一、系統架構
整個系統包含了私有云和公有云兩個節點。前端和服務端存在私有云和公有云兩套系統交互,公有云上的系統為三方黑盒系統。
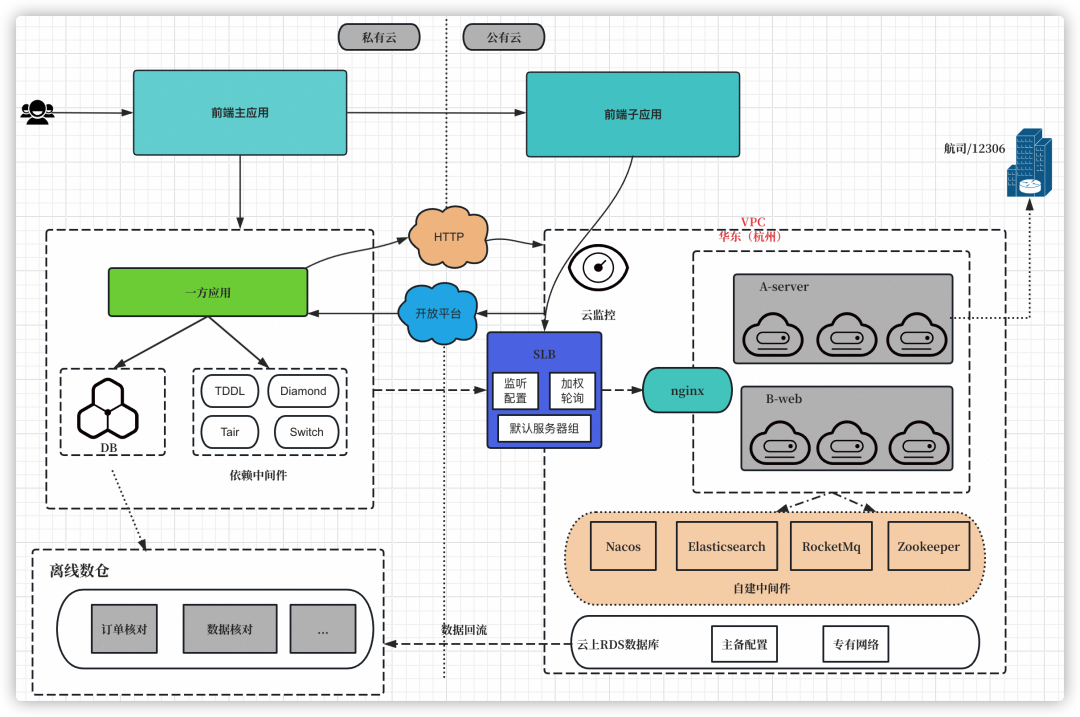
帶著上面的五點風險和挑戰,我們從前后端的視角整體制定優化策略和方案。
二、前端策略
作為釘釘的合作產品,必然也是需要保障釘釘的體驗的,這就涉及到如何將三方前端子頁面進行一方化了,我們考慮了以下幾套方案。
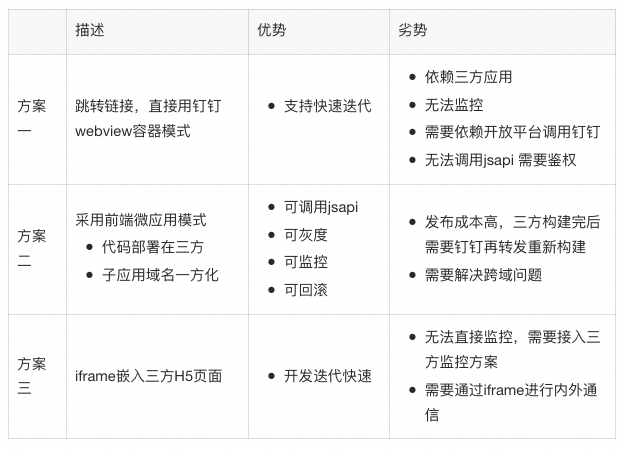
基于穩定性優先的原則,為了能夠使得三方預訂頁面具備可監控、可灰度、可回滾的能力,我們采用方案二:前端微應用的方式進行接入。
2.1?微前端架構
在微前端的架構下,我們將三方前端子應用的打包資源地址配置到釘釘合作域名應用下,當用戶訪問n.dingtalk的域名鏈接時就會走到云上系統,進而訪問三方前端打包資源,這樣的話預訂子應用就具備了一方應用的基礎能力。

2.2?微前端效果
-
域名統一化:可以通過DBase平臺進行灰度放量,保障可灰度、可回滾的基礎能力。
-
隔離性:三方H5頁面資源部署在公有云的獨立環境中運行,避免其CSS或JS影響到主應用。
-
異常監控:接入Arms監控,建立異常監控機制,可以快速定位和解決接入過程中可能出現的問題,進而實現前端頁面的error監控。
-
版本控制:第三方H5的更新應與主應用保持良好的版本控制,避免因版本不一致帶來的問題,通過版本化的構建也可以更好的做到回滾管控。
-
Jsapi調用:域名統一化后,可以使得三方預訂子頁面絲滑調用釘釘的Jsapi。
三、服務端策略
