Linux多線程詳解
- 一、Linux多線程概念
- 1.1 什么是線程
- 1.2 進程和線程
- 1.3 進程的多個線程共享
- 1.4 進程和線程的關系
- 二、Linux線程控制
- 2.1 POSIX線程庫
- 2.2 線程創建
- 2.3 獲取線程ID pthread_self
- 2.4 線程等待pthread_join
- 2.5 線程終止
- 2.6 線程棧 && pthread_t
- 2.7 線程的局部存儲
- 2.8 分離線程pthread_detach
- 三、線程的優缺點
- 3.1 線程的優點
- 3.2 線程的缺點
- 四、線程異常
- 五、線程用途
一、Linux多線程概念
1.1 什么是線程
- 在一個程序里的一個執行路線就叫做線程(thread)。更準確的定義是:線程是“一個進程內部的控制序列”。
- 每個進程至少都有一個執行線程。
- 線程在進程內部運行,本質是在進程地址空間內運行。
- 在Linux系統中,在CPU眼中,看到的PCB都要比傳統的進程更輕量化。
- 透過進程虛擬地址空間,可以看到進程的大部分資源,將進程資源合理分配給每個執行流,就形成了線程執行流。
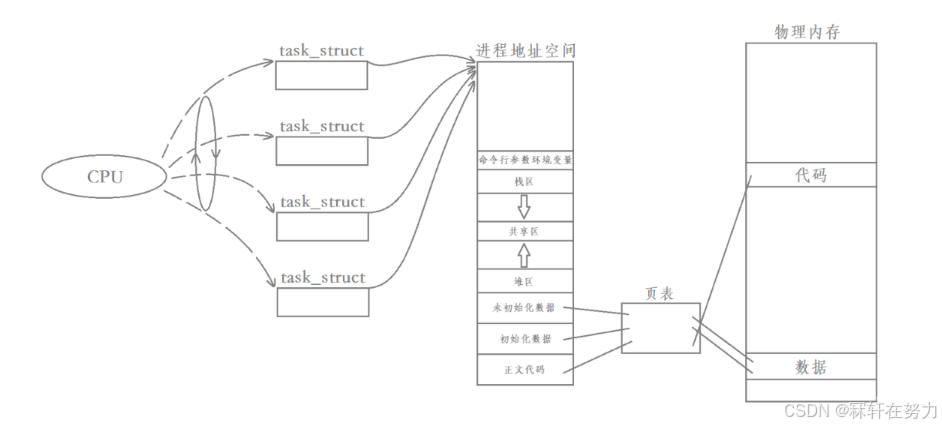
需要明確的是,一個進程的創建實際上伴隨著其進程控制塊(task_struct)、進程地址空間(mm_struct)以及頁表的創建,虛擬地址和物理地址就是通過頁表建立映射的。

每個進程都有自己獨立的進程地址空間和獨立的頁表,也就意味著所有進程在運行時本身就具有獨立性。
但如果我們在創建“進程”時,只創建task_struct,并要求創建出來的task_struct和父task_struct共享進程地址空間和頁表,那么創建的結果就是下面這樣的:

此時我們創建的實際上就是四個線程:
- 其中每一個線程都是當前進程里面的一個執行流,也就是我們常說的“線程是進程內部的一個執行分支”。
- 同時我們也可以看出,線程在進程內部運行,本質就是線程在進程地址空間內運行,也就是說曾經這個進程申請的所有資源,幾乎都是被所有線程共享的。
注意: 單純從技術角度,這個是一定能實現的,因為它比創建一個原始進程所做的工作更輕量化了。
該如何重新理解之前的進程?
下面用藍色方框框起來的內容,我們將這個整體叫做進程。

因此,所謂的進程并不是通過task_struct來衡量的,除了task_struct之外,一個進程還要有進程地址空間、文件、信號等等,合起來稱之為一個進程。
現在我們應該站在內核角度來理解進程:承擔分配系統資源的基本實體,叫做進程。
換言之,當我們創建進程時是創建一個task_struct、創建地址空間、維護頁表,然后在物理內存當中開辟空間、構建映射,打開進程默認打開的相關文件、注冊信號對應的處理方案等等。
而我們之前接觸到的進程都只有一個task_struct,也就是該進程內部只有一個執行流,即單執行流進程,反之,內部有多個執行流的進程叫做多執行流進程。
在Linux中,站在CPU的角度,能否識別當前調度的task_struct是進程還是線程?
答案是不能,也不需要了,因為CPU只關心一個一個的獨立執行流。無論進程內部只有一個執行流還是有多個執行流,CPU都是以task_struct為單位進行調度的。
單執行流進程被調度:

多執行流進程被調度:
因此,CPU看到的雖說還是task_struct,但已經比傳統的進程要更輕量化了。
Linux下并不存在真正的多線程!而是用進程模擬的!
操作系統中存在大量的進程,一個進程內又存在一個或多個線程,因此線程的數量一定比進程的數量多,當線程的數量足夠多的時候,很明顯線程的執行粒度要比進程更細。
如果一款操作系統要支持真的線程,那么就需要對這些線程進行管理。比如說創建線程、終止線程、調度線程、切換線程、給線程分配資源、釋放資源以及回收資源等等,所有的這一套相比較進程都需要另起爐灶,搭建一套與進程平行的線程管理模塊。
因此,如果要支持真的線程一定會提高設計操作系統的復雜程度。在Linux看來,描述線程的控制塊和描述進程的控制塊是類似的,因此Linux并沒有重新為線程設計數據結構,而是直接復用了進程控制塊,所以我們說Linux中的所有執行流都叫做輕量級進程。
但也有支持真的線程的操作系統,比如Windows操作系統,因此Windows操作系統系統的實現邏輯一定比Linux操作系統的實現邏輯要復雜得多。
既然在Linux沒有真正意義的線程,那么也就絕對沒有真正意義上的線程相關的系統調用!
這很好理解,既然在Linux中都沒有真正意義上的線程了,那么自然也沒有真正意義上的線程相關的系統調用了。但是Linux可以提供創建輕量級進程的接口,也就是創建進程,共享空間,其中最典型的代表就是vfork函數。
vfork函數的功能就是創建子進程,但是父子共享空間,vfork的函數原型如下:
pid_t vfork(void);
vfork函數的返回值與fork函數的返回值相同:
- 給父進程返回子進程的PID。
- 給子進程返回0。
只不過vfork函數創建出來的子進程與其父進程共享地址空間,例如在下面的代碼中,父進程使用vfork函數創建子進程,子進程將全局變量g_val由100改為了200,父進程休眠3秒后再讀取到全局變量g_val的值。
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
int g_val = 100;
int main()
{pid_t id = vfork();if (id == 0){//childg_val = 200;printf("child:PID:%d, PPID:%d, g_val:%d\n", getpid(), getppid(), g_val);exit(0);}//fathersleep(3);printf("father:PID:%d, PPID:%d, g_val:%d\n", getpid(), getppid(), g_val);return 0;
}
可以看到,父進程讀取到g_val的值是子進程修改后的值,也就證明了vfork創建的子進程與其父進程是共享地址空間的。
原生線程庫pthread
在Linux中,站在內核角度沒有真正意義上線程相關的接口,但是站在用戶角度,當用戶想創建一個線程時更期望使用thread_create這樣類似的接口,而不是vfork函數,因此系統為用戶層提供了原生線程庫pthread。
原生線程庫實際就是對輕量級進程的系統調用進行了封裝,在用戶層模擬實現了一套線程相關的接口。
因此對于我們來講,在Linux下學習線程實際上就是學習在用戶層模擬實現的這一套接口,而并非操作系統的接口。
1.2 進程和線程
進程是承擔分配系統資源的基本實體,線程是調度的基本單位。
線程共享進程數據,但也擁有自己的一部分數據:
- 線程ID。
- 一組寄存器。(存儲每個線程的上下文信息)
- 棧。(每個線程都有臨時的數據,需要壓棧出棧)
- errno。(C語言提供的全局變量,每個線程都有自己的)
- 信號屏蔽字。
- 調度優先級。
1.3 進程的多個線程共享
因為是在同一個地址空間,因此所謂的代碼段(Text Segment)、數據段(Data Segment)都是共享的:
- 如果定義一個函數,在各線程中都可以調用。
- 如果定義一個全局變量,在各線程中都可以訪問到。
除此之外,各線程還共享以下進程資源和環境:
- 文件描述符表。(進程打開一個文件后,其他線程也能夠看到)
- 每種信號的處理方式。(SIG_IGN、SIG_DFL或者自定義的信號處理函數)
- 當前工作目錄。(cwd)
- 用戶ID和組ID。
1.4 進程和線程的關系
進程和線程的關系如下圖:

在此之前我們接觸到的都是具有一個線程執行流的進程,即單線程進程。
二、Linux線程控制
2.1 POSIX線程庫
pthread線程庫是應用層的原生線程庫:
- 應用層指的是這個線程庫并不是系統接口直接提供的,而是由第三方幫我們提供的。
- 原生指的是大部分Linux系統都會默認帶上該線程庫。
- 與線程有關的函數構成了一個完整的系列,絕大多數函數的名字都是以“pthread_”打頭的。
- 要使用這些函數庫,要通過引入頭文件<pthreaad.h>。
- 鏈接這些線程函數庫時,要使用編譯器命令的“-lpthread”選項。
錯誤檢查:
-
傳統的一些函數是,成功返回0,失敗返回-1,并且對全局變量errno賦值以指示錯誤。
-
pthreads函數出錯時不會設置全局變量errno(而大部分POSIX函數會這樣做),而是將錯誤代碼通過返回值返回。
-
pthreads同樣也提供了線程內的errno變量,以支持其他使用errno的代碼。對于pthreads函數的錯誤,建議通過返回值來判定,因為讀取返回值要比讀取線程內的errno變量的開銷更小。
2.2 線程創建
創建線程的函數叫做pthread_create
pthread_create函數的函數原型如下:
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);
參數說明:
- thread:獲取創建成功的線程ID,該參數是一個輸出型參數。
- attr:用于設置創建線程的屬性,傳入NULL表示使用默認屬性。
- start_routine:該參數是一個函數地址,表示線程例程,即線程啟動后要執行的函數。
- arg:傳給線程例程的參數。
返回值說明:
- 線程創建成功返回0,失敗返回錯誤碼。
讓主線程創建一個新線程
當一個程序啟動時,就有一個進程被操作系統創建,與此同時一個線程也立刻運行,這個線程就叫做主線程。
- 主線程是產生其他子線程的線程。
- 通常主線程必須最后完成某些執行操作,比如各種關閉動作。
下面我們讓主線程調用pthread_create函數創建一個新線程,此后新線程就會跑去執行自己的新例程,而主線程則繼續執行后續代碼。
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
void* startRoutine(void* args)
{while (true){cout << "線程正在運行..." << endl;sleep(1);}
}
int main()
{pthread_t tid;int n = pthread_create(&tid, nullptr, startRoutine, (void*)"thread1");cout << "new thread id : " << tid << endl;//線程IDwhile (true){cout << "main thread 正在運行..." << endl;sleep(1);}return 0;
}
運行代碼后可以看到,新線程每隔一秒執行一次打印操作,而主線程每隔兩秒執行一次打印操作。
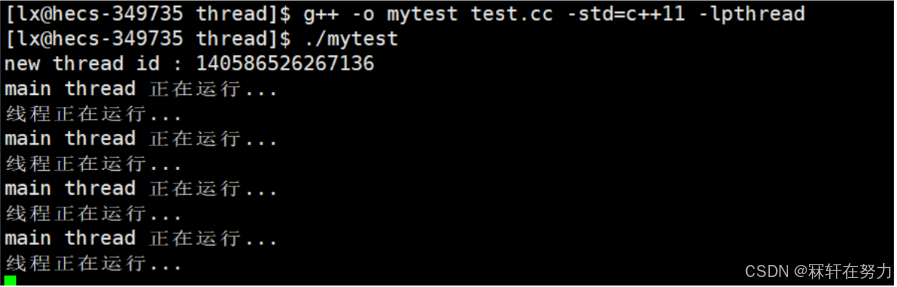
可以看到,主線程創建新線程后,二者一同運行著,且我們的新線程的ID很大。至于為什么這么大后續談。
2.3 獲取線程ID pthread_self
常見獲取線程ID的方式有兩種:
- 創建線程時通過輸出型參數獲得。
- 通過調用pthread_self函數獲得。
pthread_self函數的函數原型如下:
pthread_t pthread_self(void);
調用pthread_self函數即可獲得當前線程的ID,類似于調用getpid函數獲取當前進程的ID。
- 例如,下面的代碼,我們讓主線程和新線程都通過pthread_self函數來獲取自身的ID,并統一用16進制的方式打印。
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
static void printTid(const char *name, const pthread_t &tid)
{printf("%s 正在運行, thread id: 0x%x\n", name, tid);
}
void* startRoutine(void* args)
{const char* name = static_cast<const char*>(args);while (true){printTid(name, pthread_self());sleep(1);}
}
int main()
{pthread_t tid;int n = pthread_create(&tid, nullptr, startRoutine, (void*)"thread1");while (true){printTid("main thread", pthread_self());sleep(1);}return 0;
}

注意: 用pthread_self函數獲得的線程ID與內核的LWP的值是不相等的,pthread_self函數獲得的是用戶級原生線程庫的線程ID,而LWP是內核的輕量級進程ID,它們之間是一對一的關系。
2.4 線程等待pthread_join
首先需要明確的是,一個線程被創建出來,這個線程就如同進程一般,也是需要被等待的。如果主線程不對新線程進行等待,那么這個新線程的資源也是不會被回收的。所以線程需要被等待,如果不等待會產生類似于“僵尸進程”的問題,也就是內存泄漏。等待線程的函數叫做pthread_join,函數原型如下:
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);
參數說明:
- thread:被等待線程的ID。
- retval:線程退出時的退出碼信息。
返回值說明:
- 線程等待成功返回0,失敗返回錯誤碼。
示例:
- 在下面的代碼中我們先不關心線程的退出信息,直接將pthread_join函數的第二個參數設置為nullptr,等待線程后打印該線程的編號以及線程ID。
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
static void printTid(const char *name, const pthread_t &tid)
{printf("%s 正在運行, thread id: 0x%x\n", name, tid);
}
void* startRoutine(void* args)
{const char* name = static_cast<const char*>(args);int cnt = 500;while (true){printTid(name, pthread_self());sleep(1);if (!(cnt--)) break;}cout << "線程退出啦...." << endl;return nullptr;
}
int main()
{pthread_t tid;int n = pthread_create(&tid, nullptr, startRoutine, (void*)"thread1");sleep(1000);pthread_join(tid, nullptr);return 0;
}

如上我們發現,運行后,線程如約運行,并用ps axj命令查看此進程信息,當我們發送19號暫停此線程后,會發現我整個線程都跟著暫停了,當我發送18號信號,再次運行此線程時,又會發現線程又同時運行了,因為它們是在一個進程的。

