一、java是怎么做到可重入的
java中,通過synchronized進行加鎖,指定一個()包含了一個鎖對象。(鎖對象本身是一個啥樣的對象,這并不重要,重點關注鎖對象是不是同一個對象)
后面搭配{}.進入遇到{就觸發加鎖操作 遇到 } 就觸發解鎖操作 防止解鎖操作被遺忘
如果一個線程加鎖,一個線程不加鎖;一個線程針對locker1加鎖,一個線程針對locker2加鎖......
鎖相當于都不會產生沖突,不會產生阻塞。
二、synchronized的特性
1.互斥
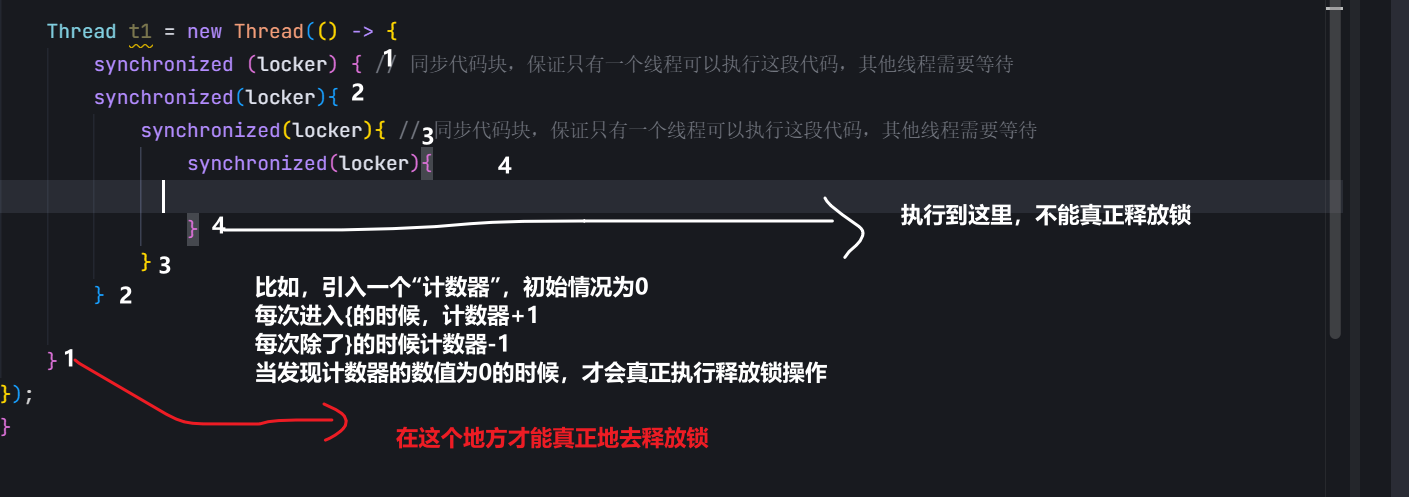
2.可重入 一個線程,一把鎖,這個線程針對這個鎖,連續加鎖兩次
synchronized(locker){
synchronized(locker)
}
locker已經是被加鎖的狀態了.嘗試對一個已經上了鎖進行加鎖,就會產生阻塞
此處阻塞的接觸,需要先釋放第一次鎖
要想釋放第一次加鎖,需要先加上第二次的鎖
一個線程針對一把鎖,連續加鎖多次,不會觸發死鎖——>可重入
可重入這個現象是如何做到的呢?
