Redis中的hash是什么
Hash: 哈希,也叫散列,是一種通過哈希函數將鍵映射到表中位置的數據結構,哈希函數是關鍵,它把鍵轉換成索引。
Redis Hash(散列表)是一種 field-value pairs(鍵值對)集合類型,類似于 Python 中的字典、Java 中的 HashMap。一個 field 對應一個value.
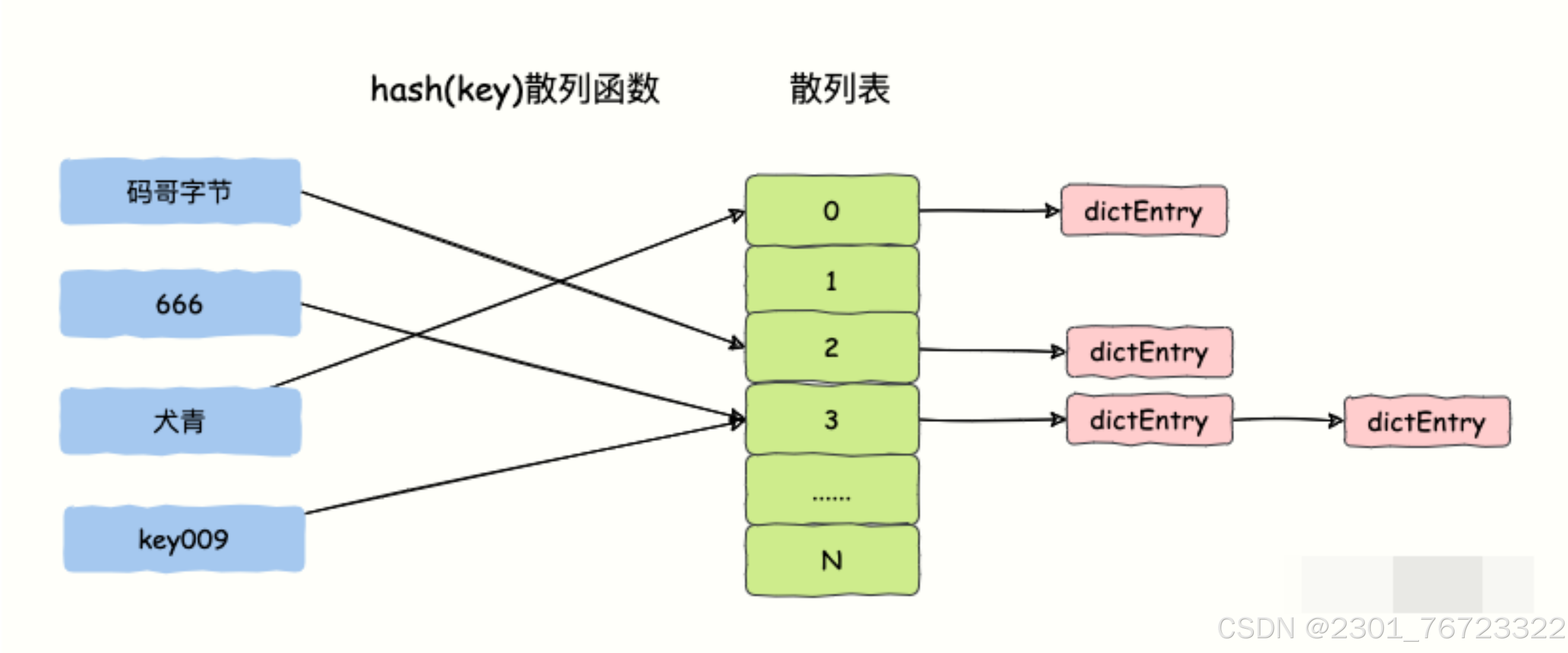
Hash沖突:兩個不同的key可能會映射到同一個位置去,這種問題我們叫做哈希沖突,或者哈希碰撞
Hash沖突解決方法:主要有兩種兩種方法,開放定址法和鏈地址法。
開放定址法 :
在開放定址法中所有的元素都放到哈希表里,當一個關鍵字key用哈希函數計算出的位置沖突了,則按照某種規則找到一個沒有存儲數據
的位置進行存儲。這里的規則有三種:線性探測、二次探測、雙重探測。
鏈地址法:
