在機器學習中,數據預處理是模型訓練前至關重要的環節,直接影響模型的性能和準確性。通過本次學習,我系統掌握了數據預處理的核心方法與工具,現將主要內容總結如下:
一、缺失值處理
缺失值是實際數據中常見的問題,處理方式主要包括以下幾種:
Pandas 中的缺失值處理
- 識別缺失值:使用
isnull()函數判斷單元格是否為空,可直觀查看數據缺失情況。 - 自定義缺失值標識:通過
na_values參數指定 “n/a”“na” 等字符串作為缺失值標識,確保數據一致性。 - 刪除缺失值:
dropna()函數可刪除包含空字段的行,參數axis(默認 0,刪除行)、how(“any” 有一個空即刪除,“all” 全為空才刪除)等可靈活控制刪除規則。 - 填充缺失值:
fillna()函數用指定值替換空字段,常見方式包括:- 固定值填充(如用 666 填充);
- 均值填充(
mean())、中位數填充(median()),適用于數值型數據,能保留數據整體分布特征。
- 識別缺失值:使用
Scikit-learn 中的缺失值處理
SimpleImputer是處理缺失值的常用工具,支持多種策略:- 均值填補(
strategy="mean"); - 中位數填補(
strategy="median"); - 常數填補(
strategy="constant",需指定fill_value); - 眾數填補(
strategy="most_frequent"),適用于分類特征(如 “Embarked” 港口信息)。
- 均值填補(
二、數據標準化
標準化的核心是將數據轉換為統一規格,消除量綱影響,常見方法包括:
