
文章目錄
- Abstract
- Introduction
- Related Work
- 2D object detection
- 3D object detection from LiDAR
- 3D object detection from images
- Integral images
- 3D Object Detection Architecture
- Feature extraction
- Orthographic feature transform
- Fast average pooling with integral images
- Topdown network
- Con?dence map prediction
- Localization and bounding box estimation
- Non-maximum suppression
- Conclusions
paper
Abstract
事實證明,從單眼圖像中檢測3D物體是一項極具挑戰性的任務,目前領先的系統的性能甚至還達不到基于激光雷達的同類系統的10%。對這種性能差距的一種解釋是,現有的系統完全受基于透視圖像的表示的支配,其中物體的外觀和規模隨著深度和有意義的距離而急劇變化,很難推斷。在這項工作中,我們認為對3D世界進行推理的能力是3D物體檢測任務的基本要素。為此**,我們引入了正交特征變換,它使我們能夠通過將基于圖像的特征映射到正交三維空間來逃避圖像域**。這使我們能夠在一個尺度一致且物體之間的距離有意義的領域中,對場景的空間配置進行整體推理。我們將這種轉換作為端到端深度學習架構的一部分,并在KITTI 3D對象基準上實現了最先進的性能。
Introduction
任何自主智能體的成功都取決于其檢測和定位周圍環境中物體的能力。預測、避免和路徑規劃都依賴于對場景中其他實體的3D位置和尺寸的穩健估計。這使得3D邊界盒檢測成為計算機視覺和機器人技術中的一個重要問題,特別是在自動駕駛的背景下。迄今為止,三維目標探測的方法主要是利用豐富的LiDAR點云[37,33,15,27,5,6,22,1],而缺乏LiDAR絕對深度信息的純圖像方法的性能明顯落后。考慮到現有激光雷達設備的高成本、遠距離激光雷達點云的稀疏性以及對傳感器冗余的需求,從單眼圖像中精確檢測3D目標仍然是一個重要的研究目標。
為此,我們提出了一種新的3D目標檢測算法,該算法以單眼RGB圖像作為輸入,產生高質量的3D邊界框,在具有挑戰性的KITTI基準[8]上實現了單眼方法中最先進的性能。
在許多意義上,圖像是一種極具挑戰性的形式。透視投影意味著單個物體的比例隨著與相機的距離而變化很大;它的外觀可以根據不同的視角發生巨大變化;而且3D世界中的距離無法直接推斷。這些因素對單目三維目標檢測系統提出了巨大的挑戰。一種更加無害的表示是許多基于激光雷達的方法中常用的正射影鳥瞰圖[37,33,1]。在這種表示下,尺度是均勻的;外表在很大程度上與觀點無關;物體之間的距離是有意義的。因此,我們所看到的關鍵是,盡可能多的推理應該在這個正字法空間中進行,而不是直接在基于像素的圖像域上進行。這一點對我們所提出的系統的成功至關重要。然而,目前尚不清楚如何僅從單目圖像構建這樣的表示。因此,我們引入了正交特征變換(OFT):一種將從透視RGB圖像中提取的一組特征映射到正交鳥瞰特征映射的可微分變換。