穩定性的容量預估也是遵循木桶理論的,構成整個系統的各個模塊都有各自的系統吞吐量,而系統最低的那塊木板,很可能就是整個系統的最終吞吐量。我們需要基于線上事件來真實評估最薄弱的一環,通過各模塊各節點的完整評估,我們決定從四個方向(發布前管控、發布中可用、發布后保障、機制&人員保障)挑選最重要的TOP事項快速落地,進而快速提升整個系統的穩定性。
| 節點 | 事項 |
| 發布前管控 |
|
| 發布中可用 |
|
| 發布后保障 |
|
| 機制&人員保障 |
|
3.1?發布前管控
3.1.1?部署方案
我們采用公有云上的CI/CD能力,通過云效平臺搭建了一套構建部署的解決方案。
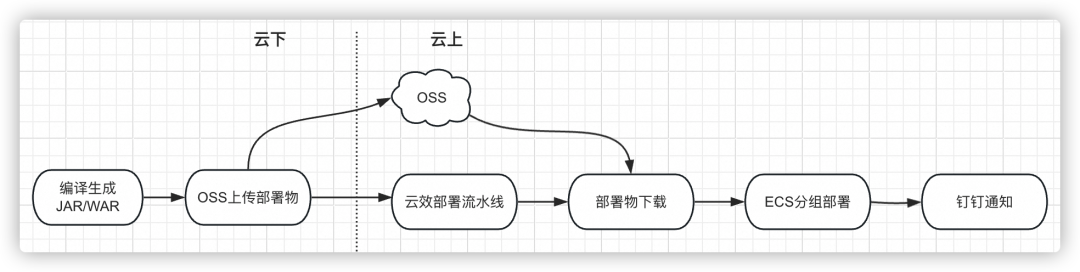
-
創建存儲Bucket:創建一個OSS bucket用來存儲部署物。
-
上傳部署物:將本地構建出的部署物(比如jar包、war包等)上傳到指定的OSS bucket,構建出的部署物文件名稱盡可能體現出部署物版本(比如加上版本號、代碼分支信息、commit id等)。
-
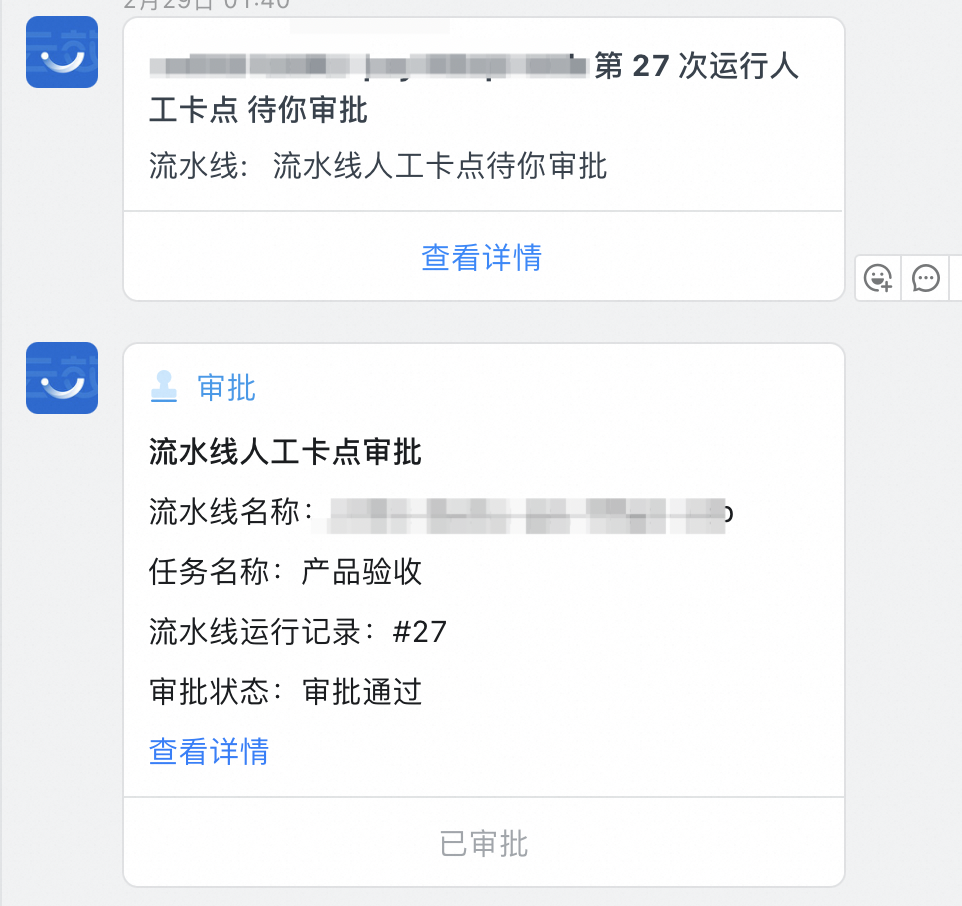
部署流水線:設定發布審批人,可以選擇或簽、會簽。整個審批環節包含,測試、產品、主管三個審批節點,保障發布環節可控流程化。
-
部署物下載:在云效里創建一條發布流水線,將源代碼編譯的環節替換為從OSS下載構建部署物(JAR、WAR等)。
-
ECS分組部署:可以在ECS分組部署階段添加部署腳本、分組、部署方式等信息。
-
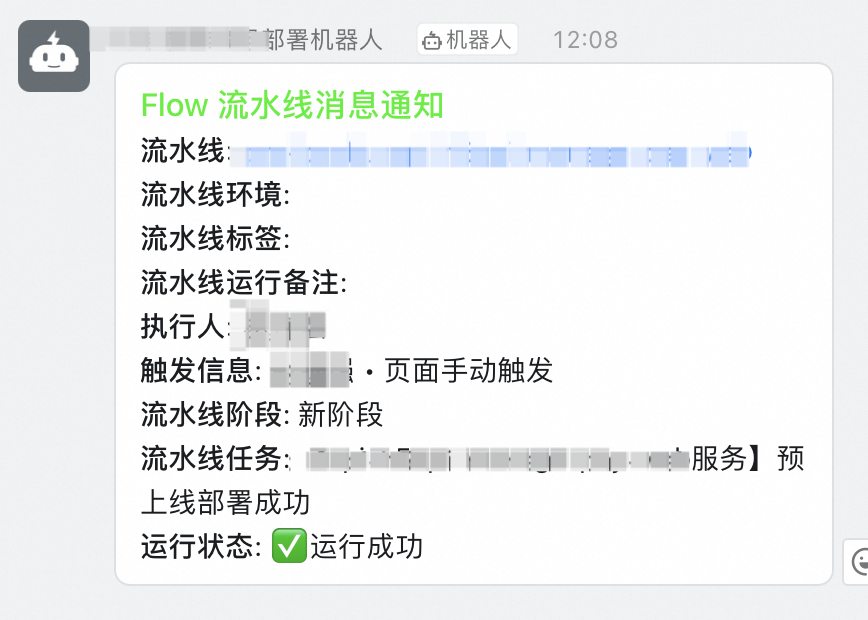