開放定址法中所有的元素都放到哈希表里,鏈地址法中所有的數據不再直接存儲在哈希表中,哈希表中存儲一個指針,沒有數據映射這個位置時,這個指針為空,有多個數據映射到這個位置時,我們把這些沖突的數據鏈接成一個鏈表,掛在哈希表這個位置下面,鏈地址法也叫做拉鏈法或者哈希桶。
Redis 的散列表 dict 由數組 + 鏈表構成,數組的每個元素占用的槽位叫做哈希桶,當出現散列沖突的時候就會在這個桶下掛一個鏈表,用“拉鏈法”解決散列沖突的問題。
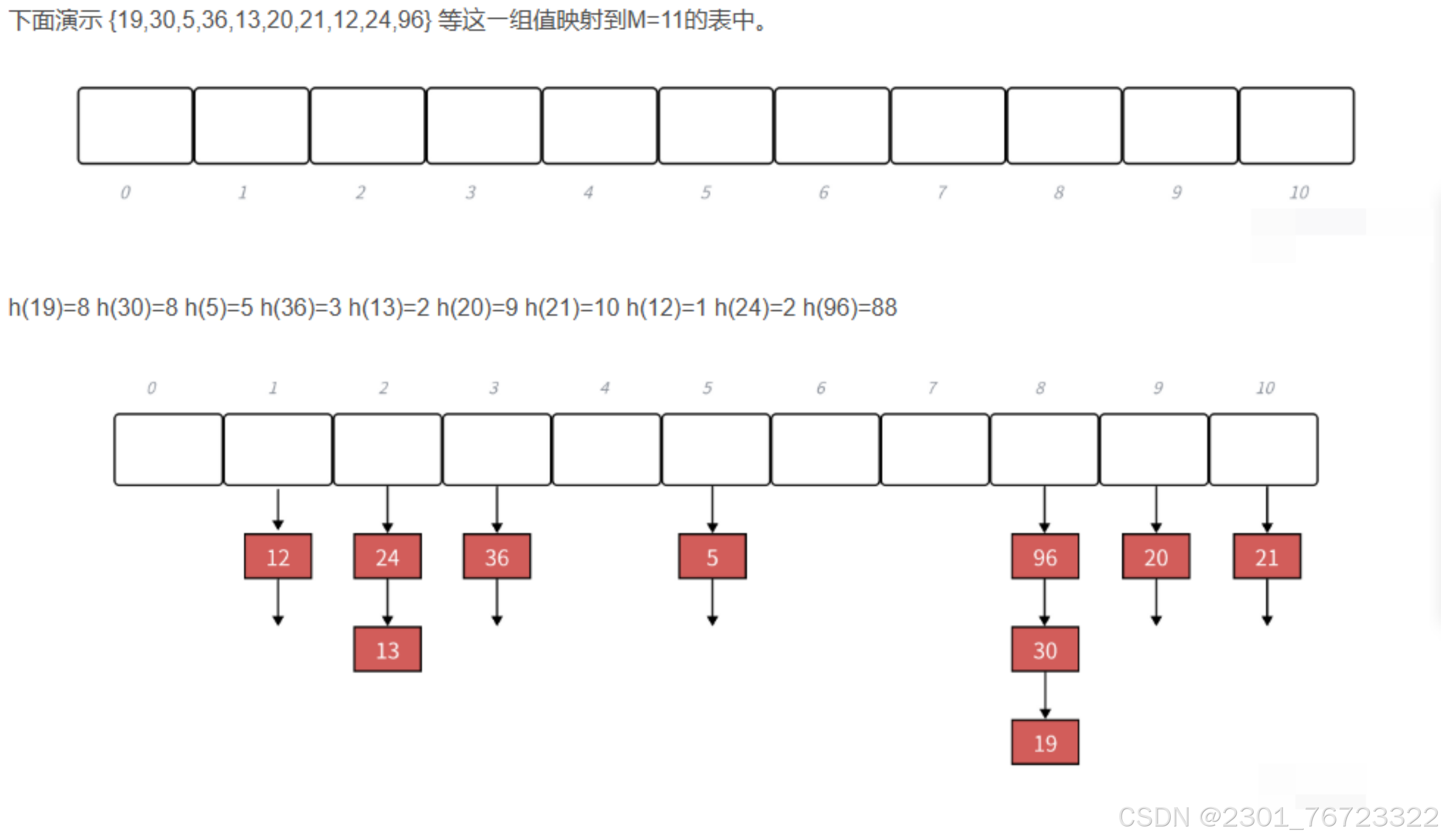
簡單地說就是將一個 key 經過散列計算均勻的映射到散列表上。
Hash數據類型底層存儲數據結構實際上有兩種。
1.dict結構。
2.在7.0版本之前使用ziplist,之后被listpack代替。
什么是listPack
Redis 在 5.0 新設計一個數據結構叫 listpack,目的是替代壓縮列表,它最大特點是 listpack 中每個節點不再包含前一個節點的長度了,壓縮列表每個節點正因為需要保存前一個節點的長度字段,就會有連鎖更新的隱患.
