目錄
模板
函數模板
類模板
非類型模板參數
模板的特化
函數模板特化
類模板的特化
為什么普通函數可以分離?
繼承
繼承概念
基類和派生類對象賦值轉換(切割,切片)
隱藏
派生類的默認成員函數
.復雜的菱形繼承及菱形虛擬繼承
繼承的總結和反思
模板
函數模板
函數模板的概念:
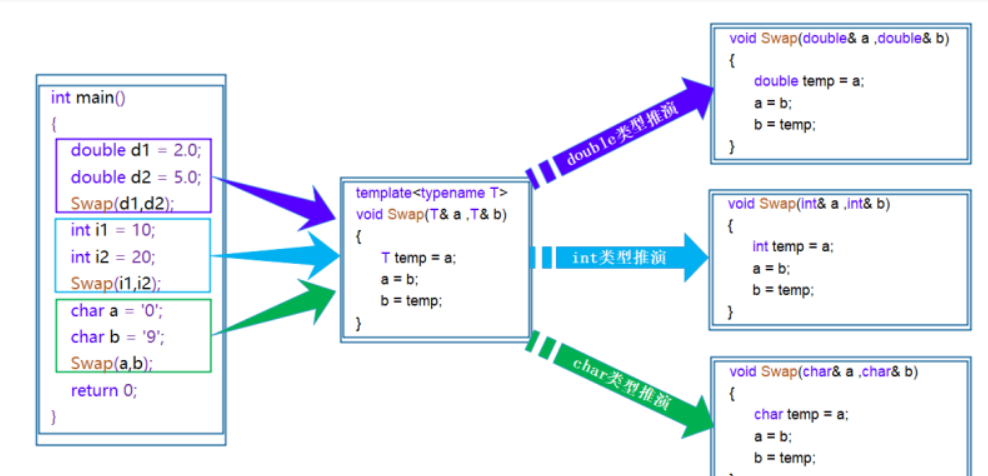
模板函數的語法格式:
template<typename T,typename V>
void Func(T t,V v)
{// ...
}函數模板的原理:
類模板
類模板的概念:
類模板與函數模板一樣代表了一個類家族,該類模板與類型無關,在使用時需要顯示實例化。
類模板的定義格式:
template<class T1, class T2, ..., class Tn>
class 類模板名
{// 類內成員定義
};類模板的實例化
類模板實例化與函數模板實例化不同,類模板實例化需要在類模板名字后跟<>,然后將實例化的類型放在<>中即可,類模板名字不是真正的類,而實例化的結果才是真正的類.
非類型模板參數
namespace bite
{// 定義一個模板類型的靜態數組template<class T, size_t N = 10>class array{public:T& operator[](size_t index){return _array[index];}const T& operator[](size_t index)const{return _array[index];}size_t size()const{return _size;}bool empty()const{return 0 == _size;}private:T _array[N];size_t _size;};
}模板的特化
概念:通常情況下,使用模板可以實現一些與類型無關的代碼,但對于一些特殊類型的可能會得到一些錯誤的結果,需要特殊處理,比如:實現了一個專門用來進行小于比較的函數模板。
函數模板特化
template<class T>//針對所有類型
bool Less(T left, T right)
{return left < right;
}template<> //對于int類型的特化,當傳入int類型時,會執行該函數
bool Less<int>(int left,int right)
{return left<right
}類模板的特化
1.全特化:將模板參數列表中所有的參數都確定化
template<class T1, class T2>
class Data
{
public:Data() {cout<<"Data<T1, T2>" <<endl;}
private:T1 _d1;T2 _d2;
};
template<>
class Data<int, char>
{
public:Data() {cout<<"Data<int, char>" <<endl;}
private:int _d1;char _d2;
}2.偏特化:任何針對模版參數進一步進行條件限制設計的特化版本。比如對于以下模板類:
template<class T1, class T2>
class Data
{
public:Data() {cout<<"Data<T1, T2>" <<endl;}
private:T1 _d1;T2 _d2;
};偏特化有兩種表現方式:
1 部分特化,將模板參數類表中的一部分參數特化
// 將第二個參數特化為int
template <class T1>
class Data<T1, int>
{
public:Data() {cout<<"Data<T1, int>" <<endl;}
private:T1 _d1;int _d2;
};2.參數跟進一步的限制
//兩個參數偏特化為指針類型
template <typename T1, typename T2>
class Data <T1*, T2*>
{
public:Data() {cout<<"Data<T1*, T2*>" <<endl;}private:
T1 _d1;T2 _d2;
};模板聲明和定義不支持分離寫道.h,和.cpp中
原因:編譯器在編譯時,是對每個文件進行獨立編譯,如果分開定義,我們在編譯時由于是模板,沒有實例化,編譯器不知道該如何生成這段代碼,所以不會編譯這段代碼,在調用時由于沒有具體的函數地址,則無法被編譯器所識別。
// add.h(聲明,放頭文件)
template <typename T>
T add(T a, T b); // 只聲明,不定義// add.cpp(定義,放源文件)
#include "add.h"
template <typename T>
T add(T a, T b) { // 定義實現return a + b;
}// main.cpp(使用模板)
#include "add.h"
int main() {add(1, 2); // 嘗試使用 add<int>return 0;
}-
編譯?