下面更改代碼,讓新線程創建5s后退出,隨后再過幾秒后被thread_join等待,當主進程開始打印消息時,說明新線程join等待完成:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
static void printTid(const char *name, const pthread_t &tid)
{printf("%s 正在運行, thread id: 0x%x\n", name, tid);
}
void* startRoutine(void* args)
{const char* name = static_cast<const char*>(args);int cnt = 5;while (true){printTid(name, pthread_self());sleep(1);if (!(cnt--)) break;}cout << "線程退出啦...." << endl;return nullptr;
}
int main()
{pthread_t tid;int n = pthread_create(&tid, nullptr, startRoutine, (void*)"thread1");sleep(10);pthread_join(tid, nullptr);cout << "main thread join success" << endl;sleep(10);while (true){printTid("main thread", pthread_self());sleep(1);}return 0;
}
我們使用如下監控腳本輔助我們觀察現象:
while :; do ps -aL | head -1 && ps -aL | grep mytest; sleep 1; done
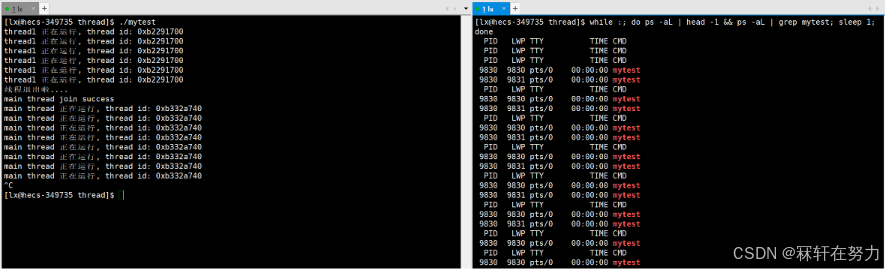
會發現當創建線程后,線程1正在運行,5s后新線程退出了,我們的監控腳本觀察到線程由兩個變成了一個,但是正常情況下預期應該是兩個線程,隨后線程等待成功,這里還是只能看到一個線程。不是說好退出后應該看到的是兩個線程嗎,事實上一個線程退出后我們并沒有看到預期結果。原因是ps命令在查的時候退出的線程是不給你顯示的,所以你只能看到一個線程。但是現在不能證明當前的新線程在退出沒有被join的時候就沒有內存泄漏。
- 所以線程退出的時候,一般必須要進行join,如果不進行join,就會造成類似于進程那樣的內存泄漏問題。
來看下線程異常的問題:
- 如下的野指針問題:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
static void printTid(const char *name, const pthread_t &tid)
{printf("%s 正在運行, thread id: 0x%x\n", name, tid);
}
void *startRoutine(void *args)
{const char *name = static_cast<const char *>(args);int cnt = 5;while (true){printTid(name, pthread_self());sleep(1);if (!(cnt--)){int *p = nullptr;*p = 100; // 野指針問題}}cout << "線程退出啦...." << endl;return nullptr;
}
int main()
{pthread_t tid;int n = pthread_create(&tid, nullptr, startRoutine, (void *)"thread1");sleep(10);pthread_join(tid, nullptr);cout << "main thread join success" << endl;sleep(10);while (true){printTid("main thread", pthread_self());sleep(1);}return 0;
}
同樣是使用如下的監控腳本輔助我們觀察現象:
while :; do ps -aL | head -1 && ps -aL | grep mytest; sleep 1; done

此時會發現:待線程出現野指針問題時,左邊會顯示段錯誤,而右邊監控腳本中的線程直接就沒了。此時就說明當線程異常了,那么整個進程整體異常退出,線程異常 == 進程異常。所以線程會影響其它線程的運行 —— 線程的健壯性(魯棒性)較低。
再來看看pthread_join等待函數的函數原型:
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);
問:如何理解第二個參數retval?
- 參數retval是線程退出時的退出碼,這是一個二級指針,一個輸出型參數。剛剛我們的代碼中,以及涉及到了線程退出的方式(從線程函數return)。退出的類型是void*。
- ptherad_join的第二個參數retval的作用就是一個輸出型參數,獲取新線程退出時的退出碼。我們先前講過進程退出時,分為三種情況:
- 代碼跑完,結果正確
- 代碼跑完,結果不正確
- 異常
在線程退出時,代碼跑完,結果不正確和結果正確都可以得到退出碼,但是線程異常時并不會出現退出碼。那么為什么異常時主線程沒有獲取新線程退出時的信號呢?
因為線程出異常就不再是線程的問題,而是進程的問題,應該讓父進程獲取退出碼,知道它什么原因退出的。因此線程終止時,只需考慮正常終止.
2.5 線程終止
如果需要只終止某個線程而不是終止整個進程,可以有三種方法:
- 從線程函數return。
- 線程可以自己調用pthread_exit函數終止自己。
- 一個線程可以調用pthread_cancel函數終止同一進程中的另一個線程。
方法一(從線程函數return)
- 此法我們在上面已經見過,就不做演示。
方法二(pthread_exit)
- pthread_exit函數的功能就是終止線程,pthread_exit函數的函數原型如下:
#include <pthread.h>
void pthread_exit(void *retval);
參數說明:
- retval:線程退出時的退出碼信息。
注意:
- 該函數無返回值,跟進程一樣,線程結束的時候無法返回它的調用者(自身)。
- pthread_exit或者return返回的指針所指向的內存單元必須是全局的或者是用malloc分配的,不能在線程函數的棧上分配,因為當其他線程得到這個返回指針時,線程函數已經退出了。
例如,在下面代碼中,我們使用pthread_exit函數終止線程,并將線程的退出碼設置為1111:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
static void printTid(const char *name, const pthread_t &tid)
{printf("%s 正在運行, thread id: 0x%x\n", name, tid);
}
void *startRoutine(void *args)
{const char *name = static_cast<const char *>(args);int cnt = 5;while (true){printTid(name, pthread_self());sleep(1);if (!(cnt--)){break;}}cout << "線程退出啦...." << endl;//1、線程退出方式1: 從線程函數直接return/*return (void *)111;*///2、線程退出方式2: pthread_exitpthread_exit((void*)1111);
}
int main()
{pthread_t tid;int n = pthread_create(&tid, nullptr, startRoutine, (void *)"thread1");(void)n;void *ret = nullptr;pthread_join(tid, &ret);cout << "main thread join success, *ret: " << (long long)ret << endl;sleep(10);while (true){printTid("main thread", pthread_self());sleep(1);}return 0;
}

