端到端自動駕駛目前是有望實現完全自動駕駛的一條有前景的途徑。然而,現有的端到端自動駕駛系統通常采用主干網絡與多任務頭結合的方式,但是它們存在任務協調和系統復雜度高的問題。為此,本文提出了DiffAD,它統一了各種駕駛目標并且聯合優化所有駕駛任務。實驗結果證明了該方法的優越性。
??【深藍AI】編譯
論文標題:DiffAD: A Unified Diffusion Modeling Approach for Autonomous Driving
論文作者:Tao Wang, Cong Zhang, Xingguang Qu, Kun Li, Weiwei Liu, Chang Huang
論文地址:https://arxiv.org/pdf/2503.12170
01 論文摘要
端到端自動駕駛(E2E-AD)已經快速成為實現完全自主駕駛的一種有前景的方法。然而,現有的E2E-AD系統通常采用傳統的多任務框架,通過單獨的特定任務頭來解決感知、預測和規劃任務。盡管這些系統以完全可微分的方式進行訓練,但是它們仍然會遇到任務協調問題,系統復雜度仍然很高。本項工作引入了DiffAD,這是一種新的擴散概率模型,它將自動駕駛重新定義為一種條件圖像生成任務。通過將異構目標在統一的鳥瞰圖(BEV)上進行柵格化并且對其潛在分布進行建模,DiffAD統一了各種駕駛目標并且在單個框架內聯合優化了所有駕駛任務,這顯著降低了系統復雜度并且實現了任務協調。反向過程迭代地細化生成的BEV圖像,從而產生更魯棒、更逼真的駕駛行為。在Carla中的閉環評估證明了所提出方法的優越性,實現了最佳的成功率和駕駛得分。
02 論文介紹
實現完全自動駕駛不僅需要對復雜場景進行深入理解,還需要與動態環境實現有效交互和對駕駛行為進行全面學習。傳統的自動駕駛系統建立在模塊化架構的基礎上,其中感知、預測和規劃是單獨開發的,然后集成到車載系統中。雖然這種設計提供了可解釋性并且便于調試,但是不同模塊的單獨優化目標往往會導致信息丟失和誤差累積。
最近的端到端自動駕駛(E2E-AD)方法試圖通過實現所有組件的聯合、完全可微分的訓練來克服這些局限性,如圖1(a)所示。
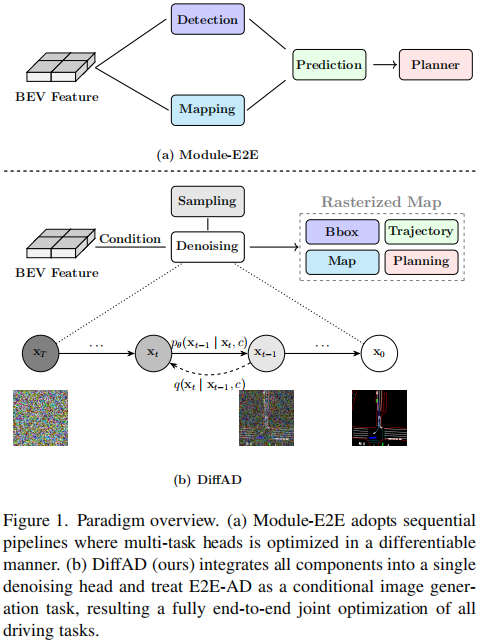
▲圖1| 范式概覽。(a)Module-E2E采用順序流程,其中多任務頭以可微分的方式進行優化;(b)DiffAD將所有組件集成到單個去噪頭中,并且將E2E-AD作為一個條件圖像生成任務??【深藍AI】編譯
然而,目前仍然存在幾個關鍵問題:
1)次優優化:UniAD和VAD等方法仍然依賴于順序流程,其中規劃階段依賴于前面模塊的輸出結果。這種依賴性會放大整個系統的誤差;
2)低效的查詢建模:當前基于查詢的方法部署了數千個可學習的查詢來捕獲潛在的交通元素。這種方法導致計算資源的分配效率低下,過度關注上游輔助任務而不是核心規劃模塊。例如,在VAD中,感知任務消耗了總運行時間的34.6%,而規劃模塊的運行時間僅占5.7%;