至關重要的是,我們不依賴任何明確的深度概念:相反,我們的系統建立了一個內部表示,能夠確定圖像中的哪些特征與鳥瞰圖上的每個位置相關。我們應用深度卷積神經網絡,即自頂向下網絡,來局部推理場景的三維結構。我們的主要工作貢獻如下:1。我們引入了正交特征變換(OFT),它將基于透視圖像的特征映射為正交鳥瞰圖,利用積分圖像高效地實現快速平均池化。2. 我們描述了一種用于從單目RGB圖像預測3D邊界框的深度學習架構。3. 我們強調了在3D中對目標檢測任務進行推理的重要性。
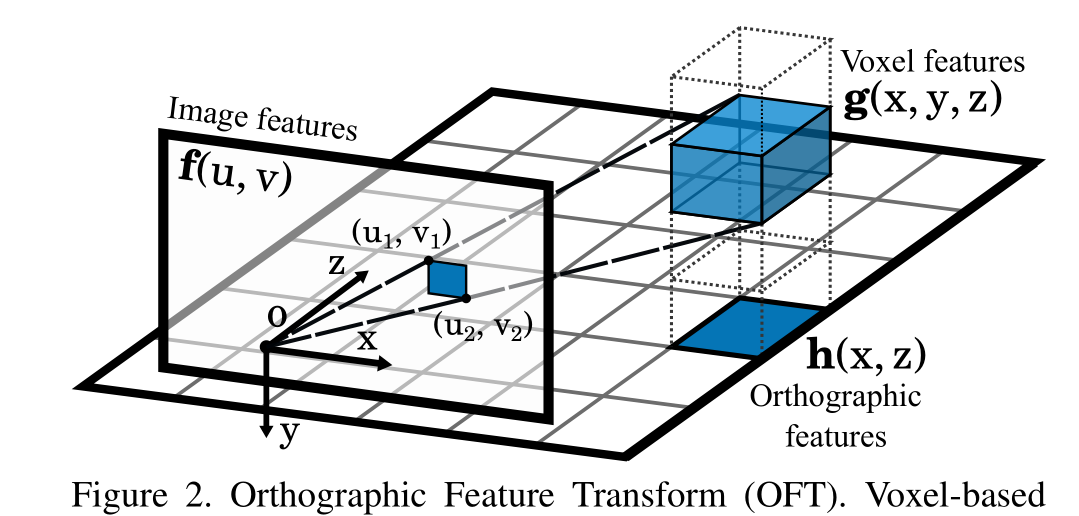
正交特征變換(OFT)。基于體素的特征g(x, y, z)是通過在投影體素區域上累積基于圖像的特征f(u, v)而生成的。體素特征沿著垂直方向折疊,得到平面特征h(x, z)。
Related Work
2D object detection
檢測圖像中的2D邊界框是一個被廣泛研究的問題,最近的方法即使在最強大的數據集上也能表現出色[30,7,19]。現有方法大致可分為兩大類:直接預測目標綁定盒的單級檢測器如YOLO[28]、SSD[20]和RetinaNet[18],以及增加中間區域提議階段的兩級檢測器如Faster R- CNN[29]和FPN[17]。迄今為止,絕大多數3D物體檢測方法都采用了后一種方法,部分原因是難以從3D空間中固定大小的區域映射到圖像空間中可變大小的區域。我們通過OFT變換克服了這一限制,使我們能夠利用單級架構的速度和精度優勢。
3D object detection from LiDAR
三維目標檢測對于自動駕駛具有重要意義,目前已經提出了大量基于激光雷達的檢測方法,并取得了相當大的成功。大多數變化源于激光雷達點云的編碼方式。Qi et al.[27]的挫敗點網絡和Du et al.[6]的工作直接對點云本身進行操作,考慮了位于圖像上由2D邊界框定義的挫敗范圍內的點子集。Minemura等人[22]和Li等人[16]將點云投影到圖像平面上,并對生成的RGB-D圖像應用faster - rcnn風格的架構。其他方法,如TopNet[33]、BirdNet[1]和Yu et al.[37],將點云離散成一些鳥瞰圖(BEV)表示,該表示編碼諸如返回強度或地平面以上點的平均高度等特征。這種表示非常有吸引力,因為它沒有展示任何在RGB-D圖像中引入的透視偽影,例如,我們工作的主要重點是在那里,因此開發一個隱式的圖像模擬這些鳥瞰圖。另一個有趣的研究方向是傳感器融合方法,如AVOD[15]和MV3D[5],它們利用地平面上的3D物體建議來聚合基于圖像和鳥瞰的特征:這一操作與我們的正射影特征變換密切相關。
3D object detection from images
同時,由于缺乏絕對深度信息,從圖像中獲取三維邊界框是一個非常具有挑戰性的問題。許多方法從使用上述標準檢測器提取的2D綁定框開始,在此基礎上,它們要么直接回歸每個區域的3D姿態參數[14,26,24,23],要么將3D模板擬合到圖像中[2,35,36,38]。也許與我們的工作最密切相關的是Mono3D[3],它通過3D邊界框提案密集地跨越3D空間,然后使用各種基于圖像的特征對每個提案進行評分。其他探索世界空間中密集3D方案的作品有3DOP[4]和Pham and Jeon[25],它們依賴于使用立體幾何對深度的明確估計。上述所有工作的一個主要限制是每個區域建議或邊界框都是獨立處理的,排除了關于場景3D配置的任何聯合推理。我們的方法執行與[3]相似的特征聚合步驟,但在保留其空間配置的同時,對結果建議應用二次卷積網絡。
