一、TL;DR
- InternVideo2.5通過LRC建模來提升MLLM的性能。
- 層次化token壓縮和任務偏好優化(mask+時空 head)整合到一個框架中,并通過自適應層次化token壓縮來開發緊湊的時空表征
- MVBench/Perception Test/EgoSchema/MLVU數據benchmark上提升明顯
二、介紹
MLLM的問題點:
MLLM在基本視覺相關任務上的表現仍不如人類,這限制了其理解和推理能力。它們在識別、定位和回憶常見場景中的物體、場景和動作時表現不佳。
本文如何解決:
研究多模態上下文的長度和細粒度如何影響MLLM以視覺為中心的能力和性能,而不是專注于通過scaling law直接擴展MLLM。
取得了什么結果:
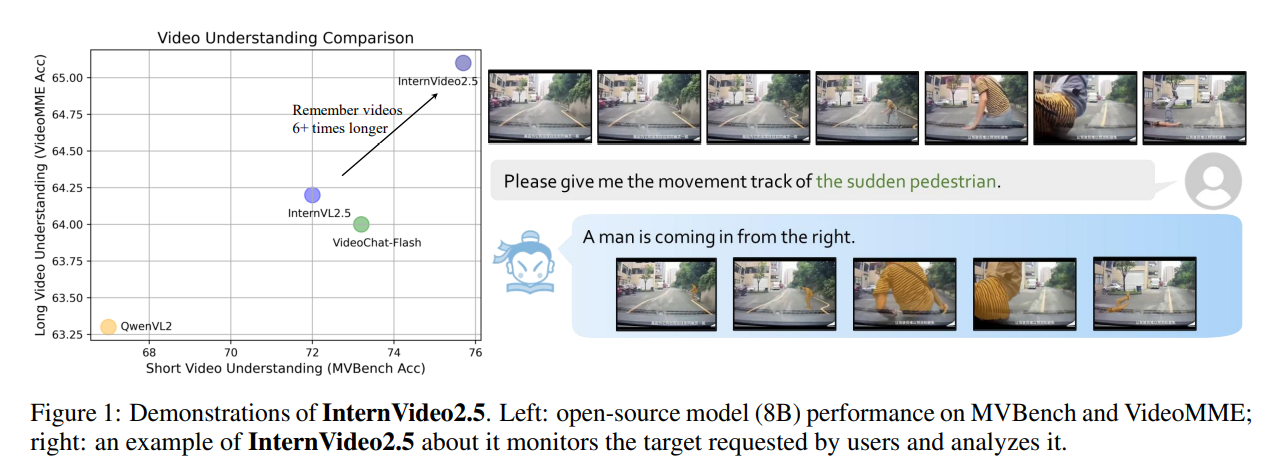
具體而言,本文的貢獻在于:
-
首次全面研究了如何實現長且豐富的上下文(Long and Rich Context,LRC),以提升MLLM的記憶和專注能力。
-
通過將層次化token壓縮(Hierarchical Token Compression,HiCo)和任務偏好優化(Task Preference Optimization,TPO)整合到一個框架中
-
-
InternVideo2.5能夠顯著提升現有MLLM在視頻理解方面的表現,并賦予它們專家級的視覺感知能力。
-
在多個短視頻和長視頻基準測試中取得了領先的性能。InternVideo2.5的視頻記憶容量使其能夠保留至少比原始版本長6倍的輸入。
-
三、方法
InternVideo2.5通過增強MLLM的上下文長度和細粒度來獲得長且準確的視頻理解,采用了視頻長度自適應的標記表示和任務偏好優化,如圖2所示。整個模型通過三個階段進行學習,利用了短視頻、長視頻以及經典視覺任務數據。整個方法詳細描述如下。
