1 認識文本預處理
-
概念:
- 文本語料在輸送給模型前一般需要一系列的預處理工作,才能符合模型輸入的要求;
- 比如:將文本轉化成模型需要的張量、規范張量的尺寸;
- 比如:
- 關于數據X:數據有沒有臟數據、數據長度分布情況等;
- 關于標簽Y:分類問題查看標簽是否均勻;
-
作用:
- 指導模型超參數的選擇 、提升模型的評估指標;
- 大白話:文本預處理的工作,就是準備出模型需要的x、y,然后送給模型;
-
主要環節:
-
文本處理的基本方法(先拆分、標注文本)
- 分詞:把長句子切成詞語(比如“我喜歡自然語言處理”→“我/喜歡/自然語言/處理”);
- 詞性標注:給詞語貼標簽(動詞、名詞等,比如“喜歡”是動詞);
- 命名實體識別:找出人名、地名、機構名(比如“北京有個清華大學”→識別出“北京”是地名,“清華大學”是機構名);
-
文本張量表示方法(把文本轉成模型能計算的數字)
- one-hot編碼:用0和1表示詞語,簡單但容易“詞多爆內存”;
- Word2vec/Word Embedding:讓意思相近的詞數字更像(比如“貓”和“狗”的向量比“貓”和“桌子”更接近),能抓語義關系;
-
文本語料的數據分析(檢查數據質量、找規律)
- 統計標簽數量、句子長度,畫出詞云(比如發現“垃圾郵件”標簽太多/太少,或者句子太長模型難處理),幫你判斷數據合不合理,需不需要調整;
-
文本特征處理(給模型加“額外信息”)
- 添加n-gram特征:不只看單個詞,還看詞語搭配(比如“機器學習”一起出現,比單獨“機器”+“學習”信息更多);
- 規范文本長度:把句子統一成差不多長度(太短補一補,太長砍一砍),方便模型處理;
-
數據增強方法(數據不夠?“造”點新數據)
- 回憶數據增強法(比如同義替換、回譯):沒太多數據時,把句子換種說法(“我很開心”→“我非常高興”),讓模型見更多樣的表達,避免學偏。
-
2 文本處理的基本方法
2.1 分詞
2.1.1 概述
-
分詞:將連續的字序列按照一定的規范重新組合成詞序列的過程;
-
作用:
- 詞作為語言語義理解的最小單元,是人類理解文本語言的基礎;
- 是AI解決NLP領域高階任務,如自動問答、機器翻譯、文本生成的重要基礎環節;
-
英文是不需要分詞的,因為英文中的空格是天然的分解符,而中文沒有明顯的分解符。
-
例:
騰訊是一家上市公司,旗下有微信、QQ等產品,我們平時主要通過微信聯系。 騰訊/是/一家/上市公司/,/旗下/有/微信/、/QQ/等/產品/,/我們/平時/主要/通過/微信/聯系/。
2.1.2 jieba分詞器
-
jieba——目前流行的中文分詞工具
import jieba-
支持三種分詞模式(分詞粒度):
-
精確模式:默認分詞模式,試圖將文本精確切分,減少冗余和歧義,適用于文本分析、文本挖掘等需要精準詞語劃分的任務,調用方法為
jieba.cut(text, cut_all=False);cut_all=False:關閉全模式,開啟精確模式; -
全模式:會掃描出句子中所有可能成詞的詞語,分詞速度快,但無法解決分詞歧義問題,適用于需要盡可能多地提取詞語,對準確性要求不高的場景 ,調用方法為
jieba.cut(text, cut_all=True); -
搜索引擎模式:在精確模式基礎上,對長詞再次進行切分,增加分詞的粒度,提高召回率,適合用于搜索引擎構建索引、處理用戶查詢等場景,調用方法為
jieba.cut_for_search(text);
-
-
支持中文繁體分詞,支持用戶自定義詞典;
-
-
jieba.cutVSjieba.lcutjieba.cut:- 返回的是一個生成器對象。生成器是一種特殊的迭代器,它并不會一次性將所有分詞結果加載到內存中,而是在迭代過程中按需生成。這樣在處理大量文本時,能顯著減少內存占用,提升程序運行效率;
- 適合處理文本量非常大的情況,比如處理大規模的文本語料庫、流式讀取文件中的文本并進行分詞等,通過迭代方式逐個獲取分詞結果,能有效控制內存使用;
jieba.lcut:- 返回的是一個列表,即一次性將所有分詞結果以列表形式存儲在內存中。在處理小量文本時,使用列表便于直接進行后續操作,如統計詞頻、篩選特定詞語等;但處理大量文本時,若內存不足,可能導致程序崩潰;
- 適用于文本量較小,需要立即對所有分詞結果進行統一操作的場景,如對一篇短文章進行分詞后,馬上統計詞頻、進行詞性標注等操作,因為可以直接通過索引等方式訪問列表中的元素;