Integral images
自從Viola和Jones b[32]的開創性工作引入積分圖像以來,積分圖像已經從根本上與目標檢測聯系在一起。它們已成為許多當代三維目標檢測方法的重要組成部分,包括AVOD[15]、MV3D[5]、Mono3D[3]和3DOP[4]。然而,在所有這些情況下,積分圖像不會反向傳播梯度或構成完全端到端深度學習架構的一部分。據我們所知,之前唯一這樣做的工作是Kasagi等人的[13],他們結合了卷積層和平均池化層來降低計算成本。
3D Object Detection Architecture

體系結構概述。前端ResNet特征提取器生成基于圖像的特征,這些特征通過我們提出的正字法特征變換映射到正字法表示。自上而下的網絡在鳥瞰空間中處理這些特征,并在地平面上的每個位置預測置信度評分S、位置偏移量?pos、尺寸偏移量?dim和角度矢量?ang。
系統的概述如圖3所示。該算法主要由五個部分組成:1。前端ResNet[10]特征提取器,從輸入圖像中提取多尺度特征映射。2. 非正射影特征變換,將每個尺度的基于圖像的特征映射轉換為正射影鳥瞰圖表示。3. 一個自上而下的網絡,由一系列ResNet殘差單元組成,以一種與圖像中觀察到的視角效果不變的方式處理鳥瞰特征圖。4. 一組輸出頭,它為每個對象類和地平面上的每個位置生成置信度評分、位置偏移、尺寸偏移和方向矢量。5. 非最大抑制和解碼階段,識別置信圖中的峰值并生成離散邊界框預測。
Feature extraction
我們架構的第一個元素是一個卷積特征提取器,它從原始輸入圖像中生成多尺度二維特征映射的層次結構。這些特征編碼圖像中低層結構的信息,這些信息構成了自頂向下網絡用來構建場景隱式3D表示的基本組件。前端網絡還負責根據圖像特征的大小推斷環深度信息,因為該架構的后續階段旨在消除按比例變化。
Orthographic feature transform
為了在沒有透視效果的情況下推斷3D世界,我們必須首先將從圖像空間中提取的特征映射應用到世界空間中的正交特征映射,我們稱之為正交特征變換(OFT)。OFT的目標是用前端特征提取器提取的基于圖像的特征映射f(u, v)∈Rn中的相關n維特征填充3D體素特征映射g(x, y, z)∈Rn。體素圖是在一個均勻間隔的三維晶格G上定義的,該晶格固定在相機下方距離為y0的地平面上,尺寸為W, H, D,體素大小為r。對于給定的體素網格位置(x, y, z)∈G,我們通過在圖像特征圖f的面積上積累特征來獲得體素特征G (x, y, z),該圖像特征圖f對應于體素的2D投影。一般來說,每個體素都是一個大小為r的立方體,在圖像平面上投射到六邊形區域。我們用一個矩形邊界框來近似它的左上角和右下角分別是(u1,v1)和(u2,v2)它們由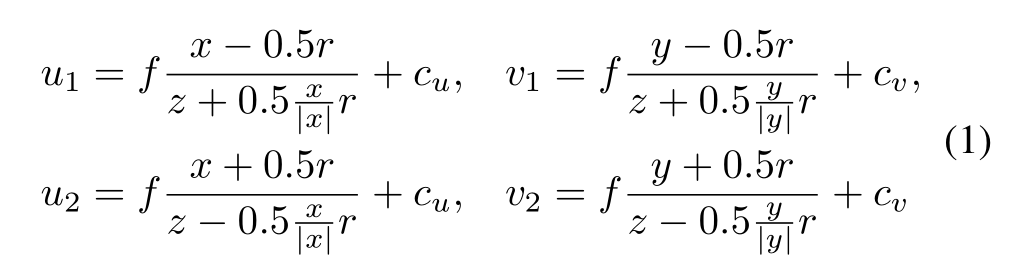
式中f為相機焦距,(cu,cv)為原理點。
然后,我們可以通過對圖像特征圖f中投影體素的邊界框進行平均池化,將特征分配到體素特征圖g中的適當位置: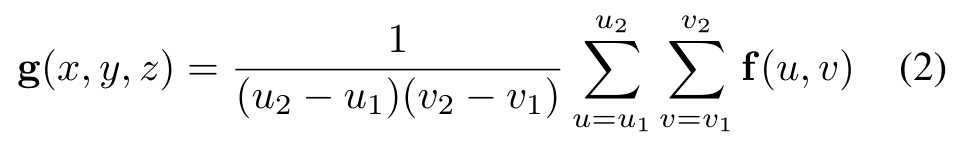
