概述
三維點云異常檢測旨在從訓練集中檢測出異常數據點,是工業檢測、自動駕駛等眾多應用的基礎。然而,現有的點云異常檢測方法通常采用多個特征存儲庫來充分保留局部和全局特征表示,這帶來了高昂的計算成本以及特征之間的不匹配問題。為解決這些問題,我們提出了一種基于聯合局部 - 全局特征的無監督點云異常檢測框架PointCore。具體而言,PointCore僅需一個存儲庫來存儲局部(坐標)和全局(PointMAE)特征表示,并為這些局部 - 全局特征分配不同的優先級,從而降低推理過程中的計算成本和不匹配干擾。此外,為了增強對異常值的魯棒性,我們引入了一種歸一化排序方法,不僅可以將不同尺度的值調整到一個統一的尺度,還能將密集分布的數據轉換為均勻分布。在Real3D - AD數據集上進行的大量實驗表明,與最先進的Reg3D - AD方法及其他幾種競爭方法相比,PointCore在推理時間上具有競爭力,并且在檢測和定位方面均取得了最佳性能。
論文地址:https://arxiv.org/html/2403.01804v1
一、引言
異常檢測旨在找出產品的異常區域,在工業質量檢測、自動駕駛等多個領域發揮著重要作用。當前的異常檢測方法大多是無監督的,主要針對二維圖像,這些模型通常在具有成熟架構的圖像上進行訓練。對于基于三維點云的異常檢測任務,目前相關文獻的研究還相對較少。與二維圖像相比,三維點云具有更豐富的結構信息,但同時也存在無序、高度稀疏和分布不規則的問題。為了有效地處理點云數據,人們應用了各種不同尺度的手工制作或基于深度學習的特征描述符。
最近,出現了一個大規模、高分辨率的三維異常檢測數據集Real3D - AD。Real3D - AD數據集中的物體分辨率為0.001mm - 0.0015mm,具有360度覆蓋范圍和完美的原型。在相關研究中,作者將圖像異常檢測中的PatchCore方法應用于點云異常檢測,并開發了一種基于通用配準的點云異常檢測器Reg3D - AD。Reg3D - AD采用雙特征表示方法來保留訓練原型的局部和全局特征,檢測精度較高,但推理速度較慢。目前的點云異常檢測器主要可分為兩類:
(1)基于重建的方法,這類方法通過自動編碼器重建輸入的點云數據,并通過比較原始數據和重建數據之間的偏差來識別異常。然而,這些方法對點云分辨率較為敏感,導致推理速度較慢且精度較差。
(2)基于存儲庫的方法,存儲庫可用于存儲代表性特征,以隱式構建正態分布并查找分布外的缺陷。與前者相比,直接使用預訓練的特征提取器構建存儲庫訓練速度快,且不受點云分辨率的影響。除此之外,現有的點云異常檢測器通常采用多個特征存儲庫來充分保留局部和全局特征表示,這帶來了高昂的計算成本以及特征之間的不匹配問題。
