1. 線性回歸
????????前面介紹了很多分類算法,分類的目標變量是標稱型數據,回歸是對連續型的數據做出預測。
標稱型數據(Nominal Data)是統計學和數據分析中的一種數據類型,它用于分類或標記不同的類別或組別,數據點之間并沒有數值意義上的距離或順序。例如,顏色(紅、藍、綠)、性別(男、女)或產品類別(A、B、C)。
標稱數據的特點:
-
無序性:標稱數據的各個類別之間沒有固有的順序關系。例如,“性別”可以分為“男”和“女”,但“男”和“女”之間不存在大小、高低等順序關系。
-
非數值性:標稱數據不能進行數學運算,因為它們沒有數值含義。你不能對“顏色”或“品牌”這樣的標稱數據進行加減乘除。
-
多樣性:標稱數據可以有很多不同的類別,具體取決于研究的主題或數據收集的目的。
-
比如西瓜的顏色,紋理,敲擊聲響這些數據就屬于標稱型數據,適用于西瓜分類
連續型數據(Continuous Data)表示在某個范圍內可以取任意數值的測量,這些數據點之間有明確的數值關系和距離。例如,溫度、高度、重量等
連續型數據的特點包括:
-
可測量性:連續型數據通常來源于物理測量,如長度、重量、溫度、時間等,這些量是可以精確測量的。
-
無限可分性:連續型數據的取值范圍理論上是無限可分的,可以無限精確地細分。例如,你可以測量一個物體的長度為2.5米,也可以更精確地測量為2.53米,甚至2.5376米,等等。
-
數值運算:連續型數據可以進行數學運算,如加、減、乘、除以及求平均值、中位數、標準差等統計量。
在數據分析中,連續型數據的處理和分析方式非常豐富,常見的有:
-
描述性統計:計算均值、中位數、眾數、標準差、四分位數等,以了解數據的中心趨勢和分布情況。
-
概率分布:通過擬合概率分布模型,如正態分布、指數分布、伽瑪分布等,來理解數據的隨機特性。
-
圖形表示:使用直方圖、密度圖、箱線圖、散點圖等來可視化數據的分布和潛在的模式。
-
回歸分析:建立連續型變量之間的數學關系,預測一個或多個自變量如何影響因變量。
-
比如西瓜的甜度,大小,價格這些數據就屬于連續型數據,可以用于做回歸。
1.1?什么是回歸
????????回歸的目的是預測數值型的目標值y。最直接的辦法是依據輸入x寫出一個目標值y的計算公式。假如你想預測小姐姐男友汽車的功率,可能會這么計算:
????????HorsePower = 0.0015 * annualSalary - 0.99 * hoursListeningToPublicRadio,寫成中文就是:小姐姐男友汽車的功率 = 0.0015 * 小姐姐男友年薪 - 0.99 * 收聽公共廣播的時間
????????這就是所謂的回歸方程(regression equation),其中的0.0015和-0.99稱為回歸系數(regression weights),**求這些回歸系數的過程就是回歸**。一旦有了這些回歸系數,再給定輸入,做預測就非常容易了。具體的做法是用回歸系數乘以輸入值,再將結果全部加在一起,就得到了預測值。
1.2?線性回歸
????????說到回歸,一般都是指線性回歸(linear regression)。線性回歸意味著可以將輸入項分別乘以一些常量,再將結果加起來得到輸出。線性回歸是機器學習中一種有監督學習的算法,回歸問題主要關注的是因變量(需要預測的值)和一個或多個數值型的自變量(預測變量)之間的關系。
????????需要預測的值:即目標變量target,y影響目標變量的因素:X_1,X_2...X_n,可以是連續值也可以是離散值,因變量和自變量之間的關系:即模型,model,就是我們要求解的,比如1個包子是2元 3個包子是6元 預測5個包子多少錢。
????????列出方程: y=wx+b,帶入:2=w*1+b,6=w*3+b,輕易求得 w=2 b=0,模型(x與y的關系): y=2*x+0,預測 x=5 時 target_y=2*5+0=10元
????????上面的方程式我們人類很多年以前就知道了,但是不叫人工智能算法,因為數學公式是理想狀態,是100%對的,而人工智能是一種基于實際數據求解最優最接近實際的方程式,這個方程式帶入實際數據計算后的結果是有誤差的。
????????人工智能中的線性回歸:數據集中,往往找不到一個完美的方程式來100%滿足所有的y目標,我們就需要找出一個最接近真理的方程式。
????????比如:有這樣一種植物,在不同的溫度下生長的高度是不同的,對不同溫度環境下,幾顆植物的環境溫度(橫坐標),植物生長高度(縱坐標)的關系進行了采集,并且將它們繪制在一個二維坐標中,其分布如下所示:
????????坐標分別為[4.2, 3.8],[4.2, 2.7],[2.7, 2.4],[0.8, 1.0],[3.7, 2.8],[1.7, 0.9],[3.2, 2.9]。
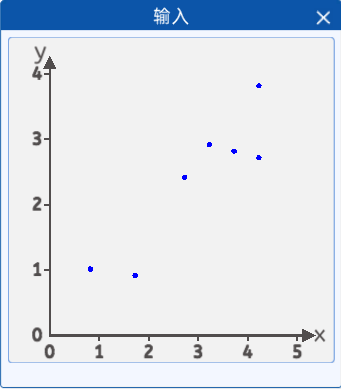
????????我們發現這些點好像分布在一條直線的附近,那么我們能不能找到這樣一條直線,去“擬合”這些點,這樣的話我們就可以通過獲取環境的溫度大概判斷植物在某個溫度下的生長高度了。
????????于是我們的最終目的就是通過這些散點來擬合一條直線,使該直線能盡可能準確的描述環境溫度與植物高度的關系。
1.3?損失函數
????????數據: [[4.2, 3.8],[4.2, 2.7],[2.7, 2.4],[0.8, 1.0],[3.7, 2.8],[1.7, 0.9],[3.2, 2.9]],我們假設 這個最優的方程是:
????????這樣的直線隨著w和b的取值不同 ?可以畫出無數條,在這無數條中,哪一條是比較好的呢?
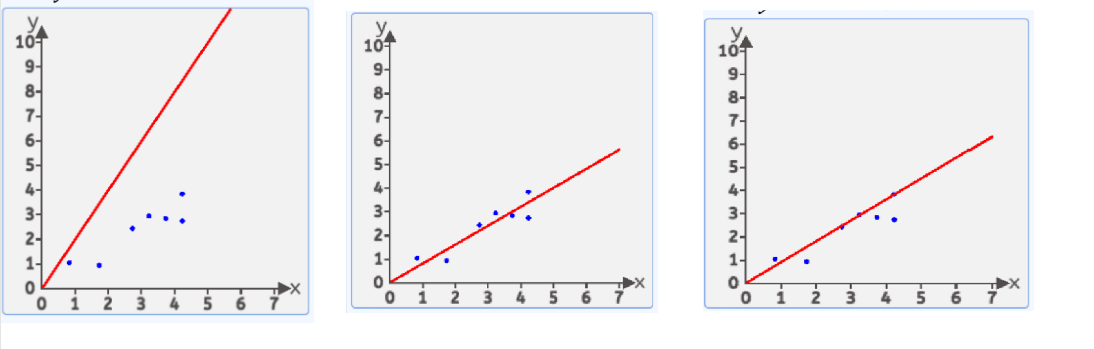
????????我們有很多方式認為某條直線是最優的,其中一種方式:均方差就是每個點到線的豎直方向的距離平方 求和 在平均 最小時 這條直接就是最優直線
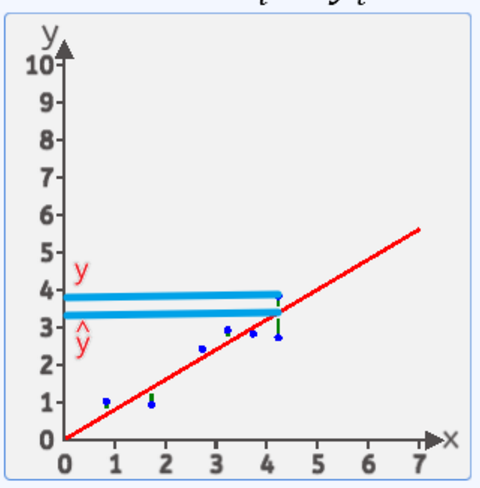
????????假設: y=wx+b,把x_1,x_2,x_3...帶入進去 然后得出:y_1^,=wx_1+b;y_2^,=wx_2+b;y_3^,=wx_3+b ...
????????然后計算{y_1-y_1^,} 表示第一個點的真實值和計算值的差值 ,然后把第二個點,第三個點...最后一個點的差值全部算出來,有的點在上面有點在下面,如果直接相加有負數和正數會抵消,體現不出來總誤差,平方后就不會有這個問題了。
????????總誤差(也就是傳說中的損失):,平均誤差(總誤差會受到樣本點的個數的影響,樣本點越多,該值就越大,所以我們可以對其平均化,求得平均值,這樣就能解決樣本點個數不同帶來的影響)。
????????這樣就得到了傳說中的損失函數:,怎么樣讓這個損失函數的值最小呢?我們先假設b=0 (等后面多元方程求解這個b就解決了)
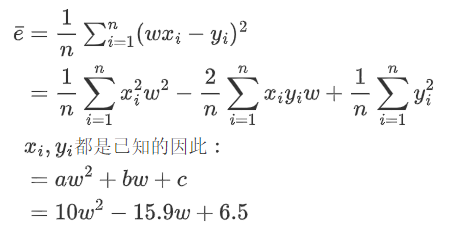
????????然后就簡單了 ?算w在什么情況下損失函數的值最小(初中的拋物線求頂點的橫坐標,高中求導數為0時)
????????求得w=0.795時損失函數取得最小值,那我們最終那個真理函數(最優解)就得到了,,在這個求解的過程中,我們是假設了b=0的 ? 學了多元方程求解后 ?這個b也是可以求解出來的,因為一元方程是一種特殊的多元方程。
????????總結:
????????1. 實際數據中 x和y組成的點 不一定是全部落在一條直線上;
????????2. 我們假設有這么一條直線 y=wx+b 是最符合描述這些點的;
????????3. 最符合的條件就是這個方程帶入所有x計算出的所有y與真實的y值做 均方差計算;
????????4. 找到均方差最小的那個w;
????????5. 這樣就求出了最優解的函數(前提條件是假設b=0)。
1.4?多參數回歸
????????上面案例中,實際情況下,影響這種植物高度的不僅僅有溫度,還有海拔,濕度,光照等等因素:實際情況下,往往影響結果y的因素不止1個,這時x就從一個變成了n個,x_1,x_2,x_3...x_n 上面的思路是對的,但是求解的公式就不再適用了。
????????案例: 假設一個人健康程度怎么樣,由很多因素組成
| 被愛 | 學習指數 | 抗壓指數 | 運動指數 | 飲食情況 | 金錢 | 心態 | 壓力 | 健康程度 |
|---|---|---|---|---|---|---|---|---|
| 0 | 14 | 8 | 0 | 5 | -2 | 9 | -3 | 339 |
| -4 | 10 | 6 | 4 | -14 | -2 | -14 | 8 | -114 |
| -1 | -6 | 5 | -12 | 3 | -3 | 2 | -2 | 30 |
| 5 | -2 | 3 | 10 | 5 | 11 | 4 | -8 | 126 |
| -15 | -15 | -8 | -15 | 7 | -4 | -12 | 2 | -395 |
| 11 | -10 | -2 | 4 | 3 | -9 | -6 | 7 | -87 |
| -14 | 0 | 4 | -3 | 5 | 10 | 13 | 7 | 422 |
| -3 | -7 | -2 | -8 | 0 | -6 | -5 | -9 | -309 |
| 11 | 14 | 8 | 10 | 5 | 10 | 8 | 1 | ? |
求如果karen的各項指標是:被愛:11 學習指數:14 ?抗壓指數:8 ?運動指數:10 ?飲食水平:5 ?金錢:10 心態:8 壓力:1,那么karen的健康程度是多少?