-
用戶自定義詞典時,遵循以下格式:
詞語 詞頻 詞性- 詞語:希望 jieba 優先識別的自定義詞匯(比如專業術語、新造詞等)
- 詞頻:數字表示 “建議的分詞優先級”(數值越小,越優先被識別),主要用于調整分詞權重
- 詞性:可選的詞性標注(如
n名詞、nz其他專名),jieba 支持自定義詞性,也可忽略(但格式上需保留空格占位)
-
jieba詞性對照表
a 形容詞ad 副詞ag 形容詞性語素an 名形詞 b 區別詞 c 連詞 d 副詞dfdg 副語素 e 嘆詞 f 方位詞 g 語素 h 前接成分 i 成語 j 簡稱略稱 k 后接成分 l 習用語 m 數詞mgmq 數量詞 n 名詞ng 名詞性語素nr 人名nrfgnrtns 地名nt 機構團體名nz 其他專名 o 擬聲詞 p 介詞 q 量詞 r 代詞rg 代詞性語素rr 人稱代詞rz 指示代詞 s 處所詞 t 時間詞tg 時語素u 助詞ud 結構助詞 得ug 時態助詞uj 結構助詞 的ul 時態助詞 了uv 結構助詞 地uz 時態助詞 著 v 動詞vd 副動詞vg 動詞性語素vi 不及物動詞vn 名動詞vq x 非語素詞 y 語氣詞 z 狀態詞zg
2.1.3 例
-
例:三種分詞模式
content = "騰訊是一家上市公司,旗下有微信、QQ等產品,我們平時主要通過微信聯系。"# 精確模式 myobj1 = jieba.cut(sentence=content, cut_all= False) print('myobj1-->', myobj1) mydata1 = jieba.lcut(sentence=content, cut_all=False) print('mydata1-->', mydata1) # 全模式 myobj2 = jieba.cut(sentence=content, cut_all=True) print('myobj2-->', myobj2) mydata2 = jieba.lcut(sentence=content, cut_all=True) print('mydata2-->', mydata2) # 搜索引擎模式 myobj3 = jieba.cut_for_search(sentence=content) print('myobj3-->', myobj3) mydata3 = jieba.lcut_for_search(sentence=content) print('mydata3-->', mydata3)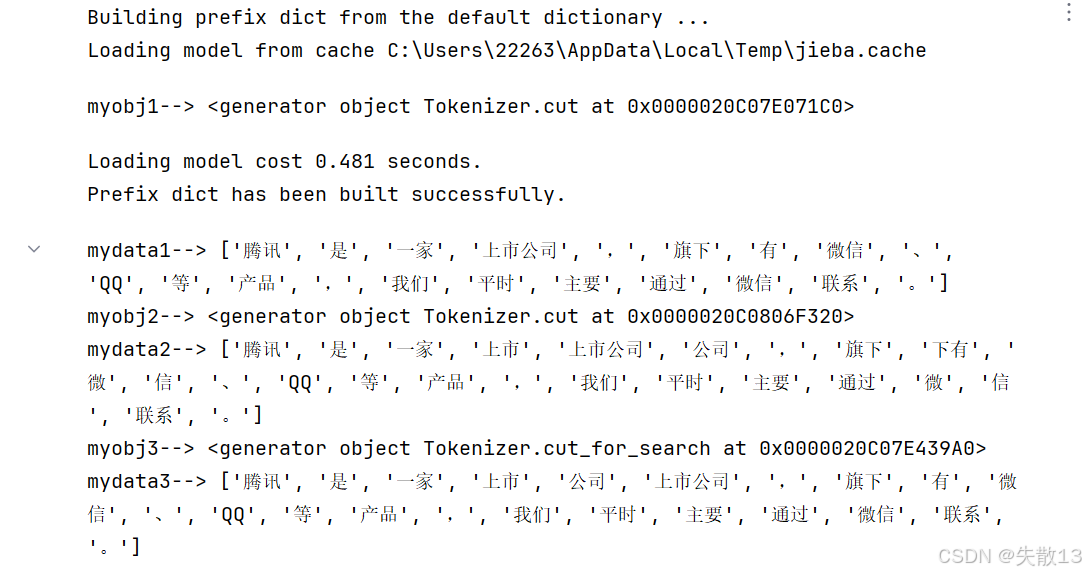
-
例:支持繁體分詞
# 支持繁體分詞 content = "煩惱即是菩提,我暫且不提" mydata = jieba.lcut(content) print('mydata-->', mydata)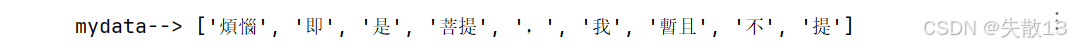
-
例:支持用戶自定義詞典
# 支持用戶自定義詞典 # 不使用用戶字典 content = "騰訊是一家上市公司,旗下有王者榮耀、和平精英等游戲,但還是要少玩游戲" mydata1 = jieba.lcut(sentence=content, cut_all=False) print('mydata1-->', mydata1)# 使用用戶字典 """ 上市 王者榮耀 1 n 和平精英 2 n """ jieba.load_userdict('data/userdict.txt') mydata2 = jieba.lcut(sentence=content, cut_all=False) print('mydata2-->', mydata2)
2.2 命名實體識別
-
命名實體:將人名、地名、機構名等專有名詞統稱命名實體。如:周杰倫、黑山縣、孔子學院、24輥方鋼矯直機……
-
命名實體識別(Named Entity Recognition,簡稱NER),識別出一段文本中可能存在的命名實體;
-
命名實體也是人類理解文本的基礎單元,是AI解決NLP領域高階任務的重要基礎環節;
-
例:
魯迅,浙江紹興人,五四新文化運動的重要參與者,代表作朝花夕拾。 魯迅(人名) / 浙江紹興(地名)人 / 五四新文化運動(專有名詞) / 重要參與者 / 代表作 / 朝花夕拾(專有名詞)