說人話:在前面的clip encoder時使用Tome做token壓縮,在淺層使用TDrop進行token prune做算力壓縮,深層使用注意力機制提取關鍵token,然后增加了一個mask Head和時間理解的head用于理解上下文和視覺細節(任務偏好優化),最后面接生成出結果

3.1 視頻長度自適應標記表示用于長多模態上下文
引入了一種實用的長度自適應token representation方法,能夠高效地處理任意長度的視頻序列。在動態幀采樣之后,給定的流程實現了具有兩個不同階段的層次化標記壓縮(HiCo):
- 視覺編碼過程中的時空感知壓縮
- 語言模型處理過程中的自適應多模態上下文整合。
自適應時間采樣:實現了一種根據視頻時長和內容特征進行調整的上下文感知采樣機制。
- 對于運動粒度至關重要的較短序列,我們采用密集時間采樣(每秒15幀)。
- 對于專注于事件級別理解的長序列(例如分鐘/小時級別的視頻),我們使用稀疏采樣(每秒1幀)。
- 這種自適應方法確保了在不同時間尺度上都能正確捕捉運動。
分層token壓縮:我們通過事件中的時空冗余和事件之間的語義冗余來壓縮長視覺信號。
-
時空token合并:通過層次化壓縮方案解決時空冗余問題,通過語義相似性進行令牌合并,保留視頻中的關鍵信息:
-
給定一個被劃分為T個時間片段的視頻序列,每個片段由視覺編碼器E處理以生成M個初始標記:vji?(i=1,2,...,M)用于第j個片段。這些標記通過標記連接器C進行自適應壓縮,產生N個壓縮后的標記sji?(i=1,2,...,N),其中N < M
-
![]()
????????通過語義相似性進行令牌合并,保留視頻中的關鍵信息。實驗表明,基于語義相似性的令牌合并方法(如ToMe)在視覺壓縮中表現出色,能夠在保留細節的同時顯著減少計算開銷。
-
多模態token丟棄:我們引入了在語言模型處理過程中運行的標記丟棄,以進一步優化長距離視覺理解。它實現了兩階段標記減少策略:
-
淺層中進行均勻token prune,以保持結構完整性,同時減少計算開銷;
-
深層中進行注意力引導的token選擇,以保留與任務的關鍵信息。
-
3.2 通過任務偏好優化增強多模態上下文中的視覺精度
