文章目錄
- ==有需要本項目的代碼或文檔以及全部資源,或者部署調試可以私信博主==
- 項目介紹
- 每文一語
有需要本項目的代碼或文檔以及全部資源,或者部署調試可以私信博主
項目介紹
隨著我國農業數字化進程的加快,農產品批發市場每天都會產生海量的價格數據,這些數據涵蓋了豐富的時空、品類和價格信息。然而,傳統的處理方式在應對大規模、動態性強的數據時,往往存在計算速度慢、擴展性不足、分析維度有限等問題,難以滿足政府、市場與生產者對實時監測與深度挖掘的需求。針對這一現狀,本項目依托 Hadoop 生態體系,構建了一套集數據采集、存儲、處理、分析和可視化于一體的分布式農產品價格分析平臺,為農業經濟決策與市場調控提供技術支持。
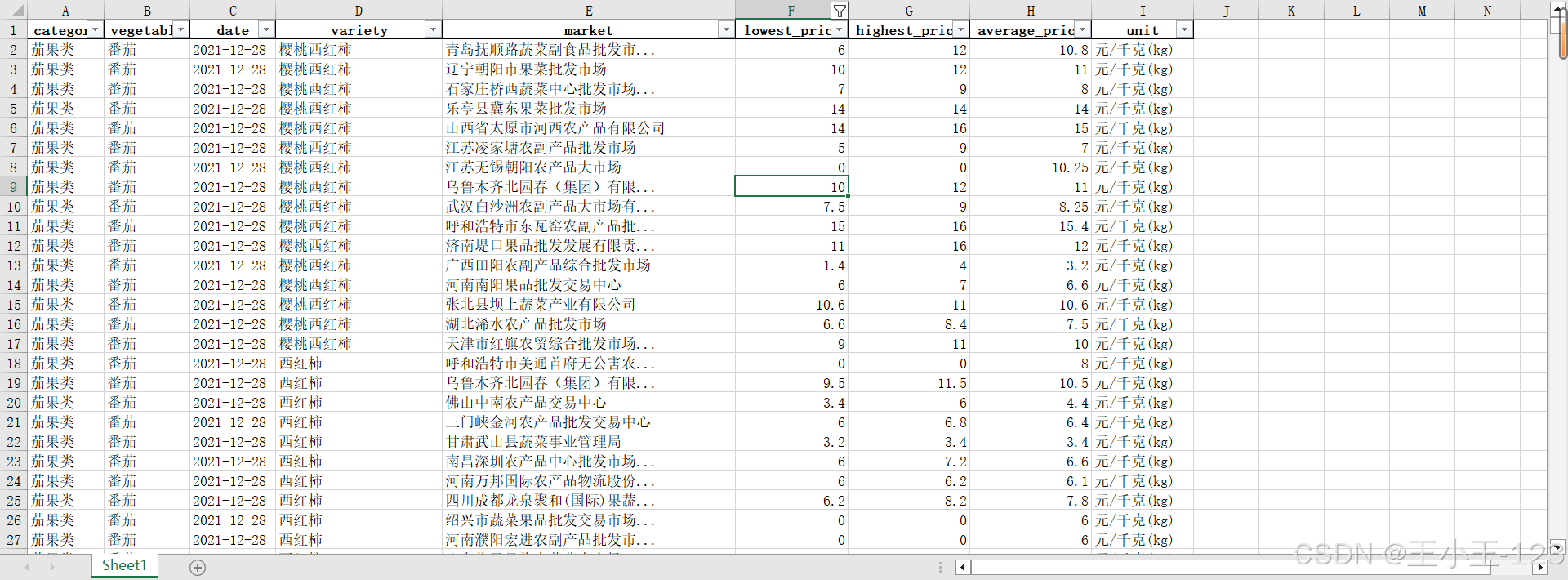