2.3 詞性標注
-
詞性:語言中對詞的一種分類方法,以語法特征為主要依據、兼顧詞匯意義對詞進行劃分的結果;
-
詞性標注(Part-Of-Speech tagging,簡稱POS),標注出一段文本中每個詞匯的詞性;
-
詞向標注作用:對文本語言的另一個角度的理解,AI解決NLP領域高階任務的重要基礎環節;
-
例:
我愛自然語言處理 我/rr,愛/v,自然語言/n,處理/vnrr:人稱代詞 v:動詞 n:名詞 vn:動名詞 -
例:
# 詞性標注 import jieba.posseg as pseg mydata1 = pseg.lcut("我愛北京天安門") print('mydata1-->', mydata1)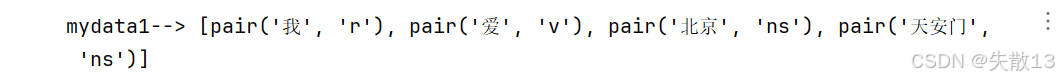
3 文本張量的表示方式
3.1 概念
-
文本張量表示:使用張量來表示一段文本,將計算機無法理解的文本轉換成計算機可以計算的向量形式;
-
表示詞的向量成為詞向量,那么表示一句話就是一個詞向量矩陣;
-
例:
["人生", "該", "如何", "起頭"] # 上面每個詞對應下面矩陣中的一個向量 [[1.32, 4.32, 0.32, 5.2], [3.1, 5.43, 0.34, 3.2], [3.21, 5.32, 2, 4.32], [2.54, 7.32, 5.12, 9.54]] -
NLP中文本詞向量表示的常用方法:
- One-Hot編碼
- Word2vec
- Word Embedding
3.2 One-Hot編碼
-
One-Hot編碼(One-Hot Encoding),也叫稀疏詞向量表示
- One-Hot編碼是將分類變量轉換為數字格式的常用方法,通常用于AI任務中處理分類標簽y數據
- 在One-Hot編碼中,對于一個具有n個不同類別的分類變量,將其表示為一個n維的向量。其中只有一個維度的值為1(代表該樣本屬于這個類別),其他維度的值均為0;
-
例:
["紅色"、"綠色"、"藍色"] [[1, 0, 0], [0, 1, 0], [0, 0, 1]]["人生", "該", "如何", "起頭"] [[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]] -
例:One-Hot編碼的生成
import jieba from tensorflow.keras.preprocessing.text import Tokenizer import joblibpip install tensorflow
# One-Hot編碼的生成 # 定義詞匯表 vocabs = ["周杰倫", "陳奕迅", "王力宏", "李宗盛", "吳亦凡", "鹿晗"]# 創建Tokenizer對象,用于文本處理和編碼轉換 # Tokenizer是Keras中用于文本預處理的工具,能將文本轉換為整數序列或one-hot編碼 mytokenizer = Tokenizer() print('mytokenizer-->', mytokenizer)# 使用詞匯表訓練Tokenizer,構建詞匯索引 # fit_on_texts()方法會遍歷輸入的文本列表,統計詞頻并生成詞匯表 mytokenizer.fit_on_texts(vocabs) # 打印index_word屬性:鍵是整數索引,值是對應的詞語(索引從1開始) print('mytokenizer.index_word-->', mytokenizer.index_word) # 打印word_index屬性:鍵是詞語,值是對應的整數索引(與index_word互為反向映射) print('mytokenizer.word_index-->', mytokenizer.word_index)# 遍歷詞匯表中的每個詞語,手動生成One-Hot編碼 for vorcab in vocabs:# 創建一個全為0的列表,長度等于詞匯表大小(即6個元素)zero_list = [0] * len(mytokenizer.index_word)# 獲取當前詞語在word_index中的索引,減1是為了對應列表的0開始索引idx = mytokenizer.word_index[vorcab] - 1# 將對應位置設為1,形成One-Hot編碼(只有一個位置為1,其余為0)print(vorcab, '的Ont-Hot編碼是:', zero_list)# 使用joblib保存訓練好的Tokenizer對象到指定路徑 # 保存后可在其他地方通過joblib.load()加載復用,避免重復訓練 joblib.dump(value=mytokenizer, filename='data/mytokenizer' ) print('保存mytokenizer END')
-