為了增強多模態語言模型(MLLMs)在細粒度視覺任務中的表現,我們引入了多任務偏好學習(MPL)。該方法通過將專門的視覺感知模塊與基礎MLLM架構集成,實現了精確的定位和時間理解等能力。
-
時間理解:為了處理動態視覺內容,我們開發了一個時間組件,結合視頻特征提取和時間對齊能力。該組件能夠預測精確的時間邊界和相關分數,從而幫助模型更好地理解視頻中的時間關系。
-
實例分割:為了實現像素級理解和實例級區分,我們設計了一個分割模塊,基于最新的分割基礎模型(如SAM2)。該模塊通過自適應投影層將MLLM的嵌入與像素級預測連接起來,從而實現了對視頻中目標的精確分割。
模型通過聯合優化視覺感知模塊和基礎MLLM,實現了對細粒度視覺任務的精確處理。
3.3 多模態上下文建模的訓練視頻語料庫
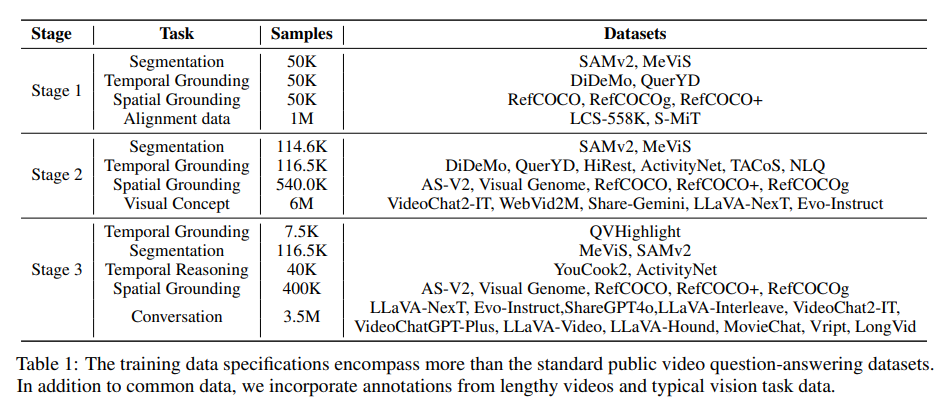
訓練過程分為三個階段,分別使用了視覺-文本對齊數據、長視頻數據和特定任務的視覺數據。訓練數據如表1所示。
-
視覺-文本數據用于跨模態對齊:我們收集了包含700萬圖像-文本對和370萬視頻-文本對的視覺-文本數據,以及14.3萬用于增強語言能力的文本數據。
-
長視頻語料庫用于上下文擴展:我們主要使用了來自MoiveChat、Cineplie、Vript和LongVid的長視頻指令數據。
-
特定任務的數據用于精確感知:包括用于指代分割任務的MeViS和SAMv2,用于空間定位的AS-V2、Visual Genome、RefCOCO等。
3.4 逐步多階段訓練
我們提出了一個統一的逐步訓練方案,共同增強MLLM的細粒度感知和時間理解能力。該方法包括三個主要階段,逐步增加任務的復雜性和視頻輸入的時間長度。
-
階段1:基礎學習:該階段專注于兩個并行目標:(a)使用多樣化的對話模板對LLM進行任務識別指令調整,使模型能夠識別和路由不同的視覺任務;(b)視頻-語言對齊訓練,其中我們凍結視覺編碼器和LLM,同時優化壓縮器和MLP以建立基本的視覺-語言連接。
-
