文章目錄
- 1.構造函數初始化列表
- 1.1 初始化列表的使用
- 1.2 有參構造函數的默認值
- 2.對象所占空間大小
- 2.1 大小的計算
- 2.2 內存對齊機制
- 3. 析構函數
- 3.1 基本概念
- 3.2 總結
- 4.valgrind工具集
- 4.1 介紹
- 4.2 memcheck的使用
- 5. 拷貝構造函數
- 5.1 拷貝構造函數定義
- 5.2 淺拷貝/深拷貝
- 5.3 拷貝構造函數的調用時機
- 5.4 總結
1.構造函數初始化列表
1.1 初始化列表的使用
在構造函數體里對數據成員賦值,實際上是先調用數據成員的默認構造函數來創建對象,接著再對其進行賦值操作;而在初始化列表中初始化數據成員,是在對象創建的時候就直接完成初始化。
#include <iostream>
#include <string>
using std::endl;
using std::cout;
using std::string;
using std::cin;class Person
{
public:Person():_age(0),_name("張三"){cout << "我是無參構造函數" << endl;}Person(int age,string name):_age(age),_name(name){cout << "我是有參構造函數" << endl;}void print();
private:int _age;string _name;
};void Person::print()
{cout << "name=" << _name << ";age=" << _age << endl;
}int main(void)
{Person p1;p1.print();Person p2(10, "張萬三");p2.print();return 0;
}

1.2 有參構造函數的默認值
構造函數的參數也可以按從右向左規則賦默認值,同樣的,如果構造函數的聲明和定義分開寫,只用在聲明或定義中的一處設置參數默認值,一般建議在聲明中設置默認值。
class Person
{
public://有參構造函數參數默認值Person(int age=10 ,string name="張萬一"):_age(age) ,_name(name){}void print();
private:int _age;string _name;
};void Person::print()
{cout << "name=" << _name << ";age=" << _age << endl;
}int main(void)
{Person p1(20);p1.print();return 0;
}

2.對象所占空間大小
2.1 大小的計算
成員函數并不影響對象的大小,對象的大小與數據成員有關
#include <iostream>
#include <string>
using std::endl;
using std::cout;
using std::string;
using std::cin;class Person
{
private:int _age;double _price;
};int main(void)
{Person p1;size_t s1 = sizeof(Person);size_t s2 = sizeof(p1);cout << s1 << ";" << s2 << endl;return 0;
}

