lab-2
0. 前置
課程記錄
操作系統的隔離性,舉例說明就是,當我們的shell,或者qq掛掉了,我們不希望因為他,去影響其他的進程,所以在不同的應用程序之間,需要有隔離性,并且,應用程序和操作系統之間,也是如此。
當失去操作系統,我們的應用程序將會直接與硬件進行交互,數據也將直接存儲在物理內存中,但是我們的兩個應用程序無法識別相互的邊界,此時就可能會產生覆蓋,所以,這就是我們希望內存能夠隔離的原因,也是我們操作系統所需要實現的功能,另外還需要multiplexing(cpu分時復用,也就是多線程,CPU運行一個進程一段時間,再運行另一個進程)
這里也有一層抽象,操作系統沒有直接將cpu提供給應用程序,而是將進程抽象了cpu,這樣操作系統才能在多個應用程序之間復用一個或者多個cpu。
而我們也可以認為exec是對內存的抽象,通過提供exec這樣一個系統調用,使得我們可以安全的訪問對應的內存,而我們不能夠直接訪問物理內存。
files,它提供了方便的磁盤抽象,我們唯一與存儲系統交互的方式就是files,我們可以任意改寫這個文件,而最終,由操作系統來決定,這個files如何與磁盤中的塊對應。
操作系統的防御性,操作系統需要確保所有的應用程序都能工作,因此,操作系統不能沒有任何抵御攻擊的準備,比如說,應用程序向系統調用中傳遞了錯誤的參數,而導致了操作系統的崩潰,進而導致操作系統拒絕了為其他所有應用程序提供服務,所以操作系統需要能夠應對惡意的程序。
并且應用程序也不能打破隔離性,而影響到其他的程序,甚至控制內核(很危險)。
通常來說,強隔離性由硬件實現,包括user/kernel mode和虛擬內存。
首先,為了支持user/kernel mode,處理器也會有兩種操作模式,不同的操作模式權限不同,kernel mode可以使用特權命令,而user mode只能使用普通權限命令。
特權命令,比如說設置page table寄存器,以及處理器的相關狀態等。
當在user mode 執行了特權命令,cpu會拒絕這條命令,并且轉入kernel mode,殺死這個進程。
kernel mode還是user mode是通過一個flag寄存器來存儲的。
page table,每個進程都會有自己的一個獨立的page table,也就是說,每個進程都有自己獨立的視圖,而進程在這個視圖上去訪問內存空間,從而被映射到物理地址中,這樣來保證他們的內存不會重合。
user/kernel mode是如何切換的?xv6中,我們在make之后,我們可以在user/usys.S找到ecall這個指令,事實上,通過ecall這個指令,我們能夠跳轉到內核中指定的由內核控制的位置來執行系統調用。
舉一個例子,當我們調用fork,或者read的時候,事實上沒有直接調用函數,而是通過ecall去跳轉到內核,執行系統調用。
現在我們有了可以執行系統調用的手段,之后內核負責實現具體的系統調用,并且需要檢查參數,防止被惡意攻擊,所以安全可靠無bug的內核也成為TCB(Trusted Computing Base)
宏內核:xv6就是一個宏內核的典型代表,所有的操作系統服務都在kernel mode中,由于任何一個操作系統的bug都有可能成為漏洞,而我們有大量的代碼放在內核中,出現漏洞的可能性就更高了,這便是宏內核的缺點,而宏內核的另一個代表就是linux,宏內核的優勢在于包括文件系統,虛擬內存等子模塊都集成在一個程序中,提供了很好的性能。
