目錄
前言
1.String
1.1RAW編碼
1.2EMBSTR編碼
1.3 INT編碼
?2.List
3.Set
3.1 InSet編碼轉化成Dict編碼
4.ZSet
4.1結合SkipList和HT實現
?4.2使用ZipList實現
4.3編碼轉換?
4.4 ZipList排序功能
5.Hash
5.1Hash底層存儲結構
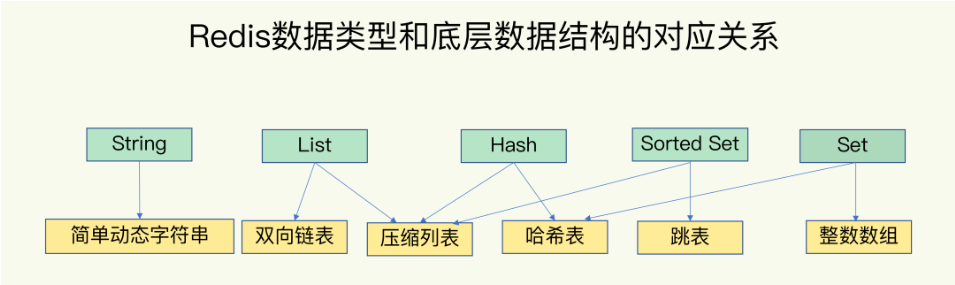
6.Redis數據結構和數據類型關系圖?
前言
?Redis 中的每種數據類型都由特定的數據結構來實現,數據結構為數據類型提供了底層的存儲和操作機制。
不同的數據類型具有不同的特性和應用場景,數據結構的選擇和設計是為了更好地滿足這些特性。
數據結構是實現數據類型的基礎,它們共同構成了 Redis 強大的功能體系,使得 Redis 能夠在不同的應用場景中,根據數據的特點和操作需求,選擇合適的數據類型和對應的數據結構來高效地處理和管理數據。
1.String
String是Redis中最常見的數據存儲類型:
其基本編碼方式是RAW,基于簡單動態字符串(SDS)實現,存儲上限為512mb。
查看編碼:object encoding key
1.1RAW編碼
ptr指針指向SDS,RedisObject和SDS是兩個獨立空間所以會有尋址過程通過ptr指針找到SDS。所以會有兩次申請內存空間,釋放內存也會有兩次內存釋放,效率比較低。
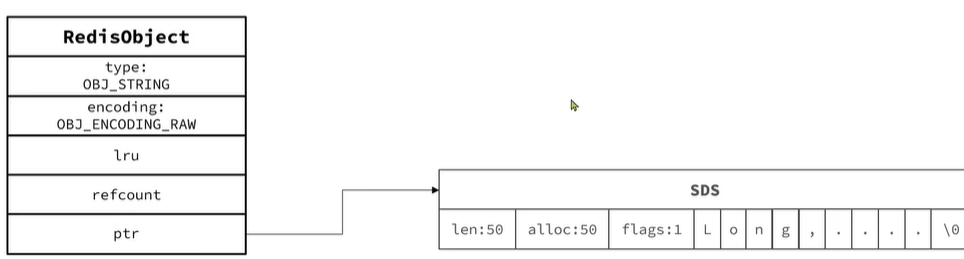
1.2EMBSTR編碼
如果存儲的SDS長度小于44字節,EMBSTR編碼,此時object head與SDS是一段連續空間。申請內存時只需要調用一次內存分配函數,效率更高。
好處:減少內存碎片
Redis 通常按頁分配內存,使用 jemalloc 等內存分配器,它會分配 8、16、32、64 等字節的內存塊。對于小于 44 字節的字符串,采用 embstr 編碼可以將其存儲在一個連續的 64 字節內存塊中,減少了內存碎片的產生。
如果字符串較長,超過 44 字節,為其單獨分配內存空間(轉為 raw 編碼),采用常規的 robj 和SDS分離方案性能下降,產生內存碎片。

1.3 INT編碼
如果存儲的字符審是整數值,并且大小在LONG_MAX范圍內,INT編碼,直接將數據保存在RedisObject的ptr指針位置(剛好8字節),不再需要SDS了。

?2.List
Redis的List結構類似雙端鏈表,可以從首尾操作列表中的元素
選擇何種數據結構呢?
