文章目錄
- 一、待解決問題
- 1.1 問題描述
- 1.2 解決方法
- 二、方法詳述
- 2.1 必要說明
- (1)MAPPO 與 IPPO 算法的區別在于什么地方?
- (2)IPPO 算法應用框架主要參考來源
- 2.2 應用步驟
- 2.2.1 搭建基礎環境
- 2.2.2 IPPO 算法實例復現
- (1)源碼
- (2)Combat環境補充
- (3)代碼結果
- 2.2.3 代碼框架理解
- 三、疑問
- 四、總結
一、待解決問題
1.1 問題描述
在Combat環境中應用了MAPPO算法,在同樣環境中學習并復現IPPO算法。
1.2 解決方法
(1)搭建基礎環境。
(2)IPPO 算法實例復現。
(3)代碼框架理解
二、方法詳述
2.1 必要說明
(1)MAPPO 與 IPPO 算法的區別在于什么地方?
源文獻鏈接:The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games
源文獻原文如下:
為清楚起見,我們將具有 集中價值函數 輸入的 PPO 稱為 MAPPO (Multi-Agent PPO)。
將 策略和價值函數均具有本地輸入 的 PPO 稱為 IPPO (Independent PPO)。
總結而言,就是critic網絡不再是集中式的了。
因此,IPPO 相對于 MAPPO 可能會更加占用計算、存儲資源,畢竟每個agent都會擁有各自的critic網絡。
(2)IPPO 算法應用框架主要參考來源
其一,《動手學強化學習》-chapter 20
其二,深度強化學習(7)多智能體強化學習IPPO、MADDPG
?非常感謝大佬的分享!!!
2.2 應用步驟
2.2.1 搭建基礎環境
這一步驟直接參考上一篇博客,【動手學強化學習】番外7-MAPPO應用框架2學習與復現
2.2.2 IPPO 算法實例復現
(1)源碼
智能體對于policy的使用分為separated policy與shared policy,即每個agent擁有單獨的policy net,所有agent共用一個policy net,二者在源碼中都能夠使用,對應位置取消注釋即可。
與MAPPO的不同就在于,每個agent擁有單獨的value net。
import torch
import torch.nn.functional as F
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
import sys
from ma_gym.envs.combat.combat import Combat# PPO算法class PolicyNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super(PolicyNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)self.fc3 = torch.nn.Linear(hidden_dim, action_dim)def forward(self, x):x = F.relu(self.fc2(F.relu(self.fc1(x))))return F.softmax(self.fc3(x), dim=1)class ValueNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim):super(ValueNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)self.fc3 = torch.nn.Linear(hidden_dim, 1)def forward(self, x):x = F.relu(self.fc2(F.relu(self.fc1(x))))return self.fc3(x)def compute_advantage(gamma, lmbda, td_delta):td_delta = td_delta.detach().numpy()advantage_list = []advantage = 0.0for delta in td_delta[::-1]:advantage = gamma * lmbda * advantage + deltaadvantage_list.append(advantage)advantage_list.reverse()return torch.tensor(advantage_list, dtype=torch.float)# PPO,采用截斷方式
class PPO:def __init__(self, state_dim, hidden_dim, action_dim,actor_lr, critic_lr, lmbda, eps, gamma, device):self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)self.critic = ValueNet(state_dim, hidden_dim).to(device)self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), actor_lr)self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), critic_lr)self.gamma = gammaself.lmbda = lmbdaself.eps = eps # PPO中截斷范圍的參數self.device = devicedef take_action(self, state):state = torch.tensor([state], dtype=torch.float).to(self.device)probs = self.actor(state)action_dict = torch.distributions.Categorical(probs)action = action_dict.sample()return action.item()def update(self, transition_dict):states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(self.device)rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device)td_target = rewards + self.gamma * \self.critic(next_states) * (1 - dones)td_delta = td_target - self.critic(states)advantage = compute_advantage(self.gamma, self.lmbda, td_delta.cpu()).to(self.device)old_log_probs = torch.log(self.actor(states).gather(1, actions)).detach()log_probs = torch.log(self.actor(states).gather(1, actions))ratio = torch.exp(log_probs - old_log_probs)surr1 = ratio * advantagesurr2 = torch.clamp(ratio, 1 - self.eps, 1 +self.eps) * advantage # 截斷action_loss = torch.mean(-torch.min(surr1, surr2)) # PPO損失函數critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))self.actor_optimizer.zero_grad()self.critic_optimizer.zero_grad()action_loss.backward()critic_loss.backward()self.actor_optimizer.step()self.critic_optimizer.step()def show_lineplot(data, name):# 生成 x 軸的索引x = list(range(100))# 創建圖形和坐標軸plt.figure(figsize=(20, 6))# 繪制折線圖plt.plot(x, data, label=name,marker='o', linestyle='-', linewidth=2)# 添加標題和標簽plt.title(name)plt.xlabel('Index')plt.ylabel('Value')plt.legend()# 顯示圖形plt.grid(True)plt.show()actor_lr = 3e-4
