ZooKeeper
安裝
官網

解壓
cd /export/server/
tar -zxvf /export/server/apache-zookeeper-3.9.3-bin.tar.gz -C /export/server/
軟鏈接
ln -s /export/server/apache-zookeeper-3.9.3-bin /export/server/zookeeper
配置
cd /export/server/zookeeper/
mkdir zkData
myid
cd zkData
vim myid
寫個數字,node1就寫1
zoo.cfg
cd /export/server/zookeeper/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改dataDir屬性為
dataDir=/export/server/zookeeper/zkData
并在末尾添加
#########cluster#########
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
然后分發一下
xsync /export/server/zookeeper /export/server/apache-zookeeper-3.9.3-bin
然后分別去node2、node3把myid中的數字改成2和3
vim /export/server/zookeeper/zkData/myid
啟動
xcall /export/server/zookeeper/bin/zkServer.sh start
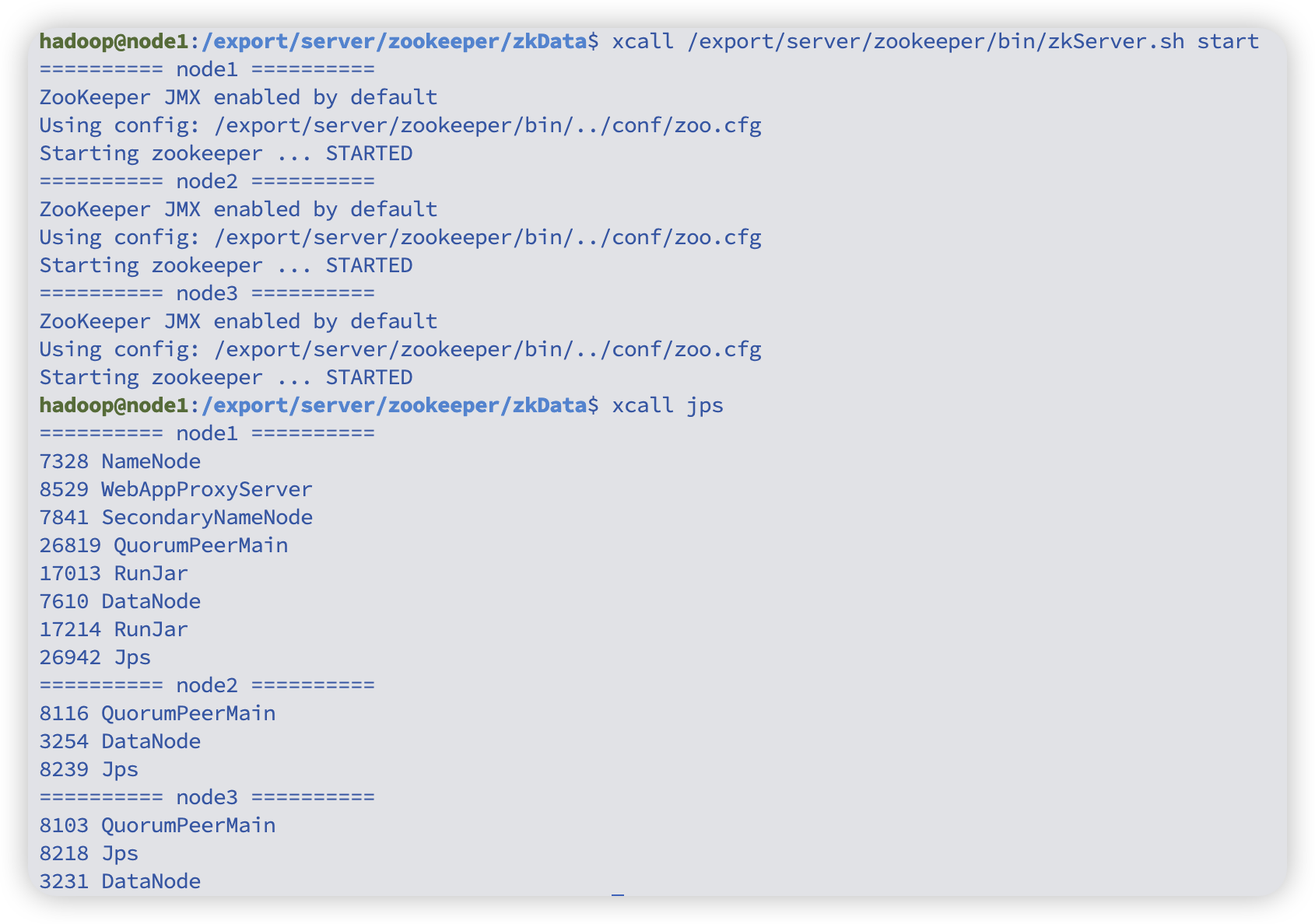
# 查看狀態,應該有leader有follower
xcall /export/server/zookeeper/bin/zkServer.sh status
# 停止
xcall /export/server/zookeeper/bin/zkServer.sh stop
kafka
官網
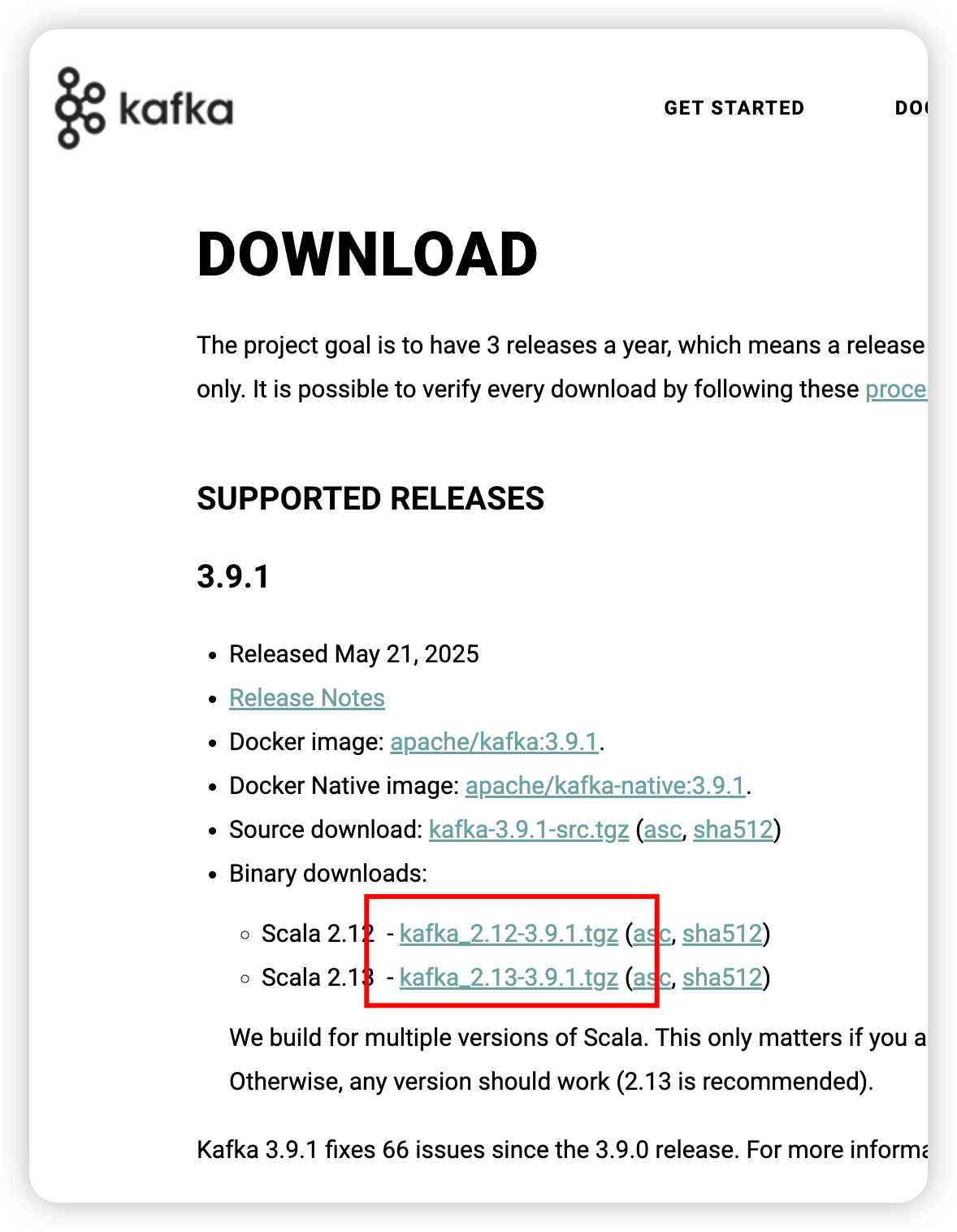
安裝
解壓
cd /export/server
tar -zxvf /export/server/kafka_2.13-3.9.1.tgz -C /export/server/
軟鏈接
ln -s /export/server/kafka_2.13-3.9.1 /export/server/kafka
配置
server.properties
cd /export/server/kafka/config/
vim server.properties
新增
advertised.listeners=PLAINTEXT://node1:9092
替換
log.dirs=/export/server/kafka/datas
替換
