下,只有row格式才能生效。具體見上面我們貼的那個鏈接的內容。
三、二階段提交(2PC)
1. 跨日志協調過程
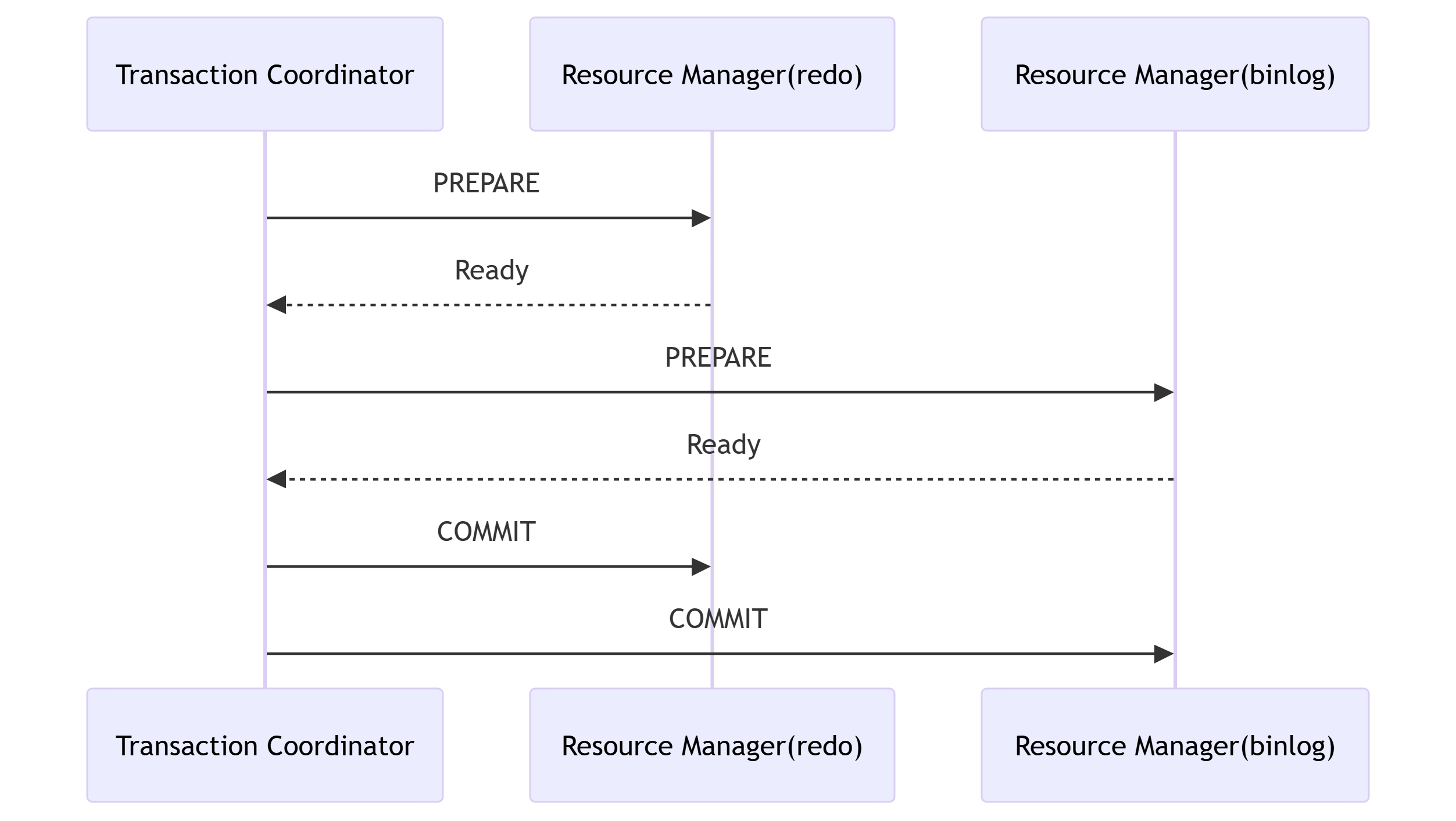
2. MySQL實現流程
-
●Prepare 階段
????????○這個階段 SQL 已經成功執行并生成 redolog,處于prepare階段
●BinLog持久化
????????○binlog 提交,通過 write() 將 binlog 內存日志數據寫入文件緩沖區;
????????○通過fsync() 將 binlog 從文件緩沖區永久寫入磁盤;
●Commit
????????○在執行引擎內部執行事務操作,更新redolog,處于Commit階段
write 操作將數據寫入文件的緩沖區,這意味著 write 操作完成后,并不一定立即將數據持久化到磁盤上,而是將數據暫時存儲在內存中。
fsync 用于強制將文件的修改持久化到磁盤上。它通常與 write 配合使用,以確保文件的修改在 fsync 操作完成后被寫入磁盤。
3. 崩潰恢復邏輯
-
binlog無記錄:回滾事務(redo prepare但未commit)
-
binlog完整:提交事務(重放redo log)
四、ACID保證機制
1. 原子性實現
// 偽代碼:事務執行過程
void execute_transaction() {write_undo_log(); // 記錄回滾信息write_redo_log(PREPARE);execute_sql();write_binlog();write_redo_log(COMMIT); // 最終提交
}
2. 隔離性實現
MVCC核心結構:
-
ReadView機制:包含m_ids(活躍事務ID列表),幫我們解決可見性的問題的, 即他會來告訴我們本次事務應該看到哪個快照,不應該看到哪個快照。
-
版本鏈:通過DB_ROLL_PTR指針串聯undo log
可見性判斷規則:基于redaview實現。一個事務,能看到的是在他開始之前就已經提交的事務的結果,而未提交的結果都是不可見的。
●trx_ids,表示在生成ReadView時當前系統中活躍的讀寫事務的事務id列表。
●low_limit_id,應該分配給下一個事務的id 值。
●up_limit_id,未提交的事務中最小的事務 ID。
●creator_trx_id,創建這個 Read View 的事務 ID。
3. 持久性保證
-
redo log刷盤策略:
innodb_flush_log_at_trx_commit = 1 # 每次提交刷盤
