Spark Core
- 什么是 RDD
代碼中是一個抽象類,它代表一個彈性的、不可變、可分區、里面的元素可并行計算的集合
彈性
存儲的彈性:內存與磁盤的自動切換;
容錯的彈性:數據丟失可以自動恢復;
計算的彈性:計算出錯重試機制;
分片的彈性:可根據需要重新分片。
分布式:數據存儲在大數據集群不同節點上
數據集:RDD 封裝了計算邏輯,并不保存數據
?數據抽象:RDD 是一個抽象類,需要子類具體實現
?不可變:RDD 封裝了計算邏輯,是不可以改變的,想要改變,只能產生新的 RDD在新的 RDD 里面封裝計算邏輯
?可分區、并行計算
二.核心屬性
分區列表
RDD 數據結構中存在分區列表,用于執行任務時并行計算,是實現分布式計算的重要屬性。
RDD 之間的依賴關系
RDD 是計算模型的封裝,當需求中需要將多個計算模型進行組合時,就需要將多個 RDD 建立依賴關系
三. 執行原理
啟動 Yarn 集群環境
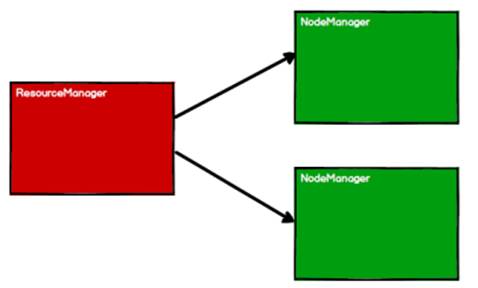
Spark 通過申請資源創建調度節點和計算節點
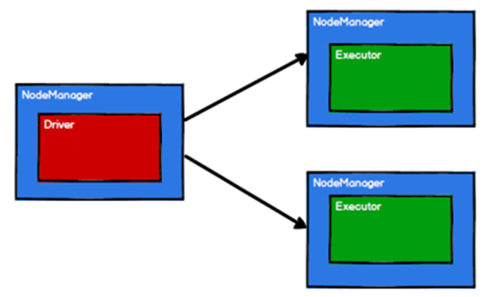
Spark 框架根據需求將計算邏輯根據分區劃分成不同的任務

調度節點將任務根據計算節點狀態發送到對應的計算節點進行計算
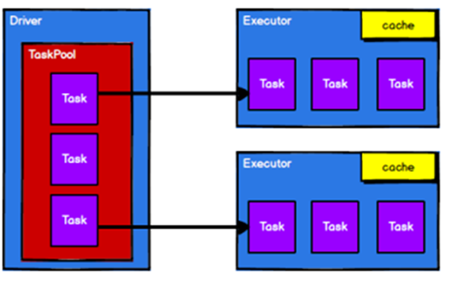
四.RDD 序列化
閉包檢查
序列化方法和屬性
Kryo 序列化框架
五.RDD 依賴關系
RDD 血緣關系
RDD 只支持粗粒度轉換,即在大量記錄上執行的單個操作。將創建 RDD 的一系列 Lineage(血統)記錄下來,以便恢復丟失的分區
RDD 依賴關系
RDD 窄依賴
RDD 寬依賴
寬依賴表示同一個父(上游)RDD 的 Partition 被多個子(下游)RDD 的 Partition 依賴,會引起 Shuffle,總結:寬依賴我們形象的比喻為多生
RDD 階段劃分
RDD 任務劃分

六.RDD 持久化
RDD Cache 緩存
Spark 會自動對一些 Shuffle 操作的中間數據做持久化操作(比如:reduceByKey)。這樣做的目的是為了當一個節點 Shuffle 失敗了避免重新計算整個輸入。但是,在實際使用的時候,如果想重用數據,仍然建議調用 persist 或 cache
RDD CheckPoint 檢查點
緩存和檢查點區別
七.RDD 分區器
只有 Key-Value 類型的 RDD 才有分區器,非 Key-Value 類型的 RDD 分區的值是 None
? 每個 RDD 的分區 ID 范圍:0 ~ (numPartitions - 1),決定這個值是屬于那個分區的。
- Hash 分區:對于給定的 key,計算其 hashCode,并除以分區個數取余。
- Range 分區:將一定范圍內的數據映射到一個分區中,盡量保證每個分區數據均勻,而且分區間有序
八.RDD 文件讀取與保存
?text 文件

sequence 文件

sequence 文件

object 對象文件

Spark運行架構
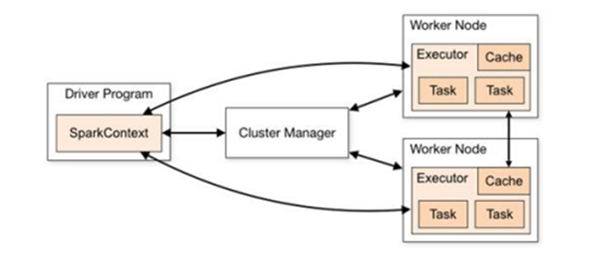
核心組件
Driver
Spark 驅動器節點,用于執行 Spark 任務中的 main 方法,負責實際代碼的執行工作。
Driver 在 Spark 作業執行時主要負責:
? 將用戶程序轉化為作業(job)
? 在 Executor 之間調度任務(task)
? 跟蹤 Executor 的執行情況
? 通過 UI 展示查詢運行情況
Executor
Spark Executor 是集群中工作節點(Worker)中的一個 JVM 進程,負責在 Spark 作業中運行具體任務(Task),任務彼此之間相互獨立
核心概念

有向無環圖(DAG)
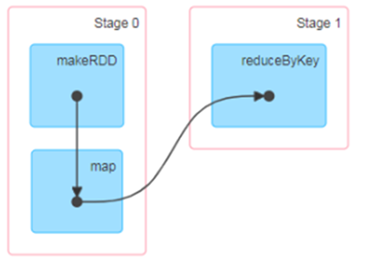
提交流程
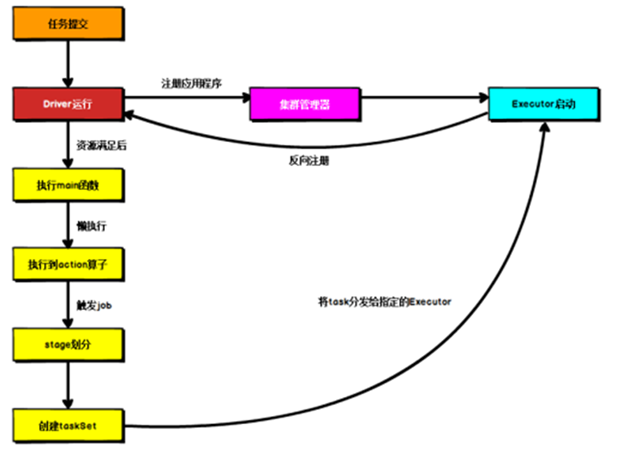
)





)




試題速瀏、分類及淺析)