3)協調的復雜性:每個任務頭都使用不同的目標函數進行單獨優化,目標的形狀和語義也各不相同,整個系統變得分裂并且難以連貫訓練。
為了解決這些局限性,本文提出了一種新的范式DiffAD,它將所有駕駛任務的優化統一在單個模型中,如圖1(b)所示。具體而言,本文將來自感知、預測和規劃的異構目標在統一的鳥瞰圖(BEV)空間上進行柵格化,從而將自動駕駛問題重新定義為條件圖像生成問題。本文采用一種去噪擴散概率模型來學習由環視圖生成的BEV圖像的分布。該方法不僅能夠同時優化所有任務,從而緩解了誤差傳播問題,還通過共享解碼頭在潛在空間中利用計算高效的生成建模策略替代了低效的基于矢量的查詢方法。此外,通過僅關注噪聲預測,而不需要多個損失函數或者復雜的二分匹配,本文方法顯著地簡化了整個訓練過程。
總之,DiffAD通過將任務統一到單個端到端框架中,克服了現有基于查詢的順序方法的局限性,該框架增強了協調,減少了誤差傳播,并且更高效地分配計算資源,以實現安全且有效的規劃。
本文的主要貢獻總結如下:
1)本文引入了一種端到端的自動駕駛范式,該范式利用統一的、完全柵格化的BEV表示將各種駕駛任務集成到單個模型中;
2)本文將駕駛任務重新表述為條件圖像生成問題,并且提出了DiffAD,這是一種擴散模型,它可以學習由環視圖生成的BEV圖像的潛在分布。此外,本文還提出了一種數據驅動方法,它從生成的BEV圖像中提取矢量化規劃軌跡;
3)本文證明,DiffAD在端到端規劃方面實現了最先進的性能,其在閉環評估方面明顯優于先前的方法。
03 DiffAD
概述:如圖2所示,DiffAD由三個主要部分組成:潛在擴散模型、BEV特征生成器和軌跡提取網絡(TEN)。
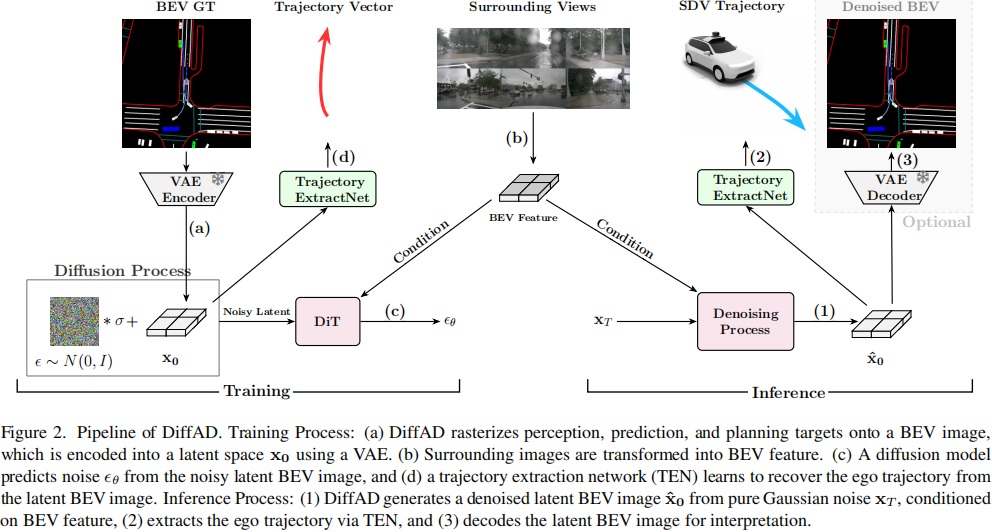
▲圖2| DiffAD的流程??【深藍AI】編譯
訓練過程:
1)柵格化和潛在空間編碼:DiffAD首先將感知、預測和規劃目標在BEV圖像中進行柵格化。然后,使用現成的VAE編碼器將BEV圖像壓縮到潛在空間中以進行降維;
2)特征提取和轉換:將環視圖像傳入特征提取器,它將得到的透視圖特征轉換為統一的BEV特征;
3)噪聲預測的擴散模型:將高斯噪聲加入潛在的BEV圖像中,以獲得帶有噪聲的潛在BEV圖像。基于邊界元法特征,訓練擴散模型以從帶有噪聲的潛在表示中預測噪聲;
4)軌跡提取:訓練基于查詢的TEN,從潛在BEV圖像中恢復自車的矢量化軌跡。
推理過程:
1)條件去噪:DiffAD首先根據BEV特征,從純高斯噪聲中生成去噪的潛在BEV圖像;
2)規劃提取:TEN從潛在BEV圖像中提取自車的規劃軌跡;
3)BEV解碼:通過將潛在BEV圖像解碼回像素空間,可以獲得預測的BEV圖像,用于解釋和調試。