釘釘部署通知:部署完成后通過調用云效流水線的web hook自動觸發部署結果通知。
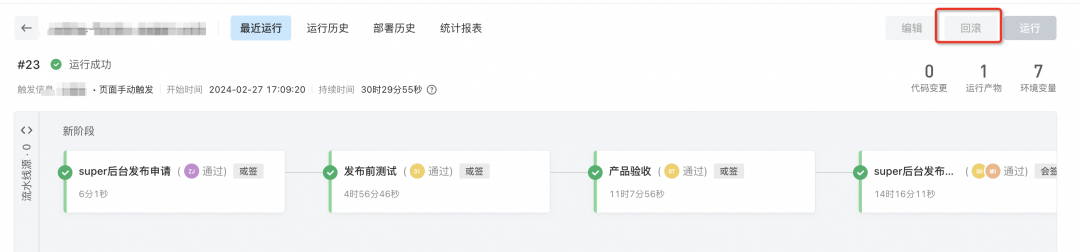
3.1.2?關鍵節點
通過云效的流水線能力,將整個系統的發布在線化,關鍵KP審核,將發布流程強管控,杜絕隨意變更引起的穩定性問題。
| 權限隔離
| KP審批
| 流水線部署
|
|
|
|
|
3.2?發布中可用
云上系統存在發布過程中的不可用問題,比如系統在發布過程中,會導致用戶以及服務商的系統頁面不可用,是最為急迫解決的問題。
| 服務商視角 | 客戶視角 |
|
|
|
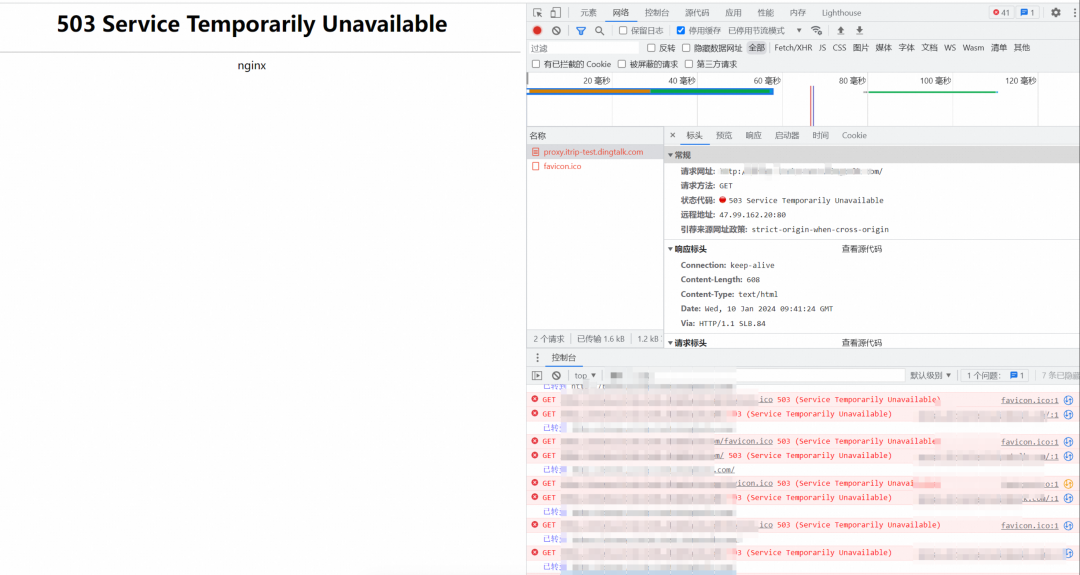
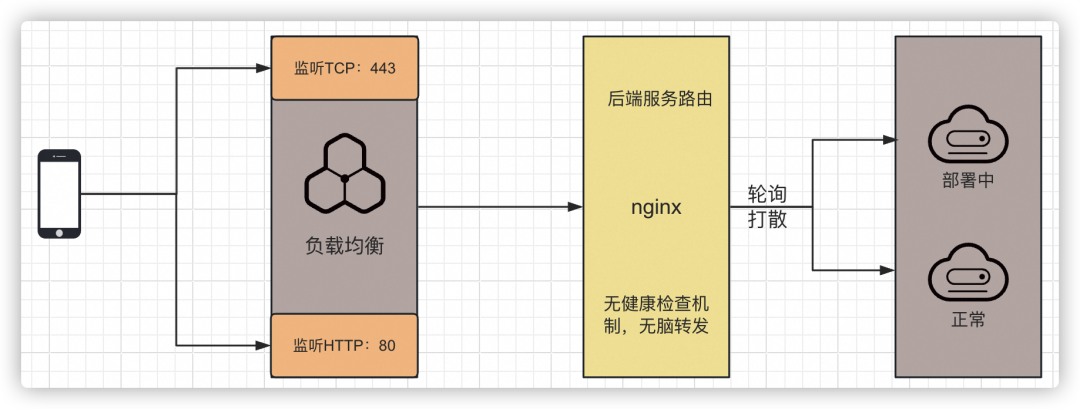
目前的部署階段不可用問題是由于nginx不具備高可用能力引起的,云上系統的后端服務器是采用輪詢方式來進行通信的,在發布階段由于輪詢到部署機器導致系統異常。所以根本原因在于nginx不具備健康檢查的能力,導致系統發布階段的不可用問題。
server {location / {proxy_set_header Host $host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_set_header X-Forwarded-Proto $scheme;proxy_pass http://proxy-pro; // `proxy_pass` 用于指定一個反向代理的后端服務器}}// 對于location指定的后端服務器配置,nginx的默認配置,默認為輪詢通信。upstream api-pro{server xxx.xx.xx.x:001;}
