目錄
文章目錄
- 目錄
- 統計學
- 統計學基本概念
- 描述性統計
- 數據可視化圖表工具
- 匯總統計
- 統計數據的分布情況:中位數、眾數、平均值
- 統計數據的離散程度:極差、方差、標準差、離散系數
- 相關分析
- Pearson 線性關系相關系數
- Spearman 單調關系相關系數
- 回歸分析
- 回歸模型
- 一元線性回歸模型
- 應用最小二乘法來調整模型參數精度
- 如何評價回歸模型的正確性?
- 多元線性回歸模型
- 避免過度擬合問題
- 擬線性回歸建模方法
統計學
- 定義:是一門關于 “數據資料” 的收集、整理、 描述、分析和解釋的學科。
- 目的:探索數據集合的內在特征與規律性。
- 應用:對系統進行深入、全面的認識;對未來作出準確的預測,繼而幫助決策。
- 方法:調查研究。
- 路徑:數據收集、數據分析、建立概念、描述預測。
掌握統計學的數據科學家或工程師,他們和具體的行業緊密相聯,有扎實的統計基礎,也有豐富的行業經驗。會編程、做數據可視化。通過海量數據進行分析,獲得具有巨大價值的產品和服務,或深刻的洞見。
統計學基本概念
使用解字法,我們可以將 “統計學” 拆分為以下基本概念:
數據:英文單詞 data,在拉丁文里是 “已知或事實” 的含義。典型的數據類型包括:
- 定性變量數據(Qualitative): 用于描述事物的屬性或類別,其值通常是非數值的,無法進行數學運算。
- 名義變量(Nominal Scale):表示無順序或等級差異的分類數據,僅用于標識或區分不同類別。例如:性別、顏色等。
- 順序變量(Ordinal Scale):類別具有自然順序或等級,但類別間的差異無法量化。例如:滿意度評分、教育水平等。
- 定量變量數據(Quantitative):以數值形式表示,具有明確的數學意義,可進行算術運算
- 區間變量(Interval Scale):數值具有等距性,但無絕對零點。例如:溫度、年份、IQ 分數等。允許加減運算,但不能計算比率,例如:20℃ 不是 10℃ 的兩倍熱。
- 比率變量(Ratio Scale):具有區間變量的所有特性,且還擁有絕對零點。即:“0” 可以表示 “無”。例如:身高、體重、收入等。可進行乘除運算,例如:身高 180cm 是 90cm 的兩倍。
數據化:把現象轉變成可以制表分析的量化形式過程。
數據收集:典型的數據來源包括:
- 統計數據:調查數據、實驗數據、匯總數據等。
- 傳感器記錄數據:金融交易、市場價格、生產過程、財務、營銷、傳感器等。
- 新媒體網絡數據:微信、微博、QQ、手機短信、圖片、視頻、音頻等。
數據分析:典型的分析行為包括:
- 描述和分析系統特征,包括:現狀、結構、因素之間關系等。
- 分析系統的運行規律與發展趨勢,即:動態數據。