讓鎖對象本身,記錄下來擁有者是哪個線程(把線程id給保存下來了)
Object...Java的對象,除了又一個內存區域,保存程序員自定義的成員之外,還有一個隱藏區域,用來保存“對象頭”。
對象頭是JVM去維護的,保存了這個對象的一些其他運行信息,例如,加鎖狀態,哪個線程加了鎖等等。
當我們已經給一個對象加鎖了,后序再去針對這個對象加鎖,那么就會先判定,當前嘗試加鎖的線程,是不是已經持有這個鎖的線程。如果沒有,才觸發阻塞,如果有,不觸發阻塞,直接放行。
二、死鎖的情況
可重入鎖,只能處理死鎖的其中一種情況,沒辦法處理其他情況
1.一個線程一把鎖,連續加鎖兩次
2.兩個線程兩把鎖,每個線程先獲得一把鎖,再嘗試獲取對方的鎖
package Thread;public class demo24 {private static Object locker1 = new Object(); private static Object locker2 = new Object(); public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> { synchronized (locker1) { System.out.println("t1拿到了locker1");try {Thread.sleep(1000);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}synchronized (locker2) { System.out.println("t1拿到了locker2"); }}
});Thread t2 = new Thread(() -> {synchronized (locker2) { System.out.println("t2拿到了locker2");try {Thread.sleep(1000);} catch (InterruptedException e) {}synchronized (locker1) { System.out.println("t2拿到了locker1");} } });t1.start();t2.start();t1.join(); // 等待t1線程執行完畢,才能繼續執行后面的代碼t2.join(); // 等待t2線程執行完畢,才能繼續執行后面的代碼}}輸出:

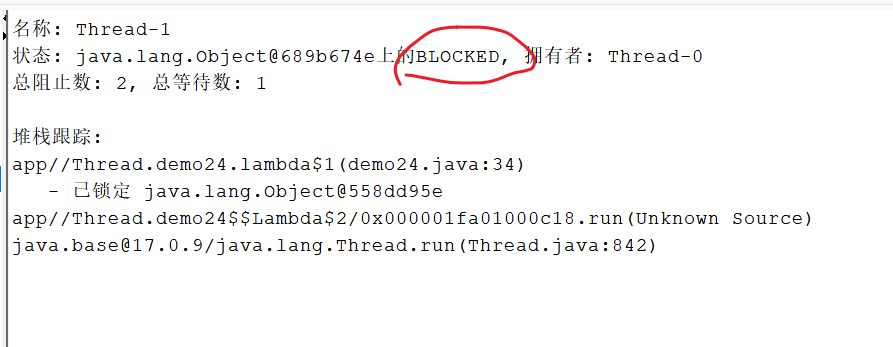
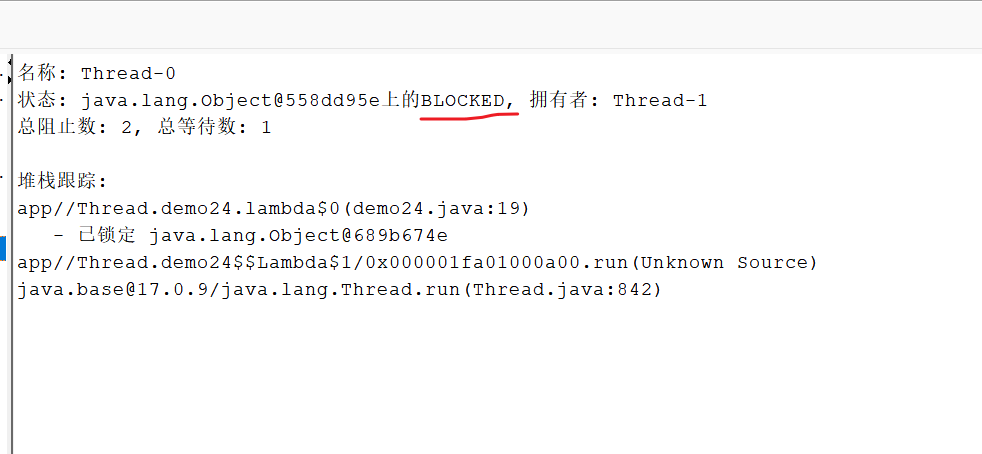
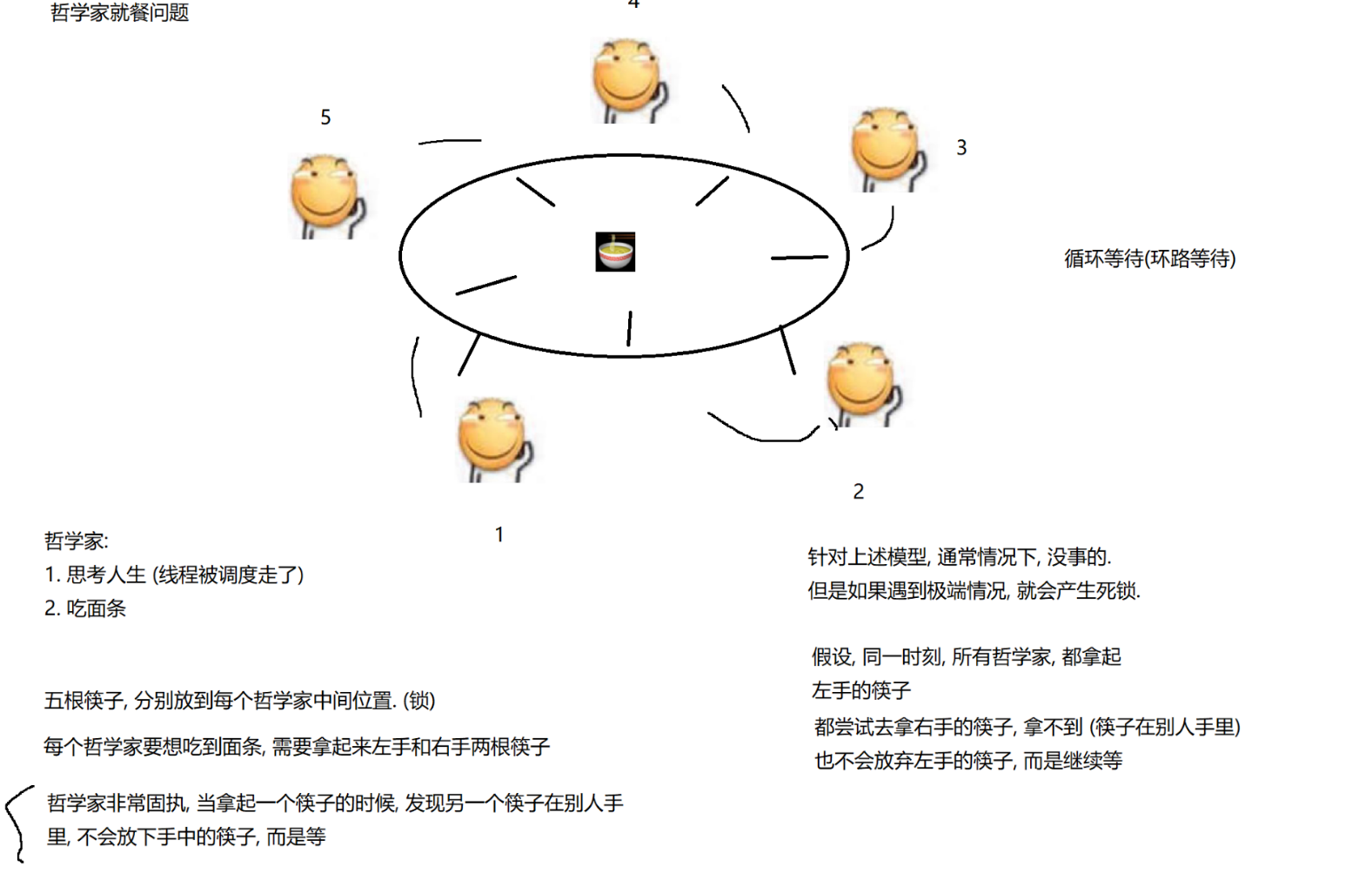
3.N個線程M把鎖,也會構成死鎖
“哲學家就餐問題”
三、如何避免死鎖的出現
死鎖這樣的情況就是會客觀發生的,線程一旦出現死鎖,線程就卡死了,不動了,后序的邏輯就無法正常執行了,這是bug
如何避免代碼中出現死鎖呢?