3.2.1?解決方案
在看清楚問題背后的原因后,理論上是有以下兩種解決方案的。

基于擴展性及系統高可用的考慮,決定采用方案二。
3.2.2?關鍵節點
步驟一:SLB轉發
首先需要做SLB層的域名路由轉發,需要調整SLB層的監聽配置:
| Before | After |
|
|
|
|
|
|


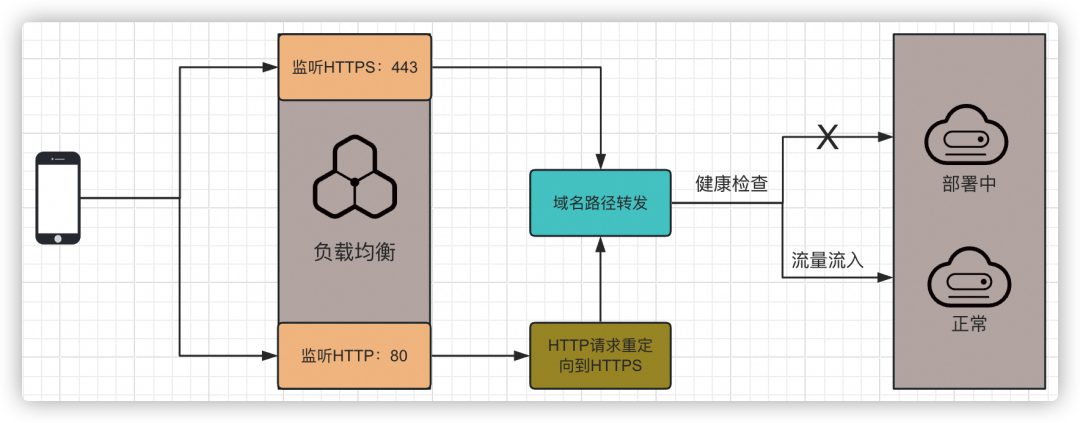
After:HTTP請求之所以強制轉發到HTTPS,原因是期望用戶側的訪問都通過HTTPS的方式進行訪問,安全性更高一些。
基于SLB的轉發策略,對于云上系統進行分發配置,如下:
| 域名 | 路徑 | 端口 | 服務器 |
| A-test.com | / | 10201 | 192.168.1.1 |
| B-test.com | / | 10204 | 192.168.1.2 |
| C-test.com | / | 10202 | 192.168.1.3 |
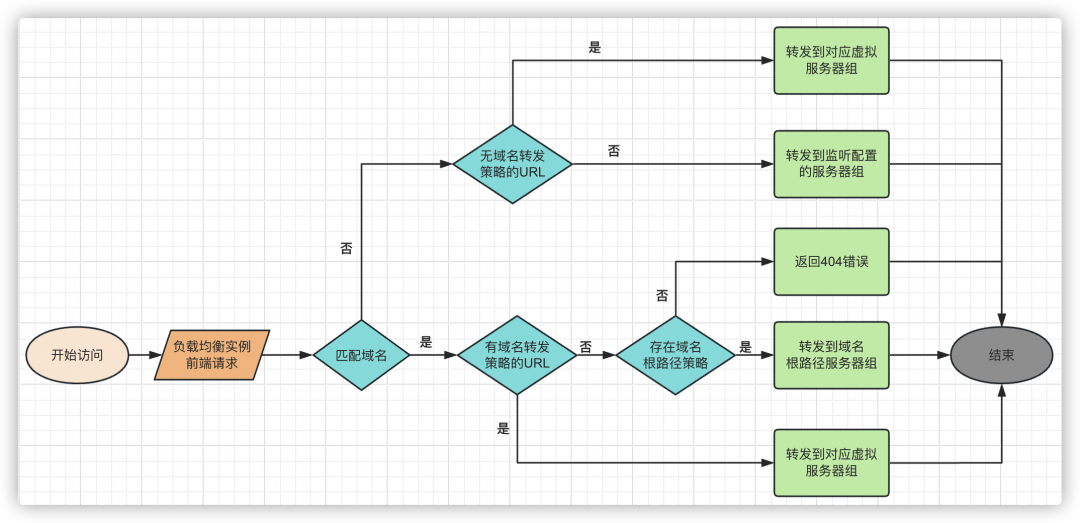
域名路徑轉發邏輯,如下圖所示:
-
方式一:前端請求中存在域名,則根據域名匹配轉發策略。
-
存在匹配該域名的轉發策略,則繼續匹配URL路徑部分。若URL路徑部分也能匹配,則將請求轉發至對應的虛擬服務器組;若URL路徑部分未能命中該域名下的任何規則,則將請求轉發給域名根路徑轉發策略(轉發策略中只配置了域名,沒有配置URL路徑)。
當用戶沒有為該域名配置根路徑轉發策略時,將向客戶端返回404錯誤。