- 對系統的未來狀態進行預測,例如:建立模型。
描述性統計
描述性統計用于將數據進行可視化展示,是一種將 “抽象思維” 轉換為 “形象思維” 的工具和方法論。
把數字置于視覺空間中,讀者的大腦就會更容易發現其中隱藏的模式,得出許多出乎意料的結果。—— Nathan Yau
- 目的:通過數據來描述規律、講述真相、解決問題。
- 思維:問題導向。數據是用來講故事的,而故事是面向聽眾的,而聽眾是帶著問題來的,所以數據可視化使用圍繞 “問題” 展開。對講述問題有用的數據應該展示,相反則可以忽略。
- 技巧:用數據說話的強烈意識 對系統特性的深入思考嘗試性分析、對信息點敏感,尤其對異常數據點敏感。
- 工具:圖表。
- 基本原則:
- 準確:能清晰地表達主題。
- 醒目:信息點特別突出。
- 美觀:圖形使用應豐富多彩。
- 圖、文并茂:文字應與圖、表的篇幅平衡。
- 詳略得當,防止冗長的流水帳。
數據可視化圖表工具
-
柱形圖(Bar Chart):用于描述定性數據的分布。適用于定性數據,例如:豆瓣電影評分。包括堆積柱形圖、百分比堆積柱形圖、瀑布圖、漏斗圖等變體。

-
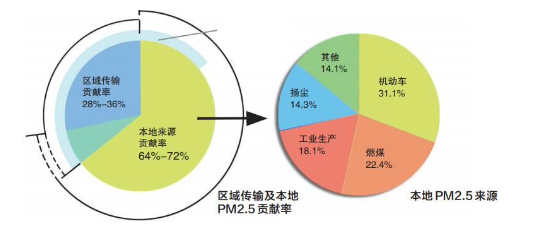
餅圖(Pie Chart):用于描述數據的結構性特征。適用于定性數據,例如:北京市空氣污染的主要來源。包括子母餅圖、旭日圖等變體。
-
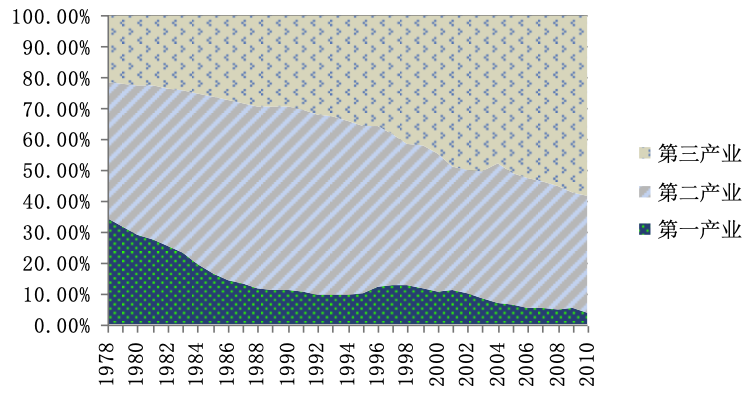
面積圖:用于描述數據的動態比率結構。適用于定量數據,例如:上海就業人口的三產構成(1978—2011)。
-
折線圖(Line Chart):用于描述數據的動態變化規律。適用于定量數據,例如:城鄉居民家庭收入/元(1991~2003)。

-
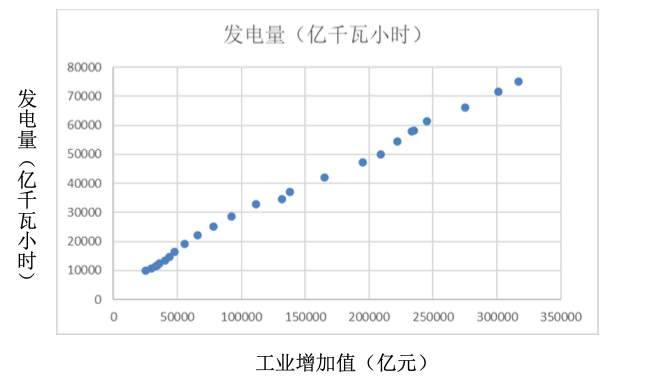
散點圖(Scatter Plot):用于描述或反映 2 個定性變量之間的相關關系。例如:發電量與工業增加值的關系(1995~2019)
-
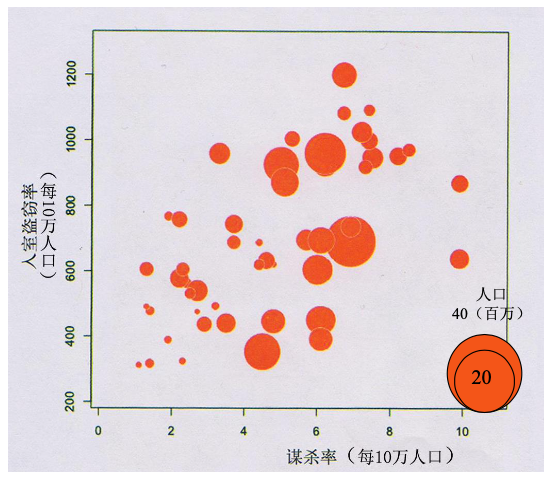
氣泡圖:用于描述 3 個定性變量的 n 個樣本點之間的關系,例如:美國犯罪率氣泡圖。
-
雷達圖(Radar chart):用于描述多個定性變量之間的數量關系,例如:城鄉居民家庭平均每人生活消費支出(1997 年)。
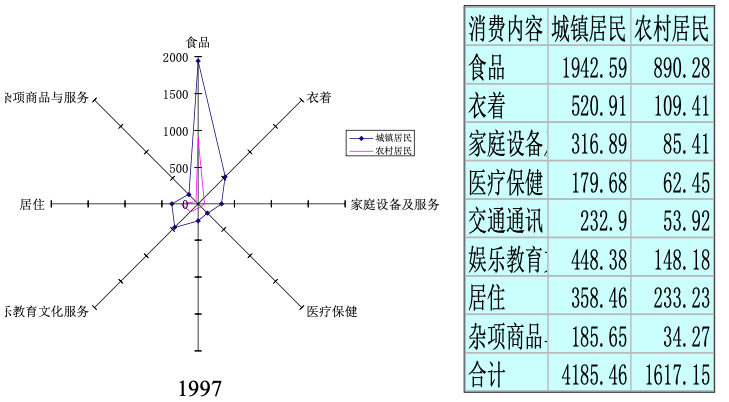
匯總統計
統計數據的分布情況:中位數、眾數、平均值
我們通常可以使用 “中位數、眾數、均值” 來描述基本的數據分布情況。但因為三者之間有著不同的特性,所以它們也有著不同的應用場景。
中位數(Median):將數據從小到大排序,處于中間位置的觀測值(實際數值)。