-
雙寫緩沖:防止頁斷裂
// 寫入流程 write_to_doublewrite_buffer(); write_to_data_file();
五、主從復制過程
MySQL 5.6推出基于庫級別的并行復制。
可以配置多個庫并行進行復制,這意味著每個庫都可以有自己的復制線程,可以并行處理來自不同庫的寫入。這提高了并行復制的性能和效率。
MySQL 5.7推出基于組提交的的并行復制。
它通過將多個事務的提交操作合并成一個批處理操作來減少磁盤IO和鎖定開銷,從而加速事務的處理,簡單來說就是將多個事務的提交操作可以合并成一個批處理操作,以減少磁盤IO次數。
一個組中多個事務,都處于Prepare階段之后,才會被優化成組提交。那么就意味著如果多個事務他們能在同一個組內提交,這個就說明了這個幾個事務在鎖上是一定是沒有沖突的。換句話說,就是這幾個事務修改的一定不是同一行記錄,所以他們之間才這樣Slave就可以用多個SQL線程來并行的執行一個組提交中的多條SQL,從而提升效率,降低主從延遲。能互不影響,同時進入Prepare階段,并且進行組提交。
事務的二階段提交就跟原生的有點區別。因為日志的刷盤過程會因為組提交而需要等待
組提交的二階段提交
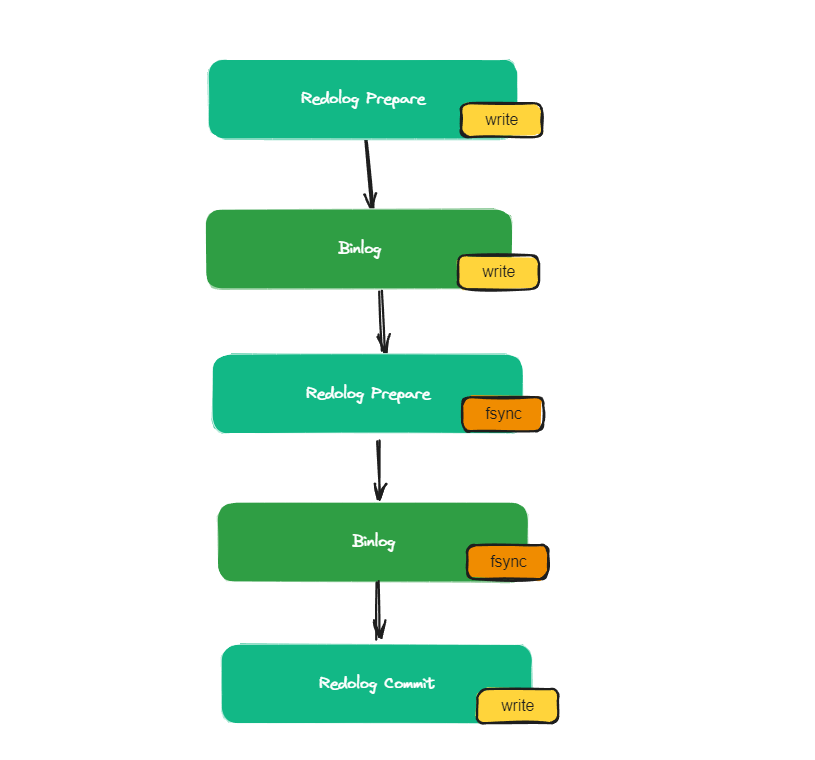
MySQL 8.0 推出基于WRITESET的并行復制。
WriteSet 是通過檢測兩個事務是否更新了相同的記錄來判斷事務能否并行回放的,因此需要在運行時保存已經提交的事務信息以記錄歷史事務更新了哪些行,并且在做更新的時候進行沖突檢測,拿新更新的記錄計算出來的hash值和WriteSet作比較,如果不存在,那么就認為是不沖突的,這樣就可以共用同一個last_committed 、
last_committed 指的是該事務提交時,上一個事務提交的編號。
就這樣,就能保證同一個write_set中的變更都是不沖突的,那么同一個write_set就可以并行的通過多個線程進行回放SQL了。
1. 復制原理
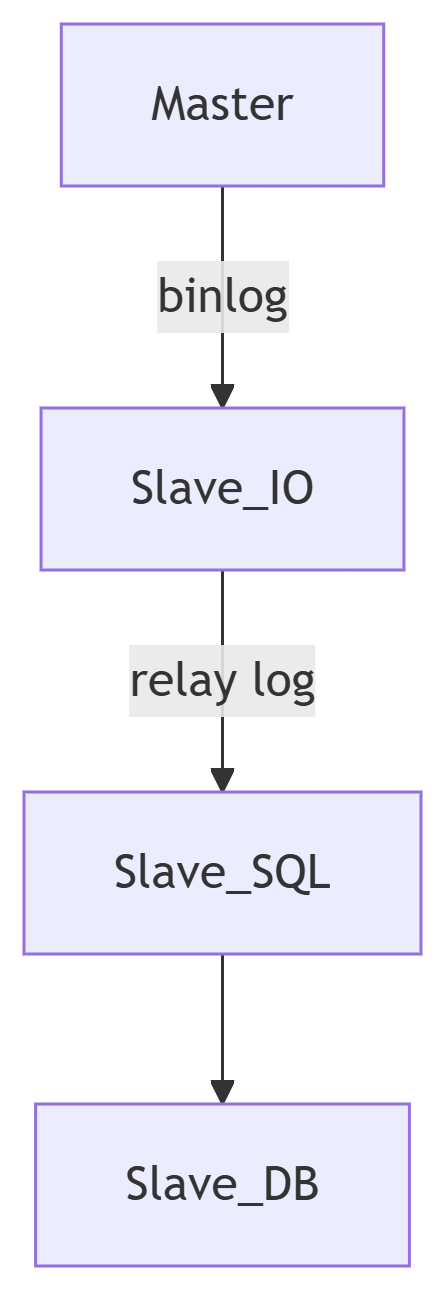
2. 詳細步驟
-
主庫:
-
事務提交時寫入binlog
-
通過dump線程發送事件
-
-
從庫:
-
IO線程:拉取binlog到relay log
-
SQL線程:重放relay log中的事件
-
狀態報告:
SHOW SLAVE STATUS
-
3. 復制模式
| 模式 | 原理 | 優點 | 缺點 |
|---|---|---|---|
