【“星睿O6”AI PC開發套件評測】GPU矩陣指令算力,GPU帶寬和NPU算力測試
安謀科技、此芯科技與瑞莎計算機聯合打造了面向AI PC、邊緣、機器人等不同場景的“星睿O6”開發套件
該套件異構集成了Arm?v9 CPU核心、Arm Immortalis? GPU以及安謀科技“周易”NPU
開箱和系統配置


根據這里的文檔,刷上debian系統即可
https://docs.radxa.com/orion/o6/getting-started/quick-start
npu工具根據這個文檔安裝,注意一定要用 python 3.8 版本才能成功,如果系統有多個python版本,可以 python3.8 -m pip install CixBuilder-6.1.2958.1-py3-none-any.whl
https://docs.radxa.com/orion/o6/app-development/artificial-intelligence/npu-introduction
小提示
- 風扇聲音太大,控制風扇轉速
root權限執行,范圍 0~255
echo 30 > /sys/class/hwmon/hwmon1/pwm1
- 修復 su 權限錯誤
root權限執行
chmod 4755 /bin/su
GPU算力測試
- GPU定頻最高
root權限執行
echo "performance" > /sys/class/misc/mali0/device/devfreq/15000000.gpu/governor
安裝vulkaninfo工具,可以看到系統默認已支持vulkan
apt install vulkan-tools
GPU驅動采用的與Android系統類似的mali_kbase內核驅動,不同于mesa開源驅動所使用的panthor,用戶態是閉源驅動
root@orion-o6:~# cat /sys/class/misc/mali0/device/devfreq/15000000.gpu/max_freq
900000000
root@orion-o6:~# lsmod | grep mali
mali_kbase 1044480 22
GPU算力測試使用項目 https://github.com/nihui/vkpeak
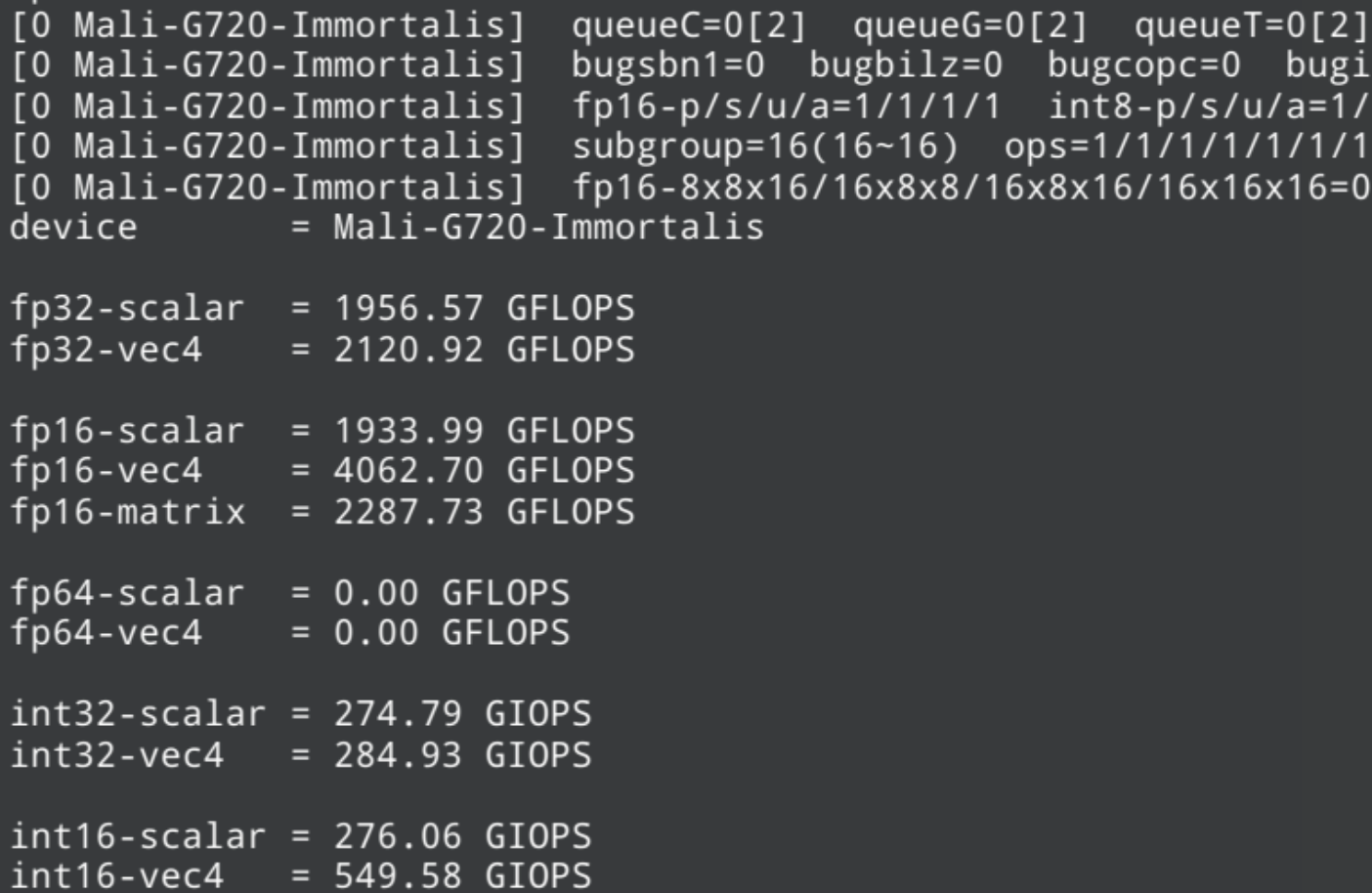
在vulkaninfo中發現,Mali Immortalis-G720 還支持矩陣擴展,支持的數據類型包含 fp16 * fp16 累加到 fp32,其中 M=16 N=32 K=32
https://registry.khronos.org/vulkan/specs/latest/man/html/VK_KHR_cooperative_matrix.html
vkpeak工具尚未適配這個MNK配置,修改vulkan shader如下,增加這個配置,循環執行 matrix mla 統計耗時測算 GFLOPS
考慮 arm mali gpu 普遍不具備 shared memory 硬件特性,于是利用 coopMatLoad 的 broadcasting 特性盡量減少內存訪問
#version 450#extension GL_EXT_shader_16bit_storage: require
#extension GL_EXT_shader_explicit_arithmetic_types_float16: require
#extension GL_KHR_memory_scope_semantics: require
#extension GL_EXT_shader_explicit_arithmetic_types: require
#extension GL_KHR_cooperative_matrix: requirelayout (constant_id = 0) const int loop = 1;layout (binding = 0) writeonly buffer c_blob { uvec4 c_blob_data[]; };shared uvec4 tmp_a[2];
shared uvec4 tmp_b[4];
shared uvec4 tmp_c[4];void main()