- 對于一個數據集,中位數經過數值運算后始終是唯一的;
- 定性數據不能數值運算所以沒有中位數;
- 只利用了數據集的中間位置數據,所以對兩端的極端值不敏感。
- 應用場景:對于名義變量,用于描述集中趨勢。
眾數(Mode):出現頻次最多的觀測值。
- 對于一個數據集,眾數可以不唯一;
- 眾數不需要數值運算得出,所以定性數據有眾數;
- 只利用了數據集的一部分數據,所以不容易受到極端值的影響。
- 應用場景:對于順序變量,用于描述集中趨勢。
平均值(Mean):所有數據之和除以數據的個數,反映數據的總體平均水平。
- 對于一個數據集,均值經過數值運算后始終是唯一的;
- 定性數據不能數值運算所以沒有均值;
- 利用了數據集的全部數據參與數值運算,所以容易受極端值影響。
- 應用場景:定量變量,一般使用平均值。例如:歌唱比賽,首先應該利用所有評委的評分,其次應該去除最高分和最低分這 2 個極端值。
統計數據的離散程度:極差、方差、標準差、離散系數
所謂離散程度,即:數據集中每 2 個數據之間的差異程度。通常使用極差、方差、標準差、離散系數進行測量。
極差(Rang):最大值與最小值之間的差距,顯然容易受到極端值的影響。
- 四分位極差(Interquartile Rang):為了消除極端值的影響。
方差(Variance):以均值為中心,測量所有觀測值與均值的平均偏離程度。
-
總體方差(Population Variance):描述整個數據集所有數據與總體均值的偏離程度。“方差” 通常指的就是整體方差。
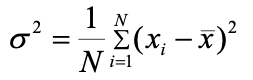
-
樣本方差(Sample Variance):描述從整個數據集中抽取的樣本數據與樣本均值的偏離程度,是總體方差的估計量。當總體方差數據量特別巨大時,可以考慮用樣本方差來進行預估。
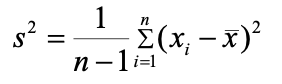
標準差(Standard Deviation):方差的平方根就是標準差。值得注意的是,在一個方差使用平方來表示觀測值樣本和均值先之間的 “垂直距離”,但平方也放大了數值的量綱。所以標準差就是對方差的平方開根,將結果數值還原為與原樣本相同的量綱。
離散系數(Coefficient of Variation):標準差常用于描述一個數據集的離散程度;而離散系數則用于比較 2 個及以上數據集之間的離散程度。離散系數是一種 “無量綱” 的相對度量,公式如下,離散系數等于標準差除以均值,從而消除了量綱的影響,例如:1.4/6=0.23 和 14/60=0.23 之間的 CV 相同,但量綱相差了 10 倍。反之,通常不會使用標準差作為多個數據集之間的離散程度的比較。
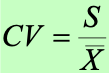