????????直接能想到的就是八元一次方程求解:
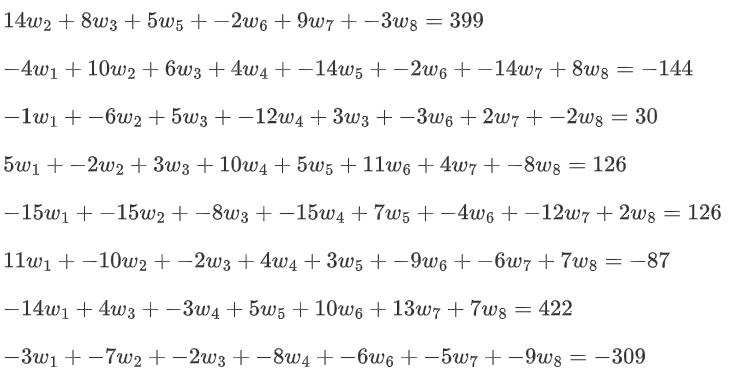
????????解出權重然后帶入即可求出karen的健康程度,權重即重要程度,某一項的權重越大說明它影響最終健康的程度越大,但是這有一個前提:這個八元一次方程組得有解才行。因此我們還是按照損失最小的思路來求權重
????????多元線性回歸:;b是截距,我們也可以使用
來表示只要是個常量就行:
????????;
????????那么損失函數就是:
????????如何求得對應的使得loss最小呢? 數學家高斯給出了答案。
1.5?最小二乘法MSE
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x0 | y |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 14 | 8 | 0 | 5 | -2 | 9 | -3 | 1 | 339 |
| -4 | 10 | 6 | 4 | -14 | -2 | -14 | 8 | 1 | -114 |
| -1 | -6 | 5 | -12 | 3 | -3 | 2 | -2 | 1 | 30 |
| 5 | -2 | 3 | 10 | 5 | 11 | 4 | -8 | 1 | 126 |
| -15 | -15 | -8 | -15 | 7 | -4 | -12 | 2 | 1 | -395 |
| 11 | -10 | -2 | 4 | 3 | -9 | -6 | 7 | 1 | -87 |
| -14 | 0 | 4 | -3 | 5 | 10 | 13 | 7 | 1 | 422 |
| -3 | -7 | -2 | -8 | 0 | -6 | -5 | -9 | 1 | -309 |
1.5.1 矩陣相關公式

,
,
1.5.2?最小二乘法
????????
????????
????????這就是傳說中的最小二乘法公式是歐幾里得范數的平方,也就是每個元素的平方相加。
????????雖然這個案例中n=8,但是常常令n=2,因為是一個常數 求最小值時n隨便取哪個正數都不會影響W結果,但是求導過程可以約掉前面的系數,會加速后面的計算。
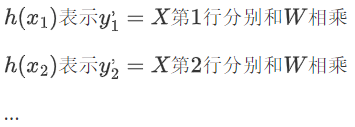
????????高斯把公式給了,但是何時loss最小呢?
????????1. 二次方程導數為0時最小:
????????2. 先展開矩陣乘法:
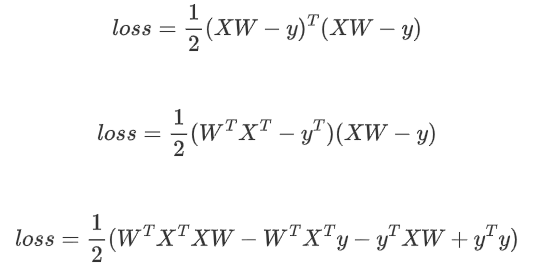
????????3. 進行求導(注意X,y都是已知的,W是未知的):
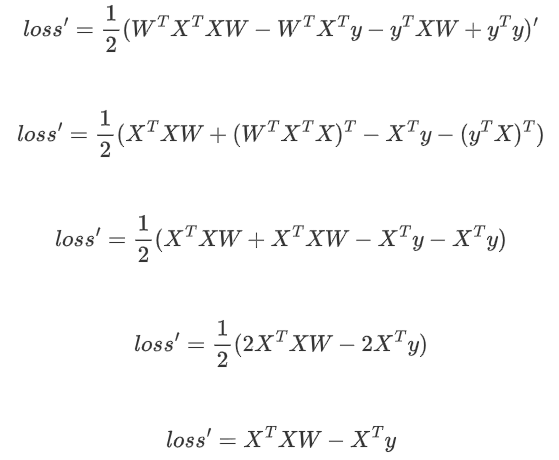
????????4. 令導數:
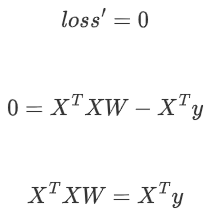
????????5. 矩陣沒有除法,使用逆矩陣轉化:
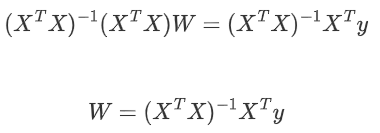
????????第二種方式鏈式求導(推薦,因為后期深度學習全是這種)
????????內部函數是:;外部函數是 :
;其中:
。
????????外部函數的導數:;
????????內部函數的導數:。
????????應用鏈式法則,我們得到最終的梯度:
????????????????????????
????????有了W,回到最初的問題,求如果karen的各項指標是:
????????被愛:11 學習指數:14 抗壓指數:8 運動指數:10 飲食水平:5 金錢:10 權利:8 壓力:1,那么karen的健康程度是多少?
????????分別用W各項乘以新的X 就可以得到y健康程度。
1.5.3 API 介紹
sklearn.linear_model.LinearRegression()
功能: 普通最小二乘法線性回歸, 權重和偏置是直接算出來的,對于數量大的不適用,因為計算量太大,計算量太大的適合使用遞度下降法參數:
fit_intercept bool, default=True是否計算此模型的截距(偏置)。如果設置為False,則在計算中將不使用截距(即,數據應中心化)。
屬性:
coef_ 回歸后的權重系數
intercept_ 偏置print("權重系數為:\n", estimator.coef_) #權重系數與特征數一定是同樣的個數。
print("偏置為:\n", estimator.intercept_)示例:
from sklearn.linear_model import LinearRegression
import numpy as np
data=np.array([[0,14,8,0,5,-2,9,-3,399],[-4,10,6,4,-14,-2,-14,8,-144],[-1,-6,5,-12,3,-3,2,-2,30],[5,-2,3,10,5,11,4,-8,126],[-15,-15,-8,-15,7,-4,-12,2,-395],[11,-10,-2,4,3,-9,-6,7,-87],[-14,0,4,-3,5,10,13,7,422],[-3,-7,-2,-8,0,-6,-5,-9,-309]])