{const int gx = int(gl_GlobalInvocationID.x);const int lx = int(gl_LocalInvocationID.x);if (lx < 2){tmp_a[lx] = uvec4(gx);tmp_b[lx] = uvec4(lx);}barrier();coopmat<float16_t, gl_ScopeSubgroup, 16, 32, gl_MatrixUseA> a;coopmat<float16_t, gl_ScopeSubgroup, 32, 32, gl_MatrixUseB> b;coopMatLoad(a, tmp_a, 0, 0, gl_CooperativeMatrixLayoutRowMajor);coopMatLoad(b, tmp_b, 0, 0, gl_CooperativeMatrixLayoutRowMajor);coopmat<float, gl_ScopeSubgroup, 16, 32, gl_MatrixUseAccumulator> c = coopmat<float, gl_ScopeSubgroup, 16, 32, gl_MatrixUseAccumulator>(0.f);for (int i = 0; i < loop; i++){c = coopMatMulAdd(a, b, c);c = coopMatMulAdd(a, b, c);c = coopMatMulAdd(a, b, c);c = coopMatMulAdd(a, b, c);c = coopMatMulAdd(a, b, c);c = coopMatMulAdd(a, b, c);c = coopMatMulAdd(a, b, c);c = coopMatMulAdd(a, b, c);c = coopMatMulAdd(a, b, c);c = coopMatMulAdd(a, b, c);c = coopMatMulAdd(a, b, c);c = coopMatMulAdd(a, b, c);c = coopMatMulAdd(a, b, c);c = coopMatMulAdd(a, b, c);c = coopMatMulAdd(a, b, c);c = coopMatMulAdd(a, b, c);}coopMatStore(c, tmp_c, 0, 0, gl_CooperativeMatrixLayoutRowMajor);barrier();if (lx < 4){c_blob_data[gx] = tmp_c[lx];}
}
vkpeak 測試截圖,可以看到 fp16 相對于 fp32 有翻倍的算力,而 fp16-fp32 matrix 接近 fp32 算力,由于當前驅動沒有實現 fp16 累加類型支持,實際對于神經網絡計算的加成可能不如用單純的 fp16 vec4 計算
GPU 不支持 fp64
GPU帶寬測試
gpu reduce sum 是個經典的計算過程,在高度優化下通常受制于 gpu 顯存帶寬
這里有個很好的優化教程 https://developer.download.nvidia.cn/assets/cuda/files/reduction.pdf
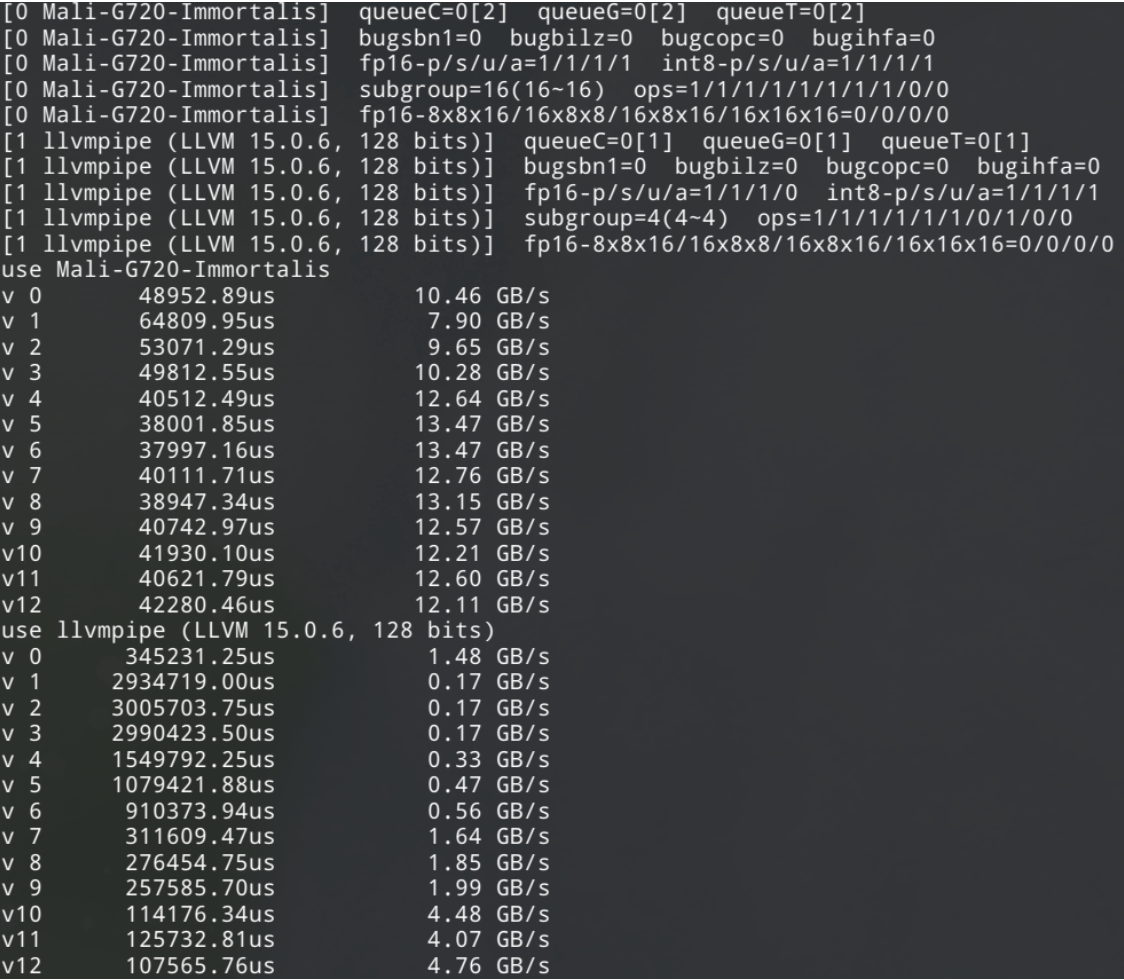
我在這個教程的基礎上,針對移動GPU和其他GPU的特性,擴充了幾個內核版本,分別測算 reduce 的顯存帶寬
結果顯示這 Mali Immortalis-G720 在 v6 版本內核中跑到了最快,對應帶寬為 13.47GB/s
llvmpipe是mesa實現的CPU模擬,一起對比下
相關 vulkan reduce sum 代碼如下(為了簡潔,已清理 Mali G720 無關的內容)
#version 450
#extension GL_KHR_shader_subgroup_basic : enable
#extension GL_KHR_shader_subgroup_arithmetic : enablelayout (local_size_x_id = 0) in;layout (binding = 0) readonly buffer in_blob { int in_data[]; };
layout (binding = 1) writeonly buffer out_blob { int out_data[]; };layout (push_constant) uniform parameter