# Kafka 連接 Zookeeper 集群的地址列表(逗號分隔)
# 每個地址格式為:主機名:端口
# node1、node2、node3 分別代表三臺 Zookeeper 節點主機
# /kafka 表示 Kafka 在 Zookeeper 中的 chroot 路徑,用于隔離存儲 Kafka 元數據,防止一個 Zookeeper 集群中多個應用(例如 Kafka、HBase、Hadoop 等)數據沖突。
zookeeper.connect=node1:2181,node2:2181,node3:2181/kafka
保存退出后,分發一下
xsync /export/server/kafka /export/server/kafka_2.13-3.9.1
然后其他節點需要修改一下broker.id和advertised.listeners
cd /export/server/kafka/config/
vim server.properties
node2 broker.id=1 advertised.listeners改成node2
node3 broker.id=2 advertised.listeners改成node3
環境變量
sudo vim /etc/profile
末尾新增
export KAFKA_HOME=/export/server/kafka
export PATH=$PATH:$KAFKA_HOME/bin
分發一下
sudo xsync /etc/profile
各個節點刷新一下
source /etc/profile
啟動
xcall /export/server/kafka/bin/kafka-server-start.sh -daemon /export/server/kafka/config/server.properties
停止
xcall /export/server/kafka/bin/kafka-server-stop.sh
如果沒有啟動成功,那就等一會重啟一下。
flume
官網
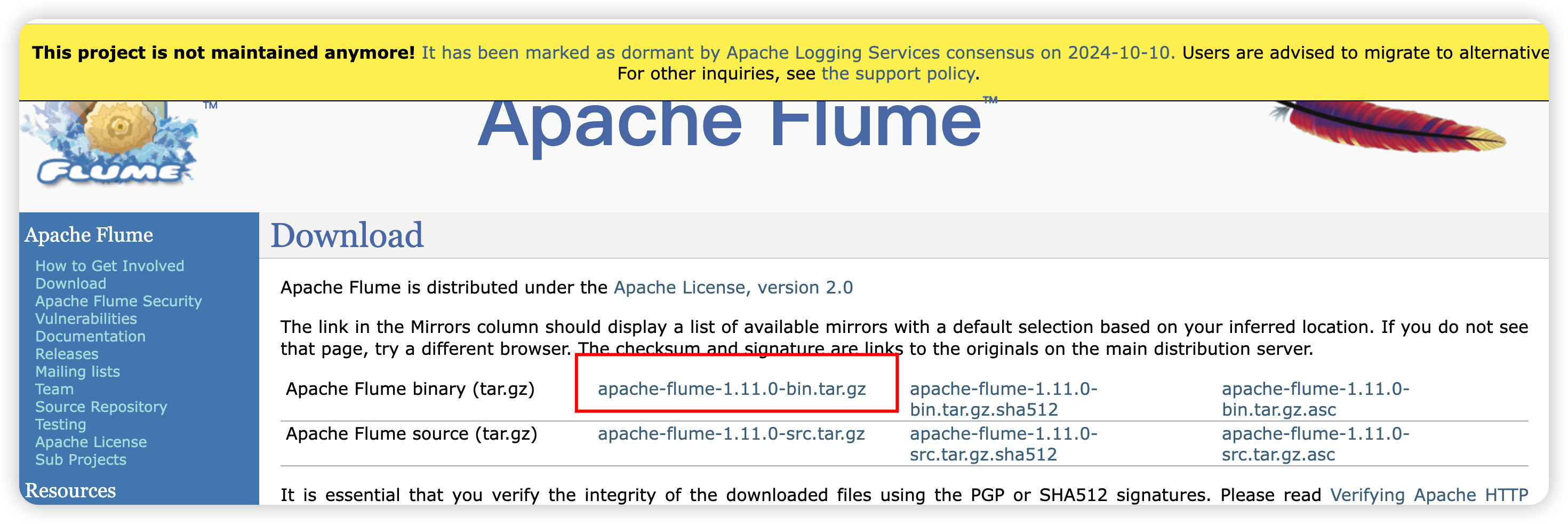
安裝
解壓
cd /export/server
tar -zxvf /export/server/apache-flume-1.11.0-bin.tar.gz -C /export/server/
軟鏈接
ln -s /export/server/apache-flume-1.11.0-bin /export/server/flume
配置
log4j2.xml
cd /export/server/flume/conf/
替換
<Properties><Property name="LOG_DIR">/export/server/flume/log</Property></Properties>
替換
<Root level="INFO"><AppenderRef ref="LogFile" /><AppenderRef ref="Console" /></Root>
DataX
官網
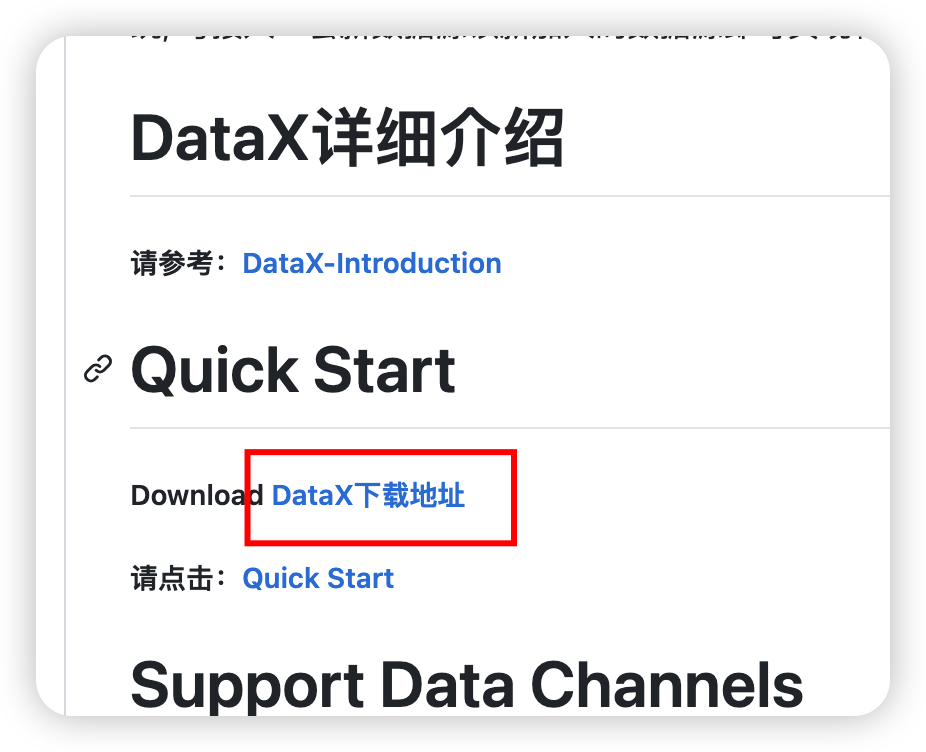
cd /export/server/
tar -zxvf /export/server/datax.tar.gz -C /export/server/