x=data[:,0:8]
y=data[:,8:]
estimator=LinearRegression(fit_intercept=False)
estimator.fit(x,y)
print("權重系數為:\n", estimator.coef_) #權重系數與特征數一定是同樣的個數。
print("偏置為:\n", estimator.intercept_)
x_new=[[11,14,8,10,5,10,8,1]]
y_predict=estimator.predict(x)
print("預測結果:\n",y_predict)
print(-3*0.4243965-7*7.32281732-2*15.05217218-8*3.5996297+0*12.05805264-6*1.76972959-5*17.0276393-9*11.31212591)1.6?梯度下降
1.6.1?梯度下降概念
????????正規方程求解的缺:之前利用正規方程求解的W是最優解的原因是MSE這個損失函數是凸函數。但是,機器學習的損失函數并非都是凸函數,設置導數為0會得到很多個極值,不能確定唯一解,MSE還有一個問題,當數據量和特征較多時,矩陣計算量太大。
????????1. 假設損失函數是這樣的,利用正規方程求解導數為0會得到很多個極值,不能確定唯一解
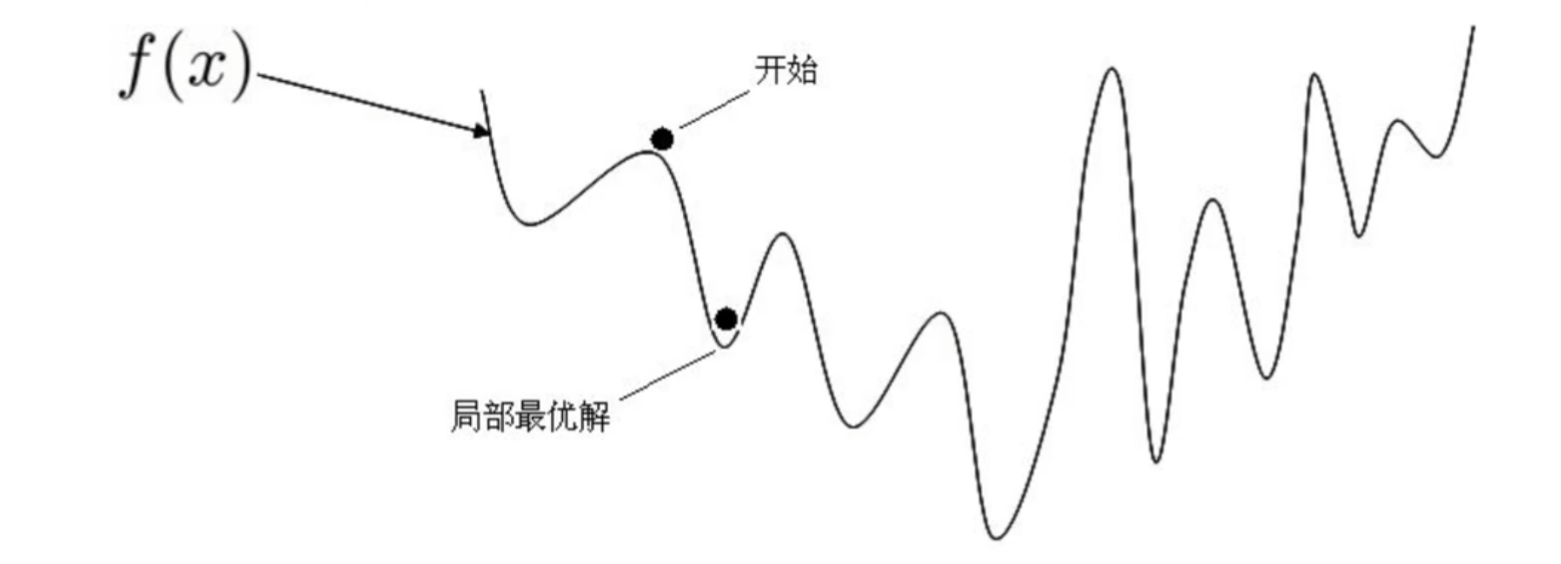
????????2. 使用正規方程求解要求X的特征維度
不能太多,逆矩陣運算時間復雜度為
, 也就是說如果特征x的數量翻倍,計算時間就是原來的
倍,8倍太恐怖了,假設2個特征1秒,4個特征8秒,8個特征64秒,16個特征512秒,而往往現實生活中的特征非常多,尤其是大模型,運行時間太長了,所以 正規方程求出最優解并不是機器學習和深度學習常用的手段,梯度下降算法更常用。
????????梯度下降:
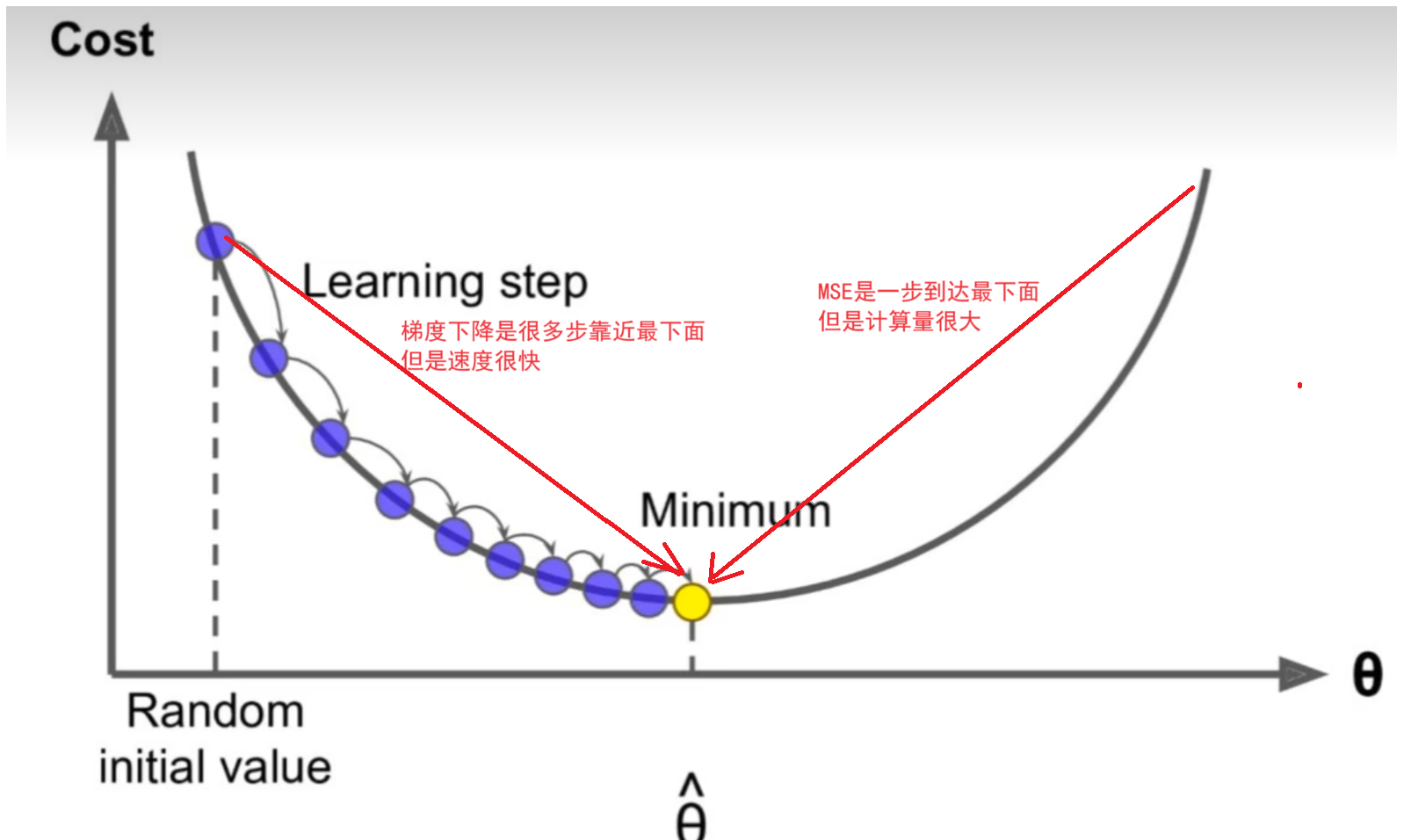
????????假設你在一個陌生星球的山地上,你想找到一個谷底,那么肯定是想沿著向下的坡行走,如果想盡快的走到谷底,那么肯定是要沿著最陡峭的坡下山。每走一步,都找到這里位置最陡峭的下坡走下一步,這就是梯度下降。
????????在這個比喻中,梯度就像是山上的坡度,告訴我們在當前位置上地勢變化最快的方向。為了盡快走向谷底,我們需要沿著最陡峭的坡向下行走,而梯度下降算法正是這樣的方法。
????????每走一步,我們都找到當前位置最陡峭的下坡方向,然后朝著該方向邁進一小步。這樣,我們就在梯度的指引下逐步向著谷底走去,直到到達谷底(局部或全局最優點)。
????????在機器學習中,梯度表示損失函數對于模型參數的偏導數。具體來說,對于每個可訓練參數,梯度告訴我們在當前參數值下,沿著每個參數方向變化時,損失函數的變化率。通過計算損失函數對參數的梯度,梯度下降算法能夠根據梯度的信息來調整參數,朝著減少損失的方向更新模型,從而逐步優化模型,使得模型性能更好。
????????在這個一元二次方程中,損失函數對于參數 w 的梯度就是關于 w 點的切線斜率。梯度下降算法會根據該斜率的信息來調整參數 w,使得損失函數逐步減小,從而找到使得損失最小化的參數值,優化模型的性能。
????????梯度下降法(Gradient Descent)是一個算法,但不是像多元線性回歸那樣是一個具體做回歸任務的算法,而是一個非常通用的優化算法來幫助一些機器學習算法求解出最優解,所謂的通用就是很多機器學習算法都是用梯度下降,甚至深度學習也是用它來求解最優解。 所有優化算法的目的都是期望以最快的速度把模型參數W求解出來,梯度下降法就是一種經典常用的優化算法。
1.6.2?梯度下降步驟
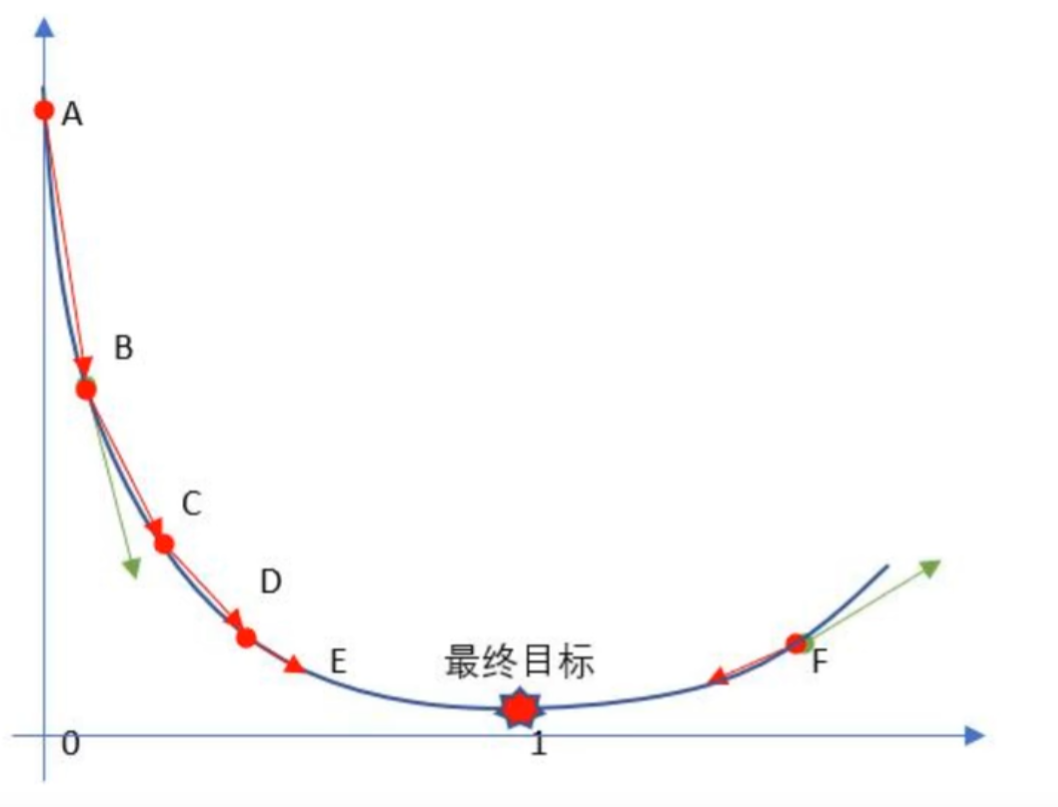
????????梯度下降流程就是“猜"正確答案的過程:
????????1. Random隨機數生成初始W,隨機生成一組成正態分布的數值w_0,w_1,w_2....w_n,這個隨機是成正太態布的(高斯說的);
????????2. 求梯度g,梯度代表曲線某點上的切線的斜率,沿著切線往下就相當于沿著坡度最陡峭的方向下降;
????????3. if g < 0,w變大,if g >0,w變小(目標左邊是斜率為負右邊為正 );
????????4. 判斷是否收斂,如果收斂跳出迭代,如果沒有達到收斂,回第2步再次執行2~4步收斂的判斷標準是:隨著迭代進行查看損失函數Loss的值,變化非常微小甚至不再改變,即認為達到收斂;
????????5. 上面第4步也可以固定迭代次數。
1.6.3?梯度下降公式
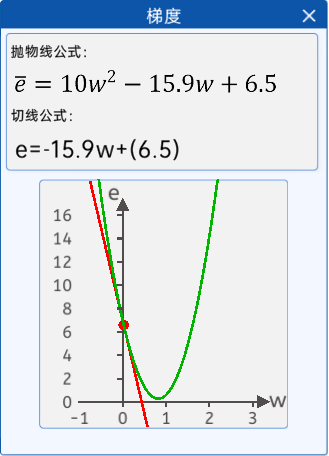
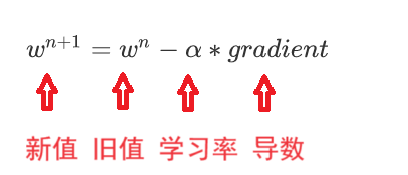
????????隨機給一個w初始值,然后就不停的修改它,直到達到拋物線最下面附近,比如:w=0.2
????????w=w-0.01*w為0.2時的梯度(導數) 假設算出來是 0.24;
????????w=w-0.01*w為0.24時的梯度(導數) 假設算出來是 0.33;
????????w=w-0.01*w為0.33時的梯度(導數) 假設算出來是 0.51;