微內核:微內核和宏內核恰恰相反,他將大部分操作系統運行在內核之外,這樣可以有效減少內核的代碼數量,從而降低出現漏洞的概率,但是微內核也有缺陷,比如說在shell需要與文件系統交互的時候,內核實際上是以消息傳遞的形式來執行系統調用的,這種情況下,每個操作都需要執行兩次跳轉,所以性能是更差的。并且,在一個宏內核中,如文件系統和虛擬內存系統可以輕易地共享page cache,但是在微內核中,這些模塊都被隔離開了,而這種共享難以實現,也使得難以獲得更高的性能。
到分析xv6啟動過程的時候,我發現只看文檔,確實還是很不理解的,推薦有實踐,帶著看代碼的部分還是看視頻最好。
xv6手冊
進程
進程具有獨占的地址空間,以及看上去是僅在運行當前程序的cpu,而其他進程無法對其進行干擾,這樣,它就會誤以為自己運行在獨立一臺機器上。
xv6使用頁表(硬件實現)為每個進程提供獨有的地址空間,xv6為每個進程維護了一個頁表(根頁表),而頁表將虛擬地址(匯編使用的地址)映射為物理地址(處理器芯片向主存發送的地址)。
從低地址區開始,依次代表著用戶(低處存放進程的指令)->全局變量->棧區->堆區
同樣的,內核的指令和數據也都被映射到了每個進程的地址空間中的高地址處(為用戶留下足夠的空間),當進程使用系統調用的時候,就會跳轉到進程地址空間的內核區域執行(感覺和中斷有點像),而在xv6中,使用的是proc來維護的一個進程的狀態(包含了頁表,內核棧,運行狀態等信息)。
每個進程都有自己的用戶棧和內核棧,當進程運行用戶命令時,只有用戶棧被使用,內核棧是空的,在進行系統調用或者中斷進入內核的時候,內核代碼就會被放入內核棧中執行,用戶棧依舊保存著數據,只是現在不活躍,進程的線程交替使用內核棧和用戶棧,而用戶代碼無法操作內核棧,所以即便用戶破壞了自己的用戶棧,內核也能正常運行,梳理一下流程:
進程系統調用 -> 處理器轉入內核棧中(或者說指令指針改變到內核棧中) -> 提升硬件特權 -> 運行特權代碼 -> 降低特權 -> 轉回到用戶棧
而我們每個進程都會有一個線程,線程之間的切換,實際上就是掛起當前線程,恢復另一個線程的狀態,線程的狀態都保存在線程棧上。(有點像中斷時的寄存器狀態的恢復和保存)
開機后發生的事情:他會初始化自己,將bootloader從磁盤中載入,而bootloader負責將內核從磁盤中載入,隨后開始運行entry,而entry的最開始,設置了兩份頁表映射,(低地址的映射和高地址的映射),因為在最開始,還沒有設置頁表的時候,我們的機器很可能沒有虛擬地址對應的那么大的內存,于是,我們只能將其對應到物理地址上,然后我們會設置這兩份頁表映射,因為最開始entry還運行在內存的低地址處,所以需要設置 0:0x400000 -> 0:0x400000的映射關系,我們還需要設置一個高地址的映射關系KERNBASE:KERNBASE+0x400000 -> 0:0x400000,而kernbase指的就是 0x80000000。
配合這張圖會比較好理解。
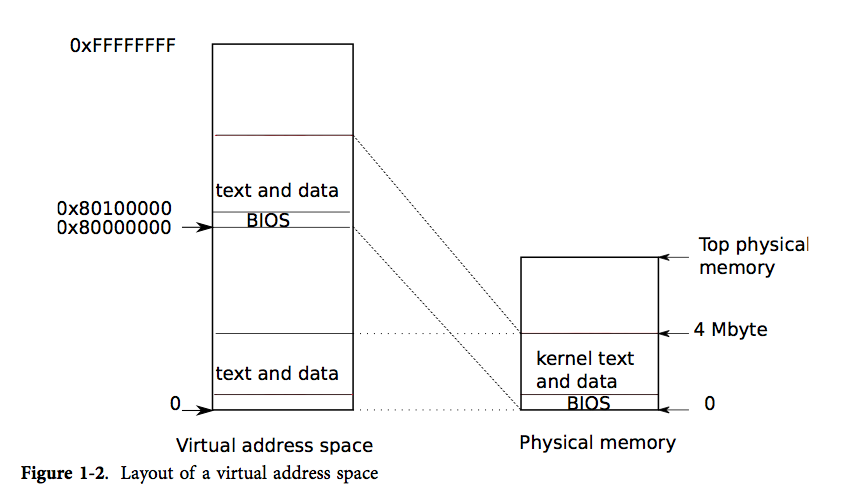
然后entry會繼續設置頁表,并且將頁表的目錄entrypgdir的物理地址載入%cr,此時就可以通過各種操作去實現分頁機制了(這里有一些比較底層的沒看懂)
