一、引言
支持向量機(Support Vector Machine, SVM)作為一種經典的機器學習算法,自20世紀90年代由Vapnik等人提出以來,在模式識別和分類任務中表現出卓越的性能。
在深度學習興起之前,SVM長期占據著圖像分類領域的主導地位,即使在當今深度神經網絡大行其道的時代,SVM仍因其理論完備性、小樣本學習能力和良好的泛化性能而在特定場景下保持著不可替代的價值。
本文將從SVM的基本原理出發,系統闡述其在圖像分類任務中的應用方法、關鍵技術、優化策略以及實際案例,全面展示這一傳統分類模型在計算機視覺領域的獨特優勢和實用價值。
全文將分為以下幾個部分:SVM基本原理回顧、圖像分類問題概述、SVM在圖像分類中的實現方法、性能優化策略、應用案例分析、與深度學習的對比及未來展望。
二、SVM基本原理回顧
2.1 統計學習理論與結構風險最小化
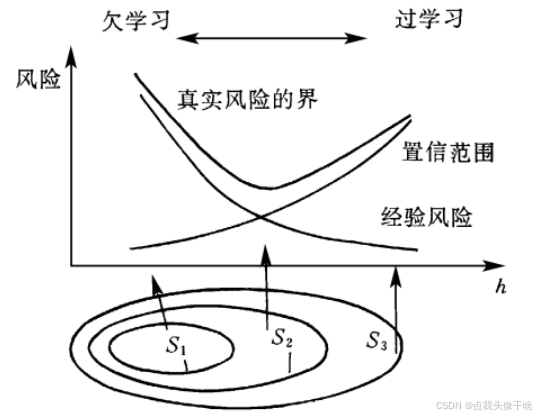
SVM建立在統計學習理論的基礎上,遵循結構風險最小化(Structural Risk Minimization, SRM)原則,與傳統的經驗風險最小化(Empirical Risk Minimization, ERM)方法形成對比。
SRM通過在經驗風險和置信區間之間尋求平衡,有效控制了模型的泛化誤差,這使得SVM在小樣本情況下仍能保持良好的分類性能。
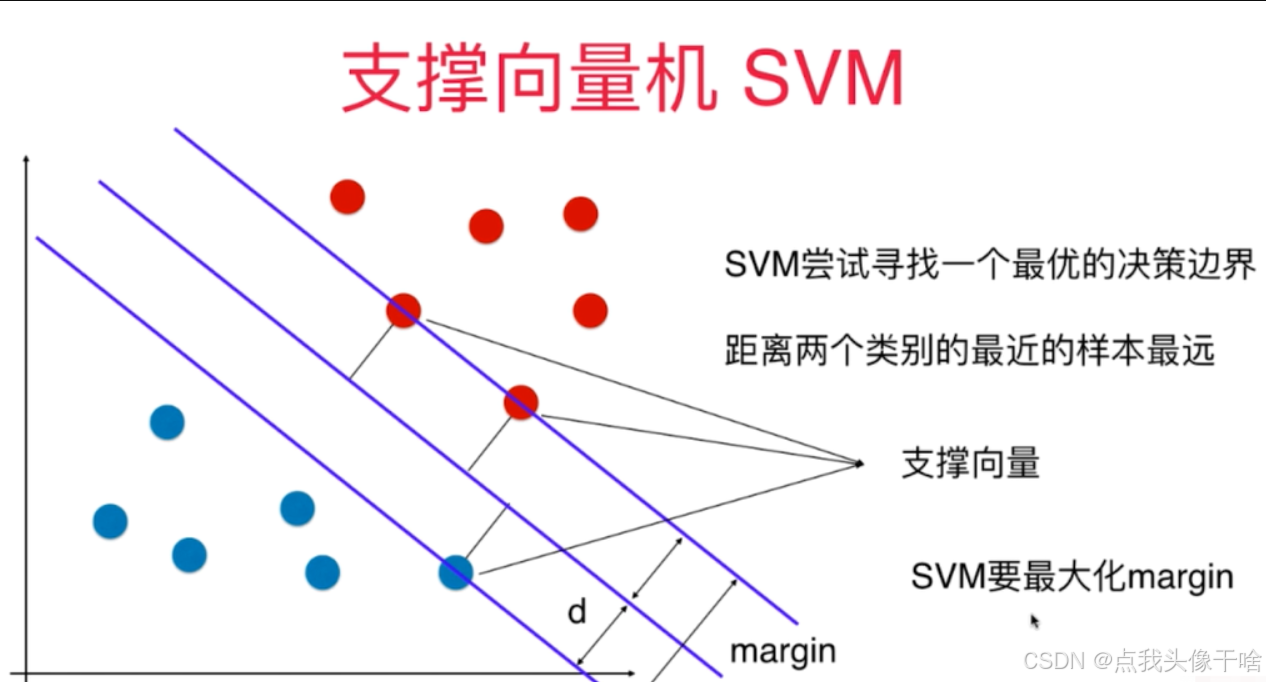
2.2 線性可分情況下的最大間隔分類器
對于線性可分的數據集,SVM的核心思想是尋找一個最優超平面,使得該超平面不僅能將不同類別的樣本正確分開,而且能使兩類樣本到超平面的最小距離(即間隔)最大化。這個最優超平面可以表示為:
w·x + b = 0
其中w是法向量,決定了超平面的方向;b是位移項,決定了超平面與原點的距離。最大化間隔等價于最小化||w||,從而轉化為一個凸二次規劃問題:
min 1/2 ||w||2
s.t. y_i(w·x_i + b) ≥ 1, ?i
2.3 非線性情況與核技巧
對于非線性可分問題,SVM通過核技巧(kernel trick)將原始特征空間映射到高維特征空間,在高維空間中實現線性可分。這一過程隱式地通過核函數完成,避免了顯式的高維計算。常用的核函數包括:
線性核:K(x_i, x_j) = x_i·x_j
多項式核:K(x_i, x_j) = (γx_i·x_j + r)^d
高斯徑向基核(RBF):K(x_i, x_j) = exp(-γ||x_i - x_j||2)
Sigmoid核:K(x_i, x_j) = tanh(γx_i·x_j + r)
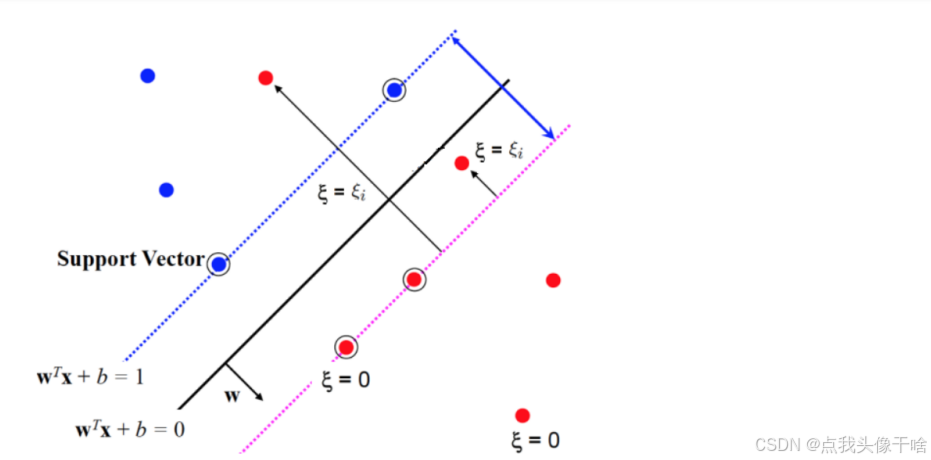
2.4 軟間隔與松弛變量
現實中的數據往往存在噪聲和異常點,嚴格的線性可分假設不成立。為此,SVM引入軟間隔(soft margin)概念,通過松弛變量ξ允許部分樣本違反間隔約束,同時懲罰這些違反行為。優化問題變為:
min 1/2 ||w||2 + C∑ξ_i
s.t. y_i(w·x_i + b) ≥ 1 - ξ_i, ξ_i ≥ 0, ?i
其中C是懲罰參數,控制對誤分類的容忍程度。
2.5 對偶問題與支持向量
通過拉格朗日乘子法將原問題轉化為對偶問題后,SVM的解可以表示為支持向量的線性組合:
f(x) = sign(∑α_i y_i K(x_i, x) + b)
支持向量是訓練集中對決策邊界起決定性作用的樣本,通常只占訓練樣本的一小部分,這使得SVM具有較好的稀疏性。