????????w=w-0.01*w為0.51時的梯度(導數) 假設算出來是 0.56;
????????w=w-0.01*w為0.56時的梯度(導數) 假設算出來是 0.58;
????????w=w-0.01*w為0.58時的梯度(導數) 假設算出來是 0.62。
????????就這樣一直更新下去,會在真實值附近,我們可以控制更新的次數。
????????關于隨機的w在左邊和右邊問題:因為導數有正負,如果在左邊導數是負數減去負數就是加往右移動,如果在右邊導數是正數減去正數就是減往左移動。
1.6.4?學習率
????????根據我們上面講的梯度下降公式,我們知道α是學習率,設置大的學習率α;每次調整的幅度就大,設置小的學習率α;每次調整的幅度就小,然而如果步子邁的太大也會有問題! 學習率大,可能一下子邁過了,到另一邊去了(從曲線左半邊跳到右半邊),繼續梯度下降又邁回來,使得來來回回震蕩。步子太小呢,就像蝸牛一步步往前挪,也會使得整體迭代次數增加。
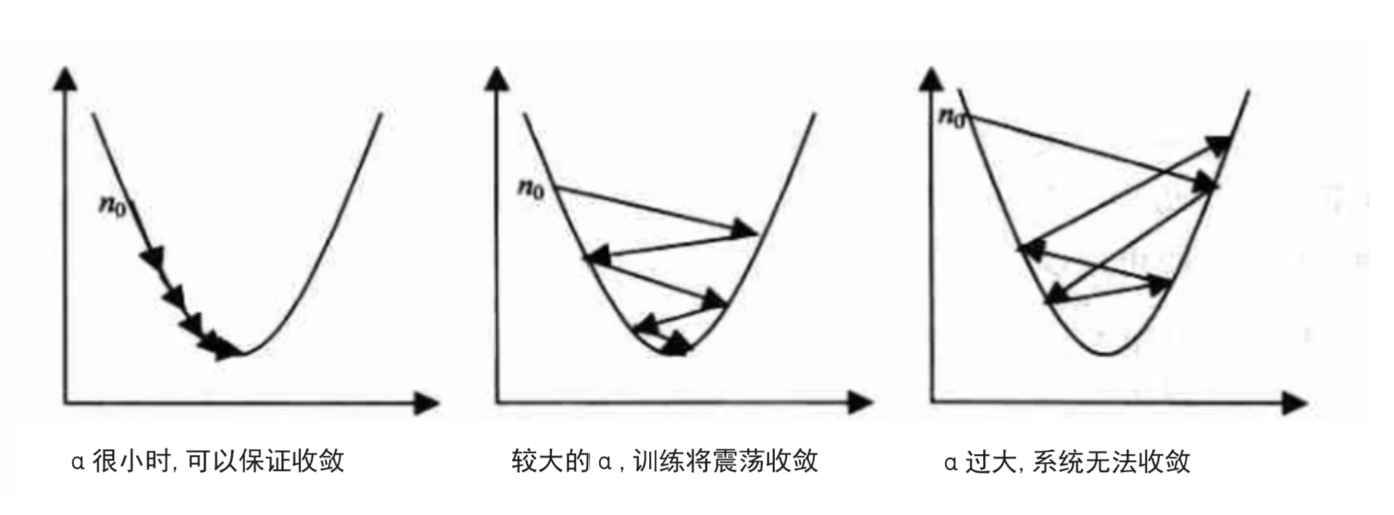
????????學習率的設置是門一門學問,一般我們會把它設置成一個小數,0.1、0.01、0.001、0.0001,都是常見的設定數值(然后根據情況調整)。一般情況下學習率在整體迭代過程中是不變,但是也可以設置成隨著迭代次數增多學習率逐漸變小,因為越靠近山谷我們就可以步子邁小點,可以更精準的走入最低點,同時防止走過。還有一些深度學習的優化算法會自己控制調整學習率這個值。
1.6.5?實現梯度下降
????????我們自己用代碼親自實現一遍梯度下降,之后使用API時就明白它底層的核心實現過程了。
????????1. 假設損失函數是只有一個特征的拋物線:
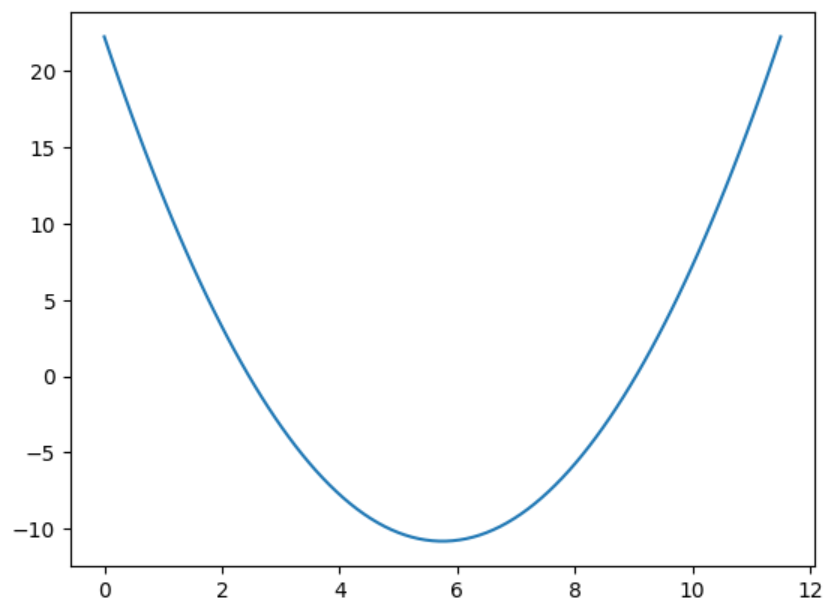
????????我們要求解這個拋物線最小值時的橫坐標的值:
#1.列損失函數 畫出函數圖像
loss=lambda w_1:(w_1-3.5)**2-4.5*w_1+10
w_1=np.linspace(0,11.5,100)
plt.plot(w_1,loss(w_1))
#2.求這個損失函數的最小值:梯度下降
def cb():g=lambda w_1:2*(w_1-3.5)-4.5#導函數t0,t1=1,100 alpha=t0/t1#學習率,設置大和過大會導致震蕩或者無法收斂w_1=np.random.randint(0,10,size=1)[0]#隨機初始值#控制更新次數for i in range(1000):alpha=t0/(i+t1)#控制學習率 逐步變小w_1=w_1-alpha*g(w_1)#梯度下降公式print("更新后的w_1:",w_1)
cb()????????2. 假設損失函數是有兩個特征的椎體(我畫不來 假裝下面是個椎體):
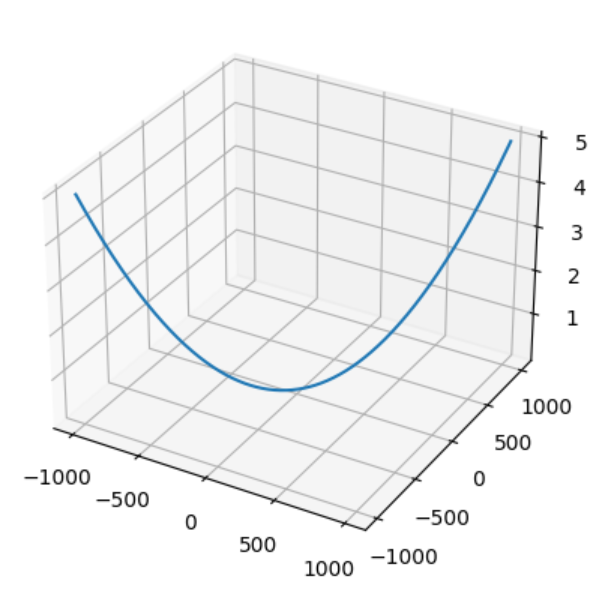
????????上一個案例:一個w_1更新梯度時是拋物線對于求導然后更新
,這個案例是:兩個
,那么我們再分別更新
時 就是對于另一個求偏導,比如隨機初始:
。
????????第一次更新時:
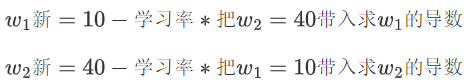
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
#1.列損失函數 畫出函數圖像
loss=lambda w_1,w_2:(w_1-3.5)**2+(w_2-2)**2+2*w_2-4.5*w_1+3*w_1*w_2+20
#2.求這個損失函數的最小值:梯度下降
def cb2():t0,t1=1,100 alpha=t0/t1#學習率,設置大和過大會導致震蕩或者無法收斂w_1=10#np.random.randint(0,100,size=1)[0]#隨機初始值w_2=40#np.random.randint(0,100,size=1)[0]#隨機初始值dw_1=lambda w_1,w_2:2*(w_1-3.5)+3*w_2-4.5#w_1的導函數dw_2=lambda w_1,w_2:3*w_1+2*w_2-2#w_2的導函數#控制更新次數for i in range(100):alpha=t0/(i+t1)#控制學習率 逐步變小w_1_=w_1#保存起來 防止梯度下降過程中w_1和w_2的值發生改變w_2_=w_2#w_1=w_1-alpha*dw_1(w_1_,w_2_)#梯度下降公式w_2=w_2-alpha*dw_2(w_1_,w_2_)print("更新后的w_1,w_2:",w_1,w_2)
cb2()1.6.6?sklearn梯度下降
????????官方的梯度下降API常用有三種:
????????1. 批量梯度下降BGD(Batch Gradient Descent) ;
????????2. 小批量梯度下降MBGD(Mini-BatchGradient Descent);
????????3. 隨機梯度下降SGD(Stochastic Gradient Descent)。
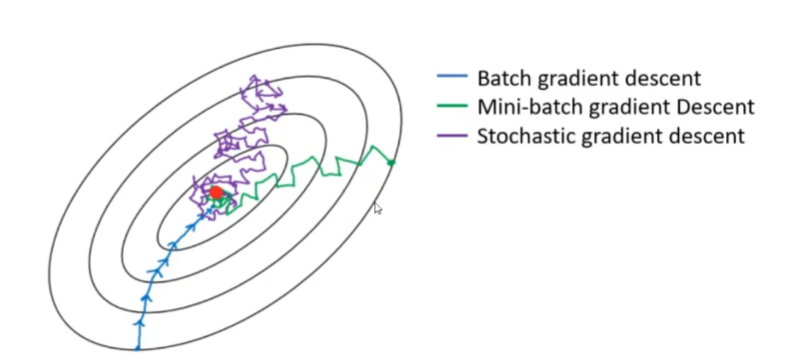
????????三種梯度下降有什么不同呢?