這段代碼我們也能看出使用pthread_exit只能退出當前子線程,不會影響其它線程。
問:為何終止線程要用pthread_exit,exit不行嗎?
看如下的代碼:
#include <iostream>
#include <cstring>
#include <pthread.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/syscall.h>
using namespace std;
__thread int global_value = 100;
void *startRoutine(void *args)
{while (true){cout << "thread" << pthread_self() << " global_value: " << global_value<< " Inc: " << global_value++ << "lwp: " << syscall(SYS_gettid) << endl;sleep(1);break;}exit(1);
}
int main()
{pthread_t td1;pthread_t td2;pthread_t td3;pthread_create(&td1, nullptr, startRoutine, (void *)"thread 1");pthread_create(&td2, nullptr, startRoutine, (void *)"thread 2");pthread_create(&td3, nullptr, startRoutine, (void *)"thread 3");int n = pthread_join(td1, nullptr);cout << n << ":" << strerror(n) << endl;n = pthread_join(td2, nullptr);cout << n << ":" << strerror(n) << endl;n = pthread_join(td3, nullptr);cout << n << ":" << strerror(n) << endl;return 0;
}

總結:
- exit是退出進程,任何一個線程調用exit,都表示整個進程退出。無論哪個子線程調用整個程序都將結束。 而pthread_exit的作用是只退出當前子線程。即使你放在主線程,它也會只退出主線程,其它線程有運行的仍會繼續運行。
方法三(pthread_cancel)
- 線程是可以被取消的,我們可以使用pthread_cancel函數取消某一個線程,pthread_cancel函數的函數原型如下:
#include <pthread.h>
int pthread_cancel(pthread_t thread);
參數說明:
- thread:被取消線程的ID。
返回值說明:
- 線程取消成功返回0,失敗返回錯誤碼。
線程是可以取消自己的,取消成功的線程的退出碼一般是-1。例如在下面的代碼中,我們讓線程執行一次打印操作后將自己取消:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
static void printTid(const char *name, const pthread_t &tid)
{printf("%s 正在運行, thread id: 0x%x\n", name, tid);
}
void *startRoutine(void *args)
{const char *name = static_cast<const char *>(args);int cnt = 5;while (true){printTid(name, pthread_self());sleep(1);if (!(cnt--)){// break;}}
}
int main()
{pthread_t td;int n = pthread_create(&td, nullptr, startRoutine, (void *)"thread1");(void)n;sleep(3);//代表main thread對應的工作cout << "new thread been canceled" << endl;pthread_cancel(td);void *ret = nullptr;pthread_join(td, &ret);cout << "main thread join success, *ret: " << (long long)ret << endl;sleep(10);while (true){printTid("main thread", pthread_self());sleep(1);}return 0;
}

