目錄
引入
結構定義
結構操作
初始化
插入
刪除
打印
查找
隨機位置插入
隨機位置刪除
銷毀
總結
數據結構專欄
https://blog.csdn.net/xyl6716/category_13002640.html
?精益求精? ?追求卓越
【代碼倉庫】:Code Is Here
【合作】 :apollomonasa@gmail.com

引入
前面我們已經學習了單鏈表及其基本應用,了解到單鏈表可以單向遍歷,一般無頭,也可以有頭,這里的頭就是虛擬頭節點(Dummy Head),比特就業課的老師喜歡管這個叫做哨兵位,其他地方沒聽過,不過不重要,這個頭通常用來占位置,方便遍歷的時候避免特判討論。此外還要引入循環的概念,就是鏈表最后一個節點指向第一個有效節點,以此實現循環的效果,結構上體現為環形鏈表。
由此,鏈表就根據帶頭、單雙向、循環可以分為8種,而今天主要介紹雙向鏈表,它是通過存儲前驅和后繼指針來實現雙向訪問的。
實際上這里介紹的是帶頭雙向循環鏈表。
結構定義
和單鏈表相比,只是增加了一個指針字段,可以概括為,數據區+前驅指針+后繼指針,只增加了一個指針,即可實現雙向訪問。


然后,將每個節點如圖連接后,就形成了雙向循環鏈表。
結構操作
接下來將介紹一些常用的操作的實現和代碼。