三、圖像分類問題概述
3.1 圖像分類的定義與挑戰
圖像分類是計算機視覺中的基礎任務,旨在為輸入圖像分配一個預定義的類別標簽。與一般的分類問題相比,圖像數據具有以下特點:
-
高維性:即使是一張小尺寸圖像,其原始像素空間維度也很高(如256×256 RGB圖像有196,608維)
-
局部相關性:相鄰像素之間存在強相關性,包含豐富的空間結構信息
-
光照、姿態、遮擋等變化:同一物體在不同條件下可能呈現顯著不同的視覺表現
-
類內差異與類間相似性:同一類別可能包含外觀差異很大的實例,而不同類別可能有相似的外觀
3.2 傳統圖像分類流程
在深度學習出現之前,傳統的圖像分類通常遵循"特征提取+分類器"的兩階段流程:
-
特征提取:從原始像素中提取有判別性的特征表示
-
全局特征:顏色直方圖、紋理特征、形狀描述符等
-
局部特征:SIFT、HOG、SURF等
-
編碼特征:詞袋模型(BoW)、Fisher向量、VLAD等
-
-
分類模型:基于提取的特征訓練分類器
-
常用分類器包括SVM、隨機森林、AdaBoost等
-
SVM因其良好的泛化能力成為最受歡迎的選擇
-
3.3 評價指標
圖像分類任務的常用評價指標包括:
-
準確率(Accuracy):正確分類樣本占總樣本的比例
-
混淆矩陣(Confusion Matrix):詳細展示各類別間的分類情況
-
精確率(Precision)、召回率(Recall)、F1分數:針對類別不平衡問題的評價指標
-
ROC曲線與AUC值:評估分類器在不同閾值下的性能表現
四、SVM在圖像分類中的實現方法
4.1 特征提取與表示
4.1.1 全局特征
-
顏色特征:
-
顏色直方圖:統計各顏色通道的分布情況
-
顏色矩:通過均值、方差、偏度等描述顏色分布
-
顏色相關圖:考慮顏色空間分布關系
-
-
紋理特征:
-
Gabor濾波器:模擬人類視覺系統對紋理的感知
-
LBP(Local Binary Patterns):描述局部紋理模式
-
Tamura紋理特征:包括粗糙度、對比度、方向性等
-
-
形狀特征:
-
Hu矩:具有平移、旋轉和尺度不變性的形狀描述符
-
Zernike矩:在單位圓上定義的正交矩
-
邊緣方向直方圖:統計圖像邊緣的方向分布
-
4.1.2 局部特征
-
關鍵點檢測與描述:
-
SIFT(Scale-Invariant Feature Transform):具有尺度不變性的局部特征
-
SURF(Speeded Up Robust Features):SIFT的加速版本
-
ORB(Oriented FAST and Rotated BRIEF):結合FAST關鍵點與BRIEF描述符
-
-
特征編碼:
-
詞袋模型(Bag of Words):將局部特征量化到視覺詞典
-
Fisher向量:通過高斯混合模型對特征分布進行編碼
-
VLAD(Vector of Locally Aggregated Descriptors):對特征與聚類中心的殘差進行聚合
-
4.1.3 特征選擇與降維
高維特征可能導致"維度災難"和計算效率問題,常用的降維方法包括:
-
主成分分析(PCA):通過線性變換將數據投影到低維空間
-
線性判別分析(LDA):尋找能最大化類間差異、最小化類內差異的投影方向
-
t-SNE:非線性降維方法,適合可視化高維數據
4.2 多類SVM策略
標準SVM是二分類器,而圖像分類通常涉及多個類別。常見的多類擴展策略包括:
-