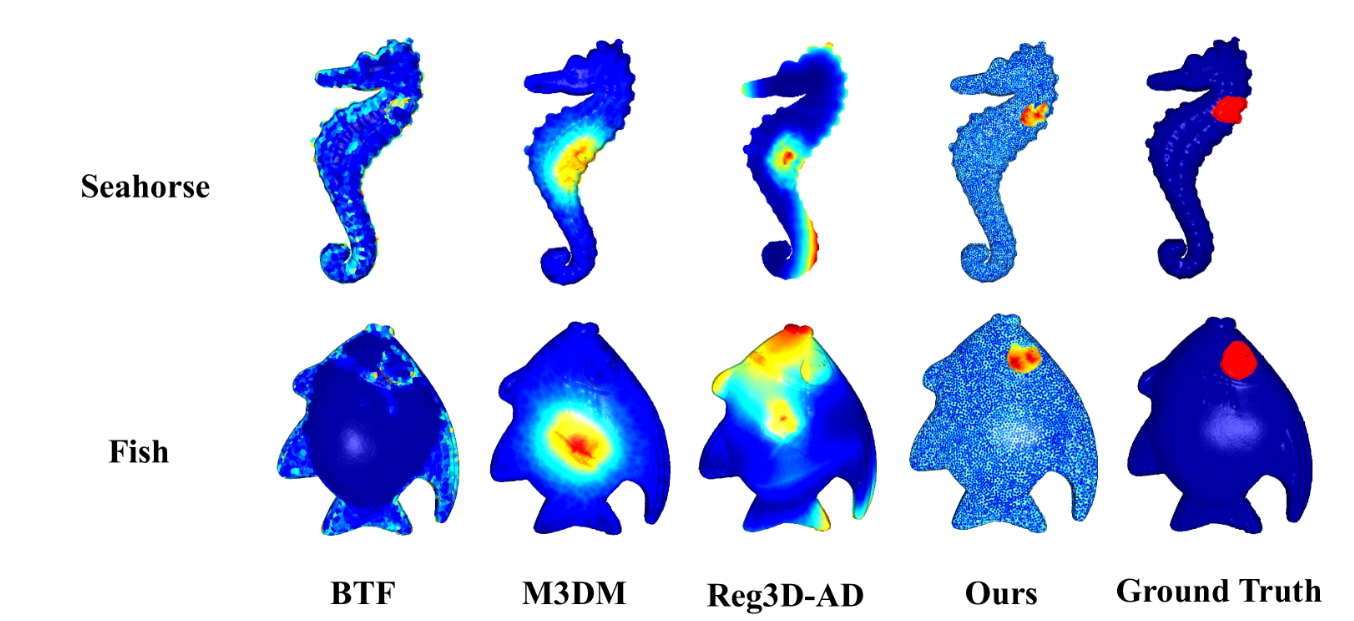
圖1:幾種方法在Real3D - AD數據集上獲得的異常得分熱圖。從可視化結果可以看出,與其他方法相比,本文提出的方法能夠更準確地檢測和定位異常數據點。
為解決上述問題,我們提出了一種基于聯合局部 - 全局特征的無監督點云異常檢測框架PointCore。具體而言,我們的貢獻總結如下:
- PointCore僅需一個存儲庫來存儲局部 - 全局特征表示,并為這些局部 - 全局特征分配不同的優先級,以降低推理過程中的計算成本和不匹配干擾。
- 我們提出了一種基于排序的歸一化方法,以消除各種異常得分之間的分布差異,并應用點到平面迭代最近點(point - plane ICP)算法對 點云配準結果進行局部優化,從而做出更可靠的決策。
- 在Real3D - AD數據集上進行的大量實驗表明,與最先進的Reg3D - AD方法及其他幾種競爭方法相比,PointCore在推理時間上具有競爭力,并且在檢測和定位方面均取得了最佳性能。
二、方法
2.1 全局和局部配準
與Reg3D - AD模型類似,我們應用快速點特征直方圖(FPFH)特征描述符和隨機抽樣一致性(RANSAC)算法來實現點云的全局配準。為了增強點云配準的穩定性,引入了點到平面迭代最近點(point - plane ICP)算法對全局配準的輸出進行局部優化。假設需要配準兩個點云 X s X_{s} Xs?(源點云)和 x t x_{t} xt?(目標點云),具體步驟如下:
- 應用從全局配準獲得的旋轉矩陣和平移向量對 X s X_{s} Xs?進行變換。
- 在 x t x_{t} xt?中搜索與 X s X_{s} Xs?中 p i p_{i} pi?距離最近的點 q i q_{i} qi?,其中 q i q_{i} qi?的法向量記為 n i n_{i} ni?。
- 假設最優旋轉歐拉角 α \alpha α, β \beta β, γ \gamma γ趨近于0,此時 cos ? ( θ ) → 1 \cos(\theta)\to1 cos(θ)→1, sin ? ( θ ) → 0 \sin(\theta)\to0 sin(θ)→0, θ → 0 \theta\to0 θ→0。旋轉矩陣 R R R可近似表示為: R ≈ [ 1 ? γ β γ 1 ? α ? β α 1 ] R \approx\left[\begin{array}{ccc}1 & -\gamma & \beta \\ \gamma & 1 & -\alpha \\ -\beta & \alpha & 1\end{array}\right] R≈ ?1γ?β??γ1α?β?α1? ?