listpack 也叫緊湊列表,它的特點就是用一塊連續的內存空間來緊湊地保存數據,同時為了節省內存空間,listpack 列表項使用了多種編碼方式,來表示不同長度的數據,這些數據包括整數和字符串。
Redis源碼對于listpack的解釋為 A lists of strings serialization format,一個字符串列表的序列化格式,也就是將一個字符串列表進行序列化存儲。Redis listpack可用于存儲字符串或者是整型
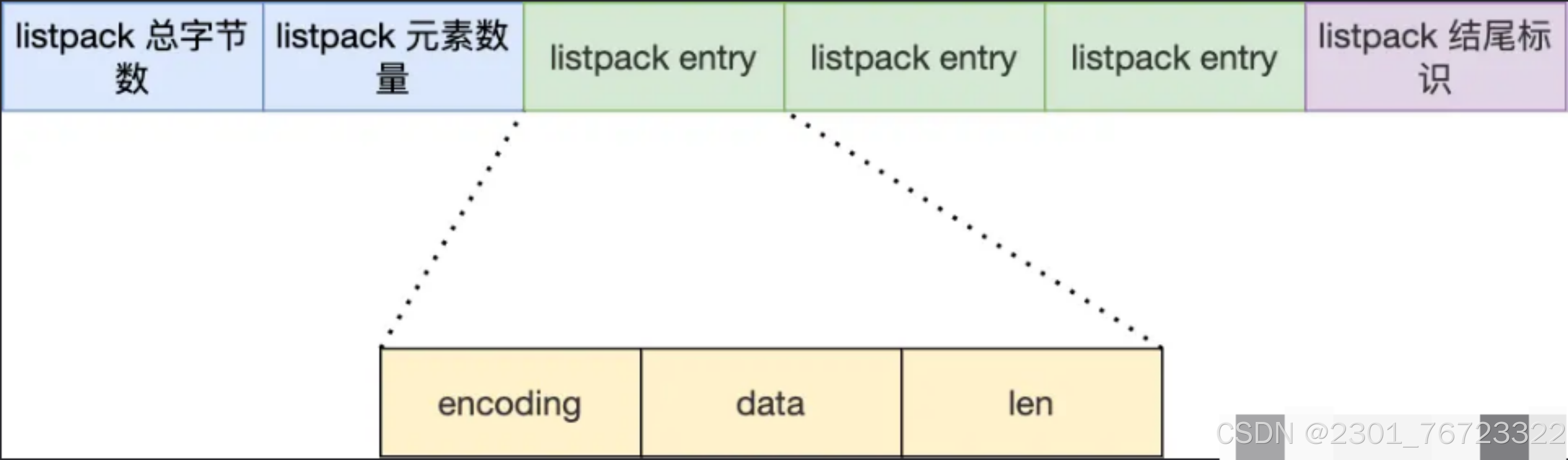
為了避免 ziplist 引起的連鎖更新問題,listpack 中的每個列表項不再像 ziplist 列表項那樣,保存其前一個列表項的長度,它只會包含三個方面內容,分別是當前元素的編碼類型(entry-encoding)、元素數據 (entry-data),以及編碼類型和元素數據這兩部分的長度 (entry-len),如下圖所示。

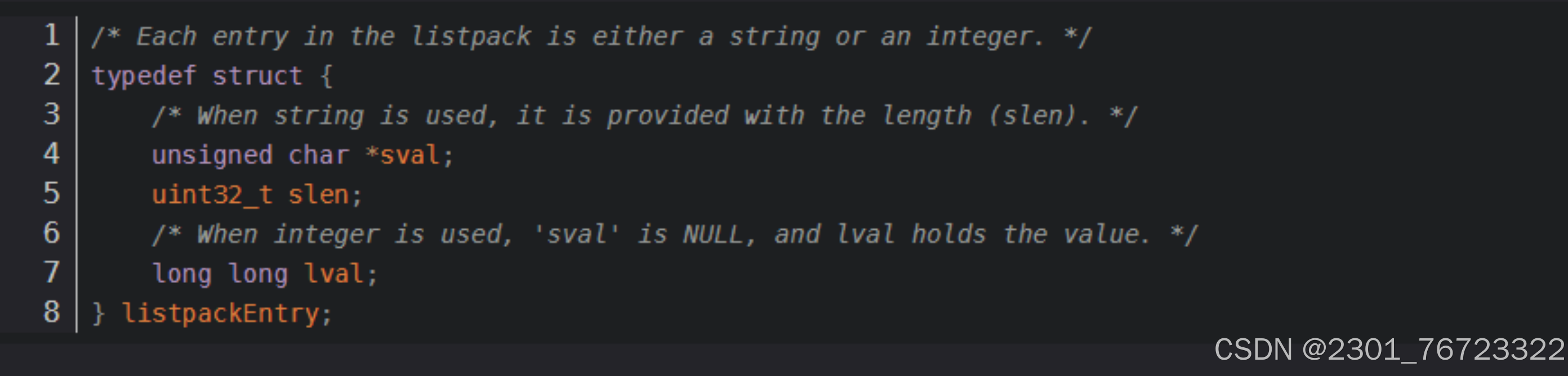
- slen,不同于ziplist,listpackEntry 中的 len 記錄的是當前 entry 的編碼類型和長度,而非上一個entry的長度。
- *sval,當存儲的數據為字符串時,使用該成員變量
- lval,當存儲的數據為整數,使用該成員變量
通常情況下使用dict數據結構存儲數據,每個field-va1 ue pairs構成一個dictEntry節點來保存。
只有同時滿足以下兩個條件的時候,才會使用listpack(7.O版本之前使用ziplist)數據結構來代替dict存儲,把key-value鍵值對按照
field在前value在后,緊密相連的方式放到一次把每個鍵值對放到列表的表尾。
- ·每個鍵值對中的field和value的字符串字節大小都小于hash-max-listpack-value配置的值(默認64)。
- ·field-value pairs鍵值對數量小于hash-max-listpack-entries配置的值(默認512)。
每次向散列表寫數據的時候,都會調用t_hash.c中的hashTypeConvertListpack()函數來判斷是否需要轉換底層數據結構。
當插入和修改的數據不滿足以上兩個條件時,就把散列表底層存儲結構轉換成dict結構。需要注意的是,不能由dict退化成listpack。