為什么退出的結果是-1呢?
-
線程和進程一樣,用的都是PCB,退出時都有自己的退出碼,調用return或exit就是自己修改PCB中的退出結果(退出碼),取消這個線程時,是OS取消的,就直接向退出碼中寫-1。
-
這里的-1就是pthread庫里頭給我們提供的宏(PTHREAD_CANCELED)
上述我們做的測試是讓main thread主線程去取消新線程new thread,不推薦反過來。這里就不做測試了。
2.6 線程棧 && pthread_t
pthread_t實際上就是地址。
- 線程是一個獨立的執行流
- 線程一定會在自己的運行過程中,產生臨時數據(調用函數,定義局部變量等)
- 線程一定需要有自己的獨立的棧結構
前面學習到,線程共享進程地址空間的內容,堆區也是的,堆區是動態申請的,線程內可以自己將其保持著,如果需要,這塊空間是可以被其它線程保持可見性的,全局數據區也是如此:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
int global_value = 100;
static void printTid(const char *name, const pthread_t &tid)
{printf("%s 正在運行, thread id: 0x%x, global_value: %d\n", name, tid, global_value);
}
void *startRoutine(void *args)
{const char *name = static_cast<const char *>(args);int cnt = 5;while (true){printTid(name, pthread_self());sleep(1);if (!(cnt--)){global_value = 200;}}cout << "線程退出啦..." << endl;int* p = new int(10);return (void*)p;
}
int main()
{pthread_t tid;int n = pthread_create(&tid, nullptr, startRoutine, (void *)"thread1");(void)n;while (true){printTid("main thread", pthread_self());sleep(1);}void *ret = nullptr;pthread_join(tid, &ret);cout << "main thread join success, *ret: " << *((int*)ret) << endl;delete (int*)ret;return 0;
}
如上我們設置全局變量為100,新線程和主線程在打印5次后,新線程對全局變量做修改,隨后觀察到的現象應該是全局變量由100變成200,主線程和新線程都應該是這個現象:
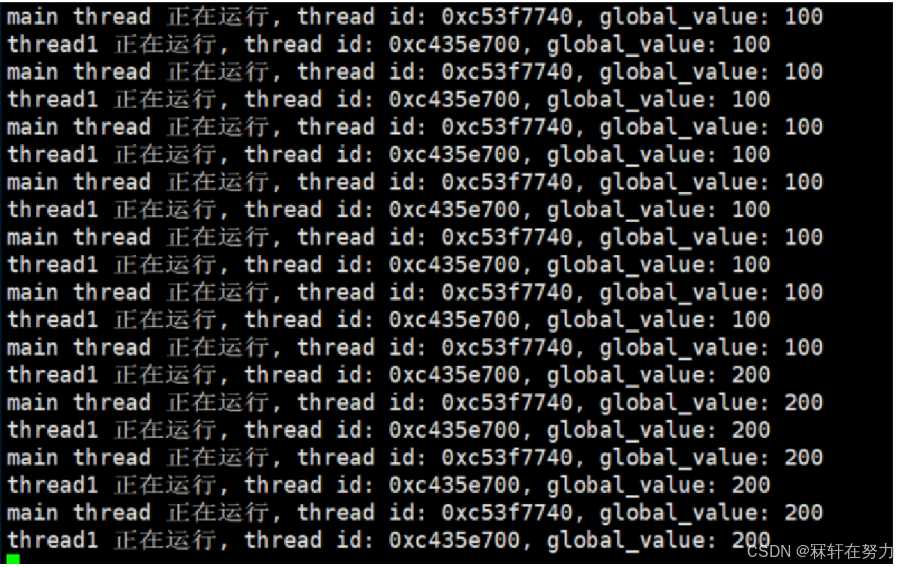
理解了數據區和堆區的劃分,現在來看線程的獨立棧結構。
我們使用的線程庫,是用戶級線程庫:pthread。是因為Linux沒有真線程,沒有辦法提供真的線程調用接口,只能提供創建子進程、共享地址空間的調用接口。但是進程的代碼、數據……怎么劃分這些都是由線程庫自己維護的。注意:此pthread庫是動態庫。
當我們需要用到此動態庫時,要把它加載到內存,隨后映射進對應的進程地址空間。
因為要把此動態庫加載到物理內存,所以我的磁盤中有如上(libpthread.so動態庫 & mytest.exe可執行程序)。我們在運行時,首先要把此可執行程序mytest.exe加載到內存,此程序內部的代碼中一定有pthread_create,pthread_join這些從libpthread.so動態庫里調來的函數,所以此時OS把該動態庫加載到內存。隨后把此動態庫經過頁表映射到進程地址空間的共享區當中,我們的task_truct通過虛擬地址訪問代碼區然后跳轉至共享區內,執行相關的創建線程等工作,執行后再返回至代碼區。
- 所以最終都是在地址空間中的共享區內完成對應的線程創建等操作的。
- 所以在我們的代碼中一定充斥著三大部分(你的,庫的,系統的)。所有的代碼都是在進程的地址空間當中進行執行的。
問:pthread_t究竟是什么呢?
既然我們已經知道此動態庫會被加載到共享區,那么我們把此共享區的libpthread.so動態庫放大來討論。線程的全部實現,并沒有全部體現在OS內,而是OS提供執行流,具體的線程結構由庫來進行管理。如下:
操作系統只提供輕量級進程,對于用戶他不管,只要線程。所以在用戶和OS之間設計了libpthread.so庫,用于創建線程,等待線程……操作。用戶創建一個線程,庫做了轉換,讓你在系統幫你創建一個輕量級進程,用戶終止一個線程,庫幫你終止一個輕量級進程,用戶等待一個線程,庫幫你轉換成等待一個輕量級進程,并且把結果返回。此庫起到的就是承上啟下的作用。

庫可以創建多個線程,需要對這些線程進行管理(先描述,再組織)。庫里頭通過類似struct thread_info的結構體(注意里頭是有私有棧的)來進行管理:
struct thread_info
{pthread_t tid;void *stack; // 私有棧...
}
當你在用戶層每創建一個線程時,在庫里頭就會創建一個線程控制塊struct thread_info(描述線程的屬性)。給創建線程的用戶返回的是該結構體的起始虛擬地址。所以我們的pthread_t實際上就是用戶級線程的控制結構體的起始地址!!!。

