摘要
本研究通過分離共形預測(SCP)框架,解決了大型視覺語言模型(LVLMs)在視覺問答(VQA)任務中幻覺緩解的關鍵挑戰。雖然LVLMs在多模態推理方面表現出色,但它們的輸出常常表現出具有高置信度的幻覺內容,從而在安全關鍵型應用中構成風險。我們提出了一種與模型無關的不確定性量化方法,該方法集成了動態閾值校準和跨模態一致性驗證。通過將數據劃分為校準集和測試集,該框架計算不一致性分數,以構建在用戶定義的風險水平(α)下具有統計保證的預測集。主要創新包括:(1)嚴格控制邊際覆蓋率,以確保經驗誤差率嚴格低于α;(2)根據
α
動態調整預測集大小,過濾低置信度輸出;(3)消除先驗分布假設和重新訓練要求。在具有八個LVLMs的基準(ScienceQA,MMMU)上的評估表明,SCP在所有
α
值上強制執行理論保證。該框架在不同的校準與測試分割比例下實現了穩定的性能,突顯了其在醫療保健、自主系統和其他安全敏感領域中實際部署的穩健性。這項工作彌合了多模態人工智能系統中理論可靠性和實際適用性之間的差距,為幻覺檢測和不確定性感知決策提供了可擴展的解決方案。
1 引言
隨著多模態模型的快速發展,大型視覺-語言模型(LVLMs)已廣泛應用于醫療保健和自動駕駛等關鍵領域 Kostumov et al. [2024], Zhang et al. [2024], Liu et al. [2023]。然而,對視覺-語言問答(VQA)任務的研究表明,與單模態語言模型相比,這些多模態系統更容易出現明顯的幻覺現象 Rohrbach et al. [2018], Rawte et al. [2023]。盡管生成的回復通常看起來令人信服并表現出高度自信,但模型可能會產生不準確的輸出。依賴于這種幻覺結果可能會引入決策偏差,甚至構成重大的安全風險。在這種背景下,開發高效且自動化的幻覺檢測機制已成為確保多模態人工智能系統可靠性的核心挑戰。此外,研究表明,在VQA任務中一起處理視覺和文本信息會增加產生幻覺的風險。這些問題突顯了對自動化檢測框架的需求,該框架能夠適應多模態不確定性,而無需依賴先驗知識。我們的方法集成了動態閾值校準和跨模態一致性驗證,旨在為安全敏感型應用提供實時、穩健的可靠性。
先前的研究主要集中在量化模型輸出,并為用戶提供評估自然語言生成(NLG)可靠性的方法,如Liang et al. [2024], Li et al. [2023]。目前的不確定性量化方法,例如基于校準的技術和口頭不確定性方法,旨在表明預測的可信度。然而,這些方法——通常本質上是啟發式的——未能提供特定于任務的性能保證,從而限制了它們的實際適用性。例如,口頭不確定性經常表現出過度自信,從而損害了其可靠性。雖然校準使概率與經驗正確率保持一致,但它需要昂貴的重新訓練,并且仍然容易受到分布偏移的影響。這些局限性突顯了需要更穩健和更具通用性的框架,以確保NLG中可信的不確定性估計。
