網絡模型
定義一個兩層網絡
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F# 定義神經網絡模型
class Net(nn.Module):def __init__(self, init_x=0.0):super().__init__()self.fc1 = nn.Linear(1, 10)self.fc2 = nn.Linear(10, 1)def forward(self, x):x = self.fc1(x)x = F.relu(x)x = self.fc2(x)return x# 初始化模型
model = Net()# 定義損失函數和優化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 生成一些示例數據
x_train = torch.tensor([[1.0], [2.0], [3.0], [4.0]], dtype=torch.float32)
y_train = torch.tensor([[2.0], [4.0], [6.0], [8.0]], dtype=torch.float32)# 訓練模型
num_epochs = 1000
for epoch in range(num_epochs):# 清零梯度optimizer.zero_grad()# 前向計算outputs = model(x_train)loss = criterion(outputs, y_train)# 反向傳播loss.backward()# 更新參數optimizer.step()if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')# 保存模型
torch.save(model.state_dict(), 'model.pth')# 加載模型
loaded_model = Net()
loaded_model.load_state_dict(torch.load('model.pth'))
loaded_model.eval() # 將模型設置為評估模式# 輸入新數據進行預測
new_input = torch.tensor([[5.0]], dtype=torch.float32)
with torch.no_grad():prediction = loaded_model(new_input)print(f"輸入 {new_input.item()} 的預測結果: {prediction.item()}")
運行結果
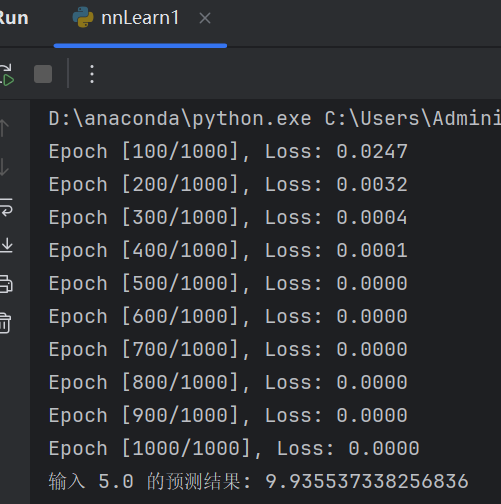
訓練好的參數值:
參數名: fc1.weight, 參數值: tensor([[ 0.5051],
? ? ? ? [ 0.2675],
? ? ? ? [ 0.4080],