最后,entry就需要跳轉到內核的C代碼,并且在內存的高地址去執行它了
這里我還有很多地方都沒看懂,感覺這里還是主要講的是x86的?有的部分還是自己去看看源代碼比較好,我看2024年的源代碼,riscv的匯編部分是很少的,也就300行左右,大部分還是c語言,包括很多操作系統的cpu,進程調度啥的,也沒看懂,這里分享一下我和AI大戰三百回合了解到的東西(不一定對):
操作系統本質上也是一個進程,也需要一個cpu去執行,而在操作系統啟動后,cpu就會不斷去執行我們提前寫好的代碼(執行程序的機器),而所有cpu的CS:IP,也就是執行程序的指針,都由操作系統這個特殊的進程來調度,但是,如果到最后,沒有任何程序可以供cpu執行,那么cpu就會陷入一個空閑循環,因為cpu總是應該執行的,然后,當我們新建了一個進程,需要cpu去執行的時候,就會獲取一個cpu,同時修改他的CS:IP使他的指令指針指向這個進程的起始位置,然后將相關的上下文切換,cpu便能繼續執行新的工作,當然在后面的調度,我們還會知道,時間片耗盡的中斷機制,當然,這是后面的話題了。
其實這方面最開始最困擾我的就是,你的CPU他怎么知道他何時應該執行程序?CPU在操作系統沒有啟動的時候,不是陷入睡眠嗎?啟動操作系統之后,就能向下執行命令,cpu難道是個只會工作的機器嗎?cpu并不是一開始就在運行吧?我們如果創建一段程序,想要去執行它,除了設置它的狀態為RUNNING,并且表示他能夠唄調度,但是實際上,cpu怎么知道,他應該去執行什么呢? 或者說,cpu怎么知道,他何時應該執行命令? 畢竟即便是匯編代碼,想要cpu開始去執行,讓他的CS:IP開始偏轉,不也需要去運行這個程序嗎?然而我們就是把它的狀態標記成RUNNING,這合適嗎?還有什么其他的步驟?
其實現在一想,自己的一些疑問也有點意思,但是同時理解了之后,回答這些疑問也是比較輕松的,不知道自己和AI大戰之后得出來的結論正確沒有,如果有什么錯誤,希望給我能留言!
1. gdb
-
誰調用了syscall? kernel/trap.c中的usertrap()這個函數
-
p->trapframe->a7的值代表什么意思? 通過hint,我從initcode.S里面發現,a7寄存器代表了執行系統調用的類型,這里應該也是代表了執行的系統調用類型
-
cpu之前是什么模式? 在這里,我輸入
p /x $sstatus打印出的值為0x200000022,而當我重新運行,設置斷點在usertrap處,輸入打印出來的值為0x200000020,我調了一下,發現是intr_on()這個函數執行之后改變的,感覺應該關系不是很大?全英文的那個手冊也很勸退,之前的cpu模式應該是用戶態吧,目前應該是超級用戶(問的AI)
-
num存在那個寄存器? 通過對應的sepc,找到對應的panic行,發現num對應了a3這個寄存器,而內核崩潰的原因是因為訪問了未映射的地址0,scause的值記錄了觸發異常的原因。
-
至于panic的時候,正在運行的進程,我倒是沒有找出來,gdb在kernel進入panic的時候,也跟著陷入了,即便是在panic里面打印相對應的進程信息也沒有找到答案。
好了,實驗完成之后,不要忘記將你的代碼恢復原樣!