{int count;
} p;shared int sdata[gl_WorkGroupSize.x];void main()
{const uint lx = gl_LocalInvocationID.x;const uint gx0 = gl_WorkGroupID.x * 2 * gl_WorkGroupSize.x + lx;const uint gx1 = gx0 + gl_WorkGroupSize.x;// load data from global memory to shared memoryint in0 = gx0 < p.count ? in_data[gx0] : 0;int in1 = gx1 < p.count ? in_data[gx1] : 0;sdata[lx] = in0 + in1;// synchronize to ensure all data is loadedbarrier();memoryBarrierShared();// perform reduction in shared memoryif (gl_WorkGroupSize.x >= 64 && gl_SubgroupSize < 32){if (lx < 32) sdata[lx] += sdata[lx + 32];barrier();memoryBarrierShared();}// subgroup reduceconst uint sid = gl_SubgroupInvocationID;int s = 0;if (gl_SubgroupID == 0){s = sdata[sid] + sdata[sid + gl_SubgroupSize];s = subgroupAdd(s);}// write result for this block to global memoryif (lx == 0){out_data[gl_WorkGroupID.x] = s;}
}
pytorch模型轉NPU的過程記錄
簡單定義一個pytorch模型,內容是10次矩陣乘,方便測試算力。導出onnx模型和 x.npy 用于后面 npu compiler 做量化校準
import torch
import numpyclass MatMulNet(torch.nn.Module):def __init__(self):super().__init__()self.linear = torch.nn.Linear(4000, 4000, bias=False)def forward(self, x):x = self.linear(x)x = self.linear(x)x = self.linear(x)x = self.linear(x)x = self.linear(x)x = self.linear(x)x = self.linear(x)x = self.linear(x)x = self.linear(x)x = self.linear(x)return xx = torch.rand((1, 4000, 4000))model = MatMulNet()torch.onnx.export(model, x, 'matmulnet.onnx', input_names=['in0'], output_names=['out0'])numpy.save('x.npy', x.numpy())
再編寫一個對應的 matmulnet.cfg 配置,主要是要根據模型修改 input_shape input calibration_data 等設置
[Common]
mode = build[Parser]
model_type = onnx
model_name = matmulnet
detection_postprocess =
model_domain = image_classification
input_model = ./matmulnet.onnx
output_dir = ./
input_shape = [1, 4000, 4000]
input = in0[Optimizer]
calibration_data = x.npy
calibration_batch_size = 1
metric_batch_size = 1
output_dir = ./
dataset = numpydataset