????????Batch Gradient Descent (BGD):在這種情況下,每一次迭代都會使用全部的訓練樣本計算梯度來更新權重。這意味著每一步梯度更新都是基于整個數據集的平均梯度。這種方法的優點是每次更新的方向是最準確的,但缺點是計算量大且速度慢,尤其是在大數據集上。
????????Mini-Batch Gradient Descent (MBGD):這種方法介于批量梯度下降和隨機梯度下降之間。它不是用全部樣本也不是只用一個樣本,而是每次迭代從數據集中隨機抽取一小部分樣本(例如,從500個樣本中選取32個),然后基于這一小批樣本的平均梯度來更新權重。這種方法在準確性和計算效率之間取得了一個平衡。
????????Stochastic Gradient Descent (SGD):在隨機梯度下降中,每次迭代僅使用隨機單個樣本(或有時稱為“例子”)來計算梯度并更新權重。這種方法能夠更快地收斂,但由于每次更新都基于單個樣本,所以會導致權重更新路徑不穩定。
1.6.7?批量梯度下降BGD
????????批量梯度下降是一種用于機器學習和深度學習中的優化算法,它用于最小化損失函數(目標函數),批量梯度下降使用整個訓練數據集來計算梯度并更新模型參數。
????????原理:批量梯度下降的基本思想是在每個迭代步驟中使用所有訓練樣本來計算損失函數的梯度,并據此更新模型參數。這使得更新方向更加準確,因為它是基于整個數據集的梯度,而不是像隨機梯度下降那樣僅基于單個樣本。
????????更新規則:假設我們有一個包含 ( m ) 個訓練樣本的數據集,其中
是輸入特征,
是對應的標簽。我們的目標是最小化損失函數
相對于模型參數
的值。
????????損失函數可以定義為:;其中
是模型對第
個樣本的預測輸出。
????????批量梯度下降的更新規則為:;對于
(其中
是特征的數量),并且
是學習率。
????????特點
-
準確性:由于使用了所有訓練樣本,所以得到的梯度是最準確的,這有助于找到全局最小值。
-
計算成本:每次更新都需要遍歷整個數據集,因此計算量較大,特別是在數據集很大的情況下。
-
收斂速度:雖然每一步的更新都是準確的,但由于計算成本較高,實際收斂到最小值的速度可能不如其他方法快。
-
內存需求:需要在內存中存儲整個數據集,對于大型數據集來說可能成為一個問題。
使用場景
-
小數據集:當數據集較小時,批量梯度下降是一個不錯的選擇,因為它能保證較好的收斂性和準確性。
-
不需要實時更新:如果模型不需要實時更新,例如在離線訓練場景下,批量梯度下降是一個合理的選擇。
實現注意事項
-
選擇合適的學習率:選擇合適的學習率對于快速且穩定的收斂至關重要。如果學習率太小,收斂速度會很慢;如果太大,則可能會導致不收斂。
-
數據預處理:對數據進行標準化或歸一化,可以提高批量梯度下降的效率。
-
監控損失函數:定期檢查損失函數的變化趨勢,確保算法正常工作并朝著正確的方向前進。
1.6.8?隨機梯度下降SGD
????????隨機梯度下降(Stochastic Gradient Descent, SGD)是一種常用的優化算法,在機器學習和深度學習領域中廣泛應用。與批量梯度下降(BGD)和小批量梯度下降(MBGD)相比,SGD 每一步更新參數時僅使用單個訓練樣本,這使得它更加靈活且計算效率更高,特別是在處理大規模數據集時。
????????基本步驟
-
初始化參數:選擇一個初始點作為參數向量
的初始值。
-
選擇樣本:隨機選取一個訓練樣本
。
-
計算梯度:使用所選樣本
的梯度
。
-
更新參數:根據梯度的方向來更新參數
;其中
是學習率,決定了每次迭代時參數更新的步長。
-
重復步驟 2 到 4:對所有的訓練樣本重復此過程,直到完成一個完整的 epoch(即所有樣本都被訪問過一次)。
-
重復多個 epoch:重復上述過程,直到滿足某個停止條件,比如達到最大迭代次數或者梯度足夠小。
-
輸出結果:輸出最小化損失函數后的最優參數
。
????????數學公式:假設我們有一個包含 (m) 個樣本的數據集,其中
是第
個樣本的特征向量,
是對應的標簽。
????????對于線性回歸問題,損失函數可以定義為均方誤差 (Mean Squared Error, MSE):
是模型對第 i個樣本的預測值。
????????梯度對于每個參數
的偏導數可以表示為:
。
????????更新規則:參數的更新規則為:
。
????????注意事項:
????????學習率:需要適當設置,太大會導致算法不收斂,太小則收斂速度慢;
????????隨機性:?每次迭代都從訓練集中隨機選擇一個樣本,這有助于避免陷入局部最小值;
????????停止條件: 可以是達到預定的最大迭代次數,或者梯度的范數小于某個閾值。
????????隨機梯度下降的一個關鍵優勢在于它能夠快速地進行迭代并適應較大的數據集。然而,由于每次只使用一個樣本進行更新,梯度估計可能較為嘈雜,這可能導致更新過程中出現較大的波動。在實際應用中,可以通過減少學習率(例如采用學習率衰減策略)來解決這個問題。
API介紹:
sklearn.linear_model.SGDRegressor()
功能:梯度下降法線性回歸
參數:loss: 損失函數,默認為 ’squared_error’fit_intercept: 是否計算偏置, default=Trueeta0: float, default=0.01學習率初始值learning_rate: str, default=’invscaling’ The learning rate schedule:‘constant’: eta = eta0 學習率為eta0設置的值,保持不變‘optimal’: eta = 1.0 / (alpha * (t + t0)) ‘invscaling’: eta = eta0 / pow(t, power_t)‘adaptive’: eta = eta0, 學習率由eta0開始,逐步變小max_iter: int, default=1000 經過訓練數據的最大次數(又名epoch)shuffle=True 每批次是否洗牌penalty: {‘l2’, ‘l1’, ‘elasticnet’, None}, default=’l2’要使用的懲罰(又稱正則化項)。默認為' l2 ',這是線性SVM模型的標準正則化器。' l1 '和' elasticnet '可能會給模型(特征選擇)帶來' l2 '無法實現的稀疏性。當設置為None時,不添加懲罰。
屬性:
coef_ 回歸后的權重系數
intercept_ 偏置示例:加載加利福尼亞住房數據集,進行回歸預測, 注意網絡。
# 線性回歸 加載加利福尼亞住房數據集,進行回歸預測
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge
from sklearn.metrics import mean_squared_errorfrom sklearn.datasets import fetch_california_housing
# 1)加載數據
housing = fetch_california_housing(data_home="./src")
print(housing)
# 2)劃分訓練集與測試集
x_train, x_test, y_train, y_test = train_test_split(housing.data, housing.target, random_state=22)
# 3)標準化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4)線性回歸預估器
estimator = SGDRegressor(learning_rate="constant", eta0=0.01, max_iter=1000, penalty="l1",loss="squared_error")estimator.fit(x_train, y_train)# 5)得出模型