| 異步(默認) | 主庫不等待從庫ACK | 高性能 | 數據可能丟失 |
| 半同步 | 至少一個從庫ACK | 平衡性能與安全 | 網絡影響性能 |
| 全同步 | 全部從庫ACK | 安全性可以保障 | 性能很差 |
4. 配置示例
-- 主庫配置 CREATE USER 'repl'@'%' IDENTIFIED BY 'password'; GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';-- 從庫配置 CHANGE MASTER TOMASTER_HOST='master_host',MASTER_USER='repl',MASTER_PASSWORD='password',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=107; START SLAVE;
5.主從延遲問題
數據庫的主從延遲是指在主從數據庫復制過程中,從服務器(Slave)上的數據與主服務器(Master)上的數據之間存在的時間差或延遲。
一般來說導致主從延遲可能由多種因素引起,以下是一些常見的原因:
網絡延遲:主節點和從節點之間的網絡延遲導致復制延遲這是比較常見的一種情況,
從節點性能問題:從服務器的性能不足也可能導致復制延遲。如果從服務器的硬件資源(CPU、內存、磁盤)不足以處理接收到的復制事件,延遲可能會增加。
復制線程不夠:當從節點只有一個線程,或者線程數不夠的時候,數據回放就會慢,就會導致主從節點的數據延遲。
解決主從延遲主要有幾個事情可以做:
優化網絡:確保主節點和從節點之間的網絡連接穩定,盡量同城或者同單元部署,減小網絡延遲。
提高從服務器性能:增加從服務器的硬件資源,如CPU、內存和磁盤,以提高其性能,從而更快地處理復制事件。
并行復制:借助MySQL提供的并行復制的能力,提升復制的效率,降低延遲。
六、關鍵優化參數
1. 事務相關
transaction-isolation = REPEATABLE-READ innodb_rollback_on_timeout = ON
2. 日志相關
sync_binlog = 1 # binlog刷盤控制 innodb_flush_log_at_trx_commit = 1 # redo刷盤控制 binlog_format = ROW # 推薦使用ROW模式
3. 復制優化
slave_parallel_workers = 4 # 并行復制 slave_preserve_commit_order = ON # 保持事務順序










)








