摘要:我們提出PixelFlow,這是一系列直接在原始像素空間中運行的圖像生成模型,與主流的潛在空間模型形成對比。這種方法通過消除對預訓練變分自編碼器(VAE)的需求,并使整個模型能夠端到端訓練,從而簡化了圖像生成過程。通過高效的級聯流建模,PixelFlow在像素空間中實現了可負擔的計算成本。在256×256的ImageNet類條件圖像生成基準測試中,它取得了1.98的FID(Fréchet Inception Distance)分數。定性的文生圖結果展示出,PixelFlow在圖像質量、藝術性和語義控制方面均表現出色。我們希望這一新范式能夠激發并開拓下一代視覺生成模型的新機遇。代碼和模型可在https://github.com/ShoufaChen/PixelFlow獲取。Huggingface鏈接:Paper page,論文鏈接:2504.07963
研究背景和目的
研究背景
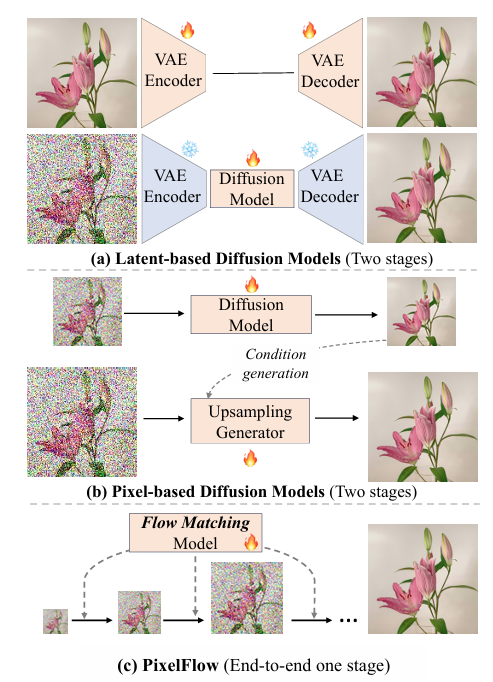
近年來,隨著生成模型,特別是擴散模型(Diffusion Models, DMs)的迅速發展,圖像生成領域取得了顯著進步。傳統的潛在空間擴散模型(Latent Space Diffusion Models, LDMs)通過將原始數據壓縮到緊湊的潛在空間中,然后使用預訓練的變分自編碼器(Variational Autoencoders, VAEs)進行表示,大大降低了計算需求并提高了生成效率。然而,這種方法也存在一些局限性。首先,LDMs將VAE和擴散模型分為兩個獨立的部分進行訓練,這阻礙了它們的聯合優化,使得整體診斷變得復雜。其次,雖然LDMs在圖像生成方面表現出色,但它們依賴于高質量的潛在表示,這在某些情況下可能難以實現。
另一方面,直接在像素空間進行圖像生成的模型也受到了廣泛關注。然而,由于像素空間中的信息量大且復雜,直接在像素空間進行擴散生成變得計算上不可行,特別是對于高分辨率圖像。因此,一些研究采用了級聯方法,先生成低分辨率圖像,然后使用超分辨率模型將其提升到高分辨率。然而,這種方法仍然需要多個獨立訓練的網絡,限制了端到端優化的可能性。
鑒于上述背景,探索一種既能在像素空間中高效生成高分辨率圖像,又能實現端到端優化的新方法顯得尤為重要。
研究目的
本文提出PixelFlow,旨在解決直接在像素空間中生成高分辨率圖像時面臨的計算挑戰,并實現端到端的訓練優化。PixelFlow通過級聯流建模,從低分辨率到高分辨率逐步生成圖像,避免了在整個過程中進行全分辨率計算,從而顯著降低了計算成本。同時,PixelFlow不使用預訓練的VAE,直接對原始像素數據進行操作,實現了端到端的可訓練性。本文的主要研究目的包括:
- 提出一種直接在像素空間中運行的圖像生成模型PixelFlow,實現高效且端到端的圖像生成。
- 通過級聯流建模,從低分辨率到高分辨率逐步生成圖像,降低計算成本。
- 在類條件圖像生成和文生圖任務上驗證PixelFlow的性能,并與其他先進模型進行比較。
- 探索PixelFlow在圖像生成中的潛在應用,為下一代視覺生成模型提供新的思路。
研究方法
模型架構
PixelFlow采用基于Transformer的架構,通過級聯流匹配(Flow Matching)算法實現從低分辨率到高分辨率的逐步圖像生成。PixelFlow的模型架構主要包括以下幾個部分:
- Patchify層:將輸入圖像轉換為一系列令牌序列,以便在Transformer中進行處理。與傳統的潛在空間模型不同,PixelFlow直接對原始像素數據進行操作。
- RoPE(Rotary Position Embedding):用于處理不同分辨率的令牌序列,使模型能夠適應不同階段的生成任務。
- 分辨率嵌入:為了區分不同分辨率的特征圖,引入了分辨率嵌入,將其與時間步嵌入相結合,并傳遞給模型。
- Transformer解碼器:采用標準的Diffusion Transformer(DiT)架構,通過自回歸的方式進行訓練,以預測下一個令牌。