雖然使用了listpack就無法實現O(1)時間復雜度操作數據,但是使用listpack能大大減少內存占用,而且數據量比較,小,性能并不是有太大差異。
Redis數據庫就是一個全局散列表。正常情況下,我只會使用ht_table[0]散列表,圖2-20是一個沒有進行rehash狀態下的字典。
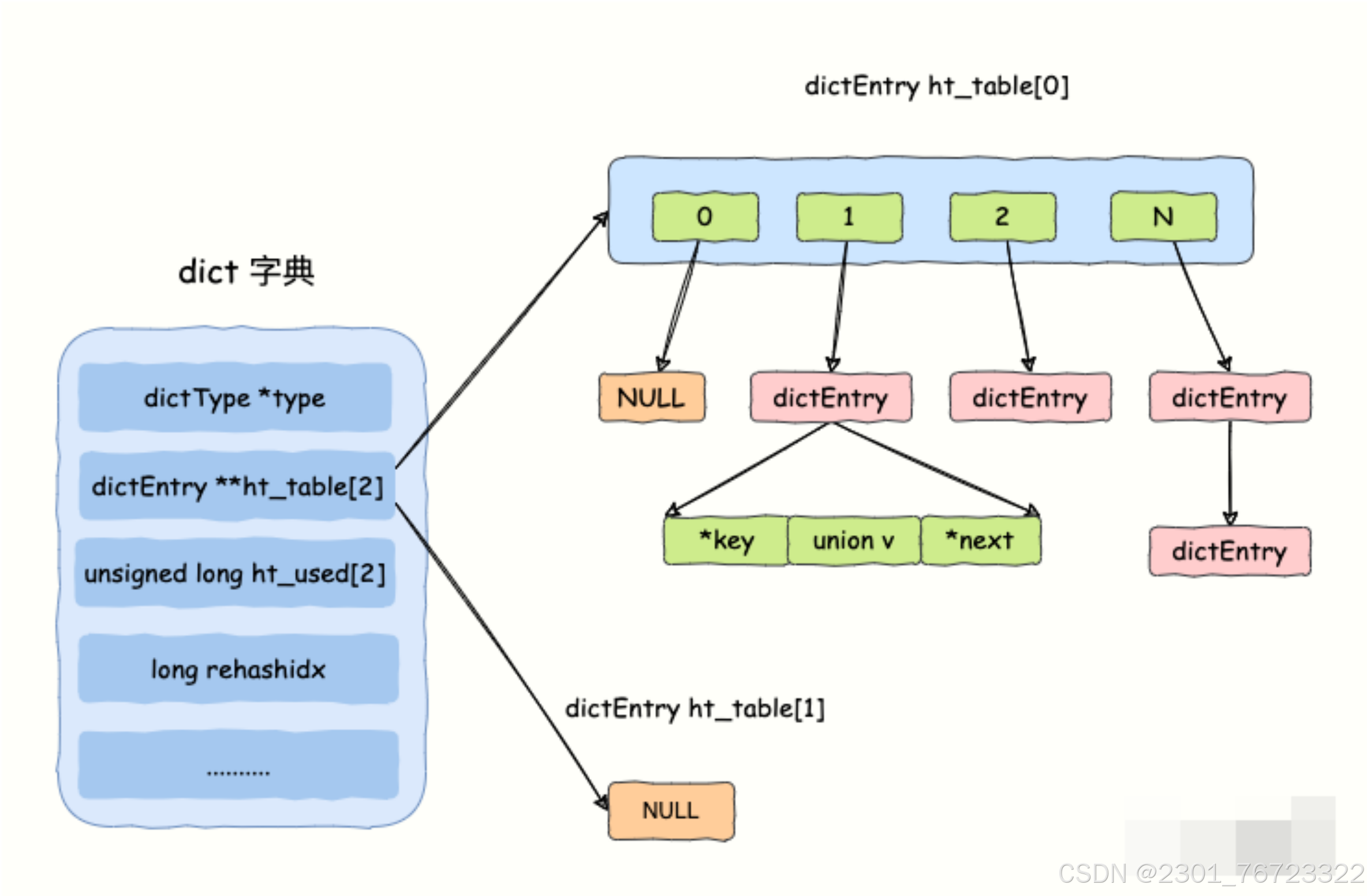
dict字典在源代碼dict.h中使用dict結構體表示。

1.dictType *type
- 這是一個指向 dictType 結構的指針,dictType 通常定義了哈希表的操作接口,包括哈希函數、鍵值的比較函數、釋放鍵值的函數等。這使得哈希表可以針對不同的數據類型進行定制化操作。
2.dictEntry **ht_table[2]
- 這是一個包含兩個指針的數組,每個指針指向一個哈希表(ht_table[0] 和 ht_table[1])。這種設計是為了支持漸進式重新哈希(Incremental Rehashing)。當哈希表的負載因子(即 ht_used[0] / ht_table[0] 的大小)超過某個閾值時,Redis 會開始將數據從 ht_table[0] 重新哈希到 ht_table[1]。這種漸進式重新哈希可以避免一次性重新哈希帶來的性能問題。
- dictEntry是哈希表中存儲鍵值對的結構,通常包含鍵、值和指向下一個哈希沖突的指針。
3.unsigned long ht_used[2]
- 這是一個包含兩個元素的數組,分別記錄 ht_table[0] 和 ht_table[1] 中存儲的鍵值對數量。ht_used[0] 表示 ht_table[0] 中的元素數量,ht_used[1] 表示 ht_table[1] 中的元素數量。
4.long rehashidx
- 這是一個索引值,用于記錄當前重新哈希操作的進度。當哈希表正在進行重新哈希時,rehashidx 表示當前正在處理的桶索引。如果 rehashidx 為 -1,表示沒有正在進行的重新哈希操作。
5.int16_t pauserehash
- 這是一個標志位,用于控制重新哈希操作是否暫停。在某些情況下,Redis 可能需要暫停重新哈希操作,以避免對性能的影響。例如,當 Redis 正在執行 RDB(Redis Database Backup)操作時,可能會暫停重新哈希。