? ? ? ? [ 0.3069],
? ? ? ? [ 0.9132],
? ? ? ? [ 0.2250],
? ? ? ? [-0.2428],
? ? ? ? [ 0.4821],
? ? ? ? [ 0.0998],
? ? ? ? [ 0.6737]])
參數名: fc1.bias, 參數值: tensor([ 0.5201, -0.0252, ?0.0504, ?0.6593, -0.4250, ?0.6001, ?0.9645, -0.2310,
? ? ? ? -0.2038, ?0.2116])
參數名: fc2.weight, 參數值: tensor([[ 0.5492, ?0.2550, ?0.3046, ?0.3183, ?0.8147, ?0.3062, -0.4165, ?0.2969,
? ? ? ? ? 0.0482, ?0.5535]])
參數名: fc2.bias, 參數值: tensor([0.0147])
-
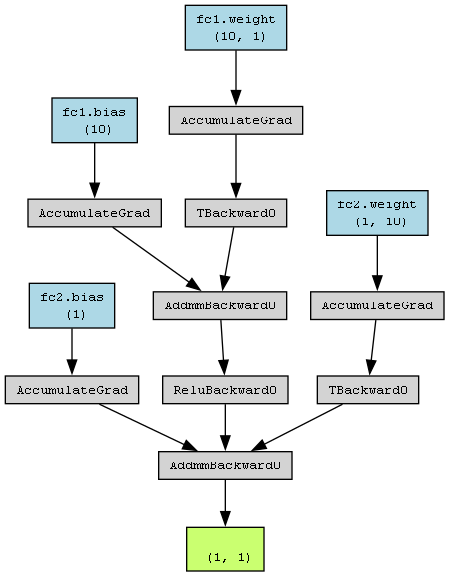
fc1?層:fc1.weight:這是輸入層到隱藏層的權重矩陣,其形狀為?(10, 1),意味著輸入層有 1 個神經元,隱藏層有 10 個神經元。矩陣中的每個元素代表從輸入神經元到對應隱藏層神經元的連接權重。fc1.bias:這是隱藏層每個神經元的偏置項,形狀為?(10,),也就是每個隱藏層神經元都有一個對應的偏置值。
-
fc2?層:fc2.weight:這是隱藏層到輸出層的權重矩陣,形狀為?(1, 10),表明隱藏層有 10 個神經元,輸出層有 1 個神經元。矩陣中的每個元素代表從隱藏層神經元到輸出層神經元的連接權重。fc2.bias:這是輸出層神經元的偏置項,形狀為?(1,),即輸出層只有一個神經元,所以只有一個偏置值。
不同的優化器
神經網絡入門—計算函數值-CSDN博客
激活函數解析
激活函數的作用
激活函數賦予神經網絡非線性映射能力,使其能夠更好地處理復雜的現實世界數據2。常見的激活函數包括ReLU、PReLU等。激活函數通常用于卷積層和全連接層,以增加模型的表達能力。
常見的激活函數
Sigmoid 函數
- 公式:
- 特點:輸出范圍在?
(0, 1)?之間,能夠把輸入映射為概率值,常用于二分類問題。不過它存在梯度消失問題,當輸入值非常大或者非常小時,梯度會趨近于 0。
import torch
import torch.nn.functional as Fx = torch.tensor([-2.0, -1.0, 0.0, 1.0, 2.0])
sigmoid_output = torch.sigmoid(x)
print("Sigmoid 輸出:", sigmoid_output)Tanh 函數
- 公式:\(\tanh(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}\)