- 假設最優平移向量為 t = [ t x , t y , t z ] t=[t_{x}, t_{y}, t_{z}] t=[tx?,ty?,tz?] 。通過摩爾 - 彭羅斯逆將損失函數表示為最小二乘問題: E ( R , t ) = ∑ i = 1 n ( ( R p i + t ? q i ) T n i ) 2 E(R, t)=\sum_{i=1}^{n}\left(\left(R p_{i}+t-q_{i}\right)^{T} n_{i}\right)^{2} E(R,t)=i=1∑n?((Rpi?+t?qi?)Tni?)2
- 應用計算得到的旋轉矩陣和平移向量對 X s X_{s} Xs?進行變換,并重復步驟2 - 5,直到損失值低于預定義的閾值。需要注意的是,用于配準的目標點云 X t X_{t} Xt?是固定的。
2.2 存儲庫構建
- 坐標采樣:我們采用貪心下采樣算法對 點云進行采樣。給定 點云 X X X和點集 C a C_{a} Ca?( α \alpha α為 C a C_{a} Ca?中的點數),我們的目標是從 C a C_{a} Ca?中獲取 S m a x S_{max} Smax?個均勻分布的點。具體步驟如下:
- 從 C a C_{a} Ca?中隨機選擇 S i n i t S_{init} Sinit?個點構建初始點集 P i n i t = P 1 , P 2 , P 3 , … , P S i n i t P_{init }={P_{1}, P_{2}, P_{3}, \ldots, P_{S_{init }}} Pinit?=P1?,P2?,P3?,…,PSinit?? 。
- 計算 C a C_{a} Ca?與 P i n i t P_{init } Pinit?之間的距離,得到一個維度為 a × S i n i t a×S_{init } a×Sinit?的矩陣 d 2 d d_{2d} d2d? : d 2 d = [ d 11 ? d 1 S m a x ? ? ? d a 1 ? d a S m i n ] d_{2d}=\left[\begin{array}{ccc} d_{11} & \cdots & d_{1 S_{max }} \\ \vdots & \ddots & \vdots \\ d_{a 1} & \cdots & d_{a S_{min }}\end{array}\right] d2d?= ?d11??da1??????d1Smax???daSmin??? ?
- 計算矩陣 d 2 d d_{2d} d2d?每一行的平均值,得到 d 1 d = [ d 1 m a n , d 2 m a n ? , d a m a n ] d_{1d}=[d_{1_{man }}, d_{2_{man }} \cdots, d_{a_{man }}] d1d?=[d1man??,d2man???,daman??] 。
- 找到矩陣 d 1 d d_{1d} d1d?中的最大值,并將對應的點添加到 P i n i t P_{init } Pinit?中。重復步驟2 - 4,直到 P i n i t P_{init } Pinit?中的元素數量等于 S m a x S_{max} Smax?。
- 點特征插值:我們使用在ShapeNet數據集上預訓練的點變換器(PointMAE)作為三維特征提取器。對于每個點云,我們將坐標采樣階段得到的坐標作為組中心點。每個中心點形成一個存儲元素,將其與坐標和PointMAE特征綁定。這些元素構成了圖2中的存儲庫。為了降低推理過程中計算PointMAE特征的計算復雜度,需要對 點云坐標進行下采樣。因此,我們進一步進行點特征插值,為特征庫中的每個坐標分配一個PointMAE特征值。特征插值方法如圖3所示。