6.signed char ht_size_exp[2]
- 這是一個包含兩個元素的數組,分別記錄 ht_table[0] 和 ht_table[1] 的大小指數。Redis 的哈希表大小通常是 2 的冪次方,ht_size_exp[0] 和 ht_size_exp[1] 分別表示 ht_table[0] 和 ht_table[1] 的大小指數。例如,如果 ht_size_exp[0] 為 4,則 ht_table[0] 的大小為 24=16。

·*key指針指向鍵值對中的鍵,實際上指向一個SDS實例。
雖然Redis是用c實現的,但是他們的string結構并不相同,Redis中的字符串是可以修改的字符串,在內存中它是以字節數組的形式存在的Redis 的。字符串叫sds,也就是 Simple Dynamic String,是一個帶長度信息的字節數組

·v是一個uon聯合體,表示鍵值對中的值,同一時刻只有一個字段有值,用聯合體的目是節省內存。
- ·val 如果值是非數字類型,那就使用這個指針存儲。
- ·uint64tu64, 值是無符號整數的時候使用這個字段存儲。
- ·int64ts64, 值是有符號整數時,使用該字段存儲。
- ·dob1ed, 值是浮點數是,使用該字段存儲。
*next指向下一個節點指針,當散列表數據增加,可能會出現不同的key得到的哈希值相等,也就是說多個key對應在一個哈希桶里面,這就是哈希沖突。Redis使用拉鏈法,也就是用鏈表將數據串起來。
為什么說v是一個uo聯合體,表示鍵值對中的值,同一時刻只有一個字段有值,用聯合體的目是節省內存?
1.節省內存
- union 聯合體是一種特殊的數據結構,它允許在同一個內存位置存儲不同的數據類型。所有成員共享同一塊內存,因此在任何時刻,union 中只有一個成員有值。寫入一個成員會覆蓋其他成員的內容.
- 在 dictEntry 中,v 的大小由其最大的成員決定。例如,void *val、uint64_t u64、int64_t s64 和 double d 的大小都是 8 字節(在 64 位系統中)。因此,v 的大小也是 8 字節,無論存儲哪種類型的數據,都不會占用額外的內存。
2.靈活存儲不同類型的數據
- Redis 的哈希表需要存儲多種類型的數據,包括指針、整數和浮點數。通過使用 union,v 可以靈活地存儲這些不同類型的數據,而不需要為每種類型分配單獨的內存空間。
