文章目錄
- 一、算法開發的一般步驟
- 1.選擇合適的深度學習框架
- 2.對于要處理的問題進行分類,是回歸問題還是分類問題。
- 3.對數據進行歸納和整理
- 4.對輸入的數據進行歸一化和量化,保證模型運行的效率和提高模型運行的準確度
- 5.在嵌入式處理器上面運行模型,對嵌入式處理器的整體性能提出了要求
- 6.將通用的算法模型轉換成適配嵌入式處理器的模型文件
- 7.對模型的運行效率進行優化
- 二、瑞芯微芯片部署初步嘗試
- 總結
一、算法開發的一般步驟
1.選擇合適的深度學習框架
(1)TensorFlow 是一個開源的機器學習框架,由 Google Brain 團隊開發并維護。它廣泛應用于深度學習、數據分析、自然語言處理、計算機視覺等領域,是目前最流行的機器學習框架之一。
TensorFlow 的名字來源于其核心數據結構——張量(Tensor)。張量是一個多維數組,可以表示從標量(0維)到向量(1維)、矩陣(2維)以及更高維度的數據結構。TensorFlow 通過構建一個**計算圖(Graph)來描述張量之間的數學運算,然后通過會話(Session)**執行這些運算。
張量(Tensor):數據的載體,是 TensorFlow 中最基本的數據結構。
計算圖(Graph):描述張量之間的運算關系,類似于程序的流程圖。
會話(Session):用于執行計算圖中的運算。
操作(Operation):計算圖中的節點,表示對張量的運算。
支持多種語言:TensorFlow 提供了 Python、C++、Java 等多種語言的 API,方便不同開發者使用。
平臺無關性:可以在 CPU、GPU、TPU(張量處理單元)等多種硬件上運行,支持桌面、服務器和移動設備。
工具和庫:支持與其他工具(如 Keras、TensorBoard 等)無縫集成,方便模型開發和可視化。
(2)PyTorch 是一個開源的機器學習庫,廣泛用于計算機視覺、自然語言處理等人工智能領域。它由 Facebook 的人工智能研究團隊開發,并于 2016 年首次發布。以下是關于 PyTorch 的詳細介紹:
動態計算圖:
PyTorch 使用動態計算圖(Dynamic Computational Graph),允許用戶在運行時動態修改計算圖的結構。這種靈活性使得調試和開發更加直觀,尤其是在處理復雜的模型或動態輸入時。
易用性:
PyTorch 提供了簡潔直觀的 API,類似于 NumPy 的操作方式,使得新手可以快速上手。同時,它也支持自動求導(Autograd)功能,簡化了梯度計算的過程。
強大的社區支持:
PyTorch 擁有一個活躍的開源社區,提供了大量的預訓練模型、教程和工具。這使得開發者可以快速找到解決方案,并利用社區的力量進行學習和開發。
與 Python 深度集成:
PyTorch 完全基于 Python,與 Python 生態系統無縫對接。它可以與 NumPy、SciPy 等科學計算庫以及各種深度學習框架(如 TensorFlow)協同工作。
高效性能:
PyTorch 提供了高效的 GPU 支持,能夠充分利用 NVIDIA 的 CUDA 技術加速計算。同時,它也支持分布式訓練,適用于大規模數據集和復雜模型的訓練。
靈活的擴展性:
PyTorch 允許用戶自定義操作和模塊,通過擴展 C++ 和 CUDA 代碼來實現高性能的自定義功能。
(3)國內有華為的昇思框架。
華為昇思(MindSpore)是華為推出的一個全場景深度學習框架,旨在實現易開發、高效執行和全場景覆蓋。
1.主要信息:
昇思MindSpore是一個面向全場景的AI計算框架,支持終端、邊緣計算和云端的全場景需求。它具備以下特點:
易開發:提供友好的API和低難度的調試體驗。
高效執行:支持高效的計算、數據預處理和分布式訓練。