3.1. 柵格化BEV表示
感知周圍交通智能體和地圖元素對于理解駕駛場景至關重要,而預測智能體的 軌跡對于做出安全駕駛決策至關重要。DiffAD 利用柵格化 BEV 表示來統一駕 駛任務的異構目標,例如邊界框、車道元素、智能體軌跡和自車規劃。
具體而言,本文將邊界框和地圖元素在 RGB 圖像上進行柵格化,用于感知任 務,表示為,其中不同的語義元素使用不同的顏色來表示。
對于軌跡預測任務,智能體的軌跡被繪制在第二張 RGB 圖像上,表示為。最后,自車的未來軌跡在第三張 RGB 圖像上進行柵格化, 用于規劃任務,表示為
。軌跡的顏色隨時間插值,以表示點 之間的時間關系。
這種統一的 BEV表示允許擴散模型同時學習感知、預測和規劃任務。此外,它 還能夠推理自車與其周圍環境之間的物理關系和社會交互,從而在所有任務中 實現場景級的一致結果。
3.2. 去噪擴散學習
根據潛在擴散模型 (LDM) 框架, 本文利用 VQ-VAE 將柵格化 BEV 圖像壓縮 到低維潛在空間中。然后, 沿著通道維度將感知、預測和規劃的潛在表示連接 起來, 以構建潛在 BEV 圖像
。
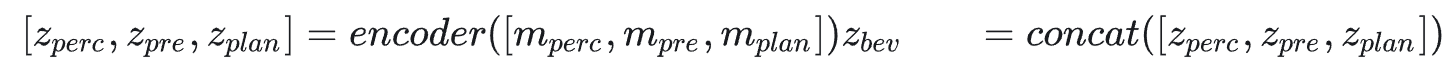
然后,通過擴散過程加入噪聲 ?, 以產生有噪聲的潛在圖像,其中
。 帶有噪聲的潛在圖像被劃分為 tokens, 并且通過 DiT 的多層傳遞, 最 終使用 MLP 層來預測噪聲 ?θ。
條件去噪:DiffAD 利用多視圖圖像和駕駛命令作為條件來引導去噪過程。 對于 條件制導機制, 出于對有效性和效率的考量, 本文采用了零初始化的自適應層 歸一化 (AdaLN)。 具體而言, 本文使用 BEVFormer 將多視圖圖像轉換為 BEV 特征圖, 然后對 BEV 特征
進行標記, 并且將其與時間步 長嵌入
和駕駛命令嵌入
相結合, 作為 AdaLN 的輸入。
![]()
時間一致性:規劃從根本上而言是一個連續的決策任務, 其中智能體必須根據 其當前狀態和環境動態變化做出決策。 為了捕獲時間信息, 本文采用 ConvLSTM 來融合歷史 BEV 特征。 然而, 僅融合 BEV 特征不足以確保規劃隨 時間推移的一致性。 為了解決這個問題, 本文引入了一種行為-引導機制, 其中 假設當前的決策不僅依賴于當前的觀測結果, 還依賴于上一個行為。 因此, 聯合分布可以建模為
其中表示智能體在時刻t的狀態,
表示在時刻t采取的行為。然而,該方法可能會導致網絡過度依賴先前的潛在 BEV 圖像, 而忽略了當前的觀測結果。 為了緩解這個問題, 本文對先前的潛在 BEV 圖像 tokens 引入了概率為 0.5 的 dropout 正則化。 最終的條件引導表示如下:
![]()
其中, 表示隨機 dropout 操作。
3.3 軌跡提取網絡