初始化
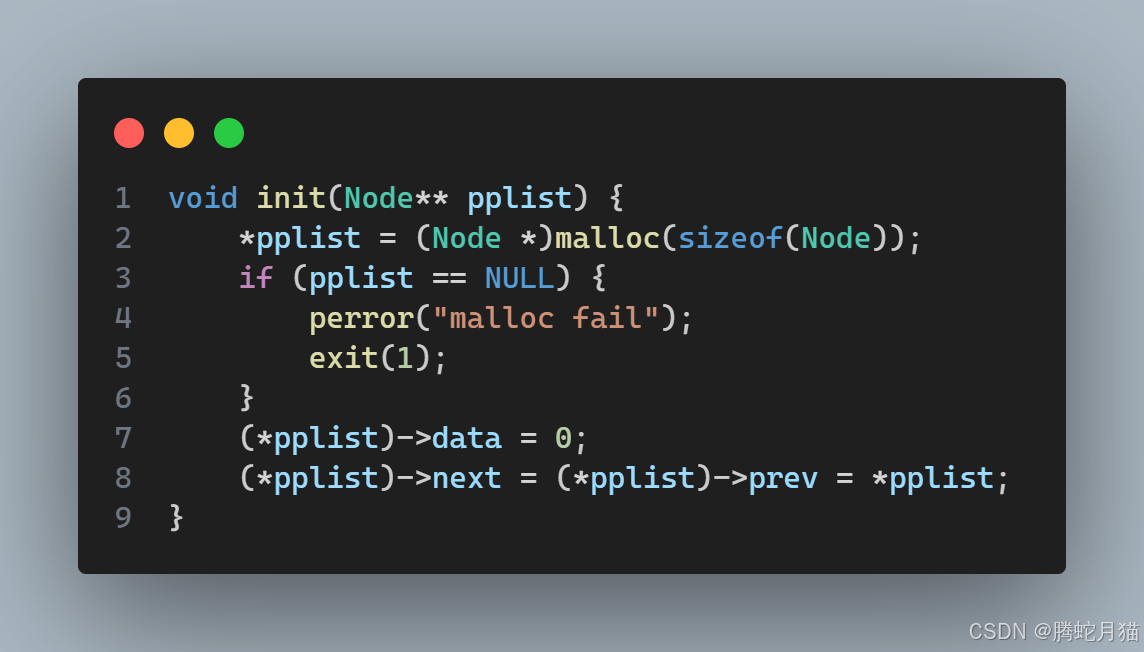
首先是參數列表的設計,由于我們需要知道鏈表的頭,并且還涉及到修改鏈表的頭指針,所以應該傳入頭指針的地址,也就是二級指針。
其次是前驅后繼的指向,由于我們的結構定義指出鏈表的頭的前驅是尾,尾的后繼是頭,所以對于一開始只有虛擬頭節點的空表來說,前驅后繼都是自己。
插入
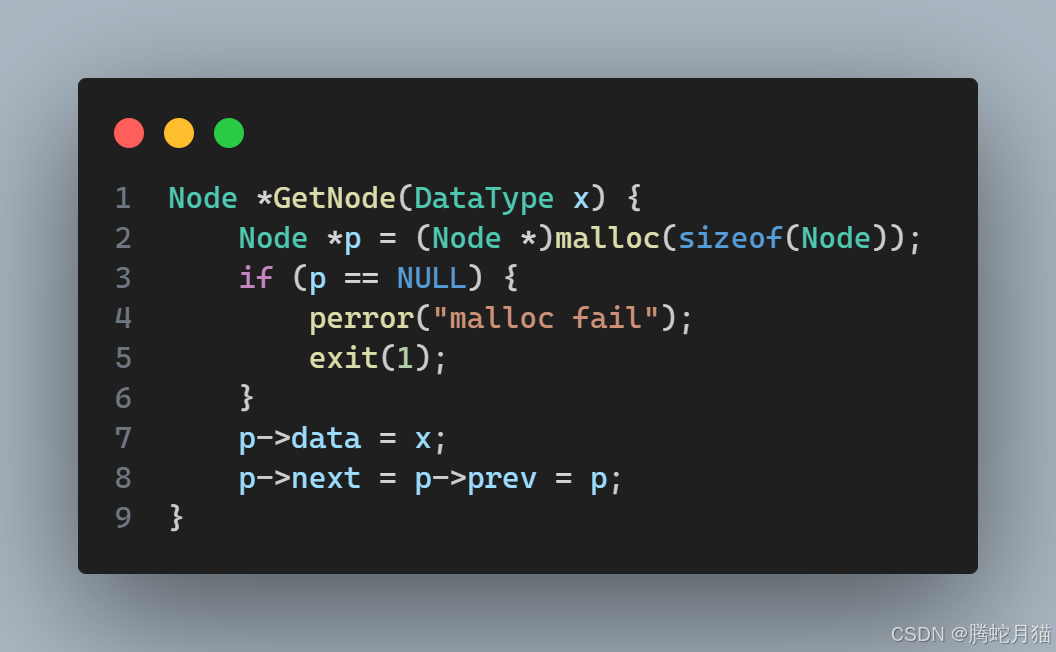
為了方便,編寫一個輔助函數,用于創建新節點。
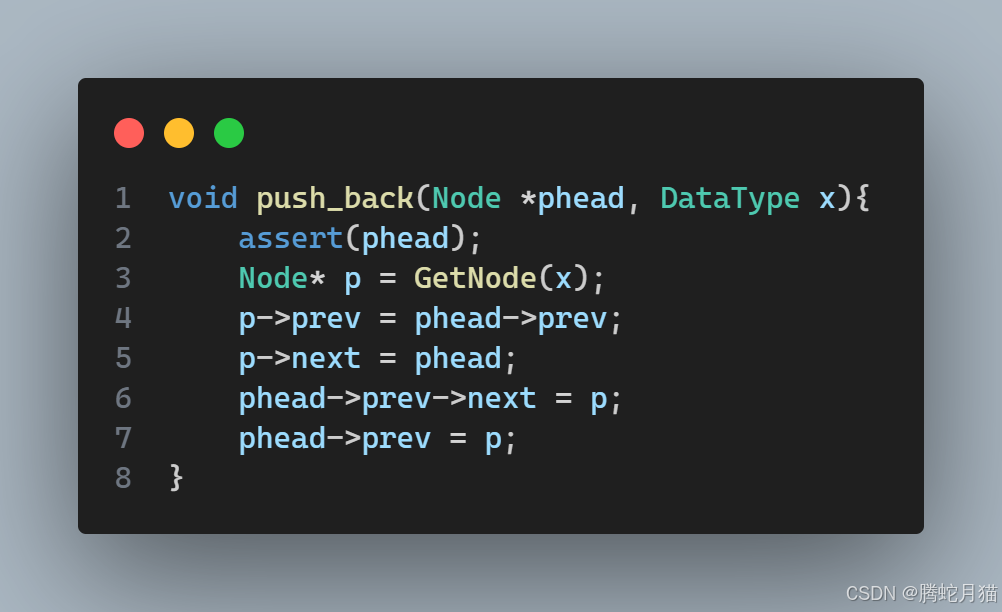