既然每一個線程都有struct thread_info結構體,而此結構體內部又有私有棧,所以結論如下:
- 主線程的獨立棧結構,用的就是地址空間中的棧區
- 新線程用的棧結構,用的是庫中提供的棧結構
2.7 線程的局部存儲
我們的線程除了保存臨時數據時可以有自己的線程棧,我們的pthread給我們了一種能力,如果定義了一個全局變量(默認所有線程共享),但是你想讓每個線程各自私有,那么我們就可以使用線程局部存儲。
- 如下我們創建了3個線程,創建一個全局變量,默認情況下此全局變量所有線程共享,現在我們來打印此全局變量以及地址來觀察現象:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
int global_value = 100;
void *startRoutine(void *args)
{while (true){cout << "thread" << pthread_self() << " global_value: " << global_value<< " &global_value: " << &global_value << " Inc: " << global_value++ << endl;sleep(1);}
}
int main()
{pthread_t tid1;pthread_t tid2;pthread_t tid3;pthread_create(&tid1, nullptr, startRoutine, (void *)"thread 1");pthread_create(&tid2, nullptr, startRoutine, (void *)"thread 2");pthread_create(&tid3, nullptr, startRoutine, (void *)"thread 3");pthread_join(tid1, nullptr);pthread_join(tid2, nullptr);pthread_join(tid3, nullptr);return 0;
}
正常情況下,我們觀察到著三個線程打印的全局變量地址應該都是一樣的,且打印的變量是在累加的,這是正常的,因為共享全局變量,我的修改別人也能拿到。

為了讓此全局變量獨屬于各個線程所私有,我們只需要給全局變量前假設__thread即可,加了這個__thread就會默認把這個global_value再拷一份給每一個進程。
__thread int global_value = 100;
代碼如下:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
__thread int global_value = 100;
void *startRoutine(void *args)
{while (true){cout << "thread" << pthread_self() << " global_value: " << global_value<< " &global_value: " << &global_value << " Inc: " << global_value++ << endl;sleep(1);}
}
int main()
{pthread_t tid1;pthread_t tid2;pthread_t tid3;pthread_create(&tid1, nullptr, startRoutine, (void *)"thread 1");pthread_create(&tid2, nullptr, startRoutine, (void *)"thread 2");pthread_create(&tid3, nullptr, startRoutine, (void *)"thread 3");pthread_join(tid1, nullptr);pthread_join(tid2, nullptr);pthread_join(tid3, nullptr);return 0;
}
如下可以看到,創建的3個線程,每個線程的全局變量的地址都是不一樣的,修改變量時,互相之間沒有影響,各自獨立。
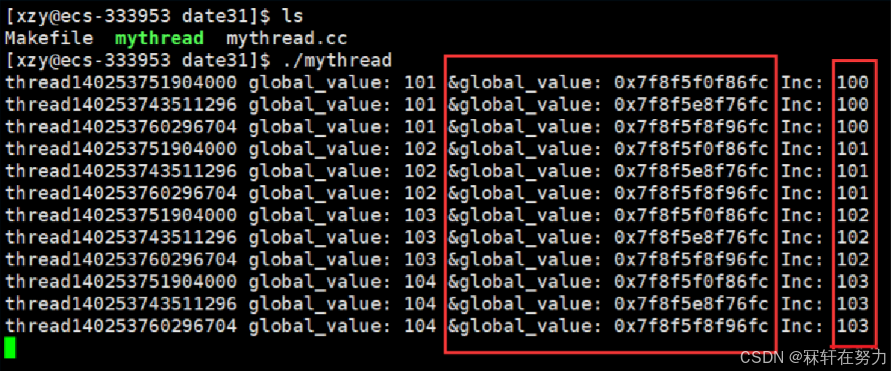
線程是有自己的輕量級進程lwp的,如果我們想要拿到此lwp,我們可以調用gettid函數獲得
#include <sys/types.h>
pid_t gettid(void);
但是此函數不能直接使用,必須得調用syscall函數,在里頭調用SYS_gettid才能拿到lwp。
#include <unistd.h>
#include <sys/syscall.h> /* For SYS_xxx definitions */
int syscall(int number, ...);
代碼如下:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/syscall.h>
using namespace std;
__thread int global_value = 100;
void *startRoutine(void *args)
{while (true){cout << "lwp: " << syscall(SYS_gettid) << endl;sleep(1);}
}
int main()
{pthread_t tid1;pthread_t tid2;pthread_t tid3;pthread_create(&tid1, nullptr, startRoutine, (void *)"thread 1");pthread_create(&tid2, nullptr, startRoutine, (void *)"thread 2");pthread_create(&tid3, nullptr, startRoutine, (void *)"thread 3");pthread_join(tid1, nullptr);pthread_join(tid2, nullptr);pthread_join(tid3, nullptr);return 0;
}
我們使用如下的監控腳本輔助我們觀察現象:
ps -aL | head -1 && ps -aL | grep mytest