2.2 內存對齊機制
有時一個類所占空間大小就是其數據成員類型所占大小之和,有時則不是,這就是因為有內存對齊的機制。
1.什么是內存對齊:
存對齊指的是將數據存儲在特定的內存地址上,使得數據的起始地址是其大小的整數倍。例如,一個int類型(通常為 4 字節)的變量,其起始地址通常是 4 的倍數。
2.原因
(1)提高訪問效率:計算機的硬件設計使得在訪問對齊的數據時更加高效。因為 CPU 通常按字長(如 4 字節或 8 字節)來訪問內存,如果數據是對齊的,CPU 可以一次讀取完整的數據;如果數據未對齊,可能需要多次訪問內存才能獲取完整的數據。
(2)硬件限制:某些硬件平臺要求數據必須按特定的對齊方式存儲,否則會拋出異常或導致性能下降。
對齊規則
(1)基本數據類型的對齊值:每種基本數據類型都有其默認的對齊值,通常等于該類型的大小。例如,char 類型的對齊值為 1 字節,int 類型的對齊值為 4 字節,double 類型的對齊值為 8 字節。
(2)結構體或類的對齊值:結構體或類的對齊值是其成員中最大對齊值。
(3)成員的存儲位置:每個成員的起始地址必須是其對齊值的整數倍。如果前一個成員的結束地址不滿足下一個成員的對齊要求,會在它們之間插入填充字節。
(4)結構體或類的總大小:結構體或類的總大小必須是其對齊值的整數倍。如果不滿足,會在結構體或類的末尾插入填充字節。
3. 析構函數
3.1 基本概念
作用:析構函數是一種特殊的成員函數,在對象的生命周期結束時自動調用,用于釋放對象所占用的資源,比如動態分配的內存、打開的文件、網絡連接等。
析構函數語法:
析構函數函數名是在類名前面加”~”組成,沒有返回值,不能有void,不能有參數,不能重載。 ~ClassName(){}
#include <iostream>
#include <cstring>// 使用命名空間 std
using namespace std;class Str {
private:char* str;
public:// 構造函數Str(const char* s) {//在堆上分配空間str = new char[strlen(s) + 1];strcpy(str, s);}// 析構函數~Str() {//堆內存的銷毀if(nullptr!=str){ delete[] str;str = nullptr;cout << "析構函數" << endl;}}void printString() {cout << str << endl;}
};void test(void)
{Str sw("Hello, World!");sw.printString();// 函數結束,對象 sw 被銷毀,析構函數自動調用
}int main(void)
{test();return 0;
}3.2 總結
- 對于全局對象,整個程序結束時,自動調用全局對象的析構函數。
- 對于局部對象,在程序離開局部對象的作用域時調用對象的析構函數。
- 對于靜態對象,在整個程序結束時調用析構函數。
- 對于 堆對象,在使用 delete 刪除該對象時,調用析構函數。
4.valgrind工具集
4.1 介紹
1.概念
Valgrind 是一款用于內存調試、性能分析和代碼剖析的工具集,在 Linux 系統中廣泛使用。
2.工具集中的主要工具
(1).Memcheck:這是 Valgrind 最常用的工具之一,主要用于檢測內存錯誤。它可以檢測出諸如內存泄漏、非法內存訪問(如越界訪問、使用未初始化的內存等)等問題。在開發過程中,這些內存錯誤可能會導致程序出現難以調試的崩潰或錯誤行為,Memcheck 能夠幫助開發者快速定位和解決這些問題。
(2)Callgrind:用于性能分析,它可以收集程序中函數調用的信息,包括函數的執行時間、調用次數等。通過分析這些數據,開發者可以找出程序中的性能瓶頸所在,從而有針對性地進行優化。
(3)Cachegrind:主要關注程序的緩存行為。它可以模擬 CPU 緩存,分析程序對緩存的使用情況,幫助開發者了解緩存命中率、緩存缺失等信息,以便優化程序的內存訪問模式,提高緩存利用率,從而提升程序性能。
(4)Helgrind:用于檢測多線程程序中的數據競爭問題。在多線程環境下,當多個線程同時訪問共享數據且沒有適當的同步機制時,就可能發生數據競爭,導致程序出現不確定的行為。Helgrind 能夠檢測出這些潛在的數據競爭情況,幫助開發者確保多線程程序的正確性和穩定性。
3.特點
(1)強大的檢測能力:能夠深入檢測各種內存相關的問題和性能瓶頸,為開發者提供詳細的錯誤信息和性能數據。
(2)易于使用:Valgrind 的命令行界面相對簡單,只需指定要運行的程序以及相應的工具選項,就可以開始對程序進行分析。
(3)跨平臺性:支持多種 Linux 平臺,具有較好的移植性,方便在不同的系統環境中使用。
4.應用場景
(1)軟件開發與調試:在開發過程中,及時發現和解決內存錯誤可以提高軟件的穩定性和可靠性,減少后期維護成本。
(2)性能優化:通過分析性能數據和緩存行為,開發者可以采取針對性的優化措施,如優化算法、調整數據結構、改進內存訪問模式等,以提高程序的運行效率。
(3)多線程程序開發:確保多線程程序的正確性和穩定性,避免數據競爭等問題導致的程序錯誤和異常。
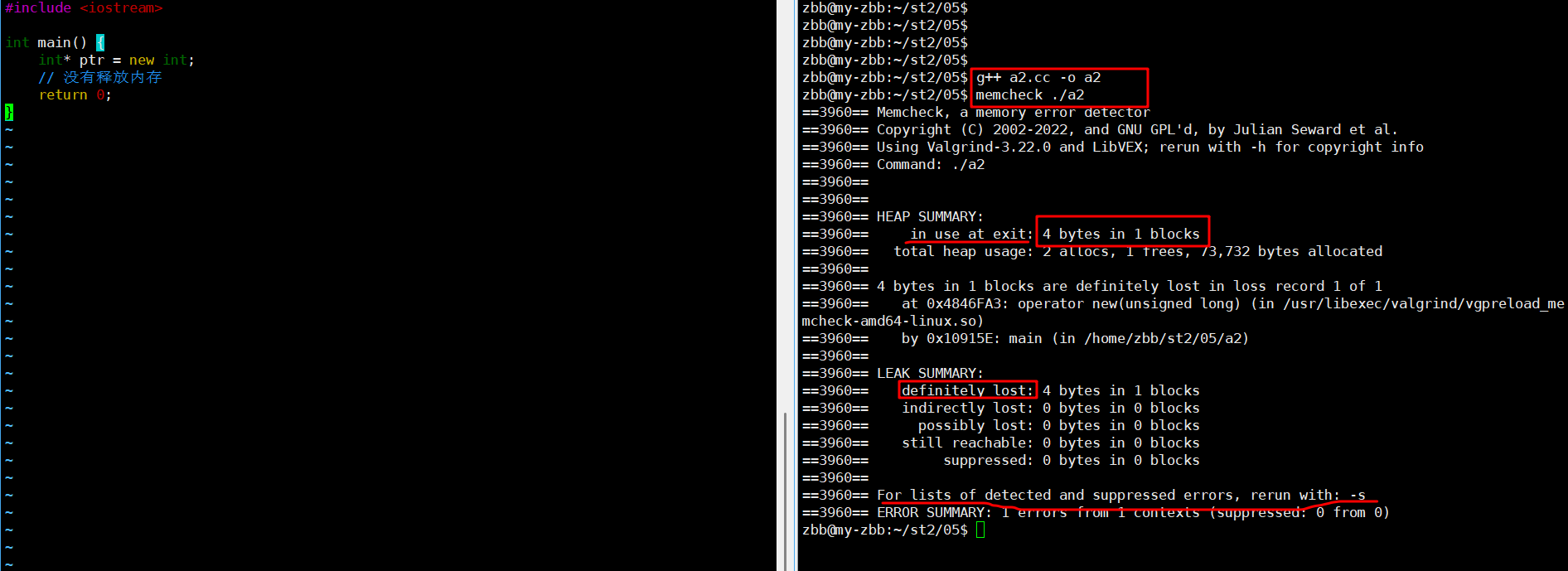
4.2 memcheck的使用
sudo apt-get install valgrind //安裝//使用
valgrind --tool=memcheck ./a.out (簡略)
valgrind --tool=memcheck --leak-check=full ./a.out (詳細)//在home目錄下編輯.bashrc文件,改別名;方便使用vim ~/.bashrc #打開并添加一下內存
alias memcheck='valgrind --tool=memcheck --leak-check=full --show-reachable=yes'
#保存退出 :wq
#生效
source ~/.bashrc
5. 拷貝構造函數
5.1 拷貝構造函數定義
1.語法格式
class ClassName {
public:// 拷貝構造函數ClassName(const ClassName& other) {// 初始化新對象的成員變量}
};
2.定義
該函數用一個已經存在的同類型的對象,來初始化新對象,即對對象本身進行復制 。在沒有顯式定義拷貝構造函數時,編譯器自動提供了默認的拷貝構造函數。
#include <iostream>
#include <cstring>namespace myspace1
{using std::endl;using std::cout;using std::cin;using std::string;
}using namespace myspace1;class Person
{
public://構造函數Person():_x(0),_y(0) {cout << "我是無參構造函數" << endl;}Person(int x, int y) :_x(x), _y(y){cout << "我是有參構造函數" << endl;}//析構函數~Person(){cout << "我是析構函數" << endl;}//拷貝構造函數Person(const Person& r):_x(r._x),_y(r._y){cout << "我是拷貝構造函數" << endl;}void print(){cout << "x=" << _x << ";y=" << _y << endl;}private:int _x;int _y;
};void test()
{Person p1(3, 4);//這里調用拷貝構造函數Person p2 = p1; //==Person p2(p1)p1.print();p2.print();
}int main(void)
{test();
}