自檢
python3 /export/server/datax/bin/datax.py /export/server/datax/job/job.json

DolphinScheduler
下載
官網
文檔
cd /export/server/
tar -zxvf /export/server/apache-dolphinscheduler-3.1.9-bin.tar.gz -C /export/server/
準備mysql賬號
sudo mysql -u root -p
-- 若需要撤銷
DROP DATABASE IF EXISTS dolphinscheduler; DROP USER IF EXISTS 'dolphinscheduler'@'%';FLUSH PRIVILEGES;-- 創建 DolphinScheduler 元數據庫
CREATE DATABASE IF NOT EXISTS dolphinschedulerDEFAULT CHARACTER SET utf8mb4COLLATE utf8mb4_general_ci;-- 創建 DolphinScheduler 用戶(只允許遠程連接)
CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY 'Dolphin!123';-- 授權 DolphinScheduler 用戶管理 dolphinscheduler 庫
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%';-- 刷新權限
FLUSH PRIVILEGES;
EXIT;
mysql driver
# 選定驅動(優先 hive 里的,其次 /export/server 下的)
JAR_SRC=""
for c in /export/server/hive/lib/mysql-connector-j-8.0.33.jar /export/server/mysql-connector-j-8.0.33.jar; do[ -f "$c" ] && JAR_SRC="$c" && break
done
[ -z "$JAR_SRC" ] && echo "未找到 mysql-connector-j-8.0.33.jar" && exit 1
echo "使用驅動: $JAR_SRC"# 復制到四個服務 + tools
for comp in api-server master-server worker-server alert-server tools; domkdir -p /export/server/apache-dolphinscheduler-3.1.9-bin/$comp/libscp -f "$JAR_SRC" /export/server/apache-dolphinscheduler-3.1.9-bin/$comp/libs/
done# 校驗是否復制成功
