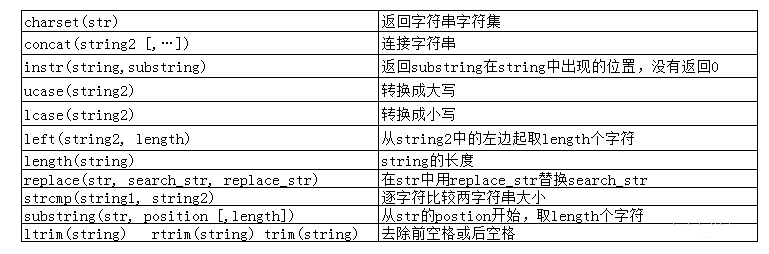
內置函數一般要用select調用
內置函數
日期函數
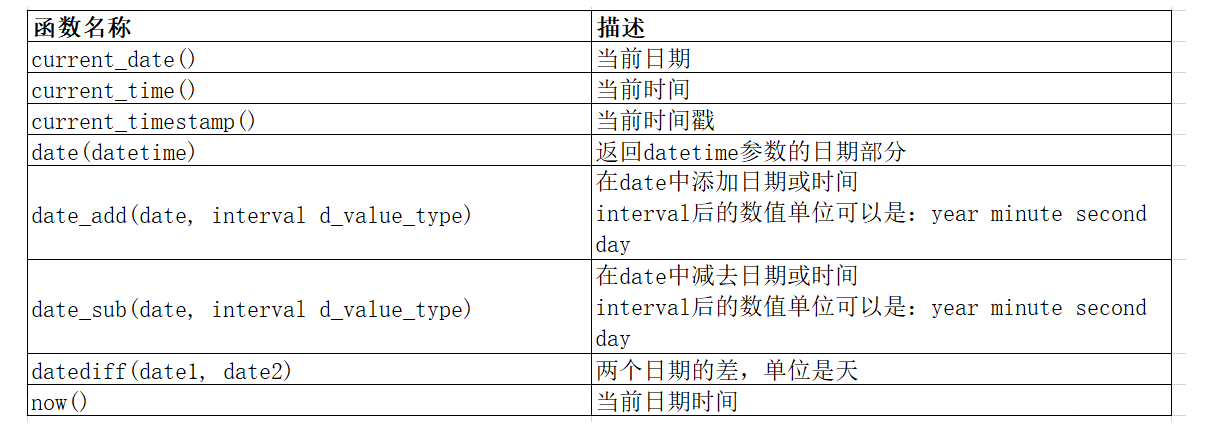
current_date函數
current_date函數用于獲取當前的日期。如下:?

current_time函數
current_time函數用于獲取當前的時間。如下:

now函數
now函數用于獲取當前的日期時間。如下:

?date函數
date函數用于獲取當前的日期時間。如下:

date_add函數?
date_add函數用于在日期的基礎上添加日期或時間。如下:

如果在date_add函數中添加的日期/時間為負值,則相當于在日期的基礎上減去日期/時間。如下:
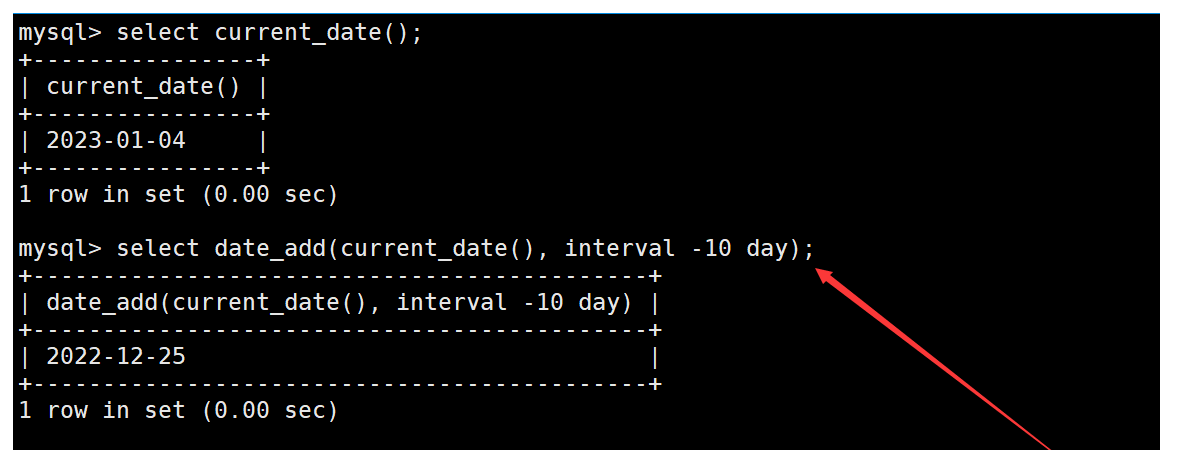
date_sub函數
date_sub函數用于在日期的基礎上減去日期或時間。如下:
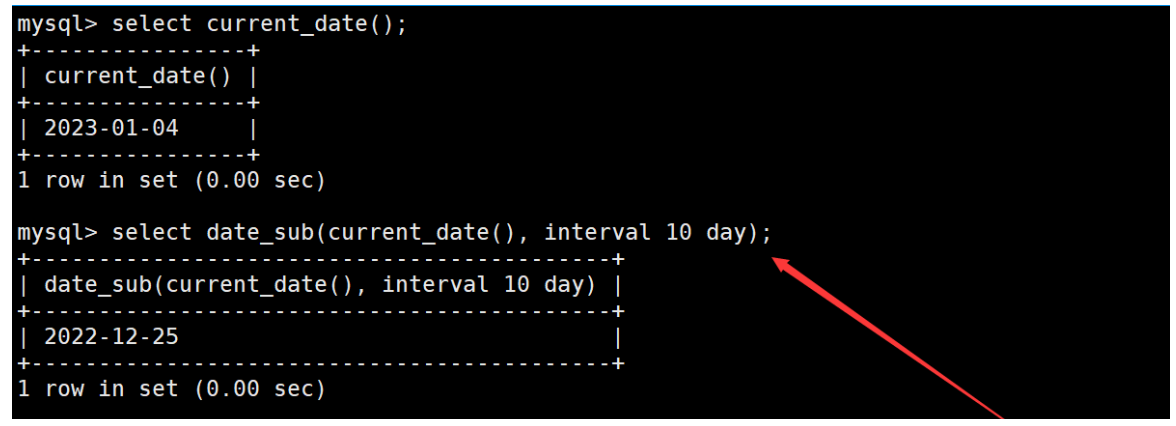
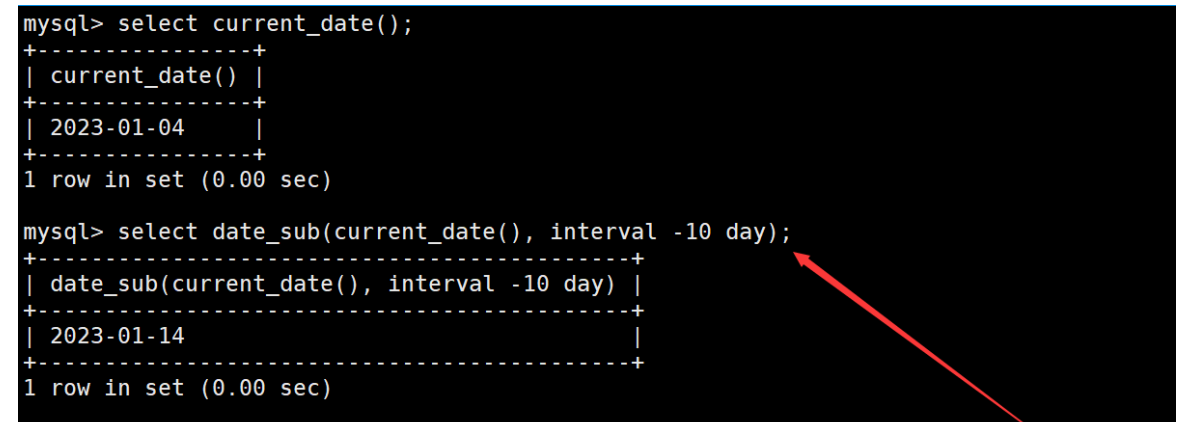
如果在date_sub函數中減去的日期/時間為負值,則相當于在日期的基礎上添加日期/時間。如下:
datediff函數
datediff函數用于獲取兩個日期的差,單位是天。如下:

綜合案例?
創建一個評論表,表中包含自增長的主鍵id、昵稱、評論內容和評論時間。如下:
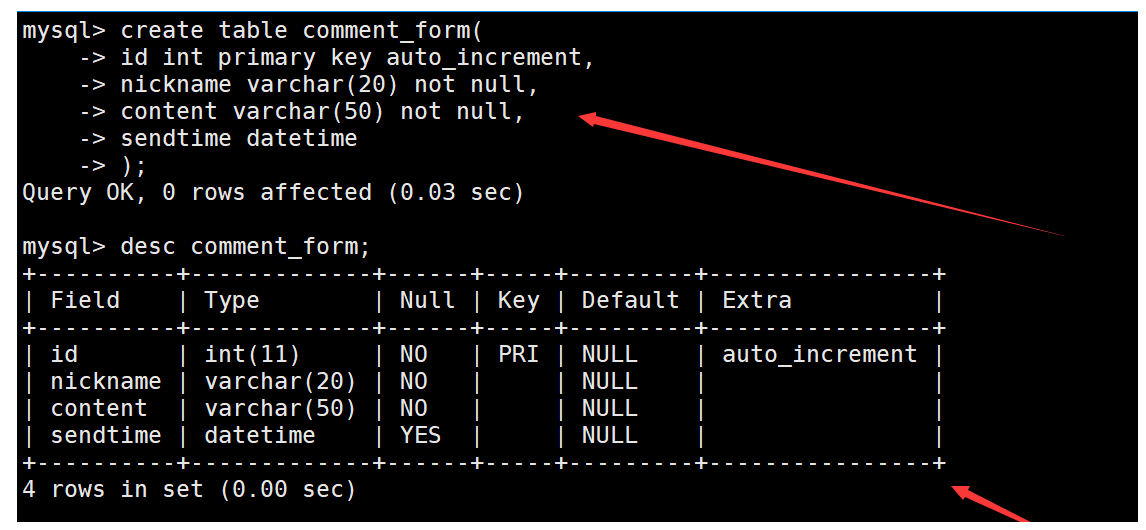
向表中插入一些數據,插入時直接通過now函數指明評論時間。如下:
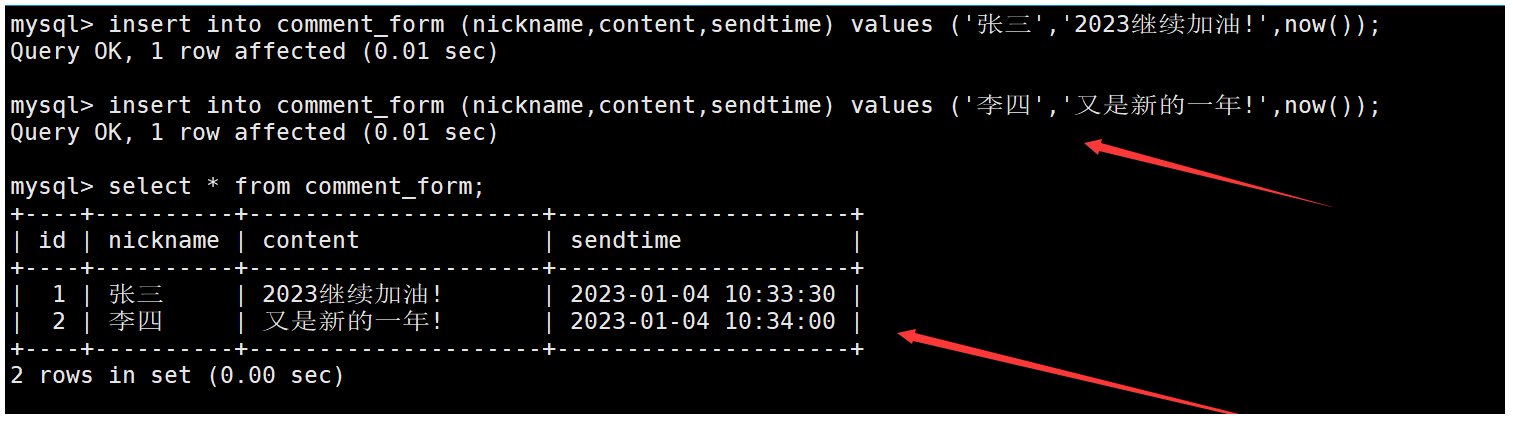
在顯示評論信息時,如果只想顯示評論的日期而不顯示評論的時間,可以在查詢sendtime字段時,通過date函數截取sendtime的日期部分進行顯示。如下:
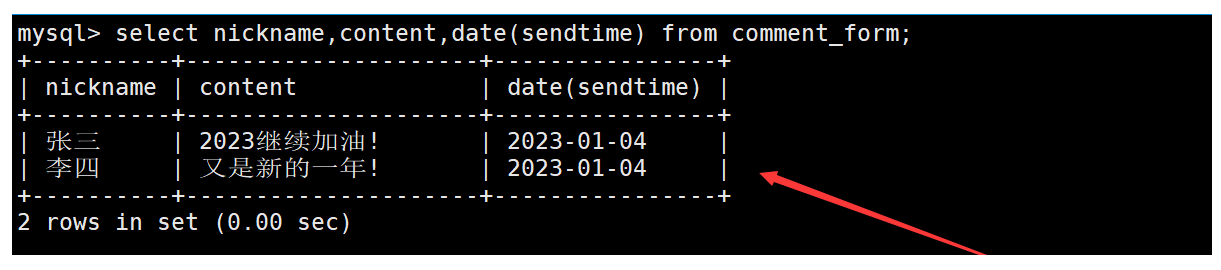
再不定時向表中插入一些數據。如下:
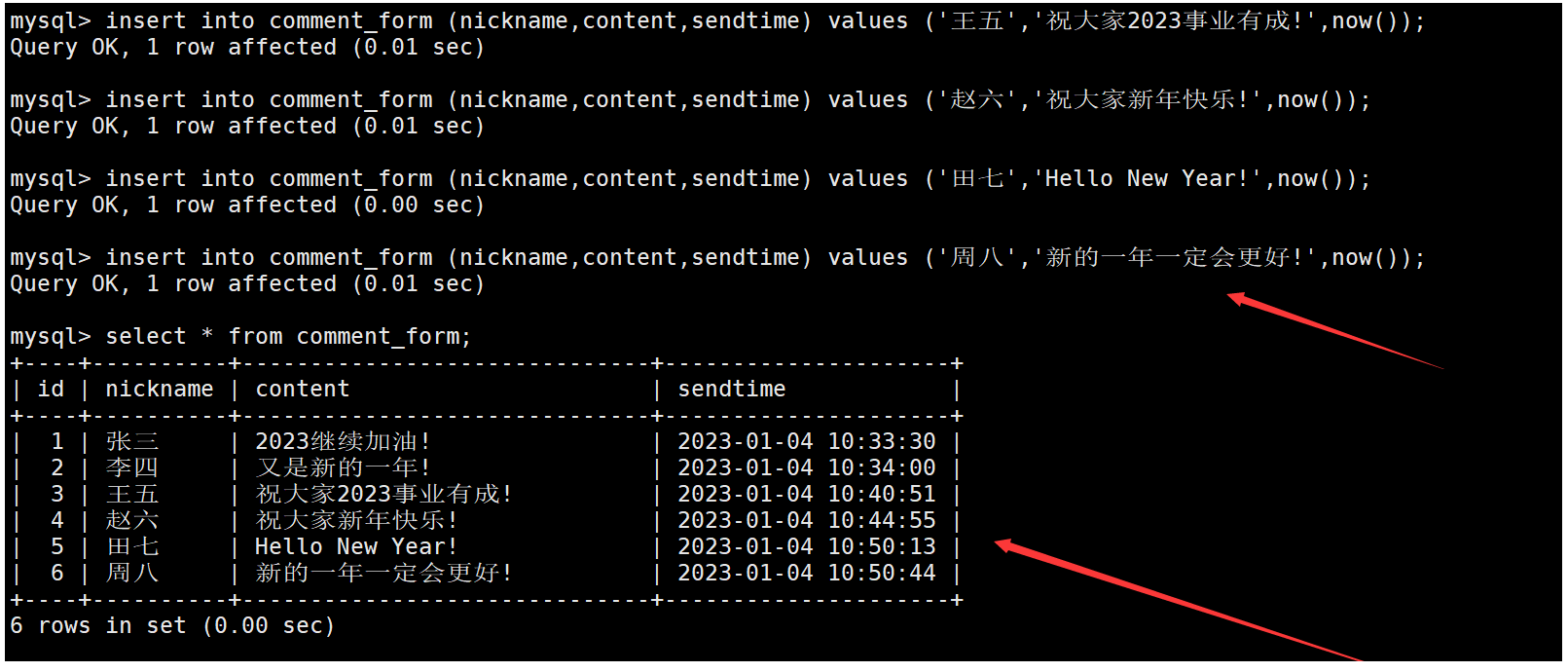
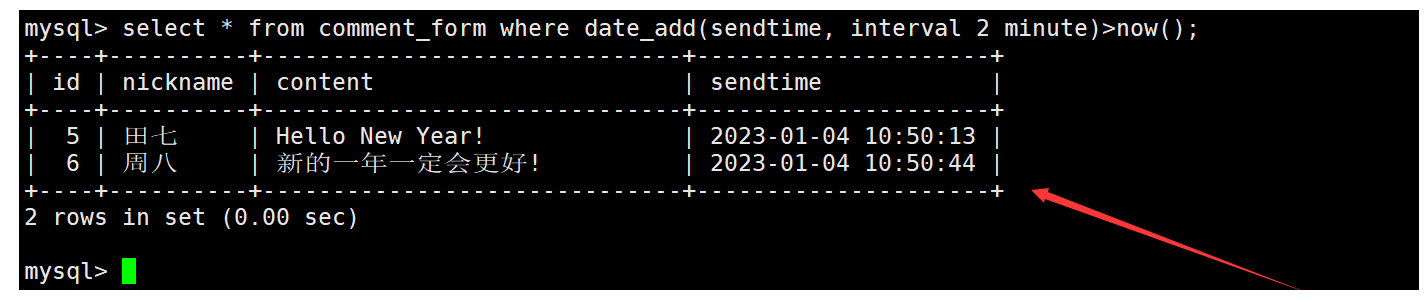
