目錄
一、混淆矩陣
1. 混淆矩陣的結構(二分類為例)
2.從混淆矩陣衍生的核心指標
3.多分類任務的擴展
4. 混淆矩陣的實戰應用
二、分類任務核心指標
1. Accuracy(準確率)
2. Precision(精確率)
3. Recall(召回率)
二、生成任務核心指標
1. BLEU(Bilingual Evaluation Understudy)
2. ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
3. PPL(Perplexity,困惑度)
三、指標對比與選型指南
四:總結
一、混淆矩陣
混淆矩陣是評估分類模型性能的核心工具,是計算準確率(Accuracy)、精確率(Precision)和召回率(Recall)的基礎工具,三者直接由混淆矩陣中的四個核心元素(TP、FP、FN、TN)定義。以矩陣形式直觀展示模型的預測結果與真實標簽的對比情況,尤其適用于二分類問題(可擴展至多分類)。以下是其完整解析:
1. 混淆矩陣的結構(二分類為例)
| 真實為正類(Positive) | 真實為負類(Negative) | |
|---|---|---|
| 預測為正類(Positive) | True Positive (TP) | False Positive (FP) |
| 預測為負類(Negative) | False Negative (FN) | True Negative (TN) |
-
TP(真正例):模型正確預測為正類的樣本數(例:真實為垃圾郵件,模型判定為垃圾郵件)。
-
FP(假正例):模型錯誤預測為正類的樣本數(例:真實為正常郵件,模型誤判為垃圾郵件)。
-
FN(假負例):模型錯誤預測為負類的樣本數(例:真實為垃圾郵件,模型漏判為正常郵件)。
-
TN(真負例):模型正確預測為負類的樣本數(例:真實為正常郵件,模型判定為正常郵件)。
2.從混淆矩陣衍生的核心指標
所有分類評估指標(Accuracy/Precision/Recall/F1)均可通過混淆矩陣計算:
| 指標 | 公式 | 物理意義 |
|---|---|---|
| 準確率(Accuracy) |  | 模型預測正確的總體比例,但對類別不均衡數據敏感(如99%負類時,全預測負類準確率99%)。 |
| 精確率(Precision) |  | 模型預測為正類的樣本中,真實為正類的比例(減少誤報)。 |
| 召回率(Recall) |  | 真實為正類的樣本中,被模型正確預測的比例(減少漏報)。 |
| F1-Score | 精確率和召回率的調和平均數,平衡兩者矛盾。 |
3.多分類任務的擴展
對于多分類問題(如貓、狗、鳥分類),混淆矩陣擴展為 3×3 或更大的矩陣:
| 預測:貓 | 預測:狗 | 預測:鳥 | |
|---|---|---|---|
| 真實:貓 | TP?=50 | 5(貓→狗) | 3(貓→鳥) |
| 真實:狗 | 2(狗→貓) | TP?=45 | 4(狗→鳥) |
| 真實:鳥 | 1(鳥→貓) | 2(鳥→狗) | TP?=40 |
-
對角線(TP?, TP?, TP?):各類別正確預測數。
-
非對角線:類別間的混淆情況(如“貓→狗”表示真實為貓但預測為狗的樣本數)。
多分類指標計算方式:
-
宏平均(Macro):對每個類別的指標單獨計算后取平均(平等看待所有類別)。
-
微平均(Micro):合并所有類別的TP/FP/FN后計算整體指標(受大類別影響更大)。
4. 混淆矩陣的實戰應用
場景1:醫療診斷(二分類)
-
目標:癌癥篩查需最小化漏診(FN↓),允許一定誤診(FP↑)。
-
優化策略:提高召回率(Recall),通過降低分類閾值(如概率>0.2即判為患病)。
場景2:電商評論情感分析(三分類:正面/中性/負面)
-
問題:負面評論的識別對商家更重要。
-
優化策略:針對“負面”類別單獨優化召回率,同時監控宏平均F1-Score。
場景3:推薦系統(點擊預測)
-
需求:減少誤推薦(FP↓),避免用戶流失。
-
優化策略:提高精確率(Precision),僅對高置信度樣本(如概率>0.8)進行推薦。
二、分類任務核心指標
1. Accuracy(準確率)
-
定義:模型預測正確的樣本數量占總樣本量的比重。
-
公式:
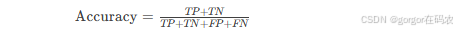
-
特點:
-
簡單直觀,但類別不均衡時失效
-
例:100個樣本中95個正類,全預測正類時準確率95%,但模型無意義
-
-
適用場景:類別分布均衡的二分類或多分類任務
-
意義:
所有預測中正確的比例,反映模型的整體表現。 -
局限性:
在類別不均衡時(如99%負類),即使全預測為負類,準確率也可高達99%,但模型無實際意義
2. Precision(精確率)
-
定義:在被識別為正類別的樣本中,為正類別的比例。
-
公式:

-
意義:衡量模型預測的精準度
-
例:癌癥篩查中,減少誤診(FP)更重要,需高精確率
-
-
別名:查準率
-
應用場景:
需減少誤報(FP)的任務,如垃圾郵件分類(避免將正常郵件誤判為垃圾)。
3. Recall(召回率)
-
定義:在所有正類別樣本中,被正確識別為正類別的比例。
-
公式:

-
意義:衡量模型對正類的覆蓋能力
-
例:金融風控中,漏掉欺詐交易(FN)損失大,需高召回率
-
-
別名:查全率
-
應用場景:
需減少漏報(FN)的任務,如癌癥篩查(寧可誤診,不可漏診)。
二、生成任務核心指標
1. BLEU(Bilingual Evaluation Understudy)
-
定義:BLEU 分數是評估一種語言翻譯成另一種語言的文本質量的指標. 它將“質量”的好壞定義為與人類翻譯結果的一致性程度. 取值范圍是[0, 1], 越接近1, 表明翻譯質量越好.