save_statistic_info = True
cast_dtypes_for_lib = True[GBuilder]
target = X2_1204MP3
outputs = matmulnet.cix
profile = True
tiling = fps
執行 cixbuild matmulnet.cfg 進行npu模型優化,量化校準,保存最終的 matmulnet.cix 模型文件,這個過程很慢,很吃CPU+內存+硬盤,就像在用CPU訓練模型似的
nihui@nihui-pc:~/dev/o6-test$ cixbuild matmulnet.cfg
[I] Build with version 6.1.2958
[I] Parsing model....
[I] [Parser]: Begin to parse onnx model matmulnet...
2025-03-30 17:16:02.520291: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/nihui/.local/lib/python3.8/site-packages/cv2/../../lib64:
2025-03-30 17:16:02.520314: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
2025-03-30 17:16:03.533484: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/nihui/.local/lib/python3.8/site-packages/cv2/../../lib64:
2025-03-30 17:16:03.533509: W tensorflow/stream_executor/cuda/cuda_driver.cc:269] failed call to cuInit: UNKNOWN ERROR (303)
2025-03-30 17:16:03.533539: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (nihui-pc): /proc/driver/nvidia/version does not exist
2025-03-30 17:16:05.448576: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
[I] [Parser]: The input tensor(s) is/are: in0_0
[I] [Parser]: Input in0 from cfg is shown as tensor in0_0 in IR!
[I] [Parser]: 0 error(s), 0 warning(s) generated.
[I] [Parser]: Parser done!
[I] Parse model complete
[I] Simplifying float model.
[I] [IRChecker] Start to check IR: /home/nihui/dev/o6-test/internal_2025_3_30_17_16_1_mhe2r/matmulnet.txt
[I] [IRChecker] model_name: matmulnet
[I] [IRChecker] IRChecker: All IR pass (Checker Plugin disabled)
[I] [graph.cpp :1600] loading graph weight: /home/nihui/dev/o6-test/./internal_2025_3_30_17_16_1_mhe2r/matmulnet.bin size: 0x26281100
[I] Start to simplify the graph...
[I] Using fixed-point full optimization, it may take long long time ....
[I] Simplify Done.
[I] Simplify float model Done.
[I] Optimizing model....
[I] [OPT] [17:16:10]: [arg_parser] is running.