共形預測 (Conformal Prediction, CP) 是一種不確定性量化框架,其主要優勢在于僅基于數據可交換性假設,為真實結果的覆蓋率提供嚴格的統計保證 Romano et al. [2019], Cresswell et al. [2024], Ke [2025]。與依賴于啟發式近似或復雜先驗分布的方法相比,CP 是模型無關的、分布自由的且計算高效的,允許它直接應用于預訓練系統,而無需重新訓練。在這項工作中,我們采用分離共形預測 (Split Conformal Prediction, SCP) 方法,并將其擴展到封閉式視覺-VQA 任務中的多項選擇場景。具體而言,首先使用 LVLM 生成目標數據集的候選答案集,然后,基于校準集樣本的真實標簽,設計一個非一致性分數 (Nonconformity Score, NS) 來量化模型輸出的不確定性。通過計算校準集中 NS 的分位數,并結合用戶指定的風險水平(表示為?
δ
),最終在測試集上實現對邊際覆蓋率的嚴格控制。該方法不僅避免了傳統方法固有的對分布假設的依賴,而且為多模態場景中可靠的決策提供了理論支持。
我們的實驗采用MMMU和ScienceQA作為基準數據集,并評估了來自四個不同模型組的八個LVLM,包括LLaVA1.5、LLaVA-NeXT、Qwen2VL和InternVL2。大量的經驗結果表明,我們的框架實現了對各種用戶指定的風險水平(表示為
α
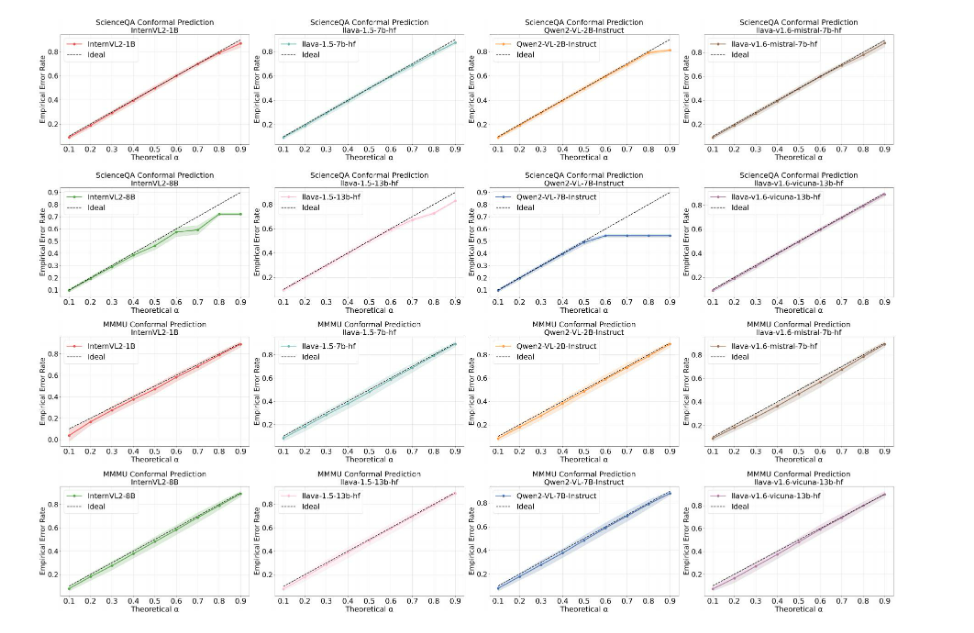
)下的錯誤覆蓋率的嚴格控制。例如,在ScienceQA基準測試中,即使對誤差概率有很高的容忍度(α ≥ 0.6),Qwen2-VL-7B-lnstruct模型也能將其經驗誤差率保持在α = 0.6以下。值得注意的是,隨著
α
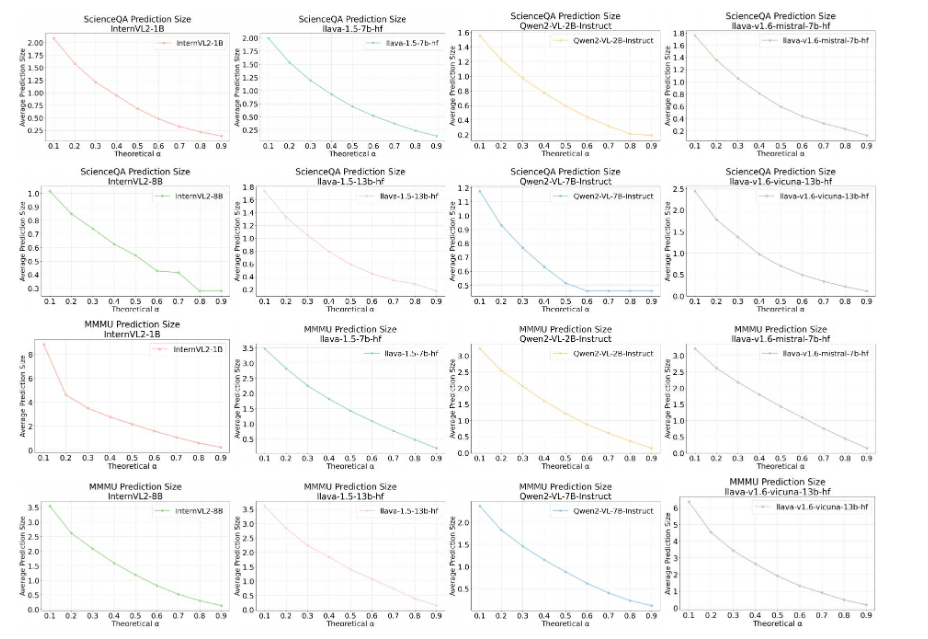
的增加,生成的答案集的平均預測大小有系統地收緊——這是減輕LVLM中幻覺的關鍵屬性。這種
α
和預測集大小之間的反比關系確保了更高的風險容忍度會產生更緊湊的預測集,從而有效地過濾掉低置信度或虛假輸出。此外,無論校準到測試數據的分割比例如何,平均經驗誤差率始終符合用戶定義的風險水平。結合可控的預測集粒度,這種穩健性突顯了該方法的雙重能力:確保統計上有效的覆蓋率,同時通過自適應集約束動態抑制幻覺響應。這種能力對于在安全至關重要的場景中部署LVLM至關重要,在這些場景中,可靠性和精確性都至關重要。
2 相關工作
大型視覺-語言模型。早期研究主要集中于從圖像和文本輸入生成文本響應。在這一基礎上,后續研究顯著擴展了LVLM的能力和應用領域。最近的進展進一步增強了細粒度解析能力,實現了對局部區域(例如,邊界框或關鍵點)的精確控制,超越了整體圖像理解。這些發展促進了LVLM在醫療診斷、具身機器人交互和自動駕駛等關鍵領域的廣泛部署。然而,多模態交互的復雜性引入了新的挑戰——例如,跨模態信息融合的不一致性可能會降低輸出的可靠性。在醫療保健和自動系統等高風險場景中,不可靠的模型響應可能導致嚴重的安全隱患,突顯了準確的幻覺檢測的必要性。與依賴外部驗證的傳統方法不同,這項工作提出了量化LVLM的內在不確定性以識別幻覺,為構建安全可靠的人工智能協作系統奠定了新的理論基礎。
