目錄
一.原子操作
1.原子操作的概念
2.原子變量
二.原子性
1.中間狀態描述
2.單處理器單核
3.多處理器或多核的情況下
4.cache(高速緩沖器的作用)
5.在cpu cache基礎上,cpu如何讀寫數據???
6.為什么會有緩存一致性問題
7.解決策略
三.內存序
1.為什么有內存序問題???
2.內存序規定了什么
3.六種不同的內存序
4.代碼案例
四.總結
一.原子操作
多線程下確保堆共享變量的操作在執行時不會被干擾,從而避免競態條件
1.原子操作的概念
①.原子操作定義:
對基本類型或指針進行的不可中斷的操作。
②.原子性:
確保操作在多線程環境下不被中斷,保證線程安全。
③.內存序:
理解內存序的概念,確保操作的同步性和順序性。
2.原子變量
①autoinc.cc
②原子變量的操作
③原子性
④原子操作是實現和平臺相關
二.原子性
1.中間狀態描述
要么都做要么都還沒做,不會然其他核心看到執行的一個中間狀態
2.單處理器單核
①單核單線程我們只需要保證操作的指令不會被中斷即可(調用機制)
②在硬件底層有自旋鎖
③屏蔽中斷:通過關閉處理器的中斷功能,讓處理器在執行關鍵代碼段的時候,不接收外部的請求從而保證了關鍵代碼段執行的過程中不會被打斷
3.多處理器或多核的情況下
除了不被打斷還需要避免其他核心操作相關的內存空間
①以往0x86,lock指令鎖總線,避免所有內存的訪問
②現在lock指令只需要阻止其他核心堆相關內存空間的訪問即可
4.cache(高速緩沖器的作用)
為了解決cpu運算速度與內存訪問速度不匹配的問題
5.在cpu cache基礎上,cpu如何讀寫數據???
我們可以通過寫回策略來決定
寫
①是否命中緩存?
命中直接寫并標記為臟 ,沒命中則直接往下
②定位緩存塊,該數據是否為臟數據?
是臟數據則刷主存,不是臟數據,從內存讀取,寫入緩存,并標記為臟
讀
①是否命中緩存?
命中直接返回,沒命中直接往下
②定位緩存塊,該數據是否為臟數據?
是臟數據則刷主存,不是臟數據,從內存讀取,寫入緩存,并標記為非臟
6.為什么會有緩存一致性問題
①cpu是多核的
②基于寫回策略將會出現緩存不一致的問題
7.解決策略
①基于總線嗅探機制實現了事務串行化,通過狀態機降低總線帶寬的壓力
②事務的串行化:“鎖”? ? ? ? ?和? ? ? ? ?“lock指令”
③MESI一致性協議
三.內存序
1.為什么有內存序問題???
①編譯器優化重排
②CPU指令優化重排
2.內存序規定了什么
①規定了多個線程訪問同一內存地址時的語義
②某個線程對內存地址的更新何時能被其他線程看見
③某個線程對內存地址訪問附件可以做什么樣的優化
3.六種不同的內存序
① std::memory_order_relaxed不保證順序性,性能優先。
② std::memory_order_consume讀取數據的順序不被重排(但現代編譯器會優化成 acquire)。
③ std::memory_order_acquire保證之前的操作不被重排到后面。
④ std::memory_order_release保證之后的操作不被重排到前面。
⑤ std::memory_order_acq_rel結合了 acquire 和 release 的特性。
⑥ std::memory_order_seq_cst保證全局順序一致性。
補充::
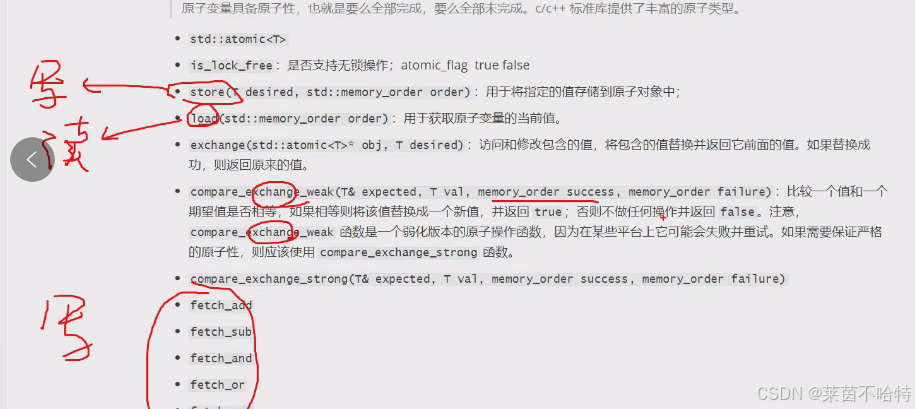
4.代碼案例
①
std::atomic<bool> x,y;
std::atomic<int> z;void write_x_then_y()
{x.store(true,std::memory_order_relaxed); // 1y.store(true,std::memory_order_relaxed); // 2
}void read_y_then_x()
{while(!y.load(std::memory_order_relaxed)); // 3if(x.load(std::memory_order_relaxed)) // 4++z;