- 特點:輸出范圍在?
(-1, 1)?之間,零中心化,相較于 Sigmoid 函數,梯度消失問題有所緩解,但仍然存在。
import torch
import torch.nn.functional as Fx = torch.tensor([-2.0, -1.0, 0.0, 1.0, 2.0])
tanh_output = torch.tanh(x)
print("Tanh 輸出:", tanh_output)ReLU 函數
- 公式:\(ReLU(x)=\max(0, x)\)
- 特點:計算簡單,能夠有效緩解梯度消失問題,在深度學習中被廣泛使用。不過它存在死亡 ReLU 問題,即某些神經元可能永遠不會被激活。
import torch
import torch.nn.functional as Fx = torch.tensor([-2.0, -1.0, 0.0, 1.0, 2.0])
relu_output = F.relu(x)
print("ReLU 輸出:", relu_output)?Leaky ReLU 函數
- 公式:\(LeakyReLU(x)=\begin{cases}x, & x\geq0 \\ \alpha x, & x < 0\end{cases}\),其中?\(\alpha\)?是一個小的常數,例如 0.01。
- 特點:解決了死亡 ReLU 問題,當輸入為負數時,也會有一個小的梯度。
import torch
import torch.nn.functional as Fx = torch.tensor([-2.0, -1.0, 0.0, 1.0, 2.0])
leaky_relu_output = F.leaky_relu(x, negative_slope=0.01)
print("Leaky ReLU 輸出:", leaky_relu_output)損失函數解析
# 定義損失函數和優化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)該程序使用了MSELoss損失函數和SGD優化器
全部損失函數總類有
__all__ = ["L1Loss","NLLLoss","NLLLoss2d","PoissonNLLLoss","GaussianNLLLoss","KLDivLoss","MSELoss","BCELoss","BCEWithLogitsLoss","HingeEmbeddingLoss","MultiLabelMarginLoss","SmoothL1Loss","HuberLoss","SoftMarginLoss","CrossEntropyLoss","MultiLabelSoftMarginLoss","CosineEmbeddingLoss","MarginRankingLoss","MultiMarginLoss","TripletMarginLoss","TripletMarginWithDistanceLoss","CTCLoss", ]
L1Loss:計算輸入和目標之間的平均絕對誤差(MAE),即?loss = 1/n * sum(|input - target|)。