print("權重系數為:\n", estimator.coef_) #權重系數與特征數一定是同樣的個數。
print("偏置為:\n", estimator.intercept_)# 6)模型評估
y_predict = estimator.predict(x_test)
print("預測的數據集:\n", y_predict)
print("得分:\n",estimator.score(x_test, y_test))
error = mean_squared_error(y_test, y_predict)
print("均方誤差為:\n", error)1.6.9?小批量梯度下降MBGD
????????小批量梯度下降是一種介于批量梯度下降(BGD)與隨機梯度下降(SGD)之間的優化算法,它結合了兩者的優點,在機器學習和深度學習中被廣泛使用。
????????原理:小批量梯度下降的基本思想是在每個迭代步驟中使用一小部分(即“小批量”)訓練樣本來計算損失函數的梯度,并據此更新模型參數。這樣做的好處在于能夠減少計算資源的需求,同時保持一定程度的梯度準確性。
????????更新規則:假設我們有一個包含 ( m ) 個訓練樣本的數據集,其中
是輸入特征,
是對應的標簽。我們將數據集劃分為多個小批量,每個小批量包含 ( b ) 個樣本,其中 ( b ) 稱為批量大小(batch size),通常 ( b ) 遠小于 ( m )。
????????損失函數可以定義為:;其中
是模型對第
個樣本的預測輸出。
????????小批量梯度下降的更新規則為:對于
(其中 n 是特征的數量),并且
是學習率, B 表示當前小批量中的樣本索引集合。
特點
-
計算效率:相比于批量梯度下降,小批量梯度下降每次更新只需要處理一部分數據,減少了計算成本。
-
梯度估計:相比于隨機梯度下降,小批量梯度下降提供了更準確的梯度估計,這有助于更穩定地接近最小值。
-
內存需求:相比批量梯度下降,小批量梯度下降降低了內存需求,但仍然比隨機梯度下降要高。
-
收斂速度與穩定性:小批量梯度下降能夠在保持較快的收斂速度的同時,維持相對較高的穩定性。
使用場景
-
中等規模數據集:當數據集大小適中時,小批量梯度下降是一個很好的折衷方案,既能夠高效處理數據,又能夠保持良好的收斂性。
-
在線學習:在數據流式到達的場景下,小批量梯度下降可以有效地處理新到來的數據批次。
-
分布式環境:在分布式計算環境中,小批量梯度下降可以更容易地在多臺機器上并行執行。
實現注意事項
-
選擇合適的批量大小:批量大小的選擇對性能有很大影響。較大的批量可以減少迭代次數,但計算成本增加;較小的批量則相反。
-
選擇合適的學習率:選擇合適的學習率對于快速且穩定的收斂至關重要。如果學習率太小,收斂速度會很慢;如果太大,則可能會導致不收斂。
-
數據預處理:對數據進行標準化或歸一化,可以提高小批量梯度下降的效率。
-
監控損失函數:定期檢查損失函數的變化趨勢,確保算法正常工作并朝著正確的方向前進。
示例:
# 線性回歸 加載加利福尼亞住房數據集,進行回歸預測
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge
from sklearn.metrics import mean_squared_errorfrom sklearn.datasets import fetch_california_housing
# 1)加載數據
housing = fetch_california_housing(data_home="./src")
print(housing)
# 2)劃分訓練集與測試集
x_train, x_test, y_train, y_test = train_test_split(housing.data, housing.target, random_state=22)
# 3)標準化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)線性回歸預估器
estimator = SGDRegressor(learning_rate="constant", eta0=0.01, max_iter=1000,shuffle=True, penalty="l1")
# 小批量梯度下降
batch_size = 50 # 批量大小
n_batches = len(x_train) // batch_size # 批次數量
for epoch in range(estimator.max_iter):indices = np.random.permutation(len(x_train)) # 隨機打亂樣本順序for i in range(n_batches):start_idx = i * batch_sizeend_idx = (i + 1) * batch_sizebatch_indices = indices[start_idx:end_idx]X_batch = x_train[batch_indices]y_batch = y_train[batch_indices]estimator.partial_fit(X_batch, y_batch) # 更新模型權重# 5)得出模型
print("權重系數為:\n", estimator.coef_) #權重系數與特征數一定是同樣的個數。
print("偏置為:\n", estimator.intercept_)# 6)模型評估
y_predict = estimator.predict(x_test)
print("得分:\n",estimator.score(x_test, y_test))
print("預測的數據集:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("均方誤差為:\n", error)梯度下降優化:
????????1. 標準化:前期數據的預處理,前面有的;
????????2. 正則化:防止過擬合(下面一小節講)。
1.7?欠擬合過擬合
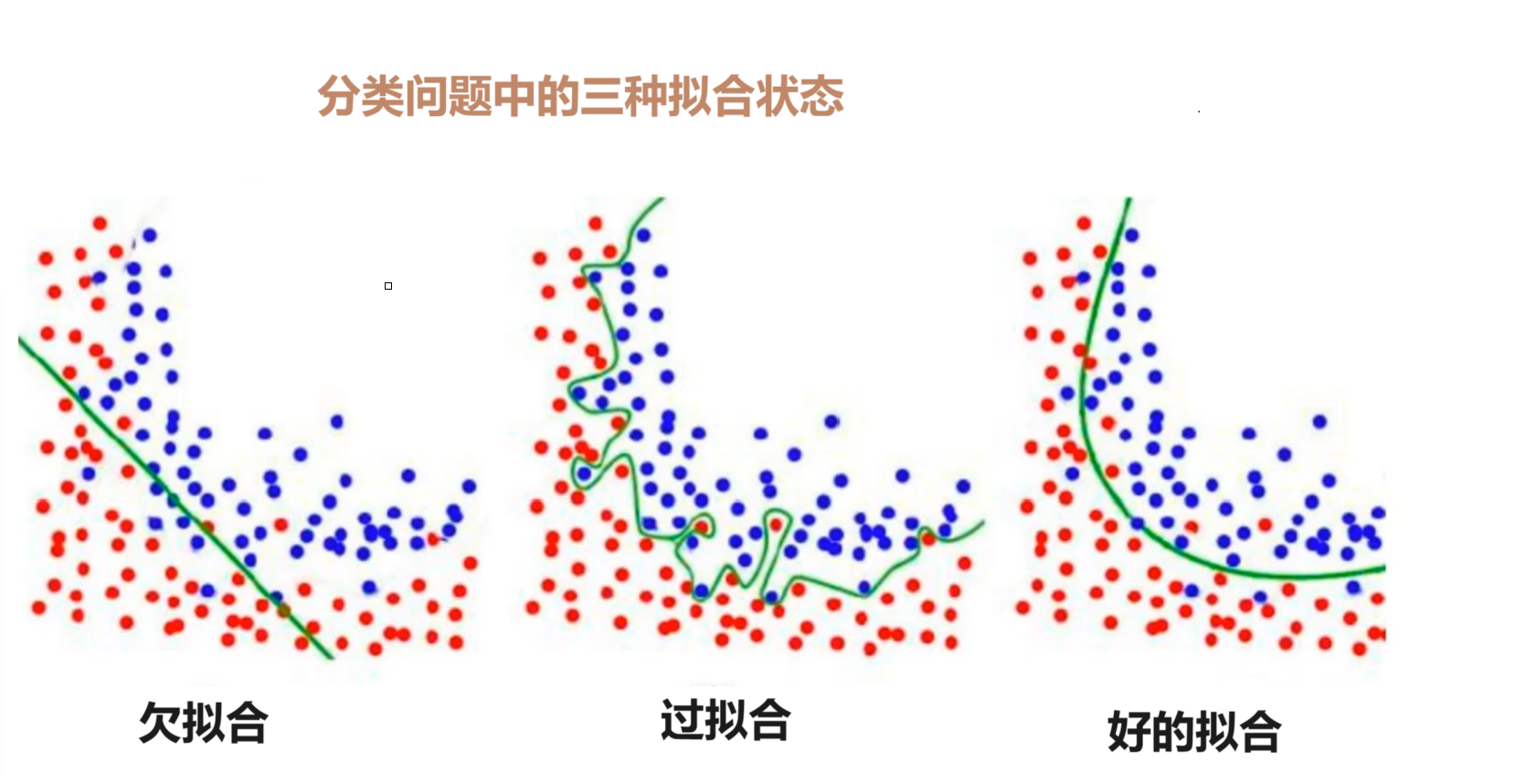
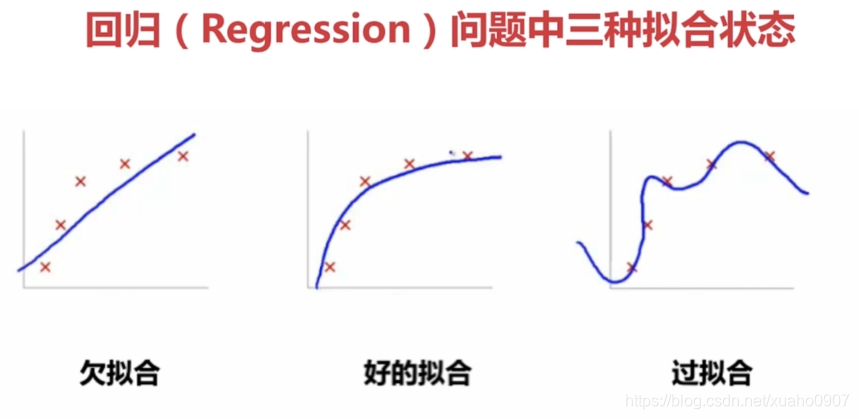
1.7.1?欠擬合
????????欠擬合是指模型在訓練數據上表現不佳,同時在新的未見過的數據上也表現不佳。這通常發生在模型過于簡單,無法捕捉數據中的復雜模式時。欠擬合模型的表現特征如下:
? ? ? ? 1. 訓練誤差較高;
? ? ? ? 2. 測試誤差同樣較高;
? ? ? ? 3. 模型可能過于簡化,不能充分學習訓練數據中的模式。
1.7.2?過擬合
????????過擬合是指模型在訓練數據上表現得非常好,但在新的未見過的數據上表現較差。這通常發生在模型過于復雜,以至于它不僅學習了數據中的真實模式,還學習了噪聲和異常值。過擬合模型的表現特征如下:
????????1. 訓練誤差非常低;
????????2. 測試誤差較高;
????????3. 模型可能過于復雜,以至于它對訓練數據進行了過度擬合。
1.7.3?正則化
????????正則化就是防止過擬合,增加模型的魯棒性,魯棒是Robust 的音譯,也就是強壯的意思。就像計算機軟件在面臨攻擊、網絡過載等情況下能夠不死機不崩潰,這就是軟件的魯棒性,魯棒性調優就是讓模型擁有更好的魯棒 性,也就是讓模型的泛化能力和推廣能力更加的強大。
????????比如,下面兩個方程描述同一條直線,哪個更好?
????????;?