}這種情況下沒有指定內存序的位置會導致y先變成true 然后 x依舊是false while結束死循環 if語句判斷失敗 從而z不會發生++的操作
由于使用了 std::memory_order_relaxed,x 和 y 的寫操作可能會在內存中被重排,因此 read_y_then_x 線程檢查到 x 為 false 的情況是可能的。最終,這會導致 z 不一定等于 1,甚至可能為 0,取決于內存重排的情況。
②
#include <atomic>
#include <thread>
#include <assert.h>
#include <iostream>std::atomic<bool> x,y;
std::atomic<int> z;void write_x_then_y()
{x.store(true,std::memory_order_relaxed); // 1y.store(true,std::memory_order_release); // 2
}void read_y_then_x()
{while(!y.load(std::memory_order_acquire)); // 3if(x.load(std::memory_order_relaxed)) // 4++z;
}這種情況下z的結果一定為1?
因為y讀出來是true的時候 x一定也是true
使用了 memory_order_release 和 memory_order_acquire,確保了在 y 設置為 true 之后,x 的修改在 read_y_then_x 線程中變得可見。
z 最終會等于 1,因為通過這些內存序約束,線程間的同步得到了保證。
③
#include <assert.h>
#include <atomic>
#include <thread>
#include <iostream>std::atomic<bool> x, y;
std::atomic<int> z;void write_x() {x.store(true, std::memory_order_seq_cst); // 1
}void write_y() {y.store(true, std::memory_order_seq_cst); // 2
}
void read_x_then_y() {while (!x.load(std::memory_order_seq_cst));if (y.load(std::memory_order_seq_cst)) // 3++z;
}
void read_y_then_x() {while (!y.load(std::memory_order_seq_cst));if (x.load(std::memory_order_seq_cst)) // 4++z;
}
int main() {for (int i = 0; i < 20; i++) {x = false;y = false;z = 0;std::thread a(write_x);std::thread b(write_y);std::thread c(read_x_then_y);std::thread d(read_y_then_x);a.join();b.join();c.join();d.join();// assert(z.load() != 0); // 5std::cout << z.load() << std::endl;}return 0;
}在 memory_order_seq_cst 下,所有的操作會嚴格按照全序進行,因此每個線程的原子操作都是同步的。
程序的輸出 z 最終將是 0 或 2,這取決于兩個 read_* 線程的執行順序。如果兩個線程都能正確讀取到 x 和 y,則 z 會增加到 2。
四.總結
只有我們要極致提升性能的時候才有考慮原子操作進行提升性能 ,在絕大部分時候我們只需要使用互斥鎖和條件變量即可滿足服務器開發的需求









)


深入了解AVFoundation-播放:多音軌、字幕、倍速播放與橫豎屏切換)




,CatM的最大速率?)
)
