對于模型微調來說,直接進行微調需要的硬件配置和時間都是相當夸張的,但要想實現風格切換自由,也不是只有模型微調一個方式,LoRA技術可以說很完美的解決了這個難題。無論是二次元畫風還是復古膠片質感,都只需要加載小巧的LoRA模型,就能立即解鎖意料之外的百變創作可能!
一、LoRA是什么?為什么必學這個技能?
? 低秩適應技術:LoRA(Low-Rank Adaptation)通過微調模型參數實現特定風格/人物的生成
? 體積優勢:相比完整模型(2-7GB),LoRA文件通常只有20-200MB
? 靈活組合:可同時加載多個LoRA實現風格疊加
? 兼容性強:支持SD1.5/SDXL等多種基礎模型
二、準備工作清單
1 本地已安裝好 diffusers 環境
如果沒有的,下面給出簡單步驟,驗證安裝
1 安裝Python環境,創建虛擬環境
(因為要下載的組件比較大,防止污染主環境,建議在虛擬環境進行)
2 激活虛擬環境,添加全局國內鏡像加速
(建立使用vscode打開虛擬環境所在目錄,會自動加載虛擬環境,避免每次都要手動激活)
$ python -m venv .venv # 根據你的喜好命名虛擬環境,我這是是 .venv
$ pip config set global.index-url https://mirrors.aliyun.com/pypi/simple # 添加國內鏡像加速
# 安裝依賴pytorch,我硬件沒有GPU,安裝了cpu版的,硬件OK,去掉后面的參數即可
$ pip install torch torchvision --extra-index-url https://download.pytorch.org/whl/cpu
# 安裝 diffusers 庫
$ pip install diffusers transformers accelerate
2 基礎模型下載
這里需要準備好你的基礎大模型,我這里使用的是 Lykon/dreamshaper-8-lcm
你也可以根據你的本地情況加載已下載的模型
https://huggingface.co/Lykon/dreamshaper-8-lcm
3 LoRA模型下載
下載好的 模型文件(.safetensors或.ckpt格式)
推薦平臺:
- Civitai(需科學上網)
- LiblibAI(國內可用)
三、LoRA加載
這里直接給出關鍵代碼,我沒有使用WebUI是因為我發現本地CPU環境運行時,沒有直接Python加載diffusers庫高效,自己加個Qt界面,自定義功能也挺好用
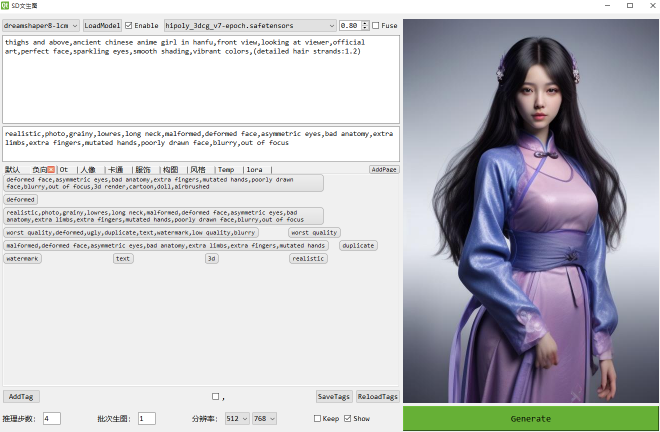
1 關鍵代碼
from diffusers import StableDiffusionPipeline, LCMScheduler# 加載基礎大模型
model_id = './models/dreamshaper-8-lcm'
pipeline = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float32
)
# 加載LCM減少推理步數
pipeline.scheduler = LCMScheduler.from_config(pipeline.scheduler.config
)
pipeline.to("cpu")# 加載LoRA模型文件
lora_id = './models/lora/hipoly_3dcg_v7-epoch.safetensors'
loraname = 'hipoly_3dcg_v7-epoch'
pipeline.load_lora_weights(lora_id, low_cpu_mem_usage=True,adapter_name=loraname
)
# 設置LoRA影響的權重(正常在LoRA下載頁,作者會給出一些建議值)
pipeline.set_adapters(loraname,adapter_weights=0.6)# 生成圖片
prompt = 'thighs and above,ancient chinese anime girl in hanfu,front view,looking at viewer,official art,perfect face,sparkling eyes,smooth shading,vibrant colors,(detailed hair strands:1.2)'
nprompt = 'realistic,photo,grainy,lowres,long neck,malformed,deformed face,asymmetric eyes,bad anatomy,extra limbs,extra fingers,mutated hands,poorly drawn face,blurry,out of focus'
image = pipeline(prompt=prompt,negative_prompt=nprompt,num_inference_steps=4, # 加載LCM后4~8步即可width=512, height=768, # 人像建議豎版guidance_scale=0 # 0 禁用,否則影響LCM生成
).images[0]
image.save('output.jpg')
2 踩坑說明
關于Lora權重不起作用的情況下,一定一定要檢查下是不是添加了 fuse 整合
fuse_lora() 將 LoRA 適配器的低秩矩陣權重動態合并到基礎模型參數中,實現推理加速(約 15-30%)并減少顯存占用?。融合后,LoRA 參數不再獨立存在,無法動態調整權重?。
pipeline.fuse_lora() # 融合
pipeline.unfuse_lora() # 取消融合
)
4.0)





—— Suno)
中的量化器簡介)