接下來就是尾插操作,創建新節點之后,需要修改的只有頭的前驅,尾的后繼,以及新節點的前驅后繼,優先修改新節點以保留原鏈表信息,然后再修改尾的后繼,最后修改頭的前驅。這個順序是最方便操作的,如果調換,就會發現不太容易找到尾。
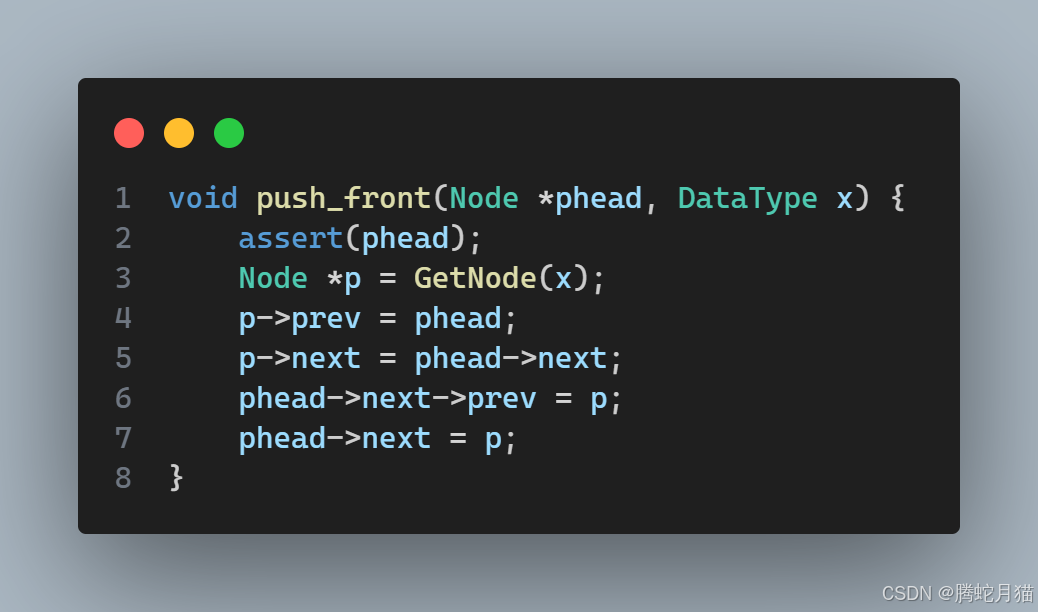
剩下的頭插也是大同小異,不多贅述,且看代碼:
刪除
這里有pop_back 和 pop_front,二者大同小異,代碼及其相似。
基本思路是先記錄要刪除的節點,然后站在這個節點調整被它影響到的它前驅和后繼的指針,最后釋放掉待刪除節點的內存。