最大最小值標準化(MinMaxScaler)
- 將數據縮放到指定范圍(默認 [0,1]),公式為:Xscaled?=Xmax??Xmin?X?Xmin??。
- 通過
feature_range參數可自定義縮放范圍(如 [5,10])。
Z 值標準化(StandardScaler/scale ())
- 將數據轉換為均值為 0、標準差為 1 的標準正態分布,公式為:Xscaled?=σX?μ?。
scale()函數直接處理數據,StandardScaler以類的形式實現,支持保存均值和標準差用于新數據轉換。
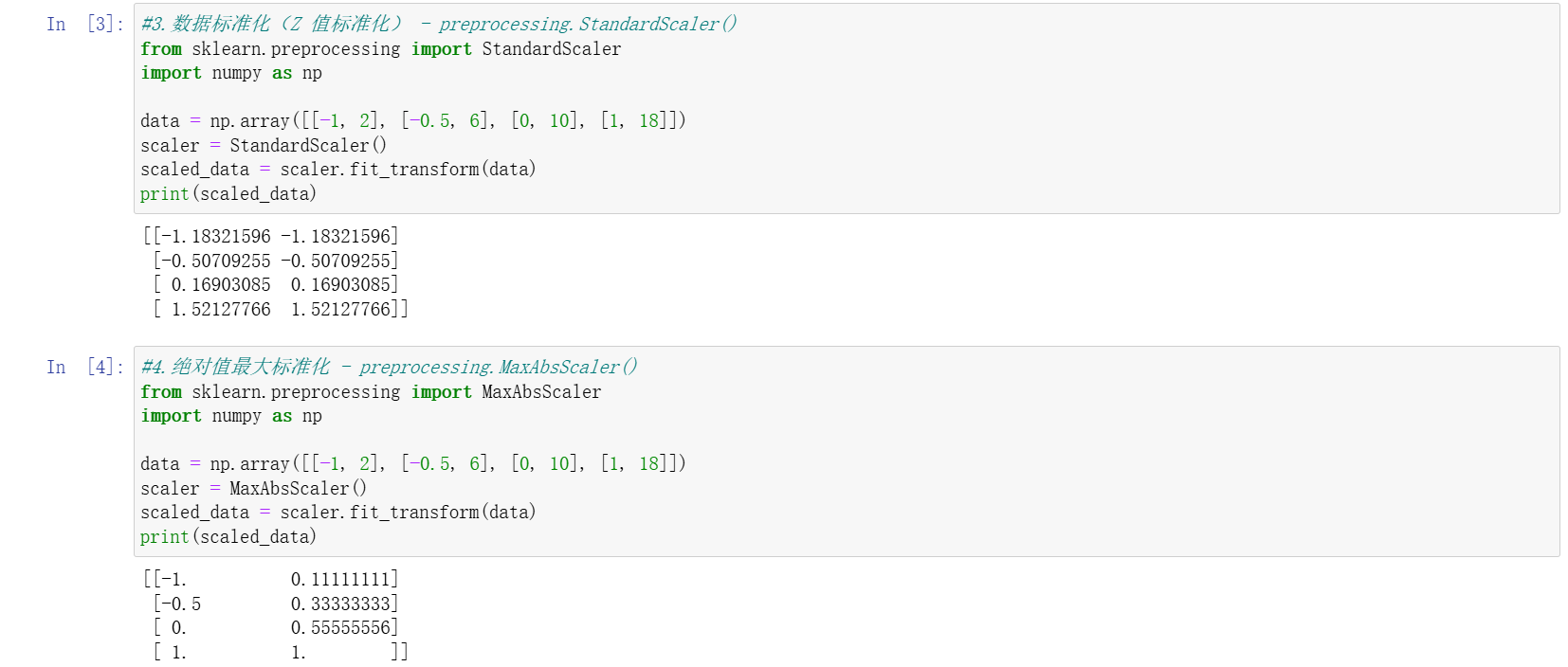
其他標準化方法