在數據采集環節,項目針對“惠農網”和“食品商務網”等公開渠道開發了爬蟲程序,抓取了近 10 萬條包含品類、品種、價格區間、產地和時間等核心字段的數據。采集過程中,通過字段映射、格式統一及初步異常剔除,確保了數據在進入后續處理環節前的完整性與規范性。
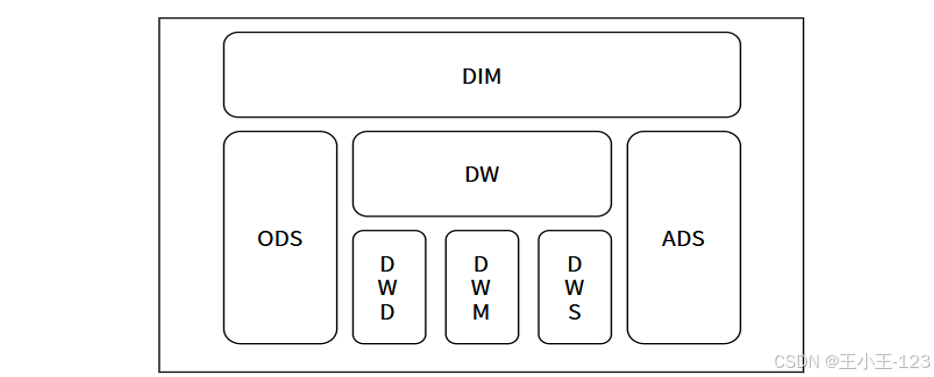
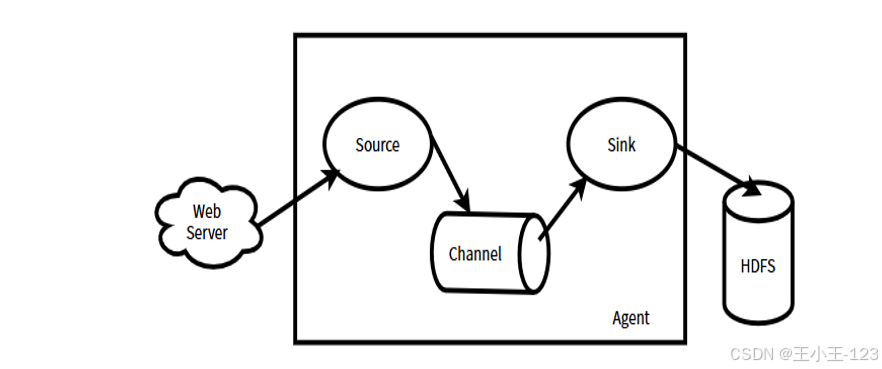
在存儲與傳輸方面,項目利用 Flume 搭建了實時數據匯聚通道,將原始數據高效導入到 Hadoop 分布式文件系統(HDFS)中,依托其高容錯和線性擴展能力實現海量數據的安全存儲。