- 這種設計使得 dictEntry 能夠高效地處理不同類型的數據,同時保持內存占用的最小化。
為啥ht_table[2]存放了兩個指向散列表的指針?用一個散列表不就夠了嗎?
默認使用ht_tab:1e[0]進行讀寫數據,當散列表的數據越來越多的時候,哈希沖突嚴重會出現哈希桶的鏈表比較長,導致查詢性能下降。
為了唯快不破想了一個法子,當散列表保存的鍵值對太多或者太少的時候,需要通過「rehash(重新散列)對散列表進行擴容或者縮容。
擴容和縮容
1.為了高性能,減少哈希沖突,會創建一個大小等于ht_used[0]*2的散列表ht_tab1e[1],也就是每次擴容時根據散列表ht_tab1e[0]已使用空間擴大一倍創建一個新散列表ht_tab1e[1]。反之,如果是縮容操作,就根據ht_tab1e[0]已使用空間縮小一倍創建一個新的散列表。
2.重新計算鍵值對的哈希值,得到這個鍵值對在新散列表ht_tab1e[1]的桶位置,將鍵值對遷移到新的散列表上。
3.所有鍵值對遷移完成后,修改指針,釋放空間。具體是把ht_tab1e[0]指針指向擴容后的散列表,回收原來小的散列表內存空間,ht_tab1e[1]指針指向NULL,為下次擴容或者縮容做準備。
什么時候會觸發擴容?
1.當前沒有執行BGSAVE或者BGREWRITEAOF命令,同時負載因子大于等于1。也就是當前沒有RDB子進程和AOF重寫子進程在工作,畢競這倆操作還是比較容易對性能造成影響的,就不擴容火上澆油了。
2.正在執行BGSAVE或者BGREWRITEA0F命令,負載因子大于等于5。(這時候哈希沖突太嚴重了,再不觸發擴容,查詢效率太慢了)。負載因子=散列表存儲dictEntry節點數量/散列表桶個數。完美情況下,每個哈希桶存儲一個dictEntry節點,這時候負載因子=1。
BGSAVE 和 BGREWRITEAOF 是 Redis 中的兩個重要命令,它們分別用于實現 Redis 的兩種持久化機制:RDB(Redis Database Backup) 和 AOF(Append Only File)。這兩種機制用于將內存中的數據持久化到磁盤,以防止數據丟失。
BGREWRITEAOF 命令觸發一個后臺進程(子進程)來重寫 AOF 文件,以壓縮和優化 AOF 文件的大小,同時避免阻塞主進程。
需要遷移數據量很大,rehash操作豈不是會長時間阻塞主線程?