-
不存在匹配該域名的轉發策略,則按照方式二匹配轉發策略。
-
方式二:前端請求中不存在域名或者轉發策略中不存在與之相匹配的域名,則直接匹配無域名轉發策略(轉發策略中只配置了URL,沒有配置域名)。
-
成功匹配到轉發策略時,將請求轉發至對應的虛擬服務器組;未能匹配到任何轉發策略時,將請求轉發至此監聽配置的服務器組。
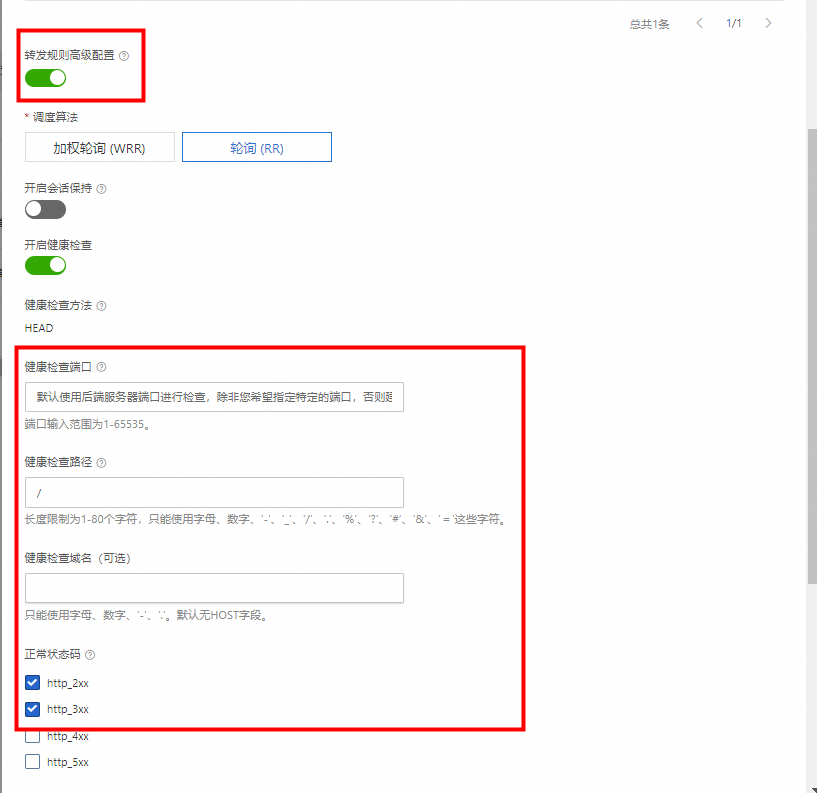
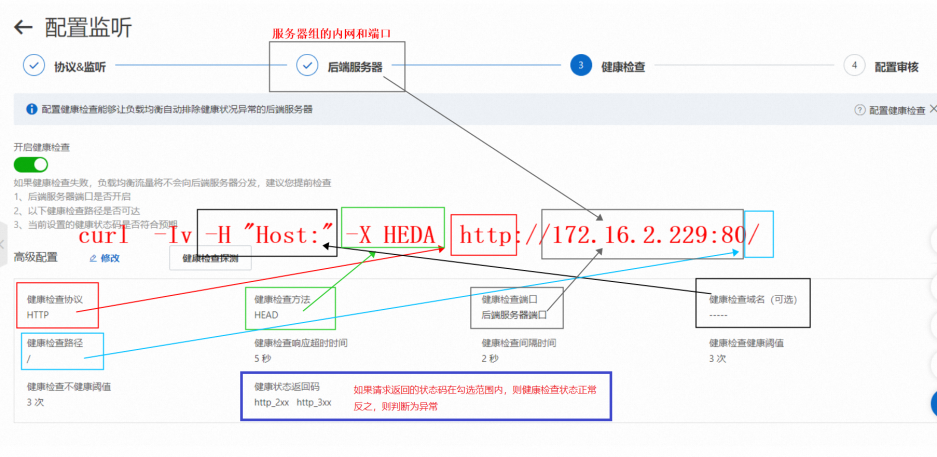
步驟二:健康檢查
目前SLB轉發為后端服務器后,可以配置健康檢查策略,如下:
| 健康檢查配置
| 健康檢查方式
|

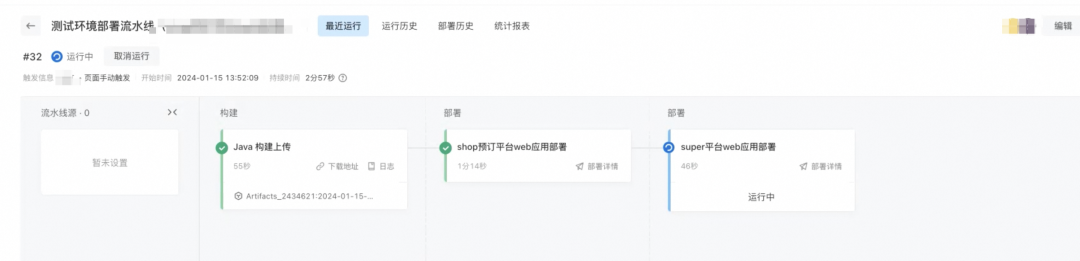
3.2.3?治理效果
基于super后臺做了一輪測試驗證,結果符合預期。
| Before 通過nginx進行路由且無健康檢查時,部署過程中會有頁面訪問失敗的情況。
| After 部署過程中可以根據健康檢查情況路由分發流量,保障部署階段的可用性。
|

3.3?發布后保障
3.3.1?云上核心監控
| 大盤監控 | ?ECS機器監控大盤 | 數據庫監控大盤 |
|
|
|
|
| 釘釘群監控報警:
| ||
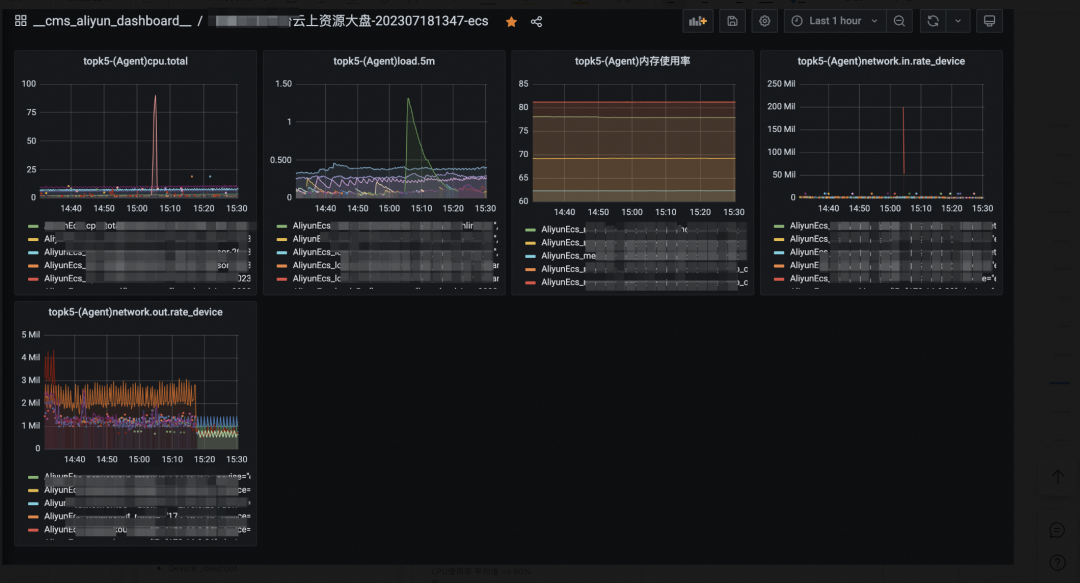
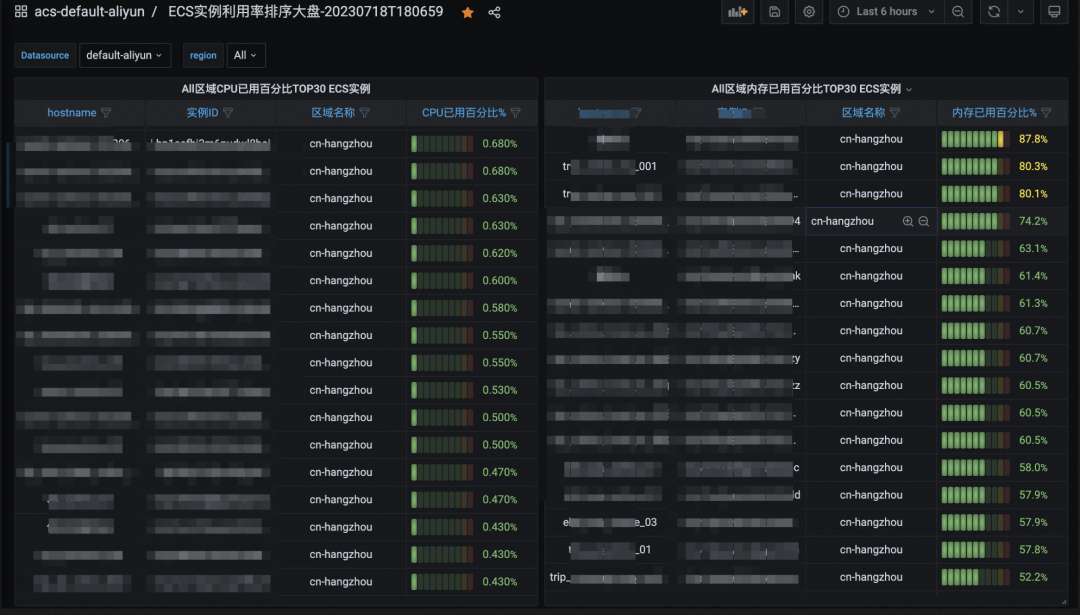
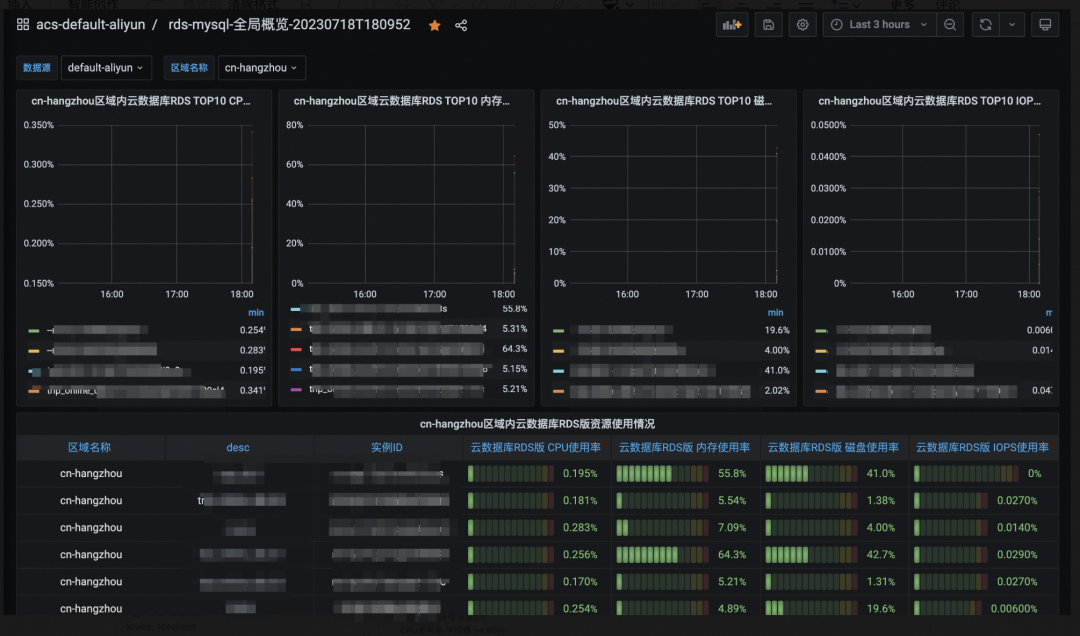
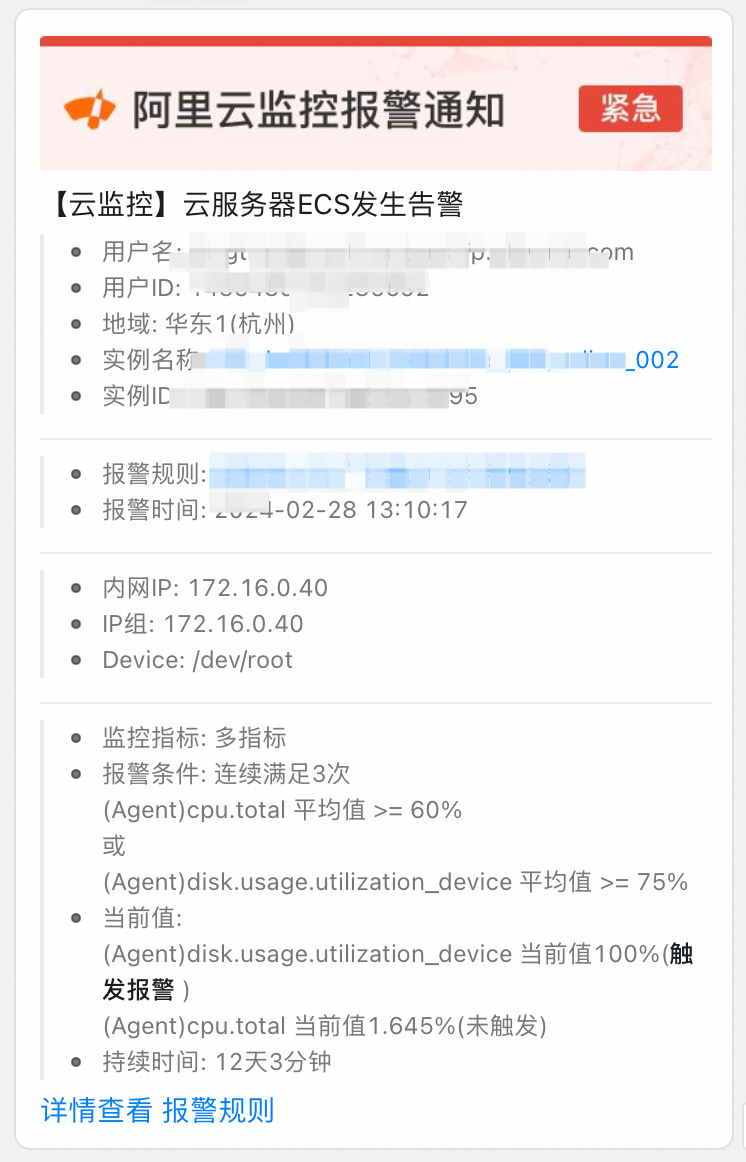