2. Trace
這個實驗要求,最開始確實沒看懂,我總是想象不出來要如何去修改一些代碼,使得能夠滿足要求,
但是hint還是很有用的,跟著hint來完全可以弄出來。
首先,trace就是說,對于每一個系統調用,你都需要跟蹤調用進程,系統調用的名稱,系統調用的返回值,直接給我說這些東西,我肯定是一頭霧水,但是實驗確實也給了足夠的hint讓我們完成這個lab,總體來講,還是比較簡單的。
首先,我們的trace.c貌似已經為我們準備好了?我們在user空間里面只需要修改makefile/usys.pl以及user.h,而trace的函數簽名已經在trace.c中確定了:
entry("trace"); //usys.plint trace(int); //user.h$U/_trace\ //makefile
接下來,便是在syscall的施工了,最開始,我們需要進入到proc.h修改我們的proc結構體的成員,為其加上int tracing的成員,作為tracing的mask掩碼。
而后,我們在調用trace系統調用的時候,需要為我們的proc這個tracing參數賦值,所以就在sysproc.c添加我們的trace系統調用是如何執行的:
uint64 sys_trace(void) {int mask;//從傳來的第一個參數中獲取maskargint(0, &mask);myproc()->tracing = mask;return 0;
}
這里為什么不直接通過參數來獲得?ai說這里是xv的特性,就不深究了,argint就是從參數中獲取第一個值,并賦給mask,然后為我們的tracing賦值,這樣,我們就能夠進行判斷了!
僅僅是賦值,并不能直接就能夠輸出我們的進程信息,我們還需要在syscall.c中的syscall函數中,添加合理的輸出信息:
void
syscall(void)
{int num;struct proc *p = myproc();num = p->trapframe->a7;if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {// Use num to lookup the system call function for num, call it,// and store its return value in p->trapframe->a0p->trapframe->a0 = syscalls[num]();//修改在此處,根據掩碼來輸出相應的系統調用信息。if ((p->tracing >> num) & 1) {printf("%d: syscall %s -> %ld\n", p->pid, syscall_str[num], p->trapframe->a0);}} else {printf("%d %s: unknown sys call %d\n",p->pid, p->name, num);p->trapframe->a0 = -1;}
}
當然,我們的每個系統調用都有相對應的數字,所以我們還需要在syscall.h中添加映射:
#define SYS_trace 22
并且將我們的映射和對應的系統調用添加進系統調用的數組中:
static uint64 (*syscalls[])(void) = {
[SYS_fork] sys_fork,
[SYS_exit] sys_exit,
[SYS_wait] sys_wait,
[SYS_pipe] sys_pipe,
[SYS_read] sys_read,
[SYS_kill] sys_kill,
[SYS_exec] sys_exec,
[SYS_fstat] sys_fstat,
[SYS_chdir] sys_chdir,
[SYS_dup] sys_dup,
[SYS_getpid] sys_getpid,
[SYS_sbrk] sys_sbrk,
[SYS_sleep] sys_sleep,
[SYS_uptime] sys_uptime,
[SYS_open] sys_open,
[SYS_write] sys_write,
[SYS_mknod] sys_mknod,
[SYS_unlink] sys_unlink,
[SYS_link] sys_link,
[SYS_mkdir] sys_mkdir,
[SYS_close] sys_close,
//添加這一行就可以了
[SYS_trace] sys_trace,
};然后,我們的syscall_str是未定義的,這里需要我們自己去定義一個數組:
//名稱數組索引
static char* syscall_str[] = {
[SYS_fork] "fork",
[SYS_exit] "exit",
[SYS_wait] "wait",
[SYS_pipe] "pipe",
[SYS_read] "read",
[SYS_kill] "kill",
[SYS_exec] "exec",
[SYS_fstat] "fstat",
[SYS_chdir] "chdir",
[SYS_dup] "dup",
[SYS_getpid] "getpid",
[SYS_sbrk] "sbrk",
[SYS_sleep] "sleep",
[SYS_uptime] "uptime",
[SYS_open] "open",
[SYS_write] "write",
[SYS_mknod] "mknod",
[SYS_unlink] "unlink",
[SYS_link] "link",
[SYS_mkdir] "mkdir",
[SYS_close] "close",
[SYS_trace] "trace",
};
但是通過這樣,我們會發現,fork出來的子進程,無法繼承父進程的tracing字段,因為我們tracing是新增的,并沒有啟用任何繼承操作,所以在proc.c里面,需要對fork函數進行修改添加以下的內容:
np->tracing = p->tracing; // 繼承父進程的跟蹤狀態
這樣,我們的trace就完成了!