相關分析
線性關系:線性函數 Y=f(X),每一個 X 值都唯一地對應一個 Y 值。
隨機關系(Stochastic Relationship):當 X 的值給定時,Y 的取值服從一個分布,而不是一個唯一對應的 Y 值。
相關系數(The Correlation Coefficient):在隨機關系場景中,需要引入一個相關系數來描述 “X” 和 “Y 的取值分布” 之間的關聯程度的量化指標。簡而言之,相關系數描述了 2 個變量 a、b 之間是否存在關系,以及關系是否密切(是否線性相關)。
現如今,根據不同的數據類型和數據分析需求,相關系數有多種定義和計算方法。包括:Pearson、Spearman、Kendall 等相關系數。
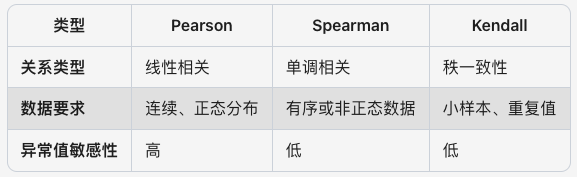
Pearson 線性關系相關系數
Pearson(皮爾遜)相關系數 r(x, y),用于衡量兩個連續變量之間的 “線性相關” 程度。
- 存在 2 個連續變量 x 和 y:

- Pearson 系數計算公式:分子為 x 和 y 的樣本協方差,分母為 x 和 y 的樣本方差的乘積。

r(x, y) 的取值范圍誒 [-1, 1],對應的判別性質為:

最佳實踐經驗值為:

Spearman 單調關系相關系數
Pearson 用于測量 x 和 y 連續變量之間的線性相關性,但現實中存在大量非線性相關的數據集,但它們之間也會存在某種關聯關系,如單調關系。單調關系,即:即一個 x 變量增加時,另一個 y 變量是否傾向于同向或反向的變化,而不會要求嚴格線性關系。
Spearman 單調關系(正相關、負相關)相關系數,基于 2 個連續變量之間的秩次( Ranks,排序位置)來進行計算。可用于線性或非線性連續變量數據集,尤其適用于順序連續變量、存在異常值的連續變量、非正態分布連續變量。
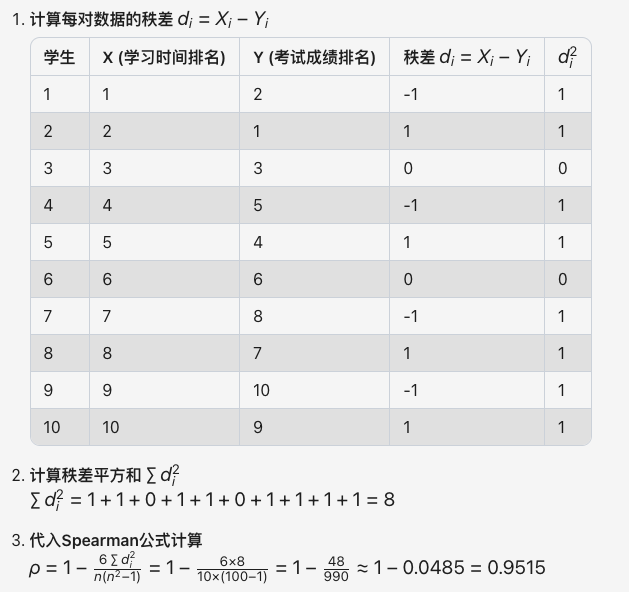
例如:使用 Spearman 來判別某班級 10 名學生按學習時間(小時/周)和考試成績排名之間的單調關系。如下表。
| 學生 | 學習時長 a | 學習時長排名 x | 考試成績 b | 考試成績排名 y |
|---|---|---|---|---|
| A | 十小時 | 1 | 99 | 2 |
| B | 九小時 | 2 | 100 | 1 |
| C | 八小時 | 3 | 98 | 3 |
| D | 七小時 | 4 | 96 | 5 |
| E | 六小時 | 5 | 97 | 4 |
| F | 五小時 | 6 | 95 | 6 |
| G | 四小時 | 7 | 93 | 8 |
| H | 三小時 | 8 | 94 | 7 |
| I | 二小時 | 9 | 91 | 10 |