。
????????第一個更好,因為下面的公式是上面的十倍,當w越小公式的容錯的能力就越好。我們都知道人工智能中回歸是有誤差的,為了把誤差降低而擬合出來的一個接近真實的公式,比如把一個測試數據[10,20]帶入計算得到的值跟真實值會存在一定的誤差,但是第二個方程會把誤差放大,公式中,當x有一點錯誤,這個錯誤會通過w放大。但是w不能太小,當w太小時(比如都趨近0),模型就沒有意義了,無法應用。
????????想要有一定的容錯率又要保證正確率就要由正則項來發揮作用了! 所以正則化(魯棒性調優)的本質就是犧牲模型在訓練集上的正確率來提高推廣、泛化能力,W在數值上越小越好,這樣能抵抗數值的擾動。同時為了保證模型的正確率W又不能極小。因此將原來的損失函數加上一個懲罰項使得計算出來的模型W相對小一些,就是正則化。這里面損失函數就是原來固有的損失函數,比如回歸的話通常是MSE,然后在加上一部分懲罰項來使得計算出來的模型W相對小一些來帶來泛化能力。
????????常用的懲罰項有L1正則項或者L2正則項:
????????,對應曼哈頓距離;
????????,對應歐氏距離。
????????其實L1 和L2 正則的公式在數學里面的意義就是范數,代表空間中向量到原點的距離,當我們把多元線性回歸損失函數加上L2正則的時候,就誕生了Ridge嶺回歸。當我們把多元線性回歸損失函數加上L1正則的時候,就孕育出來了Lasso回歸。其實L1和L2正則項懲罰項可以加到任何算法的損失函數上面去提高計算出來模型的泛化能力的。
2.?嶺回歸Ridge
2.1?損失函數公式
????????嶺回歸是失損函數通過添加所有權重的平方和的乘積(L2)來懲罰模型的復雜度。
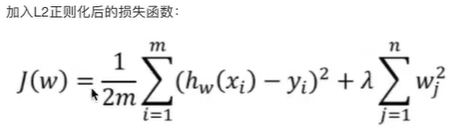
????????均方差除以2是因為方便求導,指所有的權重系數, λ指懲罰型系數,又叫正則項力度,特點:
? ? ? ? 1. 嶺回歸不會將權重壓縮到零,這意味著所有特征都會保留在模型中,但它們的權重會被縮小;
? ? ? ? 2. 適用于特征間存在多重共線性的情況;
? ? ? ? 3. 嶺回歸產生的模型通常更為平滑,因為它對所有特征都有影響。
2.2 API 介紹
具有L2正則化的線性回歸-嶺回歸。
sklearn.linear_model.Ridge()
1 參數:
(1)alpha, default=1.0,正則項力度
(2)fit_intercept, 是否計算偏置, default=True
(3)solver, {‘auto’, ‘svd’, ‘cholesky’, ‘lsqr’, ‘sparse_cg’, ‘sag’, ‘saga’, ‘lbfgs’}, default=’auto’
當值為auto,并且數據量、特征都比較大時,內部會隨機梯度下降法。
(4)normalize:,default=True, 數據進行標準化,如果特征工程中已經做過標準化,這里就該設置為False
(5)max_iterint, default=None,梯度解算器的最大迭代次數,默認為150002 屬性
coef_ 回歸后的權重系數
intercept_ 偏置說明:SGDRegressor也可以做嶺回歸的事情,比如SGDRegressor(penalty='l2',loss="squared_loss"),但是其中梯度下降法有些不同。所以推薦使用Ridge實現嶺回歸示例:嶺回歸 加載加利福尼亞住房數據集,進行回歸預測。
# 嶺回歸 加載加利福尼亞住房數據集,進行回歸預測
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge
from sklearn.metrics import mean_squared_errorfrom sklearn.datasets import fetch_california_housing
# 1)加載數據
housing = fetch_california_housing(data_home="./src")
print(housing)
# 2)劃分訓練集與測試集
x_train, x_test, y_train, y_test = train_test_split(housing.data, housing.target, random_state=22)
# 3)標準化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4)嶺回歸預估器
estimator = Ridge(alpha=0.5, max_iter=10000)
estimator.fit(x_train, y_train)# 5)得出模型
print("權重系數為:\n", estimator.coef_) #權重系數與特征數一定是同樣的個數。
print("偏置為:\n", estimator.intercept_)# 6)模型評估
y_predict = estimator.predict(x_test)
print("預測的數據集:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("均方誤差為:\n", error)3.?拉索回歸Lasso
3.1?損失函數公式????????
????????Lasso回歸是一種線性回歸模型,它通過添加所有權重的絕對值之和(L1)來懲罰模型的復雜度。Lasso回歸的目標是最小化以下損失函數:
????????????????????????
????????其中:n 是樣本數量;p 是特征的數量;是第 i 個樣本的目標值;
是第
個樣本的特征向量;w是模型的參數向量;
是正則化參數,控制正則化項的強度。
特點:
? ? ? ? 1. 拉索回歸可以將一些權重壓縮到零,從而實現特征選擇。這意味著模型最終可能只包含一部分特征;
????????2.?適用于特征數量遠大于樣本數量的情況,或者當特征間存在相關性時,可以從中選擇最相關的特征;
????????3.?拉索回歸產生的模型可能更簡單,因為它會去除一些不重要的特征。
3.2 API 介紹
????????sklearn.linear_model.Lasso()
參數:
-
alpha (float, default=1.0):控制正則化強度;必須是非負浮點數。較大的 alpha 增加了正則化強度。
-
fit_intercept (bool, default=True):是否計算此模型的截距。如果設置為 False,則不會使用截距(即數據應該已經被居中)。
-
precompute (bool or array-like, default=False):如果為 True,則使用預計算的 Gram 矩陣來加速計算。如果為數組,則使用提供的 Gram 矩陣。
-
copy_X (bool, default=True):如果為 True,則復制數據 X,否則可能對其進行修改。
-
max_iter (int, default=1000):最大迭代次數。
-
tol (float, default=1e-4):精度閾值。如果更新后的系數向量減去之前的系數向量的無窮范數除以 1 加上更新后的系數向量的無窮范數小于 tol,則認為收斂。
-
warm_start (bool, default=False):當設置為 True 時,再次調用 fit 方法會重新使用之前調用 fit 方法的結果作為初始估計值,而不是清零它們。
-
positive (bool, default=False):當設置為 True 時,強制系數為非負。
-
random_state (int, RandomState instance, default=None):隨機數生成器的狀態。用于隨機初始化坐標下降算法中的隨機選擇。
-
selection ({'cyclic', 'random'}, default='cyclic'):如果設置為 'random',則隨機選擇坐標進行更新。如果設置為 'cyclic',則按照循環順序選擇坐標。
屬性:
-
coef_:系數向量或者矩陣,代表了每個特征的權重。
-
intercept_:截距項(如果 fit_intercept=True)。
-
n_iter_:實際使用的迭代次數。
-
n_features_in_ (int):訓練樣本中特征的數量。
示例:
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import numpy as np# 加載波士頓房價數據集
data = fetch_california_housing(data_home="./src")
X, y = data.data, data.target# 劃分訓練集和測試集
X_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 創建Lasso回歸模型
lasso = Lasso(alpha=0.1) # alpha是正則化參數# 訓練模型
lasso.fit(X_train, y_train)# 得出模型
print("權重系數為:\n", lasso.coef_) #權重系數與特征數一定是同樣的個數。
print("偏置為:\n", lasso.intercept_)#模型評估