- LinkList:普通鏈表,可以從雙端訪問,鏈表每個節點都是獨立的內存,節點與節點之間的訪問通過指針,指針比較占用內存,內存碎片較多。
- ZipList:壓縮列表,可以從雙端訪問,內存占用較低,存儲上限低。如果一次性存儲大量內存需要申請大量內存空間比較困難。
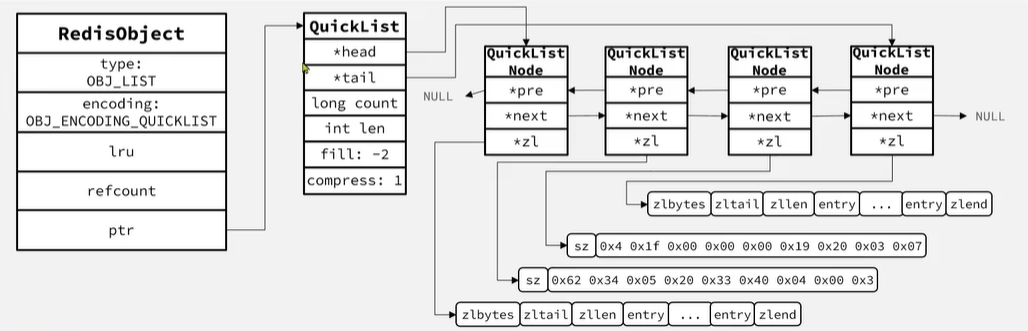
- QuickList:LinkedList+ZipList,可以雙端訪問,內存占用較低,包含多個ZipList,存儲上限高。
在3.2版本之前,Redis采用ZipList來實現List,當元素數量小于512并且元素大小小于64字節時采用ZipList編碼,超過則采用LinkedList編碼。
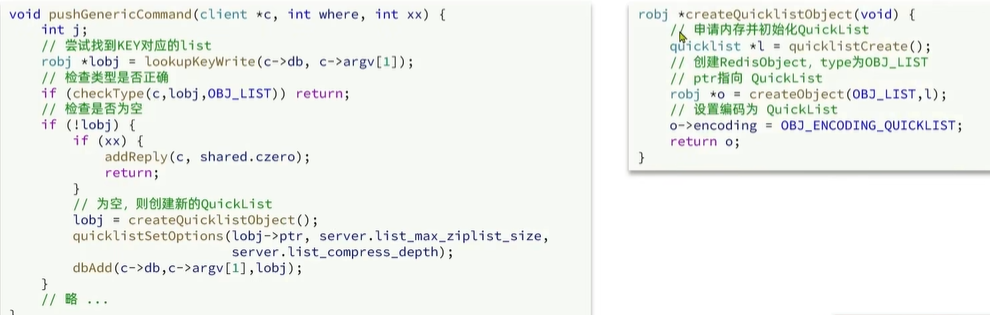
在3.2版本之后,redis統一采用QuickList來實現List。Redis 可以通過list-max-ziplist-size參數來控制每個 ZipList 節點的大小,通過list-compress-depth參數來控制 QuickList 的壓縮深度,即鏈表兩端不壓縮的節點數量,以此來平衡內存使用和操作性能。插入元素底層源碼
整體內存結構
3.Set
Set是Redis中的單列集合,滿足下列特點:
- 不保證有序性
- 保證元素唯一(可以判斷元素是否存在)