為了防止阻塞主線程造成性能問題,我并不是一次性把全部的key遷移,而是分多次,將遷移操作分散到每次情求中,避免集中式rehash造成長時間阻塞,這個方式叫漸進式rehash。
在執行漸進式rehash期間,dict會同時使用ht_table[0]和ht_table[1]兩個散列表,rehash具體步如下:
1.將rehashidxi設置成0,表示rehash開始執行。
2.在rehash期間,服務端每次處理客戶端對dict散列表執行添加、查找、刪除或者更新操作時,除了執行指定操作以外,還會檢查當前dict是否處于rehash狀態,是的話就把散列表ht_table[0]上索引位置為rehashidx的桶的鏈表的所有鍵值對rehash到散列表ht_table[1]上,這個哈希桶的數據遷移完成,就把rehashidx的值加1,表示下一次要遷移的桶所在位置。
3.當所有的鍵值對遷移完成后,將rehashidxi設置成-1,表示rehash操作已完成。
rehash過程中,字典的刪除、查找、更新和添加操作,要從兩個ht_table都搞一遍嗎?
刪除、修改和查找可能會在兩個散列表進行,第一個散列表沒找到就到第二個散列表進行查找。但是增加操作只會在新的散列表上進行。
如果請求比較少,豈不是會很長時間都要使用兩個散列表?
在Redis Server園初始化時,會注冊一個時間事件,定時執行serverCron函數,其中包含rehash操作用于輔助遷移,避免這個問題。
serverCron函數除了做rehash以外,主要處理如下工作。
- 過期key刪除。
- 監控服務運行狀態。
- 更新統計數據。
- 漸進式rehash。
- 觸發BGSAVE/AOF rewrite以及停止子進程。
- 處理客戶端超時。
- …
擴容過程:
在 Redis 的哈希表(Hash)rehash 過程中,數據遷移是分步驟、漸進式進行的,這樣做是為了避免一次性遷移大量數據造成的服務器阻塞。以下是 rehash 過程中數據遷移的具體步驟:
1. 創建新的哈希表
當觸發 rehash 條件時(例如,負載因子超過設定閾值),Redis 會創建一個新的哈希表 ht[1],其大小通常是 ht[0](當前哈希表)大小的兩倍。
2. 初始化 rehash 索引
在 dict 結構中,rehashidx 被初始化為 0。這個索引用于跟蹤 rehash 過程中已經遷移的桶的數量。
3. 漸進式遷移
Redis 使用一個定時任務或者在處理命令時的空閑時間來執行 rehash 操作。在每次 rehash 操作中,會遷移一定數量的桶(通常是一個或幾個),而不是一次性遷移所有桶。具體步驟如下:
- 從 ht[0] 中取出一個桶(通過 rehashidx 定位)。
- 遍歷桶中的所有 dictEntry(如果有鏈表,則遍歷鏈表中的所有條目)。
- 重新計算每個 dictEntry 的哈希值,并將其插入到 ht[1] 中對應的桶中。
- 更新 rehashidx,指向下一個需要遷移的桶。
4. 更新 rehash 狀態
每次遷移一定數量的桶后,Redis 會更新 rehashidx,使其指向下一個桶。這樣,下一次 rehash 操作可以從上次停止的地方繼續。
5. 完成 rehash
當 rehashidx 超過 ht[0] 的大小時,表示所有桶都已遷移到 ht[1]。此時,Redis 會進行以下操作:
- 將 ht[1] 設置為新的 ht[0],即讓新的哈希表成為當前使用的哈希表。
- 釋放舊的 ht[0] 占用的內存。
- 將 rehashidx 重置為 -1,表示 rehash 操作已完成。
6. 處理命令時的 rehash
在 rehash 過程中,Redis 仍然可以處理客戶端的命令。當命令涉及到哈希表操作時,Redis 會同時在 ht[0] 和 ht[1] 中查找或插入數據,確保數據的一致性。
通過這種漸進式的 rehash 機制,Redis 能夠在不影響服務器性能的情況下,平滑地完成哈希表的擴容操作。
BGSAVE和BGREWRITEAOF是什么意思?