給定包含所有中心點坐標的點集 P c e n t r a l P_{central } Pcentral?,其對應的PointMAE特征集為 M i n i t M_{init } Minit? 。以一個非中心點 P e P_{e} Pe?為例,我們使用k近鄰算法在點集 P c e n t r a l P_{central } Pcentral?中獲取三個最近鄰點 [ P k 1 , P k 2 , P k 3 ] [P_{k1}, P_{k2}, P_{k3}] [Pk1?,Pk2?,Pk3?] 。它們對應的歐氏距離和PointMAE特征值分別為 [ D k 1 , D k 2 , D k 3 ] [D_{k1}, D_{k2}, D_{k3}] [Dk1?,Dk2?,Dk3?]和 [ M k 1 , M k 2 , M k 3 ] [M_{k1}, M_{k2}, M_{k3}] [Mk1?,Mk2?,Mk3?] 。通過公式(3),我們可以得到 P e P_{e} Pe?的PointMAE特征 M e M_{e} Me? 。重復此過程,直到所有非中心點都獲得其對應的PointMAE特征。 M e M_{e} Me?的計算公式為: M e = D k 1 D k 2 M k 3 + D k 1 D k 3 M k 2 + D k 2 D k 3 M k 1 D k 1 D k 2 + D k 1 D k 3 + D k 2 D k 3 M_{e}=\frac{D_{k1} D_{k2} M_{k3}+D_{k1} D_{k3} M_{k2}+D_{k2} D_{k3} M_{k1}}{D_{k1} D_{k2}+D_{k1} D_{k3}+D_{k2} D_{k3}} Me?=Dk1?Dk2?+Dk1?Dk3?+Dk2?Dk3?Dk1?Dk2?Mk3?+Dk1?Dk3?Mk2?+Dk2?Dk3?Mk1??
2.3 推理模塊
- 多特征異常得分計算:存儲庫由元素集組成,即 M t r a i n = { ( M 1 c , l M 1 p ) , ( M 2 c , M 2 p ) , … , ( M n c , M n p ) } M_{train }=\{(M_{1_{c}}, l M_{1_{p}}),(M_{2_{c}}, M_{2_{p}}), \ldots,(M_{n_{c}}, M_{n_{p}})\} Mtrain?={(M1c??,lM1p??),(M2c??,M2p??),…,(Mnc??,Mnp??)} ,其中 M i c M_{i_{c}} Mic??表示第 i i i個點的坐標, M i p M_{i_{p}} Mip??表示第 i i i個點的PointMAE特征。測試特征庫定義為 F t e s t = { ( F 1 c , F 1 p ) , ( F 2 c , F 2 p ) , … , ( F m c , F m p ) } F_{test }=\{(F_{1_{c}}, F_{1_{p}}),(F_{2_{c}}, F_{2_{p}}), \ldots,(F_{m_{c}}, F_{m_{p}})\} Ftest?={(F1c??,F1p??),(F2c??,F2p??),…,(Fmc??,Fmp??)} ,其中 F j c F_{j_{c}} Fjc??是第 j j j個點的坐標, F j p F_{j_{p}} Fjp??是第 j j j個點的PointMAE特征。對于 F t e s t F_{test } Ftest?中的一個元素 ( F j c , F j p ) (F_{j_{c}}, F_{j_{p}}) (Fjc??,Fjp??) ,我們使用其坐標信息 F j c F_{j_{c}} Fjc??在 M t r a i n M_{train } Mtrain?中找到三個最近鄰點,記為 ( M i c , M i p ) (M_{i_{c}}, M_{i_{p}}) (Mic??,Mip??) , ( M o c , M o p ) (M_{o_{c}}, M_{o_{p}}) (Moc??,Mop??) , ( M u c , M u p ) (M_{u_{c}}, M_{u_{p}}) (Muc??,Mup??) 。