為了獲得用于自車控制的矢量化軌跡,需要從潛在空間中恢復軌跡。一種直接的方法是將潛在 BEV 圖像解碼回像素空間,并且應用基于規則的后處理方法。然而,為了提高泛化能力和魯棒性,本文選擇了一種數據驅動方法。
具體而言,本文設計了一個基于查詢的 transformer 網絡,以從潛在 BEV 圖像中提取軌跡。首先,通過嵌入層將潛在 BEV 圖像
分成一系列 tokens
。可學習的查詢
通過一系列 transformer 層與標記化序列進行交互。最后,單個 MLP 將學習到的查詢解碼為預測軌跡
。該過程總結如下:
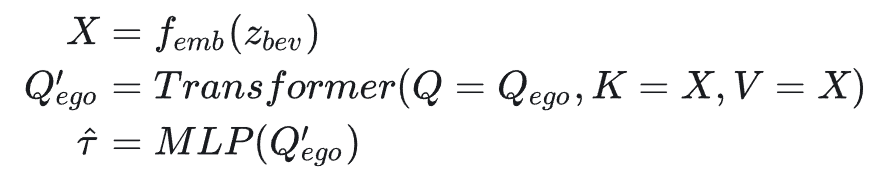
3.4 端到端學習
DiffAD 是完全端到端可訓練的,它基于柵格化 BEV 表示和擴散模型。與傳統的 Module-E2E 方法 (涉及不同駕駛任務的多個損失函數) 不同,本文系統通過使用統一的損失函數簡化了優化:噪聲回歸損失用于去噪以及軌跡提取損失用于矢量化軌跡。
去噪損失:本文使用標準均方誤差 (MSE) 損失來優化擴散模型,確保它能夠從有噪聲的潛在 BEV 圖像中準確地恢復噪聲。
軌跡提取損失:軌跡提取損失也基于 MSE,在預測軌跡和真值自車軌跡
之間應用。該損失確保了網絡能夠從潛在 BEV 圖像中準確地恢復矢量化軌跡。
04 實驗
4.1. 數據集
對于E2E模型,開環評估是不夠的。為了解決這個問題,本文在CARLA仿真器中使用Bench2Drive數據集進行訓練和閉環評估。Bench2Drive提供了三個數據子集:mini(10個片段用于調試)、base(1000個片段)和full(10000個片段用于大規模研究)。本文使用base子集進行訓練。
4.2. 指標
1)成功率(SR):該指標計算了在分配的時間內成功完成且沒有違反交通的路徑比例;
2)駕駛評分(DS):該指標考慮了路徑完成率和違規處罰;
3)FID:本文使用Frechet Inception Distance(FID)來評估縮放性能,這是評估圖像生成模型的標準指標。
4.3. 基線
1)UniAD:一種經典的基于模塊的E2E方法,它采用基于查詢的架構來顯式地連接感知、預測和規劃任務;
2)VAD:另一種基于模塊的E2E方法,它通過利用Transformer查詢與矢量化場景表示來提高計算效率;
3)AD-MLP:一種基線模型,它通過簡單地將自車的歷史狀態傳入MLP來預測未來的軌跡;
4)TCP:一種簡單但有效的基線,它僅使用前視相機和自身狀態來預測軌跡和控制命令;
5)ThinkTwice:一種促進由粗到精框架的方法,迭代地細化規劃路徑,并且利用專家特征蒸餾;
6)DriveAdapter:Bench2Drive排行榜上表現最佳的方法,它通過解耦感知和規劃,充分利用專家特征蒸餾來提升性能。
4.4. 實現細節
