1. 概述
目標檢測(Object Detection)和目標追蹤(Object Tracking)是計算機視覺中的兩個關鍵技術,它們在多種實際應用場景中發揮著重要作用。
目標檢測指的是在靜態圖像或視頻幀中識別出特定類別的目標對象,并通常以矩形框(bounding box)的形式標出其位置。目標檢測算法通常只處理單個圖像幀,其任務是檢測出該幀中所有感興趣的對象。
目標追蹤則涉及對視頻中連續幀里的目標對象進行識別和跟蹤。與目標檢測不同,目標追蹤需要在視頻序列中維持對目標的識別,確保同一目標在不同幀中被連續檢測和標記,即使目標在場景中移動或變換姿態。目標追蹤算法需要處理整個視頻序列,確保目標的一致性和唯一性。
本文旨在幫助讀者理解“目標檢測”和“目標追蹤”這兩個概念,并指導如何在編程中實現這些技術以及如何對它們進行可視化展示。這些技術在商業領域的應用非常廣泛,包括但不限于自動化農業監控、機器人導航、交通流量分析等。
2. 檢測和跟蹤
目標檢測是針對單個視頻幀或圖像的。對象檢測算法的任務是在這張靜態圖片中識別并定位一個或多個特定的對象。這通常涉及到使用矩形框(bounding boxes)來標出對象的位置,并且可能會包括對象的類別信息。
對象跟蹤則是一項更為復雜的任務,它涉及視頻序列中的連續幀。對象跟蹤算法不僅要識別出視頻中的每一幀中的對象,還要能夠在連續的幀之間關聯同一個對象,確保對同一個對象的跟蹤是連續和一致的。這通常需要為每個對象分配一個唯一的標識符(ID),并在整個視頻序列中維持這個 ID 的一致性。
在對象跟蹤中,可能會用到以下幾種技術:
- 卡爾曼濾波器(Kalman Filter):這是一種數學算法,用于從一系列的測量中估計對象的位置和速度,即使在測量中含有噪聲或誤差時也能做出準確的預測。
- 光流(Optical Flow):這是一種計算圖像中物體運動模式的技術,它可以估計圖像中每個像素或一組特征點的運動速度,從而幫助跟蹤移動的對象。
對象跟蹤的算法示例包括 DeepSort、Sort 以及 OpenCV 中的原生跟蹤算法等。這些算法利用了不同的策略和技術來有效地在視頻幀之間跟蹤對象,即使在目標遮擋、快速運動或光照變化等復雜情況下也能有效工作。
3. 光流追蹤
光流是一種描述和估計圖像中物體運動的計算機視覺技術。當物體或相機在三維空間中移動時,圖像序列中的相應物體會出現視覺上的移動。光流利用這種視覺變化來推斷物體在連續視頻幀或圖像序列中的運動。
光流的關鍵特點包括:
- 二維向量場:光流表示為一個二維向量場,其中每個向量代表一個位移向量。
- 位移向量:每個向量顯示了圖像中一個點從第一幀到第二幀的位移。這些向量的方向和大小通常用來表示物體的運動方向和速度。
- 稀疏與密集光流:光流可以是稀疏的,即只計算圖像中關鍵特征點的位移;也可以是密集的,即計算圖像中每個像素的位移。