- 求交集,并集,差集
不管是插入元素還是求交集等等這些操作都需要判斷元素是否存在,這樣就需要選擇對元素查詢效率較高的數據結構
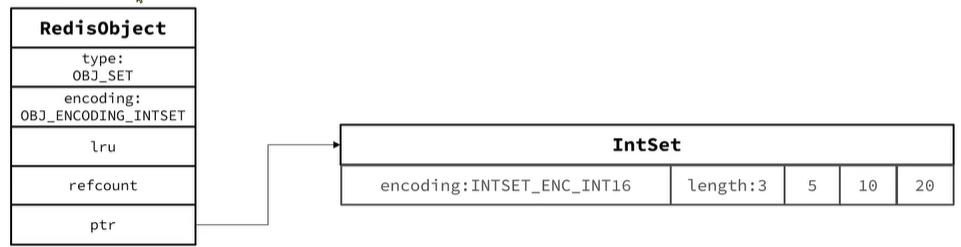
- 為了查詢效率和唯一性,set采用HT編碼(Dict)Dict中的key用來存儲元素,value統一為null
- 當存儲的所有數據都是整數,并且元素數量不超過set-max-intset-entset會采用IntSet編碼,以節省內存。
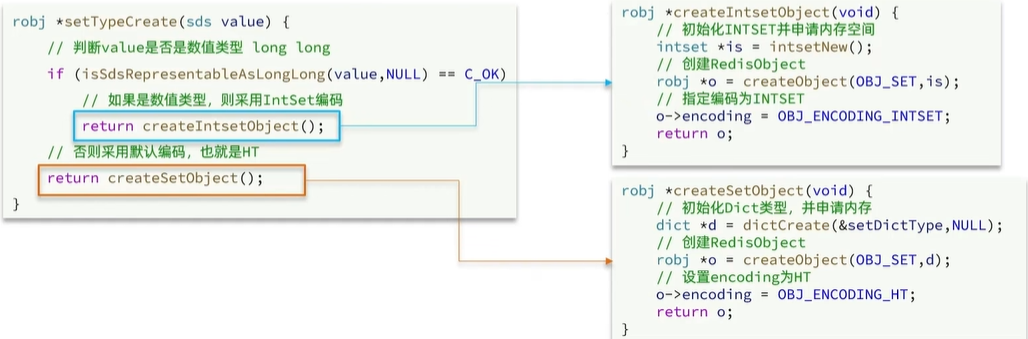
判斷用哪種數據結構底層源碼
創建IntSet數據結構底層源碼
創建Dict數據結構底層源碼
整體執行源碼



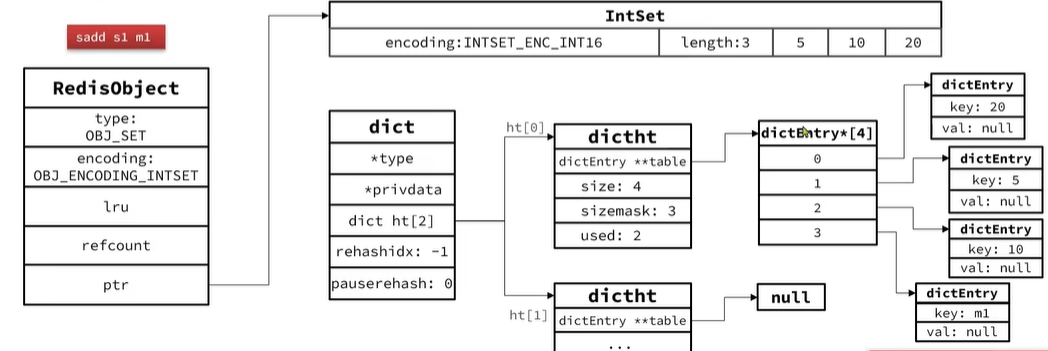
3.1 InSet編碼轉化成Dict編碼
當元素數量超過set-max-intset-entries或者存儲元素不是數字了時會自動轉換成Dict編碼
執行結構圖:
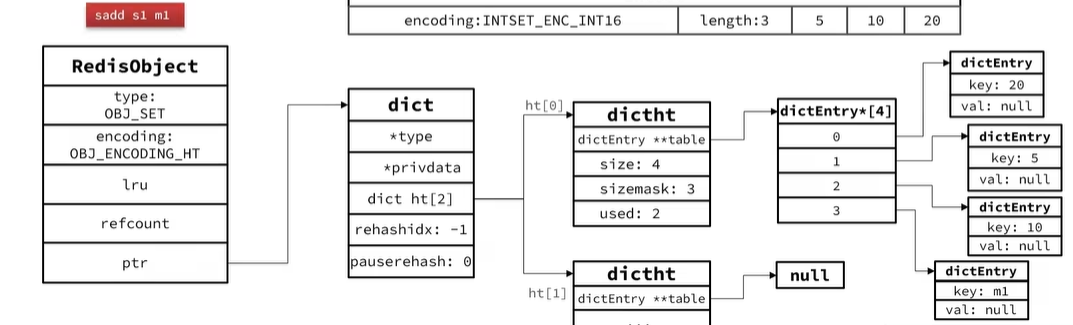
當插入一個元素為m1字符串時會升級為Dict編碼,創建Dict數據結構
RedisObject指針ptr指向Dict,encoding編碼改為Dict
4.ZSet
ZSet也就是SortedSet,其中每個元素都需要指定一個score值和member值:
可以根據score值排序
member必須唯一
可以根據member查詢分數
因此,ZSet底層數據結構必須滿足鍵值存儲,鍵必須唯一,可排序這幾個需求。
4.1結合SkipList和HT實現
- SkipList:可以排序,并且可以同時存儲score和ele值(member) | 滿足鍵值存儲和可排序
- HT(Dict):可以鍵值存儲,并且可以根據key找value | 滿足高效查詢鍵值唯一
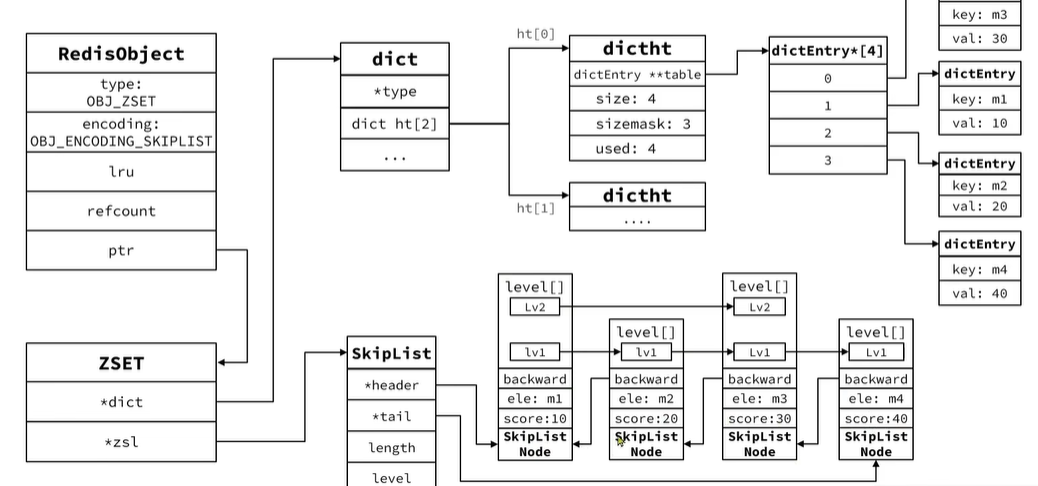
所以ZSet底層是使用這兩種數據結構來實現的dict用于快速查找,SkipList用于鍵值存儲和排序。
底層源碼:
內存圖:

?4.2使用ZipList實現
使用上述那種方式這樣帶來的壞處就是ZSet非常占用內存空間,使用兩種數據結構,存儲兩份。
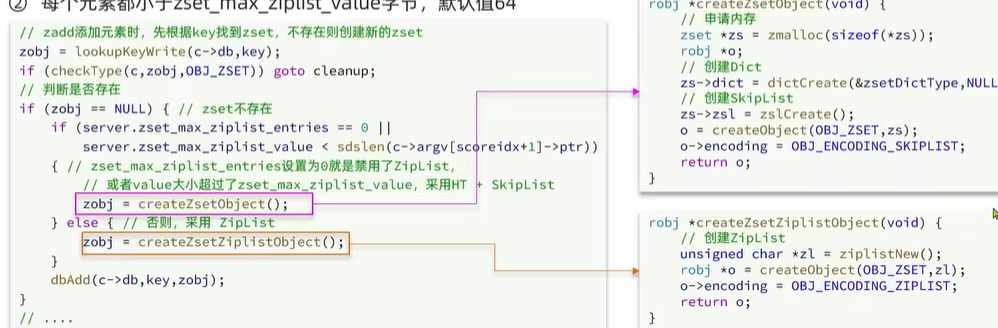
當元素數量不多時,HT和SkipList的優勢不明顯,而且更耗內存。因此Zset還會采用ZipList不過需要同時滿足兩個條件:
- 元素數量小于zset_max_ziplist_entries,默認值128
- 每個元素都小于zset_max_ziplist_value字節,默認值64
底層判斷使用哪種數據結構如下:
4.3編碼轉換?