[I] [OPT] [17:16:10]: tool name: Compass-Optimizer, version: 1.3.2958, use cuda: False, running device: cpu
[I] [OPT] [17:16:10]: [quantization config Info][model name]: matmulnet, [quantization method for weight]: per_tensor_symmetric_restricted_range, [quantization method for activation]: per_tensor_symmetric_full_range, [calibation strategy for weight]: extrema, [calibation strategy for activation]: mean, [quantization precision]: activation_bits=8, weight_bits=8, bias_bits=32, lut_items_in_bits=8[I] [OPT] [17:16:10]: Suggest using "aipuchecker" to validate the IR firstly if you are not sure about its validity.
[I] [OPT] [17:16:10]: IR loaded.
Building graph: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:00<00:00, 1651.05it/s]
[I] [OPT] [17:16:10]: Begin to load weights.
[I] [OPT] [17:16:10]: Weights loaded.
Deserializing bin: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [00:00<00:00, 89.12it/s]
[I] [OPT] [17:16:10]: Successfully parsed IR with python API.
[I] [OPT] [17:16:10]: init graph by forwarding one sample filled with zeros
forward_to: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:02<00:00, 5.23it/s]
[I] [OPT] [17:16:13]: [graph_optimize_stage1] is running.
[I] [OPT] [17:16:13]: [statistic] is running.
statistic batch: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:05<00:00, 5.98s/it]
[I] [OPT] [17:16:19]: [graph_optimize_stage2] is running.
[I] [OPT] [17:16:19]: applying calibration strategy based on statistic info
calibration: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:00<00:00, 5166.87it/s]
[I] [OPT] [17:16:19]: [quantize] is running.
[I] [OPT] [17:16:20]: These OPs will automatically cast dtypes to adapt to lib's dtypes' spec (may cause model accuracy loss due to corresponding spec's restriction): {'OpType.Input', 'OpType.Reshape', 'OpType.FullyConnected'}
quantize each layer: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:00<00:00, 16.98it/s]
[I] [OPT] [17:16:22]: collecting per-layer similarity infomation between float graph and quanted graph by forwarding 1 sample on both of them
[I] [OPT] [17:16:29]: [graph_optimize_stage3] is running.
[I] [OPT] [17:16:29]: [serialize] is running.
[I] [OPT] [17:16:29]: check the final graph by forwarding one sample filled with zeros
forward_to: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:03<00:00, 3.78it/s]
[I] [OPT] [17:16:33]: Begin to serialzie IR
Writing IR: 13it [00:00, 628.59it/s]
Serializing bin: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [00:00<00:00, 419.53it/s]
[I] [OPT] [17:16:33]: IR has been saved into /home/nihui/dev/o6-test/./internal_2025_3_30_17_16_1_mhe2r
[I] [OPT] [17:16:33]: Compass-Optimizer has done at [serialize] period.
[I] [OPT] [17:16:33]: [Done]cost time: 31s, and [scale]: out: [tensor([9942.5059])] in: [tensor([255.0000])] [output tensors cosine]: [0.9991913553234072][output tensors MSE]: [8.952337537948551e-09]
[I] Optimizing model complete
[I] Simplifying quant model...
[I] [IRChecker] Start to check IR: /home/nihui/dev/o6-test/internal_2025_3_30_17_16_1_mhe2r/matmulnet_quant.txt
[I] [IRChecker] model_name: matmulnet
[I] [IRChecker] IRChecker: All IR pass (Checker Plugin disabled)
[I] [graph.cpp :1600] loading graph weight: /home/nihui/dev/o6-test/./internal_2025_3_30_17_16_1_mhe2r/matmulnet_quant.bin size: 0x98bd900
[I] Start to simplify the graph...
[I] Using fixed-point full optimization, it may take long long time ....
[I] Simplify Done.
[I] Simplify quant model Done.
[I] Building ...
[I] [IRChecker] Start to check IR: /home/nihui/dev/o6-test/internal_2025_3_30_17_16_1_mhe2r/matmulnet_quant_s.txt
[I] [IRChecker] model_name: matmulnet
[I] [IRChecker] IRChecker: All IR pass
[I] [tools.cpp : 342] BuildTool version: 6.1.2958. Build for target X2_1204MP3 PID: 24109
[I] [tools.cpp : 362] using default profile events to profile default
[I] [tools.cpp : 781] global cwd: /tmp/9845fce62963e3e71cf53fe8278fa0a4fdb2f2accb810446318bc27aff74
[I] [graph.cpp :1600] loading graph weight: /home/nihui/dev/o6-test/./internal_2025_3_30_17_16_1_mhe2r/matmulnet_quant_s.bin size: 0x98bd900
[I] [tiling.cpp:5112] Auto tiling now, please wait ...