為便于后續分析,項目采用 Hive 構建了分層數據倉庫,將數據按原始層、明細層和匯總分析層進行結構化管理,從而提升了查詢效率和數據可追溯性。此外,通過 Sqoop 實現了 Hadoop 與關系型數據庫的雙向數據傳輸,使數據既可用于批量分析,又能靈活對接本地分析環境。

在數據處理環節,平臺基于 MapReduce 對原始數據執行清洗與預處理,包括時間字段標準化、缺失值填補、異常值識別、市場名稱歸一化等操作,并提取多維特征以支撐后續分析。為了提高預測能力,項目分別構建了 ARIMA 時間序列模型與隨機森林回歸模型,對價格變化趨勢進行建模與對比。結果顯示,隨機森林在捕捉非線性關系和多因素交互方面表現更優,擬合精度和預測穩定性均高于 ARIMA 模型,尤其在短期預測中優勢明顯。
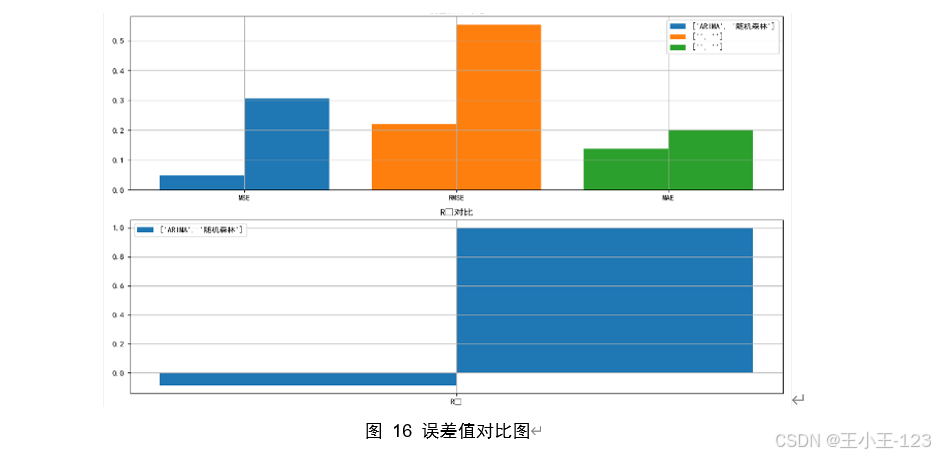