MaxAbsScaler:按絕對值最大值縮放,使數據落在 [-1,1] 區間,適用于稀疏數據。RobustScaler:基于中位數和四分位距處理,抗離群值能力強。QuantileTransformer:通過分位數信息將數據映射為均勻或正態分布,適用于偏態數據。PowerTransformer:通過冪變換(如 Box-Cox 變換)將數據映射為近似正態分布,適合需正態假設的模型。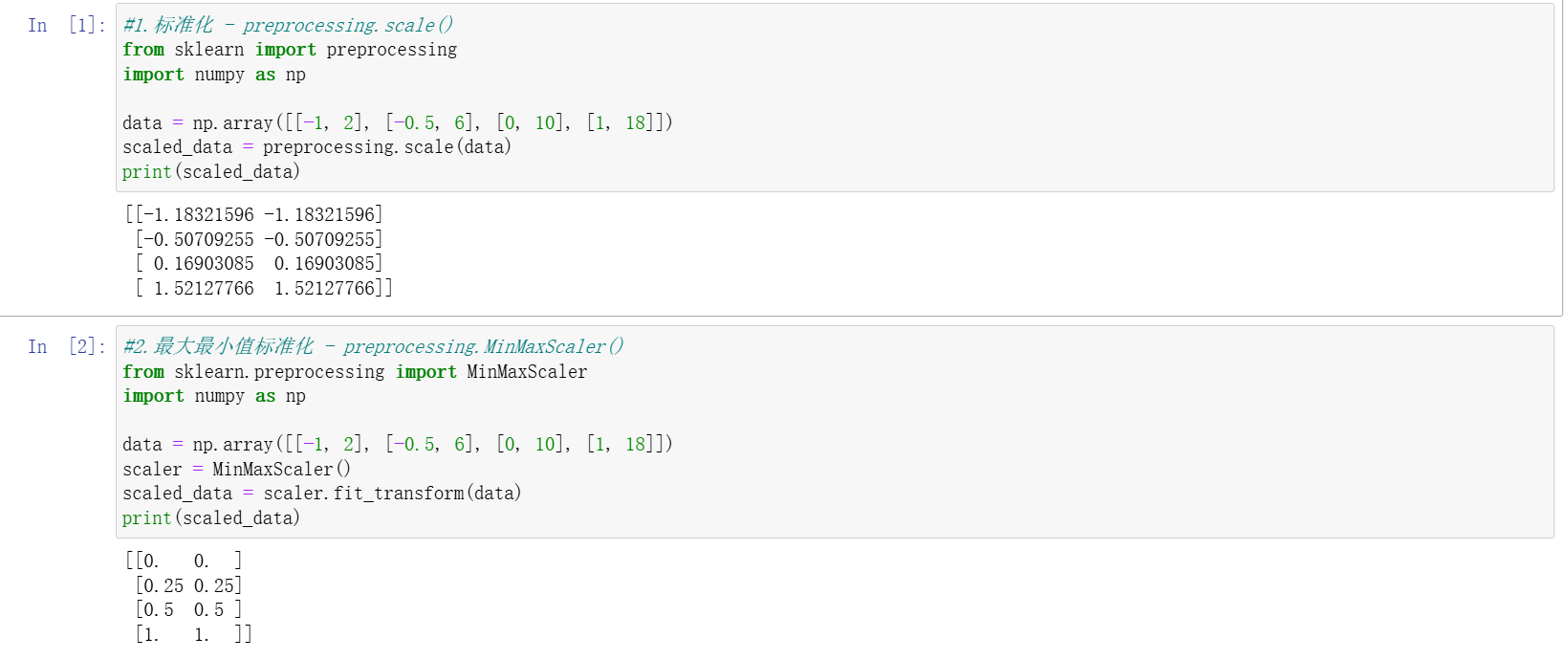

三、特征編碼
將分類特征轉換為數值形式是預處理的關鍵步驟,根據特征類型可分為:
獨熱編碼(OneHotEncoder)
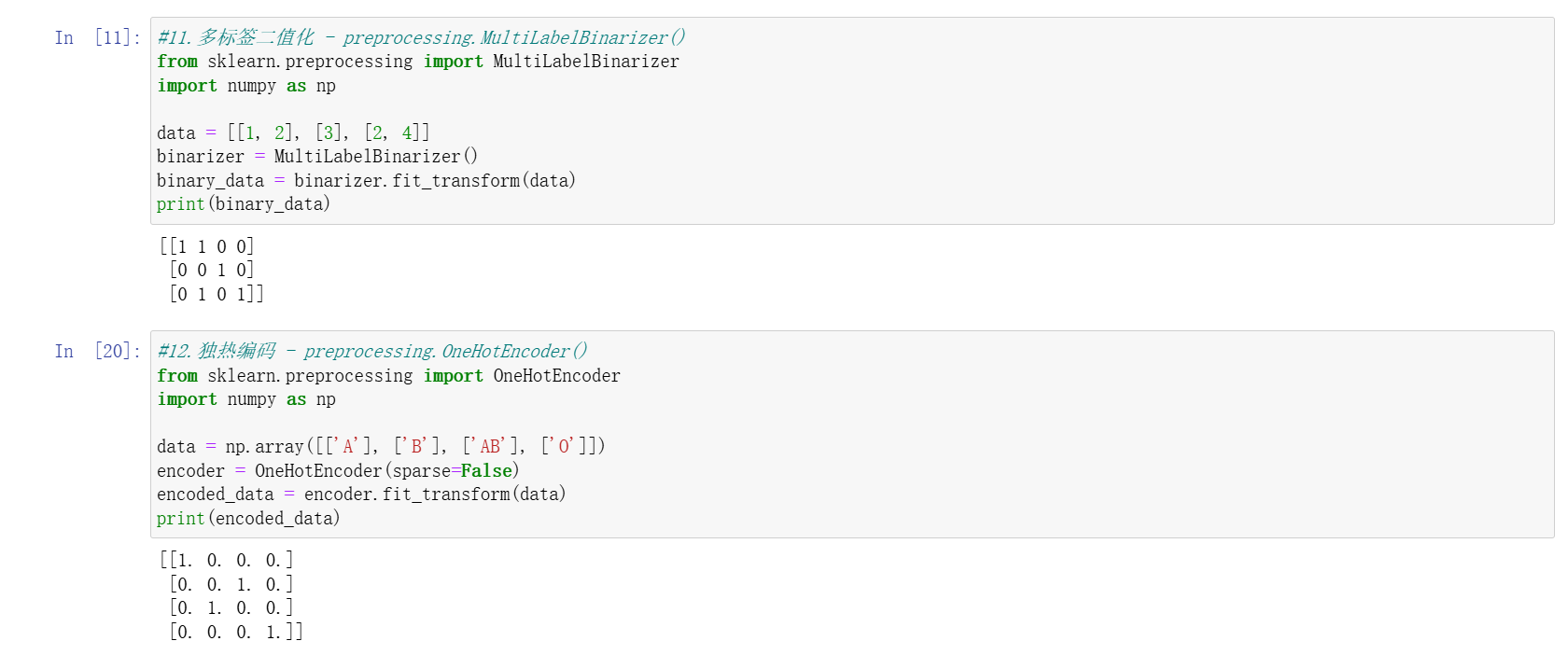
- 為每個類別創建二進制特征,適用于無順序關系的名義變量(如血型 “A/B/AB/O”)。