大型語言模型中的幻覺現象。在自然語言處理中,幻覺指的是生成的內容看似合理,但偏離了源材料或事實準確性,其概念源于感知不存在的現實的心理學概念。Lin et al. [2023], Kuhn et al. [2023], Farquhar et al. [2024], Wang et al. [2025a]。這種現象主要表現為兩種類型:內在幻覺(與源上下文直接矛盾)和外在幻覺(內容無法通過原始上下文或外部知識庫驗證)。對大型視覺-語言模型(LVLM)的研究表明,它們對以用戶為中心的交互和指令對齊的強烈關注導致了事實扭曲,可分為事實幻覺(偏離可驗證的事實)和忠實性幻覺(違反用戶指令、上下文連貫性或邏輯一致性)。檢測方法遵循兩種途徑。(1)基于外部模型的評估:這種方法采用先進的LVLM作為評分判別器來評估響應質量,但受到對合成注釋的依賴性的限制。(2)基于離散規則的檢查:基于離散規則的系統側重于通過CHAIR、MME和POPE等基準進行對象幻覺(OH)評估。緩解策略采用對比解碼(CD)和后處理技術:CD通過視覺區域比較、自我對比分析和偏好模型比較來解決感知偏差,但存在敏感性和過度簡化的問題;后處理通過迭代提示優化響應,但面臨計算開銷和有限的任務適應性。該框架為系統地評估LVLM輸出的可靠性提供了多維度的見解。
分離共形預測 (SCP)。SCP 展示了其作為大型視覺-語言模型 (LVLM) 的理論基礎不確定性量化框架的獨特優勢。其核心機制利用可交換數據校準來生成預測集,該預測集具有覆蓋真實答案的統計保證,適用于處理開放式自然語言生成任務的黑盒模型 Campos et al. [2024], Angelopoulos et al. [2023], Wang et al. [2024], Ye et al. [2024], Angelopoulos et al. [2024], Wang et al. [2025b,c]。與傳統的不確定性框架不同,SCP 需要最少的假設,同時提供可驗證的覆蓋保證。該方法保持模型無關和分布自由,僅在可交換數據條件下運行。最近的擴展通過使用置信度閾值(例如,QA 任務中的候選答案過濾)或基于似然的生成序列停止規則,使 SCP 適應多模態場景,通過動態預測集構建。為了解決開放式生成中的局限性,高級實現部署了黑盒不確定性量化策略,該策略將不確定性指標與正確性標準嚴格聯系起來,從而能夠在不同的模型架構和數據復雜性中實現穩健的覆蓋保證。盡管存在諸如非可交換數據適應和實時計算需求等挑戰,但 SCP 的模型獨立性、分布自由性質和偏差控制能力使其成為評估 LVLM 輸出可靠性的理論嚴謹且實際可行的解決方案。
3 方法
我們的方法主要解決兩個挑戰。(1)如何識別模型輸出中滿足用戶需求的響應分布。(2)如何嚴格證明所識別的輸出分布滿足模型的統計保證。我們首先開發了一種基于非一致性評分的不確定性量化方法,以建立模型生成響應的可靠性度量。此外,我們采用分裂共形預測(Split Conformal Prediction)來系統地將不確定性量化結果的啟發式近似轉換為統計上嚴格的結果。這種方法確保了預測集的穩健性和更強的統計保證,從而為模型的輸出分布提供了理論上的保證。
3.1 預備知識