使用歐氏距離,得到它們的坐標距離 { D C 1 , D C 2 , D C 3 } \{DC_{1}, DC_{2}, DC_{3}\} {DC1?,DC2?,DC3?}和特征距離 { D P 1 , D P 2 , D P 3 } \{DP_{1}, DP_{2}, DP_{3}\} {DP1?,DP2?,DP3?} 。最終的坐標異常得分 S c = m e a n ( D C 1 , D C 2 , D C 3 ) S_{c}= mean(DC_{1}, DC_{2}, DC_{3}) Sc?=mean(DC1?,DC2?,DC3?),PointMAE異常得分 S p = m i n ( D P 1 , D P 2 , D P 3 ) S_{p}=min (DP_{1}, DP_{2}, DP_{3}) Sp?=min(DP1?,DP2?,DP3?) 。
- 排序模塊:由于兩種異常得分在尺度和分布上存在差異,因此需要對它們進行歸一化處理。傳統的歸一化方法通常采用區間縮放法。對于一組數據 S l i s t S_{list } Slist?,區間縮放過程為 S n o r m = S l i s t ? m i n ( S l i s t ) m a x ( S l i s t ) ? m i n ( S l i s t ) S_{norm }=\frac{S_{list }-min (S_{list })}{max (S_{list })-min (S_{list })} Snorm?=max(Slist?)?min(Slist?)Slist??min(Slist?)? 。如圖4所示,區間縮放法可以消除兩種異常得分之間的尺度差異,但無法解決分布差異問題。當坐標異常得分存在兩個異常值時,最終的異常得分會遠小于PointMAE異常得分,這對基于算術運算的集成策略有顯著影響。為解決這一問題,我們設計了一種基于排序的歸一化方法,其中 S o r t _ r a n k ( S l i s t ) Sort\_rank (S_{list }) Sort_rank(Slist?)用于獲取 S l i s t S_{list } Slist?中每個值的排名, l e n ( S l i s t ) len(S_{list }) len(Slist?)是 S l i s t S_{list } Slist?的長度,即: S n o r m = S o r t _ r a n k ( S l i s t ) l e n ( S l i s t ) S_{norm }=\frac{ Sort\_rank \left(S_{list }\right)}{len\left(S_{list }\right)} Snorm?=len(Slist?)Sort_rank(Slist?)?
三、實驗
3.1 實驗細節
- 數據集:Real3D - AD數據集總共包含1254個樣本,分布在12個不同的類別中。每個特定類別的訓練集僅包含四個樣本,類似于二維異常檢測中的少樣本場景。這些類別包括飛機、糖果棒、雞肉、鉆石、鴨子、魚、寶石、海馬、貝殼、海星和太妃糖。Real3D - AD數據集中的所有類別均為生產線的玩具。數據集中的物體分辨率為0.001mm - 0.0015mm,具有360度覆蓋范圍和完美的原型。
- 基線方法:我們與BTF、M3DM、PatchCore進行比較,以評估我們方法的性能。根據所使用的點云特征,它們可以分為7種不同的基線方法,即BTF(Raw)、BTF(FPFH)、M3DM(PointMAE)、PatchCore(FPFH)、PatchCore(FPFH + Raw)、PatchCore(PointMAE)、PatchCore(PointMAE + RAW),其中Raw表示使用坐標信息。PointMAE和FPFH是兩種不同的特征描述符。
- 評估指標:所有評估指標與相關研究中的完全相同。我們通過接收者操作特征曲線下面積(AUROC)和精確率 - 召回率曲線下面積(AUPR/AP)來評估對象級異常檢測性能和點級異常檢測性能。AUROC和AUPR越高,異常檢測性能越好。所有實驗均在第12代英特爾酷睿i9 - 12900K CPU、64G DDR4 SDRAM和英偉達GeForce RTX 3090平臺上進行。