關鍵在于理解死鎖的“四個必要條件”
1.鎖是互斥的——我們現在正在學習的synchronized是互斥的
2.鎖不可被搶占——線程1拿到鎖之后,線程2也想要這個鎖,線程2會阻塞等待,而不是直接把鎖搶過來
(對于synchronized來說,條件1和條件2 都是synchronized的基本特點)
3.請求和保持——拿到第一把鎖的情況下,不去釋放第一把鎖,再嘗試請求第二把鎖(*確實有一定的場景是需要拿到鎖1 的前提下再嘗試去拿鎖2)
4.循環等待——等待鎖釋放,等待的關系(順序)構成了循環
(*也就是不要讓等待關系構成循環 針對鎖進行編號
;約定,加多個鎖的時候,必須按照一定的順序來加鎖,比如按照編號從小到大的順序)
上述兩種是開發中比較實用的方法,還有一些其他的方案,也能解決死鎖問題。
package Thread;public class demo24 {private static Object locker1 = new Object(); private static Object locker2 = new Object(); public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> { synchronized (locker1) { System.out.println("t1拿到了locker1");try {Thread.sleep(1000);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}synchronized (locker2) { System.out.println("t1拿到了locker2"); }
});Thread t2 = new Thread(() -> {synchronized (locker2) { System.out.println("t2拿到了locker2");try {Thread.sleep(1000);} catch (InterruptedException e) {}} //把第二把鎖的加鎖操作放到第一把鎖的外面,先釋放第一把鎖,再獲取第二把鎖,這樣就不會出現死鎖的情況了。synchronized (locker1) { System.out.println("t2拿到了locker1");} });t1.start();t2.start();t1.join(); // 等待t1線程執行完畢,才能繼續執行后面的代碼t2.join(); // 等待t2線程執行完畢,才能繼續執行后面的代碼}}四、Java 標準庫中的線程安全類
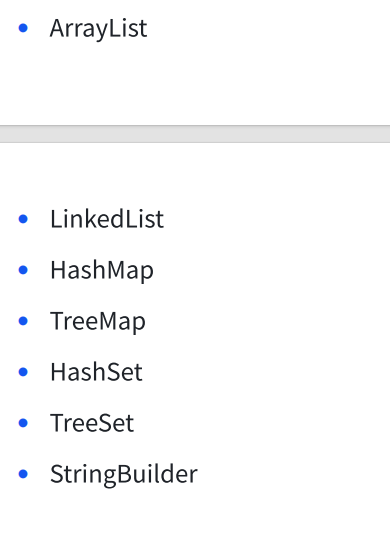
這些常用的集合類,大多是線程不安全的,把加鎖策略交給程序員
但是還有?些是線程安全的. 使用了一些鎖機制來進行控制

其中 Vector 和 HashTable 是Java早年間起,各位java大佬還不夠成熟的時候引入的設定
現在的話這些設定已經被推翻,不建議再使用
有的雖然沒有加鎖, 但是不涉及 "修改", 仍然是線程安全的

*解決線程安全問題,我們使用加鎖的方式。但是加鎖是有代價的,加鎖會非常明顯地影響到程序的執行效率。加鎖意味著可能觸發鎖競爭,一旦觸發競爭就會產生阻塞。某個線程一旦因為加鎖阻塞,能回來繼續執行任務的時間就不確定了。寫代碼的時候需要考慮清楚某個地方是否要加鎖。
五、內存可見性引起的線程安全問題