BGSAVE 和 BGREWRITEAOF 是 Redis 中的兩個重要命令,它們分別用于實現 Redis 的兩種持久化機制:RDB(Redis Database Backup) 和 AOF(Append Only File)。這兩種機制用于將內存中的數據持久化到磁盤,以防止數據丟失。
1. BGSAVE(RDB 持久化)
RDB 持久化
-
定義:RDB 是一種快照持久化機制,它會定期將內存中的數據集快照保存到磁盤上的一個 RDB 文件中。
-
優點:
- 數據恢復速度快:RDB 文件是一個緊湊的二進制文件,恢復數據時速度較快。
- 適合全量備份:適合用于全量數據備份,可以方便地將數據備份到其他存儲介質或遠程服務器。
-
缺點:
-
數據丟失風險:如果 Redis 服務器在兩次快照之間發生故障,可能會丟失最后一次快照之后的數據。
-
阻塞風險:生成 RDB 文件的過程可能會阻塞主進程,尤其是在數據量較大時。
BGSAVE 命令
-
作用:觸發一個后臺進程(子進程)來生成 RDB 文件,而主進程繼續處理客戶端請求,避免阻塞。
-
執行過程:
a.主進程創建一個子進程。
b.子進程將當前內存中的數據集快照寫入到一個新的 RDB 文件中。
c.子進程完成寫入后,用新生成的 RDB 文件替換舊的 RDB 文件。 -
觸發方式:
- 手動觸發:可以通過命令 BGSAVE 手動觸發。
- 自動觸發:Redis 會根據配置的策略自動觸發 BGSAVE。例如,可以配置 Redis 每隔一定時間或在數據變更達到一定數量時自動執行 BGSAVE。
2. BGREWRITEAOF(AOF 持久化)
AOF 持久化
- 定義:AOF 是一種日志持久化機制,它會將每個寫操作命令追加到一個日志文件(AOF 文件)中。
- 優點:
- 數據安全性高:AOF 文件記錄了每個寫操作,即使 Redis 服務器發生故障,也可以通過重放 AOF 文件中的命令恢復數據。
- 可配置性強:可以配置不同的同步策略(如每秒同步一次、每次寫操作同步一次等),以平衡性能和數據安全性。
- 缺點:
- 文件體積大:AOF 文件會不斷增長,可能會占用大量磁盤空間。
- 恢復速度慢:AOF 文件是文本格式,恢復數據時速度相對較慢。
BGREWRITEAOF 命令
-
作用:觸發一個后臺進程(子進程)來重寫 AOF 文件,以壓縮和優化 AOF 文件的大小,同時避免阻塞主進程。
-
執行過程:
a.主進程創建一個子進程。
b.子進程讀取當前內存中的數據集,并將其轉換為一系列優化后的寫操作命令,寫入到一個新的 AOF 文件中。
c.子進程完成寫入后,用新生成的 AOF 文件替換舊的 AOF 文件。 -
觸發方式:
- 手動觸發:可以通過命令 BGREWRITEAOF 手動觸發。
- 自動觸發:Redis 會根據配置的策略自動觸發 BGREWRITEAOF。例如,可以配置 Redis 在 AOF 文件大小達到一定比例時自動執行 BGREWRITEAOF。
總結
- BGSAVE:用于生成 RDB 文件,適合全量數據備份,恢復速度快,但可能會丟失最后一次快照之后的數據。
- BGREWRITEAOF:用于重寫 AOF 文件,優化 AOF 文件的大小,數據安全性高,但文件體積大,恢復速度相對較慢。
這兩種持久化機制可以單獨使用,也可以結合使用,具體選擇取決于應用場景和對數據安全性的要求。
)








解決方案驗證實驗室搬遷升級,賦能客戶技術服務)

![MySQL基礎 [六] - 內置函數+復合查詢+表的內連和外連](http://pic.xiahunao.cn/MySQL基礎 [六] - 內置函數+復合查詢+表的內連和外連)
?)
![[ctfshow web入門] web10](http://pic.xiahunao.cn/[ctfshow web入門] web10)

)



`函數)