main.cpp?時,編譯器無法生成?add<int>:
main.cpp?只包含?add.h,只能看到模板的聲明,看不到?add.cpp?中的定義。沒有完整定義,編譯器不知道如何生成?add<int>?的實際代碼,只能暫時記下 “需要一個?add<int>?函數”。 -
編譯?
add.cpp?時,編譯器也不會生成?add<int>:
add.cpp?中有模板的完整定義,但編譯器不知道?main.cpp?會用?int?類型實例化它。C++ 標準規定:編譯器不會主動為模板生成所有可能的實例(因為類型是無限的,比如?int、double、string?等),只會在看到具體實例化請求時才生成。 -
鏈接階段報錯:
鏈接器需要把?main.cpp?中對?add<int>?的引用和實際代碼關聯起來,但此時兩個目標文件中都沒有?add<int>?的二進制指令,因此會報 “未定義的引用” 錯誤。
為什么普通函數可以分離?
普通函數(非模板)的聲明和定義可以分離,因為:
?- 編譯器在編譯?
.cpp?時會為普通函數生成完整的二進制指令(比如?int add(int a, int b)?的代碼會直接生成在?add.o?中)。 - 鏈接時,
main.o?中對?add?的引用可以直接找到?add.o?中的二進制代碼。
而模板函數沒有 “默認生成” 的代碼,必須等待具體類型的實例化請求,這就要求實例化時必須能看到完整定義,所以我們建議將模板的聲明和定義放到一個文件中
繼承
繼承概念
基類和派生類對象賦值轉換(切割,切片)
派生類對象 可以賦值給 基類的對象 / 基類的指針 / 基類的引用。這里有個形象的說法叫切片或者切割。寓意把派生類中父類那部分切來賦值過去。
基類對象不能賦值給派生類對象。
基類的指針或者引用可以通過強制類型轉換賦值給派生類的指針或者引用。但是必須是基類的指針是指向派生類對象時才是安全的。這里基類如果是多態類型,可以使用RTTI(RunTime Type Information)的dynamic_cast 來進行識別后進行安全轉換
隱藏
