案例
正常情況
有一個表t ( id, a , b ),id是主鍵索引,a是Normal索引。
正常情況下,針對a進行查詢,可以走索引a

并且查詢的數量和預估掃描行數是差不多的,都是10001行

奇怪的現象
隨著時間的變化,后面可能就會發生下面的情況
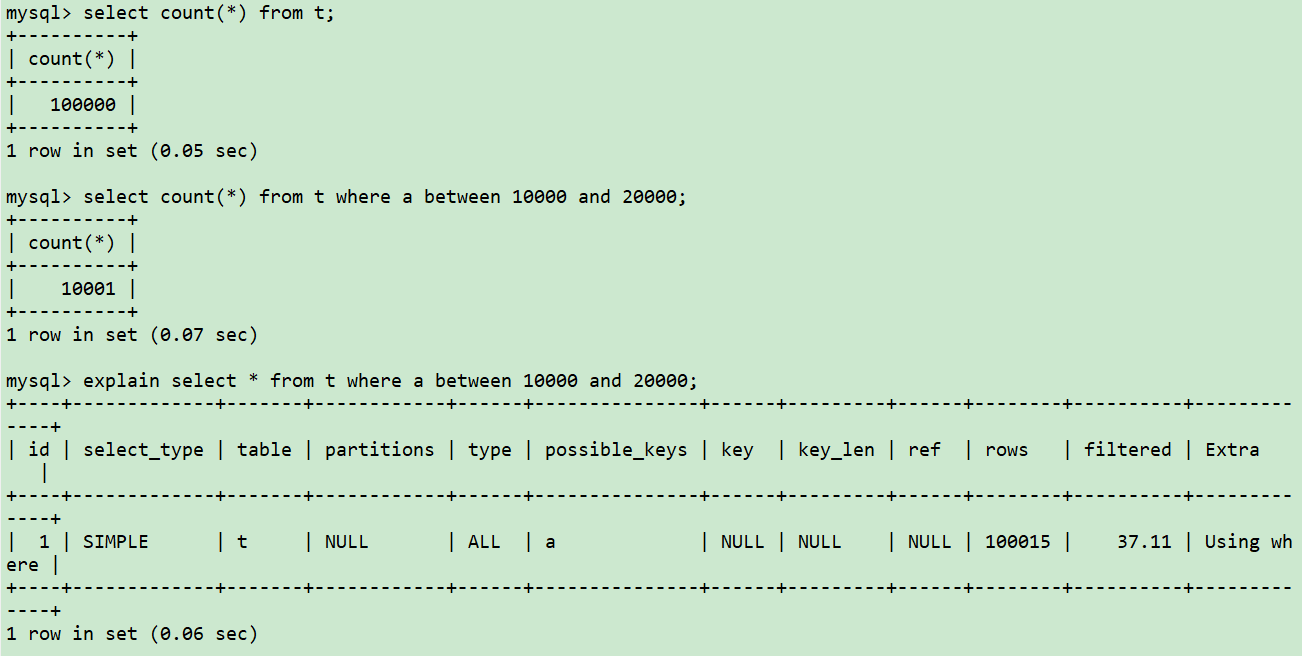
根據explain計劃,我們發現數據還是那么多,但是不走a索引了,并且優化器知道有a索引,但是最終還是走了全表掃描。
優化器的邏輯
先了解一下優化器
選擇索引是優化器的工作,而優化器選擇索引的目的,是找到一個最優的執行方案,并用最小的代價去執行語句。在數據庫里面,掃描行數是影響執行代價的因素之一。掃描的行數越少,意味著訪問磁盤數據的次數越少,消耗的 CPU 資源越少(掃描行數并不是唯一的判斷標準,優化器還會結合是否使用臨時表、是否排序等因素進行綜合判斷)
下面只討論掃描行數帶來的影響
那么優化器是怎么去估算需要掃描多少行?
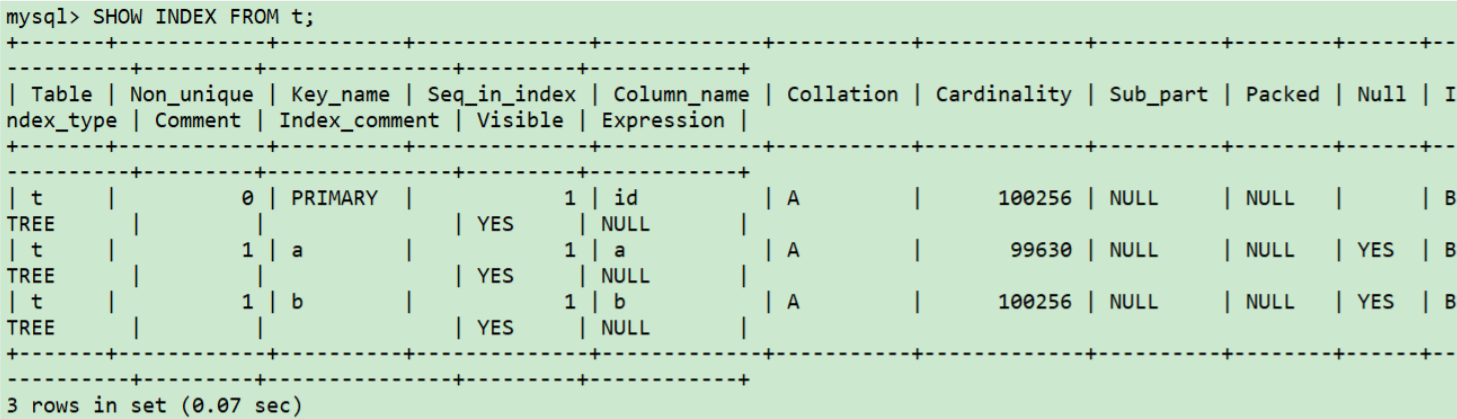
我們可以通過命令看到有一個Cardinality(基數),選擇索引需要掃描的行數就是通過它來判斷的,它代表一個索引上不同的值的個數,值越大說明區分度越高,那么越有可能走這個索引
優化器的選擇一定對么?
上面看到針對下面這個sql,優化器覺得全表掃描更合適,但實際上真的是速度最快的么?
select * from t where a between 10000 and 20000;
我們實際執行一下:

不接受優化器的建議,強行走a索引執行一下:

重點看3個指標:Query_time(執行耗時)、Rows_sent(返回行數)、Rows_examined(掃描/行數)
我們發現強行走索引a其實更快,實際掃描行數也少。那么為什么優化器不走索引a呢?
我們再執行一個命令(更新表的統計信息):
ANALYZE TABLE t;
然后我們再看一下執行計劃:
explain select * from t where a between 10000 and 20000;
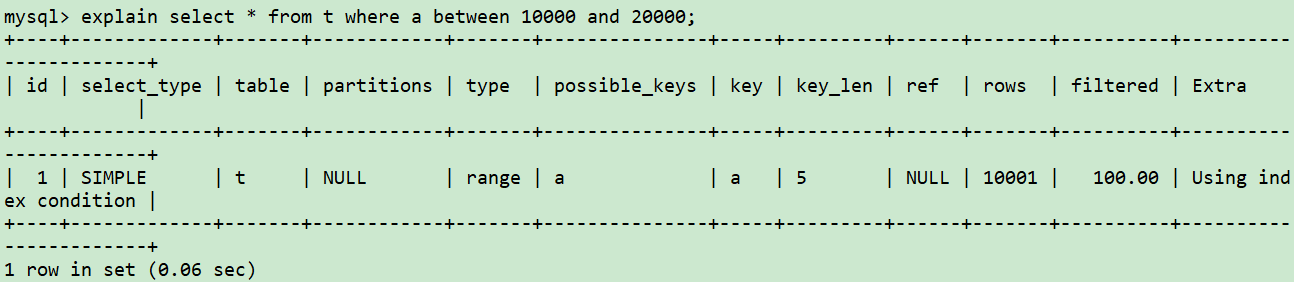
發現優化器竟然又選擇了索引a,說明是因為統計信息不準確,沒有及時更新導致優化器進行了錯誤的選擇。
接著實際執行一下:
select * from t where a between 10000 and 20000;

我們發現實際的掃描行數和預估的掃描行數對上了,并且也確實走了索引a,耗時也降下來了
最后我們再看一下索引的統計信息
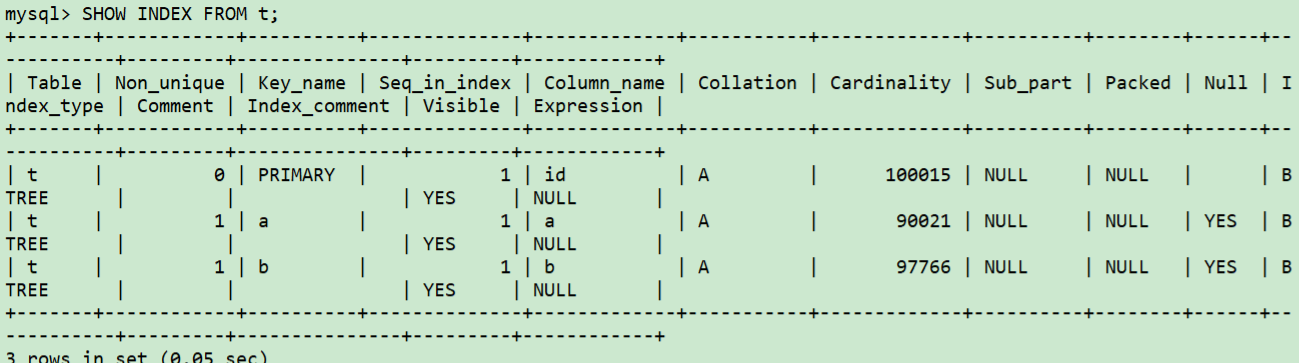
統計信息確實和上面不一樣了,更新了。但是這里有個問題是:雖然統計信息不一樣了(能確保確實更新索引統計信息的sql起作用了)但統計信息和一開始也差不多,為什么Cardinality值差不多的情況下,優化器做出了不一樣的選擇?
因為實際上表數據經歷了大量的刪除、新增操作,Cardinality不會更新一些還未提交的事務數據,所以看似基數差不多,實際上基數不一樣。優化器對主鍵的判斷是基于實際表行數來判斷的,所以主鍵的判斷是準的,不準的是其他索引的統計信息。
總結
本文討論了Mysql(InnoDB)在索引統計信息不準確或更新不及時的情況下,優化器基于統計信息進行粗估的執行計劃,可能會選錯索引。
我們一般應對的方法如下:
- 更新索引統計信息
- 修改SQL語句強制走固定索引
- 新增索引(比如上面新增一個索引a,b)
- 刪除索引(假設優化器選擇了索引b,確保該索引沒有其他作用的前提下,那么刪掉索引b,可能就會走索引a了)
![[250414] ArcoLinux 項目宣布逐步結束](http://pic.xiahunao.cn/[250414] ArcoLinux 項目宣布逐步結束)




CAS與JUC組件)













