Zookeeper 介紹
ZooKeeper 是一個開源的分布式協調服務,用于管理和協調分布式系統中的節點。它提供了一種高效、可靠的方式來解決分布式系統中的常見問題,如數據同步、配置管理、命名服務和集群管理等。本文介紹通過 DataKit 采集 Zookeeper 指標,幫助監控 Zookeeper 運行情況。
主要功能:
- 配置管理:集中管理分布式系統的配置信息,便于動態更新和同步。
- 命名服務:為分布式系統中的節點提供統一的命名和查找機制,類似于 DNS。
- 分布式鎖:通過鎖機制解決分布式系統中的資源競爭問題。
- 隊列管理:實現分布式隊列,支持順序隊列和優先隊列。
- 集群管理:監控集群成員的健康狀態,實現故障檢測和自動恢復。
Zookeeper 可觀測的必要性:
- 保障系統穩定性:ZooKeeper 是分布式系統的核心組件,負責協調多個節點的行為,確保數據一致性和服務可用性。監控 ZooKeeper 的健康狀態可以及時發現潛在問題,如節點故障、網絡異常或性能瓶頸,從而快速采取措施,避免系統整體故障。
- 優化系統性能:監控可以幫助開發者和運維人員了解 ZooKeeper 集群的性能狀況,例如操作延遲、事務處理速度等。通過分析這些數據,可以優化配置,提升系統性能。