- 避免模型誤解類別間的數值關聯,如將 “A” 編碼為 (1,0,0,0),“B” 編碼為 (0,1,0,0) 等。
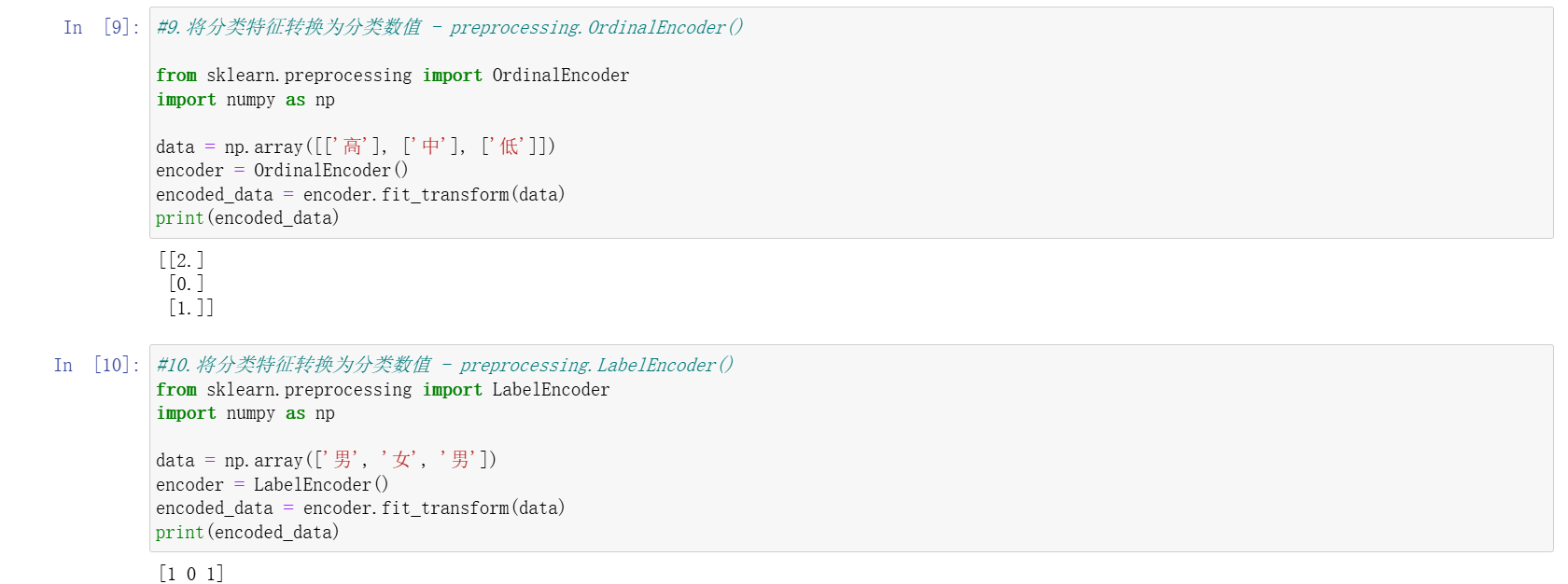
序號編碼(OrdinalEncoder)
- 將有序分類特征轉換為有序整數(如 “高 / 中 / 低” 編碼為 3/2/1),保留類別間的順序關系。
標簽編碼(LabelEncoder)
- 用于一維目標標簽(如 “男 / 女”),轉換為 0/1 等整數,不建議用于輸入特征。
其他編碼方式
MultiLabelBinarizer:對多標簽數據(如一篇文章的多個類別)進行二值化編碼。- 目標標簽編碼:處理無大小關系的目標值,用 0 到 n_classes-1 編碼,但數值本身無實際含義。
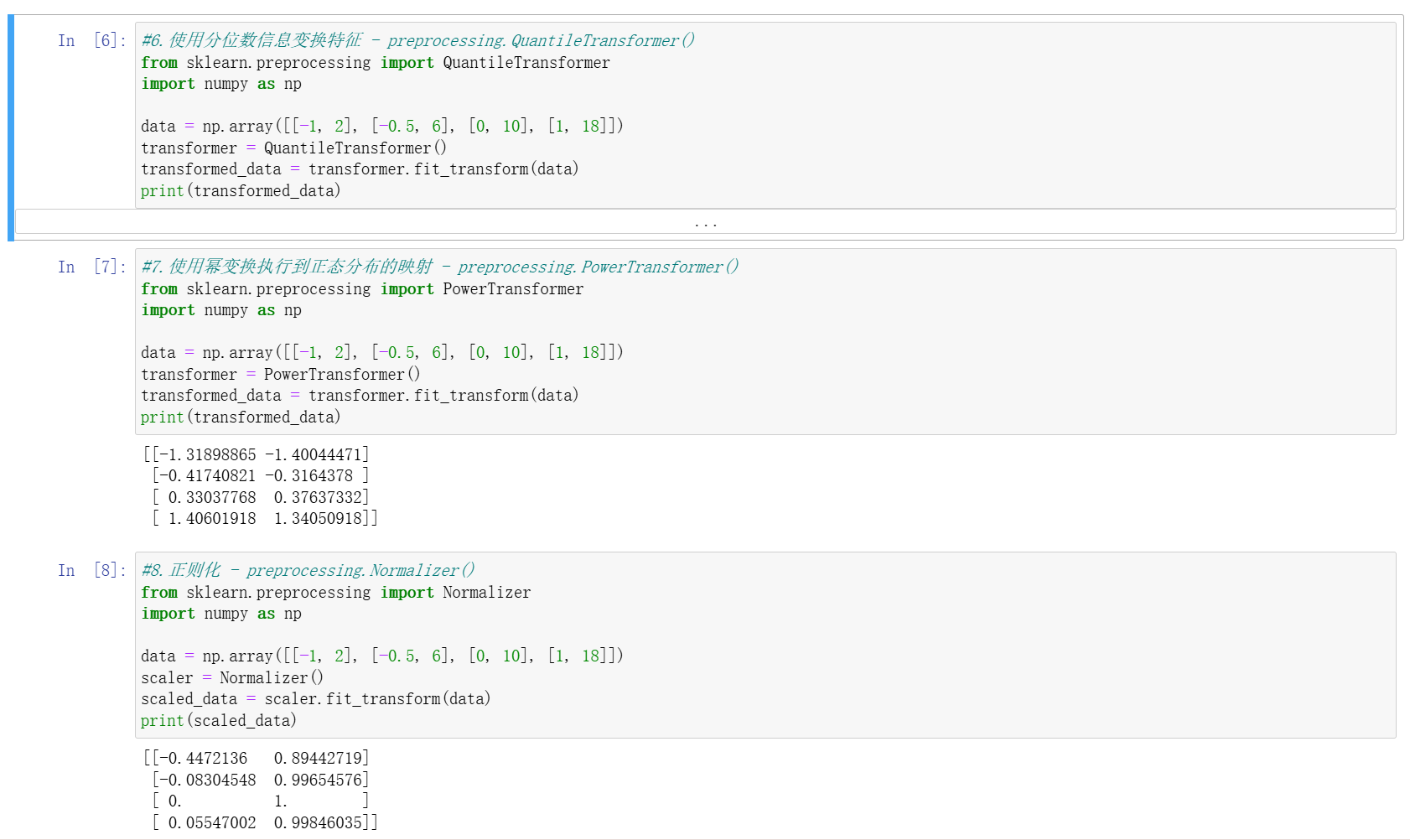
