
1. 引言
在 Amazon EKS(Elastic Kubernetes Service)環境中,理解從 ALB(Application Load Balancer)到 Pod 的完整網絡調用鏈對運維人員至關重要。本文將展示如何利用 Amazon Q CLI 這一 AI 助手工具,通過自然語言交互方式分析這一復雜網絡路徑。
📢限時插播:Amazon Q Developer 來幫你做應用啦!
🌟10分鐘幫你構建智能番茄鐘應用,1小時搞定新功能拓展、測試優化、文檔注程和部署
?快快點擊進入《Agentic Al 幫你做應用 -- 從0到1打造自己的智能番茄鐘》實驗
免費體驗企業級 AI 開發工具的真實效果吧
構建無限,探索啟程!
我們將重點關注外部請求經過 ALB、節點 iptables 規則,最終到達 Pod 的全過程,并演示運維人員如何通過向 Q CLI 提問來獲取網絡分析框架和技術解釋,從而更高效地排查故障和優化性能。
同時,文章也將提供常見網絡問題的解決方案與優化實踐,幫助讀者構建更穩定的 EKS 網絡環境。
2. EKS 與 ALB Ingress 架構及 Amazon Q CLI 介紹
在深入探討網絡調用鏈之前,我們需要了解 Amazon EKS 與 ALB Ingress 的基本架構組件及其交互方式。
2.1 核心組件與數據流
主要組件:
-
Amazon EKS:由亞馬遜云科技管理的控制平面和用戶管理的 EC2 工作節點組成,其中 VPC CNI 插件為 Pod 分配 VPC IP 地址。
-
Amazon Load Balancer Controller:連接 Kubernetes 資源與亞馬遜云科技負載均衡服務的橋梁,自動配置和管理相應的亞馬遜云科技負載均衡器。
網絡模式:
-
Instance 模式:ALB 將流量發送到 EC2 節點的 NodePort,再由節點上的 iptables 規則 DNAT(Destination Network Address Translation)到目標 Pod。這種模式下,源 IP 會被 SNAT 為節點 IP。
-
IP 模式:ALB 直接將流量發送到 Pod IP,繞過了 kube-proxy 和 NodePort,保留了客戶端源 IP。
典型請求流程(Instance 模式):
-
客戶端請求 → ALB
-
ALB 根據監聽器規則 → EC2 節點 NodePort
-
節點 iptables 規則(kube-proxy 管理) → DNAT 到目標 Pod
-
Pod 處理請求并生成響應
-
響應經 SNAT 處理 → ALB → 客戶端
2.2 Amazon Q CLI 介紹與準備工作
在接下來的網絡調用鏈分析中,我們將使用 Amazon Q CLI 作為輔助分析工具。Amazon Q CLI 是亞馬遜云科技提供的一款 AI 助手命令行工具,它能夠通過自然語言交互幫助運維人員理解復雜的亞馬遜云科技環境和網絡路徑。
開始之前,請確保已經在本地電腦安裝了必要的工具:
-
Amazon Q CLI 已安裝并配置,操作說明:安裝適用于命令行的 Amazon Q
-
Amazon CLI 已安裝并配置,操作說明:安裝或更新最新版本的 Amazon CLI
通過 Q 命令進入到與 Amazon Q CLI 的對話中。
Amazon Q CLI 的主要優勢包括:
-
自然語言交互:可以使用自然語言描述問題,無需記憶復雜的命令語法