級聯流建模
PixelFlow通過級聯流建模實現從低分辨率到高分辨率的逐步圖像生成。在訓練過程中,通過下采樣和上采樣操作構建不同分辨率的樣本,并在這些樣本之間進行插值,以構建訓練示例。模型被訓練來預測從中間樣本到真實數據樣本的速度,從而指導生成過程。在推理過程中,從最低分辨率的純高斯噪聲開始,逐步去噪并上采樣圖像,直到達到目標分辨率。
訓練與推理
在訓練過程中,PixelFlow從所有分辨率階段均勻采樣訓練示例,并使用序列打包技術在一個小批量中聯合訓練不同分辨率的樣本,以提高效率和可擴展性。在推理過程中,PixelFlow采用標準的流基采樣方法,使用歐拉離散采樣器或Dopri5求解器,根據所需的速度和準確性權衡進行選擇。為了確保不同尺度之間的平滑過渡,還采用了重噪聲策略來減輕跳躍點問題。
研究結果
模型性能
在ImageNet 256×256類條件圖像生成基準測試上,PixelFlow取得了1.98的FID分數,與先進的潛在空間模型相比具有競爭力。此外,在文生圖任務上,PixelFlow在GenEval、T2I-CompBench和DPG-Bench等基準測試上也表現出色,證明了其在生成高質量圖像方面的能力。
定性分析
定性結果顯示,PixelFlow能夠生成具有高質量、藝術性和語義控制的圖像。特別是在文生圖任務中,PixelFlow能夠準確地捕捉復雜文本描述中的關鍵視覺元素和它們之間的關系,生成與文本高度一致的圖像。
消融研究
消融研究表明,級聯流建模和端到端訓練對于PixelFlow的性能至關重要。通過減少起始序列長度、增加推理步驟數和使用更高級的ODE求解器,可以進一步提高PixelFlow的生成質量。此外,分類器自由引導(CFG)策略的使用也對PixelFlow的性能產生了顯著影響。
研究局限
盡管PixelFlow在圖像生成方面取得了顯著成果,但仍存在一些局限性:
- 計算成本:盡管PixelFlow通過級聯流建模顯著降低了計算成本,但在最后一個階段仍然需要進行全分辨率計算,這占據了總推理時間的約80%。
- 訓練收斂速度:隨著序列長度的增加,PixelFlow的訓練收斂速度會變慢。
- 模型擴展性:PixelFlow的模型擴展性尚未得到充分驗證,特別是在處理更高分辨率的圖像時。
未來研究方向
針對上述局限性,未來的研究可以從以下幾個方面展開:
- 優化計算成本:探索更高效的算法和硬件加速技術,以進一步降低PixelFlow的計算成本,特別是在最后一個階段的全分辨率計算中。
- 提高訓練效率:研究如何加速PixelFlow的訓練過程,特別是在處理長序列時。這可能包括改進模型架構、優化訓練策略或使用更強大的計算資源。
- 擴展模型能力:驗證PixelFlow在處理更高分辨率圖像時的性能,并探索其在其他視覺生成任務中的應用,如視頻生成和圖像編輯等。
- 結合潛在空間表示:研究如何將潛在空間表示與PixelFlow相結合,以進一步提高其生成質量和可擴展性。這可能包括在PixelFlow中引入預訓練的VAE或使用混合潛在空間和像素空間的方法。
綜上所述,PixelFlow作為一種直接在像素空間中運行的圖像生成模型,通過級聯流建模和端到端訓練實現了高效且高質量的圖像生成。未來的研究將進一步優化PixelFlow的性能和擴展性,推動其在視覺生成領域的應用和發展。
)




)

)
![【權限】v-hasPermi=“[‘monitor:job:add‘]“ 這個屬性是怎么控制能不能看到這個按鈕](http://pic.xiahunao.cn/【權限】v-hasPermi=“[‘monitor:job:add‘]“ 這個屬性是怎么控制能不能看到這個按鈕)



學習路徑全解析:從入門到精通)


)



![[250414] ArcoLinux 項目宣布逐步結束](http://pic.xiahunao.cn/[250414] ArcoLinux 項目宣布逐步結束)