- 應用領域:光流在多個領域有廣泛應用,包括但不限于:
- 結構從運動(Structure from Motion)
- 視頻壓縮
- 視頻穩定化
- 物體跟蹤
- 運動檢測
- 機器人導航
- 計算方法:光流可以通過多種算法計算,包括基于梯度的方法、基于頻域的方法、以及基于能量最小化的方法。
- 局限性:光流可能受到多種因素的影響,如光照變化、遮擋、快速運動等,這些因素可能導致光流計算的不準確或失敗。
4. Yolov8 算法
YOLOv8 是基于 YOLO(You Only Look Once)的模型,由 Ultralytics 開發。通常,這個模型專門用于:
- 檢測對象
- 分割
- 分類對象
YOLOv8 系列模型被廣泛認為是該領域最好的模型之一,提供卓越的準確性和更快的性能。它的易用性歸功于它由五個獨立的模型組成,每個模型都滿足不同的需求、時間限制和范圍。
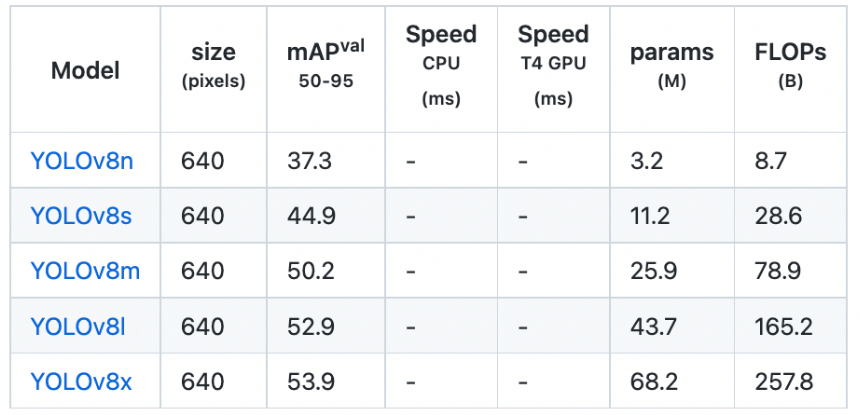
在比較 YOLOv8 不同版本時,可以看到模型在多個方面存在差異:
- 平均精度(mAP):不同版本的 YOLOv8 在平均精度上有所不同,這是一個衡量模型在目標檢測任務上性能的指標。
- 參數數量:各模型擁有的參數數量也不同,參數數量越多,模型的復雜度通常越高,這可能會影響模型的推理速度和資源消耗。
- 資源消耗和速度:一些模型可能在運行時更為資源密集,這可能會影響處理速度。例如,X 模型被認為是最先進的,提供了更高的精度,但可能會導致視頻或圖像渲染速度變慢。而 Nano 模型(N)則是最快的選擇,但在準確性上做了一些妥協。
YOLOv8 系列提供了不同版本的模型以適應不同的應用場景和需求。用戶可以根據自己的具體需求,如對速度或準確性的偏好,來選擇最合適的模型版本。例如,如果應用場景對速度要求極高,可能更適合選擇 Nano 模型;而如果對檢測精度有較高要求,X 模型可能是更好的選擇。
4.1 SORT 算法
SORT 算法由 Alex Bewley 提出,是一種用于視頻序列中二維多目標跟蹤的跟蹤算法。它是其他跟蹤算法(如 DeepSort)的基礎。由于其極簡主義的特點,該算法非常易于使用和實現。您可以通過這里了解更多關于該算法的信息,甚至可以查看源代碼。
4.2 數學原理
4.2.1 卷積神經網絡(CNN)
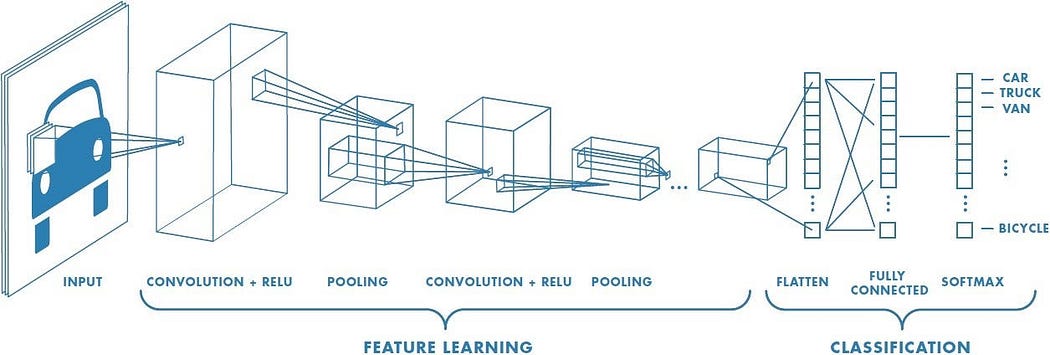
卷積神經網絡結構 [來源:點擊這里 ]
卷積神經網絡(CNN)是基于卷積層和池化層的神經網絡。正如在《卷積神經網絡全面指南——簡單易懂的方式》中所述,“卷積操作的目標是從輸入圖像中提取高級特征,例如邊緣”。簡單來說,卷積層負責從初始輸入中提取最重要的特征。而池化層則負責簡化內容,即“負責減少卷積特征的空間尺寸”。通過這種過程,機器能夠理解初始輸入的特征。因此,我們得到了一個復雜的特征學習過程,其中卷積層和池化層相互堆疊[4]。