for comp in api-server master-server worker-server alert-server tools; doecho "### $comp"ls /export/server/apache-dolphinscheduler-3.1.9-bin/$comp/libs | grep -i "mysql-connector"
done
配置
install_env.sh
cd /export/server/apache-dolphinscheduler-3.1.9-bin/bin/env
mv dolphinscheduler_env.sh dolphinscheduler_env.sh.back
mv install_env.sh install_env.sh.back
vim install_env.sh
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
## ---------------------------------------------------------
# INSTALL MACHINE
# ---------------------------------------------------------
# A comma separated list of machine hostname or IP would be installed DolphinScheduler,
# including master, worker, api, alert. If you want to deploy in pseudo-distributed
# mode, just write a pseudo-distributed hostname
# Example for hostnames: ips="ds1,ds2,ds3,ds4,ds5", Example for IPs: ips="192.168.8.1,192.168.8.2,192.168.8.3,192.168.8.4,192.168.8.5"
ips=${ips:-"node1,node2,node3"}
# 需要安裝 DolphinScheduler 的所有機器列表;此處為三節點集群:node1、node2、node3# Port of SSH protocol, default value is 22. For now we only support same port in all `ips` machine
# modify it if you use different ssh port
sshPort=${sshPort:-"22"}
# SSH 端口,三臺機器保持一致;如果自定義端口請修改# A comma separated list of machine hostname or IP would be installed Master server, it
# must be a subset of configuration `ips`.
# Example for hostnames: masters="ds1,ds2", Example for IPs: masters="192.168.8.1,192.168.8.2"
masters=${masters:-"node1,node2"}