5.2 淺拷貝/深拷貝
淺拷貝:默認拷貝構造函數執行的是淺拷貝,只復制對象的成員變量的值。對于包含指針成員的對象,淺拷貝會導致多個對象的指針成員指向同一塊內存區域,當其中一個對象被銷毀時,釋放該內存會導致其他對象的指針成為懸空指針,引發未定義行為。
深拷貝:為了避免淺拷貝帶來的問題,需要顯式定義拷貝構造函數,實現深拷貝。深拷貝會為新對象的指針成員分配新的內存空間,并將原對象指針所指向的內容復制到新的內存中。
錯誤案例
#include <iostream>
#include <cstring>namespace myspace1
{using std::endl;using std::cout;using std::cin;using std::string;
}using namespace myspace1;class Person
{
public://構造函數Person():_x(0),_name(new char[strlen("張三")+1]()){strcpy(_name, "張三");cout << "我是無參構造函數" << endl;}Person(int x, const char *name) :_x(x), _name(new char[strlen(name) + 1]()){strcpy(_name, name);cout << "我是有參構造函數" << endl;}//析構函數~Person(){delete[] _name;cout << "我是析構函數" << endl;}void print(){cout << "x=" << _x << ";name=" << _name << endl;}private:int _x;char* _name;
};void test()
{Person p1(20, "張萬三");//這里調用拷貝構造函數Person p2 = p1; //==Person p2(p1)p1.print();p2.print();
}int main(void)
{test();
}
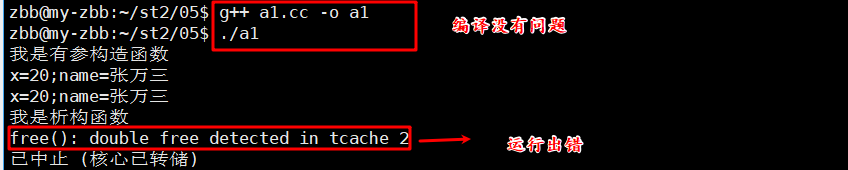
如果是默認的拷貝構造函數,p2會對p1的_name進行淺拷貝,指向同一片內存;p2被銷毀時,會調用析構函數,將這片堆空間進行回收;p1再銷毀時,析構函數中又會試圖回收這片空間,出現double free問題
所以需要我們顯示定義拷貝構造函數
#include <iostream>
#include <cstring>namespace myspace1
{using std::endl;using std::cout;using std::cin;using std::string;
}using namespace myspace1;class Person
{
public://構造函數Person():_x(0),_name(new char[strlen("張三")+1]()){strcpy(_name, "張三");cout << "我是無參構造函數" << endl;}Person(int x, const char *name) :_x(x), _name(new char[strlen(name) + 1]()){strcpy(_name, name);cout << "我是有參構造函數" << endl;}//析構函數~Person(){delete[] _name;cout << "我是析構函數" << endl;}//拷貝構造函數Person(const Person& r):_x(r._x), _name(new char[strlen(r._name) + 1]){strcpy(_name, r._name);cout << "我是拷貝構造函數" << endl;}void print(){cout << "x=" << _x << ";name=" << _name << endl;}private:int _x;char* _name;
};void test()
{Person p1(20, "張萬三");//這里調用拷貝構造函數Person p2 = p1; //==Person p2(p1)p1.print();p2.print();
}int main(void)
{test();
}