4.2.1 光流數學原理
連續兩幀之間的像素運動被稱為光流。無論是相機在運動還是場景在運動,都取決于運動的主體。
光流的基本目標是計算由于相機運動或物體運動而導致的物體的位移向量。為了計算所有圖像像素或稀疏特征集合的運動向量,我們的主要目標是確定它們的位移。
如果我們用一張圖片來說明光流問題,它看起來會像這樣:
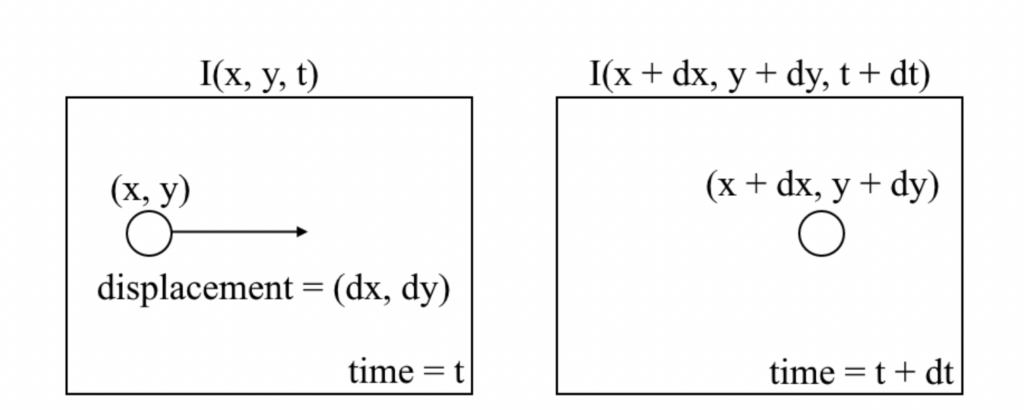
光流通過定義一個密集的向量場來發揮作用,它是計算機視覺和機器學習應用中的關鍵組成部分,包括目標跟蹤、目標識別、運動檢測和機器人導航等。在這個場中,每個像素都被賦予了一個位移向量,這有助于確定輸入視頻序列中每個移動目標像素的方向和速度[5]。
5. 實踐操作
5.1 使用 YOLOv8 和 SORT 進行目標跟蹤
首先,需要了解如何使用 YOLOv8 模型。
pip install ultralytics
# 如果在 Jupyter Notebook 中,請使用 !pip install ultralytics
然后:
from ultralytics import YOLO
# 假設你已經安裝了 opencv
import cv2 MODEL = "yolov8x.pt" # 創建你選擇的模型實例
model = YOLO(MODEL) results = model("people.jpg",show=True)
# "0" 將會一直顯示窗口,直到有按鍵按下(適用于視頻)
# waitKey(1) 將會顯示一幀圖像 1 毫秒
cv2.waitKey(0)

這是從 YOLOv8x 版本獲得的結果。
現在,已經了解了基礎內容,接下來將進入真正的目標檢測和跟蹤。
import cv2
from ultralytics import YOLO
import math
# 使用 cvzone,它比 cv2 更美觀且易于使用
import cvzone
# 從 SORT 導入所有函數
from sort import *
# cap = cv2.VideoCapture(0) #用于網絡攝像頭
# cap.set(3,1280)
# cap.set(4,720)
cap = cv2.VideoCapture("data/los_angeles.mp4")
model = YOLO("yolos/yolov8n.pt")
cap 變量是我們使用的視頻實例,model 是 YOLOv8 模型的實例。
classes = {0: 'person',
1: 'bicycle',
2: 'car',
...