| J | 一小時 | 10 | 92 | 9 |
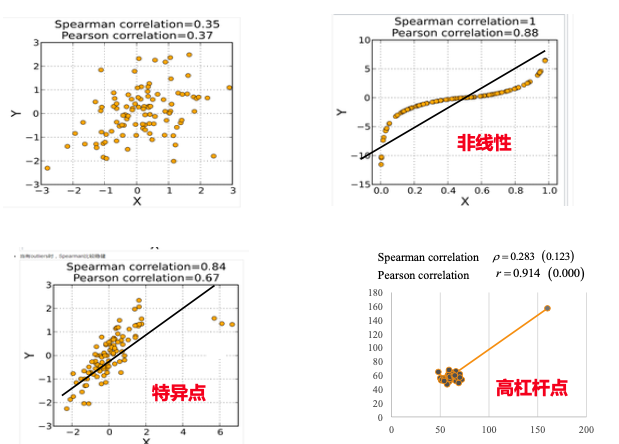
顯然,以上 a 和 b 兩組數據呈現出非線性特征,但這兩組數據未必就不存在任何正相關或負相關的關系。同時 a 和 b 兩組數據屬于順序變量類型,所以可以采用 Spearman 來測量判別。
從下述計算可知,Spearman 計算過程完全不關心 a 和 b 的實際數據,只會關系 x 和 y 的 ranks 排名關系。計算結果 Spearman 系數 ≈0.952,接近 1,表明學習時間排名與考試成績排名存在極強的正相關。
回歸分析
回歸模型
回歸模型(regression)的誕生可以追溯到 19 世紀,英國生物統計學家弗朗西斯·高爾頓(Francis Galton)在研究遺傳特征時提出。1886 年,高爾頓發表了《遺傳的身高向平均數方向的回歸》一文,通過分析 1078 對父母與子女的身高數據,發現了一個有趣的現象:
- 身材較高的父母,其子女身高也高于平均身高,但通常不如父母那么高;
- 身材較矮的父母,其子女身高也比平均身高矮,但不如父母那么矮。
高爾頓將這種后代身高 “趨向于平均身高” 的現象稱為 “回歸”。
高爾頓的學生卡爾·皮爾遜(Karl Pearson)進一步收集了更多數據,證實了這一發現,并建立了第一個數學形式的回歸方程:? = 33.73 + 0.516x,其中 x 為父母平均身高,? 為預測的子女身高。這一方程表明父母身高每增加一個單位,其成年子女身高平均增加約 0.516 個單位,體現了 “趨中回歸” 的現象。
但需要注意的是,隨著研究的發展,“回歸” 一詞在現代統計學中的含義已經與原始含義不同。現代回歸分析主要關注建立自變量 x 和因變量 y 之間的關系模型,即:研究因變量與自變量之間的統計關系。而不再局限于高爾頓發現的 “趨中” 現象。
更具體而言,現代回歸模型主要用于解決以下問題:
- 變量關系建模:量化自變量 x 與因變量 y 之間的關系強度與方向。例如:研究廣告投入與銷售額之間的關系。
- 預測未來數值:基于已知的數據集 x 和 y 求解總體參數 βi 和隨機誤差 ?,繼而建立其回歸模型(公式),用于預測未來的數值 ?。例如:預測房價、股票價格或疾病風險。
- 分類問題處理:雖然回歸模型主要用于連續值的預測,但通過邏輯回歸等變體,回歸模型也能有效解決分類問題。
回歸模型的經典方程為:Y=f(X)+?
- Y:因變量
- X:自變量
- f(X):回歸函數,如:
- 線性回歸函數:一元線性回歸模型 Y=β0+β1X 。
- 非線性回歸函數:多項式回歸模型 Y=β0+β1X+β2X^2
- 邏輯回歸函數:如 Sigmoid 函數,用于分類問題。
- ?:隨機誤差