所得到的體素特征圖g已經提供了一個場景的表示,它不受每個視角投影的影響。然而,在大體素網格上運行的深度神經網絡通常是非常占用內存的。鑒于我們感興趣的主要是美聯社——皺紋如自主駕駛大多數對象固定在2 d地平面,我們可以通過崩潰使問題更容易處理3 d立體像素特征映射到一個第三,二維表示我們詞拼寫功能映射h (x, z),地圖正字法的特性是通過總結體素特征沿縱軸與一組學習乘法后體重矩陣W (y)∈Rn×n:

在轉換成最終的正射影特征圖之前轉換成中間體素表示的優點是保留了場景的垂直結構信息。這被證明是必不可少的下游任務,如估計高度和垂直位置的對象邊界框。
Fast average pooling with integral images
上述方法的一個主要挑戰是需要在非常多的區域上聚合特征。例如,一個典型的體素網格設置產生大約150k個邊界框,這遠遠超過了Faster R-CNN[29]架構使用的~ 2k個感興趣的區域。為了方便在如此大量的區域上進行池化,我們使用了基于積分圖像[32]的快速平均池化操作。一個積分圖像,或者在這種情況下,積分特征映射F,是使用遞歸關系從一個輸入特征映射F構造出來的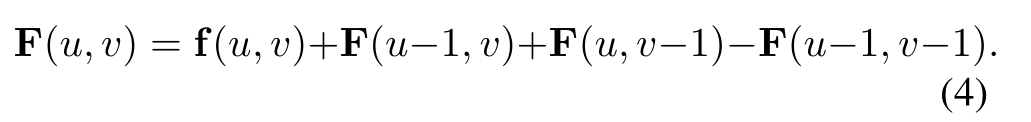
給定積分特征映射F,由邊界框坐標(u1,v1)和(u2,v2)定義的區域(見式1)對應的輸出特征g(x, y, z)為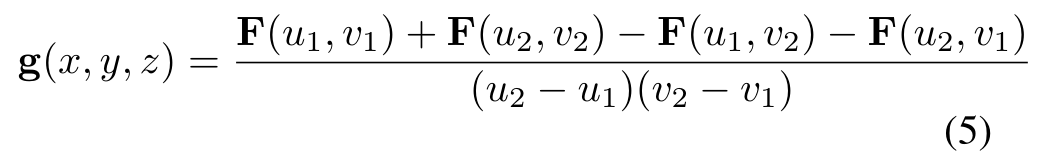
這種池化操作的復雜性與單個區域的大小無關,這使得它非常適合我們的應用程序,在我們的應用程序中,區域的大小和形狀取決于體素是離相機近還是遠。它在原始特征圖f方面也是完全可區分的,因此可以用作端到端深度學習框架的一部分。
Topdown network
這項工作的一個重要貢獻是強調了三維推理對復雜三維場景中物體識別和檢測的重要性。在我們的體系結構中,這個重構組件是由一個子網絡執行的,我們稱之為自頂向下網絡。這是一個簡單的卷積網絡,具有resnet風格的跳過連接,它在前面描述的OFT階段生成的2D特征圖h上運行。由于自頂向下網絡的濾波器是卷積的,所以所有的處理對特征在地平面上的位置是不變的。這意味著,距離相機較遠的特征圖與距離較近的特征圖得到完全相同的處理,盡管對應的圖像區域要小得多。我們的目標是,最終的特征表示將因此捕獲純粹關于場景的底層3D結構的信息,而不是它的2D投影。
Con?dence map prediction
在2D和3D方法中,檢測通常被視為分類問題,使用交叉熵損失來識別圖像中包含物體的區域。然而,在我們的應用中,我們發現采用Huang等人的置信圖回歸方法更為有效。置信圖S(x, z)是一個平滑函數,它表示存在以位置(x, y0,z)為中心的有邊界框的物體的概率,其中y0是相機到地平面的距離。給定一組N個具有邊界框中心的基礎真值對象pi = 【xi yi zi】T,i =1,…, N,我們將地面真值置信映射計算為每個目標中心周圍寬度為σ的光滑高斯區域。位置(x, z)的置信度由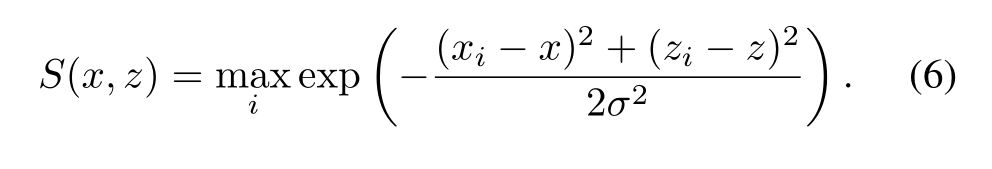
我們的網絡的置信度圖預測頭是通過1損失來訓練的,以回歸到正字法網格h上每個位置的地面真實置信度。一個有充分記錄的挑戰是,正(高置信度)位置比負位置少得多,這導致損失的負分量主導優化[31,18]。為了克服這個問題,我們將對應于負位置(我們將其定義為S(x, z) < 0.05的位置)的損失按10 × 2的常數系數進行縮放。