- 預防故障:監控系統可以提前預警潛在問題,例如磁盤 I/O 等資源瓶頸,從而在問題惡化之前進行干預,預防故障的發生。
- 支持故障排查:當 ZooKeeper 集群出現問題時,監控數據可以提供關鍵線索,幫助快速定位問題根源。例如,通過分析日志和性能指標,可以確定是網絡問題、配置錯誤還是硬件故障。
- 提升運維效率:運維人員可以直觀地查看 ZooKeeper 集群的狀態,減少手動排查問題的時間,提高運維效率。
- 確保集群一致性:ZooKeeper 的核心功能之一是保證分布式系統中數據的一致性。監控可以確保集群中的所有節點狀態一致,及時發現和修復不一致的情況。
- 支持動態調整:分布式系統的環境和需求可能會動態變化,監控 ZooKeeper 可以幫助運維人員根據實時數據動態調整集群配置,例如增加節點或優化資源分配。
觀測云
觀測云是一款功能強大的統一可觀測平臺,提供對多云環境、云原生應用、中間件以及各類應用程序的實時監控和分析能力。在 ZooKeeper 的監控場景中,觀測云通過其核心數據采集器 DataKit,結合 ZooKeeper 的監控指標,實現對 ZooKeeper 集群的實時監控和數據可視化展示。觀測云通過其強大的數據可視化功能,將 ZooKeeper 的監控指標以直觀的儀表盤形式展示出來,幫助用戶快速定位問題并優化系統性能。