critic_lr = 1e-3
epochs = 10
episode_per_epoch = 1000
hidden_dim = 64
gamma = 0.99
lmbda = 0.97
eps = 0.2
team_size = 2 # 每個team里agent的數量
grid_size = (15, 15) # 二維空間的大小
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")# 創建環境
env = Combat(grid_shape=grid_size, n_agents=team_size, n_opponents=team_size)
state_dim = env.observation_space[0].shape[0]
action_dim = env.action_space[0].n# =============================================================================
# # 創建智能體(不參數共享:separated policy)
# agent1 = PPO(
# state_dim, hidden_dim, action_dim,
# actor_lr, critic_lr, lmbda, eps, gamma, device
# )
# agent2 = PPO(
# state_dim, hidden_dim, action_dim,
# actor_lr, critic_lr, lmbda, eps, gamma, device
# )
# =============================================================================# 創建智能體(參數共享:shared policy)
agent = PPO(state_dim, hidden_dim, action_dim,actor_lr, critic_lr, lmbda, eps, gamma, device
)win_list = []for e in range(epochs):with tqdm(total=episode_per_epoch, desc='Epoch %d' % e) as pbar:for episode in range(episode_per_epoch):# Replay buffer for agent1buffer_agent1 = {'states': [],'actions': [],'next_states': [],'rewards': [],'dones': []}# Replay buffer for agent2buffer_agent2 = {'states': [],'actions': [],'next_states': [],'rewards': [],'dones': []}# 重置環境s = env.reset()terminal = Falsewhile not terminal:# 采取動作(不進行參數共享)# a1 = agent1.take_action(s[0])# a2 = agent2.take_action(s[1])# 采取動作(進行參數共享)a1 = agent.take_action(s[0])a2 = agent.take_action(s[1])next_s, r, done, info = env.step([a1, a2])buffer_agent1['states'].append(s[0])buffer_agent1['actions'].append(a1)buffer_agent1['next_states'].append(next_s[0])# 如果獲勝,獲得100的獎勵,否則獲得0.1懲罰buffer_agent1['rewards'].append(r[0] + 100 if info['win'] else r[0] - 0.1)buffer_agent1['dones'].append(False)buffer_agent2['states'].append(s[1])buffer_agent2['actions'].append(a2)buffer_agent2['next_states'].append(next_s[1])buffer_agent2['rewards'].append(r[1] + 100 if info['win'] else r[1] - 0.1)buffer_agent2['dones'].append(False)s = next_s # 轉移到下一個狀態terminal = all(done)# 更新策略(不進行參數共享)# agent1.update(buffer_agent1)# agent2.update(buffer_agent2)# 更新策略(進行參數共享)agent.update(buffer_agent1)agent.update(buffer_agent2)win_list.append(1 if info['win'] else 0)if (episode + 1) % 100 == 0:pbar.set_postfix({'episode': '%d' % (episode_per_epoch * e + episode + 1),'winner prob': '%.3f' % np.mean(win_list[-100:]),'win count': '%d' % win_list[-100:].count(1)})pbar.update(1)win_array = np.array(win_list)
# 每100條軌跡取一次平均
win_array = np.mean(win_array.reshape(-1, 100), axis=1)# 創建 episode_list,每組 100 個回合的累計回合數
episode_list = np.arange(1, len(win_array) + 1) * 100
plt.plot(episode_list, win_array)
plt.xlabel('Episodes')
plt.ylabel('win rate')
plt.title('IPPO on Combat(shared policy)')
plt.show()
(2)Combat環境補充
這里還需要說明的是,由于在獎勵設置過程中采用了win(獲勝),但是Combat環境中step函數并沒有返還該值
buffer_agent1['rewards'].append(r[0] + 100 if info['win'] else r[0] - 0.1)...
win_array = np.array(win_list)
...