在顯示評論信息時,如果要查詢2分鐘內發布的評論信息,實際就是要篩選出評論時間加上2分鐘后大于當前時間的評論,這時需要同時借助date_add和now函數。如下:
字符串函數
charset函數
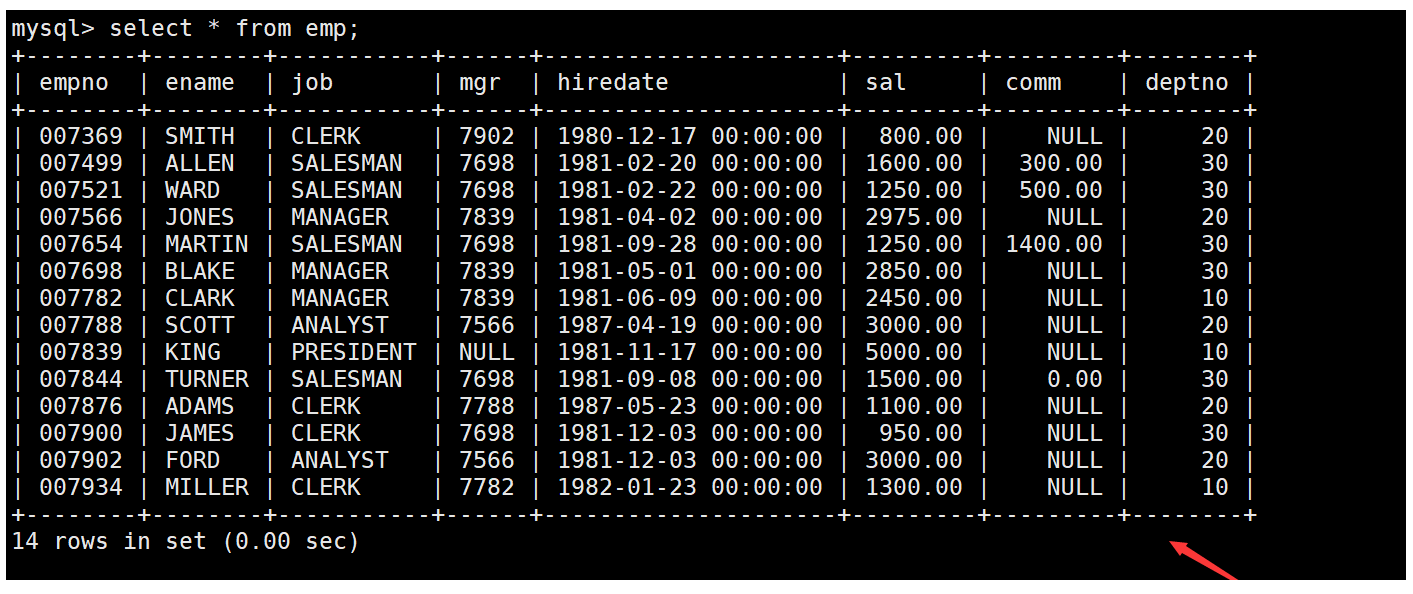
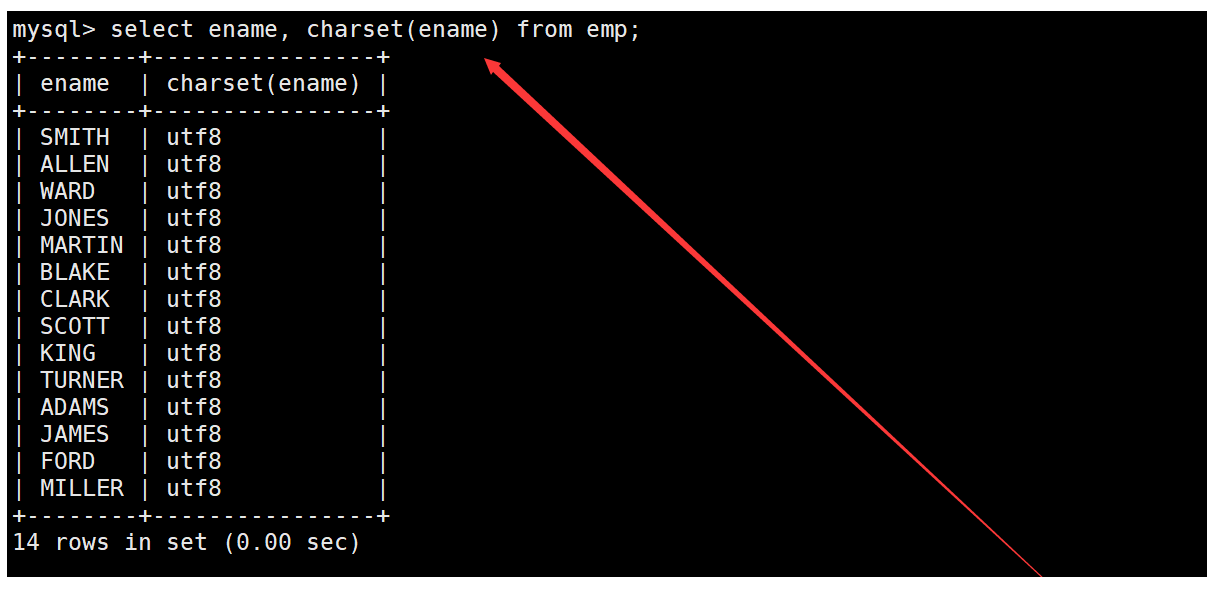
現有如下員工表,要求獲取員工表中ename列使用的字符集。如下:
在查詢員工表中的信息時,使用charset函數獲取ename列使用的字符集即可。如下:
?concat函數
現有如下成績表,要求以“XXX的語文是XX分,數學是XX分,英語是XX分”的格式顯示成績表中的信息。如下:
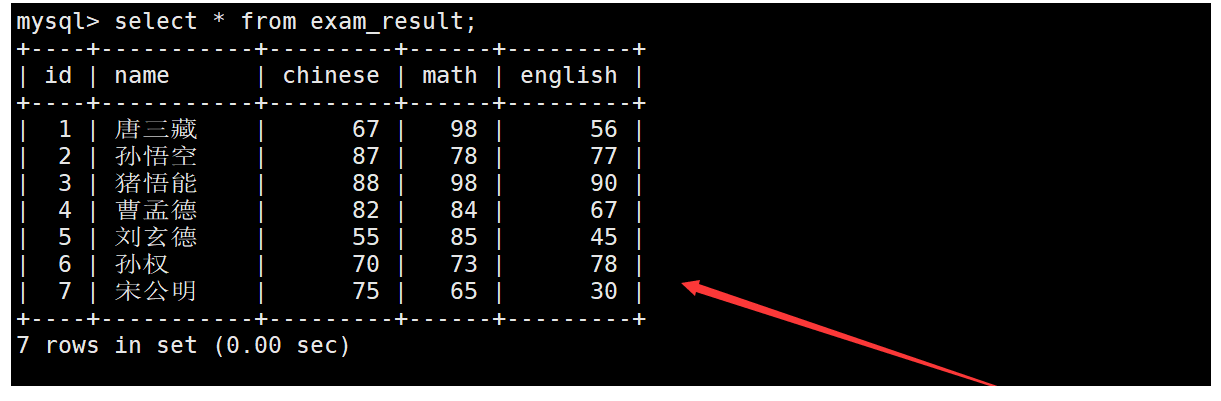
在查詢成績表中的信息時,使用concat函數按要求進行字符串連接即可。如下:

instr函數
?instr函數用于獲取一個字符串在另一個字符串中首次出現的位置,如果沒有出現則返回0。如下:

ucase函數
ucase函數用于獲取轉換成大寫后的字符串。如下:

lcase函數
lcase函數用于獲取轉換成小寫后的字符串。如下:

left函數
left函數用于從字符串的左邊開始,向后截取指定個數的字符。如下:

length函數
length函數用于獲取字符串占用的字節數。如下:
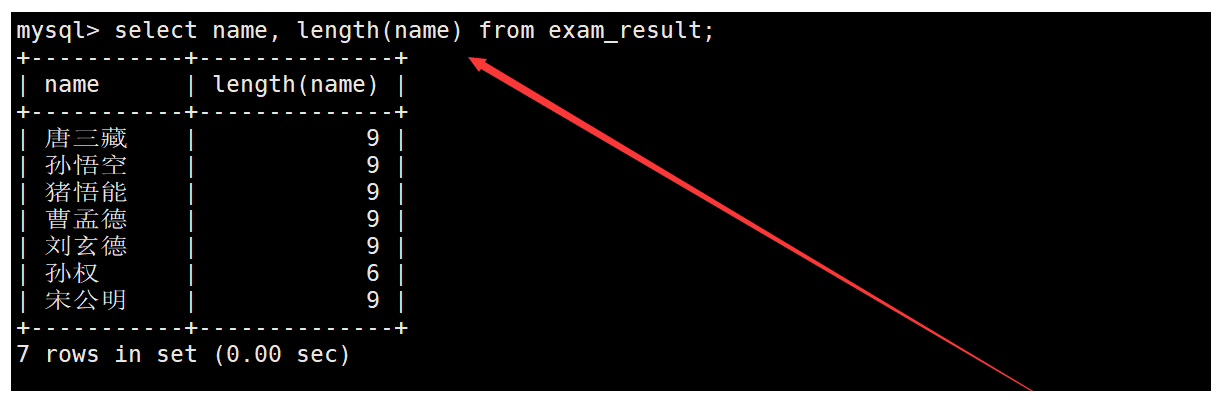
說明一下:?對于多字節字符來說,不同編碼中一個字符所占的字節個數是不同的,比如utf8中一個字符占用3個字節,而gbk中一個字符占用2個字節。
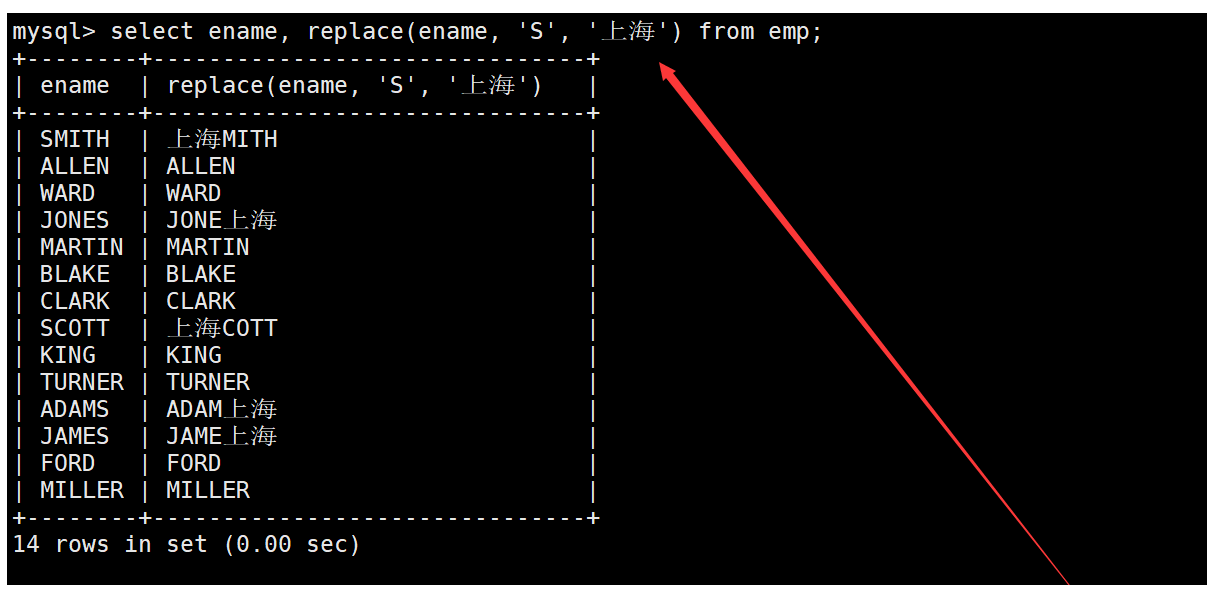
replace函數
replace函數用于將字符串中的指定子字符串替換成另一個字符串,例如將員工表中所有名字中的“S”替換成“上海”。如下:
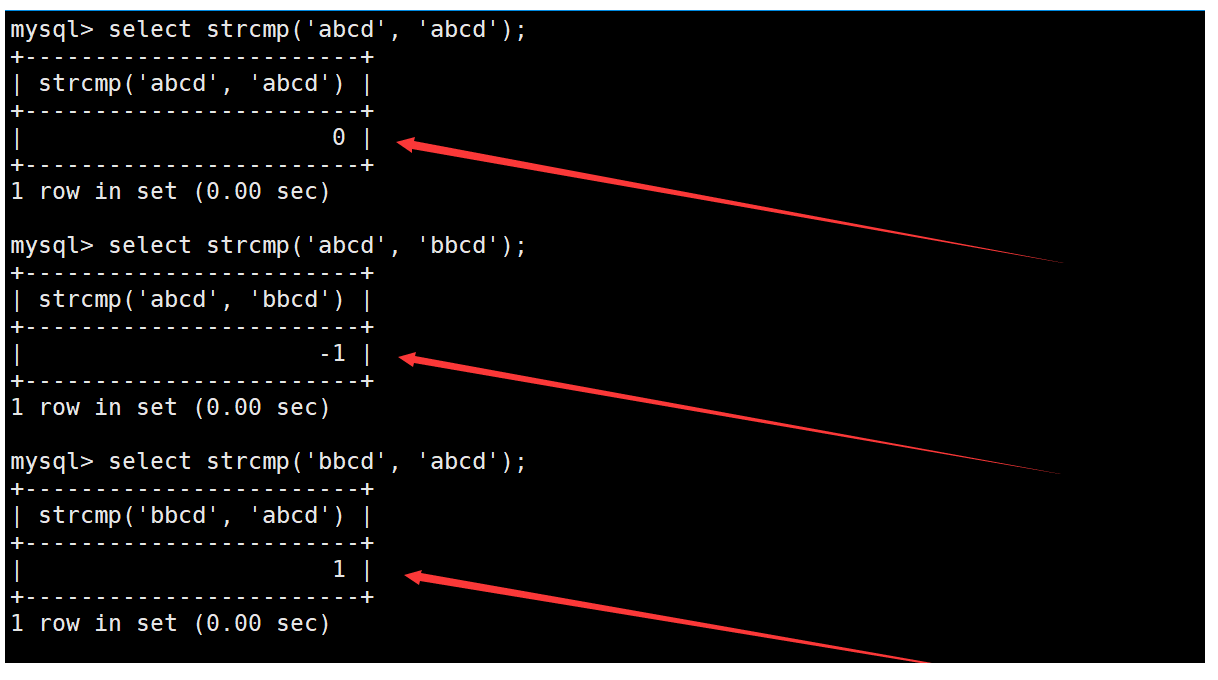
strcmp函數
strcmp函數用于逐字符按照ASCII碼比較兩個字符串的大小,兩個字符串大小相等返回0,前者大返回1,后者大返回-1。如下:
需要注意的是,strcmp函數在比較時是不區分大小寫的。如下:

ltrim、rtrim和trim函數
數學函數
其他函數
復合查詢(重點)
基本查詢
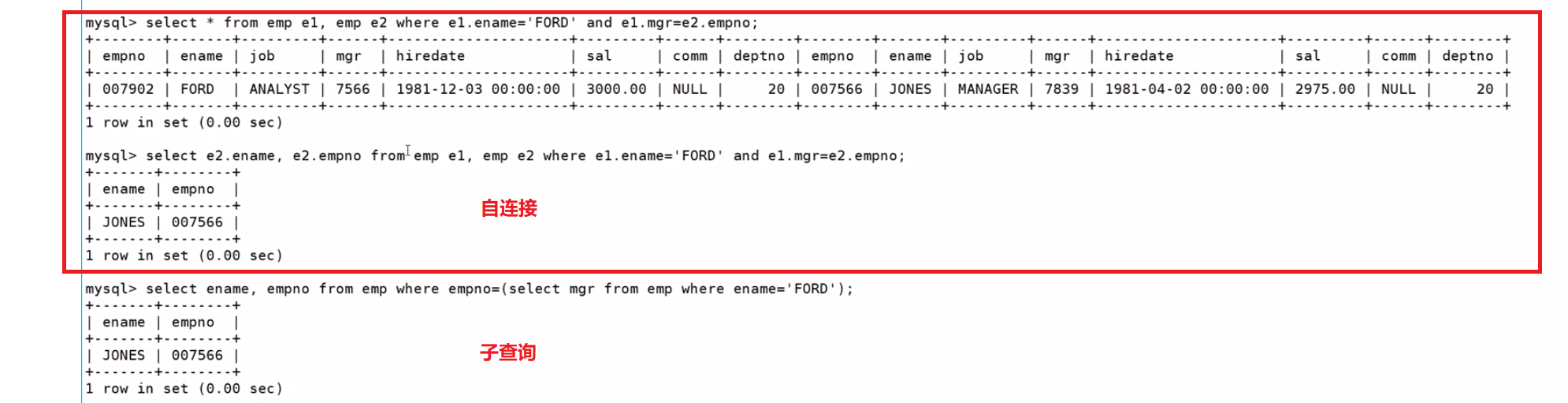
對同一張表做笛卡爾積
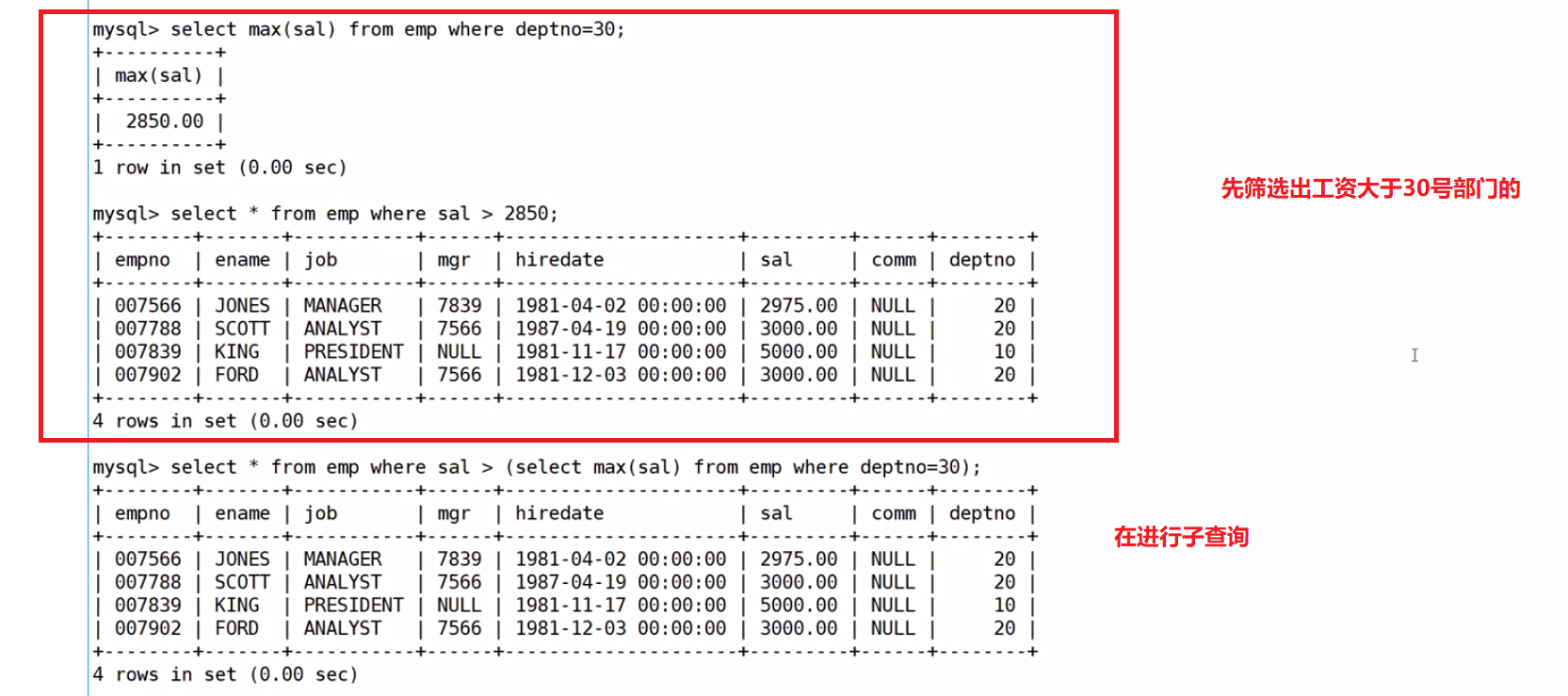
all關鍵字;顯示工資比部門30的所有員工的工資高的員工的姓名、工資和部門號?
先用基本的方法寫?
 ?
?
多列子查詢?
單行子查詢是指子查詢只返回單列,單行數據;多行子查詢是指返回單列多行數據,都是針對單列而言的,而多列子 查詢則是指查詢返回多個列數據的子查詢語句
查詢和SMITH的部門和崗位完全相同的所有雇員,不含SMITH本人??
查詢思路:先查詢SMITH屬于哪個部門的,然后再用多列子查詢,查詢出來和SMITH的部門和崗位完全相同的所有雇員,最后再排除SMITH本人
mysql> select ename from EMP where (deptno, job)=
(select deptno, job from EMP where ename='SMITH') and ename <> 'SMITH';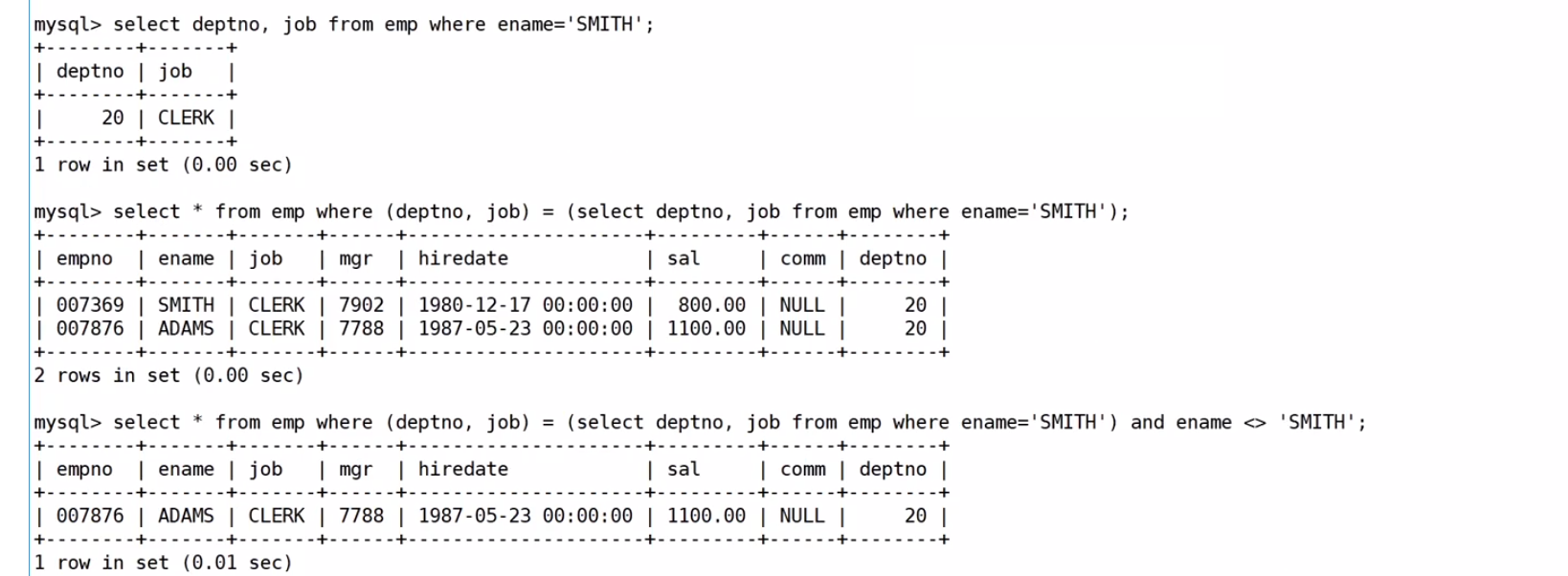 ?也可以用?in 把?和SMITH的部門和崗位完全相同的所有雇員?看成一對?