# Master 角色所在節點;建議至少 2 個節點以保證高可用# A comma separated list of machine <hostname>:<workerGroup> or <IP>:<workerGroup>.All hostname or IP must be a
# subset of configuration `ips`, And workerGroup have default value as `default`, but we recommend you declare behind the hosts
# Example for hostnames: workers="ds1:default,ds2:default,ds3:default", Example for IPs: workers="192.168.8.1:default,192.168.8.2:default,192.168.8.3:default"
workers=${workers:-"node1:default,node2:default,node3:default"}
# Worker 角色與分組;這里三臺都加入 default 分組,便于調度均衡# A comma separated list of machine hostname or IP would be installed Alert server, it
# must be a subset of configuration `ips`.
# Example for hostname: alertServer="ds3", Example for IP: alertServer="192.168.8.3"
alertServer=${alertServer:-"node3"}
# Alert 告警服務所在節點;放在 node3# A comma separated list of machine hostname or IP would be installed API server, it
# must be a subset of configuration `ips`.
# Example for hostname: apiServers="ds1", Example for IP: apiServers="192.168.8.1"
apiServers=${apiServers:-"node1"}
# API 服務所在節點;放在 node1(可按需擴容到多節點)# The directory to install DolphinScheduler for all machine we config above. It will automatically be created by `install.sh` script if not exists.