2.8 分離線程pthread_detach
-
默認情況下,新創建的線程是joinable的,線程退出后,需要對其進行pthread_join操作,否則無法釋放資源,從而造成內存泄漏。
-
但如果我們不關心線程的返回值,join也是一種負擔,此時我們可以將該線程進行分離,后續當線程退出時就會自動釋放線程資源。
-
一個線程如果被分離了,這個線程依舊要使用該進程的資源,依舊在該進程內運行,甚至這個線程崩潰了一定會影響其他線程,只不過這個線程退出時不再需要主線程去join了,當這個線程退出時系統會自動回收該線程所對應的資源。
-
可以是線程組內其他線程對目標線程進行分離,也可以是線程自己分離。
-
joinable和分離是沖突的,一個線程不能既是joinable又是分離的。
分離線程的函數叫做pthread_detach,pthread_detach函數的函數原型如下:
#include <pthread.h>
int pthread_detach(pthread_t thread);
參數說明:
- thread:被分離線程的ID。
返回值說明:
- 線程分離成功返回0,失敗返回錯誤碼。
joinable和分離是沖突的,一個線程不能既是joinable又是分離的。
為什么我sleep(1)后才符合我們的預期呢?( 一個線程不能既是joinable又是分離的)。有sleep之后join就會失敗,沒有sleep,join就會成功,那么哪個才是正確的呢?
我們更傾向于讓主線程去分離其它線程:
#include <iostream>
#include <cstring>
#include <pthread.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/syscall.h>
using namespace std;
__thread int global_value = 100;
void *startRoutine(void *args)
{cout << "線程分離..." << endl;while (true){cout << "thread" << pthread_self() << " global_value: " << global_value<< " Inc: " << global_value++ << "lwp: " << syscall(SYS_gettid) << endl;sleep(1);}
}
int main()
{pthread_t tid1;pthread_t tid2;pthread_t tid3;pthread_create(&tid1, nullptr, startRoutine, (void *)"thread 1");pthread_create(&tid2, nullptr, startRoutine, (void *)"thread 2");pthread_create(&tid3, nullptr, startRoutine, (void *)"thread 3");//等待一秒為了防止,子線程還沒分離,主線程就開始等待了。sleep(1);pthread_detach(tid1);pthread_detach(tid2);pthread_detach(tid3);//驗證不能既分離又join等待int n = pthread_join(tid1, nullptr);cout << n << ":" << strerror(n) << endl;n = pthread_join(tid2, nullptr);cout << n << ":" << strerror(n) << endl;n = pthread_join(tid3, nullptr);cout << n << ":" << strerror(n) << endl;return 0;
}

總結分離線程:
- 線程分離了,意味著,不在關心這個線程的死活。所以這也相當于線程退出的第4種方式,延后退出。
- 立即分離或者延后分離都可以,但是要保證線程活著。
- 新線程分離,但是主線程先退出(進程退出),所有線程就都退了。
- 一般分離線程,對應的主線程不退出(常駐內存的進程)
三、線程的優缺點
3.1 線程的優點
-
創建一個新線程的代價要比創建一個新進程小得多。
-
與進程之間的切換相比,線程之間的切換需要操作系統做的工作要少很多。
-
線程占用的資源要比進程少很多。
-
能充分利用多處理器的可并行數量。
-
在等待慢速IO操作結束的同時,程序可執行其他的計算任務。
-
計算密集型應用,為了能在多處理器系統上運行,將計算分解到多個線程中實現。
-
IO密集型應用,為了提高性能,將IO操作重疊,線程可以同時等待不同的IO操作。
概念說明:
- 計算密集型:執行流的大部分任務,主要以計算為主。比如加密解密、大數據查找等。
- IO密集型:執行流的大部分任務,主要以IO為主。比如刷磁盤、訪問數據庫、訪問網絡等。
3.2 線程的缺點
-
性能損失: 一個很少被外部事件阻塞的計算密集型線程往往無法與其他線程共享同一個處理器。如果計算密集型線程的數量比可用的處理器多,那么可能會有較大的性能損失,這里的性能損失指的是增加了額外的同步和調度開銷,而可用的資源不變。
-
健壯性降低: 編寫多線程需要更全面更深入的考慮,在一個多線程程序里,因時間分配上的細微偏差或者因共享了不該共享的變量而造成不良影響的可能性是很大的,換句話說,線程之間是缺乏保護的。
-
缺乏訪問控制: 進程是訪問控制的基本粒度,在一個線程中調用某些OS函數會對整個進程造成影響。
-
編程難度提高: 編寫與調試一個多線程程序比單線程程序困難得多。
四、線程異常
- 單個線程如果出現除零、野指針等問題導致線程崩潰,進程也會隨著崩潰。
- 線程是進程的執行分支,線程出異常,就類似進程出異常,進而觸發信號機制,終止進程,進程終止,該進程內的所有線程也就隨即退出。
五、線程用途
- 合理的使用多線程,能提高CPU密集型程序的執行效率。
- 合理的使用多線程,能提高IO密集型程序的用戶體驗(如生活中我們一邊寫代碼一邊下載開發工具,就是多線程運行的一種表現)。






(貪心問題————區間問題))
)



)