暴露 Zookeeper 指標
從 3.6.0 版本開始,ZooKeeper 原生支持 Prometheus 格式的指標暴露。只需在?zoo.cfg?配置文件中添加以下配置:
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
metricsProvider.httpPort=7000
metricsProvider.exportJvmInfo=true
然后重啟 Zookeeper 服務。
執行完畢后,可通過?http://主機ip:7000/metrics?查看當前主機獲取到的所有監控數據。
采集器配置
進入 DataKit 安裝目錄下的?conf.d/prom?目錄,復制?prom.conf.sample?并命名為?zookeeper.conf。
[[inputs.prom]]urls = ["http://192.168.0.19:7000/metrics"] ## 采 集 器 別 名 source = "zookeeper" ## 采 集 間 隔 "ns", "us" (or "μs"), "ms", "s", "m", "h" interval = "10s" measurement_name = "zookeeper" metric_types = [] ## TLS 配 置 tls_open = false [inputs.prom.tags] service = "zookeeper" # ·················[inputs.prom.as_logging]enable = falseservice = "service_name"## Customize tags.# [inputs.prom.tags]# some_tag = "some_value"# more_tag = "some_other_value"## (Optional) Collect interval: (defaults to "30s").# interval = "30s"## (Optional) Timeout: (defaults to "30s").# timeout = "30s"
主要修改 urls,配置好后保存,重啟 DataKit?即可。
關鍵指標
登錄觀測云控制臺,點擊「指標」 -「指標管理」,輸入“zookeeper”,就能查詢采集到的指標。
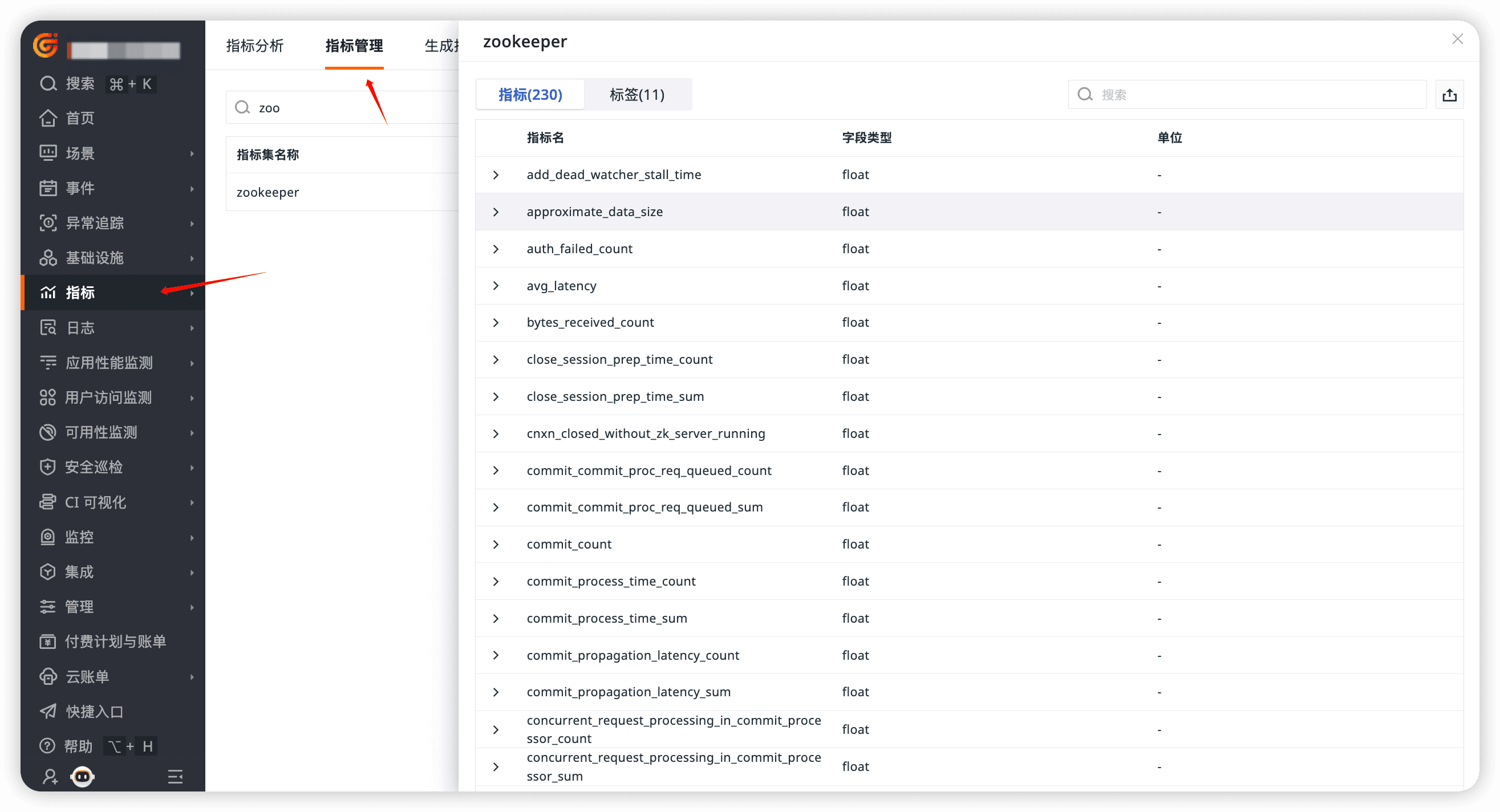
ZooKeeper 是一個分布式協調服務,用于管理分布式系統中的配置信息、命名服務、分布式同步等。以下是對 ZooKeeper 指標的解釋:
- 系統性能與延遲:通過 ZooKeeper 的四字命令(如 stat、srvr 等)可以獲取服務的運行狀態,包括是否處于領導者或追隨者角色、服務的延遲等
- 會話數:監控會話數可以幫助了解 ZooKeeper 的使用情況,及時發現異常的會話增長。
- 請求延遲:監控 ZooKeeper 的請求延遲可以幫助評估服務的響應性能。高延遲可能表明存在性能問題,需要進一步調查。
以下是關于 Zookeeper 關鍵指標的介紹:
| 指標 | 描述 | 單位 |
|---|---|---|
| avg_latency | 平均延遲 | ms |
| readlatency_count | 讀操作延遲的計數 | count |
| propagation_latency_count | 數據傳播延遲的計數 | count |
| commit_count | 提交操作的次數 | count |
| requests_in_session_queue_count | 會話隊列中的請求數量 | count |
| requests_not_forwarded_to_commit_processor | 未轉發到提交處理器的請求數量 | count |
| prep_processor_queue_size | 預處理隊列的大小 | Bytes |
| connection_request_count | 當前存活的連接數 | count |
| num_alive_connections | 用于緩存文件系統的內存量 | Bytes |
| session_queues_drained_count | 會話隊列被清空的次數 | count |
| auth_failed_count | 認證失敗的次數 | count |
| ensemble_auth_fail | 集群認證失敗的次數 | count |
| bytes_received_count | 接收的字節數 | Bytes |
| open_file_descriptor_count | 當前打開的文件描述符數量 | count |
| process_open_fds | 進程打開的文件描述符數量 | count |
| uptime | 系統或進程的運行時間 | s |
| approximate_data_size | 近似數據大小 | Bytes |
| znode_count | 節點數量 | count |
| watch_count | 監控數量 | count |
場景視圖
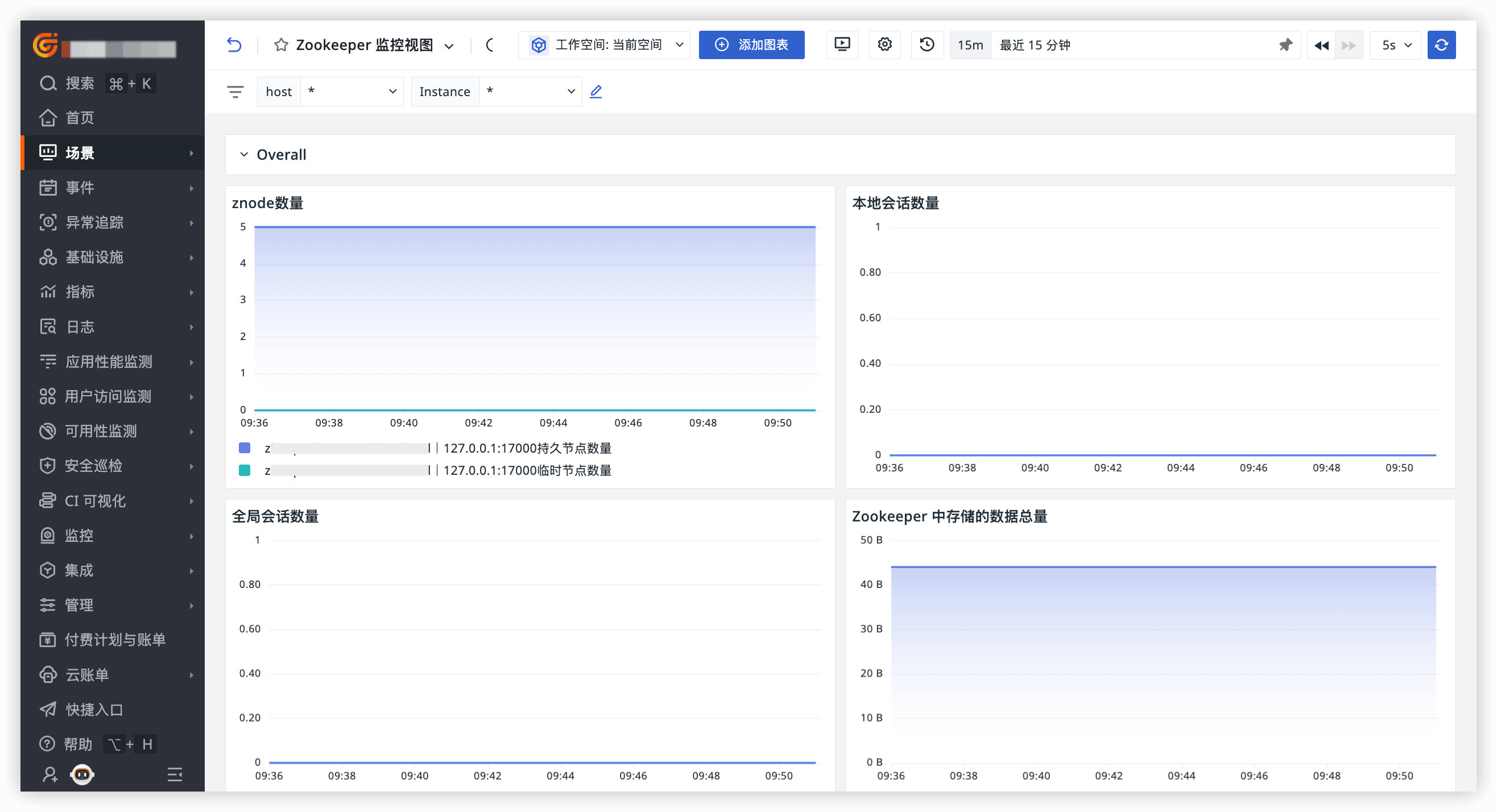