NLLLoss:負對數似然損失,常用于分類任務,通常在模型輸出經過?log_softmax?變換后使用。NLLLoss2d:二維的負對數似然損失,適用于圖像等二維數據的分類任務。PoissonNLLLoss:泊松負對數似然損失,適用于泊松分布的數據,常用于計數數據的回歸。GaussianNLLLoss:高斯負對數似然損失,假設數據服從高斯分布,用于回歸任務。KLDivLoss:Kullback-Leibler 散度損失,用于衡量兩個概率分布之間的差異。MSELoss:均方誤差損失,計算輸入和目標之間的平均平方誤差,即?loss = 1/n * sum((input - target) ** 2),常用于回歸任務。BCELoss:二元交叉熵損失,用于二分類任務,輸入和目標都應該是概率值(在 0 到 1 之間)。BCEWithLogitsLoss:將?Sigmoid?函數和?BCELoss?結合在一起,適用于輸入是未經過激活函數的原始輸出(logits)的情況。HingeEmbeddingLoss:用于度量兩個輸入樣本之間的相似性,常用于度量學習任務。MultiLabelMarginLoss:多標簽分類的邊緣損失,適用于一個樣本可能屬于多個類別的情況。SmoothL1Loss:平滑的 L1 損失,在 L1 損失的基礎上進行了平滑處理,在某些情況下比 L1 和 L2 損失表現更好。HuberLoss:也稱為平滑 L1 損失,結合了 L1 和 L2 損失的優點,對離群點更魯棒。SoftMarginLoss:用于二分類的軟邊緣損失,允許一些樣本在邊緣內。CrossEntropyLoss:交叉熵損失,通常是?log_softmax?和?NLLLoss?的組合,常用于多分類任務。MultiLabelSoftMarginLoss:多標簽軟邊緣損失,適用于多標簽分類問題,每個標簽都有一個獨立的分類器。CosineEmbeddingLoss:基于余弦相似度的嵌入損失,用于度量兩個輸入樣本之間的余弦相似度,常用于度量學習。MarginRankingLoss:邊緣排序損失,用于比較兩個輸入樣本的得分,常用于排序任務。MultiMarginLoss:多邊緣損失,用于多分類任務,基于每個類別的邊緣來計算損失。TripletMarginLoss:三元組邊緣損失,常用于度量學習,通過比較三元組(錨點、正樣本、負樣本)之間的距離來學習嵌入。TripletMarginWithDistanceLoss:結合了距離度量的三元組邊緣損失,在?TripletMarginLoss?的基礎上增加了距離度量的計算。CTCLoss:連接主義時間分類損失,常用于處理序列到序列的問題,如語音識別和手寫文字識別等,不需要對齊輸入和輸出序列。