1. 在繼承體系中基類和派生類都有獨立的作用域。
2. 子類和父類中有同名成員,子類成員將屏蔽父類對同名成員的直接訪問,這種情況叫隱藏,也叫重定義。(在子類成員函數中,可以使用 基類::基類成員 顯示訪問)且不構成重寫
3. 需要注意的是如果是成員函數的隱藏,只需要函數名相同就構成隱藏。
4. 注意在實際中在繼承體系里面最好不要定義同名的成員
派生類的默認成員函數
1. 派生類的構造函數必須調用基類的構造函數初始化基類的那一部分成員。如果基類沒有默認
的構造函數,則必須在派生類構造函數的初始化列表階段顯示調用。
2. 派生類的拷貝構造函數必須調用基類的拷貝構造完成基類的拷貝初始化。
3. 派生類的operator=必須要調用基類的operator=完成基類的復制。
4. 派生類的析構函數會在被調用完成后自動調用基類的析構函數清理基類成員。因為這樣才能
保證派生類對象先清理派生類成員再清理基類成員的順序。
5. 派生類對象初始化先調用基類構造再調派生類構造。
6. 派生類對象析構清理先調用派生類析構再調基類的析構。
7. 因為后續一些場景析構函數需要構成重寫,重寫的條件之一是函數名相同那么編譯器會對析構函數名進行特殊處理,處理成destrutor(),所以父類析構函數不加virtual的情況下,子類析構函數和父類析構函數構成隱藏關系。
.復雜的菱形繼承及菱形虛擬繼承
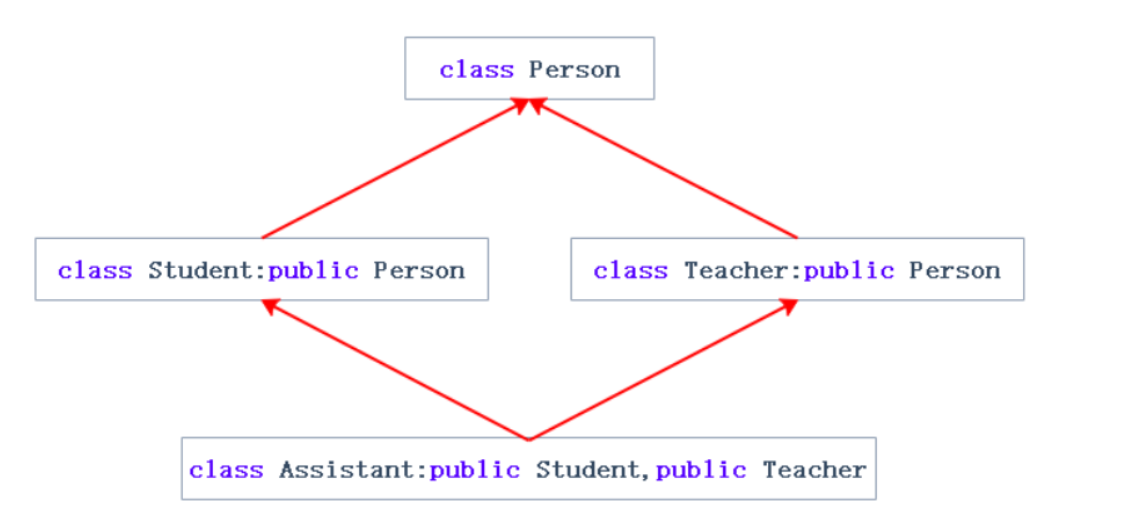
class Person
{string _name;
}:class Student :public Person
{int _num
};class Teacher : public Person
{int _id;
};class Assitant: public Student,public Teacher
{stirng _majorCourse;
};void Test ()
{// 這樣會有二義性無法明確知道訪問的是哪一個Assistant a ;
a._name = "peter";