?也可以用?in 把?和SMITH的部門和崗位完全相同的所有雇員?看成一對?
 總結:目前全部的子查詢,全部都在where子句中,充當判斷條件。任何時刻,查詢出來的臨時結構,本質在邏輯上也是表結構。MySQL中一切皆表
總結:目前全部的子查詢,全部都在where子句中,充當判斷條件。任何時刻,查詢出來的臨時結構,本質在邏輯上也是表結構。MySQL中一切皆表
在from子句中使用子查詢
顯示每個高于自己部門平均工資的員工的姓名、部門、工資、平均工資
思路過程:第一步:先查找所有部門的平均薪資,然后再分組查找每個部門的平均薪資,最后再把每個部門的平均薪資的結果充當個臨時表,搭配from。注意要起別名
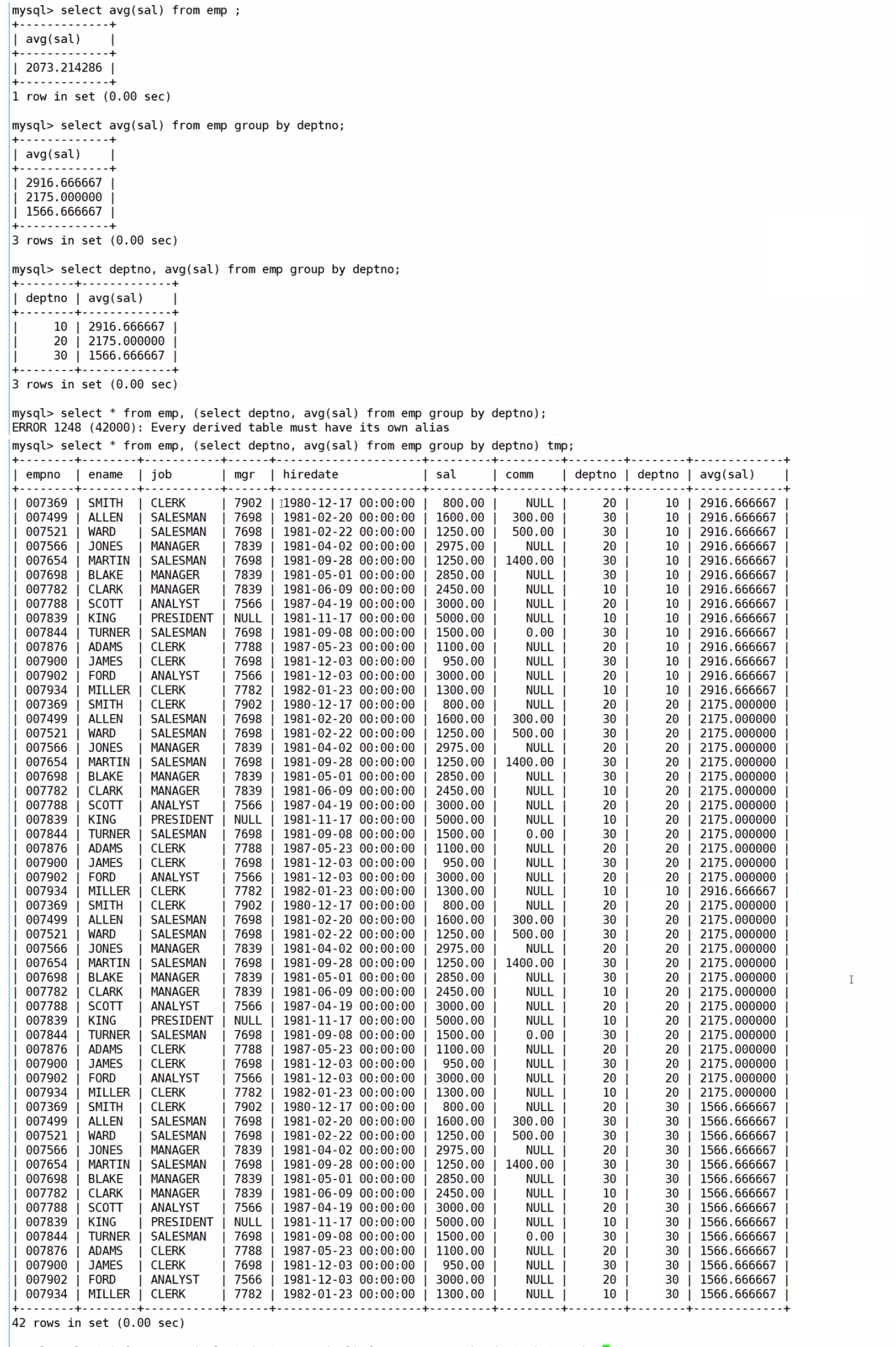
第二步:有些數據是沒意義的,就好比SMITH是20號部門的,你給她個10號部門的平均薪資,是沒有意義的,所以我們要用笛卡爾積給去除掉
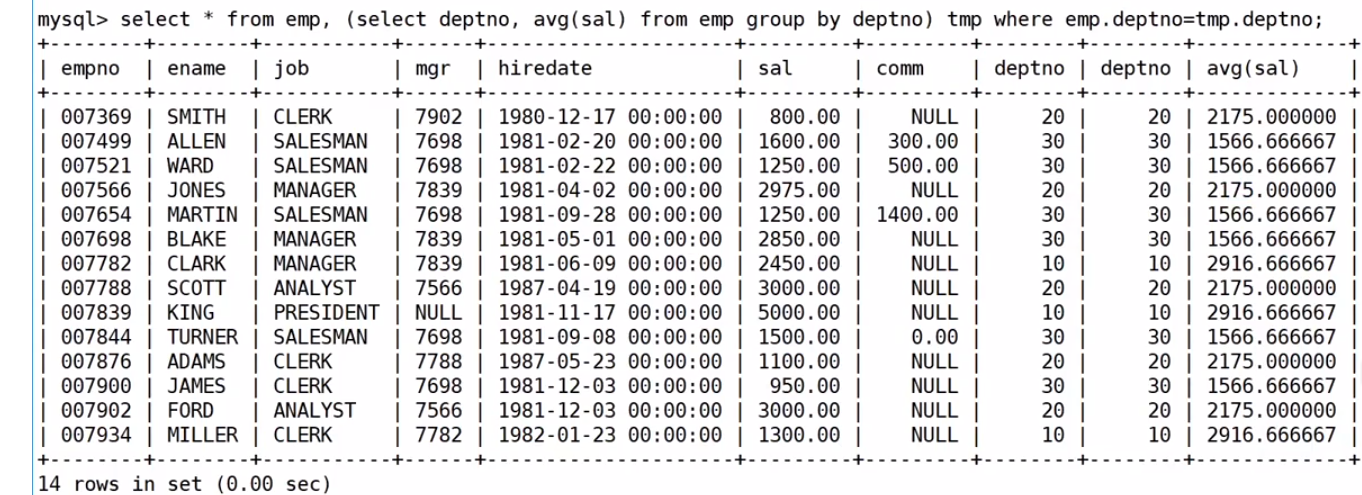 ?最后在進行篩選大于平均工資的
?最后在進行篩選大于平均工資的