例:One-Hot編碼的使用
mytokenizer = joblib.load('data/mytokenizer') # 定義要進行One-Hot編碼的目標詞語 token1 = "李宗盛" # 創建一個全為0的列表,長度與詞匯表(vocabs)的元素數量一致 zero_list1 = [0] * len(vocabs) # 檢查詞匯是否在Tokenizer的詞匯表中 if token1 in mytokenizer.word_index: # 通過加載好的Tokenizer,獲取目標詞語對應的索引,再減1轉換為列表的0起始下標# mytokenizer.word_index 是一個字典,鍵是詞語,值是該詞語在Tokenizer中的索引(從1開始)idx1 = mytokenizer.word_index[token1] - 1# 將對應下標的位置置為1,完成One-Hot編碼(只有對應位置為1,其余為0)zero_list1[idx1] = 1print(token1, '的One-Hot編碼是:', zero_list1) else:print(f"{token1}不在詞匯表中")token2 = "狗蛋兒" zero_list2 = [0] * len(vocabs) if token2 in mytokenizer.word_index: idx2 = mytokenizer.word_index[token2] - 1zero_list2[idx2] = 1print(token2, '的One-Hot編碼是:', zero_list2) else:print(f"{token2}不在詞匯表中")
-
優點:操作簡單,容易理解;
-
缺點:完全割裂了詞與詞之間的聯系;如果在大語料集下,每個向量的長度過大,會占據大量內存;屬于稀疏詞向量表示;
-
正因為One-Hot編碼隔離了詞和詞的聯系,又易浪費內存空間,所以出現了稠密向量的表示方法:
- Word2vec
- Word Embedding
3.3 Word2vec模型
3.3.1 概述
-
Word2vec模型是一種將單詞轉換為詞向量的自然語言處理技術;
- 是利用深度學習網絡挖掘單詞間語義關系,用網絡里的權重參數表示詞向量(比如“蘋果”和“水果”的向量,在語義空間里距離近);
- 是在無監督的語料(互聯網大量文本,沒人手動標標簽)上構建了一個有監督的任務(預測單詞這種帶目標的事情),底成本利用海量數據;
-
Word2Vec有兩種訓練詞向量方式:
- **CBOW(Continuous Bag of Words)**方式訓練詞向量
- 試圖根據上下文中的周圍單詞來預測當前單詞,即用周圍詞預測中間詞
- 它將周圍單詞的詞向量求和或取平均作為上下文的表示,然后通過一個神經網絡進行預測
- Skip-Gram方式訓練詞向量
- 試圖根據當前單詞來預測上下文中的周圍單詞,即用中間詞預測周圍詞
- 它將當前單詞的詞向量作為輸入,然后通過一個神經網絡來預測周圍單詞
- **CBOW(Continuous Bag of Words)**方式訓練詞向量
3.3.2 CBOW方式
-
已知數據:有5個字母構成的文本序列“abcdeaaeddccbadae …”,其中a、b、c、d、e的One-Hot表示為見下表
字母 One-Hot表示 a 1 0 0 0 0 b 0 1 0 0 0 c 0 0 1 0 0 d 0 0 0 1 0 e 0 0 0 0 1 -
需求:
- 構建神經網絡,輸入層數據要求5個特征,隱藏層有3個神經元,輸出層5個神經元;
- 使用已知數據訓練這個神經網絡;
- 用隱藏層的權重參數充當 a、b、c、d、 e 這5個單詞的詞向量;
-
需求分析:
-
兩個問題:
- 已知文本序列,如何構建神經網絡,來探索 a、b、c、d、 e 這5個單詞之間的語義關系?
- a、b、c、d、 e 這5個單詞之間的語義關系,又如何保存到神經網絡中?