-
知識庫支持:內置了亞馬遜云科技服務和網絡架構的知識,可以提供專業的解釋和建議
-
上下文感知:能夠理解亞馬遜云科技資源之間的關系,提供連貫的分析視角
-
分析框架提供:針對復雜問題提供分析框架和思路,指導運維人員進行實際操作
通過使用 Amazon Q CLI,運維人員可以更快地理解從 ALB 到 Pod 的網絡調用鏈,提高問題解決效率。
3. 使用 Amazon Q CLI 輔助分析網絡調用鏈
本章將展示運維人員如何使用 Amazon Q CLI 工具輔助分析 EKS 環境中從 ALB 到 Pod 的完整網絡路徑。通過向 Q CLI 提出有針對性的問題,運維人員可以獲得清晰的分析框架和技術解釋,從而更好地理解復雜的網絡路徑。
3.1 從客戶端經由 ALB 到 EC2 節點的流量路
當外部客戶端發起請求時,流量首先到達 Amazon ALB,然后轉發到 EC2 節點。我們可以通過向 Q CLI 提問來分析這個過程:
在 EKS 集群上部署了一個服務,通過 NodePort 的方式由 ALB 暴露給用戶。分析這個場景下 HTTP 請求從客戶端經過 ALB 到達 EC2 節點的完整流程。包括 DNS 解析、TCP 連接和請求處理。請以圖表方式展示。
Q CLI 的分析結果如下:
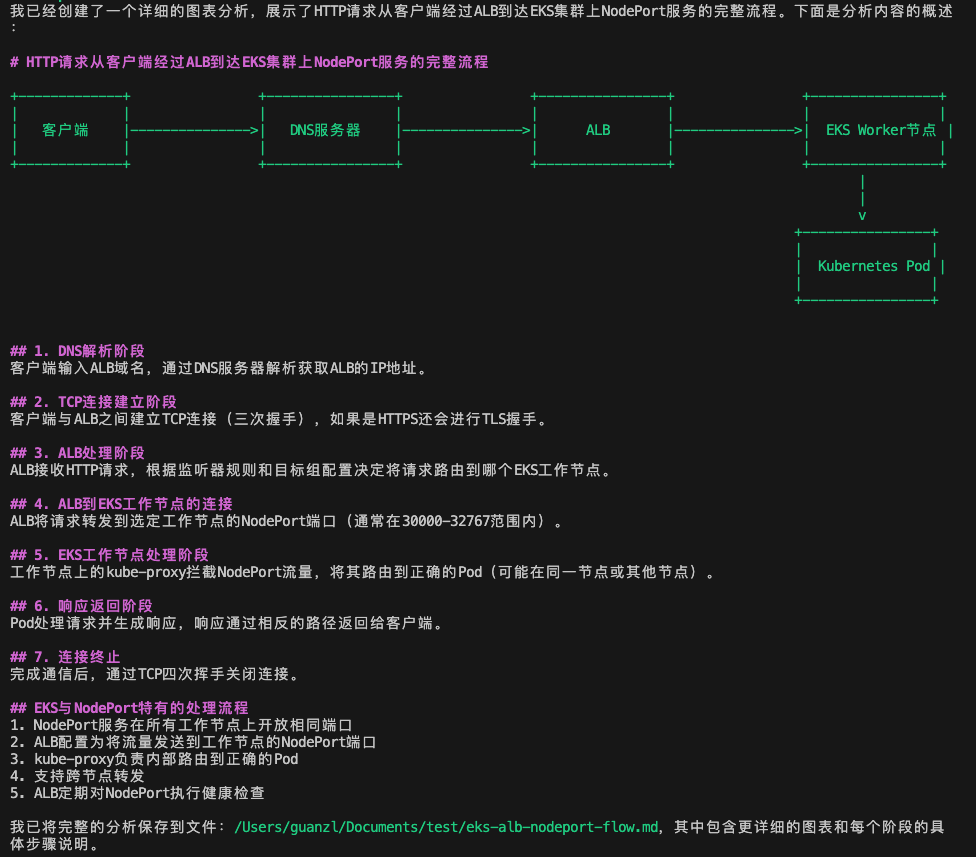
它顯示,這個過程包含以下關鍵步驟:
1、客戶端到 ALB 階段:
-
DNS 解析獲取 ALB 的 IP 地址
-
TCP 三次握手建立連接
-
HTTP 請求發送到 ALB
-
ALB 根據監聽器規則處理請求
2、ALB 到 EC2 節點階段:
-
ALB 根據目標組配置選擇目標 EC2 實例
-
ALB 將請求轉發到 EC2 節點的 NodePort
-
請求通過 VPC 網絡到達 EC2 實例
3.2 節點內部的 iptables 處理機制
當請求到達 EC2 節點的 NodePort 后,節點內部的 iptables 規則負責將流量轉發到正確的 Pod。這是 Kubernetes 網絡模型中最復雜的部分之一。
向 Q CLI 提問:
EKS 節點的 ssh 密鑰是/Users/guanzl/.ssh/masterconn.pem,請連到 EKS cluster zhili-cluster-1 的節點上分析 EKS 節點上的 iptables 規則鏈如何處理從 NodePort 進入的流量,直到轉發到正確的服務 sample-app-service 關聯 Pod。繪制一個完整的規則鏈流程圖,包括從 PREROUTING 到最終的 DNAT。
Q CLI 的分析結果顯示:
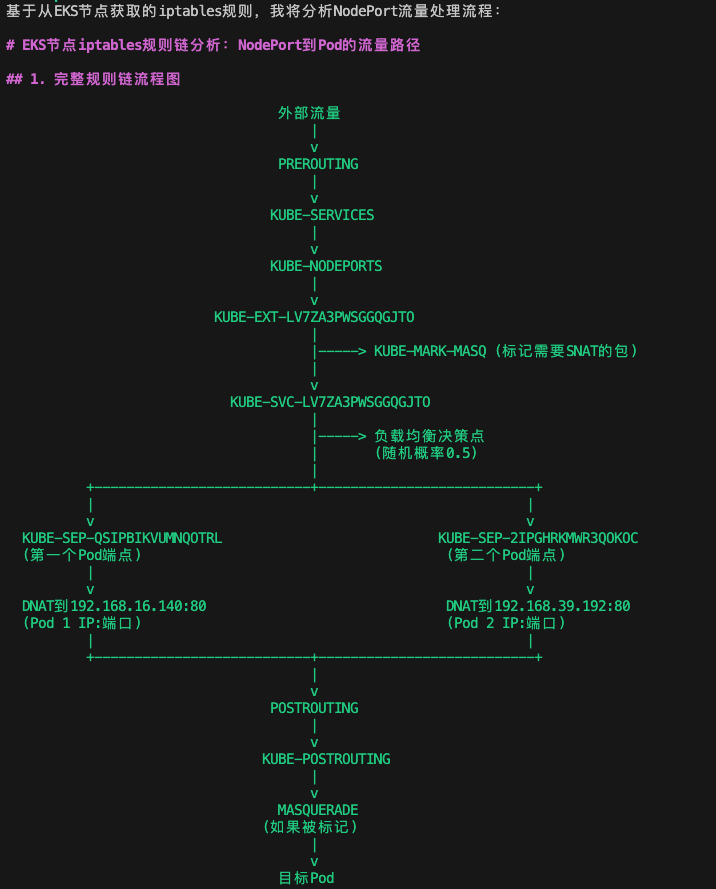
此外,在圖表后 Q CLI 還給出了完整流程總結:
-
流量入口:ALB 將請求發送到 EKS 節點的 31564 端口(NodePort)
-
PREROUTING 處理:流量進入PREROUTING鏈,然后轉發到KUBE-SERVICES鏈
-
NodePort 識別:在 KUBE-SERVICES 鏈中,識別為 NodePort 流量,轉發到 KUBE-NODEPORTS 鏈
-
服務匹配:在 KUBE-NODEPORTS 鏈中,匹配端口 31564,轉發到 KUBE-EXT-LV7ZA3PWSGGQGJTO 鏈
-