附加條件:順便顯示在哪個地方工作?
部門的工作地點是在dept中,所以是先用笛卡爾積,我們上面按照需要篩選出來的員工跟部門表進行合并,起個別名為t1

然后去掉無效信息

再按照所要求的信息。需要符合要求的員工名稱,部門地點,部門

查找每個部門工資最高的人的姓名、工資、部門、最高工資???
select EMP.ename, EMP.sal, EMP.deptno, ms from EMP,
(select max(sal) ms, deptno from EMP group by deptno) tmp where EMP.deptno=tmp.deptno and EMP.sal=tmp.ms;肯定是先聚合,先把每個部門工資的薪資先找到

?把這個結果作為臨時表與emp表進行笛卡爾積組合
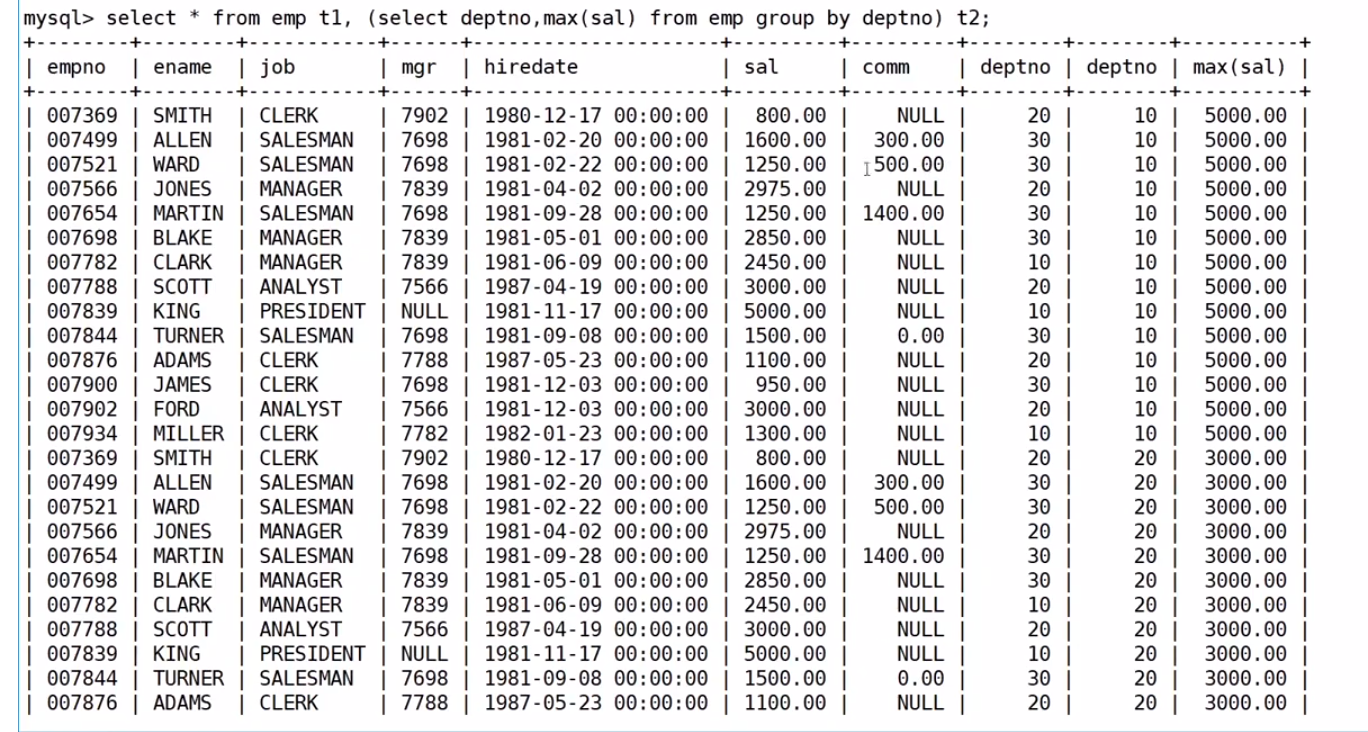
?然后進行篩選去掉無效信息
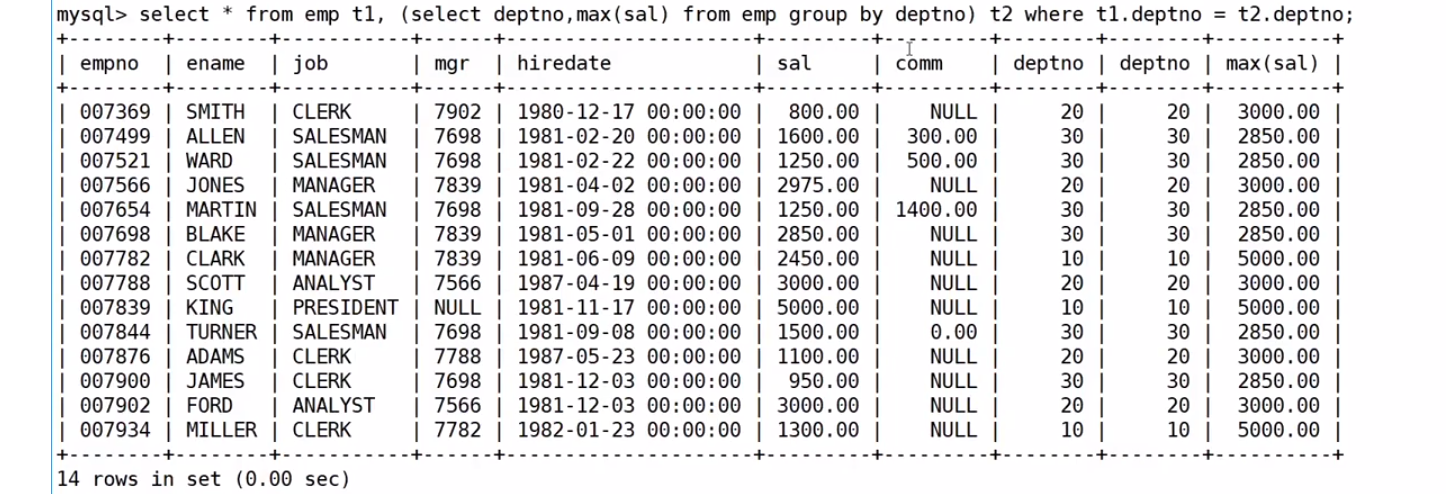
最后按照要求
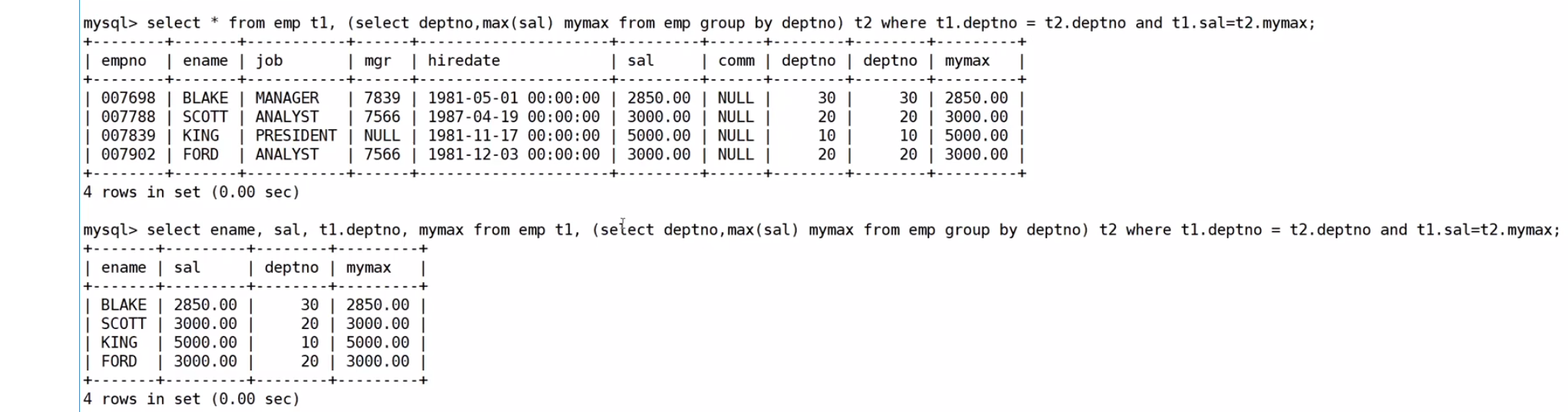
?顯示每個部門的信息(部門名,編號,地址)和人員數量
??方法1:使用多表(不推薦,因為為了要照顧group by語法結構,還需要對多個數據進行分組)
select DEPT.dname, DEPT.deptno, DEPT.loc,count(*) '部門人數' from EMP, DEPT
where EMP.deptno=DEPT.deptno
group by DEPT.deptno,DEPT.dname,DEPT.loc;過程:先統計每個部門有多少人,然后按照部門分組
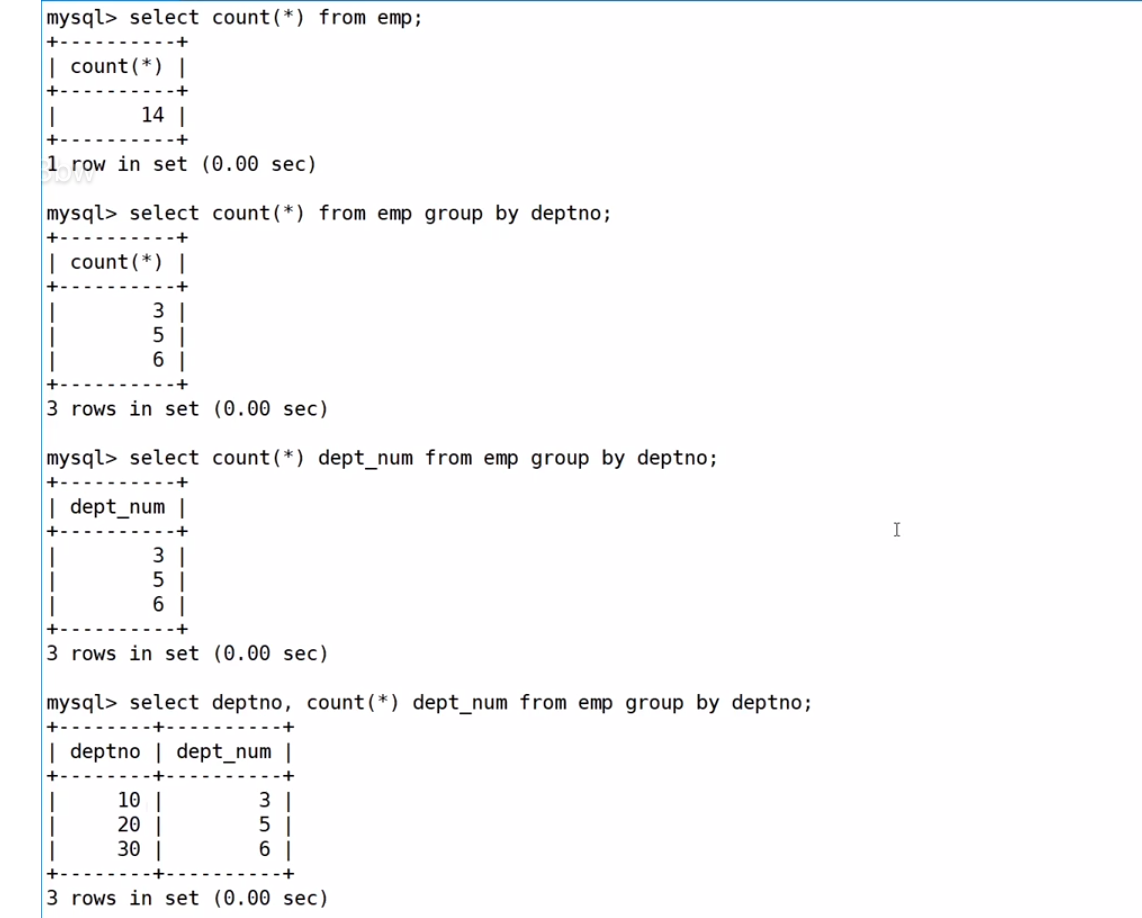
然后進行笛卡爾積,把兩個表放在一起,去除無效信息
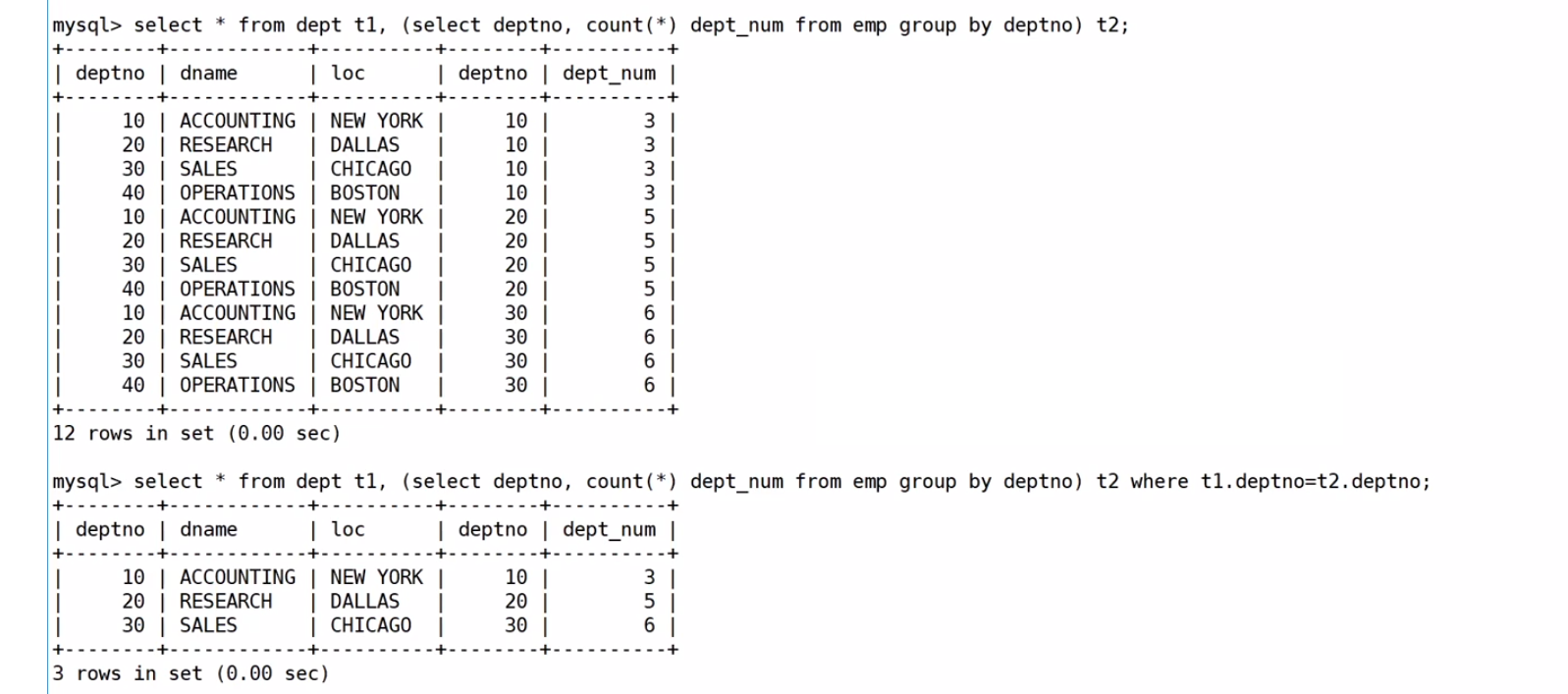
最后再按照要求