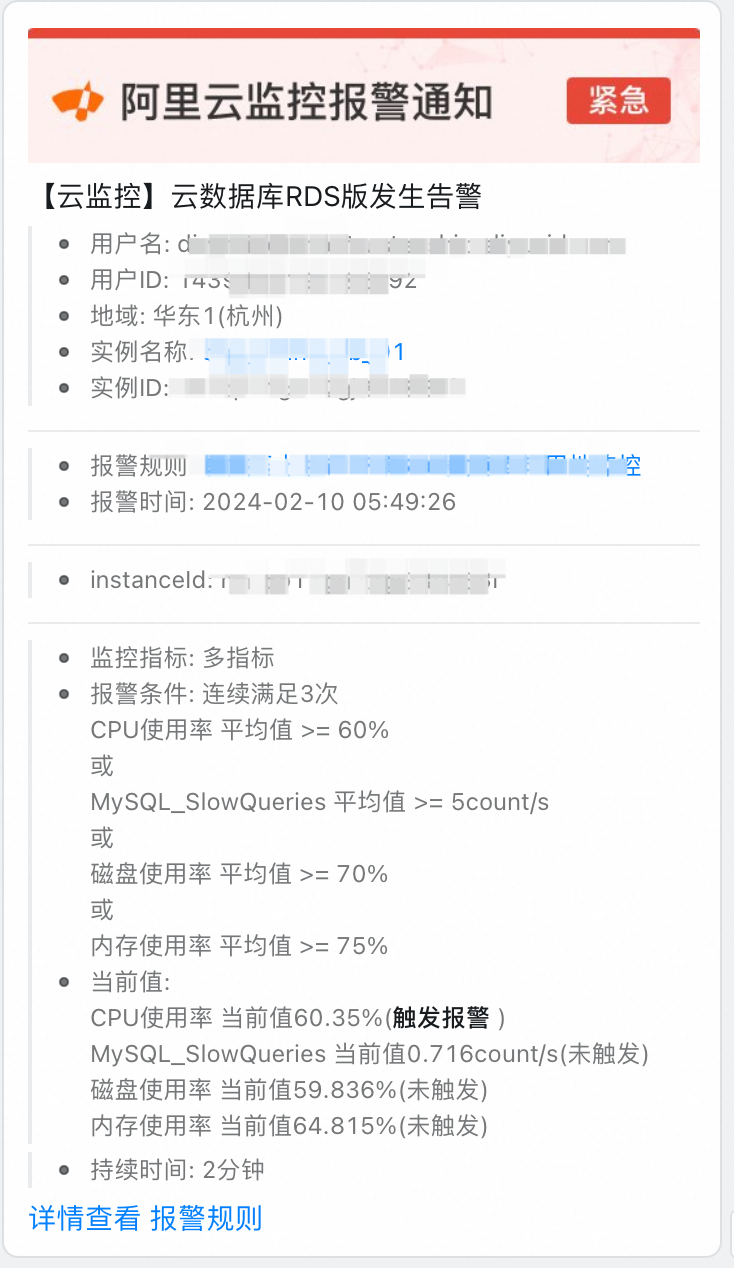
3.3.2?數據離線核對
由于平臺涉及到和三方的數據流入流出,如果數據不一致會導致用戶月度結算、購票等鏈路的使用及體驗問題,所以我們建立了和三方的對賬能力,通過該基礎能力可以在T+1的時效內發現三方的系統問題,進而規避系統風險。
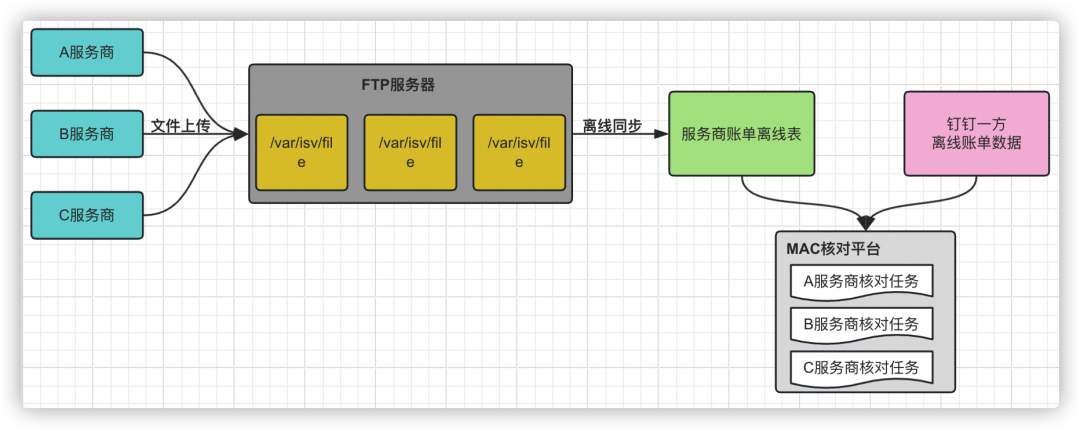
-
向各個服務商提供sFTP服務器賬戶密碼,分配不同的文件bucket。
-
服務商定時上傳對賬文件到oss文件服務器。
-
ODPS創建明細對賬表、總賬對賬表。
-
ODPS上針對各個服務商單獨創建同步任務,從oss服務器同步文件數據至對應的離線表。
-
通過MAC核對平臺,針對各個服務商部署單獨的核對任務。
3.3.3?UI自動化測試
平臺接入了10余家專業的行業頭部ISV,這更加劇了平臺可用性的隱患,在三方頁面不可用的情況下,便會導致用戶投訴反饋。
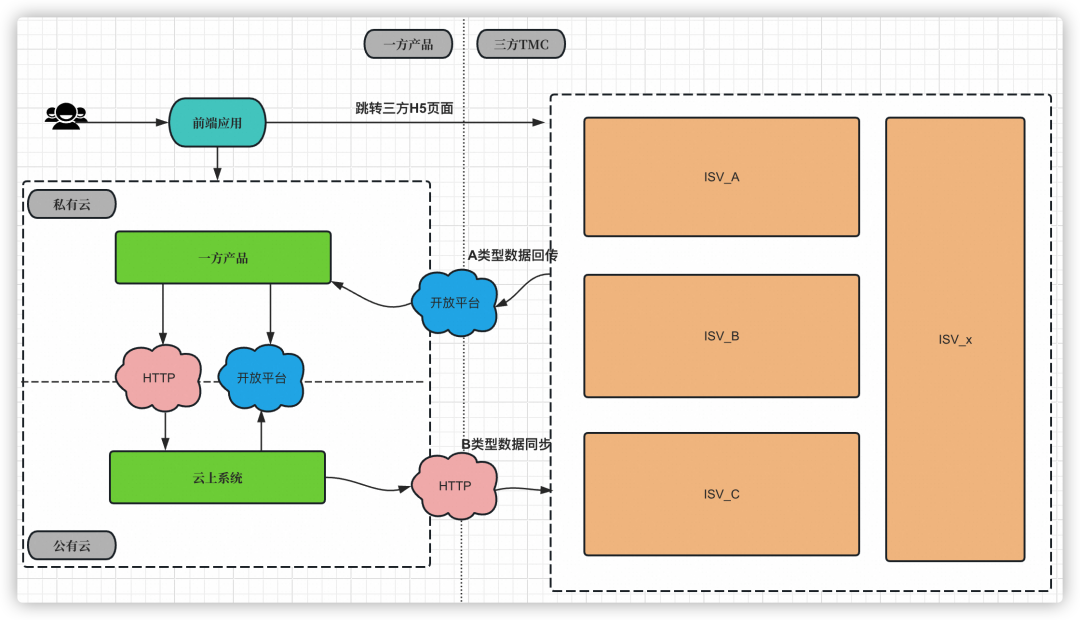
基礎監控
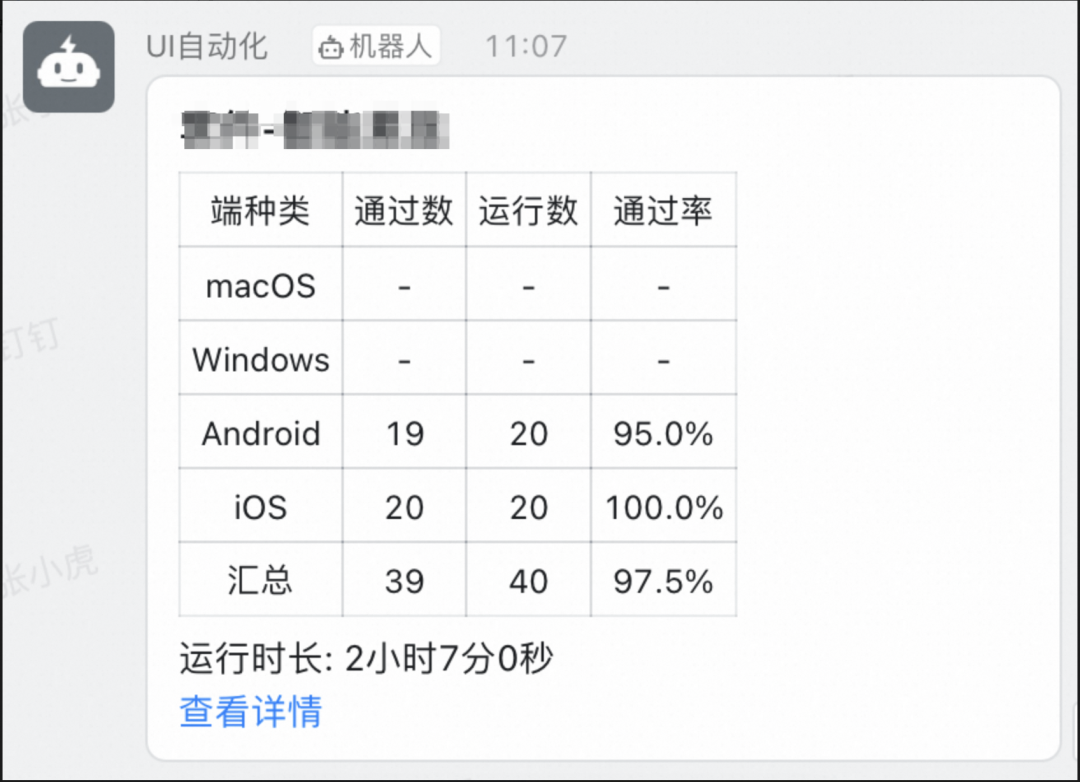
在梳理了核心場景之后,我們通過UI自動化測試每天定時掃描三方頁面的可用性,通過斷言的方式發現核對三方頁面的有效性。
def test_Platform_model_trip_business_travel_ticket_booking(self):# 輪詢是否有判斷頁面是否加載完成mobile.loop_exist_pic("xx_xxx",subfolder="smart_pic/platform_mode/isv")# 