目錄
第1關:維數災難與降維
第2關:PCA算法流程
任務描述
編程要求
測試說明
第3關:sklearn中的PCA
任務描述
編程要求
測試說明
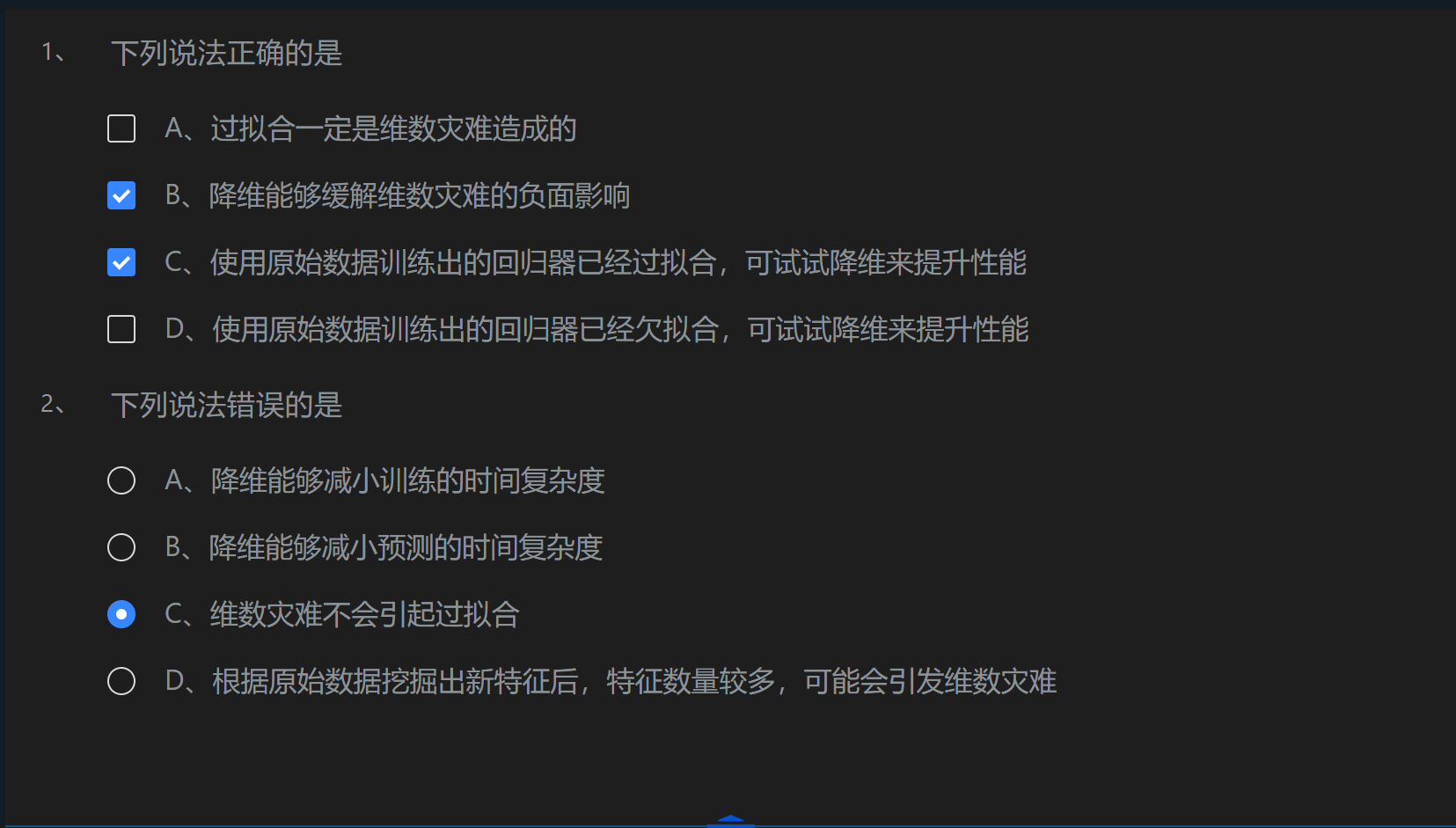
第1關:維數災難與降維
第2關:PCA算法流程
-
任務描述
本關任務:補充 python 代碼,完成 PCA 函數,實現降維功能。
-
編程要求
在 begin-end 之間填寫pca(data, k)函數,實現 PCA 算法,要求返回降維后的數據。其中:
data :原始樣本數據,類型為 ndarray;
k :需要降維至 k 維,類型為 int。
-
測試說明
只需完成 pca 函數即可,程序內部會調用您所完成的 pca 函數來進行驗證。以下為其中一個測試用例(其中 data 部分表示原始樣本數據,k 表示需要降維至 k 維):
測試輸入:
?{'data':[[1, 2.2, 3.1, 4.3, 0.1, -9.8, 10], [1.8, -2.2, 13.1, 41.3, 10.1, -89.8, 100]],'k':3}?
預期輸出:
?[[-6.34212110e+01 ?6.32827124e-15 ?1.90819582e-17]
?[ 6.34212110e+01 -6.32827124e-15 ?2.02962647e-16]]?
開始你的任務吧,祝你成功!
第3關:sklearn中的PCA
-
任務描述
本關任務:你需要調用 sklearn 中的 PCA 接口來對數據繼續進行降維,并使用 sklearn 中提供的分類器接口(可任意挑選分類器)對癌細胞數據進行分類。
-
編程要求
在 begin-end 之間填寫cancer_predict(train_sample, train_label, test_sample)函數實現降維并對癌細胞進行分類的功能,其中:
train_sample :訓練樣本,類型為 ndarray;
train_label :訓練標簽,類型為 ndarray;
test_sample :測試樣本,類型為 ndarray。
-
測試說明
只需返回預測結果即可,程序內部會檢測您的代碼,預測 AUC 高于 0.9 視為過關。
開始你的任務吧,祝你成功!
from sklearn.decomposition import PCA
from sklearn.ensemble import RandomForestClassifierdef cancer_predict(train_sample, train_label, test_sample):'''使用PCA降維,并進行分類,最后將分類結果返回:param train_sample:訓練樣本, 類型為ndarray:param train_label:訓練標簽, 類型為ndarray:param test_sample:測試樣本, 類型為ndarray:return: 分類結果'''#********* Begin *********#train_x = train_sampletrain_y = train_labelclf = RandomForestClassifier()clf.fit(train_x, train_y)predictions = clf.predict(test_sample)#********* End *********#return predictions


)















