哈希桶是哈希表(散列表)中的一個概念,是哈希表數組中的每個元素 ,用于存儲鍵值對數據。它有以下特點和相關要點:
- 結構與原理:哈希表底層常由數組構成,數組的每個元素即哈希桶。通過哈希函數計算鍵的哈希值,該值作為索引指向對應的哈希桶。比如,用哈希函數
Hash(key)=key % 10計算鍵key的哈希值,就能確定其對應的哈希桶位置。 - 沖突處理:不同鍵經哈希函數計算后可能得到相同哈希值,即哈希沖突。常見的處理方式有:
- 鏈地址法:也叫開散列法,每個哈希桶維護一個鏈表(或其他可鏈接的數據結構)。沖突發生時,將新鍵值對添加到對應哈希桶的鏈表末尾。例如,多個鍵計算出的哈希值都對應數組的第 3 個位置,這些鍵值對就依次鏈接在該位置的鏈表上。
- 開放尋址法:不借助額外鏈表,所有鍵值對直接存于哈希表數組。沖突發生時,通過線性探測、二次探測或雙重哈希等方式,在數組中找下一個空閑位置存儲鍵值對。
- 負載因子與擴容:負載因子 = 填入表中元素的個數 / 散列表的長度,用于衡量哈希表的填充程度。負載因子過高會增加哈希沖突概率,影響性能。當達到預設閾值(如 0.75)時,通常會對哈希表進行擴容,創建更大容量的數組,并重新計算所有鍵的哈希值,將鍵值對遷移到新數組的哈希桶中 。
- 應用場景:廣泛應用于需要快速查找、插入和刪除數據的場景,如數據庫索引、緩存系統、編程語言中的集合類(如 Java 的
HashMap、C++ 的unordered_map) 。像在電商系統中,可使用哈希桶快速查找商品信息;在編譯器中,用于符號表的管理,快速查找變量和函數定義。
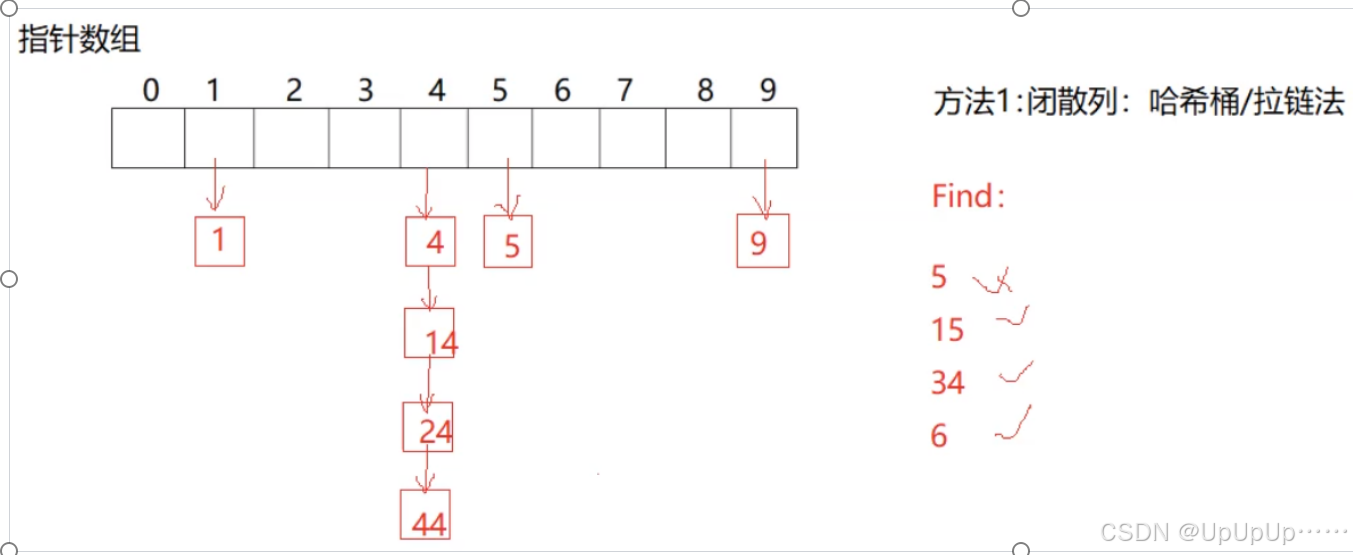
哈希桶的實現:
namespace hash_bucket
{template<class K>struct hashFunc{size_t operator()(const K& key){return static_cast<size_t>(key);}};template<>struct hashFunc<string>{size_t operator()(const string& key){size_t hash = 0;for (auto e : key){hash *= 131;hash += e;}return hash;}};template<class K,class V>struct HashNode{HashNode<K, V>* next;pair<K, V> _kv;HashNode() {};HashNode(const pair<K,V>& kv):_kv(kv),next(nullptr){}};template<class K,class V,class Hash=hashFunc<K>>class hashTables{using node = HashNode<K, V>;//typedef HashNode<K, V> node;public:hashTables(){_tables.resize(10);}bool insert(const pair<K, V>& kv){if (find(kv.first)){return false;}//下面是擴容,這里需要注意的是它的負載因子可以達到 1 /*if (_n == _tables.size()){size_t newsize = _tables.size() * 2;hashTables<K, V> newTables;newTables._tables.resize(newsize);for (size_t i = 0; i < _tables.size(); i++){node* cur = _tables[i];while (cur){newTables.insert(cur->_kv);cur = cur->next;}}_tables.swap(newTables._tables);}*///這一段相比較上一段減少了insert調用,減少了開銷!if (_n == _tables.size()){vector<node*> newtables;newtables.resize(_tables.size() * 2);for (size_t i = 0; i < _tables.size(); i++){node* cur = _tables[i];while (cur){node* next = cur->next;size_t hashi = hs(cur->_kv.first) % newtables.size();cur->next = newtables[hashi];newtables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}size_t hashi = hs(kv.first) % _tables.size();node* newnode = new node(kv);//頭插newnode->next = _tables[hashi];_tables[hashi] = newnode;//更新頭結點!++_n;}node* find(const K& key){size_t hashi =hs(key) % _tables.size();node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->next;}return nullptr;}bool erase(const K& key){size_t hashi =hs( key) % _tables.size();node* cur = _tables[hashi];node* prev = nullptr;while (cur){/*prev = cur;*/if (cur->_kv.first == key){if (prev==nullptr)//頭刪{_tables[hashi] = cur->next;}else//后續正常刪{prev->next = cur->next;}delete cur;return true;}prev = cur;cur = cur->next;}return false;}~hashTables(){for (size_t i = 0; i < _tables.size(); i++){node* cur = _tables[i];while (cur){node* next = cur->next;delete cur;cur = next;}_tables[i] = nullptr;}}void print(){for (size_t i = 0; i <_tables.size(); i++){node* cur = _tables[i];while (cur){cout << "key: " << cur->_kv.first << "-> " << cur->_kv.second << endl;cur = cur->next;}}}private:vector<node*> _tables;//指針數組size_t _n=0;Hash hs;};
}
void test_hush3()
{hash_bucket::hashTables<int, int> h;int a[] = { 1,2,3,4,5,6,7 };for (auto e : a){h.insert(make_pair(e, e));}h.insert({ 8,8 });h.print();h.erase(8);h.print();
}頭插的時候:

上面的代碼要注意的是它的擴容,它直接重新申請一個數組鏈表,而不是像開放地址法一樣,進行一個重新搞一個對象,然后在對象的新表里面進行挪動數據了。現在哈希桶的這個擴容方法減少了insert的調用!!!







(貪心問題————區間問題))
)



)