我們將Si = S(Xi, Yi)表示為第i個校準示例的不一致性得分。
3.2 方法

步驟1和步驟2通常被稱為校準,而步驟3被稱為預測。直觀地說,預測集包括所有與樣本對應的預測,這些樣本的符合程度至少與校準集中足夠大的一部分樣本一樣好。
3.3 理論保證
共形預測 (CP) 的覆蓋保證源于其兩個基本理論性質:無分布有效性和邊際覆蓋率。正如 Vovk 等人 (2005) 所證明的,由前一小節中定義的共形預測器生成的預測集滿足以下覆蓋保證:



4 評估
4.1 實驗設置
基準測試。我們的實驗采用了多項選擇基準測試。對于多項選擇數據集,我們采用了兩個基準測試:MMMU 和 ScienceQA。具體來說,MMMU 包含來自大學水平的 1.15 萬個多模態問題
考試、測驗和教科書,涵蓋六個核心學科:藝術與設計、商業、科學、健康與醫學、人文與社會科學以及技術與工程。這些問題涵蓋30個學科和183個子領域,涉及30種高度異構的圖像類型。MMMU還提供了一個完整的測試集,包含150個開發樣本和900個驗證樣本。對于ScienceQA,這些問題來源于IXL Learning管理的開放資源,IXL Learning是由K-12領域專家策劃的在線教育平臺。該數據集包含符合加州共同核心內容標準的問題,包含21,208個樣本,分為訓練集(12,726個)、驗證集(4,241個)和測試集(4,241個)。
基礎LVLM。在本實驗中,我們評估了來自4個不同模型組的8個LVLM模型。具體而言,我們使用LLaVA-1.5、LLaVA-NeXT、Qwen2-VL和InternVL2對上述基準進行推理。LLaVA1.5通過一個兩層MLP連接器將CLIP視覺編碼器與大型語言模型(例如,Vicuna)對齊,采用兩階段訓練策略(預訓練和指令微調),并在視覺問答和OCR任務中表現出強大的性能。Qwen2-VL采用動態分辨率自適應,通過靈活的高分辨率圖像分割來保留細粒度細節。InternVL2通過縮放視覺編碼器(例如,InternViT-6B),應用具有像素重排的動態高分辨率處理以減少視覺tokens,并利用三階段漸進對齊策略,從而增強了通用視覺語言能力。
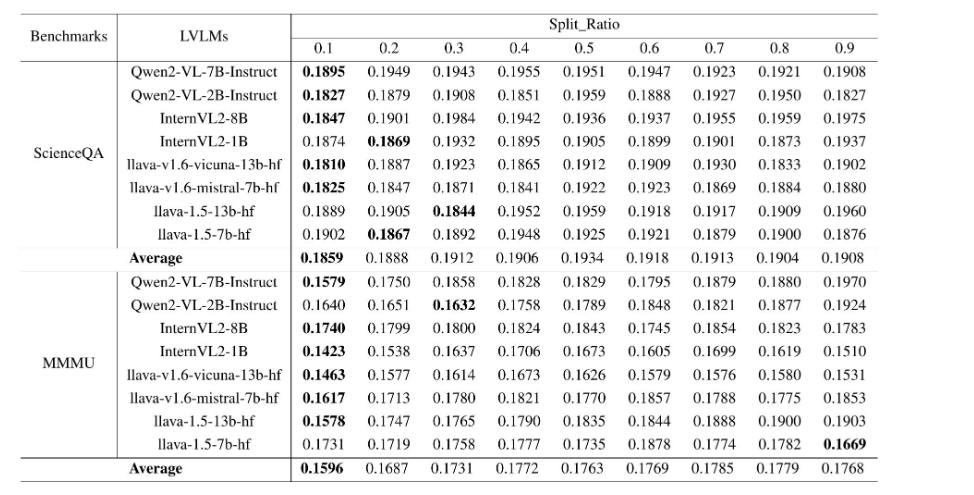


4.2 經驗誤差率



4.3 預測集合大小




5 結論
我們提出了一種基于分裂共形預測的統計可靠性框架,以解決大型視覺-語言模型在視覺問答任務中的幻覺問題。通過采用動態閾值校準和跨模態一致性驗證,我們將數據分為校準集和測試集,使用不一致性評分量化輸出不確定性,并從校準集分位數構建預測集。在用戶指定的風險水平α下,我們的方法嚴格控制真實答案的邊際覆蓋率。在多種多模態基準測試中,跨越不同的LVLM架構的實驗表明,SCP滿足所有α值的理論統計保證,并且預測集大小與α成反比調整,從而有效地過濾掉低置信度輸出。我們的模型無關且計算效率高的框架無需先驗分布假設或模型再訓練,為安全關鍵場景中可靠的多模態評估提供了堅實的理論和實踐支持。









-HIVE中的窗口函數)


)

)



在vector store中存儲embbdings)
)