package Thread;public class Demo15 {public static int count = 0; // 共享變量,多個線程共同修改的變量,稱為共享變量public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> { // 線程t1for (int i = 0; i < 5000; i++) { // 循環5000次count++; // 自增操作,相當于count = count + 1}});Thread t2 = new Thread(() -> { // 線程t2for (int i = 0; i < 5000; i++) { // 循環5000次count++; // 自增操作,相當于count = count + 1}});t1.start(); // 啟動線程t1t2.start(); // 啟動線程t2// 等待線程t1和線程t2執行完畢t1.join(); // 等待線程t1執行完畢t2.join(); // 等待線程t2執行完畢System.out.println(count); // 打印count的值,應該是10000,因為每個線程都自增了5000次}}
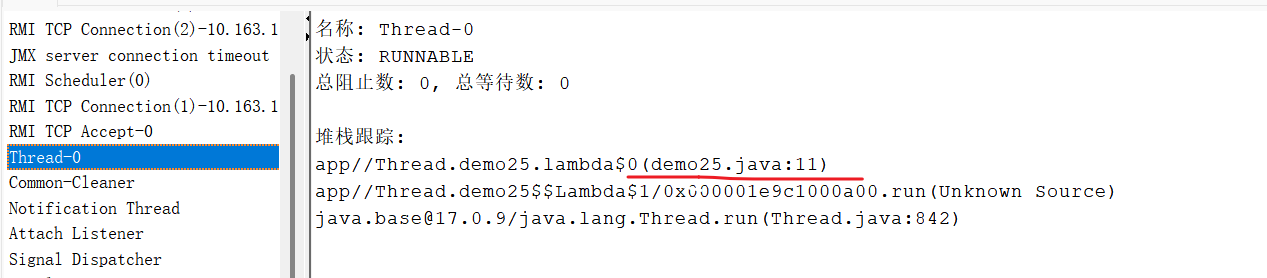
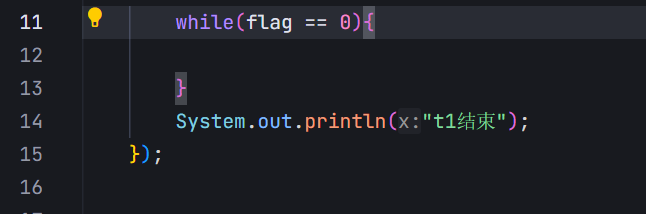
這個問題產生的原因,就是“內存可見性”
flag變量的修改,對于t1線程“不可見了”,t2修改了flag,但是t1看不見
編譯器優化
主流編程語言,編譯器的設計者(對于Java來說,談到的編譯器包括javac和jvm)考慮到一個問題:實際上寫代碼的程序員,水平是參差不齊的(具有一定的差距)
雖然有的程序員水平不高,寫的代碼效率比較低,編譯器在編譯執行的時候,分析理解現有代碼的意圖和效果,然后自動對這個代碼進行調整和優化,在確保程序執行邏輯不變的前提下,提高程序的效率。
編譯器優化的效果是很明顯,但是大前提是“程序的邏輯不變”
大多數情況下,編譯器優化,都可以做到“邏輯不變的前提”
但是在有些特定場景下,編譯器優化可能出現“誤判”,導致邏輯發生改變。
“多線程代碼”
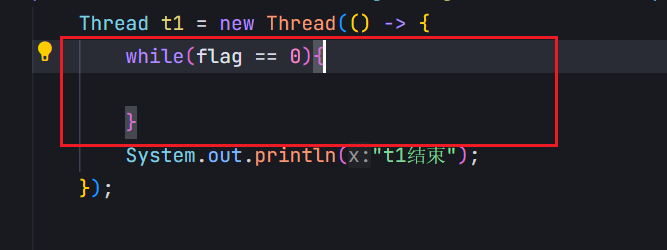
對于這個程序來說,編譯器看到的效果是:有一個變量flag,會快速地,反復地讀取整個內存的值(反復執行load\cmp\load\cmp);同時,反復執行的過程中,每次拿到的flag的值還都是一樣的,上述的load操作相比cmp,耗時會多很多,讀取內存,比讀取寄存器,效率會慢很多(幾百倍,幾千倍)
既然load讀取的值都是一樣的,而且load開銷這么多,于是編譯器直接把從內存讀取flag這個操作給優化掉了。上述操作只是前幾次讀內存,后面發現一樣,就干脆從讀好的寄存器中直接獲取這個flag的值,此時,循環的俠侶就大幅度地提升了。
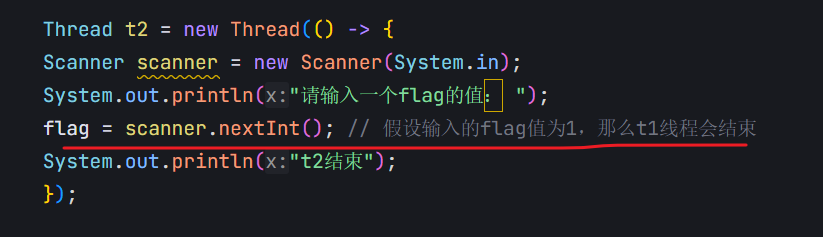
編譯器不確定這里的flag修改代碼到底能不能執行,以及啥時候執行。
上述內存可見性問題,是編譯器優化機制,自身出現的bug。
六、volatile關鍵字
通過這個關鍵字,提醒編譯器,某個變量是“易變”的,此時就不要針對這個易變的變量進行上述優化。
給變量添加了volatile關鍵字,編譯器在看到volatile的時候,就會提醒JVM運行的時候不進行上述的優化。
在讀寫volatile變量的指令前后添加“內存屏障相關的指令”
JMM Java Memory Model
Java的內存模型
首先一個Java進程,會有一個“主內存”存儲空間,每個Java線程又會有自己的“工作內存”存儲空間
形如上述的代碼,t1進行flag變量的判定時,就會把flag的值從主內存,先讀取到工作內存,再用工作內存中的值進行判定。同時,t2對flag進行修改,修改的則是主內存的值,主內存的值的修改不會影響到t1的工作內存。
上述解釋,出自于Java的官方文檔
main memory(主內存)就是內存?