全場景覆蓋:支持云、邊緣和端側的多種應用場景。
安全可信:具備企業級的安全特性,保護數據和模型的安全。
2.主要功能
分布式并行能力:支持一行代碼自動并行執行,能夠訓練千億參數的大模型。
圖算深度融合:優化AI芯片的算力,提升計算效率。
動靜圖統一:兼顧靈活開發與高效運行。
AI + 科學計算:支持生物分子、電磁、流體等領域的科研應用。
多種編程范式:支持面向對象、函數式等多種編程方式。
2.對于要處理的問題進行分類,是回歸問題還是分類問題。
回歸?:預測連續的數值型輸出,例如房價、溫度、股票價格等。其目標是建立自變量與因變量之間的數學關系(線性或非線性),實現對未知數據的數值估計。
?分類?:預測離散的類別標簽,例如垃圾郵件識別(二分類)或水果圖片分類(多分類)。其核心是通過決策邊界將數據劃分到預定義的類別中。
3.對數據進行歸納和整理
- 數據收集
明確數據來源:確定算法需要的數據類型和來源,例如傳感器數據、圖像、文本、數據庫等。
數據量評估:評估所需數據的規模,確保數據量足夠支持算法的訓練和驗證。
數據完整性檢查:初步檢查數據是否完整,是否存在缺失值或異常值。 - 數據清洗
去除重復數據:檢查并刪除重復的數據記錄,避免對模型訓練造成偏差。
處理缺失值:
刪除缺失值:如果缺失數據較少,可以直接刪除包含缺失值的記錄。
填充缺失值:使用均值、中位數、眾數或插值方法填充缺失值。
修正錯誤數據:檢查數據中的異常值或錯誤數據,并進行修正或刪除。
4.對輸入的數據進行歸一化和量化,保證模型運行的效率和提高模型運行的準確度
標準化:將數據轉換為均值為0、標準差為1的分布。
歸一化:將數據縮放到指定范圍(如 [0, 1] 或 [-1, 1])。
5.在嵌入式處理器上面運行模型,對嵌入式處理器的整體性能提出了要求
目前一般可以運行算法的芯片都是核心數比較多,或者加入了自家的算法處理單元,比如NPU或者GPU。
6.將通用的算法模型轉換成適配嵌入式處理器的模型文件
比如瑞芯微芯片提供了rknn-Toolkit2。
RKNN-Toolkit2 工具在 PC 平臺上提供 C 或 Python 接口,簡化模型的部署和運行。用戶可以通過該工具輕松完成以下功能:模型轉換、量化、推理、性能和內存評估、量化精度分析以及模型加密。RKNN 軟件棧可以幫助用戶快速的將 AI 模型部署到 Rockchip 芯片。整體的框架如下:
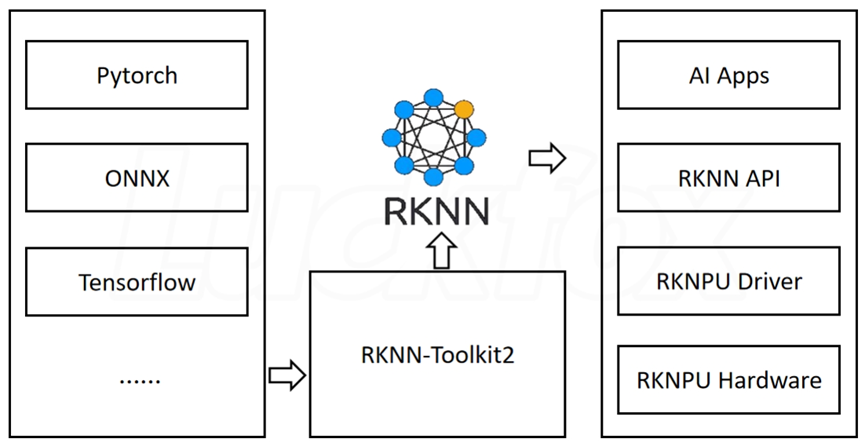
為了使用 RKNPU,用戶需要首先在計算機上運行 RKNN-Toolkit2 工具,將訓練好的模型轉換為 RKNN 格式模型,之后使用 RKNN C API 或 Python API 在開發板上進行部署。
7.對模型的運行效率進行優化
可以使用硬件優化,比如采用多核心多線程的方式,提高模型的并行處理能力。還有就是對于算子進行優化。對數據進行精度的降低,但是對于運行效率可以提高。
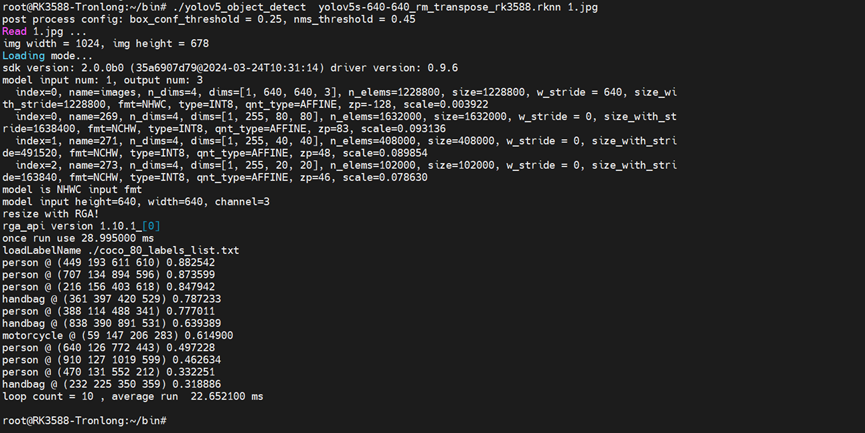
二、瑞芯微芯片部署初步嘗試


總結
以上就是對于嵌入式處理器中部署和運行算法程序的一般開發思路。目前算法學習涉及到的知識面比較多,有卷積、神經網絡,梯度,學習率,激活函數,損失函數,均值算法等。需要一個部分一個部分地去走通整個工程,這樣對于算法的學習有一個全面的了解。
的模糊車牌圖像清晰化復原算法設計與實現(含Github代碼+Web端在線體驗鏈接))
Gin學習筆記(四)Gin的數據渲染和中間件的使用:數據渲染、返回JSON、淺.JSON()源碼、中間件、Next()方法)



基礎教程七 深度模板視圖\剔除\謂詞)
穩定性優化:從實驗室到量產的關鍵技術)

—重要API》)







 A. Boboniu Chats with Du)

:創建內觀時裝備偏移問題)