3. attack
這個lab是真的卡了我很久,課上說這次的lab很簡單,可是對于我這種菜雞還是太過困難了。
首先觀察attacktest的函數,發現其中生成一個secret,隨后調用調用secret.c中的函數,就是將一串密鑰寫入內存中,后回到attacktest,調用我們需要寫的的attack,我們的attack需要將獲取的密鑰寫入到fd2中,以供檢查,然后attacktest會比對我們的獲取的密鑰是否和真正的密鑰相同。
總體流程如上,這里需要操作內存頁,好難~先來看看我們的secret.c
int
main(int argc, char *argv[])
{if(argc != 2){printf("Usage: secret the-secret\n");exit(1);}char *end = sbrk(PGSIZE*32);end = end + 9 * PGSIZE;strcpy(end, "my very very very secret pw is: ");strcpy(end+32, argv[1]);exit(0);
}
這里分配了32個內存頁,隨后在第10頁中寫入了我們的密鑰,同時帶有一個前綴,我最開始的思路其實就是根據前綴去尋找密鑰,但是事實證明,這個方法行不通,于是我開始從其他的突破點入手,比如說,這是一個頁,我可以通過找到這個頁,并且我們也能夠知道其偏移量,這樣,我們就有能力去尋找這個密鑰,但是如何去尋找到這一頁地址?我們如何知道,重新分配的內存頁,哪一頁才是我們需要的?我想,這就是強迫我們去讀源碼的一個lab。
去讀源碼然后分析也是一個很艱難的過程,這里大部分也參考了其他的博客,我一個人肯定是寫不出來的😭
首先我們需要了解的是內存頁的分配與回收(位于kernel/kalloc.c),xv6的內存是采取棧式的鏈表管理,分配時,從棧中取出內存頁,回收的時候則推回棧頂,這也是我們尋找真正的頁的根基。
隨后我們需要知道,在attacktest中,attack之前,到底分配了多少,回收了多少內存頁,只要知道這個,我們的困難就迎刃而解了。當然,雖然說上去很簡單,但這也要求我們必須熟悉其中涉及的每一個系統調用,函數會分配的頁數,這也是我們熟悉xv6的一個很好的機會。
首先是attacktest中的fork(),這是一個系統調用,位于/kernel/proc.c,總所周知,每一個進程都會分配一個內存頁,fork當然也會,當我們進入到fork的函數體的時候,也確實如此,他通過調用allocproc來分配空間,在allocproc中:
// Allocate a trapframe page.if((p->trapframe = (struct trapframe *)kalloc()) == 0){freeproc(p);release(&p->lock);return 0;}// An empty user page table.p->pagetable = proc_pagetable(p);if(p->pagetable == 0){freeproc(p);release(&p->lock);return 0;}
他通過kalloc分配了一個頁表,這個頁表存儲上下文信息,而又通過proc_pagetable分配了一個頁,這個頁是虛擬頁到物理頁的映射,在內部,他會創建一個新的頁表:
pagetable = uvmcreate();
if (pagetable == 0)return 0;
然后將虛擬地址空間的一部分映射到物理地址上面:
// 映射 trampoline 代碼(用于系統調用返回)// trampoline 是在用戶虛擬地址空間的最頂端,負責在系統調用的上下文切換時跳轉到內核。// 該映射設置為只讀且可執行(PTE_R | PTE_X),因為 trampoline 是內核代碼// 注意:此區域僅用于系統調用跳轉,并不是用戶程序直接訪問的,因此沒有 PTE_U 標志if(mappages(pagetable, TRAMPOLINE, PGSIZE,(uint64)trampoline, PTE_R | PTE_X) < 0){uvmfree(pagetable, 0);return 0;}// 映射 trapframe 頁,位于 trampoline 頁面下方// trapframe 用于保存進程的上下文(寄存器值、堆棧指針等),// 這是在系統調用或中斷時保存進程狀態的地方,供 trampoline 使用。// 這里的映射設置為可讀寫(PTE_R | PTE_W),因為操作系統需要在該頁寫入和讀取數據。if(mappages(pagetable, TRAPFRAME, PGSIZE,(uint64)(p->trapframe), PTE_R | PTE_W) < 0){uvmunmap(pagetable, TRAMPOLINE, 1, 0);uvmfree(pagetable, 0);return 0;}