所以,如果拷貝構造函數需要顯式寫出時(該類有指針成員申請堆空間),在自定義的拷貝構造函數中要換成深拷貝的方式,先申請空間,再復制內容
5.3 拷貝構造函數的調用時機
1.當使用一個已經存在的對象初始化另一個同類型的新對象時
void test()
{Person p1(20, "張萬三");Person p2 = p1; //==Person p2(p1)p1.print();p2.print();
}
2.當函數參數(實參和形參的類型都是對象),形參與實參結合時(實參初始化形參);
void fun(Person p) //避免多余的復制,節省空間:fun(Person &p) 使用引用
{p.print();
}void test()
{Person p1(20, "張三");fun(p1);
}
3.當函數的返回值是對象,執行return語句時
//避免多余的復制,節省空間
//Person &fun1()
//{
// //返回的是引用,要注意返回對象的聲明周期(返回全局變量/變量前加 static)
// return
//}
Person fun2()
{//Person(20, "李四"); 匿名對象;在這行代碼執行完畢后,該臨時對象就會立即調用析構函數銷毀。Person p3(30, "王強");return p3; //發生復制
}
5.4 總結
1.默認情況下,c++編譯器至少為我們寫的類增加3個函數
(1).默認構造函數(無參,函數體為空)
(2).默認析構函數(無參,函數體為空)
(3).默認拷貝構造函數,對類中非靜態成員屬性簡單值拷貝
如果用戶定義拷貝構造函數,c++不會再提供任何默認構造函數
如果用戶定義了普通構造(非拷貝),c++不在提供默認無參構造,但是會提供默認拷貝構造
2.構造/析構
(1)構造函數主要作用在于創建對象時為對象的成員屬性賦值,構造函數由編譯器自動調用,無須手動調用。
(2)析構函數主要用于對象銷毀前系統自動調用,執行一些清理工作。
3.淺拷貝/深拷貝
(1)一般情況下,淺拷貝沒有任何副作用,但是當類中有指針,并且指針指向動態分配的內存空間,析構函數做了動態內存釋放的處理,會導致內存問題。
(2)當類中有指針,并且此指針有動態分配空間,析構函數做了釋放處理,往往需要自定義拷貝構造函數,自行給指針動態分配空間,深拷貝。
)

)





![信息學奧賽一本通 1498:Roadblocks | 洛谷 P2865 [USACO06NOV] Roadblocks G](http://pic.xiahunao.cn/信息學奧賽一本通 1498:Roadblocks | 洛谷 P2865 [USACO06NOV] Roadblocks G)




)