標記與轉發:在 KUBE-EXT-LV7ZA3PWSGGQGJTO 鏈中,標記需要 SNAT 的包,并轉發到 KUBE-SVC-LV7ZA3PWSGGQGJTO 鏈
-
負載均衡:在 KUBE-SVC-LV7ZA3PWSGGQGJTO 鏈中,通過隨機概率選擇一個后端 Pod
-
DNAT 轉換:在選定的 Pod端點鏈(KUBE-SEP-QSIPBIKVUMNQOTRL或KUBE-SEP-2IPGHRKMWR3QOKOC)中,執行 DNAT,將目標地址轉換為 Pod 的 IP 和端口
-
SNAT 處理:在 POSTROUTING 鏈中,對標記的包執行 SNAT,確保返回流量能正確路由
這個過程中,特別值得注意的是 KUBE-SVC 鏈中的負載均衡機制:
-A KUBE-SVC-XXX -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-1
-A KUBE-SVC-XXX -j KUBE-SEP-2這種基于概率的負載均衡在高流量場景下可能導致分布不均,是后續優化的重點之一。
3.3 Pod 通信與響應返回路徑
經過 iptables 的 DNAT 處理后,數據包需要從節點網絡棧到達目標 Pod,處理完成后再返回客戶端。這個雙向過程涉及多個網絡組件的協同工作。向 Q CLI 提問:
“分析數據包經過 iptables DNAT 后如何到達目標 Pod,以及響應如何返回客戶端。”
Q CLI 的分析結果顯示:
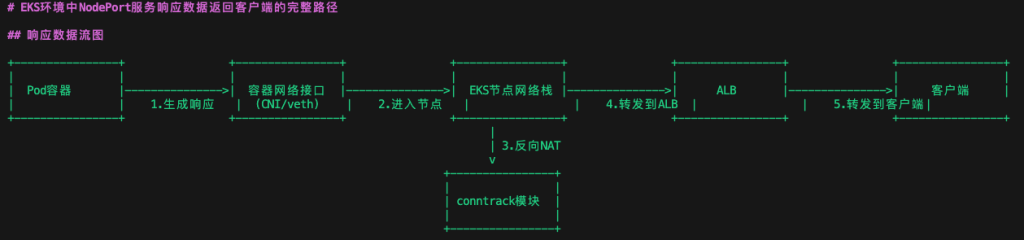
1、DNAT 后,數據包到達 Pod 的路徑:
-
DNAT 轉換:數據包經過 iptables 的 DNAT 規則,目標地址被修改為 Pod 的 IP 和端口
-
路由決策:內核根據新的目標地址重新進行路由決策
-
網絡轉發:數據包轉發到目標 Pod
-
連接跟蹤:內核的 conntrack 模塊記錄連接信息,包括原始地址和轉換后地址
-
到達 Pod:數據包最終到達 Pod 的網絡命名空間,被應用程序接收處理
2、響應返回的路徑:
-
Pod 生成響應數據包,此時源地址為 Pod IP,目標為客戶端 IP
-
響應數據包離開 Pod 網絡命名空間,進入節點網絡棧
-
conntrack 模塊自動進行反向 NAT,將源地址從 Pod IP 改回服務 IP(如 NodePort 對應的地址和端口)
-
數據包通過節點網卡發送到 ALB
-
ALB 將響應轉發給原始客戶端
這個過程中,Linux 內核的 conntrack 模塊起著至關重要的作用,它維護了 NAT 轉換的狀態表,確保響應數據包能夠正確返回。
3.4 conntrack 連接跟蹤狀態分析
conntrack 模塊是 Linux 網絡棧的核心組件,對于理解 NAT 環境中的連接狀態至關重要。
向 Q CLI 提問:
“分析 Linux conntrack 模塊在 Kubernetes 服務網絡中的作用。”
Q CLI 的分析指出:
1、連接狀態跟蹤。conntrack 維護了所有網絡連接的狀態表,記錄了每個連接的詳細信息,這使得 Linux 內核能夠了解哪些數據包屬于已建立的連接,哪些是新連接請求。
-
源 IP:端口和目標 IP:端口
-
協議類型(TCP/UDP/ICMP 等)
-
連接狀態(NEW, ESTABLISHED, RELATED, INVALID 等)
-
連接超時時間