總而言之,回歸分析特別適用于需要量化關系、精確預測和分類問題的場景,它通過數學形式明確表達了變量間的關聯,比上文中提到的相關分析能提供更多信息。
一元線性回歸模型
一元線性回歸(Simple Linear Regression Model)用于線性關系預測場景。
數據模型為:
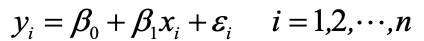
- y:因變量(被預測變量)
- x:自變量(預測變量)
- β0:截距(Y 軸交點)
- β1:斜率(X 每變化 1 單位,Y 的變化量)
- ?:隨機誤差(無法由 X 解釋的波動)
在一元線性回歸模型的實際應用中,首先需要提供 n 個 (x, y) 的樣本數據集,用于反解/估計出模型參數 β0、β1 的估計量 b0、b1,繼而得到預測函數。
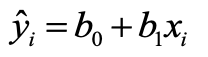
如上圖,稱為 “一元回歸線”。然后,基于一元回歸線,對于 n 個新的輸入數據 x,可以求解出對應的 ?,即:y 的擬合值(預測值)。
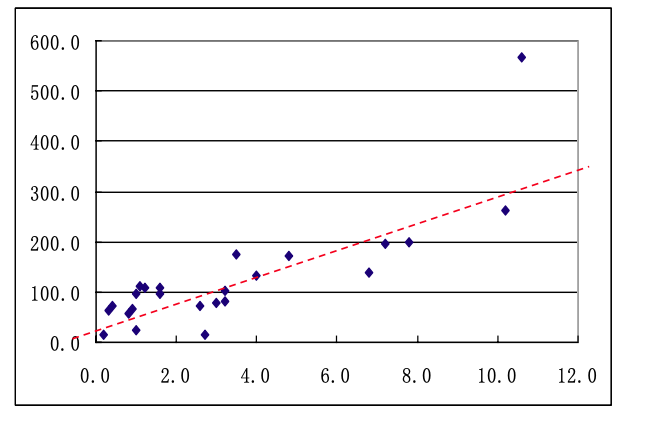
應用最小二乘法來調整模型參數精度
上文中,一元回歸線函數可以用于預測,但預測的準確度應該如何量化和調整呢?即:模型參數 β0、β1 的估計量 b0、b1 的精度到底是好是壞?這里面顯然還需要補充一種 “反饋調整模型參數” 的機制。
最小二乘法(Least Squares Method)就是一種結合了 “預測和反饋調整” 的回歸模型,其通過 “最小化殘差平方和” 來尋找數據的最佳函數匹配。它在回歸分析、曲線擬合、參數估計等領域有廣泛應用。
簡而言之,最小二乘法的核心思想是最小化 “觀測值”與 “模型預測值” 之間的殘差平方和,以此來 “自動反饋調整” 預測模型的參數。在一元回歸線函數的基礎上,在得到擬合值 ? 之后,再與觀測值 y 計算出殘差值。進一步的對于 n 個 (x, y) 的數據集,就可以計算出殘差平方和。
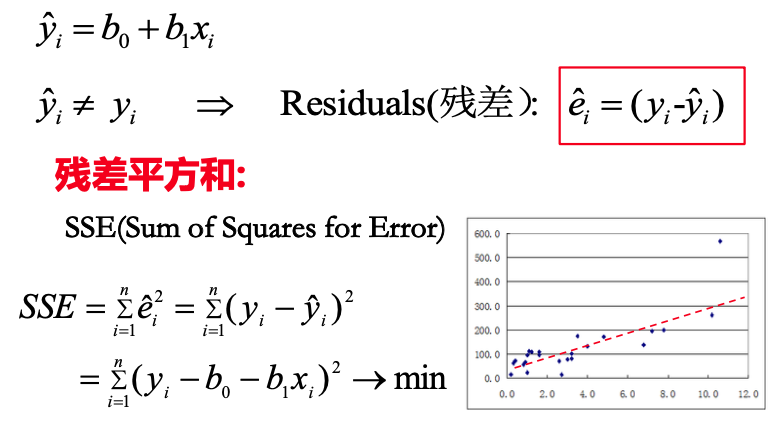
理解 “殘差平方和” 的幾何意義可以類比 “方差”,即:以預測值為中心,測量所有觀測值與預測值的偏離程度,當 SSE 趨于 min 時,一元回歸線的模型參數越精確。最小二乘法通過最小化平方殘差提供了一種直觀且高效的參數估計方法,但其效果依賴于模型假設和數據質量。
如何評價回歸模型的正確性?
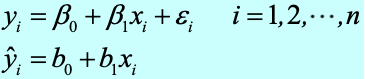
最后,我們還需要解決一個問題,即:如何評價一個線性回歸模型的正確性呢?這包含了 3 個層面:
- 該模型能否較好地解釋 yi 的取值變化規律?
- x 與 y 是線性關系嗎?
- x 在解釋 y 時是一個有用的自變量嗎?