[I] [aipu_plugin.cpp: 344] Convolution(/linear/MatMul) uses performance-lib
[I] [aipu_plugin.cpp: 344] Convolution(/linear_1/MatMul) uses performance-lib
[I] [aipu_plugin.cpp: 344] Convolution(/linear_2/MatMul) uses performance-lib
[I] [aipu_plugin.cpp: 344] Convolution(/linear_3/MatMul) uses performance-lib
[I] [aipu_plugin.cpp: 344] Convolution(/linear_4/MatMul) uses performance-lib
[I] [aipu_plugin.cpp: 344] Convolution(/linear_5/MatMul) uses performance-lib
[I] [aipu_plugin.cpp: 344] Convolution(/linear_6/MatMul) uses performance-lib
[I] [aipu_plugin.cpp: 344] Convolution(/linear_7/MatMul) uses performance-lib
[I] [aipu_plugin.cpp: 344] Convolution(/linear_8/MatMul) uses performance-lib
[I] [aipu_plugin.cpp: 344] Convolution(/linear_9/MatMul) uses performance-lib
[I] [actg.cpp : 473] new sgnode with actg: 0
[I] [datalayout_schedule2.cpp:1067] Layout loss: 10
[I] [datalayout_schedule2.cpp:1068] Layout scheduling ...
[I] [datalayout_schedule2.cpp:1071] The layout loss for graph matmulnet: 1
[I] [datalayout_schedule.cpp: 776] The graph matmulnet post optimized score:0
[I] [datalayout_schedule.cpp: 789] layout schedule costs: 0.392489ms
[I] [IRChecker] Start to check IR:
[I] [IRChecker] model_name: cost_model
[I] [IRChecker] IRChecker: All IR pass
[I] [load_balancer.cpp:2152] enable multicore schedule optimization for load balance strategy 0 it may degrade performance on single core targets.
[I] [load_balancer.cpp:1233] ----------------------------------------------
[I] [load_balancer.cpp:1234] Scheduler Optimization Performance Evaluation:
[I] [load_balancer.cpp:1271] level: 0 cycles: 0 utils: 0 0 0
[I] [load_balancer.cpp:1271] level: 1 cycles: 93004044 utils: 1 0 0
[I] [load_balancer.cpp:1277] total cycles: 93004044
[I] [load_balancer.cpp:1278] ----------------------------------------------
[I] [load_balancer.cpp: 141] schedule level: done
[I] [load_balancer.cpp: 144] [level 0]
[I] [load_balancer.cpp: 93] subgraph_in0
[I] [load_balancer.cpp: 104] -*-[real]in0
[I] [load_balancer.cpp: 148] [load] 0
[I] [load_balancer.cpp: 144] [level 1]
[I] [load_balancer.cpp: 93] subgraph_subgraph_reshape
[I] [load_balancer.cpp: 104] -*-[real]subgraph_reshape_sg_input_0
[I] [load_balancer.cpp: 104] -*-[real]reshape
[I] [load_balancer.cpp: 104] -*-[real]reshape/layout/NCHWC32
[I] [load_balancer.cpp: 93] -*-subgraph_/linear/MatMul
[I] [load_balancer.cpp: 104] -*--*-[real]/linear/MatMul
[I] [load_balancer.cpp: 93] -*-subgraph_/linear_1/MatMul
[I] [load_balancer.cpp: 104] -*--*-[real]/linear_1/MatMul
[I] [load_balancer.cpp: 93] -*-subgraph_/linear_2/MatMul
[I] [load_balancer.cpp: 104] -*--*-[real]/linear_2/MatMul
[I] [load_balancer.cpp: 93] -*-subgraph_/linear_3/MatMul
[I] [load_balancer.cpp: 104] -*--*-[real]/linear_3/MatMul
[I] [load_balancer.cpp: 93] -*-subgraph_/linear_4/MatMul
[I] [load_balancer.cpp: 104] -*--*-[real]/linear_4/MatMul
[I] [load_balancer.cpp: 93] -*-subgraph_/linear_5/MatMul
[I] [load_balancer.cpp: 104] -*--*-[real]/linear_5/MatMul
[I] [load_balancer.cpp: 93] -*-subgraph_/linear_6/MatMul
[I] [load_balancer.cpp: 104] -*--*-[real]/linear_6/MatMul
[I] [load_balancer.cpp: 93] -*-subgraph_/linear_7/MatMul
[I] [load_balancer.cpp: 104] -*--*-[real]/linear_7/MatMul
[I] [load_balancer.cpp: 93] -*-subgraph_/linear_8/MatMul
[I] [load_balancer.cpp: 104] -*--*-[real]/linear_8/MatMul
[I] [load_balancer.cpp: 93] -*-subgraph_/linear_9/MatMul
[I] [load_balancer.cpp: 104] -*--*-[real]/linear_9/MatMul
[I] [load_balancer.cpp: 104] -*-[real]/linear_9/MatMul_post_reshape
[I] [load_balancer.cpp: 148] [load] 93004044
[I] [load_balancer.cpp: 151] schedule level: done done
[I] [mc_scheduler_mem_alloc.cpp: 422] with GM optimization reduce footprint:0B
[I] [aipu_plugin_tpc.cpp: 173] LayoutConvertor(reshape/layout/NCHWC32)uses tensor-process-lib
[I] [aipu_plugin_tpc.cpp: 173] LayoutConvertor(reshape/layout/NCHWC32)uses tensor-process-lib
[I] [layoutconvertor.cpp: 258] Building reshape/layout/NCHWC32...