-
思路:
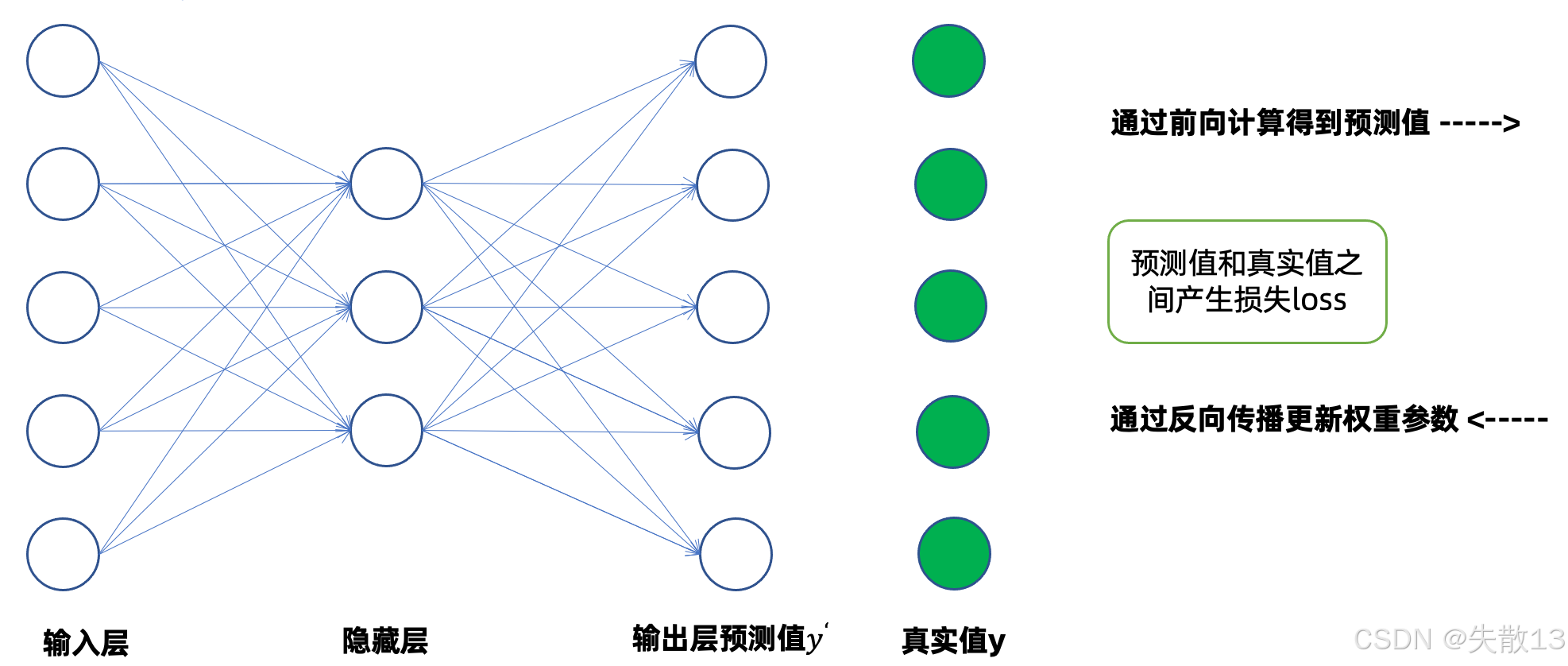
- 數據流:輸入數據5個特征,經過隱藏層變成3個特征,經過輸出層變成5個特征;
- 數據形狀:m*5 >> m*3 >> m*5(m是樣本數量),即降維又升維;
- 隱藏層參數矩陣
w為:5*3(5是輸入維度,3是隱藏層維度)、輸出層參數矩陣w':3*5(3是隱藏層維度,5是輸出維度); - 訓練過程:數據經過前向傳播得到預測值
?,預測值?與真實值y比較得到損失,通過反向傳播可以更新權重矩陣w和w'參數;
-
-
CBOW 核心是用周圍單詞預測中間單詞,過程如下:
- 構建樣本
- 引入滑動窗口(此處規定滑動窗口大小為3)切分文本序列,構建樣本。比如:
- 樣本1:x(a, c),y (b)。中間詞是 b ,周圍詞就是 a 和 c
- 樣本2:x(b, d),y ?。中間詞是 c ,周圍詞就是 b 和 d
- ……
- 將x中的兩個字母的One-Hot編碼拼在一起(或求和平均)當作輸入,將y的One-Hot編碼當作真實值;
- 引入滑動窗口(此處規定滑動窗口大小為3)切分文本序列,構建樣本。比如:
- 神經網絡前向傳播(降維+升維)
- 降維(參數矩陣
w):- 輸入 x(a 和 c 的One-Hot編碼拼在一起或者通過求和平均后得到的值)維度是 5 ,通過參數矩陣
w(5*3維度,5是輸入維度,3是隱藏層維度),把 5 維 “拍扁” 成 3 維隱藏層輸出; - 這一步叫 “降維”,把高維、語義孤立的One-Hot,轉成低維、帶語義關聯的向量(隱藏層輸出就是 “詞向量雛形”);
- 輸入 x(a 和 c 的One-Hot編碼拼在一起或者通過求和平均后得到的值)維度是 5 ,通過參數矩陣
- 升維(參數矩陣
w'):- 隱藏層 3 維輸出,再通過參數矩陣
w’(3*5,3是隱藏層維度,5是輸出維度),升回 5 維,得到預測值?; - 這一步是 “升維”,讓模型能輸出和真實值同維度的預測結果,方便計算誤差;
- 隱藏層 3 維輸出,再通過參數矩陣
- 降維(參數矩陣
- 計算損失(Loss):拿預測值
?(模型猜的b^)和真實值y(實際的b)比,用損失函數算差距。差距越大,Loss 越高,模型越 “差”; - 反向傳播(更新
w和w'):根據 Loss 反向調整參數矩陣w和w'的數值,讓下次預測更準;
- 構建樣本
-
訓練結束后,參數矩陣
w就存著單詞的詞向量-
此處
w是5*3維度(5是輸入維度,3是隱藏層維度),每一列對應一個單詞的詞向量; -
比如對于字母 a 的詞向量:
-
因為 a 的One-Hot是
[1,0,0,0,0],所以取w的 “第 0 列”。假設w矩陣長這樣[w11, w12, w13] [w21, w22, w23] [w31, w32, w33] [w41, w42, w43] [w51, w52, w53] -
那么 a 的詞向量是
[w11, w21, w31, w41, w51];
-
-
這樣,原本孤立的One-Hot,就通過訓練,在
w里變成了“語義相關”的低維向量。
-
3.3.3 Skip-Gram方式
-
CBOW 核心是用中間單詞預測周圍單詞,過程如下:
-
構建樣本
- 引入滑動窗口(此處規定滑動窗口大小為3)切分文本序列,構建樣本。比如:
- 樣本1:x(b),y (a, c)。中間詞是 b ,周圍詞就是 a 和 c
- 樣本2:x(c),y (b, d)。中間詞是 c ,周圍詞就是 b 和 d
- ……
- 將x中的字母的One-Hot編碼當作輸入,將y的One-Hot編碼當作真實值;
- 引入滑動窗口(此處規定滑動窗口大小為3)切分文本序列,構建樣本。比如:
-
神經網絡前向傳播(降維+升維)
- 降維(參數矩陣
w):- 輸入 x(b 的 One-hot)維度是 5 ,通過參數矩陣
w(5*3維度,5是輸入維度,3是隱藏層維度),把 5 維 “拍扁” 成 3 維隱藏層輸出; - 這一步提取 b 的“語義特征”;
- 輸入 x(b 的 One-hot)維度是 5 ,通過參數矩陣
- 升維(參數矩陣
w'):- 隱藏層 3 維輸出,再通過參數矩陣
w’(3*5,3是隱藏層維度,5是輸出維度),升回 5 維,得到預測值?; - 這一步讓模型能輸出和真實值同維度的結果,方便算誤差;
- 隱藏層 3 維輸出,再通過參數矩陣
- 降維(參數矩陣
-
計算損失(Loss):拿預測值
?(模型猜的a^和c^)和真實值y(實際的a和c)比,用損失函數算差距。差距越大,Loss 越高,模型越 “差”; -
反向傳播(更新
w和w'):根據 Loss 反向調整參數矩陣w和w'的數值,讓下次預測更準;
-
-
訓練結束后,參數矩陣
w就存著單詞的詞向量-
此處
w是5*3維度(5是輸入維度,3是隱藏層維度),每一行對應一個單詞的詞向量; -
比如對于字母 b 的詞向量:
-
因為 b 的One-Hot是
[0,1,0,0,0],所以取w的 “第 1 行”。假設w矩陣長這樣[w11, w12, w13] [w21, w22, w23] [w31, w32, w33] [w41, w42, w43] [w51, w52, w53] -
那么 b 的詞向量是
[w21, w22, w23];
-
-
這樣,原本孤立的One-Hot,就通過訓練,在
w里變成了“語義相關”的低維向量。
-
3.3.4 Word2vec模型的訓練和使用