點擊選擇第一個票務x = mobile.get_screenshot_resolution()[0] / 2.0 / mobile.get_scale()y = mobile.get_screenshot_resolution()[1] / 5.0 * 2 / mobile.get_scale()mobile.get_driver().click(x, y)# 斷言查詢是否有預定按鈕,否則就提示服務商沒有可預訂的訂單assert mobile.loop_exist_text('預訂')[0], '服務商沒有可預訂的訂單'
當預期的斷言失敗后就會推送到群內報警,并可以通過詳情查看到具體的異常頁面,如下所示:
|
| 針對異常的case,可以通過查看詳情明確具體的異常節點,對于快速定位問題很有幫助。
|

3.4?機制保障
-
早值班機制:每天釘釘和三方生態伙伴同學需要發早值班日志,針對發現的問題在排期優化解決。
-
穩定性周會機制:通過穩定性周會的方式同步風險和治理進展。
-
人員地圖:建立每個服務商的系統保障人員地圖,發現線上非預期問題,可以快速聯系到相關同學及時解決,保障1分鐘發現、5分鐘定位、10分鐘恢復。
四、治理成果
總體來說合作產品模式遇到了以下幾個風險和挑戰:
-
方案無感知:純黑盒模式下對系統細節感知弱,變更風險高。
-
無發布管控:云上系統部署不可控,三方部署內容感知弱、部署頻率不可控。
-
無灰度能力:云上系統部署無灰度能力,部署即全量。
-
無監控能力:云上系統監控感知弱,三方日志規范不標準,監控成本高。
-
安穩意識弱:三方人員安穩意識薄弱,三方故障等于釘釘故障。