work memory (工作內存)相當于是打了個比方,本質上這一塊區域并不是內存,而是CPU的寄存器和CPU的緩存構成的統稱
Java自身是希望做成“跨平臺”,Java用戶不需要了解系統底層和硬件差異。Java的設計者是不希望用戶了解這些底層細節的。另一方面,不同的CPU底層結構也不一定相同。
拋開Java上下文不談,只關注操作系統和硬件,沒有上面“主內存”“工作內存”的說法的。
存儲數據,不只是有內存,還有外存(硬盤),還有cpu寄存器,cpu上還有緩存。
現代CPU都引入了緩存,CPU的緩存空間比寄存器要大,速度要比寄存器要慢,但是比起內存還是要快。
CPU的寄存器和緩存,就統稱為work memory?
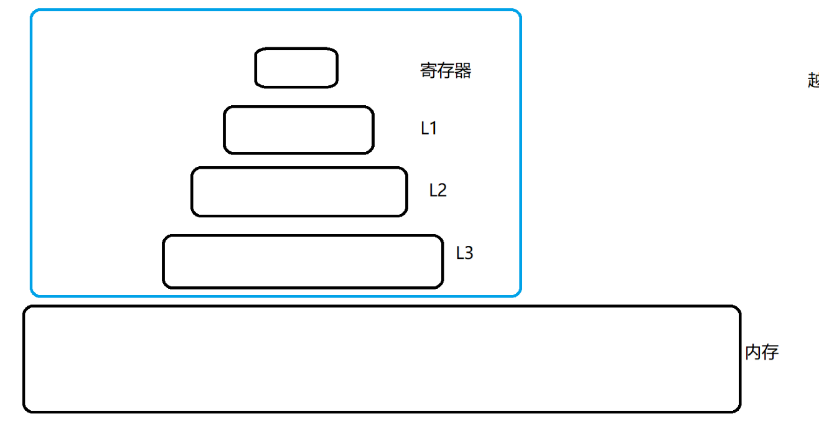
越往上,速度就越快,空間就越小,成本就越高。
編譯器優化,就是把本來要從內存中讀取的值,優化成從寄存器中讀取。
可能是優化成從寄存器上讀取,也可能是優化成從L1緩存上讀取,也可能是優化成從L2緩存上讀取,也可能是優化成從L3緩存上讀取……(都沒有從內存上重新讀取,因此讀不到最新的修改之后的數值)
編譯器優化,并非是100%觸發,根據不同的代碼結構,可能產生出不同的優化效果(有優化/無優化/優化方式)
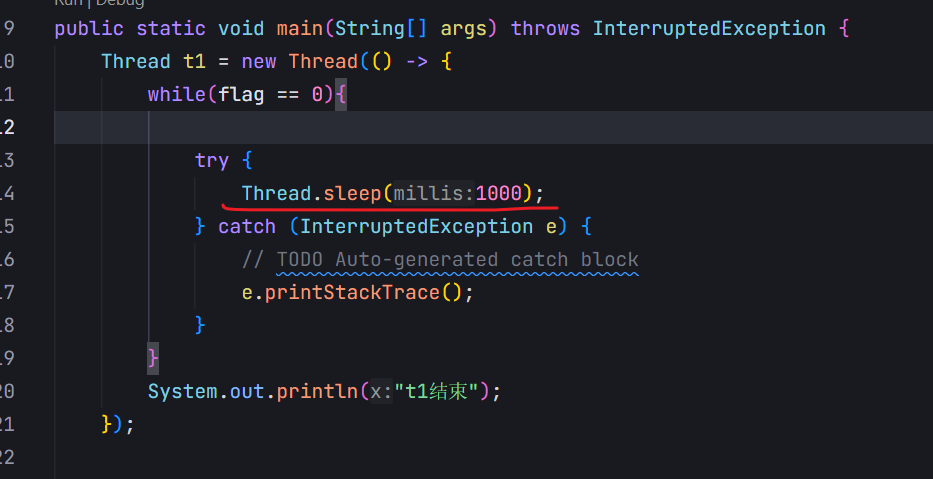
此處雖然沒有寫volatile,但是加了sleep也會使得上述程序不在優化。
因為:
1.循環速度大幅度降低了
2.有了sleep一次循環的瓶頸,就不是load,此時再優化load,就沒有什么用了。
3.sleep本身會觸發線程調度,調度過程觸發上下文切換。