一對多(One-vs-Rest, OvR):
-
為每個類別訓練一個二分類SVM,將該類與其他所有類區分
-
預測時選擇決策函數值最大的類別
-
簡單直接,但當類別很多時可能面臨類別不平衡問題
-
-
一對一(One-vs-One, OvO):
-
為每兩個類別訓練一個二分類SVM
-
對于K個類別,需要訓練K(K-1)/2個分類器
-
預測時采用投票機制,選擇得票最多的類別
-
每個子問題更簡單,但分類器數量隨類別數平方增長
-
-
有向無環圖(DAGSVM):
-
將OvO分類器組織成有向無環圖
-
通過逐層淘汰減少分類器調用次數
-
保持OvO精度的同時提高預測效率
-
-
多類目標函數:
-
直接修改SVM目標函數,使其能同時優化所有類別的分類邊界
-
如Crammer和Singer提出的多類SVM公式
-
理論更優雅,但實現復雜度較高
-
4.3 核函數選擇與參數優化
4.3.1 核函數選擇
在圖像分類中,核函數的選擇至關重要:
-
線性核:
-
適用于特征維度高、樣本量大的情況
-
計算效率高,但無法處理非線性可分問題
-
常用于稀疏特征或已經過非線性變換的特征
-
-
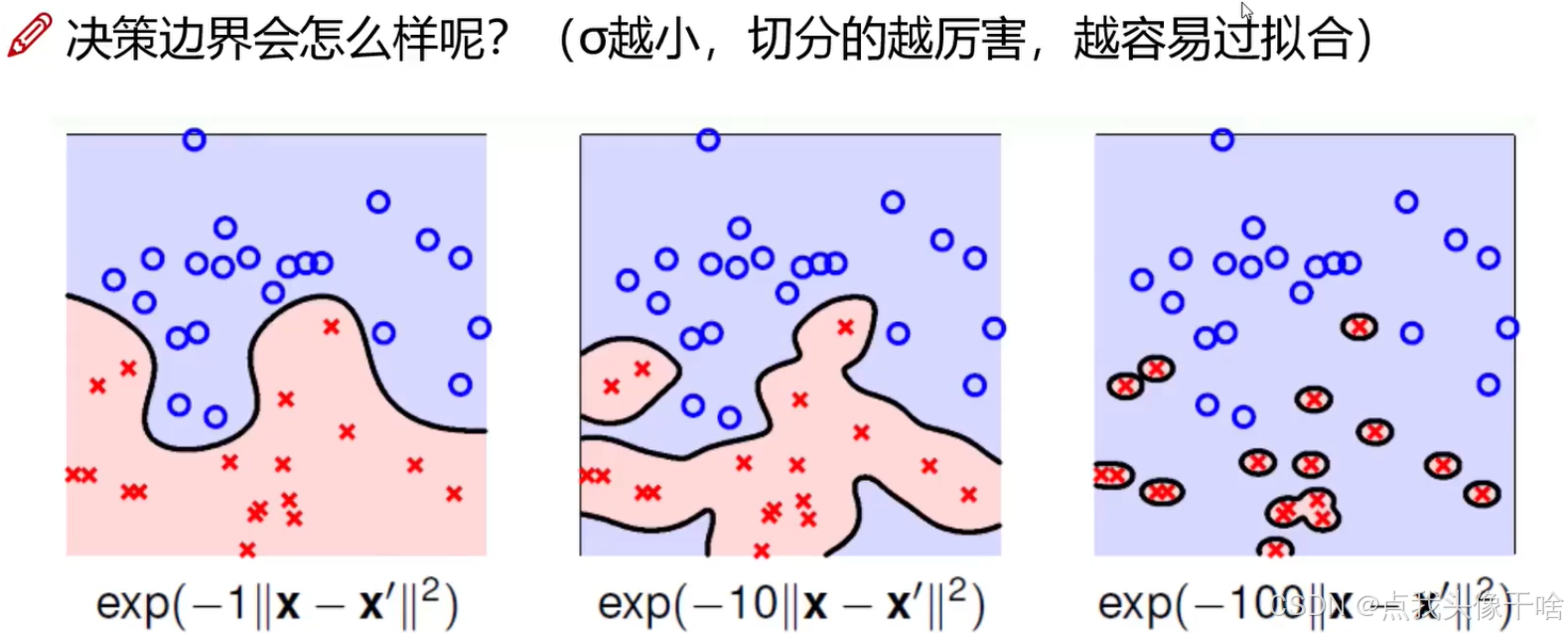
RBF核:
-
最常用的核函數,具有較強的非線性表達能力
-
需要謹慎選擇帶寬參數γ
-
適用于大多數圖像分類任務
-
-
多項式核:
-
適合具有明顯階數特征的問題
-
參數d的選擇影響模型復雜度
-
在特定圖像分類任務中可能有不錯表現
-
-
自定義核:
-
針對特定問題設計專用核函數
-
如圖像專用核:金字塔匹配核、空間金字塔匹配核等
-
需要領域知識和大量實驗驗證
-
4.3.2 參數優化
SVM的關鍵參數需要精心調優:
-
懲罰參數C:
-
控制模型對誤分類的容忍度
-
C值大:分類邊界窄,可能過擬合
-
C值小:分類邊界寬,可能欠擬合
-
-
RBF核參數γ:
-
控制單個樣本的影響范圍
-
γ值大:決策邊界復雜,可能過擬合
-
γ值小:決策邊界平滑,可能欠擬合
-
-
優化方法:
-
網格搜索:在指定參數范圍內系統搜索
-
隨機搜索:在參數空間隨機采樣
-
啟發式方法:如遺傳算法、貝葉斯優化等
-
4.4 實現流程示例
一個完整的基于SVM的圖像分類系統實現流程如下:
-
數據準備:
-
收集并標注圖像數據集
-
劃分訓練集、驗證集和測試集
-
數據增強(如翻轉、旋轉、裁剪等)
-
-
特征提取:
-
根據任務特點選擇合適的特征提取方法
-
對每幅圖像提取特征表示
-
可選進行特征標準化或歸一化
-
-
模型訓練:
-
選擇SVM類型(線性/非線性)和核函數
-
使用交叉驗證在驗證集上優化參數
-
用最優參數在完整訓練集上訓練最終模型
-
-
評估與部署:
-
在測試集上評估模型性能
-
分析混淆矩陣找出分類薄弱環節
-
將訓練好的模型部署到實際應用
-
五、性能優化策略
5.1 特征工程優化
-
多層次特征融合:
-
結合全局特征與局部特征的優勢
-
如同時使用顏色直方圖和SIFT特征
-
通過特征拼接或后期融合實現
-
-
空間金字塔匹配:
-
將圖像劃分為多層次的網格
-
在每個層次上提取并匯集局部特征
-
保留一定的空間布局信息
-
-
深度特征與傳統特征結合:
-
使用預訓練CNN的中間層輸出作為特征
-
與傳統手工設計特征相結合
-
發揮深度特征的高層語義表達能力
-
5.2 算法層面優化
-
增量學習與在線學習:
-
對于大規模數據集,采用增量式SVM
-
