主要內容總結
本文提出了一種具有強推理能力的列表式段落重排序模型ReasonRank,旨在解決現有重排序模型在推理密集型場景(如復雜問答、數學問題、代碼查詢等)中表現不佳的問題,核心原因是這類場景缺乏高質量的推理密集型訓練數據。
為解決這一問題,研究團隊:
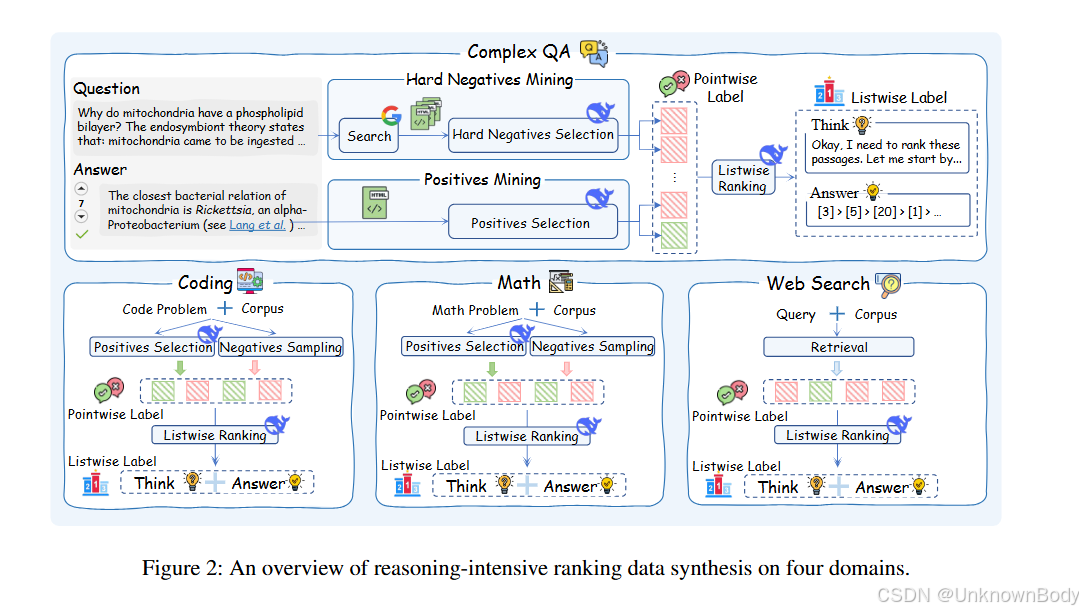
- 設計了自動推理密集型訓練數據合成框架,從復雜問答、代碼、數學、網頁搜索四個領域收集查詢和段落,利用DeepSeek-R1生成高質量標簽(包括推理鏈和黃金排序列表),并通過自一致性過濾機制保證數據質量,最終得到1.3萬條高質量訓練數據。
- 提出兩階段訓練框架:
- 冷啟動監督微調(SFT)階段:讓基礎大語言模型學習列表式推理模式和黃金排序。
- 強化學習(RL)階段:設計多視角排序獎勵(結合NDCG@10、Recall@10、RBO等指標),優化模型的排序能力,適配列表式排序的滑動窗口特性。
實驗結果顯示,ReasonRank在BRIGHT和R2MED兩個推理密集型基準上超越現有基線模型,且延遲低于點式重排序模型Rank1,在BRIGHT排行榜上達到SOTA性能(40.6分)。
創新點
- 自動推理密集




全景解析)





)




![ICBC_TDR_UShield2_Install.exe [ICBC UKEY]](http://pic.xiahunao.cn/ICBC_TDR_UShield2_Install.exe [ICBC UKEY])

--下)
)
Ubuntu-22.04搭建 k8s-1.30.1集群,開啟Dashboard-2.7.0、部署ingress-nginx-1.10.1)