78: 'hair drier',
79: 'toothbrush'}result_array = [classes[i] for i in range(len(classes))]
最初,從 YOLOv8 API 獲取的類別是以浮點數或類別 ID 的形式。當然,每個數字都對應一個類別名稱。創建一個字典會更簡單,如果需要的話,還可以將其轉換為數組(我懶得手動做了)。
# 線條坐標(稍后解釋)
l = [593,500,958,500]
while True:# 按幀讀取視頻內容_, frame = cap.read() # 每一幀都通過 YOLO 模型results = model(frame,stream=True) for r in results: # 創建邊界框boxes = r.boxes for box in boxes:# 提取坐標x1, y1, x2, y2 = box.xyxy[0] x1, y1, x2, y2 = int(x1),int(y1),int(x2),int(y2)# 創建實例的寬度和高度w,h = x2-x1,y2-y1 cvzone.cornerRect(frame,(x1,y1,w,h),l=5, rt = 2, colorC=(255,215,0), colorR=(255,99,71))# 每個邊界框的置信度或準確度conf = math.ceil((box.conf[0]*100))/100 # 類別 ID(數字)cls = int(box.cls[0])
這是檢測每個對象的部分。現在是時候跟蹤并統計道路上的每一輛車了:
while True:_, frame = cap.read()results = model(frame,stream=True)detections = np.empty((0,5)) #創建一個空數組 for r in results: boxes = r.boxes for box in boxes:''' 其余代碼 '''ins = np.array([x1,y1,x2,y2,conf]) #每個對象都應該這樣記錄detections = np.vstack((detections,ins)) # 然后將它們堆疊在一起形成一個公共數組 tracks = tracker.update(detections) #將我們的檢測結果發送到跟蹤函數cv2.line(frame, (l[0],l[1]),(l[2],l[3]),color=(255,0,0),thickness=3) #作為閾值的線條
現在,將創建一個數組來存儲我們所有的檢測結果。接下來,將這個數組發送到跟蹤函數中,在那里可以提取唯一的 ID 和邊界框坐標(這些坐標與之前的相同)。重要的是 cv2.line 實例:正在使用特定的坐標生成一條線。如果某些 ID 的車輛穿過這條線,總計數將增加。本質上,正在建立一個根據車輛 ID 運行的車輛計數器。
for result in tracks:x1,y1,x2,y2,id = resultx1,y1,x2,y2 = int(x1),int(y1),int(x2),int(y2)#.putTextRect 是為了在邊界框上方放置一個矩形cvzone.putTextRect(frame,f'{result_array[cls]} {conf} id:{int(id)} ',(max(0,x1),max(35,y1-20)),scale=1, thickness=1, offset=3, colorR=(255,99,71))#邊界框中心的坐標cx,cy = x1+w//2, y1+h//2 if l[0]<cx<l[2] and l[1]-10<cy<l[3]+10:if totalCount.count(id) == 0:#統計每一個新穿過線的車輛totalCount.append(id)#當一個對象穿過線時,線條會改變顏色cv2.line(frame, (l[0],l[1]),(l[2],l[3]),color=(127,255,212),thickness=5)#顯示計數車輛數量的矩形cvzone.putTextRect(frame,f' Total Count: {len(totalCount)} ',(70,70),scale=2, thickness=1, offset=3, colorR=(255,99,71))m.write(frame)cv2.imshow("Image",frame)cv2.waitKey(1)