2、支持 NAT 功能。在 Kubernetes 中,conntrack 為 kube-proxy 的 iptables 模式提供了關鍵支持。沒有 conntrack,Kubernetes 的 Service 網絡模型將無法正常工作。
-
當請求通過 Service IP 訪問后端 Pod 時,iptables 執行 DNAT 操作
-
conntrack 記錄這個 NAT 映射關系
-
當 Pod 返回響應時,conntrack 自動執行反向 NAT,確保數據包能正確返回客戶端
3、會話保持與負載均衡。conntrack 確保來自同一客戶端的連續請求能夠被路由到同一 Pod,提供會話親和性。這對于有狀態應用尤為重要。
4、潛在挑戰
-
表容量限制:高流量環境可能導致 conntrack 表滿,新連接被丟棄
-
連接粘性:Service 更新 selector 后,已有連接仍會路由到舊 Pod
-
性能開銷:大量連接時可能成為性能瓶頸
通過使用 Amazon Q CLI 輔助分析,運維人員可以更快地理解 EKS 網絡調用鏈的復雜機制,獲得分析思路和排查方向,從而提高問題解決效率。Q CLI 提供的分析框架和技術解釋,結合實際的命令驗證,為運維工作提供了有力支持。
4. 常見問題與優化實踐
在 EKS 環境中運行生產級應用時,我們可能會遇到各種網絡相關的挑戰。本章將深入探討四個常見問題,分析其根本原因,并提供實用的解決方案和優化建議。
4.1 Pod負載不均衡
4.1.1 問題描述
EKS 的 kube-proxy 默認使用 iptables 模式。基于前文對網絡調用鏈的分析,我們了解到 iptables 模式下流量是基于固定概率分配的。這種機制存在幾個明顯的局限性:
-
連接級別的隨機性:負載均衡在連接級別,導致短連接場景下分布不均
-
忽略實際負載狀態:分配機制沒有考慮 Pod 的實際負載、連接數或處理能力
-
連接持久性問題:長連接可能導致某個 Pod 長時間”粘住”大量請求
這些限制在高并發或短連接場景下尤為明顯,可能出現某些 Pod 被“打爆”,而其他幾乎空閑的現象,形成嚴重的負載傾斜。
4.1.2 優化策略
如果在 EKS 上遇到負載傾斜問題,可以考慮切換到 IPVS(IP Virtual Server) 模式:將 kube-proxy 配置為 IP Virtual Server (IPVS) 模式,相比 iptables 模式有以下優勢:
-
使用哈希表而非線性搜索處理數據包,性能更高
-
提供多種負載均衡算法,如 Round Robin,Weighted Round Robin 等。
4.2 連接跟蹤表溢出
4.2.1 問題癥狀
在 EKS 集群高流量場景下,節點可能出現連接跟蹤表(conntrack)溢出的情況,表現為:
-
間歇性的連接超時或請求被拒絕
-
系統日志中出現”nf_conntrack: table full, dropping packet”錯誤
-
更新 Service 的 selector 后,流量仍然導向舊的 Pod 長達幾十秒
4.2.2 問題原因
EKS 節點使用 Linux 內核的 conntrack 模塊跟蹤所有網絡連接狀態。當連接數超過 net.netfilter.nf_conntrack_max 設置的最大值時,新的連接會被丟棄。默認配置通常不足以應對高流量生產環境。
4.2.3 診斷方法
可通過以下命令診斷 conntrack 表狀態:
# 查看當前conntrack表使用情況
sudo sysctl net.netfilter.nf_conntrack_count
# 查看最大conntrack表大小
sudo sysctl net.netfilter.nf_conntrack_max
# 檢查是否有溢出日志
sudo dmesg | grep conntrack4.2.4 優化策略
針對 conntrack 表溢出問題,可以采取以下優化措施:
1、增加 conntrack 表容量:
# 臨時修改
sudo sysctl -w net.netfilter.nf_conntrack_max=1048576
sudo sysctl -w net.netfilter.nf_conntrack_buckets=262144
# 永久修改
echo 'net.netfilter.nf_conntrack_max=1048576' | sudo tee -a /etc/sysctl.conf
echo 'net.netfilter.nf_conntrack_buckets=262144' | sudo tee -a /etc/sysctl.conf2、優化 conntrack 超時設置:
# 已建立連接的超時時間
sudo sysctl -w net.netfilter.nf_conntrack_tcp_timeout_established=86400
# TIME_WAIT 狀態的超時時間(默認 120 秒,可減少)
sudo sysctl -w net.netfilter.nf_conntrack_tcp_timeout_time_wait=303、定期清理 conntrack 表
# 例如清除特定服務端口的 conntrack 記錄
sudo conntrack -D -p tcp --dport <service-port>4.3 滾動更新期間出現 5xx 錯誤
4.3.1 問題描述
在 EKS 環境中,使用 Amazon Load Balancer Controller 的應用在滾動更新期間出現 502 Bad Gateway 或 504 Gateway Timeout 錯誤。這一現象在使用 target-type: ip 模式(ALB 直接路由到 Pod IP)時尤為明顯。
4.3.2 問題分析
這些 5xx 錯誤本質上是由 Amazon ALB 控制面與數據面之間的異步更新機制,以及 Kubernetes Pod 終止過程的時序不匹配導致的。具體流程如下:
-
滾動更新開始,Kubernetes 向舊 Pod 發送 SIGTERM 信號,啟動終止序列
-
Amazon Load Balancer Controller 檢測到 Pod 終止事件,向 ALB 控制面發送目標注銷請求
-
ALB 控制面將目標標記為 “draining” 狀態,但這一狀態變更需要時間傳播到所有 ALB 數據面節點
-
在這個傳播窗口期(通常為幾秒到幾十秒),ALB 數據面節點仍可能將新請求路由到正在終止的 Pod
-
此時 Pod 可能已關閉其監聽端口或終止應用進程,導致請求失敗并觸發 ALB 返回 502/504 錯誤
4.3.3 優化策略
可以采取以下措施來緩解這個問題。
1、給容器添加 preStop 鉤子延遲,這會在 Pod 終止前增加一個延遲,給負載均衡器足夠的時間將目標標記為排空狀態并停止發送新請求。