我們的xv6是采取的三級頁表結構,最開始創建的pagetable作為我們的根頁表,我們的trampoline和trapframe(之前已經分配)作為我們的三級頁表,但是此時還需要一個二級頁表來幫助映射,所以我們還需要一個分配一個二級頁表來維護完整的映射結構,因此此處分配了三個頁表,對應了pagetable,trampoline和二級頁表。
回到我們的fork()
// Copy user memory from parent to child.if(uvmcopy(p->pagetable, np->pagetable, p->sz) < 0){freeproc(np);release(&np->lock);return -1;}
這里將我們分配的內存從父進程復制到子進程中,這里原父進程也占用了四個頁表,并且還需要一個一級頁表和二級頁表來建立映射,所賜此處又新分配了6個頁表。
所以我們的fork一共分配了10個頁表。
然后回到我們的attacktest,我們可以看見,下一步可能有內存分配的地方就是exec()去執行我們的secret了,exec可以說是最復雜的一個系統調用了,但是我們的目的不是深入分析他,目前只需要知道他分配了哪些內存即可,他在代碼前面會使用proc_pagetable去創建新的頁表以此來替換舊頁表。
if((pagetable = proc_pagetable(p)) == 0)goto bad;
隨后,exec會遍歷elf文件的頭表,會將我們的LOAD段加入我們的內存頁中,使用readelf查看_secret如下:
root@rinai-VMware-Virtual-Platform:/home/rinai/6S081/xv6-labs-2024# readelf -l user/_secret Elf 文件類型為 EXEC (可執行文件)
Entry point 0x5c
There are 3 program headers, starting at offset 64程序頭:Type Offset VirtAddr PhysAddrFileSiz MemSiz Flags AlignRISCV_ATTRIBUT 0x00000000000073e5 0x0000000000000000 0x00000000000000000x0000000000000047 0x0000000000000000 R 0x1LOAD 0x0000000000001000 0x0000000000000000 0x00000000000000000x0000000000000901 0x0000000000000901 R E 0x1000LOAD 0x0000000000002000 0x0000000000001000 0x00000000000010000x0000000000000000 0x0000000000000020 RW 0x1000Section to Segment mapping:段節...00 .riscv.attributes 01 .text .rodata 02 .data .bss
結果如上,存在兩個LOAD段,需要分別加載到不同的內存頁中,(大概知道是咋回事就行),同時,我們當然還需要一級頁表和二級頁表來進行映射,因此,這里創建了四個頁。
加載段到內存的代碼是這樣寫的:
// 加載程序段到內存中for(i=0, off=elf.phoff; i<elf.phnum; i++, off+=sizeof(ph)){if(readi(ip, 0, (uint64)&ph, off, sizeof(ph)) != sizeof(ph))goto bad;if(ph.type != ELF_PROG_LOAD) // 跳過非 LOAD 類型段continue;if(ph.memsz < ph.filesz) // 內存大小不能小于文件大小goto bad;if(ph.vaddr + ph.memsz < ph.vaddr) // 防止溢出goto bad;if(ph.vaddr % PGSIZE != 0) // 地址必須頁對齊goto bad;// 為段分配內存(虛擬地址)uint64 sz1;if((sz1 = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz, flags2perm(ph.flags))) == 0)goto bad;sz = sz1;// 從文件中讀取代碼或數據,寫入到段對應虛擬地址中if(loadseg(pagetable, ph.vaddr, ip, ph.off, ph.filesz) < 0)goto bad;}
隨后還會分配用戶棧:
// 將棧的起始地址 `sz` 向頁邊界對齊sz = PGROUNDUP(sz);uint64 sz1;// 為進程分配一塊內存區域,作為用戶棧空間。// uvmalloc 會根據提供的頁表 `pagetable` 分配內存,// 并將分配的內存區域的結束地址返回給 `sz1`// 新的棧空間大小從 `sz` 到 `sz + (USERSTACK + 1) * PGSIZE`,分配的是可寫內存 (PTE_W)if ((sz1 = uvmalloc(pagetable, sz, sz + (USERSTACK + 1) * PGSIZE, PTE_W)) == 0)goto bad; // 如果分配失敗,跳轉到錯誤處理部分// 更新棧的結束地址為分配的內存的結束地址sz = sz1;// 清除棧的保護區域,使其變為不可訪問// 棧的保護區域位于棧的頂部 (棧底的內存頁),// 用來防止棧溢出攻擊,當訪問該區域時會觸發頁面錯誤 (page fault)uvmclear(pagetable, sz - (USERSTACK + 1) * PGSIZE);// 設置棧指針 `sp` 為棧的結束地址sp = sz;// 計算棧的基址,即棧的底部地址// `stackbase` 指向棧空間的起始位置stackbase = sp - USERSTACK * PGSIZE;
此時,又分配了兩頁內存。
最后,還會調用函數來釋放舊的頁表
void
proc_freepagetable(pagetable_t pagetable, uint64 sz)
{uvmunmap(pagetable, TRAMPOLINE, 1, 0);uvmunmap(pagetable, TRAPFRAME, 1, 0);uvmfree(pagetable, sz);
}
其中,trampoline是整個操作系統共享,不會被釋放,tramframe也是一樣,是當前進程用戶態和內核態轉換時用到的存儲區,不會被釋放,所以最后會釋放舊頁表占用的5頁和用戶的4頁內存。
exec一共分配了9頁,釋放了9頁,而后,開始執行我們的secret程序,他申請了32頁內存,并且在第10頁寫入了相對應的secret,到現在,我們的attacktest已經申請過了42頁內存。
而secret實際上是作為fork出來的子進程運行的,而在我們的父進程中,首先就是等待secret子進程的退出,此時,我們分配的內存頁都會被回收,此處的回收順序,也應當重點關注(kernel/proc.c):
// 釋放進程使用的資源并重置進程狀態
static void
freeproc(struct proc *p)
{// 如果該進程的 trapframe(保存用戶態寄存器上下文)存在,則釋放它占用的內核內存if(p->trapframe)kfree((void*)p->trapframe);// 將 trapframe 指針置為空,表示已釋放p->trapframe = 0;// 如果該進程的頁表存在,則釋放該頁表所管理的所有用戶態內存if(p->pagetable)proc_freepagetable(p->pagetable, p->sz);// 清除種種標志p->pagetable = 0;p->sz = 0;p->pid = 0;p->parent = 0;p->name[0] = 0;p->chan = 0;p->killed = 0;p->xstate = 0;p->state = UNUSED;
}
可以看到,我們首先釋放的是trapframe,隨后釋放所有的用戶態內存:
uvmfree(pagetable_t pagetable, uint64 sz)
{if(sz > 0)uvmunmap(pagetable, 0, PGROUNDUP(sz)/PGSIZE, 1);freewalk(pagetable);
}
這個函數會根據地址從低到高釋放內存,釋放順序為:data + text段,用戶棧+page guard,最后是32頁堆內存,此時的空閑頁表的順序為:5頁頁表,32頁頁表,用戶棧,page guard。
隨后再次執行fork,緊接著又是exec系統調用,根據之前的經驗,fork會分配10頁,而exec分配了9頁,釋放了9頁,數量不變,此時,我通過計算會發現,第17頁,就是我們需要尋找的答案:
int main(int argc, char *argv[]) {char *end = sbrk(PGSIZE*32);end = end + 16 * PGSIZE;printf("secret: %s\n", end+32);write(2, end+32, 8);exit(0);
}
這個lab就跟解密一樣,確實感覺很有難度,包括分析的視角,深度,感覺都不是一般人能想到的,鍛煉了獨立思考的能力(雖然我沒有),還能夠理解xv6的源碼,感覺是很棒的lab,就是感覺對我這種人來說,太難了💀,開始擔心起之后的lab會有多恐怖了。
寫到這里,我又去官網上看了看課程的一些準備工作,包括要去看什么什么源碼,我基本只看了手冊和課,所以覺得困難也是理所當然的吧。(潤去看代碼了😡)
我一個人肯定寫不出這樣的lab了,參考文獻:
https://nos-ae.github.io/posts/attack-xv6/
https://blog.csdn.net/weixin_42543071/article/details/143351746
,CatM的最大速率?)
)







)



?(Grok3 回答))
)