// 需要顯示指定訪問哪個父類的成員可以解決二義性問題,但是數據冗余問題無法解決a.Student::_name = "xxx";a.Teacher::_name = "yyy";
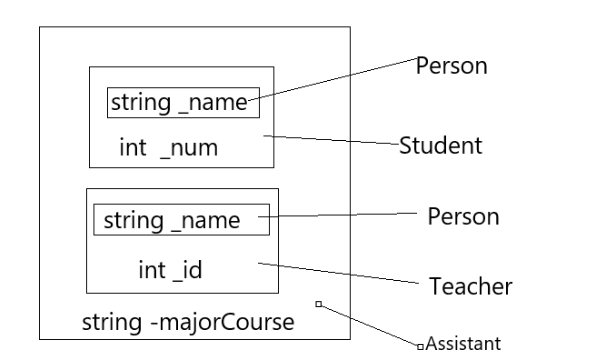
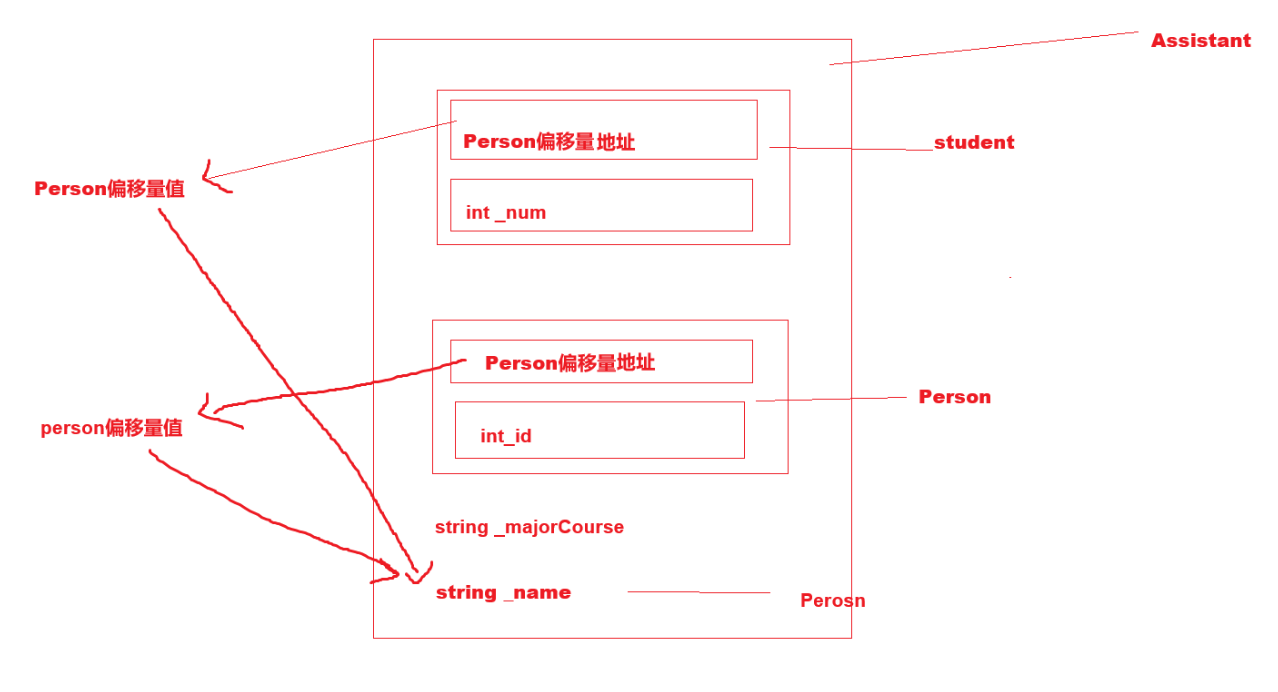
}class Person
{
public :string _name ; // 姓名
};
class Student : virtual public Person
{
protected :int _num ; //學號
};
class Teacher : virtual public Person
{
protected :int _id ; // 職工編號
};
class Assistant : public Student, public Teacher
{
protected :string _majorCourse ; // 主修課程
};
void Test ()
{Assistant a ;a._name = "peter";
}class A
{
public:int _a;
};
// class B : public A
class B : virtual public A
{
public:int _b;
};
// class C : public A
class C : virtual public A
{
public:int _c;
};
class D : public B, public C
{
public:int _d;
};
int main()
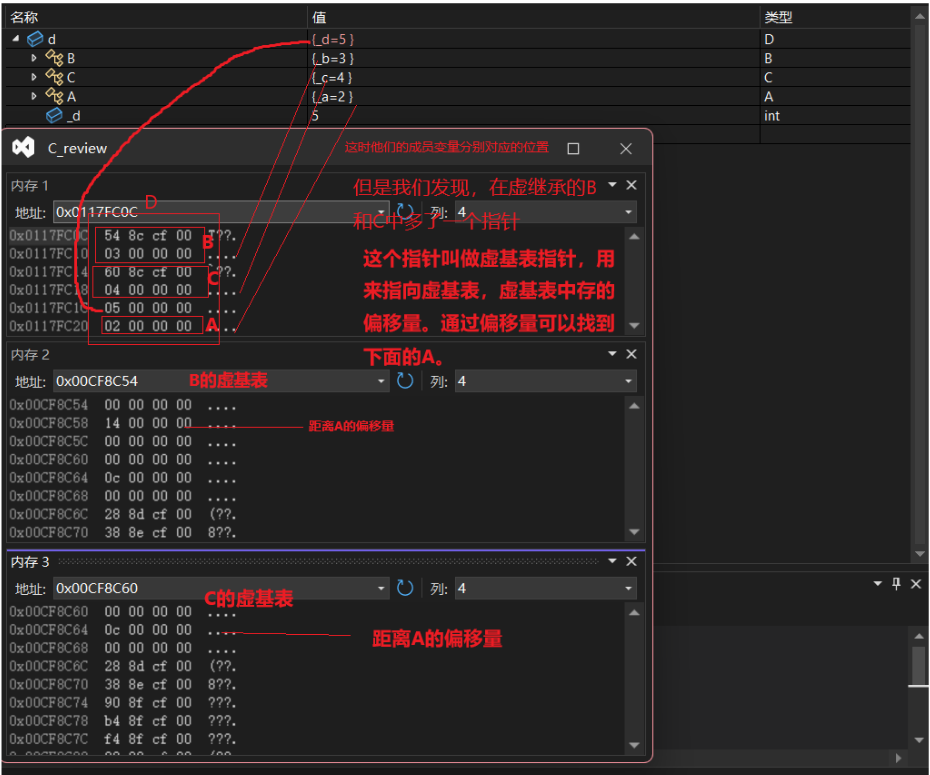
{D d;d.B::_a = 1;d.C::_a = 2;d._b = 3;d._c = 4;d._d = 5;return 0;
}下圖是菱形繼承的內存對象成員模型:可以發現有數據冗余問題