[I] [aipu_plugin_tpc.cpp: 173] LayoutConvertor(reshape/layout/NCHWC32)uses tensor-process-lib
[I] [builder.cpp:1788] The graph DDR Footprint requirement(estimation) of feature maps:
[I] [builder.cpp:1789] Read and Write:335.69MB
[I] [builder.cpp:1043] Reduce constants memory size: 137.404MB
[W] [ar_reader.cpp: 142] name offset not found
[W] [ar_reader.cpp: 63] /usr/bin//../lib//libmcheck.ais not a archive file.
[I] [builder.cpp:2250] memory statistics for this graph (matmulnet)
[I] [builder.cpp: 559] Total memory : 0x01004f90 Bytes ( 16.019MB)
[I] [builder.cpp: 559] Text section: 0x00024750 Bytes ( 0.142MB)
[I] [builder.cpp: 559] RO section: 0x00000d00 Bytes ( 0.003MB)
[I] [builder.cpp: 559] Desc section: 0x00048300 Bytes ( 0.282MB)
[I] [builder.cpp: 559] Data section: 0x00f42850 Bytes ( 15.260MB)
[I] [builder.cpp: 559] BSS section: 0x00014bf0 Bytes ( 0.081MB)
[I] [builder.cpp: 559] Stack : 0x00040400 Bytes ( 0.251MB)
[I] [builder.cpp: 559] Workspace(BSS) : 0x00000000 Bytes ( 0.000MB)
[I] [builder.cpp:2266]
[I] [tools.cpp :1127] - compile time: 2.624 s
[I] [tools.cpp :1033] With GM optimization, DDR Footprint stastic(estimation):
[I] [tools.cpp :1040] Read and Write:488.36MB
[I] [tools.cpp :1083] - draw graph time: 0.002 s
[I] [tools.cpp :1766] remove global cwd: /tmp/9845fce62963e3e71cf53fe8278fa0a4fdb2f2accb810446318bc27aff74
Serialization Model: /home/nihui/dev/o6-test/matmulnet.cix
build success.......
Total errors: 0, warnings: 2
把 matmulnet.cix 和 x.npy 兩個文件都拷貝到 orion o6 開發板上,寫個最簡單的 NPU 模型推理測試代碼,記錄一次推理所需時間并測算出 int8 TOPS
orion o6 debian系統默認已經安裝了 libnoe 運行庫,能直接使用
import numpy
import time
from libnoe import *npu = NPU()npu.noe_init_context()
print('noe_init_context done')graph_id = npu.noe_load_graph('./matmulnet.cix')['data']
print('noe_load_graph done')input_datatype = npu.noe_get_tensor_descriptor(graph_id, NOE_TENSOR_TYPE_INPUT, 0).data_type