-
用途:機器翻譯、文本生成質量評估
-
原理:通過n-gram(連續n個詞)匹配計算生成文本與參考文本的相似度
-
公式:
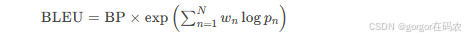
-
BP(Brevity Penalty):懲罰過短生成結果
-
pnpn?:n-gram精度(匹配次數/生成文本n-gram總數)
-
-
特點:
-
值域0~1,越高越好
-
對長文本連貫性評估不足
-
側重精確性(生成文本是否包含參考文本的關鍵詞)。
-
- BLEU舉例:
?
下面舉例說計算過程(基本步驟):
1. 分別計算candidate句和reference句的N-grams模型,然后統計其匹配的個數,計算匹配度.
2. 公式:candidate和reference中匹配的 n?gram 的個數 /candidate中n?gram 的個數.
? 假設機器翻譯的譯文candidate和一個參考翻譯reference如下:
candidate: It is a nice day todayreference: today is a nice day
candidate: {it, is, a, nice, day, today}reference: {today, is, a, nice, day}結果:其中{today, is, a, nice, day}匹配,所以 匹配度為5/6
candidate: {it is, is a, a nice, nice day, day today}reference: {today is, is a, a nice, nice day}結果:其中{is a, a nice, nice day}匹配,所以 匹配度為3/5
? 使用3-gram進行匹配:
candidate: {it is a, is a nice, a nice day, nice day today}reference: {today is a, is a nice, a nice day}結果:其中{is a nice, a nice day}匹配,所以 匹配度為2/4
candidate: {it is a nice, is a nice day, a nice day today}reference: {today is a nice, is a nice day}結果:其中{is a nice day}匹配,所以 匹配度為1/3
通過上面的例子分析可以發現,匹配的個數越多,BLEU值越大,則說明候選句子更好. 但是也會出現下面的極端情況:
candidate: the the the thereference: The cat is standing on the ground如果按照1-gram的方法進行匹配,則匹配度為1,顯然是不合理的
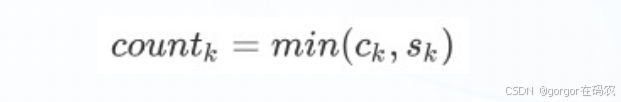
candidate: the the the thereference: The cat is standing on the ground如果按照1-gram的方法進行匹配,ck=4 sk=2 ,countk=min(4,2)=2則匹配度為2/4=1/2.
# 安裝nltk的包-->pip install nltk
from nltk.translate.bleu_score import sentence_bleu
def cumulative_bleu(reference, candidate):bleu_1_gram = sentence_bleu(reference, candidate, weights=(1, 0, 0, 0))bleu_2_gram = sentence_bleu(reference, candidate, weights=(0.5, 0.5, 0, 0))bleu_3_gram = sentence_bleu(reference, candidate, weights=(0.33, 0.33, 0.33, 0))bleu_4_gram = sentence_bleu(reference, candidate, weights=(0.25, 0.25, 0.25, 0.25))return bleu_1_gram, bleu_2_gram, bleu_3_gram, bleu_4_gram# 生成文本
condidate_text = ["This", "is", "some", "generated", "text"]
# 參考文本列表
reference_texts = [["This", "is", "a", "reference", "text"],
["This", "is", "another", "reference", "text"]]
# 計算 Bleu 指標
c_bleu = cumulative_bleu(reference_texts, condidate_text)
# 打印結果
print("The Bleu score is:", c_bleu)
# The Bleu score is: (0.6, 0.387, 1.5945e-102, 9.283e-155)2. ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
-
定義:ROUGE 指標是在機器翻譯、自動摘要、問答生成等領域常見的評估指標. ROUGE 通過將模型生 成的摘要或者回答與參考答案(一般是人工生成的)進行比較計算,得到對應的得分。
-
用途:文本摘要、對話生成評估
-
常見變體:
-
ROUGE-N:基于n-gram的召回率

-
ROUGE-L:基于最長公共子序列(LCS)
-
評估生成文本與參考文本的語義覆蓋度
-
-
-
特點:
-
ROUGE-N側重詞匯重疊,ROUGE-L關注語義連貫
-
值域0~1,越高越好
-
側重內容覆蓋度(生成文本是否包含參考文本的核心信息)。
-
側重召回率
-
-
ROUGE舉例:
下面舉例說計算過程(這里只介紹ROUGE_N):
基本步驟:Rouge-N實際上是將模型生成的結果和標準結果按N-gram拆分后,計算召回率.
