一、稀疏檢索:關鍵詞匹配的經典代表
稀疏檢索是一種基于關鍵詞統計的傳統檢索方法。其基本思想是:通過詞頻和文檔頻率來衡量一個文檔與查詢的相關性。
核心原理
文檔和查詢都被表示為稀疏向量(如詞袋模型),只有在詞出現的位置才有非零值。
最常見的兩種稀疏檢索算法:
- TF-IDF(Term Frequency-Inverse Document Frequency)
由兩個部分組成: - TF(詞頻):某個詞在文檔中出現的頻率
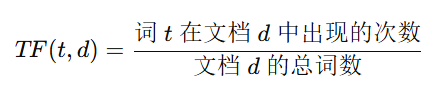
- IDF(逆文檔頻率):某個詞在所有文檔中出現的稀有程度
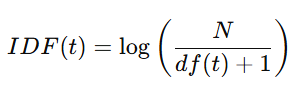
df(t) 是包含詞 𝑡 的文檔數量
最終得分:TF-IDF(t,d)=TF(t,d)×IDF(t)
稀疏檢索的局限性:
1. 不考慮詞序和上下文語義
示例:
- “男朋友送的禮物”
- “送男朋友的禮物”
在語義上完全不同,但關鍵詞相同,稀疏檢索會認為它們高度相似。
2. 對同義詞不敏感
- 例如“車”和“汽車”雖然含義一致,稀疏模型不會將它們歸為同一語義。
二、稠密檢索:理解語義的現代方法
稠密檢索依賴于深度學習模型將文本轉化為向量(embedding),這些向量可以捕捉語義信息、詞序和上下文。
核心原理:
使用預訓練模型(如 BERT、GTE、BGE)將文檔和查詢轉化為稠密的向量表示(維度通常為768、1024等)
使用 向量相似度(如余弦相似度、點積)進行匹配和排序
優勢:
- 捕捉語義信息:能區分不同語義的句子
- 支持同義詞識別、上下文推理
- 更適合處理自然語言表達豐富的用戶提問
潛在問題:
- 訓練成本高:需要訓練或微調 embedding 模型
- 信息壓縮:將高維文本語義壓縮進一個定長向量,可能導致信息丟失
- 可解釋性差:不像關鍵詞檢索那樣能清楚看到匹配邏輯
三、兩者對比
| 項目 | 稀疏檢索(TF-IDF / BM25) | 稠密檢索(Embedding) |
|---|---|---|
| 原理 | 基于關鍵詞統計 | 基于語義向量相似度 |
| 表達方式 | 稀疏詞袋向量 | 稠密浮點向量 |
| 優勢 | 簡單、高效、易解釋 | 理解語義、詞序、上下文 |
| 缺點 | 無法處理語義變化 | 信息壓縮、訓練成本高 |
| 同義詞識別 | 差 | 好 |
| 查詢變化適應 | 差 | 好 |











)



RNNoise 基于遞歸神經網絡的噪聲抑制庫)