支持新增樣本的增量訓練
-
減少重新訓練的計算成本
-
-
概率輸出校準:
-
標準SVM輸出非概率性決策值
-
通過sigmoid函數或Platt縮放轉換為概率
-
便于后續的多模型融合或決策
-
-
集成學習方法:
-
將多個SVM模型集成提升性能
-
Bagging:通過自助采樣構建多樣性基分類器
-
Boosting:迭代調整樣本權重聚焦難樣本
-
5.3 計算效率優化
-
近似算法與稀疏化:
-
使用近似SVM算法處理大規模數據
-
如Core Vector Machine(CVM)
-
通過稀疏化減少支持向量數量
-
-
并行計算:
-
利用SVM訓練中的并行性
-
多核CPU或GPU加速計算
-
特別適用于核矩陣計算
-
-
專用優化庫:
-
LIBSVM:經典的SVM實現庫
-
LIBLINEAR:針對線性SVM的高效實現
-
ThunderSVM:支持GPU加速的SVM庫
-
六、應用案例分析
6.1 手寫數字識別(MNIST)
MNIST數據集包含0-9手寫數字的28×28灰度圖像,是經典的圖像分類基準。

-
特征提取:
-
原始像素(784維)
-
HOG特征(提取邊緣方向信息)
-
投影特征(水平和垂直方向的投影直方圖)
-
-
SVM實現:
-
采用RBF核SVM
-
參數通過網格搜索優化(C=10, γ=0.01)
-
使用OvO策略處理多類問題
-
-
性能表現:
-
原始像素特征:準確率約98.5%
-
結合HOG特征:準確率可達99%以上
-
與簡單神經網絡性能相當
-
6.2 場景分類(Scene-15)
Scene-15包含15類室內外場景圖像,每類200-400張。

-
特征提取:
-
密集采樣的SIFT特征
-
通過K-means構建視覺詞典(1000詞)
-
空間金字塔匹配(1×1, 2×2, 4×4網格)
-
-
SVM實現:
-
采用χ2核SVM(適合直方圖類特征)
-
多類采用OvR策略
-
參數優化后C=100, γ=0.1
-
-
性能表現:
-
平均準確率約85%
-
優于當時的多數傳統方法
-
計算效率高于早期CNN方法
-
6.3 物體識別(Caltech-101)
Caltech-101包含101類物體圖像,每類約40-800張。

-
特征提取:
-
基于SIFT的Fisher向量編碼
-
局部顏色特征補充
-
PCA降維至128維
-
-
SVM實現:
-
RBF核SVM
-
采用DAGSVM多類策略
-
參數C=1, γ=0.005
-
-
性能表現:
-
平均準確率約75%(30訓練樣本/類)
-
對小樣本情況魯棒性強
-
特征工程對性能影響顯著
-
6.4 醫學圖像分類(皮膚病變)
ISIC皮膚病變數據集包含多種皮膚鏡圖像。
-
特征提取:
-
不對稱性、邊界、顏色和紋理特征(ABCD規則)
-
深度特征(預訓練ResNet的池化層輸出)
-
臨床元數據(患者年齡、病變位置等)
-
-
SVM實現:
-
采用線性SVM(因特征已高度工程化)
-
概率輸出用于臨床決策支持
-
類別加權處理不平衡數據
-
-
性能表現:
-
AUC達0.92,優于多數傳統方法
-
模型可解釋性強,受醫生歡迎
-
計算效率高,適合臨床部署
-
七、與深度學習的對比及未來展望
7.1 SVM與深度學習的比較
| 特性 | SVM | 深度神經網絡 |
|---|---|---|
| 理論基礎 | 統計學習理論,凸優化 | 生物啟發,非凸優化 |
| 特征處理 | 需要手工特征工程 | 自動特征學習 |
