系列文章目錄
初識CNN01——認識CNN
初識CNN02——認識CNN2
初識CNN03——預訓練與遷移學習
初識CNN04——經典網絡認識
文章目錄
- 系列文章目錄
- 一、GoogleNet——Inception
- 1.1 1x1卷積
- 1.2 維度升降
- 1.3 網絡結構
- 1.4 Inception Module
- 1.5 輔助分類器
- 二、ResNet——越深越好
- 總結
一、GoogleNet——Inception
GoogLeNet(Inception v1)是谷歌團隊在2014年ImageNet大規模視覺識別挑戰賽(ILSVRC 2014)中奪得分類任務冠軍的深度學習模型。它的主要創新在于保持深度的同時大幅減少了參數量(約600萬參數,僅為AlexNet的1/10到1/12),并引入了Inception模塊、輔助分類器等結構來提升性能并緩解梯度消失問題。
1.1 1x1卷積

當卷積核大小為1時,我們可以將其用于通道融合。以一個三通道RGB圖像為例:
import torch
import cv2
import torch.nn as nn
from matplotlib import pyplot as plt@torch.no_grad()
def gray():# input:RGB圖片img = cv2.imread("./images/a.jpg")img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)print(img.shape)# 1 x 1卷積con1_1 = nn.Conv2d(in_channels=3,out_channels=1,kernel_size=1,stride=1,padding=0,bias=False,)print(con1_1.weight.data.shape)# 常規轉換公式:0.2989R + 0.5870G + 0.1140B# 修改權重參數con1_1.weight.data = torch.Tensor([[[[0.2989]], [[0.5870]], [[0.1140]]]])print(con1_1.weight.data.shape)# 使用卷積核處理圖像out = con1_1(torch.Tensor(img).permute(2, 0, 1).unsqueeze(0))print(out.shape)# 顯示圖片plt.imshow(out.squeeze(0).permute(1, 2, 0).numpy(), cmap="gray")plt.show()if __name__ == "__main__":gray()

1.2 維度升降
- 瓶頸結構
借助1x1卷積我們可以設計這種兩頭寬,中間窄的網絡結構。如果一個輸入特征大小為N1×H×W, 使用N1×N2個1×1卷積,就可以將其 映射為N2×H×W大小的特征。當N1>N2,就實現了通道降維。
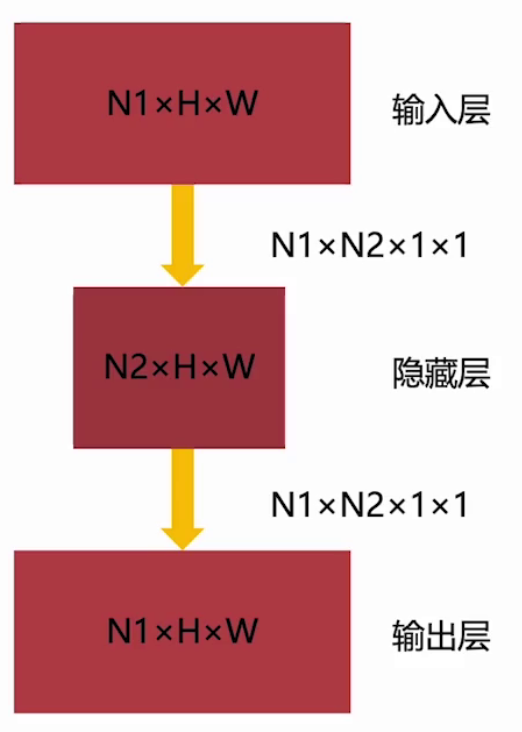
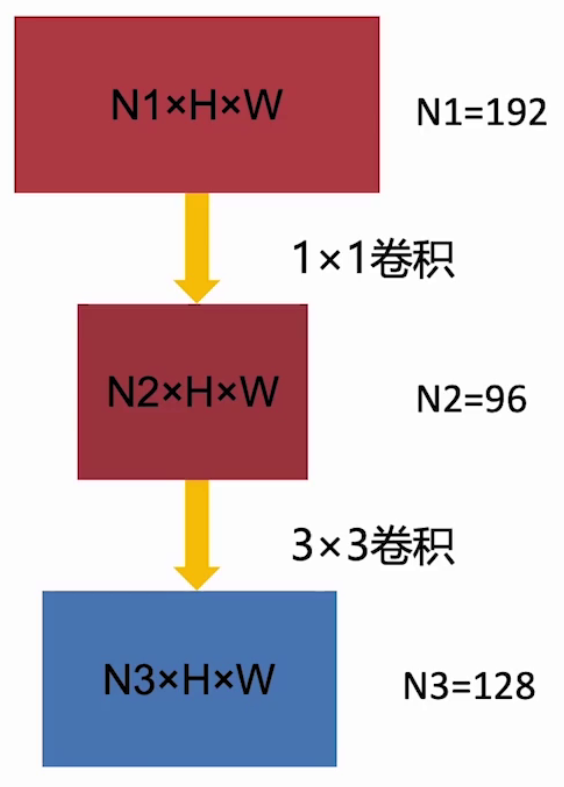
可以通過以上結構完成參數壓縮:
假設輸入通道數為192,輸出通道數為128,則普通3×3卷積,參數量為128×192×3×3=221184,而先使用1×1卷積進行降維到96個通道,然后再用3×3升維到128
,則參數量為:96×192×1×1+128×96×3×3=129024。
- 紡錘結構
與瓶頸結構類似,不過是兩頭窄,中間寬的網絡結構。
1.3 網絡結構
網絡結構如下圖所示,可以看到為多尺度,更寬,分組的網絡設計:

1.4 Inception Module
從以上的結構圖中可以看到一個反復出現的單詞Inception,該結構由谷歌的研究人員在2014年提出,它的名字來源于電影《盜夢空間》,因為它設計時使用了多個并行的卷積神經網絡模塊,這些模塊之間形成了一個嵌套的結構,就像人在夢中穿梭于不同場景中一樣。
Inception結構是對輸入圖像并行地執行多個卷積運算或池化操作,并將所有輸出結果拼接為一個非常深的特征圖,且不同大小卷積核的卷積運算可以得到圖像中的不同信息,處理獲取到的圖像中的不同信息可以得到更好的圖像特征,一個Inception結構如下圖所示。
? 其中1x1卷積的位置如果放置在前,通道降維;如果放置在后,更好地維持性能

Inception結構的思想和之前的卷積思想不同,LeNet-5模型是將不同的卷積層通過串聯連接起來的,但是Inception結構是通過串聯+并聯的方式將卷積層連接起來的。
Inception結構通常用于圖像分類和識別任務,因為它能夠有效地捕捉圖像中的細節信息。它的主要優勢在于能夠以高效的方式處理大量的數據,并且模型的參數量相對較少,這使得它能夠在不同的設備上運行。
1.5 輔助分類器
在以上網絡結構中,有些分支在中間層就進行了softmax操作得到結果,這個結構叫做輔助分類器。在GoogLeNet中有兩個輔助分類器,分別在Inception4a和Inception4d,它們的結構如下圖所示:

輔助分類器通常與主要的分類器結合使用,以幫助模型更好地理解圖像中的細節和復雜模式。這種技術可以提高模型的泛化能力,使其更準確地預測未知的圖像。訓練時,額外的兩個分類器的損失權重為0.3,推理時去除。
二、ResNet——越深越好
ResNet(Residual Network,殘差網絡)是由何愷明等人于2015年提出的深度卷積神經網絡架構。它通過引入殘差學習和跳躍連接(Skip Connection),有效解決了極深神經網絡中的梯度消失和網絡退化問題,使得訓練數百甚至上千層的網絡成為可能,并在ImageNet等競賽中取得了突破性成果。
2.1 梯度消失
深層網絡有個梯度消失問題:模型變深時,其錯誤率反而會提升,該問題非過擬合引起,主要是因為梯度消失而導致參數難以學習和更新。

想要理解這個問題我們需要回憶反向傳播與鏈式法則,即神經網絡通過梯度下降來更新權重。梯度通過反向傳播計算,從輸出層一路通過鏈式法則 乘到輸入層。對于一個 L 層的網絡,第 l 層的梯度是它之后所有層梯度的乘積。
現在想象一下,在反向傳播時,梯度需要連續乘以這些很小的導數(比如0.1, 0.25)。經過多層之后,這個連乘的結果會指數級地趨近于零。這意味著,對于靠近輸入層的網絡層(淺層),計算出的梯度值幾乎為零。
2.2 Residual結構
Residual結構即殘差結構,有兩種不同的殘差結構,在ResNet-18和ResNet-34中,用的如下圖中左側圖的結構,在ResNet-50、ResNet-101和ResNet-152中,用的是下圖中右側圖的結構。

上圖左圖可看到輸入特征的channels是64,經過一個3x3的卷積核卷積之后,進行Relu激活,再經過一個3x3的卷積核進行卷積,但并沒有直接激活。并且可以看到,在主分支上有一個圓弧的線從輸入特征矩陣直接到加號,這個圓弧線是shortcut(捷徑分支),它直接將輸入特征矩陣加到經過第二次3x3的卷積核卷積之后的輸出特征矩陣,再經過Relu激活函數進行激活。
在傳統網絡中我們是直接學習的期望映射y=H(x)y=H(x)y=H(x),這種映射能處理大多數關系,但對于恒等關系,即輸入與輸出相等的映射,擬合效果很差。但如果使用映射關系y=F(x)+xy=F(x)+xy=F(x)+x,那么若某層的最優映射接近恒等映射,那么學習殘差 F(x)F(x)F(x) 逼近 0 比學習一個完整的恒等映射要容易得多。

通過使用殘差連接,使得更深的網絡具有更低的錯誤率。

總結
本文主要介紹了經典網絡中的GoogleNet以及ResNet,主要是對于1x1卷積核的使用以及殘差結構的理解,而非具體網絡細節。


: DAPO,VAPO,GMPO,GSPO, CISPO,GFPO)

)


)






)

)