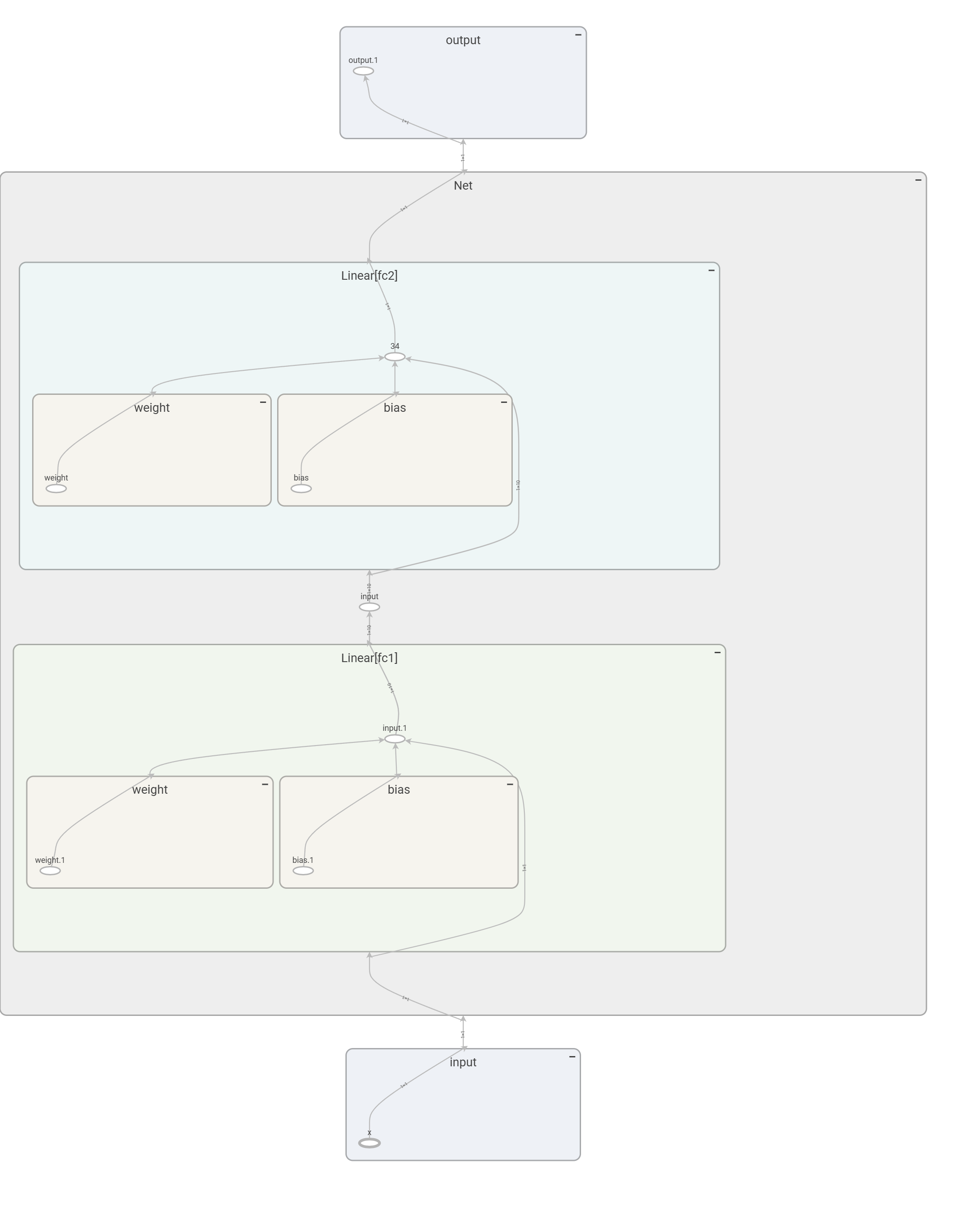
可視化模型
Graphviz
Download | Graphviz
安裝時候選擇添加path到環境變量
輸入
dot -version
顯示下面說明安裝成功
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchviz import make_dot# 定義神經網絡模型
class Net(nn.Module):def __init__(self, init_x=0.0):super().__init__()self.fc1 = nn.Linear(1, 10)self.fc2 = nn.Linear(10, 1)def forward(self, x):x = self.fc1(x)x = F.relu(x)x = self.fc2(x)return x# 初始化模型
model = Net()# 生成一個示例輸入
x = torch.randn(1, 1)# 前向傳播
y = model(x)# 繪制計算圖
dot = make_dot(y, params=dict(model.named_parameters()))
dot.render('net_model_structure', format='png', cleanup=True)
Tensorboard
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.tensorboard import SummaryWriter# 定義神經網絡模型
class Net(nn.Module):def __init__(self, init_x=0.0):super().__init__()self.fc1 = nn.Linear(1, 10)self.fc2 = nn.Linear(10, 1)def forward(self, x):x = self.fc1(x)x = F.relu(x)x = self.fc2(x)return x# 初始化模型
model = Net()# 初始化 SummaryWriter
writer = SummaryWriter('file/net_model')# 生成一個示例輸入
x = torch.randn(1, 1)# 將模型結構寫入 TensorBoard
writer.add_graph(model, x)# 關閉 writer
writer.close()
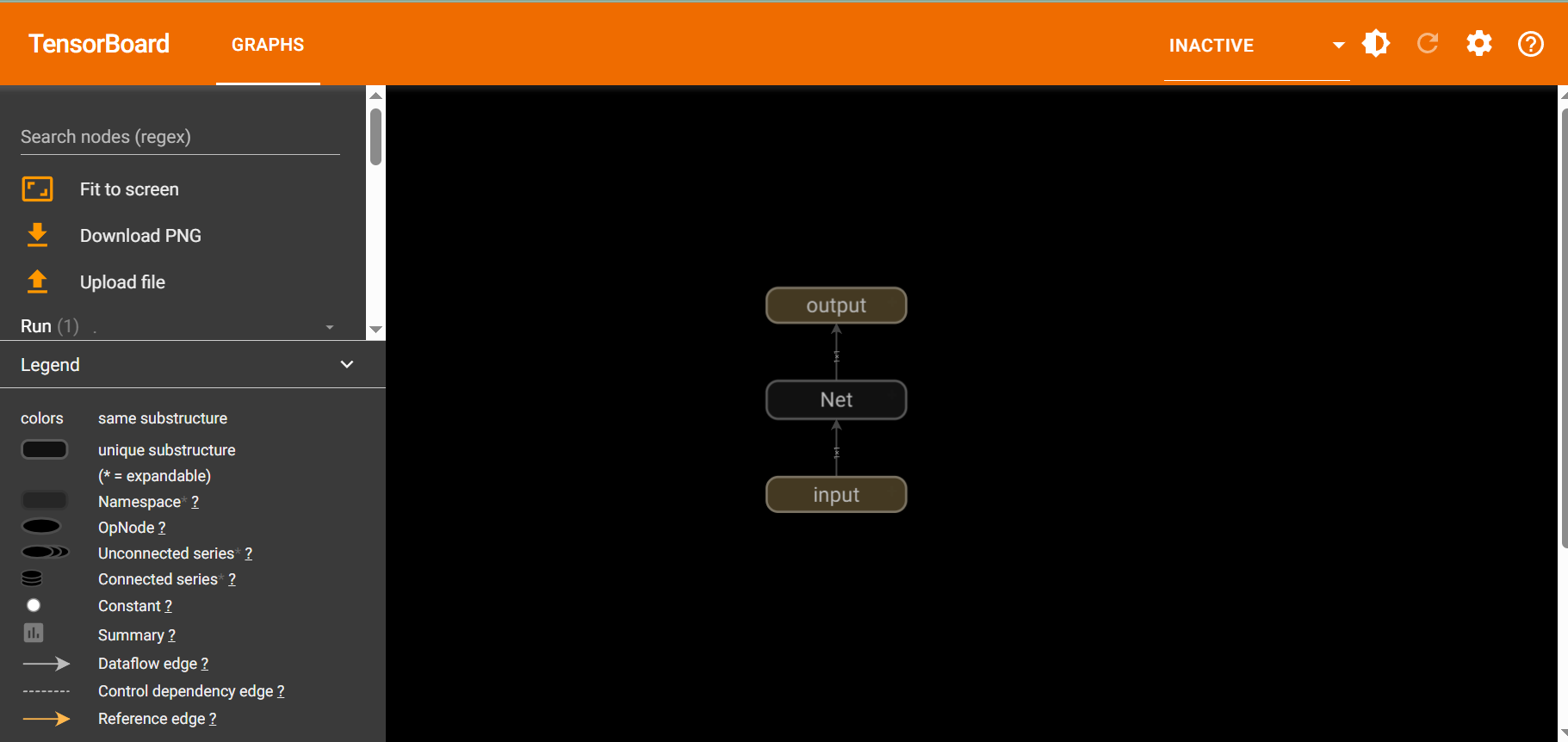
進入file文件夾
![]()
![]()
?tensorboard --logdir="./net_model"

試題速瀏、分類及淺析)








)




)