Localization and bounding box estimation
置信圖S將每個對象位置的粗略近似值編碼為置信分數中的峰值,從而給出精確到特征圖分辨率r的位置估計。為了更精確地定位每個目標,我們附加了一個額外的網絡輸出頭,它預測從地平面(x, y0,z)上的網格單元位置到相應地真目標pi中心的相對偏移量?pos: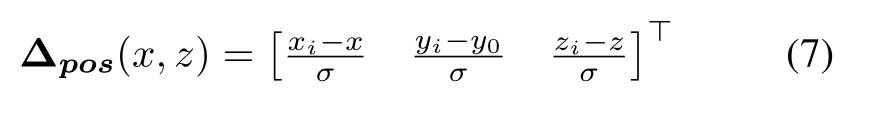
我們使用與3.4節中描述的相同的比例因子σ將位置偏移歸一化到一個合理的范圍內。如果對象的邊界框的任何部分與給定的網格單元相交,則將ground truth對象實例i分配給網格位置(x, z)。不與任何地面真值對象相交的單元在訓練期間被忽略。除了定位每個對象之外,我們還必須確定每個邊界框的大小和方向。因此,我們引入兩個進一步的網絡輸出。第一個是維頭,它預測具有維數di = 【wi hi li】的指定地面真值對象i之間的對數尺度偏移量?dim。平均維數dˉ= [wˉ hˉ l]遍歷給定類的所有對象。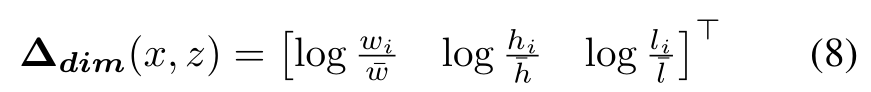
第二個,方向頭,預測物體方向θi關于y軸的正弦和余弦:

請注意,由于我們是在正射影鳥瞰空間中操作,因此我們能夠直接預測y軸方向θ,而不像其他作品(例如[23])預測所謂的觀察角度α,以考慮透視和相對視點的影響。位置偏移量?pos,尺寸偏移量?dim和方向矢量?ang使用1損失進行訓練。
Non-maximum suppression
與其他目標檢測算法類似,我們采用非最大抑制(NMS)階段來獲得最終的離散目標預測集。在傳統的目標檢測設置中,這一步可能是昂貴的,因為它需要O(N2)個邊界框重疊計算。這是復合的事實,成對的三維盒子不一定是軸對齊的,這使得重疊的計算比2D的情況下更加困難。幸運的是,使用置信圖代替錨盒分類的另一個好處是,我們可以在更傳統的圖像處理意義上應用NMS,即在二維置信圖S上搜索局部最大值。在這里,正射影鳥瞰圖再次被證明是無價的:在3D世界中,兩個物體不可能占據相同的體積,這意味著置信度圖上的峰值是自然分離的。為了減輕預測中噪聲的影響,我們首先采用寬度為σNMS的高斯核平滑置信映射。如果S (xi,zi)≥S (xi +m, zi +n)?m, n∈{-1,0,1}。(10)在產生的峰值位置中,任何置信度S(xi,yi)小于給定閾值t的位置都被消除。這將產生最終的預測對象實例集,其邊界框中心pi、維度di和方向θi分別由公式7、8和9中的關系反轉給出。
Conclusions
在這項工作中,我們提出了一種新的單眼3D物體檢測方法,基于直覺,在鳥瞰域中操作可以減輕圖像中許多不理想的屬性,這些屬性使得難以提供世界的3D配置。我們提出了一種簡單的正射影特征轉換方法,將基于圖像的特征轉換為鳥瞰圖,并描述了如何利用積分圖像有效地實現它。然后將其納入深度學習管道的一部分,其中我們特別強調了以深度2D卷積網絡形式應用于提取的鳥瞰圖特征的空間推理的重要性。最后,我們通過實驗驗證了我們的假設,即在自上而下的空間中推理確實取得了更好的結果,并在KITTI 3D對象基準上展示了最先進的性能。




將一個矩陣(或圖像)與一個標量值相加的函數addC())





MySQL 分庫分表:應對數據增長挑戰的有效策略)
簡介及其價值觀與最佳實踐)

)