3.3.4.1 概述
-
FastText 工具包
-
背景:Facebook(現 Meta)開源的 NLP 工具;
-
功能:文本分類、訓練詞向量;
-
-
Tomas Mikolov 是 Word2Vec 作者,后來又搞了 FastText ,相當于**“Word2Vec 升級版/拓展版”**:
-
Word2Vec 主要聚焦“單詞級”詞向量訓練;
-
FastText 加入“字符級”信息(比如把“apple”拆成“app”“ppl”“ple” ),對小語種、生僻詞更適配,功能也更豐富(文本分類 + 詞向量)。
-
-
不管用 Word2Vec 還是 FastText ,訓練詞向量都繞不開這些步驟:
- 獲取訓練數據
- 詞向量的訓練、保存、加載、查看
- 模型效果檢驗
- 模型超參數設定
3.3.4.2 獲取訓練數據
-
數據來源:
http://mattmahoney.net/dc/enwik9.zip,這是英語維基百科的部分網頁信息,大小在300M左右(解壓后1個G); -
原始數據中包含 XML/HTML 格式的內容,這些內容并不是我們需要的,所以接下來對原始數據做一些處理;
-
編寫
wikifil.py腳本,用于清洗enwik9文件:#!/usr/bin/env python3 # -*- coding: utf-8 -*-""" Python版Wikipedia XML清洗腳本功能與原Perl腳本(wikifil.pl)完全相同: 1. 只保留<text>...</text>之間的內容 2. 移除#REDIRECT頁面 3. 清除所有XML/HTML標簽 4. 轉換URL編碼字符 5. 移除參考文獻、外部鏈接、圖片標記等 6. 保留圖像說明文字 7. 將鏈接轉換為普通文本 8. 將數字拼寫出來(如1→one) 9. 最終只保留小寫字母和空格(無連續空格) """import re import sysdef clean_wiki_text():text_mode = Falsewith open("enwik9", "r", encoding="utf-8") as f:for line in f:# 檢測是否進入<text>標簽if "<text " in line:text_mode = True# 忽略#REDIRECT頁面if "#redirect" in line.lower():text_mode = Falseif text_mode:# 檢測是否離開<text>標簽if "</text>" in line:text_mode = Falsecontinue# 移除XML標簽line = re.sub(r'<.*?>', '', line)# 解碼URL編碼字符line = line.replace('&', '&')line = line.replace('<', '<')line = line.replace('>', '>')# 移除參考文獻 <ref...>...</ref>line = re.sub(r'<ref[^<]*<\/ref>', '', line)# 移除XHTML標簽line = re.sub(r'<[^>]*>', '', line)# 處理URL鏈接,保留可見文本line = re.sub(r'\[http:[^] ]*', '[', line)# 移除圖片鏈接標記,保留說明文字line = re.sub(r'\|thumb', '', line, flags=re.IGNORECASE)line = re.sub(r'\|left', '', line, flags=re.IGNORECASE)line = re.sub(r'\|right', '', line, flags=re.IGNORECASE)line = re.sub(r'\|\d+px', '', line, flags=re.IGNORECASE)line = re.sub(r'\[\[image:[^\[\]]*\|', '', line, flags=re.IGNORECASE)# 簡化分類標記line = re.sub(r'\[\[category:([^|\]]*)[^]]*\]\]', '[[\\1]]', line, flags=re.IGNORECASE)# 移除其他語言鏈接line = re.sub(r'\[\[[a-z\-]*:[^\]]*\]\]', '', line, flags=re.IGNORECASE)# 移除wiki URL,保留可見文本line = re.sub(r'\[\[[^\|\]]*\|', '[[', line)# 移除{{icons}}和{tables}line = re.sub(r'\{\{[^\}]*\}\}', '', line)line = re.sub(r'\{[^\}]*\}', '', line)# 移除方括號line = line.replace('[', '').replace(']', '')# 移除其他URL編碼字符line = re.sub(r'&[^;]*;', ' ', line)# 轉換為小寫line = line.lower()# 將數字拼寫出來line = line.replace('0', ' zero ')line = line.replace('1', ' one ')line = line.replace('2', ' two ')line = line.replace('3', ' three ')line = line.replace('4', ' four ')line = line.replace('5', ' five ')line = line.replace('6', ' six ')line = line.replace('7', ' seven ')line = line.replace('8', ' eight ')line = line.replace('9', ' nine ')# 移除非字母字符,合并連續空格line = re.sub(r'[^a-z]', ' ', line)line = re.sub(r' +', ' ', line).strip()if line:print(line)if __name__ == "__main__":clean_wiki_text() -
將下面這兩個文件放在同一個目錄下:
-
打開 CMD 命令行,執行:
python wikifil.py > fil9 -
可以查看生成的
fil9文件中的前 20 行內容:Get-Content fil9 -Head 20
3.3.4.3 詞向量的訓練、保存、加載、查看
-
安裝 fasttext:安裝的方式具體還是見GitHub - facebookresearch/fastText: Library for fast text representation and classification.;
- 可能涉及到C++17的編譯、由于Python版本過高不支持安裝等問題,下面只給出示例代碼;
pip install fasttext -
訓練、保存、加載
def fasttext_train_save_load():# 訓練詞向量mymodel = fasttext.train_unsupervised('data/fil9', epoch=1)# 保存詞向量mymodel.save_model("data/mymodel.bin")# 加載詞向量mymodel = fasttext.load_model("data/mymodel.bin") -
查看
# 查看詞向量 def fasttext_get_word_vector():# 加載已經訓練好的詞向量模型mymodel = fasttext.load_model("data/mymodel.bin")# 查看詞向量themyvector = mymodel.get_word_vector('the')print('myvector--->', type(myvector), myvector.shape, myvector)
3.3.4.4 模型效果檢驗
-
檢查單詞向量質量的一種簡單方法就是查看其鄰近單詞,然后主觀來判斷這些鄰近單詞是否與目標單詞相關,進而來粗略評定模型效果的好壞;
-
查看臨近詞:
# 查看臨近詞 def fasttext_get_nearest_neighbors():# 加載已經訓練好的詞向量模型mymodel = fasttext.load_model("data/mymodel.bin")# 查看詞向量dog的臨近詞result = mymodel.get_nearest_neighbors('dog')print('result--->', result)
3.3.4.5 模型超參數設定
# 模型參數設定
def fasttext_parm():''' unsupervised_default = {'model': "skipgram", # 1 選擇詞向量的訓練方式'lr': 0.05, # 2 學習率'dim': 100, # 3 詞向量特征數'ws': 5,'epoch': 5, # 4 訓練輪次'minCount': 5,'minCountLabel': 0,'minn': 3,'maxn': 6,'neg': 5,'wordNgrams': 1,'loss': "ns",'bucket': 2000000,'thread': multiprocessing.cpu_count() - 1, # 5 線程數'lrUpdateRate': 100,'t': 1e-4,'label': "__label__",'verbose': 2,'pretrainedVectors': "",'seed': 0,'autotuneValidationFile': "",'autotuneMetric': "f1",'autotunePredictions': 1,'autotuneDuration': 60 * 5, # 5 minutes'autotuneModelSize': ""}'''mymodel = fasttext.train_unsupervised('./data/fil9', epoch=1, model='cbow', lr=0.1, dim=300, thread=8)
3.3.5 CBOW VS Skip-Gram
- 原理:CBOW用周圍單詞預測當前單詞;Skip - Gram憑當前單詞預測周圍單;
- 計算效率:CBOW因對多個上下文單詞向量求和平均,計算高效;Skip - Gram要為每個單詞生成上下文,訓練速度慢、效率低;
- 數據需求:CBOW需更多訓練數據匯總整體信息;Skip - Gram在大規模數據中處理低頻詞更優,能生成豐富上下文信息;