| 數據需求 | 小樣本表現良好 | 需要大量數據 |
| 計算復雜度 | 相對較低 | 通常較高 |
| 模型解釋性 | 相對較好 | 通常較差 |
| 硬件需求 | CPU即可 | 通常需要GPU |
| 超參數敏感性 | 核參數和C關鍵 | 大量超參數需要調整 |
| 訓練時間 | 相對較短 | 可能很長 |
| 部署難度 | 簡單輕量 | 可能較復雜 |
7.2 SVM在深度學習時代的價值
盡管深度學習在許多圖像分類任務上取得了突破性進展,SVM仍具有獨特價值:
-
小數據場景:當標注數據有限時,SVM通常優于深度學習
-
可解釋性要求:醫療、金融等領域需要可解釋的決策過程
-
資源受限環境:嵌入式設備或實時系統需要輕量級模型
-
特征明確問題:當領域知識能指導設計有效特征時
-
模型融合:作為深度學習模型的補充或后處理組件
7.3 未來發展方向
-
與深度學習的融合:
-
使用深度特征+SVM的混合架構
-
將SVM作為神經網絡的最后一層
-
借鑒SVM的間隔理論改進深度學習
-
-
新型核函數設計:
-
針對圖像數據的專用核函數
-
深度核學習:結合深度網絡與核方法
-
自適應核選擇機制
-
-
大規模分布式SVM:
-
面向超大規模圖像數據的SVM算法
-
分布式內存計算框架下的實現
-
在線學習與增量學習優化
-
-
領域專用優化:
-
針對醫學、遙感等特定領域的SVM改進
-
結合領域知識的特征與核設計
-
多模態數據融合策略
-
八、結論
支持向量機作為傳統機器學習中的經典分類模型,在圖像分類任務中展現了強大的性能和良好的適應性。通過精心設計的特征工程、合適的核函數選擇和參數優化,SVM能夠在多種圖像分類任務上取得媲美甚至超越早期深度學習方法的性能。盡管當前深度學習在多數視覺任務中占據主導地位,但SVM仍因其理論完備性、小樣本學習能力和良好的可解釋性,在特定應用場景中保持著不可替代的價值。
未來的研究應當關注SVM與深度學習的融合創新,充分發揮兩類方法的互補優勢。同時,針對新興應用領域的專用SVM改進,以及面向大規模數據的高效SVM算法,也將是值得探索的方向。無論如何,SVM作為機器學習發展歷程中的重要里程碑,其核心思想和算法精髓仍將持續影響計算機視覺和模式識別領域的發展。
相關代碼
以下是一些使用支持向量機(SVM)進行圖像分類的Python代碼示例,涵蓋了不同場景和應用:
庫文件:pip install scikit-learn opencv-python scikit-image tensorflow
1. 基礎SVM圖像分類(使用sklearn)
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, accuracy_score
import numpy as np# 加載數據集(這里以sklearn自帶的digits數據集為例)
digits = datasets.load_digits()
X = digits.images.reshape((len(digits.images), -1)) # 將圖像展平
y = digits.target# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 創建SVM分類器
clf = svm.SVC(kernel='rbf', gamma=0.001, C=100)# 訓練模型
clf.fit(X_train, y_train)# 預測