整個治理過程,沉淀了通用的公有云CI/CD能力,實現了公有云發布三板斧的能力建設,并建立了平臺持續、穩定、可靠的穩定性保障機制。
-
完善公有云發布管控能力:建立完整的云上系統CI/CD能力,保障無任何由于線上變更操作失誤導致的線上問題。
-
建立發布三板斧基礎能力:具備可灰度、可回滾、可監控的基礎能力。在一個月的治理過程中,通過系統監控、UI自動化測試提前發現并規避了6起線上問題,通過離線核對發現并解決服務商及平臺系統8例缺陷。
-
優化高可用的運維能力:通過負載均衡健康檢查路由的方案解決三方系統發布過程中,由于流量切換導致部分請求不可用的問題,治理完成后無任何由于部署過程導致用戶體驗中斷或完全不可用的問題。
-
建立穩定性保障機制:建立同三方的穩定性周會、早值班等機制,通過階段性的宣講和總結提升三方同學對于共建系統的穩定性意識。
| 治理前 | 治理后 | |
| 可監控 | ? | ? |
| 可灰度 | ? | ? |
| 可回滾 | ? | ? |
| 發布管控 | ? | ? |
| 事件數 | 5/月 | 0 |
五、未來展望
目前平臺業務在快速發展中,如何在快速的業務發展和夯實底座之間保持平衡,未來我們會繼續鞏固建設平臺的穩定性基座。總之穩定性是一個持久的戰役、關注細節的戰役,基礎不穩,地動山搖,穩定性是技術人的底線和生命線!
)









)



![(BFS)題解:P9425 [藍橋杯 2023 國 B] AB 路線](http://pic.xiahunao.cn/(BFS)題解:P9425 [藍橋杯 2023 國 B] AB 路線)

)