? 假設模型生成的文本candidate和一個參考文本reference如下:
candidate: It is a nice day todayreference: today is a nice day
candidate: {it, is, a, nice, day, today}
reference: {today, is, a, nice, day}
結果:其中{today, is, a, nice, day}匹配,所以匹配度為5/5=1,這說明生成的內容完全覆蓋了參考文本中的所有單詞,質量較高.代碼
# 安裝rouge-->pip install rouge
from rouge import Rouge# 生成文本
generated_text = "This is some generated text."
# 參考文本列表
reference_texts = ["This is a reference text.", "This is another generated reference text."]
# 計算 ROUGE 指標
rouge = Rouge()
scores = rouge.get_scores(generated_text, reference_texts[1])# 打印結果
print("ROUGE-1 precision:", scores[0]["rouge-1"]["p"])
print("ROUGE-1 recall:", scores[0]["rouge-1"]["r"])
print("ROUGE-1 F1 score:", scores[0]["rouge-1"]["f"])
# ROUGE-1 precision: 0.8
# ROUGE-1 recall: 0.6666666666666666
# ROUGE-1 F1 score: 0.72727272231404963. PPL(Perplexity,困惑度)
-
定義:PPL用來度量一個概率分布或概率模型預測樣本的好壞程度. PPL越小,標明模型越好.
-
用途:語言模型(如GPT、BERT)的預訓練評估
-
定義:模型對測試數據集的“困惑程度”,反映預測能力
-
公式:
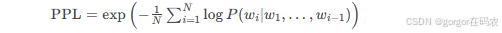
-
NN為測試集總詞數,PP為模型預測概率
-
-
特點:
-
PPL越低,模型對語言分布擬合越好
-
與生成質量間接相關(低PPL的模型生成文本更流暢,但未必內容正確)。
-
例:GPT-3的PPL約20,遠優于傳統RNN模型(PPL>100)
-
代碼
import math#定義語料庫
sentences = [
['I', 'have', 'a', 'pen'],
['He', 'has', 'a', 'book'],
['She', 'has', 'a', 'cat']
]
#定義語言模型
unigram = {'I':1/12, 'have':1/12, 'a': 3/12, 'pen':1/12, 'He':1/12,'has':2/12,'book':1/12,'She':1/12, 'cat':1/12}# 計算困惑度
perplexity = 0
for sentence in sentences:sentence_prob = 1for word in sentence:sentence_prob *= unigram[word]temp = -math.log(sentence_prob, 2)/len(sentence)perplexity+=2**temp
perplexity = perplexity/len(sentences)
print('困惑度為:', perplexity)
# 困惑度為: 8.15三、指標對比與選型指南
| 任務類型 | 推薦指標 | 核心關注點 |
|---|---|---|
| 文本分類 | Accuracy, F1, AUC-ROC | 類別均衡性、精確率與召回率平衡 |
| 機器翻譯 | BLEU, METEOR | n-gram匹配、語義相似度 |
| 文本摘要 | ROUGE-L, ROUGE-1/2 | 內容覆蓋度、關鍵信息保留 |
| 語言模型預訓練 | PPL | 語言建模能力(預測下一個詞的能力) |
| 情感分類 | Accuracy(均衡數據),F1(不均衡數據) |
?四:總結
????????Accuracy、Precision、Recall主要用于分類任務(如翻譯、摘要),評估模型預測的準確性、精確性和覆蓋性。而BLEU、ROUGE用于生成任務(如情感分析、意圖識別),如機器翻譯和文本摘要,評估生成文本的質量。PPL(困惑度)則用于評估語言模型本身的預測能力,不直接涉及具體任務的結果。以下是它們的關聯與區別詳解:
核心定位與任務類型
| 指標類型 | 適用任務 | 核心目標 |
|---|---|---|
| BLEU/ROUGE/PPL | 生成任務(文本生成、翻譯、摘要) | 評估生成文本的質量(內容匹配、流暢性) |
| Accuracy/Precision/Recall | 分類任務(二分類、多分類) | 評估分類結果的準確性、覆蓋度與精準度 |













)