登錄觀測云控制臺,點擊「場景」 -「新建儀表板」,輸入 “Zookeeper”, 選擇 “ Zookeeper”,點擊 “確定” 即可添加視圖。
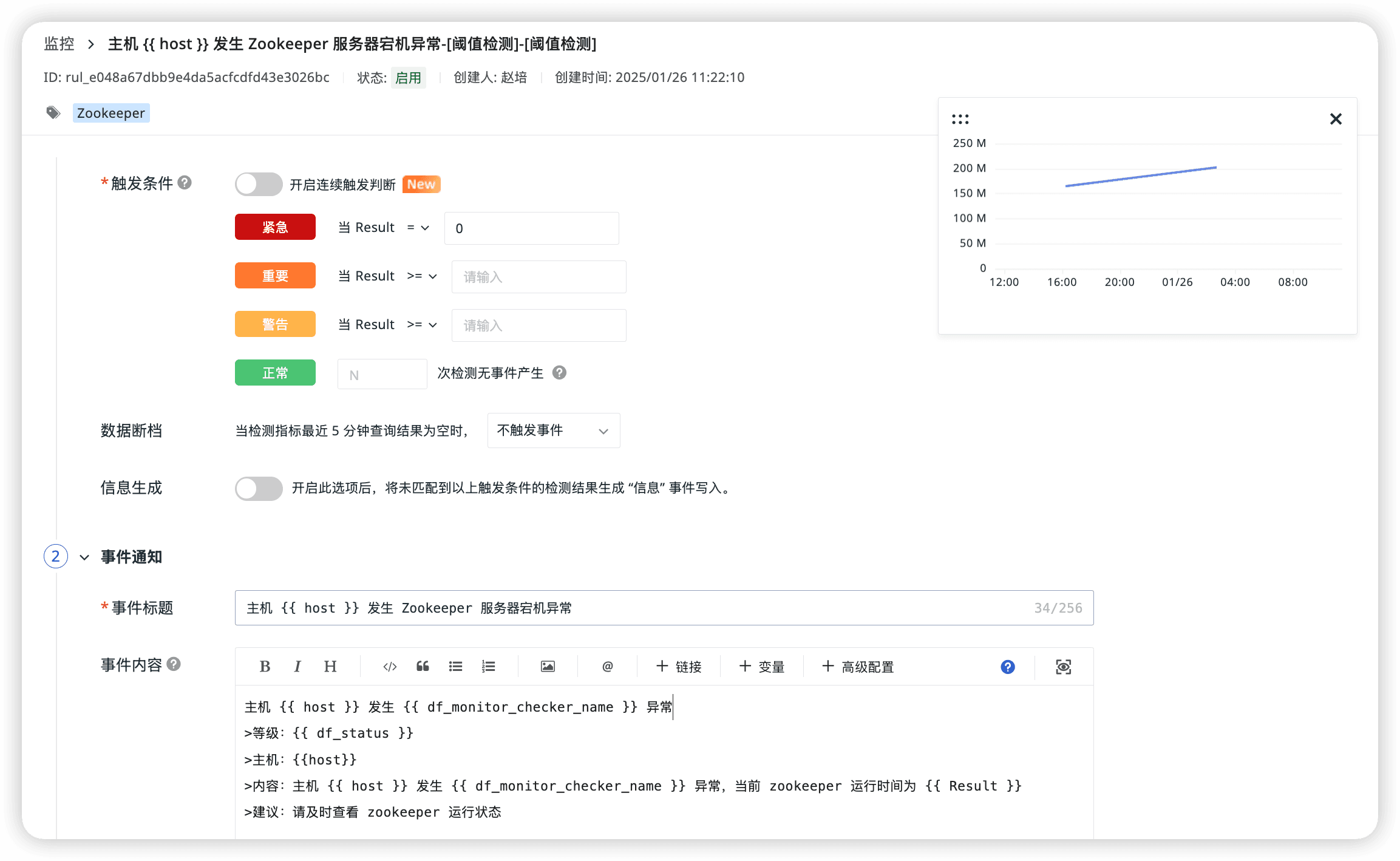
監控器(告警)
Zookeeper 服務器發送宕機異常

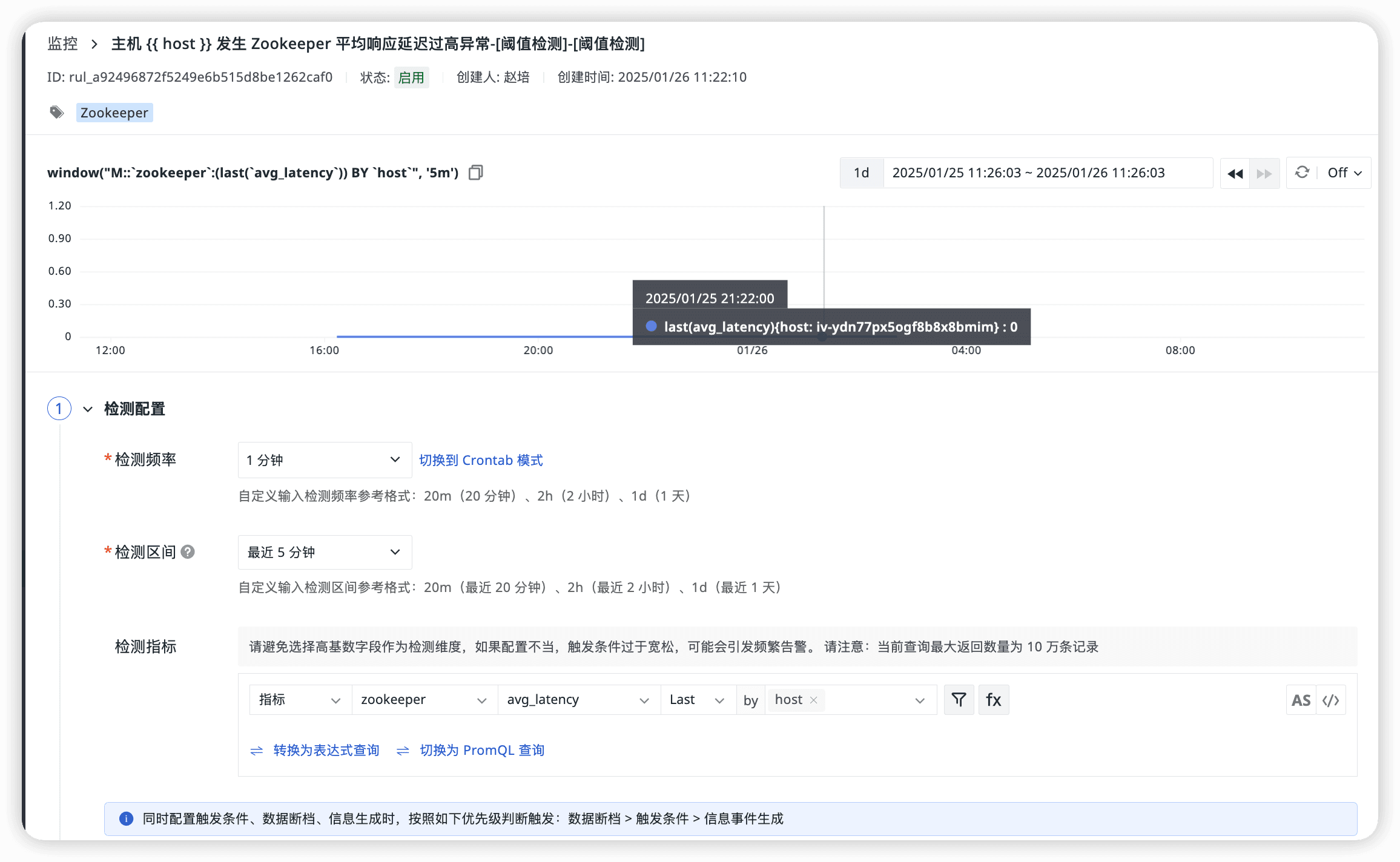
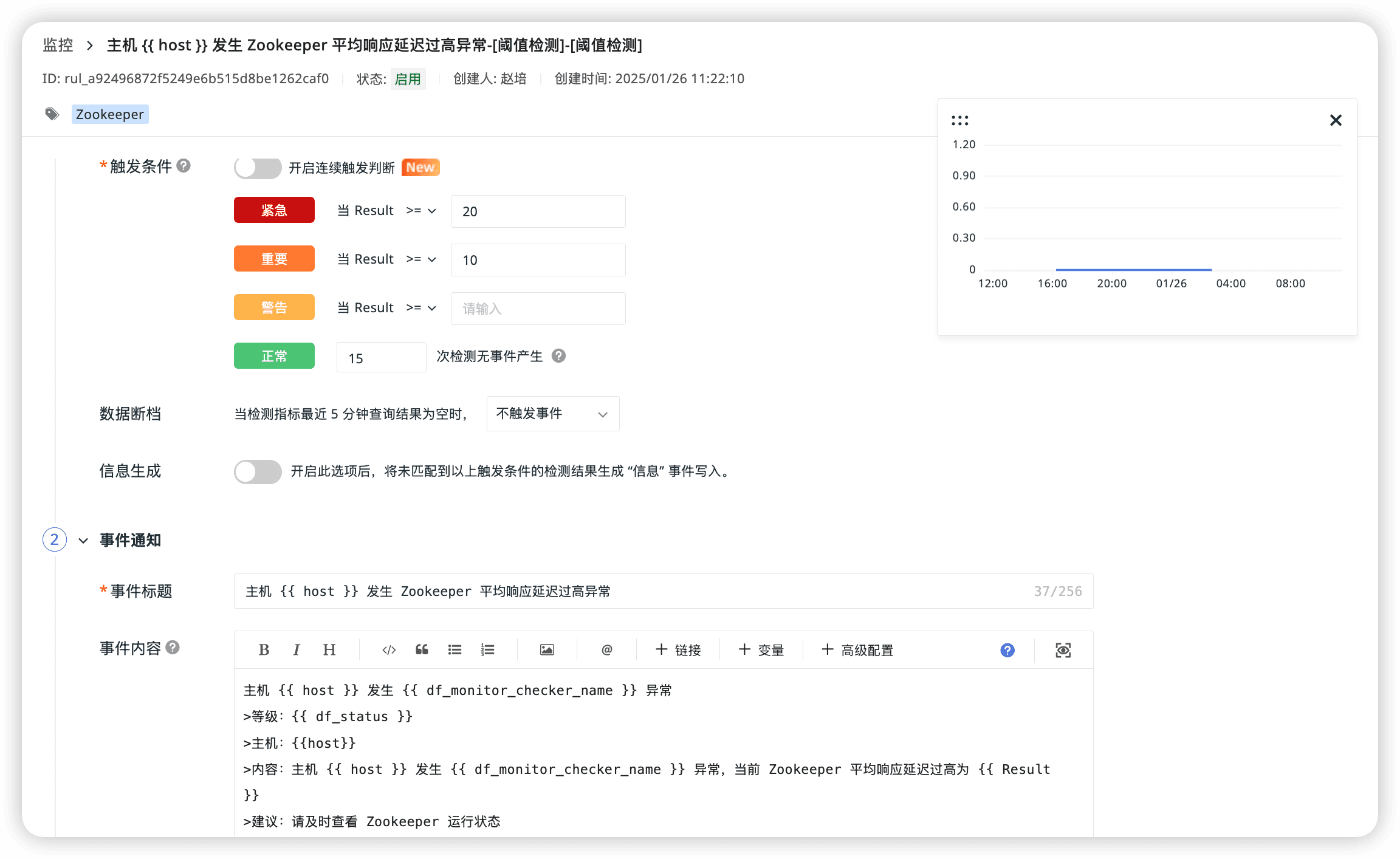
Zookeeper 平均響應延遲過高異常
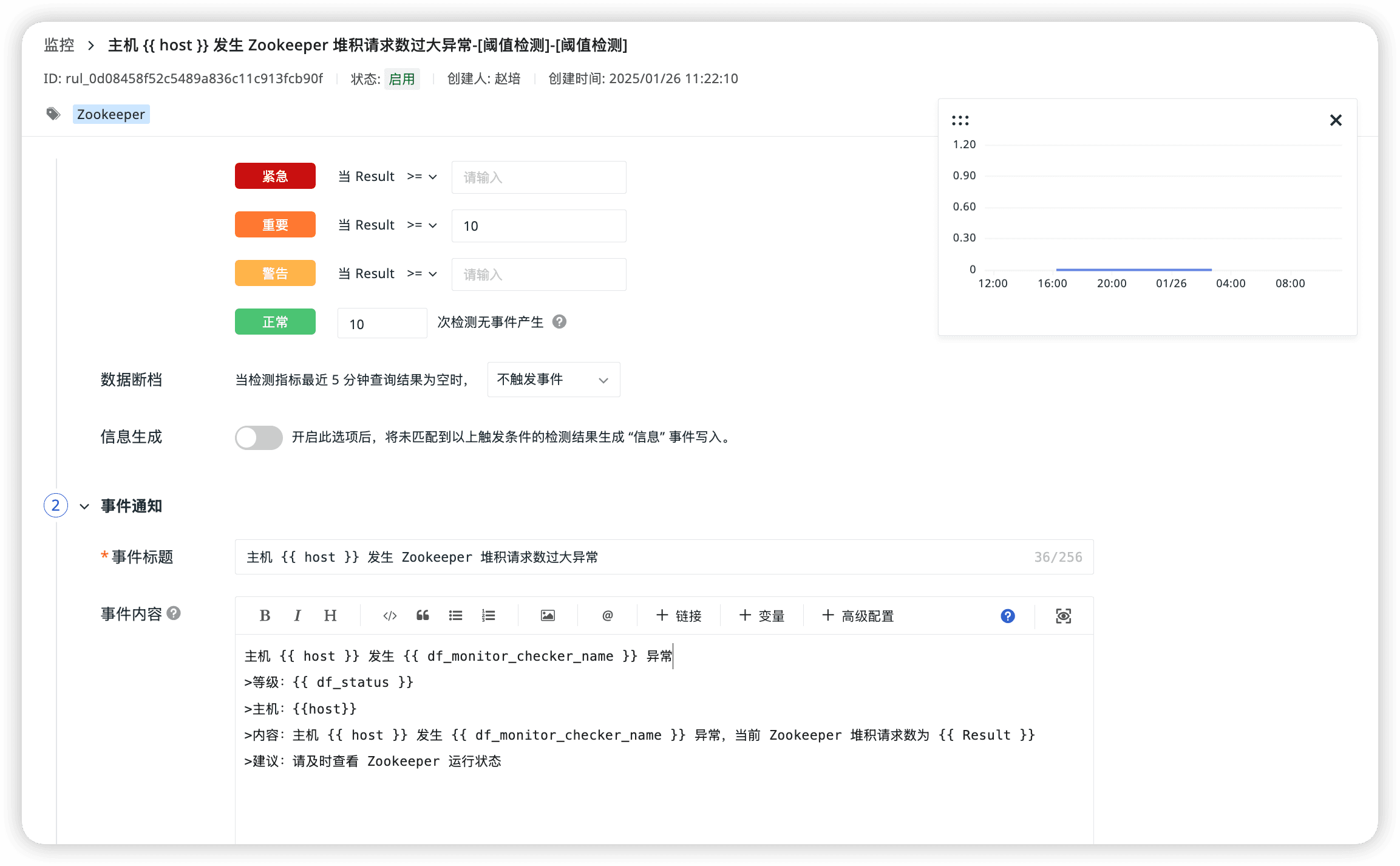
Zookeeper 堆積請求數過大異常

總結
通過使用觀測云平臺對 ZooKeeper 進行統一監控,我們能夠實時追蹤關鍵性能指標,如會話連接數、節點讀寫操作次數、以及會話超時情況。這些指標對于優化 ZooKeeper 集群性能、識別性能瓶頸、及時排查故障至關重要。它們幫助我們優化會話管理策略,確保集群狀態一致性,進行有效的資源規劃,并為分布式協調任務提供支持。這樣的監控不僅增強了用戶體驗,也顯著提高了系統的可靠性和穩定性。




:Rust 內存安全基石詳解)










——系統盤下目錄及文件詳解)