y_pred = clf.predict(X_test)# 評估
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))2. 使用HOG特征+SVM進行圖像分類
from skimage.feature import hog
from skimage import exposure
import cv2
import numpy as np# 提取HOG特征
def extract_hog_features(images):features = []for image in images:# 如果是彩色圖像,先轉換為灰度if len(image.shape) > 2:image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)# 計算HOG特征fd, hog_image = hog(image, orientations=8, pixels_per_cell=(16, 16),cells_per_block=(1, 1), visualize=True)features.append(fd)return np.array(features)# 假設我們已經加載了圖像數據到X_train, X_test, y_train, y_test# 提取HOG特征
X_train_hog = extract_hog_features(X_train)
X_test_hog = extract_hog_features(X_test)# 創建并訓練SVM
hog_svm = svm.SVC(kernel='linear', C=1.0)
hog_svm.fit(X_train_hog, y_train)# 評估
hog_pred = hog_svm.predict(X_test_hog)
print("HOG+SVM Accuracy:", accuracy_score(y_test, hog_pred))3. 使用SIFT特征+BOW+SVM(適用于更復雜的圖像分類)
import cv2
import numpy as np
from sklearn.cluster import KMeans
from sklearn.svm import SVC# SIFT特征提取
def extract_sift_features(images):sift = cv2.SIFT_create()descriptors_list = []for img in images:gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)_, descriptors = sift.detectAndCompute(gray, None)if descriptors is not None:descriptors_list.append(descriptors)return descriptors_list# 創建視覺詞典
def create_visual_dictionary(descriptors_list, n_clusters=100):all_descriptors = np.vstack(descriptors_list)kmeans = KMeans(n_clusters=n_clusters, random_state=42)kmeans.fit(all_descriptors)return kmeans# 將圖像轉換為BoW特征