因此需要在step()函數中加入對win(獲勝)的判斷,與return返回值
# 判斷是否獲勝win = Falseif all(self._agent_dones):if sum([v for k, v in self.opp_health.items()]) == 0:win = Trueelif sum([v for k, v in self.agent_health.items()]) == 0:win = Falseelse:win = None # 平局# 將獲勝信息添加到 info 中info = {'health': self.agent_health, 'win': win, 'opp_health': self.opp_health, 'step_count': self._step_count}return self.get_agent_obs(), rewards, self._agent_dones, info
(3)代碼結果
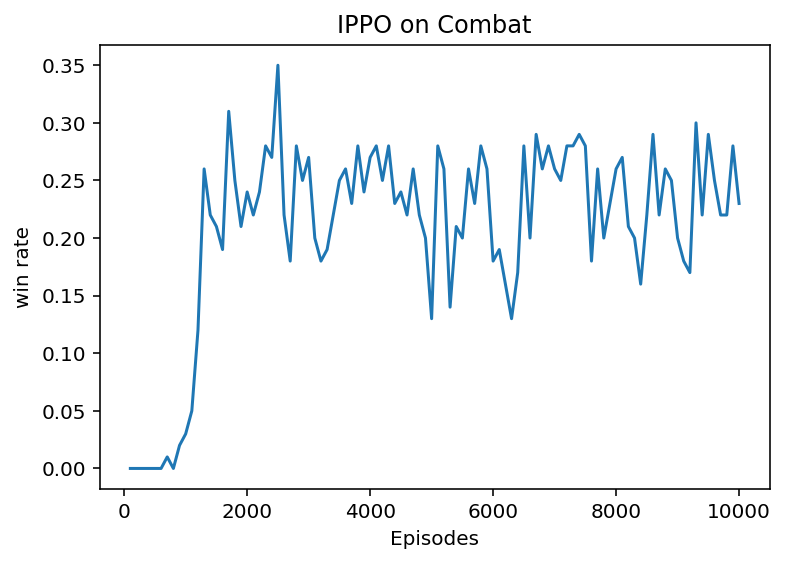
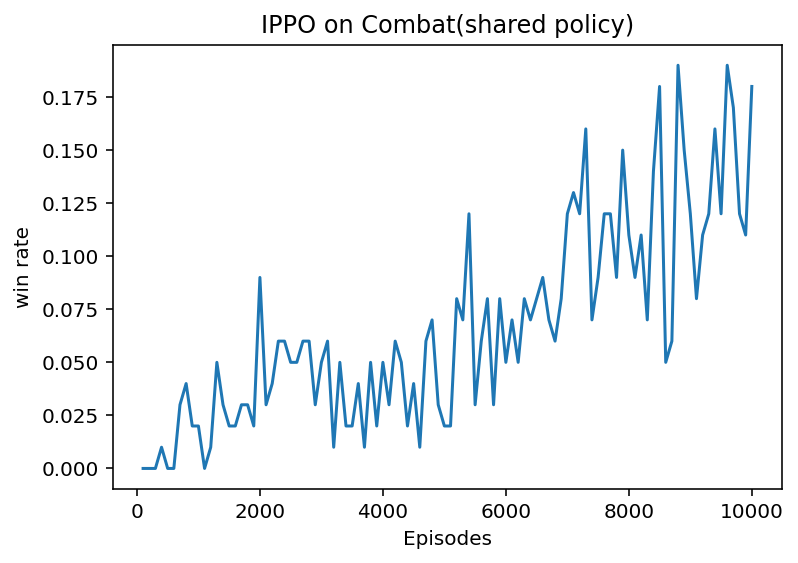
左圖為separated policy下運行結果,右圖為shared policy下運行結果。
明顯可以看出,separated policy有著更好的效果,但是代價就是在訓練過程中會占用更多的資源。
2.2.3 代碼框架理解
從2.2.2節源碼不難看出,IPPO算法其實就是在PPO算法上改為了多agent的環境,其中policy net,value net的更新原理并沒有改變,因此代碼框架的理解查看PPO算法原理即可。
參考鏈接:【動手學強化學習】part8-PPO(Proximal Policy Optimization)近端策略優化算法
三、疑問
- 暫無
四、總結
IPPO算法相對于MAPPO算法會占用更多的資源,如果環境較為簡單,可以采用該算法。如果環境比較復雜,建議先采用MAPPO算法進行訓練。








)