# Do not set this configuration same as the current path (pwd). Do not add quotes to it if you using related path.installPath=${installPath:-"/export/server/dolphinscheduler"}
# 安裝目標目錄;install.sh 會在各節點自動創建# The user to deploy DolphinScheduler for all machine we config above. For now user must create by yourself before running `install.sh`
# script. The user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled than the root directory needs
# to be created by this user
deployUser=${deployUser:-"hadoop"}
# 部署用戶(需具備 sudo 與 HDFS 操作權限);與你當前使用的 hadoop 用戶一致# The root of zookeeper, for now DolphinScheduler default registry server is zookeeper.
zkRoot=${zkRoot:-"/dolphinscheduler"}
# Zookeeper 注冊中心根路徑;三節點 ZK 集群共享該路徑dolphinscheduler_env.sh
vim dolphinscheduler_env.sh
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
## JAVA_HOME, will use it to start DolphinScheduler server
export JAVA_HOME=${JAVA_HOME:-/export/server/jdk}
# (Java 安裝路徑;優先取系統已配置的 JAVA_HOME,否則使用 /export/server/jdk# Database related configuration, set database type, username and password
export DATABASE=${DATABASE:-mysql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL=${SPRING_DATASOURCE_URL:-"jdbc:mysql://node1:3306/dolphinscheduler?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true&nullCatalogMeansCurrent=true"}
export SPRING_DATASOURCE_USERNAME=${SPRING_DATASOURCE_USERNAME:-dolphinscheduler}
export SPRING_DATASOURCE_PASSWORD=${SPRING_DATASOURCE_PASSWORD:-Dolphin!123}
# (切換為 MySQL;URL 使用主機名 node1,時區與字符集已設置;用戶名/密碼與之前創建一致# DolphinScheduler server related configuration
export SPRING_CACHE_TYPE=${SPRING_CACHE_TYPE:-none}
export SPRING_JACKSON_TIME_ZONE=${SPRING_JACKSON_TIME_ZONE:-Asia/Shanghai}
export MASTER_FETCH_COMMAND_NUM=${MASTER_FETCH_COMMAND_NUM:-10}
# (服務端配置:關閉緩存;Jackson 使用中國時區;Master 每次抓取命令數量為 10(可按需調整)# Registry center configuration, determines the type and link of the registry center
export REGISTRY_TYPE=${REGISTRY_TYPE:-zookeeper}
export REGISTRY_ZOOKEEPER_CONNECT_STRING=${REGISTRY_ZOOKEEPER_CONNECT_STRING:-node1:2181,node2:2181,node3:2181}
# (注冊中心為 Zookeeper;三節點集群連接串# Tasks related configurations, need to change the configuration if you use the related tasks.
export HADOOP_HOME=${HADOOP_HOME:-/export/server/hadoop}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/export/server/hadoop/etc/hadoop}
export SPARK_HOME1=${SPARK_HOME1:-/export/server/spark1}
export SPARK_HOME2=${SPARK_HOME2:-/export/server/spark2}
export PYTHON_HOME=${PYTHON_HOME:-/usr/bin}
export HIVE_HOME=${HIVE_HOME:-/export/server/hive}
export FLINK_HOME=${FLINK_HOME:-/export/server/flink}
export DATAX_HOME=${DATAX_HOME:-/export/server/datax}
export SEATUNNEL_HOME=${SEATUNNEL_HOME:-/export/server/seatunnel}
export CHUNJUN_HOME=${CHUNJUN_HOME:-/export/server/chunjun}
# (各類任務依賴路徑;未安裝的組件可保持默認或注釋;PYTHON_HOME 設為系統 /usr/bin 便于直接調用 python3export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_HOME/bin:$SEATUNNEL_HOME/bin:$CHUNJUN_HOME/bin:$PATH
# (將相關組件的 bin 目錄加入 PATH,確保任務執行時可直接調用對應命令
初始化數據庫
bash /export/server/apache-dolphinscheduler-3.1.9-bin/tools/bin/upgrade-schema.sh
安裝