def images_to_bow(images, kmeans, sift):bow_features = np.zeros((len(images), kmeans.n_clusters))for i, img in enumerate(images):gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)_, descriptors = sift.detectAndCompute(gray, None)if descriptors is not None:words = kmeans.predict(descriptors)for w in words:bow_features[i][w] += 1return bow_features# 假設我們已經加載了圖像數據到train_images, test_images, y_train, y_test# 提取SIFT特征
train_descriptors = extract_sift_features(train_images)# 創建視覺詞典
kmeans = create_visual_dictionary(train_descriptors, n_clusters=100)# 轉換為BoW特征
sift = cv2.SIFT_create()
X_train_bow = images_to_bow(train_images, kmeans, sift)
X_test_bow = images_to_bow(test_images, kmeans, sift)# 訓練SVM
bow_svm = SVC(kernel='rbf', C=10, gamma=0.1)
bow_svm.fit(X_train_bow, y_train)# 評估
bow_pred = bow_svm.predict(X_test_bow)
print("BoW+SVM Accuracy:", accuracy_score(y_test, bow_pred))4. 使用預訓練CNN特征+SVM(結合深度學習方法)
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg16 import preprocess_input
import numpy as np# 加載預訓練VGG16模型(去掉最后的全連接層)
base_model = VGG16(weights='imagenet', include_top=False)
model = Model(inputs=base_model.input, outputs=base_model.get_layer('block5_pool').output)# 提取CNN特征
def extract_cnn_features(img_paths):features = []for img_path in img_paths:img = image.load_img(img_path, target_size=(224, 224))x = image.img_to_array(img)x = np.expand_dims(x, axis=0)x = preprocess_input(x)feature = model.predict(x)features.append(feature.flatten())return np.array(features)# 假設我們有一組圖像路徑和標簽