- 適用場景:CBOW適合訓練數據大、高頻詞情況;Skip - Gram對低頻詞、復雜語義關系場景表現好,像大規模數據集中處理低頻詞。
3.4 Word Embedding
-
Word Embedding(詞嵌入),通過一定的方式將詞匯映射到指定維度(一般是更高維度)的空間;
- 廣義:只要是將單詞用向量來表示的方法,都算(比如 Word2Vec、GloVe 這些),不管用不用深度學習;
- 狹義:在深度神經網絡里,專門加一個 “嵌入層”(比如 PyTorch 的
nn.Embedding),用網絡訓練出向量;
-
Word2Vec方式產生詞向量和Word Embedding(
nn. Embedding)方式有何異同?- 相同點:都是將單詞用向量來表示,讓計算機能處理文本;
- 不同點:
- Word2Vec產生詞向量后,某一個詞向量比如單詞“the”的詞向量就固定下來了,是靜態的;
nn.Embedding層產生詞向量后,詞嵌入層作為整體神經網絡的一部分,權重參數會參與更新,是動態的;- Word2Vec使用起來一般需要兩步:輸入單詞"the"拿到詞向量 >> 再送給神經網絡進行使用;
nn.Embedding層使用起來只有一步:直接嵌入到神經網絡中。
4 使用tenserboard可視化嵌入的詞向量
-
需求:
-
有下面兩句話
騰訊是一家上市公司,旗下有王者榮耀、和平精英等游戲,但還是要少玩游戲 我愛自然語言處理 -
對這兩句話分詞,并完成文本數值化、數值張量化
-
然后對詞向量進行可視化
-
import torch
from tensorflow.keras.preprocessing.text import Tokenizer
from torch.utils.tensorboard import SummaryWriter
import jieba
import torch.nn as nn
import tensorflow as tf
import tensorboard as tb
tf.io.gfile = tb.compat.tensorflow_stub.io.gfile
# 1 對句子分詞,構建詞列表word_list
# 定義兩個示例句子
sentence1 = '騰訊是一家上市公司,旗下有王者榮耀、和平精英等游戲,但還是要少玩游戲'
sentence2 = '我愛自然語言處理'
sentences = [sentence1, sentence2]
word_list = []
# 用jieba對每個句子分詞,結果存入word_list
for s in sentences:word_list.append(jieba.lcut(s))
print('word_list--->', word_list)
# 2 對句子分詞列表word_list做詞表構建,得到每個詞的索引映射
mytokenizer = Tokenizer()
mytokenizer.fit_on_texts(word_list)
print('mytokenizer.index_word--->', mytokenizer.index_word)
print('mytokenizer.word_index--->', mytokenizer.word_index)
my_token_list = list(mytokenizer.index_word.values()) # 獲取詞列表,用于后續可視化
print('my_token_list--->', my_token_list)
# 3 創建nn.Embedding層,實現詞嵌入
# num_embeddings是詞表大小(不同詞的數量),embedding_dim是詞向量維度
embed = nn.Embedding(num_embeddings=len(mytokenizer.index_word), embedding_dim=8)
print('詞嵌入層embed--->', embed)
# 設置打印精度,方便查看張量值
torch.set_printoptions(precision=4, sci_mode=False)
print('詞嵌入層的矩陣參數(每個單詞的詞向量)embed--->', embed.weight.data)
# 4 創建SummaryWriter對象,可視化詞向量
# 用于把詞嵌入矩陣和詞列表寫入TensorBoard,方便可視化查看
summarywriter = SummaryWriter()
summarywriter.add_embedding(embed.weight.data, my_token_list)
summarywriter.close()
# 5 通過索引獲取詞向量
# 遍歷詞表索引,獲取對應詞向量并打印
for idx in range(len(mytokenizer.index_word)):tmp_vec = embed(torch.tensor([idx]))print('tmp_vec--->', tmp_vec.detach().numpy())
- 在程序的當前目錄下運行:
tensorboard --logdir=runs --host 0.0.0.0,再通過http://127.0.0.1:6006訪問。


)










: DAPO,VAPO,GMPO,GSPO, CISPO,GFPO)

)


)