此處補充一個輔助函數empty
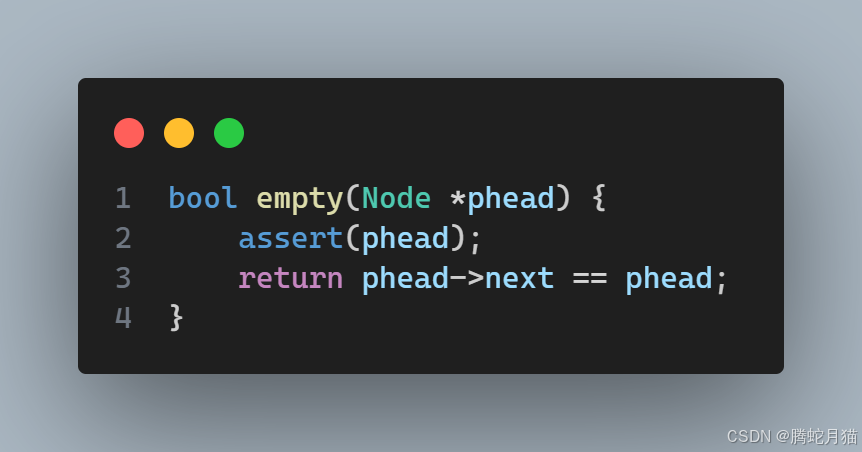
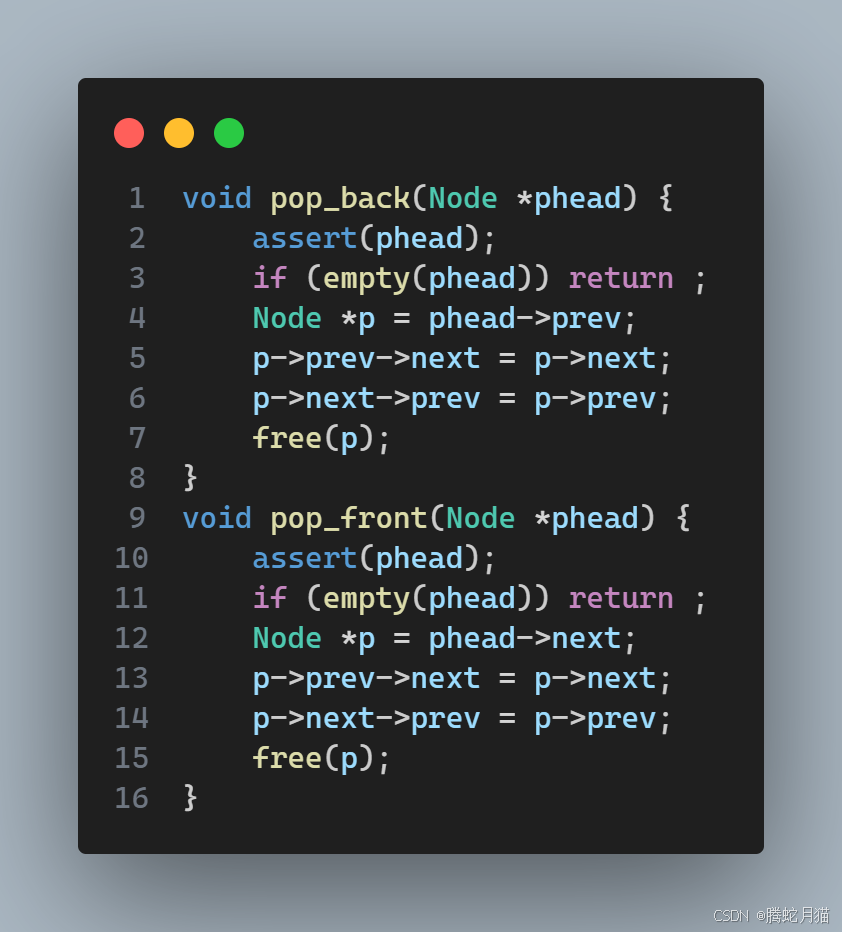
打印
打印就是遍歷,和單向鏈表并無不同,只不過判斷終止條件從空指針變成了Dummy Head。
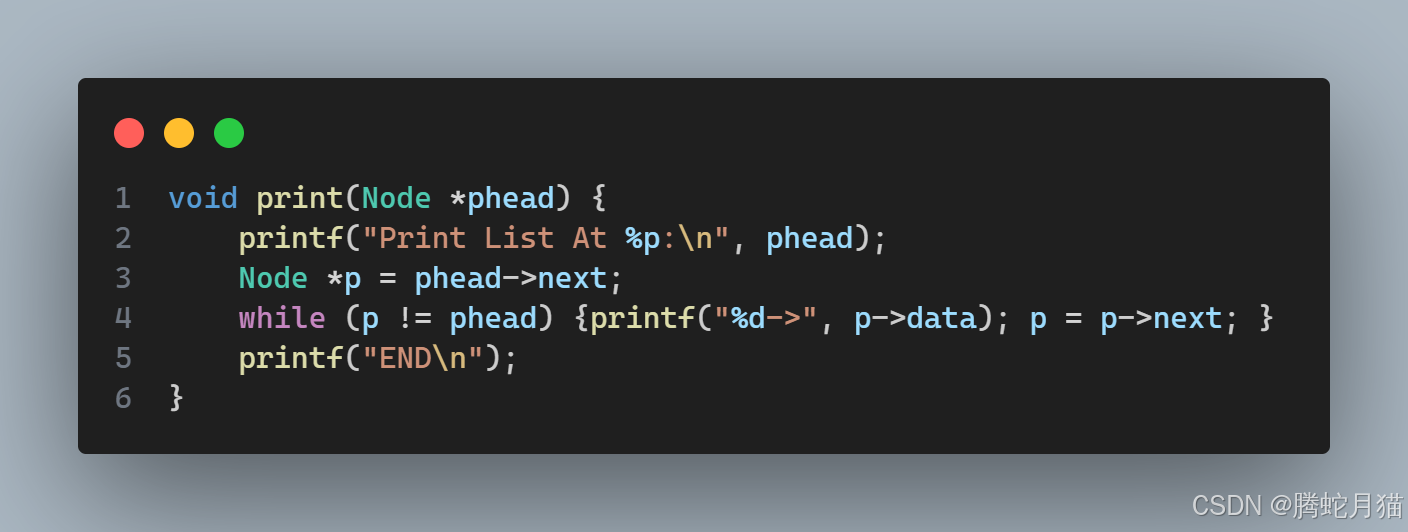
打印效果示例
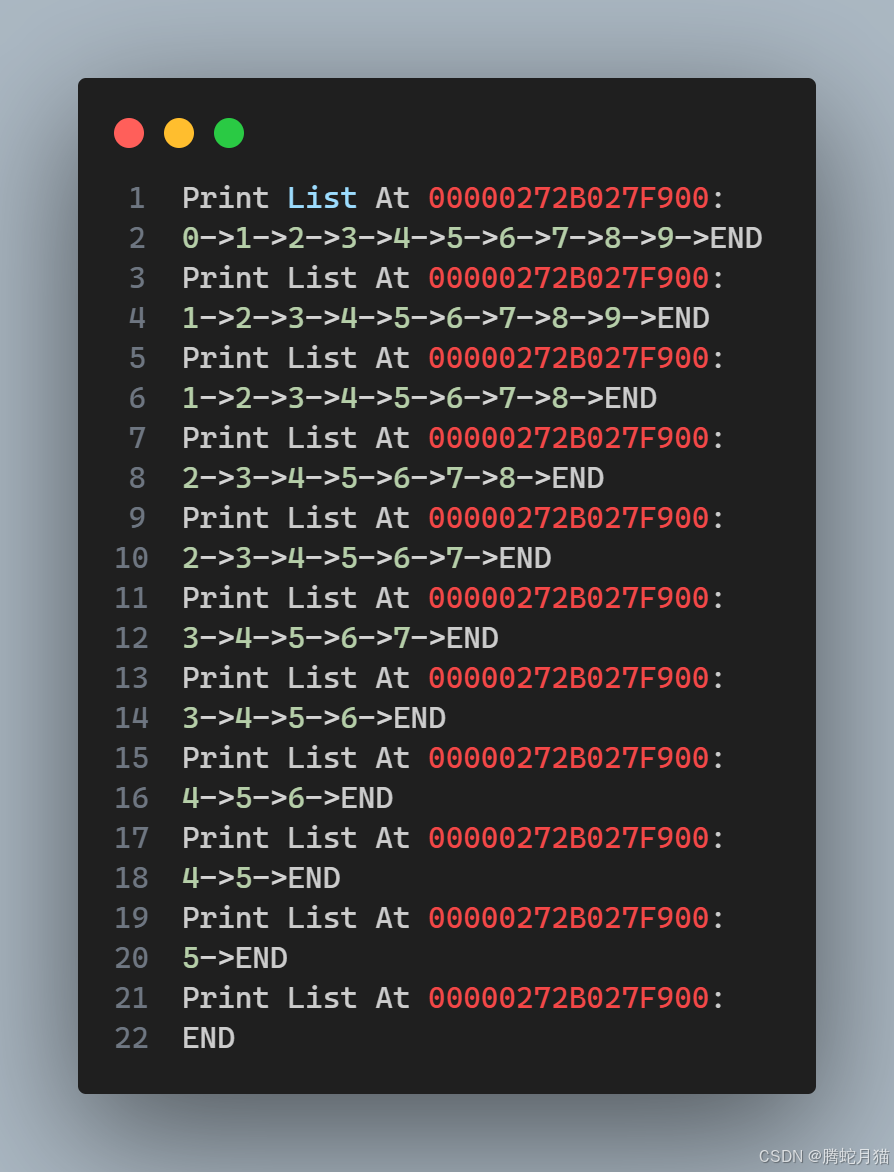
經過測試,頭刪和尾刪功能都正常。
查找