output_datatype = npu.noe_get_tensor_descriptor(graph_id, NOE_TENSOR_TYPE_OUTPUT, 0).data_type
print('noe_get_tensor_descriptor done')job_cfg = { "partition_id": 0, "dbg_dispatch": 0, "dbg_core_id": 0, "qos_level": 0, }
fm_idxes = []
wt_idxes = []
job_id = npu.noe_create_job(graph_id, job_cfg, fm_idxes, wt_idxes)['data']
print('noe_create_job done')x = numpy.load('x.npy')
npu.noe_load_tensor(job_id, 0, x.tobytes())
print('noe_load_tensor done')# infer
t0 = time.perf_counter()npu.noe_job_infer_sync(job_id, -1)t1 = time.perf_counter()
duration = t1 - t0print('noe_job_infer_sync done ', duration * 1000, ' ms')
print('gi8ops = ', 4000 * 4000 * 4000 * 10.0 / (1024 * 1024 * 1024) / duration * 2)out = npu.noe_get_tensor(job_id, NOE_TENSOR_TYPE_OUTPUT, 0, D_INT8)['data']
print('noe_get_tensor done')npu.noe_clean_job(job_id)
print('noe_clean_job done')npu.noe_unload_graph(graph_id)
print('noe_unload_graph done')npu.noe_deinit_context()
print('noe_deinit_context done')
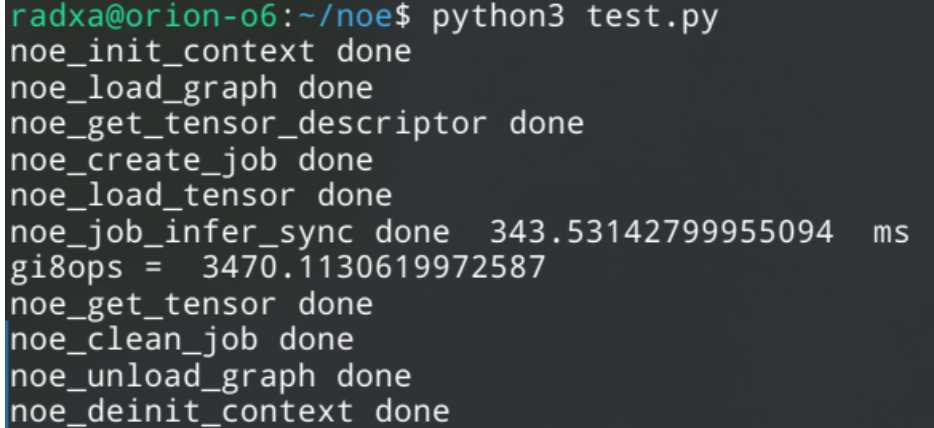
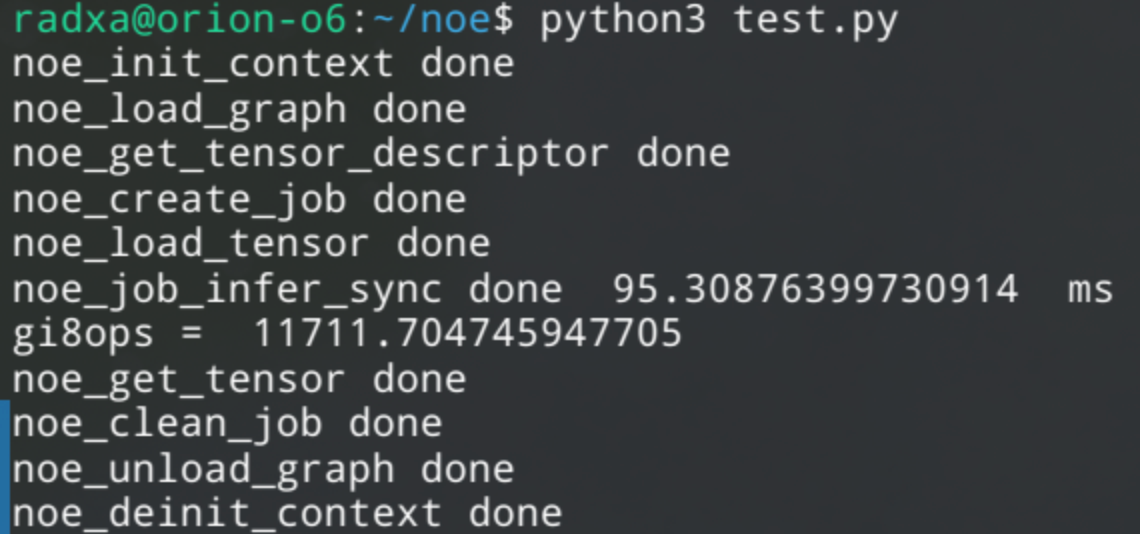
執行效果如下,可以看到 10 次 4000x4000 矩陣乘 int8 量化后在 NPU 上耗時 343ms,等效于 3.47TOPS
conv3x3 NPU算力測試
考慮到 matmul 計算比較吃帶寬,改為計算密度更高的 conv3x3 卷積
class Conv3x3Net(torch.nn.Module):def __init__(self):super().__init__()self.conv = torch.nn.Conv2d(800, 800, (3,3), padding=(1,1), bias=False)def forward(self, x):x = self.conv(x)x = self.conv(x)x = self.conv(x)x = self.conv(x)x = self.conv(x)x = self.conv(x)x = self.conv(x)x = self.conv(x)x = self.conv(x)x = self.conv(x)return xx = torch.rand((1, 800, 100, 100))
npu轉換過程和上面一樣,計算TOPS改為 print('gi8ops = ', 800 * 800 * 3 * 3 * 102 * 102 * 10.0 / (1024 * 1024 * 1024) / duration * 2)
結果顯然 conv3x3 的效率更高,達到 11.71TOPS
根據規格說明,NPU 支持 INT4 / INT8 / INT16 / FP16 / BF16 和 TF32 加速,算力高達 28.8TOPs
但是 NPU手冊上卻寫著只支持 8bit 16bit 量化,實際工具只支持最低 int8 量化,int4 算力目前無法測試 qaq
)













)