# train_images_paths, test_images_paths, y_train, y_test# 提取特征
X_train_cnn = extract_cnn_features(train_images_paths)
X_test_cnn = extract_cnn_features(test_images_paths)# 訓練SVM
cnn_svm = svm.SVC(kernel='linear', C=1.0)
cnn_svm.fit(X_train_cnn, y_train)# 評估
cnn_pred = cnn_svm.predict(X_test_cnn)
print("CNN+SVM Accuracy:", accuracy_score(y_test, cnn_pred))5. 多類別SVM分類(使用OvO策略)
from sklearn.multiclass import OneVsOneClassifier
from sklearn.svm import SVC# 創建OvO SVM分類器
ovo_clf = OneVsOneClassifier(SVC(kernel='rbf', gamma=0.01, C=100))# 訓練模型
ovo_clf.fit(X_train, y_train)# 預測
ovo_pred = ovo_clf.predict(X_test)# 評估
print("OvO SVM Accuracy:", accuracy_score(y_test, ovo_pred))
print("\nClassification Report:\n", classification_report(y_test, ovo_pred))6. SVM參數網格搜索(尋找最優參數)
from sklearn.model_selection import GridSearchCV# 定義參數網格
param_grid = {'C': [0.1, 1, 10, 100],'gamma': [1, 0.1, 0.01, 0.001],'kernel': ['rbf', 'linear', 'poly']
}# 創建GridSearchCV對象
grid = GridSearchCV(svm.SVC(), param_grid, refit=True, verbose=2, cv=5)
grid.fit(X_train, y_train)# 輸出最佳參數
print("Best parameters found:", grid.best_params_)# 使用最佳模型預測
grid_pred = grid.predict(X_test)
print("Optimized SVM Accuracy:", accuracy_score(y_test, grid_pred))這些代碼示例展示了SVM在不同場景下的圖像分類應用。實際使用時,需要根據具體數據集和任務需求進行調整:
-
對于簡單圖像分類,可以直接使用像素值作為特征
-
對于更復雜的任務,建議使用HOG、SIFT等特征提取方法
-
當數據量不大但特征維度高時,線性SVM通常表現良好
-
對于小樣本問題,RBF核SVM通常是不錯的選擇
-
結合深度學習特征可以進一步提升性能
》)














植物應對干旱的生理學反應 | The physiology of plant responses to drought)