lifecycle:preStop:exec:command: [ "sh", "-c", "sleep 30" ]2、設置 terminationGracePeriodSeconds。這為 Pod 提供了更長的”優雅退出”時間,確保有足夠的時間處理現有請求并完成清理工作。
3、減少 ALB 的注銷延遲。加快目標從 ALB 目標組中移除的速度。
annotations:alb.ingress.kubernetes.io/target-group-attributes: deregistration_delay.timeout_seconds=304、啟用 Pod Readiness Gates。確保 Pod 只有在成功注冊到 ALB 目標組后才被標記為就緒,同樣,只有在成功從 ALB 目標組中注銷后才會被終止。
kubectl label namespace <your_namespace> elbv2.k8s.aws/pod-readiness-gate-inject=enabled4.4 Service 更新 selector 后流量延遲切換問題
4.4.1 問題描述
當用戶部署了新的 deployment 并通過更新 Service 的 pod selector 切換到新 deployment 時,會出現一個持續數秒到數分鐘的時間窗口,流量仍然會導向舊的 Pod,導致應用行為不一致或錯誤。這個問題在高并發環境中尤為明顯。
4.4.2 問題原因
這是因為當更新 Service 的 selector 時,kube-proxy 更新 iptables 規則,但 Linux 內核的 conntrack 模塊會保持現有的連接記錄,直到這些連接超時或被顯式清除。這些保持的連接狀態會導致已建立的流量繼續被發送到舊的 Pod。
4.4.3 優化策略
針對這個問題,可以采取以下策略:
-
停止舊 Deployment 斷開 conntrack 中的連接
-
主動清除 EKS 節點上相關的 conntrack 表項
-
藍綠部署策略。創建新的 Service 指向新的 deployment,并更新 Ingress 指向新的 Service。這種方法避免了修改現有 Service,而是創建新的 Service 并更新入口層配置,完全繞過了 conntrack 連接粘性問題。
5. 總結
本文深入分析了 Amazon EKS 環境中 ALB Ingress Controller 的 Instance 模式網絡調用鏈,從外部請求到內部 Pod 的完整流程。此外,我們還分析了四個常見網絡問題及響應的優化策略。
通過理解這些網絡機制,您可以更有效地排查 EKS 環境中的網絡問題,優化應用性能,并設計更健壯的云原生架構,為構建穩定高效的 Kubernetes 應用提供技術支持。
*前述特定亞馬遜云科技生成式人工智能相關的服務僅在亞馬遜云科技海外區域可用,亞馬遜云科技中國僅為幫助您了解行業前沿技術和發展海外業務選擇推介該服務。
本篇作者
本期最新實驗為《Agentic AI 幫你做應用 —— 從0到1打造自己的智能番茄鐘》
? 自然語言玩轉命令行,10分鐘幫你構建應用,1小時搞定新功能拓展、測試優化、文檔注釋和部署
💪 免費體驗企業級 AI 開發工具,質量+安全全掌控
??[點擊進入實驗] 即刻開啟 AI 開發之旅
構建無限, 探索啟程!








)