默認生成的目錄權限是hadoop組hadoop用戶,這是不合理的,改成默認主組(bigdata組)
cd /export/server/apache-dolphinscheduler-3.1.9-bin/bin# 1) 備份
mv install.sh install.sh.back# 2) 在 "if [ ! -d $installPath ];then" 之后插入屬組選擇邏輯(追加多行)
sed -E '/^\s*if \[ ! -d \$installPath \];then\s*$/a\\ # 【修改】計算屬組優先級:DEPLOY_GROUP > bigdata(當 deployUser=hadoop 且存在) > deployUser 主組\\ if [ -n "${DEPLOY_GROUP}" ]; then\\ _target_group="${DEPLOY_GROUP}";\\ elif [ "${deployUser}" = "hadoop" ] && getent group bigdata >/dev/null 2>\&1; then\\ _target_group="bigdata";\\ else\\ _target_group="$(id -gn ${deployUser} 2>/dev/null || echo ${deployUser})";\\ fi
' install.sh.back > install.sh.tmp# 3) 精確替換 chown 行(不使用有歧義的字符類)
# 把:sudo chown -R $deployUser:$deployUser $installPath
# 換成:sudo chown -R $deployUser:${_target_group} $installPath
sed -E \'s#^([[:space:]]*)sudo[[:space:]]+chown[[:space:]]+-R[[:space:]]+\$deployUser:\$deployUser[[:space:]]+\$installPath#\1sudo chown -R \$deployUser:${_target_group} \$installPath#' \install.sh.tmp > install.shrm -f install.sh.tmp# 4) 校驗插入與替換
echo "------ inserted lines around if-block ------"
nl -ba install.sh | sed -n '1,200p' | sed -n '/if \[ ! -d \$installPath \];then/,+8p'
echo "------ chown lines ------"
grep -n "chown -R" install.sh || true
解決垃圾回收采用cms但是高版本jdk以完全廢棄的問題
解決commons-cli問題
cd /export/server/apache-dolphinscheduler-3.1.9-bin/bin# 1) 備份(若未備份)
[ -f remove-zk-node.sh ] && cp -a remove-zk-node.sh remove-zk-node.sh.back# 2) 用干凈的 awk 補丁重寫腳本
awk '{# --- 第一步:修復 GC 參數(僅字符串替換,不影響其他邏輯) ---gsub(/-XX:\+UseConcMarkSweepGC/,"-XX:+UseG1GC");gsub(/[[:space:]]-XX:\+CMSParallelRemarkEnabled/,"");gsub(/[[:space:]]-XX:\+UseCMSInitiatingOccupancyOnly/,"");gsub(/[[:space:]]-XX:CMSInitiatingOccupancyFraction=[0-9]+/,"");print $0;# --- 第二步:在定義 DOLPHINSCHEDULER_LIB_JARS 之后插入 commons-cli 解析 ---if ($0 ~ /^export[[:space:]]+DOLPHINSCHEDULER_LIB_JARS=/ && done != 1) {print "";print "# ---- auto resolve commons-cli ----";print ": ${ZOOKEEPER_HOME:=/export/server/zookeeper}";print "COMMONS_CLI_JAR=\"\"";print "for p in \\";print " \"$DOLPHINSCHEDULER_HOME/api-server/libs/commons-cli-*.jar\" \\\\";print " \"$DOLPHINSCHEDULER_HOME/tools/libs/commons-cli-*.jar\" \\\\";print " \"$ZOOKEEPER_HOME/lib/commons-cli-*.jar\" \\\\";print " \"/usr/lib/zookeeper/commons-cli-*.jar\" \\\\";print " \"/opt/zookeeper/lib/commons-cli-*.jar\"; do";print " for f in $p; do";print " [ -f \"$f\" ] && COMMONS_CLI_JAR=\"$f\" && break";print " done";print " [ -n \"$COMMONS_CLI_JAR\" ] && break";print "done";print "if [ -z \"$COMMONS_CLI_JAR\" ]; then";print " echo \"[ERROR] commons-cli-*.jar 未找到,請拷貝一份到 api-server/libs/ 或設置 ZOOKEEPER_HOME/lib\" >&2";print " exit 1";print "fi";print "export DOLPHINSCHEDULER_LIB_JARS=\"$DOLPHINSCHEDULER_LIB_JARS:$COMMONS_CLI_JAR\"";print "# ---- end resolve commons-cli ----";print "";done=1}}
' remove-zk-node.sh.back > remove-zk-node.shchmod +x remove-zk-node.sh bash /export/server/apache-dolphinscheduler-3.1.9-bin/bin/install.sh
瀏覽器訪問地址 http://node1公網ip:12345/dolphinscheduler/ui 即可登錄系統UI。
默認的用戶名和密碼是 admin/dolphinscheduler123










: DAPO,VAPO,GMPO,GSPO, CISPO,GFPO)

)


)