階段2:細粒度感知訓練:該階段通過(a)使用特定任務的數據集集成和訓練特定任務的組件,包括任務標記、區域頭、時間頭和掩碼適配器;以及(b)使用350萬圖像和250萬短視頻-文本對進行視覺概念預訓練來增強模型的視覺理解能力。
-
階段3:集成準確和長形式上下文訓練:最后階段通過(a)在結合多模態對話和特定任務數據的混合語料庫上進行多任務訓練,允許任務監督梯度從專門頭流向MLLM;以及(b)在包含350萬樣本的綜合數據集上進行指令調整,包括110萬圖像、170萬短視頻(<60秒)和70萬長視頻(60-3600秒)。
這種逐步訓練策略使模型能夠在發展細粒度感知和長形式視頻理解的同時,減少對通用能力的潛在退化。與依賴長文本擴展上下文窗口的先前方法不同,我們直接在長視頻上進行訓練,以最小化訓練和部署場景之間的差距。
3.5 實現
-
分布式系統:基于XTuner開發了一個多模態序列并行系統,用于訓練和測試數百萬個多模態標記(主要是視覺)。通過整合序列和張量分布式處理以及多模態動態(軟)數據打包,我們實現了長視頻的可擴展計算。
-
模型配置:在我們的多模態架構中,我們使用了一個結合先進視頻處理和語言建模能力的綜合框架。該系統實現了動態視頻采樣,處理64-512幀,每個8幀剪輯壓縮為128個標記,產生大約每幀16個標記的表示
四、實驗結果
在MVBench和Perception Test上,InternVideo2.5分別提升了3.7分和6.7分。在長視頻理解方面,InternVideo2.5在EgoSchema和MLVU上的提升尤為明顯,分別提升了12.4分和3.9分
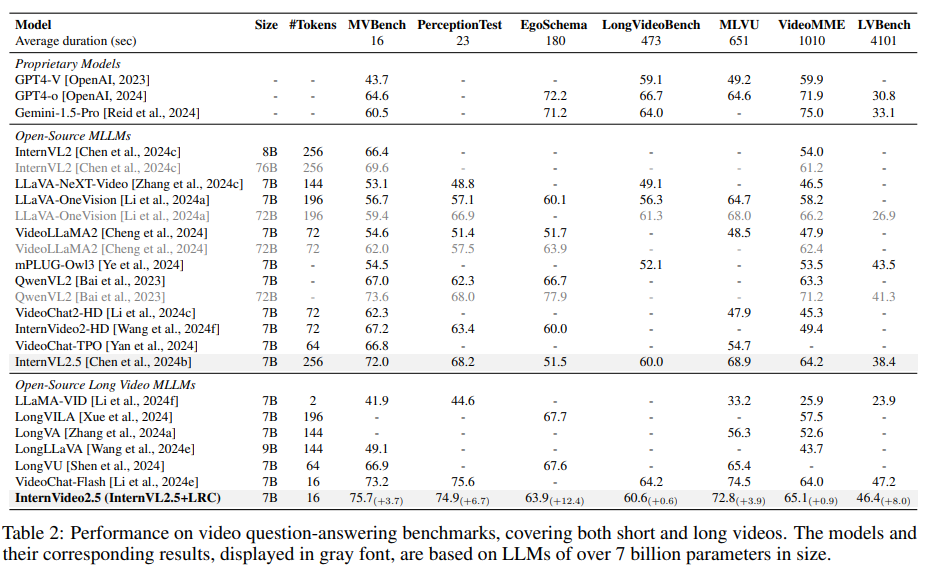
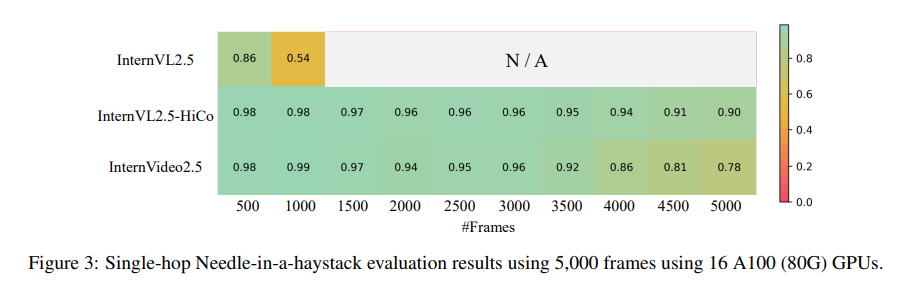
視頻理解效果好,尤其是細節:

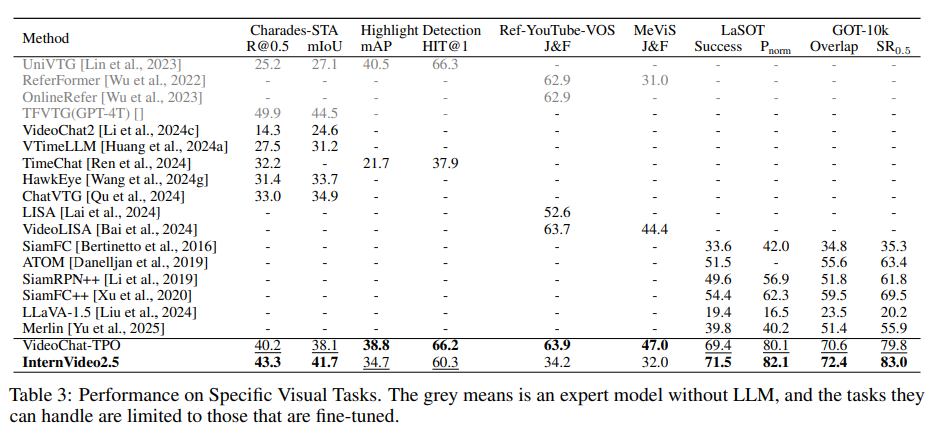
在特定任務上也表現出色:
條件運算符和條件表達式)




)

)



)