訓練:本文使用來自穩定擴散的現成預訓練變分自動編碼器(VAE)模型。VAE編碼器的下采樣系數為8。在本節的所有實驗中,擴散模型都在潛在空間中運行。本文保留了DiT中的擴散超參數。為了促進學習過程,本文在第一階段從單張圖像學習開始用于感知部分,即檢測和建圖,而預測和規劃中的BEV圖像則填充為零。然后將模型與所有感知、預測和規劃部分聯合訓練。
推理:本文利用DDIM-10采樣器進行推理,并且使用官方的評估工具來計算閉環指標。對于車輛控制,本文采用官方提供的PID控制器。
4.5. 主要結果
表格1中的總體結果表明,DiffAD明顯優于包括UniAD和VAD在內的基線方法,并且超過了ThinkTwice和DriveAdapter等基于蒸餾的方法的性能。
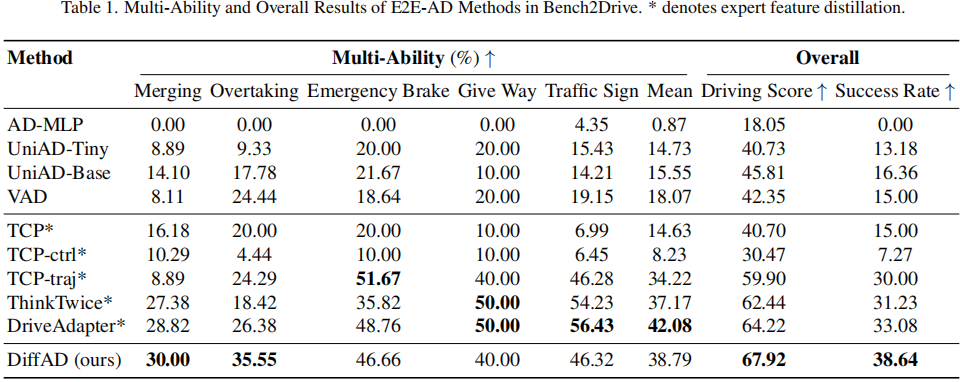
▲表1| E2E-AD方法在Bench2Drive上的多項能力和整體結果??【深藍AI】編譯
在多項能力評估中,DiffAD在并道和緊急制動等交互式場景中比UniAD和VAD具有顯著優勢。這一改進歸功于其集成的學習框架,該框架使任務目標之間能夠顯式地交互,從而實現了更連貫、更有效的規劃。由于訓練數據集的規模相對較小,與利用專家特征蒸餾的方法相比,DiffAD在交通標志方面的性能略低。結合專家特征(提供了有價值的駕駛知識)可以幫助緩解潛在的過擬合問題。因此,利用專家特征蒸餾的模型(例如TCP、ThinkTwice和DriveAdapter)通常優于沒有利用它的模型(例如VAD和UniAD)。
本文對DiffAD進行失效案例分析,如圖3所示。
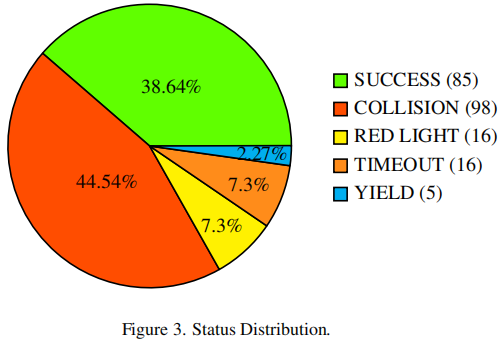
▲圖3| 狀態分布??【深藍AI】編譯
分析表明,很大一部分路徑失效是由與交通智能體發生碰撞導致的,這表明在CARLA v2中的交互存在挑戰。此外,少數失效是由于超時造成的,通常是由于規劃模塊在停止后偶爾無法恢復運動引起的,通過利用專家蒸餾或者加入更多的交通信號燈交互數據可以有效地緩解這個問題。一小部分失效發生在智能體闖紅燈時,可能是由于CARLA中交通信號燈的渲染質量低或者存在具有挑戰性的光照條件使其難以檢測。
4.6. 消融研究
去噪步數對性能的影響:DiffAD的迭代去噪遵循由粗到精的細化過程,逐步地改進感知和規劃。如表格2所示,將去噪步數從3增加到10可以顯著降低FID(-53.5%),同時提高駕駛得分(+2.18)和成功率(+3.64),這表明多步細化有助于解決軌跡模糊問題。然而,將步數擴展到10以上(例如,擴展到20)會導致性能飽和,這表明計算開銷和規劃精度之間達到了最佳平衡。

▲表2| 去噪步數對性能的影響??【深藍AI】編譯
任務聯合優化的影響:本文研究了聯合優化輔助任務對規劃性能的影響。如表格3所示,三個任務的聯合優化實現了最佳的結果,突顯了任務聯合優化在提高規劃性能方面的重要性。