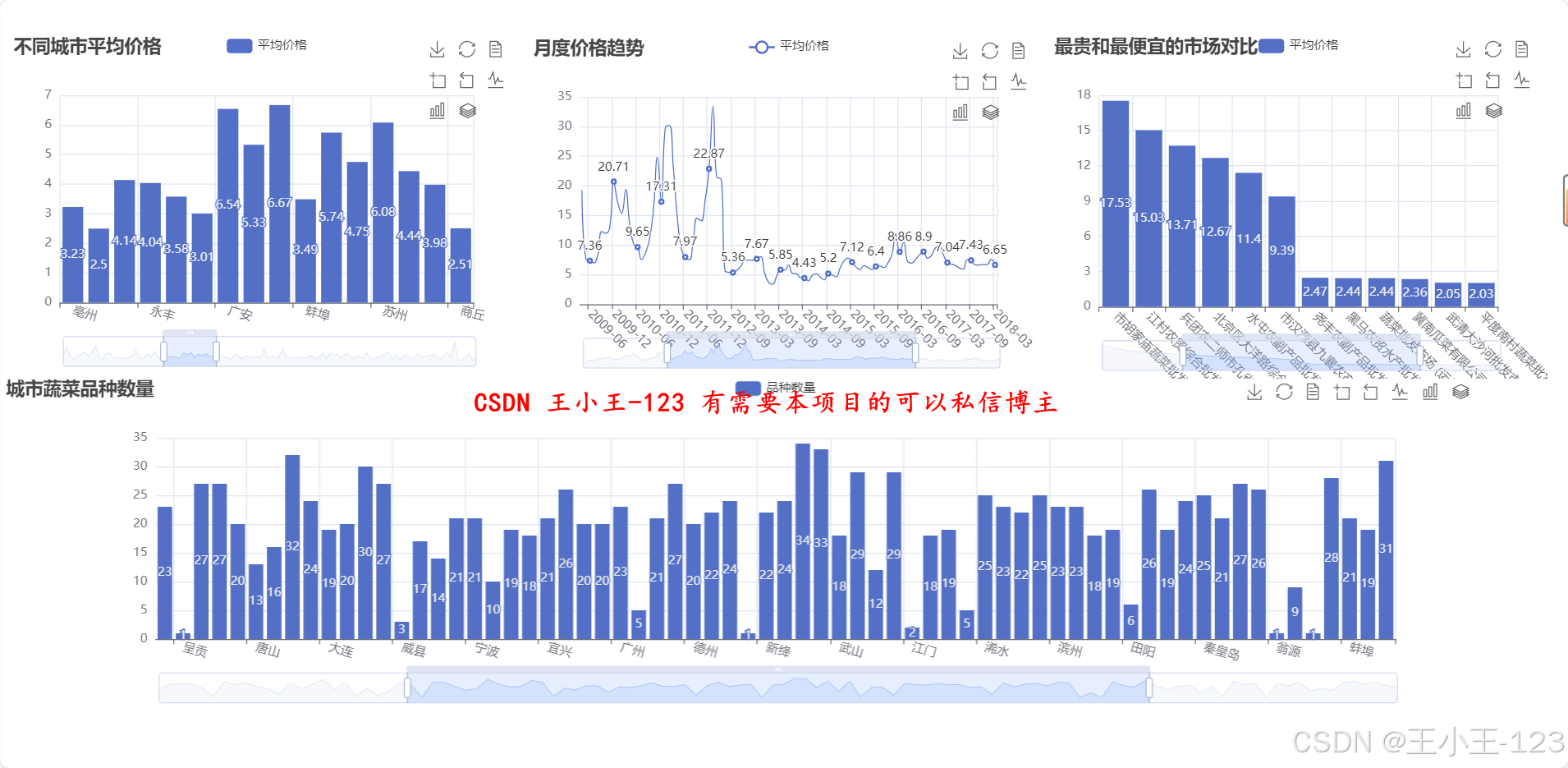
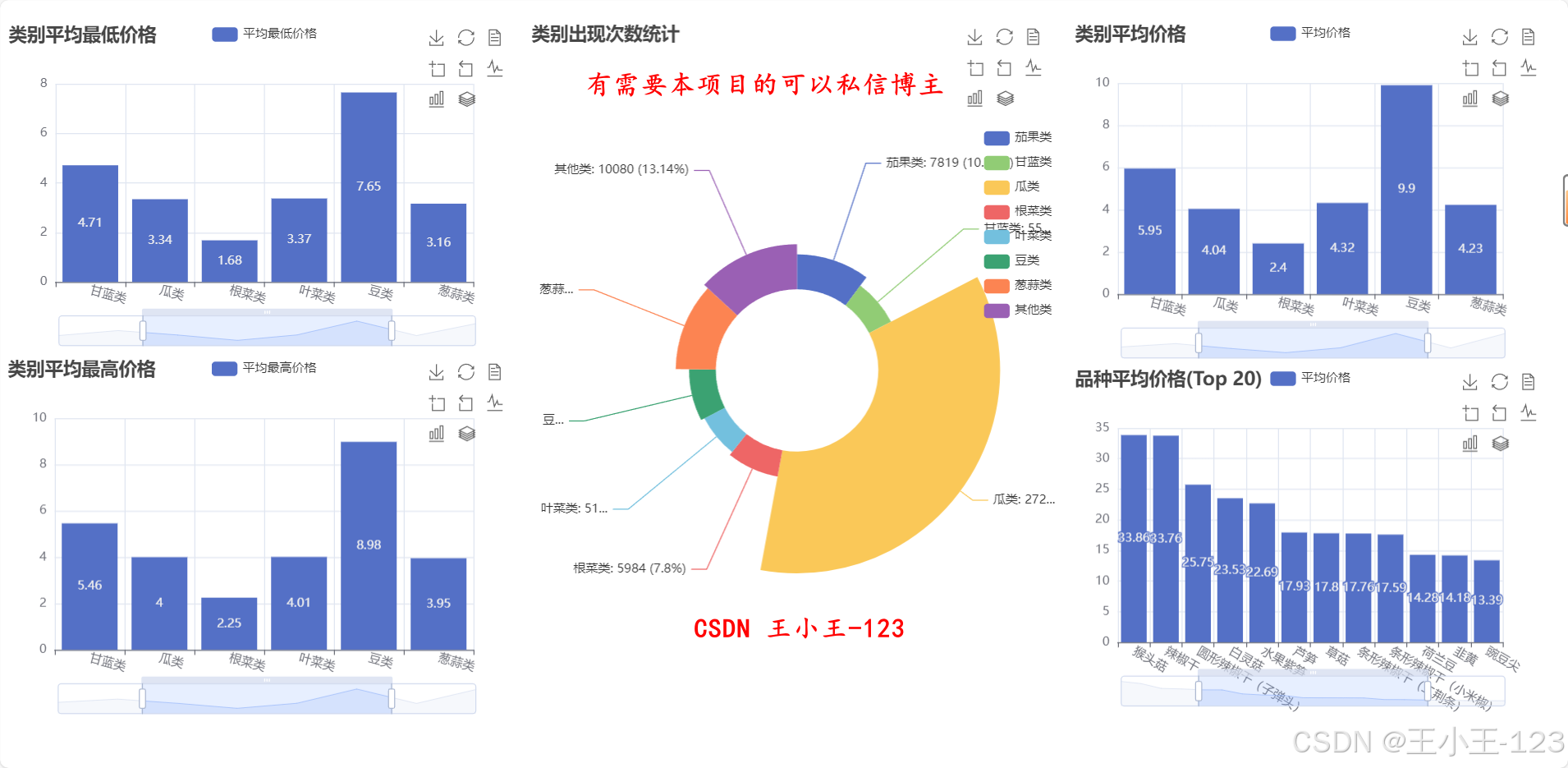
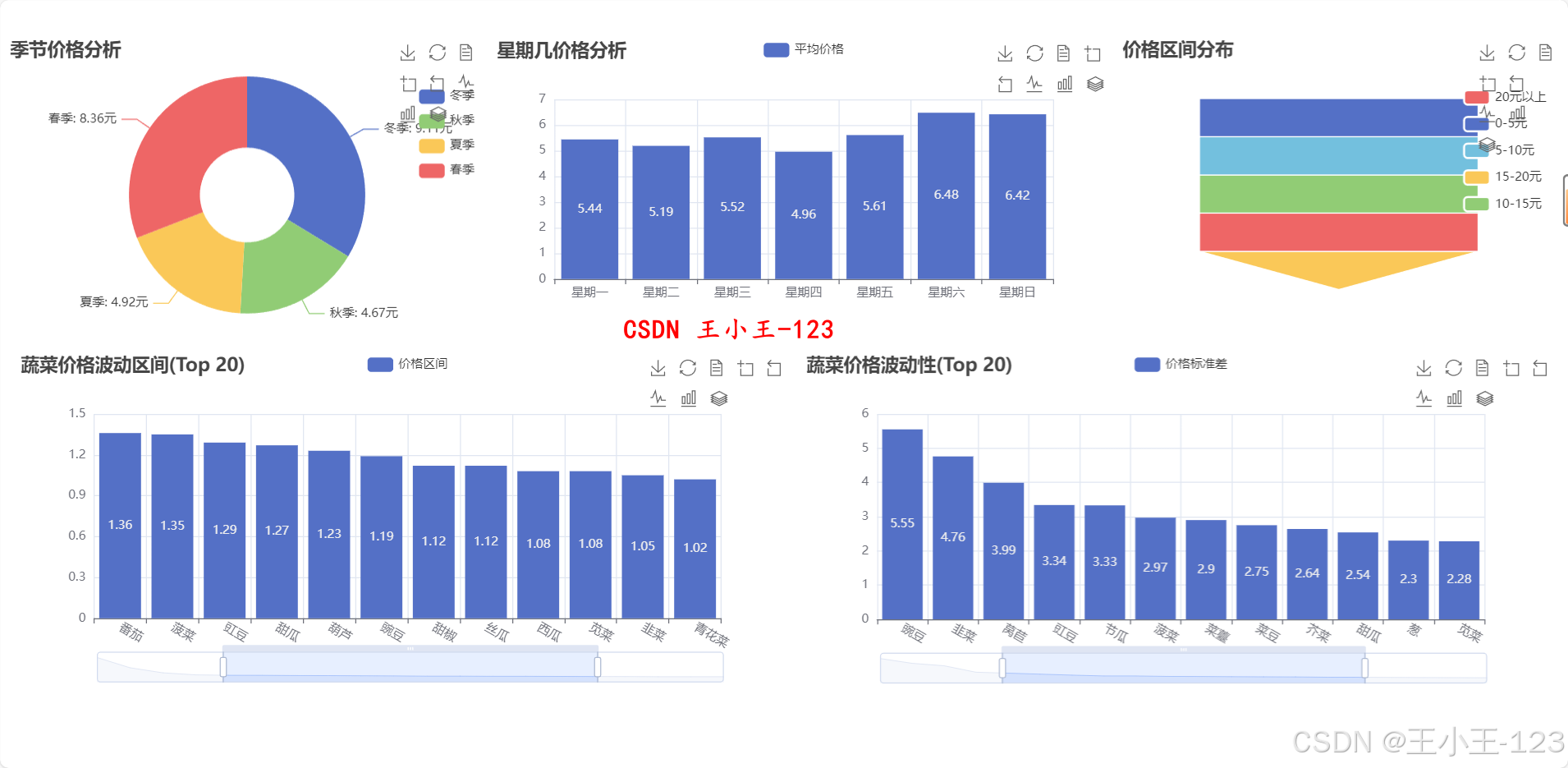
在可視化部分,平臺采用 Echarts 和 Jupyter Notebook 結合的方式,將分析結果轉化為直觀的交互式圖表。可視化內容涵蓋多類主題:如不同城市價格分布、各品類價格區間、季節性波動趨勢、市場供需差異等。通過這些可視化結果,可以直觀揭示區域間價格差距、節令對價格的影響、品類結構變化等特征。例如,冬季平均價格顯著高于秋季,部分高端品類在特定地區長期維持高價,周末價格存在小幅上升趨勢等。這些發現可為農戶優化種植計劃、批發商調整采購策略以及政府制定調控政策提供參考。
項目研究表明,農產品價格不僅受產銷兩端的供求關系、運輸與儲存成本的影響,還會受到氣候、季節、消費習慣等多種因素的共同作用。在當前的試驗預測中,針對河南地區胡蘿卜的短期價格預測顯示價格在未來數日內趨于穩定,這印證了模型在特定場景下的實用性。
本項目的核心價值在于,將 Hadoop 的分布式存儲與計算能力,與機器學習模型及可視化分析手段有機結合,構建了一個可擴展、可持續迭代的農產品價格分析體系。通過高效的數據管道和清晰的可視化呈現,能夠幫助市場參與者更快速地掌握關鍵信息、降低決策風險、提升應對市場波動的能力。
每文一語
成功在于堅持



)

)








)
)
Homebrew 的安裝和使用)
全解析2)