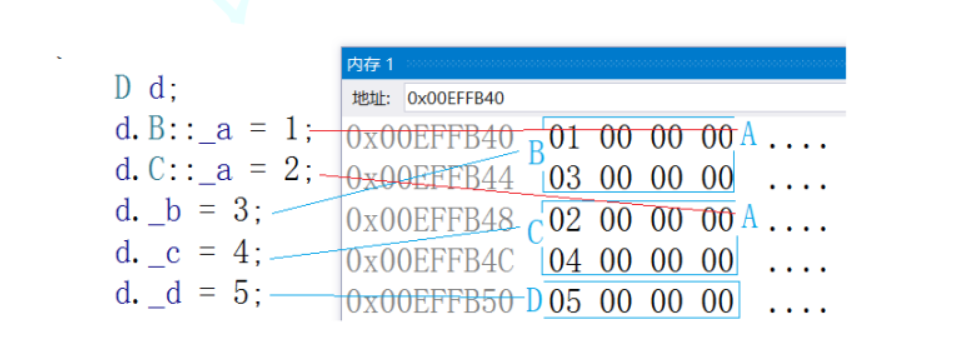
下圖是菱形虛擬繼承的內存對象成員模型:這里可以分析出D對象中將A放到的了對象組成的最下面,這個A同時屬于B和C,那么B和C如何去找到公共的A呢?這里是通過了B和C的兩個指針,指向的一張表。這兩個指針叫虛基表指針,這兩個表叫虛基表。虛基表中存的偏移量。通過偏移量可以找到下面的A。
繼承的總結和反思
1. 很多人說C++語法復雜,其實多繼承就是一個體現。有了多繼承,就存在菱形繼承,有了菱形繼承就有菱形虛擬繼承,底層實現就很復雜。所以一般不建議設計出多繼承,一定不要設計出菱形繼承。否則在復雜度及性能上都有問題。
2. 多繼承可以認為是C++的缺陷之一,很多后來的OO語言都沒有多繼承,如Java。
3. 繼承和組合
public繼承是一種is-a的關系。也就是說每個派生類對象都是一個基類對象。
組合是一種has-a的關系。假設B組合了A,每個B對象中都有一個A對象。
優先使用對象組合,而不是類繼承 。
繼承允許你根據基類的實現來定義派生類的實現。這種通過生成派生類的復用通常被稱為白箱復用(white-box reuse)。術語“白箱”是相對可視性而言:在繼承方式中,基類的內部細節對子類可見 。繼承一定程度破壞了基類的封裝,基類的改變,對派生類有很大的影響。派生類和基類間的依賴關系很強,耦合度高。
對象組合是類繼承之外的另一種復用選擇。新的更復雜的功能可以通過組裝或組合對象來獲得。對象組合要求被組合的對象具有良好定義的接口。這種復用風格被稱為黑箱復用(black-box reuse),因為對象的內部細節是不可見的。對象只以“黑箱”的形式出現。組合類之間沒有很強的依賴關系,耦合度低。優先使用對象組合有助于你保持每個類被封裝。
實際盡量多去用組合。組合的耦合度低,代碼維護性好。不過繼承也有用武之地的,有些關系就適合繼承那就用繼承,另外要實現多態,也必須要繼承。類之間的關系可以用繼承,可以用組合,就用組合。


get報錯注入 過濾select和union ‘閉合)





)





)