既然ZSet底層都是用來兩種編碼方式根據不同情況,那么肯定會出現編碼轉換,添加元素不滿足一下兩個條件就會觸發編碼轉換。
- 元素數量小于zset_max_ziplist_entries,默認值128
- 每個元素都小于zset_max_ziplist_value字節,默認值64
底層執行源碼:

4.4 ZipList排序功能
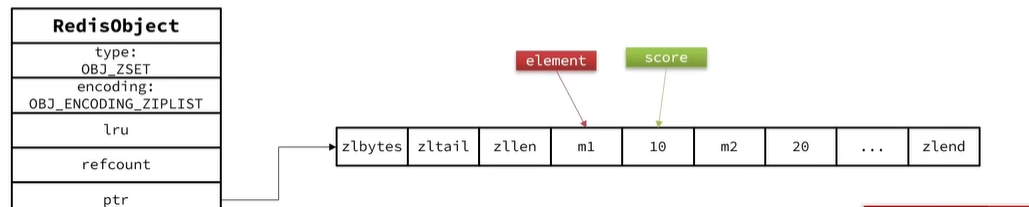
ZipList本身沒有排序功能,而且沒有鍵值對的概念,因此需要有zset通過編碼實現:
- ZipList是連續內存,因此score和element是緊換在一起的兩個entry,element在前,score在后
- score越小越接近隊首,score越大越接近隊尾,按照score值升序排列
底層結構圖:
因為元素比較少ZipList內存中是連續存儲的,所以查找的時候就去遍歷,插入元素的時候按照大小順序插入,這樣就保證了排序。性能也不錯。
5.Hash
Hash結構與Redis中的Zset非常類似:
- 都是鍵值存儲
- 都需要根據鍵獲取值
- 鍵必須唯一
區別如下:
- zset的鍵是member,值是score;hash的鍵和值都是任意值
- zset要根據score排序;hash則無需排序
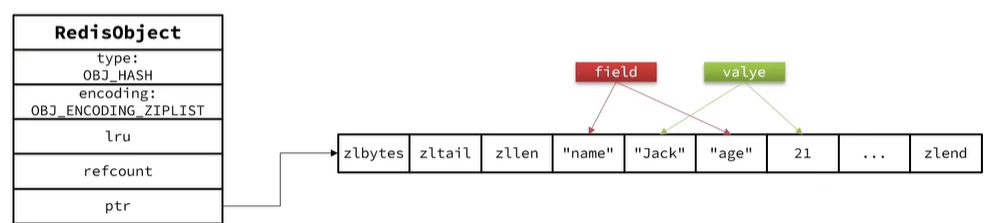
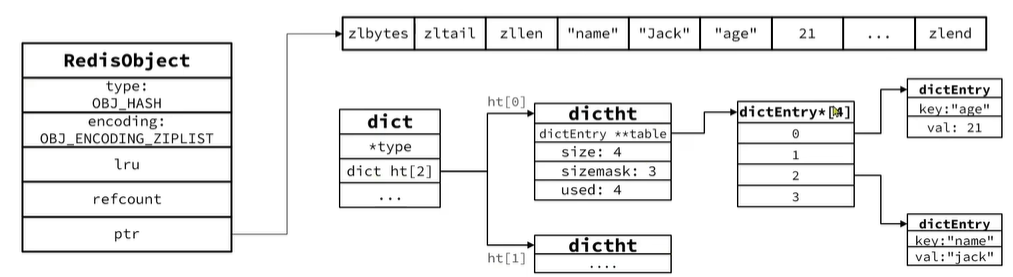
5.1Hash底層存儲結構
- Hash結構默認采用ZipList編碼,用以節省內存。ZipList中相鄰的兩個entry分別保存field和value
- 當數據量較大時,hash結HT編碼,也就是Dict,觸發條件有兩個:
????????????????ziplist中的元素數量超過了hash-max-ziplist-entries(默認512)
????????????????ziplist中的任意entry大小超過了hash-max-ziplist-value(默認64字節)轉換流程:
觸發條件達成轉換編碼
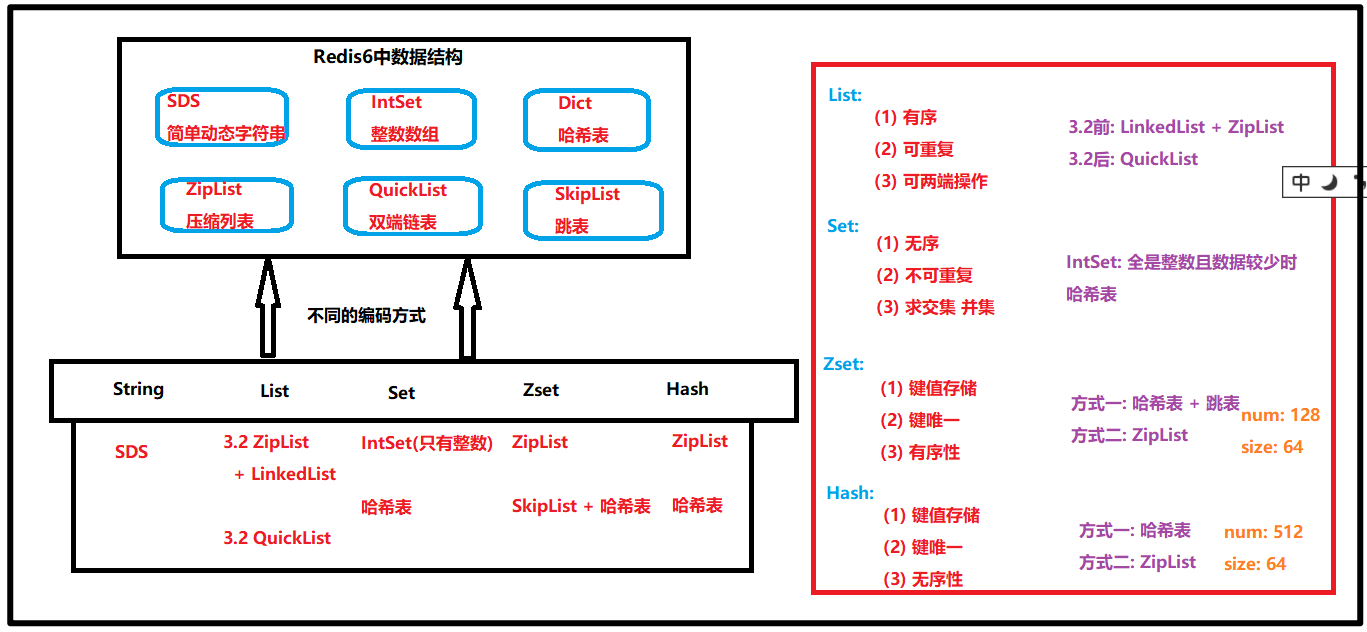
6.Redis數據結構和數據類型關系圖?






)





——范圍管理、進度管理)