現在,最有趣的部分來了:cx 和 cy 是邊界框中心的坐標。通過使用這些值,可以判斷車輛是否穿過了指定的線條(查看代碼)。如果車輛確實穿過了線條,我們的下一步是驗證分配給這輛車的 ID 是否唯一,也就是說,這輛車之前沒有穿過線條。
5.1 結果
車輛跟蹤和計數
如圖所示,我在這里顯示了邊界框,以及對應的目標類別、置信度和唯一 ID。左上角顯示了總目標數量。
5.2 使用光流進行目標跟蹤
SORT 算法通過分配 ID 并將當前幀與上一幀建立聯系來進行跟蹤,而光流過程則更側重于運動估計。換句話說,它估計哪些物體在移動,并估計物體的運動方向或向量。
光流有兩種類型:
- 稀疏光流(Sparse Optical Flow)
- 密集光流(Dense Optical Flow)
雖然密集光流會計算每一幀中每個像素的光流(從而創建一個僅包含移動物體的圖像),但稀疏光流則計算物體的主要特征點的流向量。
現在我們來看看代碼:
flow = cv2.calcOpticalFlowFarneback(prevgray, gray, None, 0.5, 3, 15, 3, 5, 1.2, 0)
首先,我們需要計算光流。我們可以通過 OpenCV 庫來實現,它已經包含了這個算法。當然,不要忘記將這個函數放在一個while循環中,以便算法能夠持續計算光流(讀取視頻和處理視頻的過程與使用 YOLOv8 和 SORT 進行目標跟蹤小節中的內容相同)。
def draw_flow(img, flow, step=16):# 獲取圖像的高和寬h, w = img.shape[:2]# 在圖像上以網格模式創建點y, x = np.mgrid[step/2:h:step, step/2:w:step].reshape(2,-1).astype(int)# 獲取網格點處的光流方向fx, fy = flow[y,x].T# 創建線條以顯示光流方向lines = np.vstack([x, y, x-fx, y-fy]).T.reshape(-1, 2, 2)lines = np.int32(lines + 0.5)# 將灰度圖像轉換為彩色img_bgr = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)# 繪制線條以表示光流方向cv2.polylines(img_bgr, lines, 0, (0, 255, 0))# 在線條的起始點繪制小圓圈 for (x1, y1), (_x2, _y2) in lines:cv2.circle(img_bgr, (x1, y1), 1, (0, 255, 0), -1)return img_bgr
這是負責稀疏光流的def函數。我們只需要從圖像中提取點,將其轉換為流向量,然后簡單地進行可視化。
def draw_hsv(flow):# 獲取流向量矩陣的高和寬h, w = flow.shape[:2]# 將流向量矩陣分解為其 x 和 y 分量fx, fy = flow[:,:,0], flow[:,:,1]# 計算流向量的角度并轉換為度ang = np.arctan2(fy, fx) + np.pi# 計算流向量的大小v = np.sqrt(fx*fx + fy*fy)# 創建一個空的 HSV 圖像hsv = np.zeros((h, w, 3), np.uint8)# 根據流向量的角度設置 HSV 圖像的色調通道hsv[...,0] = ang * (180 / np.pi / 2)# 將 HSV 圖像的飽和度通道設置為最大值hsv[...,1] = 255# 根據流向量的大小設置 HSV 圖像的亮度通道hsv[...,2] = np.minimum(v * 4, 255)# 將 HSV 圖像轉換為 BGR 色彩空間bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)# 返回最終的 BGR 圖像,其中包含光流可視化結果 return bgr
這是負責密集光流的def函數。在這里,該函數將流向量轉換為色調值,因此最終結果將僅顯示移動的像素[7]。





)