?方法2:使用子查詢
先進行分組計算每個部門的人數,然后進行聚合

最后再按照要求?

解決多表問題的本質:想辦法將多表轉換成單表,所以mysql中,所有select的問題全部都可以轉換成單表問題(多表查詢的指導思想)
合并查詢(用得不多)
在實際應用中,為了合并多個select的執行結果,可以使用集合操作符 union,union all
union
該操作符用于取得兩個結果集的并集。當使用該操作符時,會自動去掉結果集中的重復行。
將工資大于2500或職位是MANAGER的人找出來 ?
mysql> select ename, sal, job from EMP where sal>2500 union -> select ename, sal, job from EMP where job='MANAGER';//去掉了重復記錄步驟如下,union會幫你去重

union all
該操作符用于取得兩個結果集的并集。當使用該操作符時,不會去掉結果集中的重復行。
案例:將工資大于25000或職位是MANAGER的人找出來
mysql> select ename, sal, job from EMP where sal>2500 union all -> select ename, sal, job from EMP where job='MANAGER';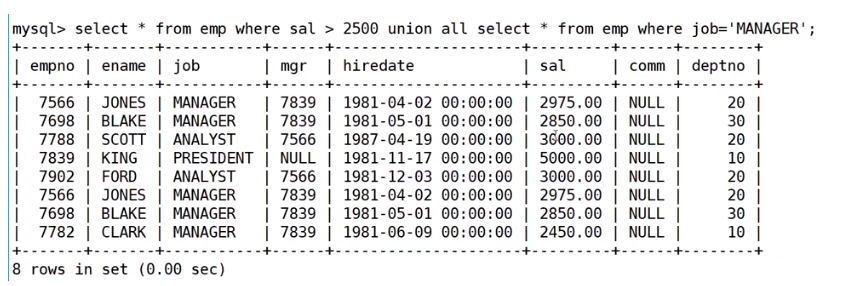
?)
![[ctfshow web入門] web10](http://pic.xiahunao.cn/[ctfshow web入門] web10)

)



`函數)
![[創業之路-364]:穿透表象:企業投資的深層邏輯與誤區規避](http://pic.xiahunao.cn/[創業之路-364]:穿透表象:企業投資的深層邏輯與誤區規避)

![[實戰] 天線陣列波束成形原理詳解與仿真實戰(完整代碼)](http://pic.xiahunao.cn/[實戰] 天線陣列波束成形原理詳解與仿真實戰(完整代碼))