四、數據轉換與離散化
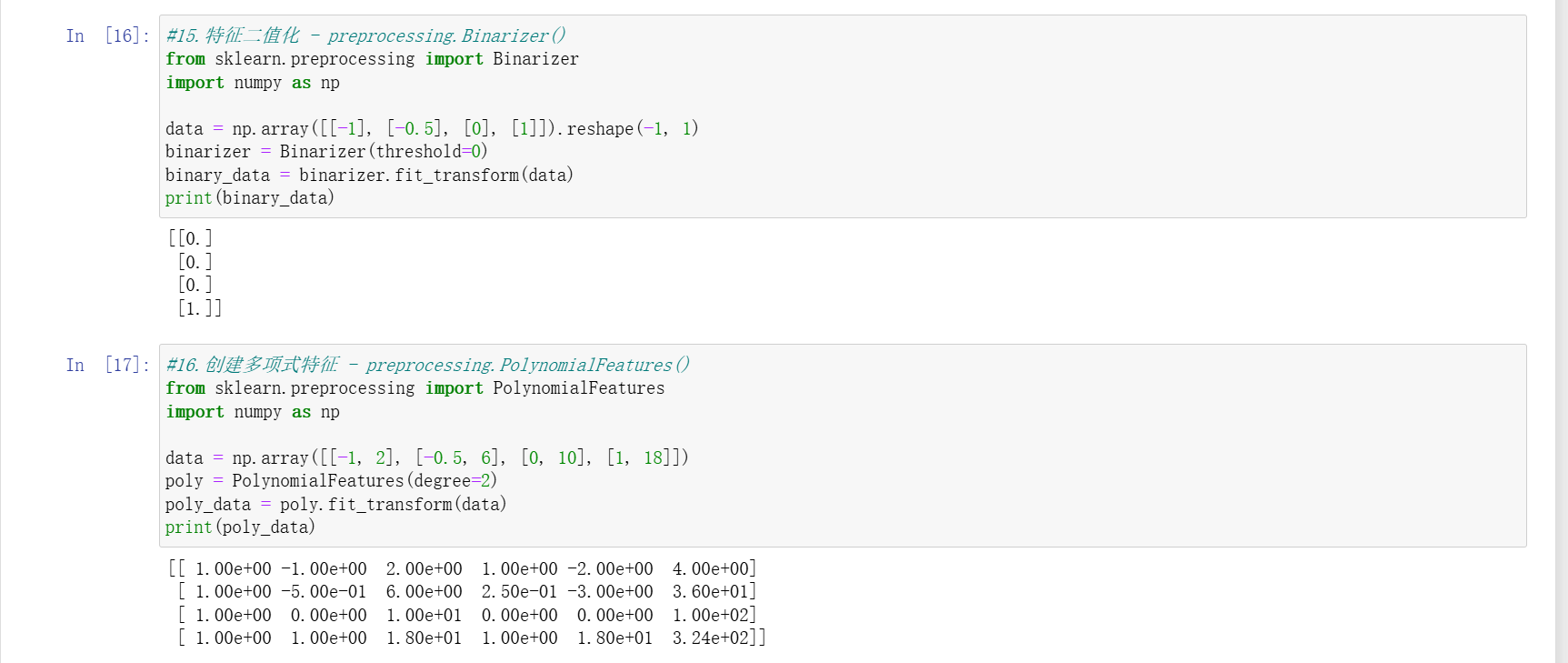
數據二值化(Binarizer)
- 根據閾值將數據分為 0 或 1(如年齡 > 30 為 1,否則為 0),簡化特征表示。
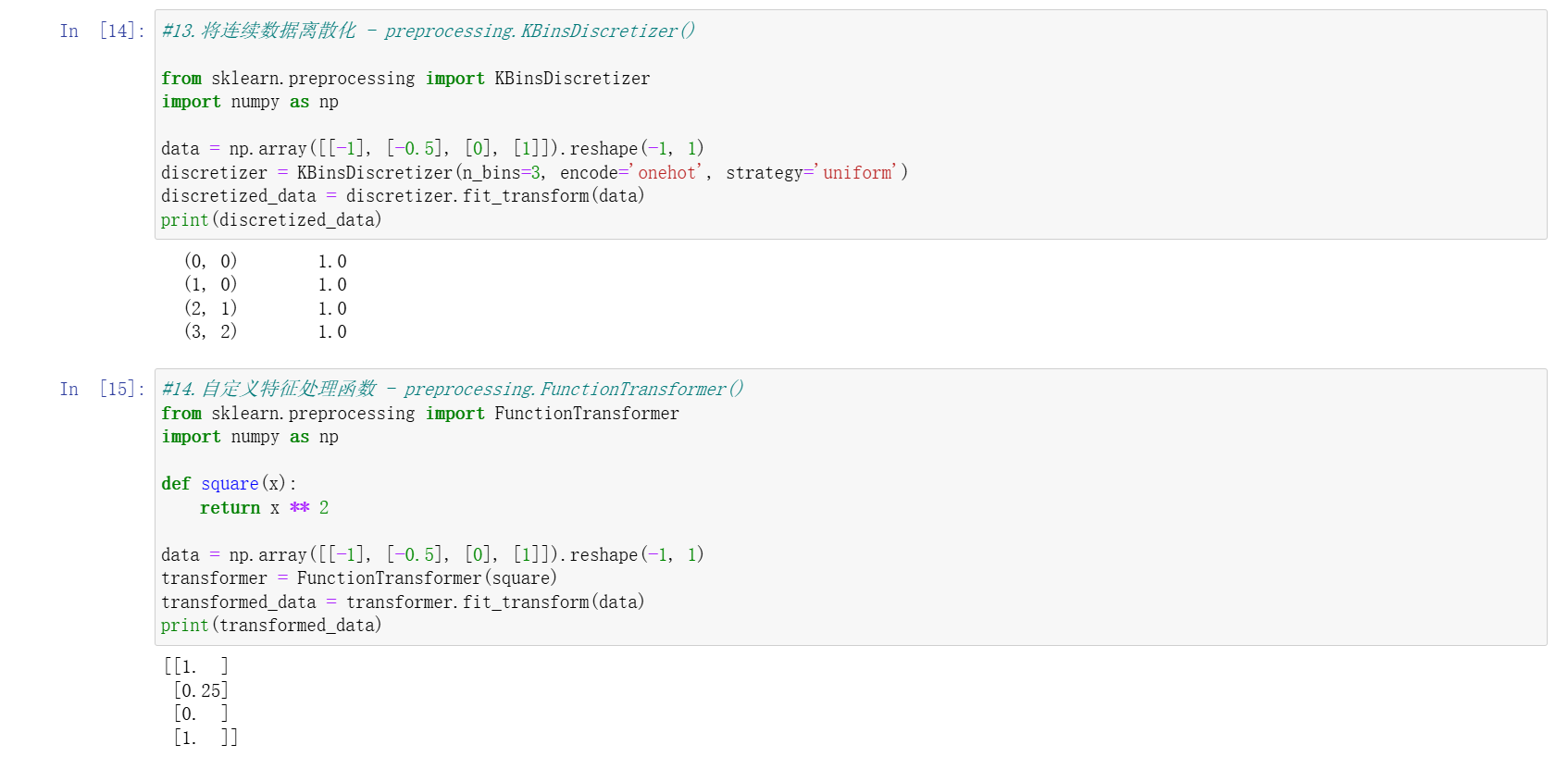
連續數據離散化(KBinsDiscretizer)
- 將連續特征劃分為多個區間(分箱),支持均勻分箱、分位數分箱等策略,可轉換為整數或獨熱編碼。
多項式特征生成(PolynomialFeatures)
- 生成特征的平方項、交叉項等,捕捉特征間的非線性關系,如將 (x1, x2) 擴展為 (1, x1, x2, x12, x1x2, x22)。
自定義特征處理(FunctionTransformer)
- 將自定義函數(如對數變換、平方運算)封裝為轉換器,靈活滿足特定處理需求。

五、總結與應用
數據預處理的核心目標是提升數據質量,使數據更適合模型輸入。實際應用中需根據數據特點選擇合適方法:
- 數值型數據常需標準化或歸一化;
- 分類特征需根據是否有序選擇編碼方式;
- 缺失值和離群值需針對性處理,避免影響模型學習。
掌握scikit-learn的preprocessing模塊和pandas的相關工具,能高效完成預處理流程,為后續模型訓練奠定堅實基礎。
和移動網絡(蜂窩數據)的環境下,使用安卓平板,通過USB數據線(而不是Wi-Fi)來控制電腦(版本2))









)


get報錯注入 過濾select和union ‘閉合)





)