volatile這個關鍵字,能夠解決內存可見性引起的線程安全問題,但是不具備原子性這樣的特點。
synchronized和volatile是兩個不同的維度,前者是兩個線程都修改,volatile是一個線程讀,另一個線程修改。
六、wait/notify
這兩個關鍵字是用來協調線程之間的執行順序的
兩個線程在運行的時候,都是希望持續運行下去的(不涉及結束)。但是兩個線程中的某些環節,我們希望能夠有一定的先后順序。
*線程執行本身是隨即調度的(順序不確定),join控制線程的結束順序
例如線程1 ,線程2
希望線程1 先執行完某個邏輯之后,再讓線程2去執行。
此時就可以讓線程2通過wait主動進行阻塞,讓線程1先參與調度,等線程1把對應的邏輯執行完了,就可以通過notify喚醒線程2.
另外,wait / notify 也能解決“線程餓死”的問題。
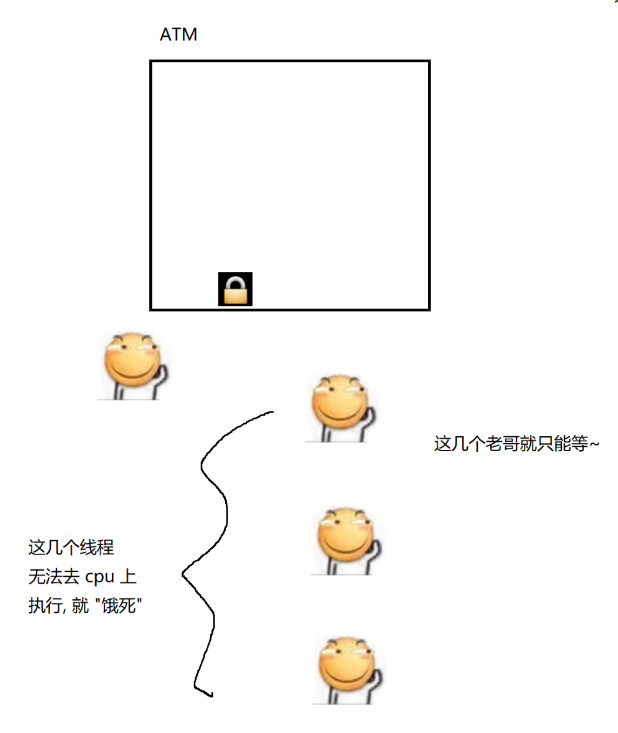
當線程1釋放鎖之后,其他線程就要競爭這個鎖(線程1 自身也可以重復參與到競爭中)
由于其他線程還要等待操作系統喚醒,此時線程1就是在cpu上執行,就有很大的可能性,“捷足先登”
不像死鎖,死鎖發生,就僵硬住,除非程序啟動,否則就會一直僵持。
線程餓死,沒那么嚴重,在線程1反復獲取幾次鎖之后,其他線程也是有機會拿到鎖的,但是其他線程拿到鎖的時間會延長,降低了程序的效率。






圖像與通道拼接函數-----執行 查找表操作圖像處理函數LUT())
注冊與映射機制:JsonListTypeHandler和JsonListTypeHandler注冊時機)








ENFJ人格)