對應的也有 3 種模型評估方法:
-
R^2 擬合優度判定系數(Coefficient of Determination):公式如下,分子是殘差平方和,分母是方差。

-
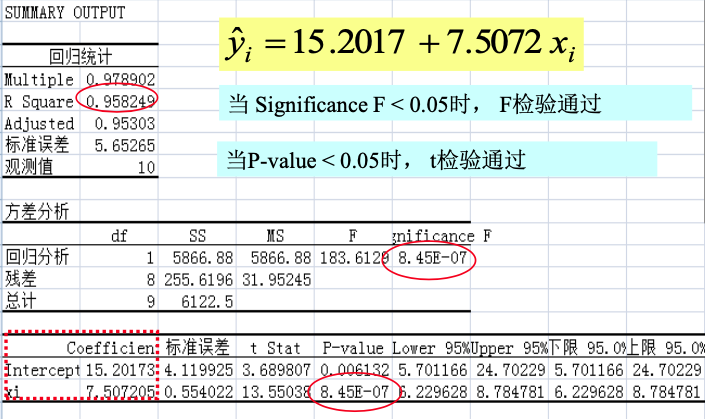
F-test:檢驗回歸模型的線性關系。當 Significance F < 0.05 時, F-test 通過,X 和 Y 之間存在線性關系。
-
t-test:回歸系數的顯著性檢驗。當 P-value < 0.05 時, t-test 通過,X 對 Y 有解析作用。
實際上,在實際應用中,R^2、F-test、t-test 的計算都可以交由現代計算軟件完成,如下圖所示。我們只需要關注結果繼而判斷模型質量即可。
多元線性回歸模型
多元線性回歸模型,顧名思義,相較于一元線性回歸模型,擁有多個因變量 Xj,及其對應的模型參數 β0、β1、… 、βk,如下圖。
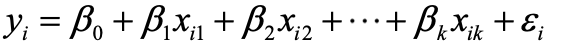
同樣的,可以采用最小二乘法來求解模型參數,構建多元線性回歸模型,如下圖。

也同樣的,可以采用 R^2、F-test、t-test 來評價多元線性回歸模型的質量好還。
避免過度擬合問題
過度擬合(Overfitting)指回歸模型在觀測數據(訓練樣本)上表現優異,例如:R^2 評分特別的高。然而該回歸模型在新數據(真實場景數據)上卻表現出了精度顯著下降的現象,即:泛化能力差(指回歸模型對新數據的預測能力)。
如下圖所示,圖(1)的精度不夠,圖(3)過度擬合了,而圖(2)則是剛好(具有普遍泛化預測能力)。
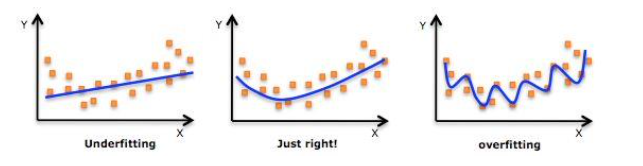
出現過度擬合問題的常見原因有 3 大類型:
- 數據層面:訓練樣本數量不足,導致模型無法學習到普遍規律。
- 模型層面:模型的參數太多,模型復雜度過高。
- 特征層面:訓練樣本噪音(異常點)干擾過大,模型誤將噪音認為是特征,從而擾亂了模型參數。
對應的也有以下常規解決思路:
- 增加數據量。
- 簡化模型。
- 清洗噪音數據。
此外還需要一系列的檢測方法來識別過度擬合問題:
- 交叉驗證法
- 留一交叉驗證法
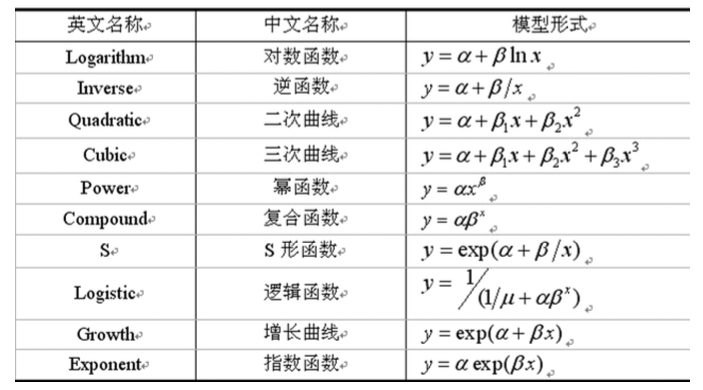
擬線性回歸建模方法
上述我們討論的一元線性回歸模型、多元線性回歸模型都是線性相關場景的模型建模。但實際生活中還存在大量的非線性相關場景,例如:多項式模型、指數模型等。此時可以采用擬線性回歸方法,即:將非線性關系線性化,然后再運用線性模型。如下圖所示,將一個 “多項式模型” 轉換為了一個 “多元線性模式”。

常用的擬線性回歸模型如下表所示。

:矩陣距離)






:基于MaskNet和WideDeep的商品推薦CTR模型實現)
)





將一個矩陣(或圖像)與一個標量值相加的函數addC())