3.2 Real3D - AD數據集上的異常檢測
我們將我們的方法與Real3D - AD數據集上的幾種方法進行比較,表1展示了對象級AUROC(O - AUROC)的異常檢測結果。FPFH和PointMAE特征分別與Raw特征結合。結果表明,基于PointMAE的組合表現更好。對于所提出的PointCore架構,點云的坐標信息是不可或缺的。表2展示了我們的模型與最先進方法之間更全面的比較。PointCore在所有指標上都取得了有競爭力的性能,包括在O - AUROC指標上提升了17.75%。點級AUROC(P - AUROC)、對象級AUPR(O - AUPR)和點級AUPR(P - AUPR)的性能進一步證明了我們方法在異常檢測方面的優越性能。表3列出了BTF、M3DM和PatchCore之間推理時間的比較。可以看出,表3中的BTF雖然速度快,但在O - AUROC和P - AUROC方面表現一般甚至較差。除BTF外,我們的方法是最快的。
3.3 消融實驗
在本節中,我們在表4的3視圖設置下對基于Reg3D - AD的設計選擇進行消融實驗。
- 局部優化(LO)的有效性:Reg3D - AD模型采用FPFH + RANSAC方法進行配準,其中RANSAC算法通過迭代尋找最優位姿矩陣。然而,RANSAC每次迭代中隨機選擇點的方式會導致最終配準結果存在顯著差異。我們對太妃糖數據集中的一對點云進行了20次實驗,結果表明即使參數相同,也會有很大的變化。引入局部優化算法是為了提高配準過程的穩定性。歐拉角的方差從1.1058°降至 ( 7.7796 × 1 0 ? 6 ) c (7.7796×10^{-6})^{c} (7.7796×10?6)c ,得分達到0.642±0.01。關于局部優化方法,我們在不同程度的高斯噪聲下對點點ICP和點面ICP算法進行了配準誤差測試。結果表明,在較低噪聲水平下,點面ICP配準方法通常能得到更準確的結果。Reg3D - AD數據集中的異常樣本類似于低噪聲水平的點云,因此選擇點面ICP作為局部優化方法。
- PointCore架構的有效性:與Reg3D - AD架構相比,PointCore架構可以更好地利用點云的坐標信息,實現更快、更準確的點云異常檢測。在速度方面,我們通過綁定點的坐標信息和PointMAE特征信息加速了推理過程,減少了后續PointMAE尋找最近鄰時引入的大量計算成本。相比之下,Reg3D - AD架構將坐標信息和PointMAE特征信息分別存儲在不同的存儲庫中,推理時每個坐標和PointMAE都必須在相應的存儲庫中尋找最近鄰,這帶來了巨大的計算挑戰,尤其是PointMAE特征有1154維。在準確性方面,我們增強了坐標信息的主導地位,避免了PointMAE特征中明顯的不匹配。具體來說,在Reg3D - AD架構中,測試點云的PointMAE特征必須在不利用任何坐標信息的情況下在PointMAE存儲庫中尋找最近鄰,這會導致局部相似組之間的錯誤匹配。通過嚴格限制坐標的匹配范圍,我們顯著降低了不匹配的概率。
- 排序模塊(RB)的有效性:從表4可以看出,排序模塊顯著提高了對象級AUROC和對象級AUPR,但在點級指標上的提升有限。這是因為排序模塊主要用于減輕異常值對不同異常分數分布的重大影響。它在對象級異常分數中起著重要的平衡作用,因為對象級異常分數的樣本量相對較小。相比之下,點級異常分數本身樣本眾多,異常值的影響極小。
四、結論
我們提出了一種無監督點云異常檢測器 PointCore,它基于單存儲庫開發,利用局部 - 全局特征來存儲輸入點云的多尺度信息。在 Real3D - AD 數據集上進行的大量實驗表明,我們的方法具有更高的召回率和更低的誤報率,在需要精確檢測缺陷樣本的實際應用中更具優勢。此外,由于局部 - 全局特征存儲庫和多特征異常分數計算方法都降低了計算成本,所提出的框架效率較高。














詳解)




)