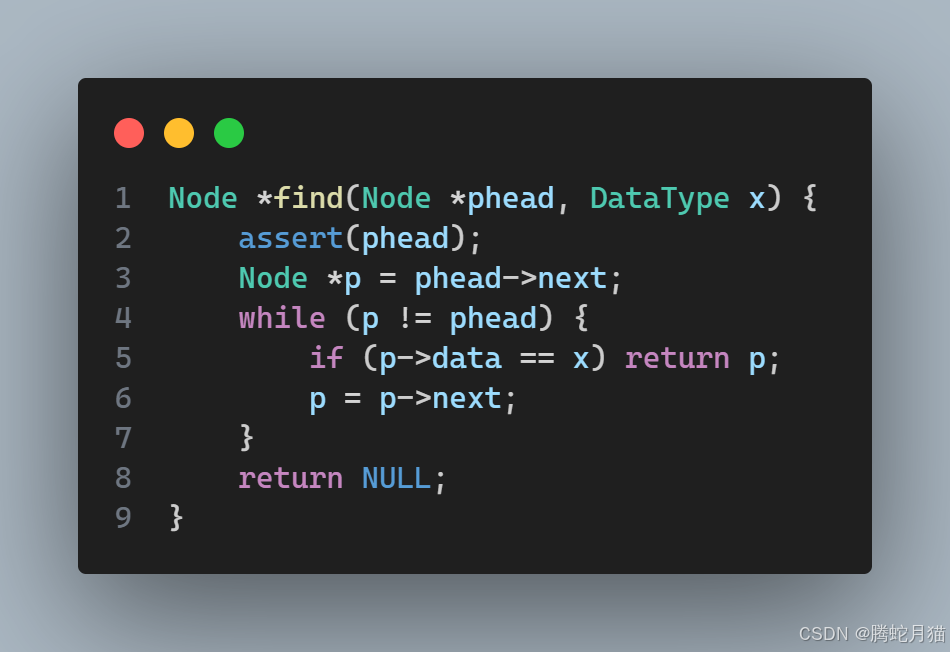
查找功能本質上還是遍歷,只是加上一個條件判斷。
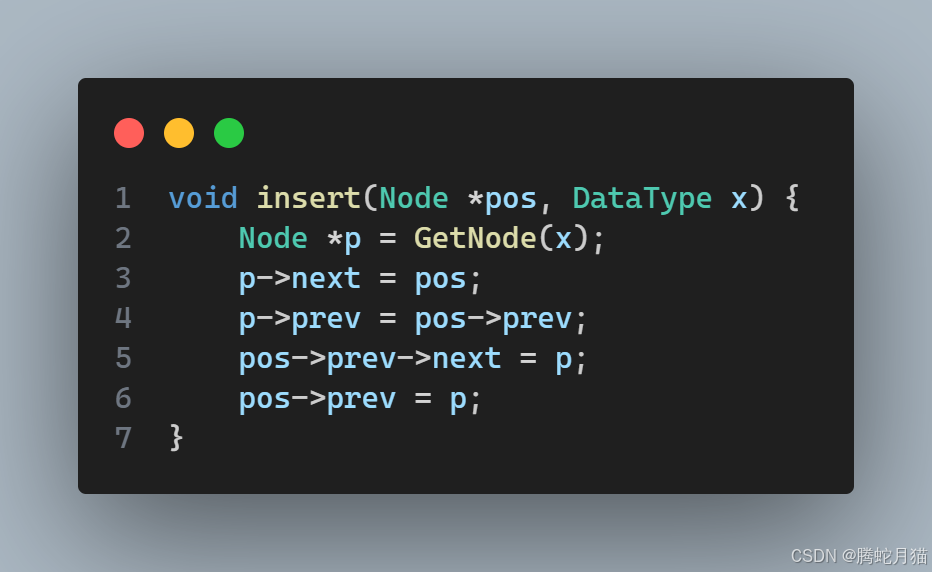
隨機位置插入
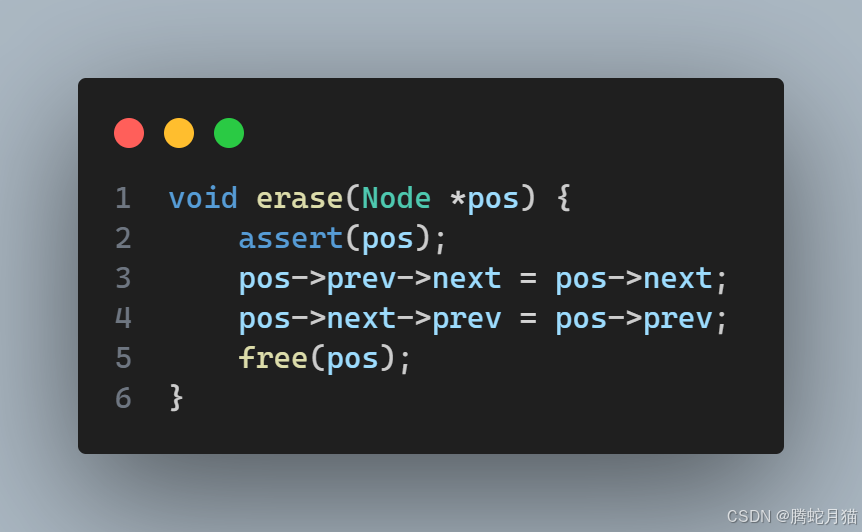
隨機位置刪除
銷毀

總結
比起單鏈表,雙向鏈表的結構定義雖然更多了,但是結構操作普遍在代碼長度和時間復雜度上都更簡單,就比如尾插和頭插都是O(1)的。換句話說,占用內存更多,運行時間更短,這就是所謂空間換時間。這種時空互換的觀念在今后的數據結構學習中還會有更多體現,但在今天初現端倪。
此外,初始化并不一定要像我那樣實現,可以設計成返回初始化后的Dummy Head,這樣使得函數調用更加一致,避免了傳入二級指針。
至此,線性表中的順序表和鏈表就講完了,下一篇文章正式開啟棧和隊列的學習,并且此后的文章在風格上不會有太大改變,但是在設計上會更加完整,篇幅會大大增加,一種數據結構不會再分為好幾篇文章講解,方便讀者查閱。







)

)




![[優選算法專題二滑動窗口——將x減到0的最小操作數]](http://pic.xiahunao.cn/[優選算法專題二滑動窗口——將x減到0的最小操作數])