▲表3| 聯合優化輔助任務的影響??【深藍AI】編譯
行為引導dropout的影響:直觀上,過度依賴先前的決策會增加關鍵緊急情況下的響應延遲。相反,在不考慮先前行為的情況下做出決策可能會導致突發的感知錯誤,從而導致不切實際的規劃結果。為了更好地理解這種權衡,本文分析了行為引導模塊中不同dropout率對規劃性能的影響。表格4展示了不同dropout率的結果。0.95的dropout率實現了最佳平衡,這表明保留一小部分先前的行為引導有利于魯棒的規劃。

▲表4| 行為引導dropout對規劃性能的影響??【深藍AI】編譯
統一生成建模的效率:如表格5所示,盡管DiffAD的參數規模更大(545.6M vs VAD的58.1M),但是它實現了具有競爭力的延遲(258ms vs 140ms)和實時FPS(3.9)。
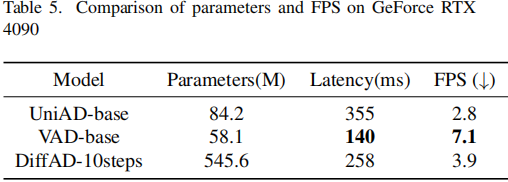
▲表5| 參數和FPS在GeForce RTX 4090上的比較??【深藍AI】編譯
該效率歸功于兩項關鍵創新:
1)任務無關壓縮:VAE有效地壓縮了BEV圖像,同時保留了關鍵信息,大大減少了用于交互和細化的tokens數量;
2)并行擴散頭:與順序多任務流程不同,DiffAD采用共享的去噪網絡來聯合優化所有駕駛任務,消除了級聯推理的低效問題。
生成建模的多模態:在圖4中,本文展現了定性結果,其展示了DiffAD強大的生成能力及其產生不同規劃結果的能力。對于每種場景,本文通過采樣不同的潛在變量來生成兩個決策。本文將規劃軌跡(紅色)和專家軌跡(藍色)疊加到環視相機的原始前視圖像上。BEV真值(GT)顯示在左側,而預測的BEV顯示在右側。值得注意的是,生成的BEV與真值密切對齊,并且各種規劃的軌跡始終是安全且合理的。這展現了DiffAD準確感知環境和有效學習交互行為的能力。

▲圖4| 模型多模態決策的演示??【深藍AI】編譯
05 總結和未來工作
本項工作提出了DiffAD,這是一種基于擴散框架的端到端自動駕駛模型。本文的主要貢獻在于將駕駛任務的異構目標轉化為統一的柵格化表示,將E2E-AD表述為條件圖像生成任務。該方法簡化了問題,并且為利用各種生成模型(例如擴散模型、GANs、VAE和自回歸模型)提供了明確的途徑。本文認為,DiffAD的強大性能突顯了生成模型在推進自動駕駛研究方面的潛力,并且希望它能夠激發該領域的進一步探索。
局限性和未來工作:盡管本文框架具有前景,但是在Carla v2中的成功率仍然遠未達到完美。有效地利用多模態生成預測進行規劃以及使模型輸出與人類偏好相一致是值得進一步探索的方向。此外,Carla中的交通仿真與現實世界條件之間存在顯著差距。為了解決這個問題,未來工作將在實車上部署該系統,以評估其在現實交通場景中的性能。





之如何封裝并調用dll)


)


詳解:靈活處理動態數據的利器)