y_predict = lasso.predict(x_test)
print("預測的數據集:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("均方誤差為:\n", error)4.?邏輯回歸
4.1?概念
????????邏輯回歸(Logistic Regression)是機器學習中的一種分類模型,邏輯回歸是一種分類算法,雖然名字中帶有回歸,但是它與回歸之間有一定的聯系。由于算法的簡單和高效,在實際中應用非常廣泛。
????????邏輯回歸一般用于二分類問題,比如:是好瓜還是壞瓜,健康還是不健康,可以托付終身還是不可以。
4.2?原理
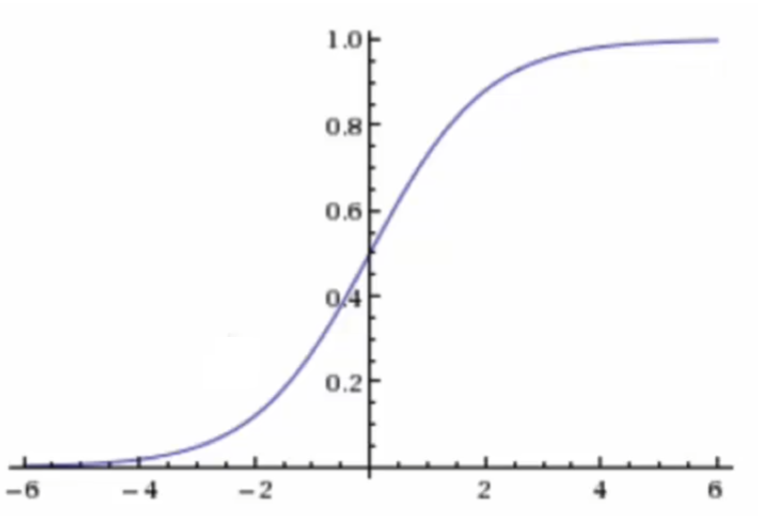
????????邏輯回歸的輸入是線性回歸的輸出,線性回歸:;
sigmoid激活函數:;sigmoid函數的值是在[0,1]區間中的一個概率值,默認為0.5為閾值可以自己設定,大于0.5認為是正例,小于則認為是負例,把上面的h(w) 線性的輸出再輸入到sigmoid函數當中
。
????????損失函數:
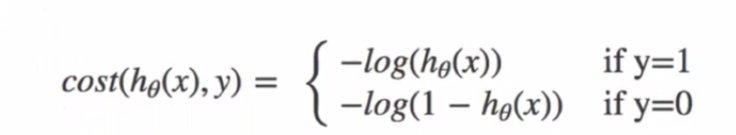
????????損失函數圖:當y=1時:
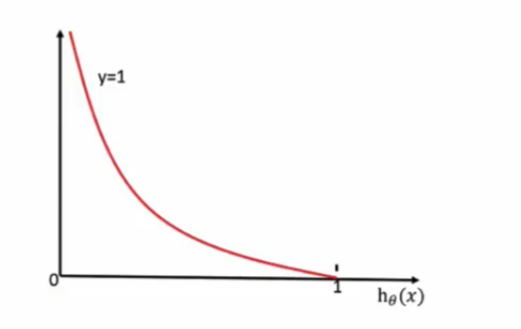
????????通過損失函數圖像,我們知道:當y=1時,我們希望值越大越好;當y=0時,我們希望
值越小越好。
????????綜合0和1的損失函數:
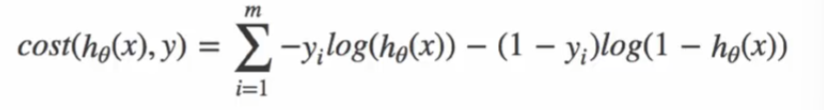
? ? ? ? 通過計算:

????????然后使用梯度下降算法,去減少損失函數的值,這樣去更新邏輯回歸前面對應算法的權重參數,提升原本屬于1類別的概率,降低原本是0類別的概率。
4.3 API 介紹
sklearn.linear_model.LogisticRegression()
參數:fit_intercept bool, default=True 指定是否計算截距max_iter int, default=100 最大迭代次數。迭代達到此數目后,即使未收斂也會停止。
模型對象:.coef_ 權重.intercept_ 偏置predict()預測分類predict_proba()預測分類(對應的概率)score()準確率示例:
#導包
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
#加載數據
X,y = load_iris(return_X_y=True)
print(y)#二分類 刪除第三類
X=X[y!=2]
y=y[y!=2]
print(y)#數據集劃分
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=33)
print(X_train.shape,y_train.shape)#邏輯回歸模型
model=LogisticRegression()#訓練
model.fit(X_train,y_train)#權重
print(model.coef_)#偏置
print(model.intercept_)#預測分類
y_predict=model.predict(X_test)
print(y_predict)
print(y_test)#預測分類對應的概率
proba=model.predict_proba(X_test)
print(proba)#評估
print(model.score(X_test,y_test))5.?無監督學習之K-means算法
5.1?無監督學習
????????無監督學習(Unsupervised Learning)計算機根據樣本的特征或相關性,實現從樣本數據中訓練出相應的預測模型。
????????無監督學習模型算法中,模型只需要使用特征矩陣X即可,不需要真實的標簽y,聚類算法是無監督學習中的代表之一。
-
聚類算法:
-
數據集中,擁有數據特征,但是沒有具體的標簽
-
將數據劃分成有意義或有用的簇
-
聚類算法追求“簇內差異小,簇外差異大”。而這個 “差異”便是通過樣本點到其簇質心的距離來衡量
-
-
聚類算法和分類算法的區別:
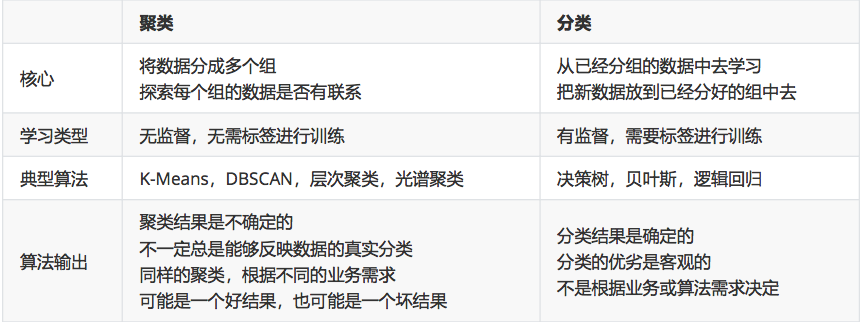
5.2?K-means 算法
????????K-means 是一種流行的聚類算法,主要用于無監督學習中對未標記的數據進行分類,該算法的目標是將數據集中的樣本劃分為K個簇,使得簇內的樣本彼此之間的差異最小化,這種差異通常通過簇內所有點到該簇中心點的距離平方和來衡量。
| 屬性 | 含義 |
|---|---|
| 簇 | Kmeans算法將一組N個樣本的特征矩陣X劃分為K個無交集的簇,直觀上看來簇是一個又一個聚集一起的數據,在一個簇中的數據就認為是同一類,簇就是聚類的結果表現,其中簇的個數是一個超參數 |
| 質心 | 每個簇中所有數據的均值u,通常被稱為這個簇的"質心",在二維平面中,簇的質心橫坐標是橫坐標的均值,質心的縱坐標是縱坐標的均值 |
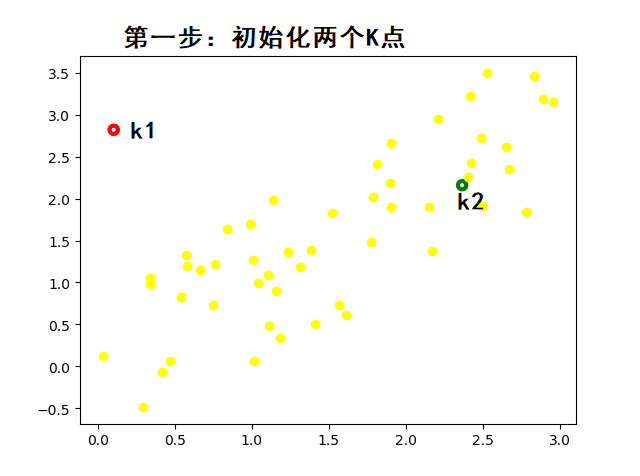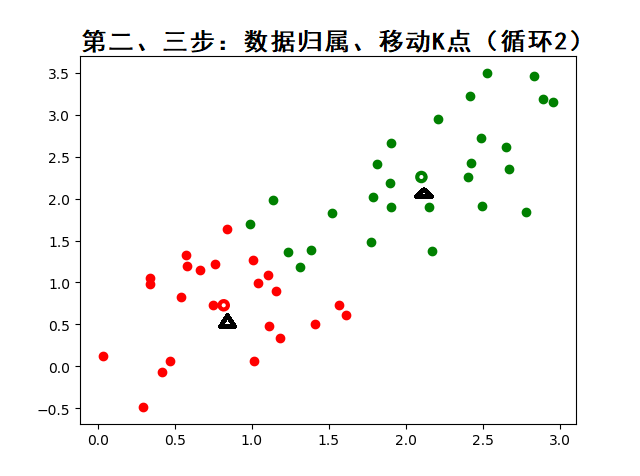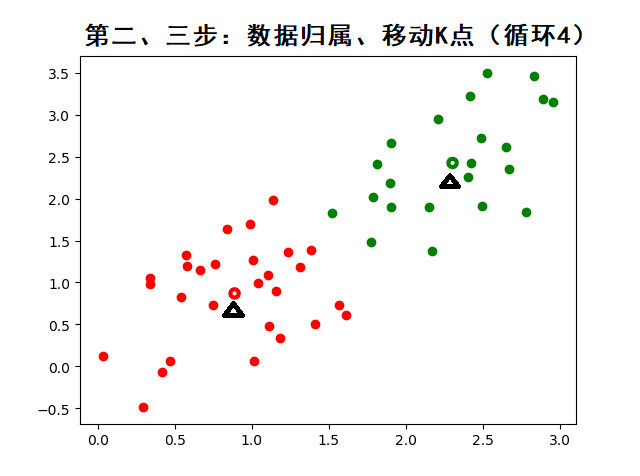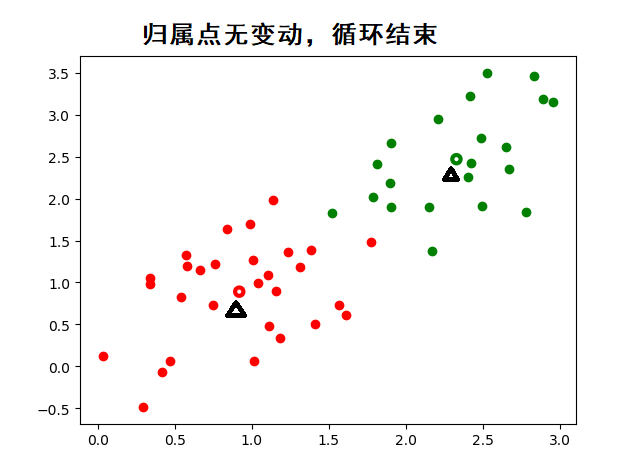
????????K-means 算法的基本步驟:
? ? ? ? 1. 隨機抽取`k`個樣本作為最初的質心,這可以通過隨機選取數據集中的K個樣本或者使用一些啟發式方法來實現;
? ? ? ? 2. 計算每個樣本點與`k`個質心的距離(通常是歐氏距離),將樣本點分配到最近的一個質心,生成`k`個簇;
????????3.?對于每個簇,計算所有被分該簇的樣本點的平均值作為新的質心;
? ? ? ? 4. 當質心的位置不再發生變化或者迭代結束,聚類完成。
????????動態圖示:
5.3 API 介紹
????????K-means 算法輸入的是 k 值和樣本數據結合,輸出的是 k 個簇的集合。
-
sklearn.cluster.KMeans類是scikit-learn庫提供的一個用于執行K-means聚類算法的工具。它提供了一個易于使用的接口來執行聚類操作,并且內置了多種優化選項,KMeans()用來實例化模型對象參數如下:
-
n_clusters: int,默認為8。要創建的簇的數量; -
init:, callable 或傳入的數組,默認為'k-means++'。指定如何初始化質心。'k-means++'使用一種啟發式方法來選擇初始質心,以加快收斂速度;'random'則隨機選擇初始質心;
-
n_init: int,默認為10。運行算法的次數,每次使用不同的質心初始化。最終結果將是具有最低惰性的模型; -
max_iter: int,默認為300。單次運行的最大迭代次數。
-
-
cluster_centers_屬性:cluster_centers_ 屬性存儲了每個聚類的中心點坐標; -
labels_屬性:labels_ 存儲了每個數據點的聚類標簽。 -
make_blobs方法是 Sklearn 庫中 sklearn.datasets 模塊提供的一個函數,用于生成一組二維或高維的數據簇。這些數據簇通常用于聚類算法的測試。具體來說:-
參數:
-
n_samples 參數指定了生成樣本的數量;
-
centers 參數定義了數據集中簇的中心數量;
-
random_state 參數用于設置隨機數生成器的種子,以便在不同運行之間獲得相同的結果。
-
-
返回值:返回一個元組
-
X:一個形狀為 (n_samples, n_features) 的數組,表示生成的樣本數據。每個樣本都是一行,特征列為樣本的各個維度坐標;
-
y:一個形狀為 (n_samples,) 的數組,表示每個樣本所屬的簇標簽(中心索引)。如果不需要這個標簽,可以像示例中那樣用 _ 忽略它。
-
-
示例:
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
data=np.random.randint(0,1000,(1000,2))
# print(data)
# plt.scatter(data[:,0],data[:,1])
# plt.show()
# model.fit(data)
n_class=7
model=KMeans(n_class)
model.fit(data)
# print(model.cluster_centers_)
# print(model.labels_)
# print(model.labels_==0)
# print(data[model.labels_==0])
for i in range(n_class):point=data[model.labels_==i]plt.scatter(point[:,0],point[:,1])
# plt.scatter(model.cluster_centers_[:,0],model.cluster_centers_[:,1])
plt.show()
-第三方MCP Server實戰指南(五))

















